基于知識蒸餾的低分辨率陶瓷基板圖像瑕疵檢測
2023-12-04 02:40:06孫小棟朱啟兵徐曉祥
光學精密工程 2023年20期
郭 峰, 孫小棟, 朱啟兵*, 黃 敏, 徐曉祥
(1. 江南大學 輕工過程先進控制教育部重點實驗室,江蘇 無錫 214122;2. 無錫市創凱電氣控制設備有限公司,江蘇 無錫 214400)
1 引言
陶瓷基板是大功率電力電子電路結構的基礎材料。在陶瓷基板的生產過程中,常出現鍍金層損傷、邊緣多金、缺瓷、油污、摻雜異物五種瑕疵,這些瑕疵會影響電子器件的壽命、性能以及穩定性。快速而準確地檢測并剔除這些瑕疵基板對于保證產品質量具有重要意義[1]。目前,利用機器視覺技術結合深度神經網絡進行產品瑕疵檢測已成為主流方法。本研究團隊針對陶瓷基板瑕疵形狀多變、尺寸跨度大,且多金和缺瓷瑕疵目標較小,樣本量小,各類瑕疵數量分布不均勻等問題,提出了一種改進的YOLOv4 算法,通過修改置信度損失函數,引入注意力機制,優化錨框尺寸等策略,實現了五類瑕疵的準確檢測(平均準確率98.3%)[1]。這一精度是在單個陶瓷基板圖像分辨率為608×608 的條件下取得的。由于陶瓷基板尺寸較小,實際生產過程中,一個較大的基板片上需要制作多個行列排布的陶瓷基板,在保證上述圖像分辨率的條件下,要完成整個基板片上所有陶瓷基板的圖像采集,需要頻繁移動圖像采集設備,從而導致較長的圖像采集時間,不利于檢測速度的提高。為了提高檢測速度,一個潛在的方法是擴大圖像采集設備的視場(Field of View, FOV),實現多個陶瓷基板完整信息的同時采集;從而減少圖像采集設備的移動頻次,達到節約圖像采集時間的目的。但FOV的增加,也導致了單個陶瓷基板的分辨率下降。陶瓷基板分辨率的下降(稱之為低分辨率陶瓷基板圖像)帶來了瑕疵像素尺寸的縮小,給瑕疵(特別是小尺寸瑕疵)檢測帶來困難,導致大量的漏檢和誤檢現象產生。因此,提高低分辨率陶瓷基板圖像上的瑕疵檢測精度對于滿足實際生產中對瑕疵檢測快速性的要求具有重要價值。
目前主要通過超分辨率重建方法[2]和知識蒸餾方法[3]來提高低分辨率圖像上的目標檢測性能。超分辨率重建方法是指利用無監督方法或者有監督方法重建出高分辨率圖像,然后再利用目標檢測網絡對目標進行檢測,該方法雖然能通過還原出高分辨率圖像的特征信息從而提高檢測性能,但檢測高分辨率圖像的速度也會隨之降低,而在本文任務中,隨著FOV 的增加,相同時間內需要檢測的圖像也隨之增加,因此該方法無法滿足本文檢測任務對實時性的要求。
知識蒸餾的基本思想是構建教師網絡和學生網絡,基于神經網絡遷移學習的策略,利用教師網絡學習到的信息指導學生網絡的訓練,從而使得學生網絡獲得更好的性能。目前知識蒸餾算法主要用于深度神經網絡的模型壓縮,以獲得相對于教師網絡更加輕量化且性能良好的學生網絡[4-10]。最近,QI 等[3]為提高低分辨率圖像的目標檢測性能,利用知識蒸餾策略將教師網絡學習到的高分辨率圖像特征信息用于指導學生網絡的訓練。取得了較好的低分辨率圖像下的目標檢測性能。
