數據挖掘在計算機專業課程設置中的應用研究
2023-12-05 02:50:10陳輝,張玲
淮南職業技術學院學報 2023年5期
陳 輝,張 玲
(1.淮南職業技術學院圖書館, 安徽 淮南 232001; 2.淮南職業技術學院經濟管理學院, 安徽 淮南 232001)
2019年12日,教育部和財政部正式公布了我國197所“雙高計劃”建設名單,包括56所高水平學校建設高校和141所高水平專業群建設高校。“雙高計劃”也被一些人稱為是職業教育版的“雙一流” 工程,每五年一個支持周期,2019年啟動第一輪建設。安徽省教育廳于2023年1月啟動了省級雙高計劃——安徽省高水平高職學校和專業群建設計劃。省內高校的“雙高計劃”的遴選工作和申報工作也相應展開,A院校為了搭上“雙高計劃”的快車,開啟學校“雙高計劃”的申報工作,學校內部的提質增效活動開展起來,提升教學管理工作也提上日程。應該通過合理的課程設置,提升學校的教學質量,為申報“雙高計劃”提供扎實的支撐。
1 數據挖掘簡介
1.1 數據挖掘概述
數據挖掘就是從紛繁復雜的大量數據中,找到隱藏在其中的有用數據。隨著數據庫系統的廣泛應用和網絡技術的高速發展,社會產生大量數據,在數據爆發時代的條件下,數據挖掘技術應運而生的。數據挖掘的對象可以是任何類型的數據源,在對數據源采取數據挖掘之前,需要事先制定計劃,設計好每一步的動作,最后要達到什么樣的目的,這樣才能保證數據挖掘有條不紊地實施并取得成功。數據挖掘分為有指導的數據挖掘和無指導的數據挖掘,具體而言,分類、估值和預測屬于有指導的數據挖掘,關聯規則和聚類屬于無指導的數據挖掘。
1.2 數據挖掘理論
一是項與項集。假設集合項集l={元素1, 元素2, …, 元素n},其中,元素m(m=1,2,…,n)是項集l中的項。這樣的集合稱為項的集合,即項集,包含n個項的項集稱為n項集。二是事務與事務集。每個事務T是一個項集,它是項集l的一個子集,使用唯一標識符Tid標記。不同的事務組成事務集D,它是關聯規則發現的事務數據庫。三是關聯規則。所謂關聯規,就是形如集合X=>Y的蘊涵式,其中集合X、Y是項集的子集且不能為空集,而X與Y交集為空。四是置信度(confidence)。在關聯規則下,置信度的定義如下:

五是支持度(support)。在關聯規則下,支持度是用來表示事務包含集合X和Y進行并集運算得到的結果,是集合X和Y中項的概率。六是頻繁項集(frequent itemset)。需要事先定義最小出現頻度(支持度計數)閾值,使用閾值過濾掉項集l中低于它的項,則項集l中滿足的項是頻繁項集。 六是項集的出現頻度(support count)。它是包含項集的事務數,也就是項集的頻度、支持度計數或計數。 7是強關聯規則。滿足最小支持度和最小置信度的關聯規則,即待挖掘的關聯規則。
2 計算機專業課程設置存在的問題
2.1 沒有做到統一管理
高職學校的課程設置和教學安排一般分配到二級學院設置,但是學時分配、教學資源分配、師資力量分配等受到學院主管部門或學校現有資源制衡,難以做到最優搭配,專業建設目標和課程建設目標,因所處角度不同呈現多元化發展,有時還走回頭路,不能綜合利用現有的社會大數據資源。
2.2 課程領域分布不合理
高職學校的課程領域分布不合理,通識課和專業課分布雖然受限于上級文件,但是也存在要么廣度過于寬廣,要么深度過深的問題,體現學校想讓學生什么都學和什么都會的心情,不能在廣度和深度中準確把握度的問題,體現在課程設置中就是課程領域分布不合理。
2.3 課程實施不精細
高職學校的課程實施比較粗獷。大學課程的關聯性相對減弱,在課程實施的過程中不能統籌管理或缺乏統籌管理,具體表現就是理論課和實踐課課時分配不合理、專業課課程教學實施順序錯亂、通識課占比不合理等。
2.4 課程設置反饋機制不敏感
高職學校的課程教學反饋機制比較成熟,但是課程設置反饋機制不敏感,學校只注重學生的課程教學成績反饋,對于課程設置的反饋不敏感,某些課程設置不合理,往往要延遲幾年才能改正,開課順序合理不合理更沒有相關依據,只是一味憑借經驗開設。
3 數據挖掘在高校計算機專業課程設置中的運用——以A院校計算機專業部分學生的課程成績為例
3.1 數據解釋需求
從A學院教務系統下載基礎數據,運用數據挖掘技術處理樣本數據,求出課程之間的關聯性,用以指導課程開設順序。
3.2 基礎數據準備
以A院校計算機專業2021級部分學生2022~2023第二學期的課程成績為例,進行初步數據清洗,取出樣本數據,見表1。