受QI[3]的工作啟發,本文將知識蒸餾思想引入到低分辨率陶瓷基板圖像的瑕疵檢測,基于YOLOv5 框架構建由教師網絡和學生網絡組成的知識蒸餾模型YOLOv5-CSKD,利用教師網絡學到的高分辨率特征信息指導學生網絡的訓練,從而使得學生模型能夠學習到低分辨率圖像特征在高分辨圖像中的特征分布,同時,在教師網絡中引入基于 Coordinate Attention (CA)[11]注意力思想的特征融合模塊,使得教師網絡學習到的特征同時適應高分辨率圖像信息和低分辨率圖像信息,從而能較好的指導學生網絡的訓練;仿真結果表明,基于知識蒸餾的陶瓷基板瑕疵檢測模型YOLOv5-CSKD 能夠取得了96.80%的平均準確率和90.01%的平均準確率的檢測性能。
2 YOLOv5 算法介紹
YOLOv5 算法主要由主干網絡(backbone)、頸部網絡(neck)、以及頭部網絡(head)三部分組成。其中主干網絡與CSPDarknet53 類似,采用多層次結構網絡,提取輸入圖像的不同尺度的特征圖,每一層均由卷積塊CBS(Conv+Batch-Norm+Silu)和殘差結構組成殘差塊,在減少計算量,緩解梯度消失的同時保證了特征提取的完整性;頸部網絡為PANet[12],利用從底到頂的通道和從頂到底的通道,將高層和低層的特征圖進行融合編碼,以增強特征圖的信息表達;頭部網絡將融合之后的特征圖進行解碼,得到最后的預測結果(目標的種類及位置信息)。YOLOv5 的損失函數如式(1)~式(4)所示。
其中:LOSS 表示模型訓練總的損失函數,LOSSreg為定位損失函數,LOSSconf為置信度損失函數,LOSScls為分類損失函數。1objij代表預測輸出中第i網格內第j預測框內有目標;S2代表每個特征層上面有S×S個單元格;B=3,代表每個單元格內有3 個預測框;bij,b?ij為預測框和真實框;IoU,ρ2,c2分別表示兩個框的交并比值,中心點歐氏距離和最小閉包區域的對角線距離;v為長寬比一致性;Cij,C?ij分別為置信度的真實值和預測值;α,λnoobj為權重系數;1noobjij代表第i網格內第j預測框內無目標;P ij(c),P?ij(c)表示目標屬于每一類的概率的真實值和預測值。
最后,通過置信度閾值的設置來過濾掉得分較低的邊界框,對剩下的邊界框進行非極大值抑制(Non-Maximum Suppression, NMS)操作來剔除重復的邊界框,從而實現目標檢測。
3 基于知識蒸餾的YOLOv5 模型設計
知識蒸餾是指由教師-學生網絡組成的訓練網絡,通常是已訓練好的教師模型提供知識,學生模型通過蒸餾訓練來獲取教師的知識。傳統的目標分類或檢測任務中,一般采用“0”和“1”硬標簽方式對數據進行標注,但此標注方式使得標簽中包含較少的類間關系,而知識蒸餾則采用教師網絡的輸出概率作為標簽,可以較好地表達類間的相關性。
高分辨率的大尺寸圖片包含著目標更詳細的信息,因而可以使目標檢測網絡獲得更好的性能。但是高分辨率圖片在深度學習網絡中的計算量和內存量是巨大的,實際運用時需要綜合考慮計算速度與計算量。同時,在高分辨率圖片上訓練的網絡模型無法直接用于預測低分辨率的圖片。借助于知識蒸餾的方法,可以將高分辨率的復雜教師模型所學習到的知識遷移到低分辨率的高效學生模型中[13]。例如,Fu 等人[14]將教師模型所學習的空間和時間知識遷移到低分辨率的輕量級時空網絡中來執行視頻注意預測任務。
在利用知識蒸餾進行模型壓縮時,輸入圖像為相同尺寸,模型無需考慮輸入尺寸帶來的特征尺寸不一致的問題,但在利用知識蒸餾提高低分辨率圖像檢測性能的方法中,由于許多網絡結構采用多尺度的思想來檢測不同尺寸大小的目標,使得學生網絡和教師網絡進行蒸餾的特征圖來自于不同深度的特征層,因此需要對網絡結構進行設計使得進行知識蒸餾的教師網絡特征與學生網絡特征的尺寸一致。
考慮到性能和實時性,本文以YOLOv5l 作為教師網絡和學生網絡的主要網絡結構,在此基礎上實現基于知識蒸餾的目標檢測算法設計。
3.1 教師網絡設計
本文的知識蒸餾主要關注頸部特征層的知識蒸餾。YOLOv5 網絡的輸出由3 層預測支路組成,每一層的特征尺寸和通道數都不相同,因此,當教師網絡采用高分辨率圖像進行訓練,而學生網絡采用低分辨率圖像進行訓練時,相同大小尺寸的特征層通道數不相同,而相同通道數的特征層則尺寸大小不同,使得無法有效進行知識蒸餾訓練。為了使教師網絡的特征信息能夠指導學生網絡的訓練,需要采用卷積網絡將教師網絡或學生網絡的特征層進行處理,使得進行知識蒸餾兩個網絡的特征層的尺寸和通道數在同一層級上相同。
在教師網絡的訓練過程中,若僅采用高分辨率圖像作為訓練數據,會使得教師網絡學習到的特征偏向于高分辨率圖像的信息分布,導致學生網絡的性能提升有限,因此在教師網絡的訓練過程中同時利用高分辨率圖像和低分辨率圖像作為輸入,使得教師網絡不僅能學習到高分辨率圖像下更精細的特征信息,也能適應低分辨率圖像下的信息分布。
教師網絡的結構圖如圖1 所示,左側為高分辨率圖像(448×448)輸入學習到的特征,右側為低分辨率圖像(224×224)輸入學習到的特征,二者采用同一網絡結構,其中,CI,C'I(I=0,1,…,5) 為主干網絡的特征,PJ,P'J(J=2,3,…,5)為頸部網絡的中間特征,NS,N'S(S=2,3,…,5) 為頸部網絡的輸出特征,FS(S=2,3,…,5)為融合之后的特征。由于輸入圖像的分辨率相差一倍,因此NS的特征尺寸大小是N'S的兩倍,如果利用卷積對NS進行尺寸縮小會使得NS包含的特征信息被壓縮,從而導致小目標檢測能力變弱。因此,本文選擇將與NS特征尺寸相同的N'S-1進行通道壓縮,使其通道數與NS一致,這樣就將可以來自不同分辨率的特征進行融合。
在原始YOLOv5 模型中,當輸入分辨率較小,且數據集中的目標尺寸偏小時,較少的頂層特征信息會被激活去參與預測,即N5這一條支路較少參與預測,但若是直接去掉此支路則會導致性能下降,底層無法獲取從N5所在的層級傳遞的高維特征信息。基于此,考慮到N'5沒有對應的高分辨率圖像的特征尺寸與之對應,在設計特征融合時,只利用N'4,N'3,N'2參與特征融合以及預測。由于N'2對應的特征尺寸更大,有著更加精細化的特征,能在一定程度上提高小目標檢測的能力。
教師網絡的損失函數如式(5)所示,其中LOSSh,LOSSl,LOSSf分別為高分辨率圖像的特征、低分辨率圖像的特征以及兩種分辨率圖像的融合特征經過YOLOv5 頭部網絡所產生的預測損失(通過公式(1)計算得到);λ為超參數,用來平衡損失中融合特征損失所占的比重。