表1 2022~2023第二學期的課程成績數據表
3.3 數據格式化
數據挖掘需要數值型數據,所以要把表1中文本型數據格式化成數值型數據,依據數值型關聯規則,把表1中數據格式化成2進制數據,比如以80分以上(包含80分)格式化成“1”,否則為“0”,則表1格式化成二進制數據,見表2。

表2 格式化成二進制型數據表
3.4 Apriori 算法
Apriori算法是目前最有影響的挖掘布爾關聯規則頻繁項集的算法之一,也是挖掘算法中最經典的算法。它的核心思想是利用逐層搜索的迭代方法找出數據庫中項集的關系,以形成規則,其迭代算法過程由連接(類矩陣運算)與剪枝(去掉那些沒必要的中間結果)組成。該算法中項集的概念即為項的集合。為進一步規范數據,將課程成績作為數據挖掘的商品進行編號,生成數據庫,見表3。對表3進行關聯運算,關聯規則為min support=6/10。
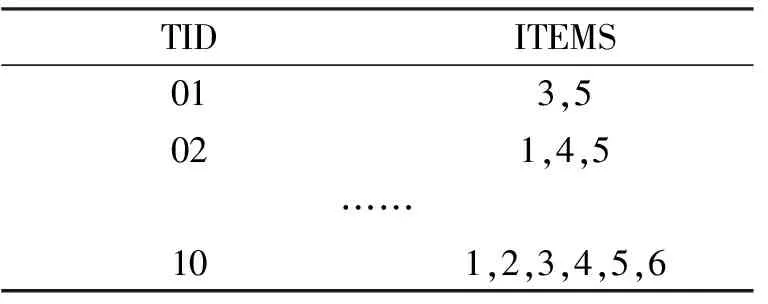
表3 數據庫事務列表D
3.4.1 關聯運算步驟


圖1 C1表

圖2 L1表

圖3 C2

圖4 L2

圖5 C3

圖6 L3
3.4.2 Apriori算法結論
Apriori算法的最終結果是:L=L1∪L4∪L5或L=L3∪L4∪L5。產生的關聯表如圖7所示。進一步計算關聯規則,可挖掘出強關聯規則:
規則1=>4
Support=support({1,4})=60%
Confidence=support({1,4})/support({1})=100%
規則4=>1
Support=support({1,4})=60%
Confidence=support({1,4})/support({4})=66.7%
規則1,4=>5
Support=support({1,4})=60%
Confidence=support({1,4,5})/support({1,4})=100%
同理,可以計算出每個規則。假定min confidence=3/4=85%,通過分析,發現滿足X.Confidence>min Confidence 條件的關聯規則有:1?4,1?5,3?4, 3?5, 4?5,5?4,{1, 4}?5, {3, 4}?5這些規則都成為強關聯規則。

圖7 Apriori算法產生的關聯規則
4 結語
運用數據挖掘技術,針對A院校計算機專業2021級部分學生2022~2023第二學期的課程成績進行分析,發現計算機應用基礎和計算機網絡概論、圖形化編程技術基礎課程相互關聯、相互影響;計算機網絡概論和圖形化編程技術基礎課程相互關聯、相互影響。綜上可知計算機應用基礎和計算機網絡概論、圖形化編程技術基礎三門課程聯系緊密,設置課程時,可關聯參考。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
大眾投資指南(2021年35期)2021-02-16 01:06:26
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
電力與能源(2017年6期)2017-05-14 06:19:37
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
信息通信技術(2015年6期)2015-12-26 01:16:46