3.2 特征融合模塊設計
為了使指導學生網絡訓練的教師網絡特征同時能包含兩種分辨率圖像的信息,QI[3]設計了一個特征融合模塊,將來自不同分辨率圖像的特征進行融合生成新的特征并參與教師網絡的損失函數計算,最后用這個融合特征指導學生網絡的訓練,但QI 的特征融合方法僅給來自不同分辨率的特征賦予一個權重,無法從多維數據中選擇出更加全面有效的特征信息,因此本文基于CA 注意力的思想,提出了一個能夠同時關注通道和空間權重的輕量級特征融合模塊,即CAF(Coordinate Attention Fuse)模塊,模塊結構圖如圖2 所示,其中,NS,NS-1',FS(S=3,4,5)分別為教師網絡、學生網絡的頸部結構輸出特征和二者的融合特征。
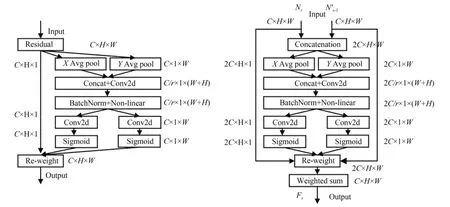
圖2 特征融合模塊結構圖Fig.2 Structure of feature fusion module
假 設 輸 入 為NS,NS-1, 其 中{NS,NS-1}∈RC×H×W,C為特征通道數,H,W為特征尺寸的高和寬。首先,將NS,NS-1進行通道拼接得到,然后分別沿著X,Y 方向 進 行 Avg Pool 得 到分別反映了特征層在X,Y方向上的關聯性;將處理成同樣的維度并進行通道拼接,然后經過卷積操作,Non-linear 層之后,得到,使得特征層通道信息和空間信息發生了交互;將進行分離并經過卷積層以及Sigmoid 函數之后,得到,此時的融合了兩個特征之間的空間以及通道信息,然后將二者相乘得到權重矩陣hS∈R2C×H×W,分別將NS,NS-1與hS{0},hS{1}進行矩陣相乘,然后將得到的結果相加得到最終的融合特征FS,其中,hS{0},hS{1}表示按hS的通道維度上的索引順序將hS分成維度為C×H×W的兩個特征塊。最后得到的融合特征FS不僅從高分辨率特征和低分辨率特征中選取了最合適的特征信息,而且同時考慮了通道和空間上的最優特征信息。
3.3 學生網絡設計
學生網絡的結構圖如圖3 所示,學生網絡主要利用低分辨率圖像進行檢測,其主體網絡結構與教師網絡一致,無特征融合模塊,在訓練時直接加載教師網絡的權重進行訓練。
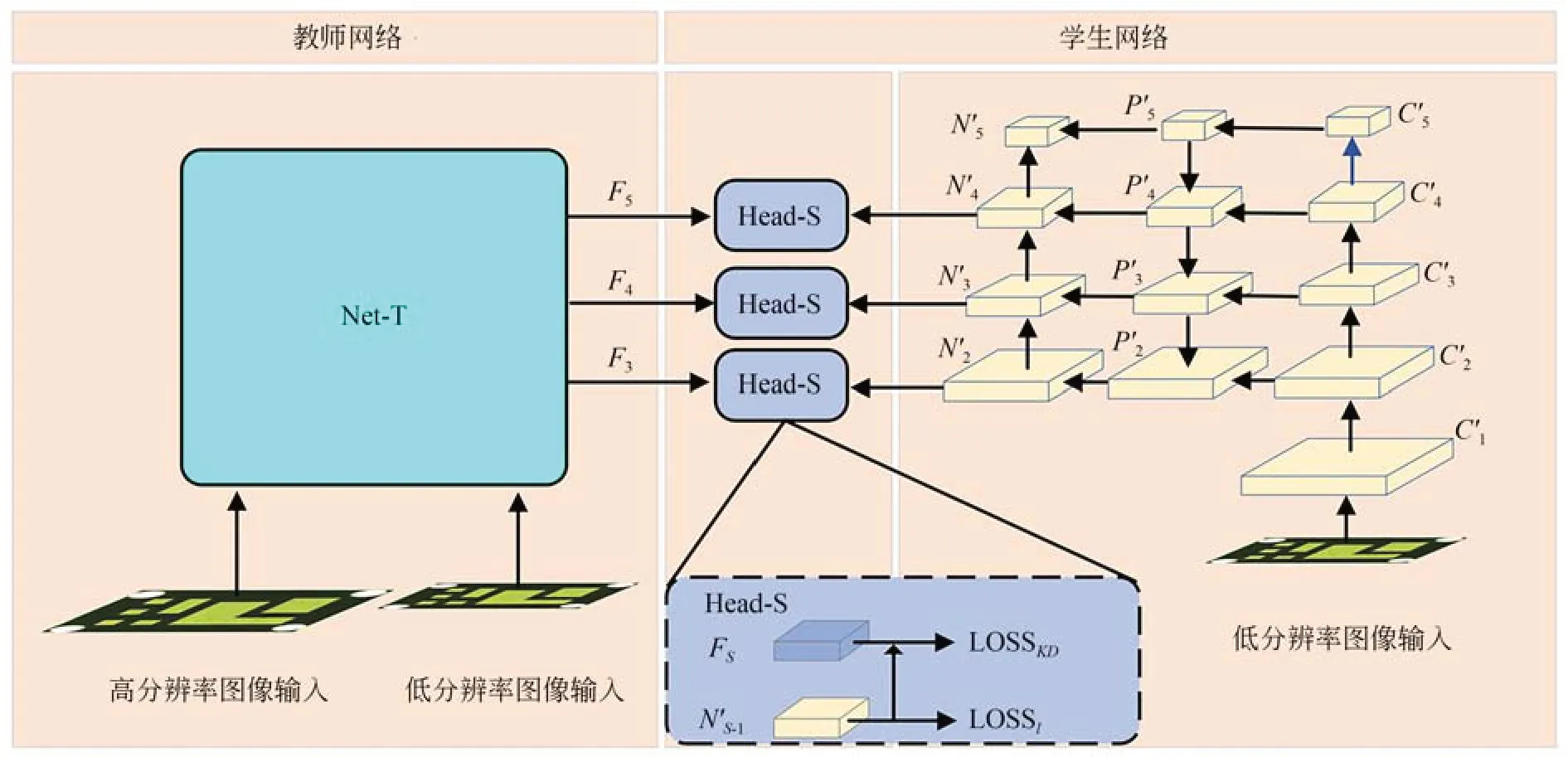
圖3 學生網絡結構圖Fig.3 Structure of student network
學生網絡的損失函數如式(6)所示,學生網絡的損失主要包含兩部分,一部分是學生網絡自身低分辨率圖像輸入下的原始YOLOv5 損失,即LOSSl;另一部分是學生網絡頸部網絡輸出的特征NS-1與教師網絡的融合特征FS之間的知識蒸餾損失,即LOSSKD,其定義如式(7)所示,其中S∈[3,5],LOSSKD采用L1 損失度量NS-1與FS之間的差距;γ為超參數,用來平衡學生網絡的損失函數中預測損失與知識蒸餾損失所占的比重。
3.4 基于GHM 機制的置信度損失函數設計
當模型訓練至穩定時,一些類內差距較大或者數量較少的難檢測瑕疵樣本,其損失會被其他同類的易檢測樣本或數量較多的其他類樣本所抑制,使得其特征在訓練過程中難以被有效學習,從而導致模型對這些瑕疵的特征信息不敏感,造成漏檢。為了緩解這種情況,本文利用GHM 分類損失函數(gradient harmonizing mechanism-classification, GHM-C)[15]改進了模型的置信度損失函數,學生網絡和教師網絡的置信度損失函數均采用改函數。具體實現步驟為:
(1)對于模型輸出的第k個預測框(k=1,…N,N為預測框的總數),按公式(8)計算其梯度模gk,其中Ck,C?k分別代表第k個預測框的置信度預測值與真實值;
(2)將置信度的輸出區間[0,1]按步長劃分為若干等長子區間St(t=1,…M,M為子區間數量),統計預測框的梯度模落在子區間St的數量Nt;計算得到各樣本的梯度密度調和參數βk(如式(9)所示);
(3)將原始模型計算的置信度交叉熵的梯度值分別乘上各自歸屬子區間的梯度密度調和參數βk,從而達到衰減其影響的目的(如式(10)所示)。
其中:LGHM-C表示最終的基于GHM-C 的置信度損失函數,LCE表示交叉熵損失。修改之后模型最終的損失函數如式(11)所示,LOSS 是總的損失函數,其中LOSSreg為定位損失函數,LOSScls為分類損失函數。最終的教師網絡和學生網絡的損失函數LOSSh,LOSSl,LOSSf均由LOSS組成。
4 實驗及結果分析
4.1 實驗環境
本次實驗的操作系統為Windows 10(64位),CPU 為英特爾Core i9-10900X@3.70GHz,內存為64 GB,GPU 為兩個NVIDIA GeForce RTX 3090,總顯存為48 GB。深度學習框架實現為Python Pytorch, GPU 加速庫為CUDA11.0。
4.2 數據集介紹
本文需要檢測的陶瓷基板圖像如圖4(a)所示。其中方塊區域為鍍金層,本文所指的瑕疵都是指出現在鍍金層上的瑕疵。典型瑕疵主要有污漬、異物、多金、缺瓷以及損傷五類,部分瑕疵如圖4(b)所示。污漬瑕疵會出現鍍金層上任何一個區域,由于無法預測是何種物質導致的污漬,因此無法定義一個通用的顏色信息或形狀信息去描述這種瑕疵,且污漬的尺寸跨度大、形狀多變;異物瑕疵大多來源于外界環境,因此形狀和顏色也具有多樣性及不定性,且由于陶瓷基板屬于高集成度的產品,圖像采集均是采用帶有顯微功能的相機完成,因此一些極細小的物質也會被認為是異物,并且很多異物的尺寸很小,給模型檢測帶來了很大的挑戰;缺瓷瑕疵主要分布在鍍金層邊緣,主要是由于生產工藝不良造成鍍金不全,其形狀較小,屬于小目標瑕疵;損傷瑕疵主要是鍍金層的劃傷或者刮傷,尺寸跨度大且形狀(線狀或帶狀)分布多變;多金瑕疵主要是由于設備或生產工藝問題造成的鍍金層邊緣出現凸起,形狀較小,也屬于小目標瑕疵,且分布區域多變。

圖4 陶瓷基板與部分瑕疵示意圖Fig.4 Schematic diagram of ceramic substrate and defects
采集的單張陶瓷基板原始圖像經過裁剪后分辨率約為1 637×1 175,按照生產需求,采集的圖像由原來的一次性采集1 個陶瓷基板到現在的一次性采集16 個陶瓷基板,如圖5 所示。裁剪后的單張陶瓷基板原始圖像分辨率將降至410×294 左右,因此模型輸入分辨率需降至224×224左右。為了還原真實現場的低分辨率陶瓷基板瑕疵檢測,本文實驗的數據集由裁剪后的原始圖片分別降采樣至224×224 分辨率與448×448 分辨率,其中224×224 為低分辨率輸入圖像,448×448 為高分辨率輸入圖像。

圖5 相機拍照視野示意圖Fig.5 Schematic diagram of camera field of view
4.3 數據集增強
本實驗共采集到2 413 張陶瓷基板圖像,經過目標區域提取預處理之后得到陶瓷基板數據集。按照文獻[16]的方式對2 215 張訓練樣本進行數據增強,具體步驟為:從2 215 張圖片中裁剪出50 張包含典型瑕疵(多為樣本數較少的瑕疵)的子區域(每個區域只包含一種典型缺陷);并將這50 張子區域圖像進行水平、垂直翻轉,尺度的縮放,引入高斯噪聲(標準差為1.2)以及銳化操作等;最后將這些增強后的裁剪圖像“粘貼”至無瑕疵陶瓷基板圖像中可能出現瑕疵的區域,從而獲得增強后的圖片2 386 張,用作訓練,剩余198張未增強圖片用作測試。使用LabelImg 圖像標注軟件進行人工標注,數據集格式為VOC2007,后轉為YOLO 數據集格式。
4.4 網絡訓練
本文的網絡訓練分為教師網絡訓練和學生網絡訓練。教師網絡訓練階段,總訓練Epoch 為200 次,批量大小(Batch size)為32,初始學習率為0.01,warm_up 的Epoch 數為3、動量為0.8、初始bias_lr 為0.1,權重衰減系數為0.000 5,使用隨機梯度下降法(SGD)進行優化,動量等于0.937。本文將超參數λ設為0.8。
學生網絡訓練階段,總訓練Epoch為200次,批量大小(Batch size)為64,初始學習率為0.01,warm_up 的Epoch 數為3、動量為0.8、初始bias_lr為0.1,權重衰減系數為0.0005,使用隨機梯度下降法(SGD) 進行優化,動量等于0.937,知識蒸餾采用的溫度系數為3.0。本文將超參數γ設為0.4。
4.5 實驗結果
4.5.1 不同檢測算法的結果對比
本文選取準確率、召回率作為評判模型性能的指標,計算公式如式(12),式(13)所示:
其中:TP 表示將正例預測為正例的個數,FP 表示將反例預測為正例的個數,FN 表示將正例預測為反例的個數。
待檢測圖片數量共198 張,每張圖片包含1至5 種類別的瑕疵,污漬、異物、多金、損傷以及缺瓷五種瑕疵的檢測結果如表1 所示。
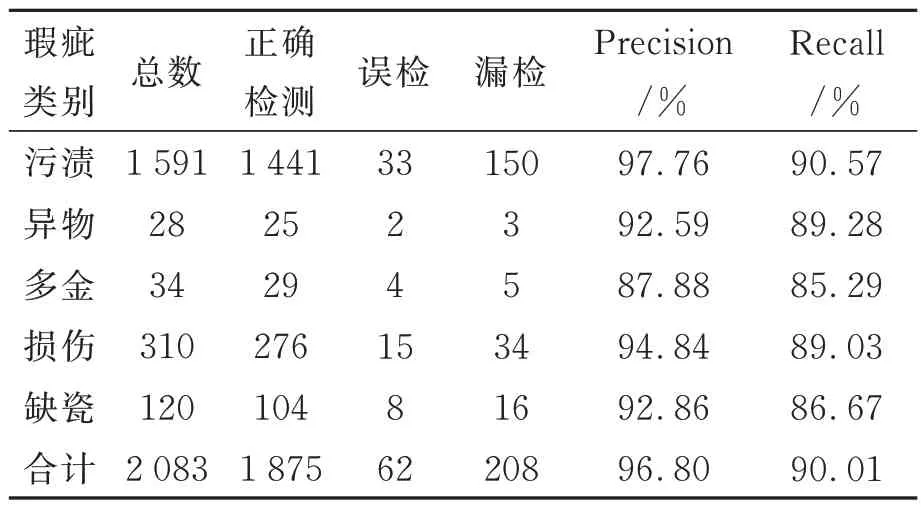
表1 瑕疵檢測結果Tab.1 Results of defect detection
由表1 可知,本文提出的算法對于陶瓷基板中污漬、異物、多金、損傷以及缺瓷五種不同種類瑕疵的檢測準確率已基本達到87.88%以上,召回率均已基本達到85.29%以上。其中,多金和缺瓷的檢測效果較差,其原因可能為:一方面這兩種瑕疵的樣本數量較少,因此在訓練時勢必會受到影響;另一方面,這兩種瑕疵尺寸相對較小,當圖片分辨率降低時,模型能夠關注的像素變少,因此檢測性能較差。
為了進一步驗證本文算法在陶瓷基板瑕疵檢測上的有效性,將本文算法與常見的目標檢測算法Faster R-CNN[17],Cascade RCNN[18],YOLOv4[19],YOLOX[20],YOLOv6[21],YOLOv7[22]以及改進前的YOLOv5 在本文數據集上進行對比試驗,采用原文作者的實驗參數,未采用知識蒸餾的模型均訓練400 Epoch,選取平均準確率、平均召回率作為評價指標,不同算法的性能如表2所示。表2 中的“-”表示該模型在給定的訓練次數下實驗未收斂。
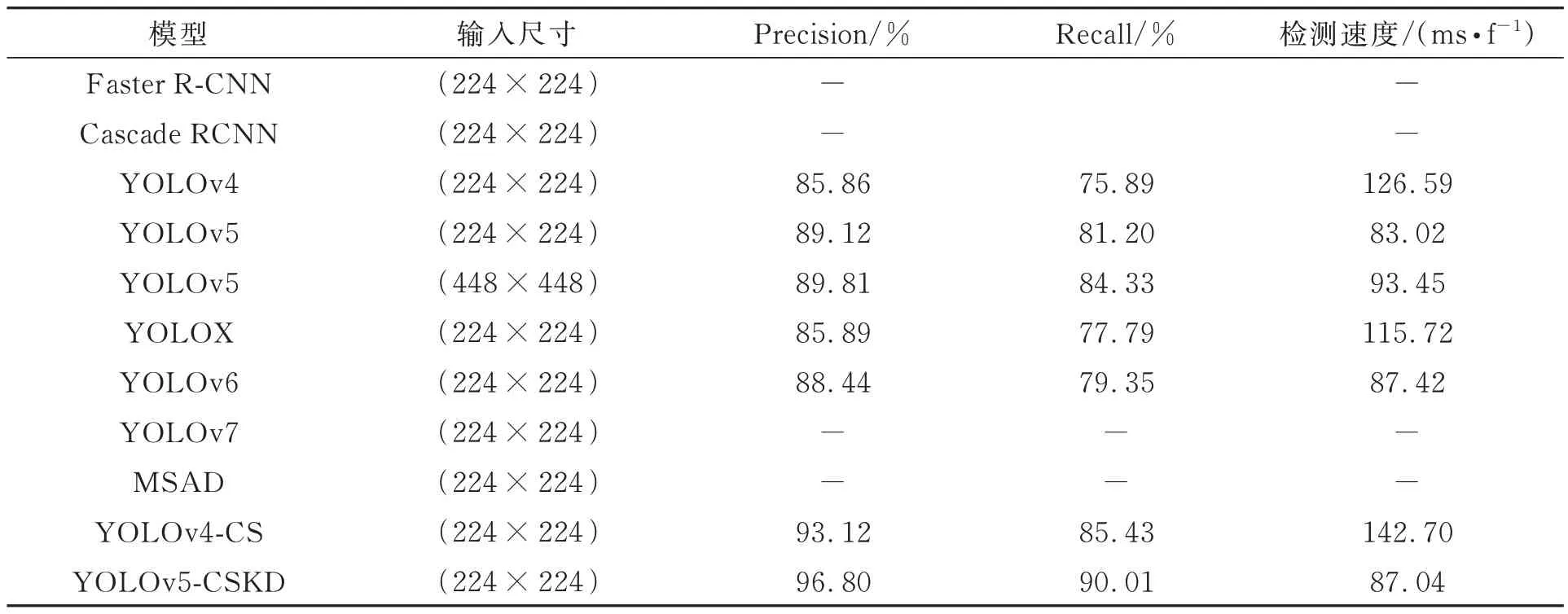
表2 不同算法瑕疵檢測結果Tab.2 Defect detection results of different algorithms
根據表2,本為提出的YOLOv5-CSKD 算法對陶瓷基板瑕疵檢測平均準確率和平均準確率分別達到了96.80%和90.01%,相比于原始的YOLOv5 算法,分別提高了6.99%和8.81%,且相比于原始YOLOv5 模型,本文提出的YOLOv5-CSKD 算法在224×224 分辨率下的檢測時間相差較小。在224×224 分辨率下所有對比算法中,YOLOv5-CSKD 具有最好的性能,說明本文提出創新的有效性。
圖6 給出了陶瓷基板典型瑕疵輸入為224×224 分辨率的檢測結果(局部截圖)。圖6 中(a)~(e)的檢測結果依次為YOLOv4,YOLOv5,YOLOX,YOLOv6,YOLOv5-CKSD。

圖6 不同模型的局部檢測結果Fig.6 Local detection results of different models
從圖6 中可以看出,在(224×224)的輸入分辨率下,YOLOv4 的檢測結果相對較差。原始YOLOv5,YOLOX,YOLOv6 均存在不同程度的漏檢,其中,原始的YOLOv5 檢測結果明顯好于YOLOX,YOLOv6,所以本文采用YOLOv5 作為基準研究模型。對比原始YOLOv5 以及YOLOv5-CKSD,可以得出,YOLOv5-CKSD 能有效檢測出原始YOLOv5 模型無法檢測出的瑕疵,因此可以證明本文提出的模型YOLOv5-CKSD 在低分辨率陶瓷基板輸入下的檢測性能較其他方法有明顯提升。
4.5.2 對比實驗
為了驗證本文提出的特征融合模塊CFA 的有效性,本文針對該模塊進行了對比實驗。對比實驗結果如表3 所示,其中,SUM 表示低分辨率特征和高分辨特征直接逐像素相加,C-FF 為QI[3]提出的特征融合方式,CAF 為本文提出的特征融合方式。三種融合特征融合方式的局部對比結果如圖7 所示。
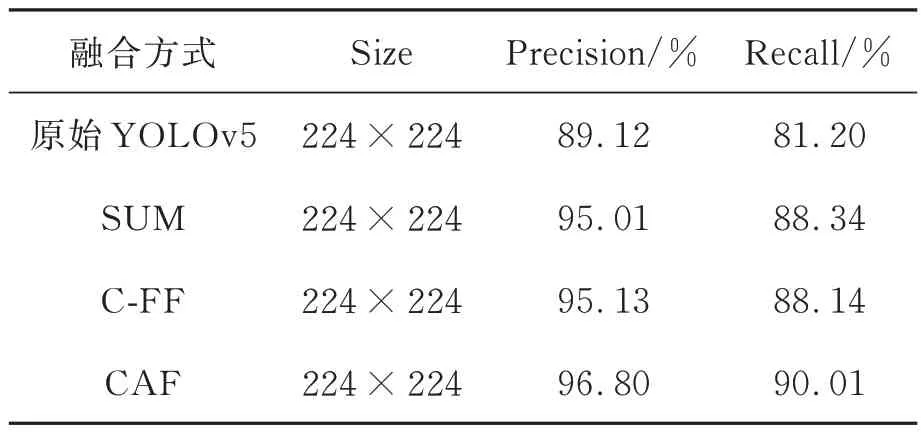
表3 不同特征融合方式的實驗結果Tab.3 Experimental results of different feature fusion methods
從表3 中可以看出,在對YOLOv5 進行知識蒸餾時,基于SUM 融合方式與基于C-FF 融合模塊的性能差距較小,本文提出CAF 模塊具有更好的結果,獲得了96.80%的平均準確率和90.01%的平均準確率。從圖7 中可以看出,在低分辨率輸入下,SUM 和C-FF 對小目標信息的敏感度較低,無法準確檢測出瑕疵,而本文提出的CAF 模塊則能準確檢測出圖像中的瑕疵。
4.5.3 消融實驗
為了驗證在置信度損失函數中添加GHM-C對模型性能提升的有效性,本文分別進行了消融實驗,實驗采用的模型使用不同置信度損失函數,其他設置以及參數相同,模型輸入分辨率為224×224,消融實驗結果如表4 所示。
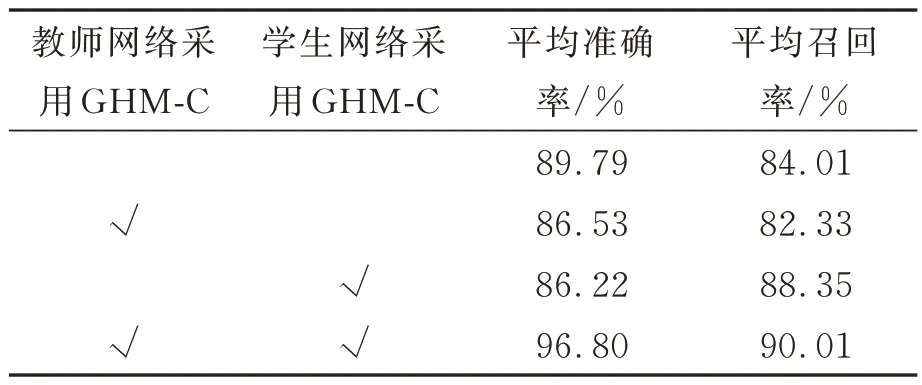
表4 采用不同置信度損失函數的對比實驗結果Tab.4 Comparative experimental results using different confidence loss functions
從表中可以看出,只給教師網絡采用GHMC 會導致學生網絡的平均每準確率和平均召回率略有降低,可能原因為教師網絡和學生網絡采用的置信度損失函數不同,因此使得知識蒸餾效果產生負面效果;只給學生網絡添加GHM-C 使得學生網絡學習的特征與教師網絡有所不同,從而導致學生網絡無法從教師網絡獲得正確的信息,因此學生網絡的平均召回率明顯提升,但是預測出許多錯誤的結果,平均準確率略有降低;同時給教師網絡和學生網絡使用GHM-C 不僅使得模型的召回率提升,同時準確率也有提升,在之前組合中許多被誤檢的目標在這個組合中能夠準確地被檢測出。因此本文提出的YOLOv5-CSKD 在教師網絡中和學生網絡中均采用GHM-C 作為置信度損失函數訓練。
5 結 論
針對目前陶瓷基板瑕疵檢測在低分辨率輸入圖像上不足之處,論文將知識蒸餾引入到陶瓷基板瑕疵檢測中,基于YOLOv5 網絡模型設計了教師網絡以及學生網絡,并設計了特征融合模塊同時融合高分率圖像特征和低分辨率圖像特征,用融合之后的特征對學生網絡進行知識蒸餾,可以使得學生網絡學習到更加全面的信息。實驗結果表明,基于知識蒸餾的陶瓷基板瑕疵檢測算法對低分辨率陶瓷基板圖像的五種不同類型的瑕疵均取得更好地檢測效果,平均準確率和平均準確率分別達到了96.80%和90.01%。本文僅較多考慮了YOLOv5 網絡與知識蒸餾算法的結合,在后續的研究中,我們將對網絡結構進行優化改進,實現檢測性能更優、模型更輕量化。
猜你喜歡
快樂語文(2021年27期)2021-11-24 01:29:04
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
甘肅教育(2020年22期)2020-04-13 08:11:16
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
福建基礎教育研究(2019年3期)2019-05-28 23:14:43
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12