
基于人工智能策略及深度學習的行人過街交通信號控制器設計與策略研究
2024-01-03 01:04:18韓志方HANZhifang金輝JINHui
價值工程 2023年35期
韓志方HAN Zhi-fang;金輝JIN Hui
(遼寧工業大學,錦州 122000)
0 引言
我國屬于交通高運量高發展國家,尤其在北上廣等特大城市,月均交通出行均已破億,其中上海在2023 年6 月的統計中月客流總量達到3.05 億人次。在如此龐大的出行人群沖擊下交通系統的載荷面臨空前的挑戰就目前研究顯示,我國日常交通出行以混合型交通模式為主,即行人、機動車及非機動車的復合模式,當面臨大流量和城市交通錯綜復雜的道路狀態時,這種模式的出行風險有顯著升高的趨勢,這也是當下城市交通事故多發的一個理論性深層原因,尤其在道路交叉口信號控制樞紐等位置更是表現非常明顯。為解決城市交通發展中的這一問題,各國在城市建設規劃期就已有很多相關研究,例如20 世紀80 年代,由Pushkarev.B 等人掀起的交通信號系統控制研究,為之后廣泛應用的路口信號燈奠定了理論基礎[1]。又如,2000 年由美國交通部發布的《美國道路通行能力手冊》在信號控制基礎上加入了對行人特征因素及信號控制時間周期的的研究成果,更有針對性地對不同出行體模型特征進行了優化,減小了早期單一模型下的判斷誤差,開創了信號模型控制的時代[2]。近年來我國在行人交通信號控制領域發展迅猛,劉安陽等人在總結前人模型研究精髓的基礎上通過Logit[3]統計模型進行基于行人間隙的行為規律模型統計,極大優化了信號控制策略。但上述研究弊端在于過分依賴固定性的參數變量,難以仿真出真實場景,具有一定的應用局限性,本文借助AI 深度學習機制,建立多參數動態模型機制,通過模擬不同場景的行人與信號燈交互模式,優化控制策略從而提升現有信號控制器的使用效率,提升交通出行的安全性。
1 深度學習下人行過街控制模型設計
在行人的特征性分析中,一般會考慮交通流理論中參數作為切入點,本文在人的行為模式判斷中引入間隙理論將信號控制問題轉化為人車沖突問題[4],尤其是在人與轉彎車同行或車頭距行人較遠情況下,對于行人穿行的行為特征研究上如何提升安全管控效果,一般需要分別考慮城市道路交通信號配置的三種相位情況及這三種情況下機動車與行人可能發生沖突的區域及點位,如圖1 所示。

圖1 人車沖突的三種常見相位
當綜合考慮人車混合狀態時情況較為復雜,單一的線性分析已經不能滿足對安全性與準確性的要求,故本研究在深度學習常用的模塊YOLOv5s 基礎之上,引入損失函數及Deep Sort 目標追蹤算法[5],以最小算量實現輕量級的人車混合跟蹤識別與預測。研究基礎依靠深度卷積模型,通過合理的激活函數設置和損失函數閾值選取,在提升算法精準度的前提下,減少計算消耗,提升模型輸出效率,整體結構模型如圖2 所示。
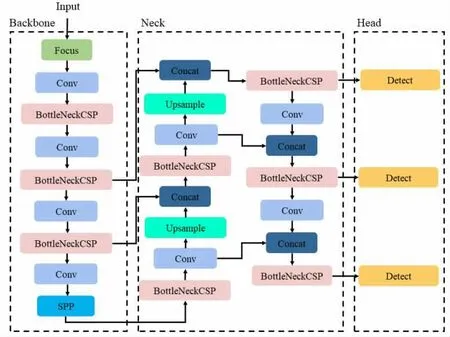
圖2 YOLOv5s 模型結構
一般而言如圖2 所示,模型由輸入層、網絡化學習層和預測輸出層組成,其中輸入層主要進行圖像信息的型制統一,即數據預處理。本模型原型基于YOLOv5s 進行改良,可進行圖像尺寸識別更為寬泛,可最小實現1×1 的圖像輸入識別。網絡化學習層主要進行基于特征值提取的學習訓練,本模型特征提取依賴BottleNeck[6],特征向下復制傳遞依靠CSPNet,本模型的改進在于引入了CSPDarknet53,該模塊可以顯著減少計算與訓練所需的網絡結構及特征值參數總量,對于圖片池化前的尺寸要求容忍度更高,相應最終信息融合度也更好。
綜合上述,本文所述的研究模型在以往深度網絡化的復雜高算力模型的基礎上,進行了邏輯改良,引入了簡化模塊算法機制,在特征向量提取部分對單個圖片進行切割和縮小,極大豐富了圖片特征信息量,在后續算法網絡中刪除檢測框中低置信度圖片后,可對剩余部分進行還原,通過這一過程的改良大大降低了算法對算力的消耗和網絡層的復雜度,同時由于特征值的增加也提高了算法準確率。
2 SD-YOLOv5 算法的仿真試驗
首先對于基于YOLOv5 改進后的SD-YOLOv5 方法,進行實驗條件確認,其應用場景多為交通路口或樞紐地帶,檢測目標多為行人及車輛,故在選取訓練目標對象時針對這兩項內容進行篩選,訓練集與測試集按照7:3 進行數量劃分。測試用工作軟件環境選取如表1 所示。
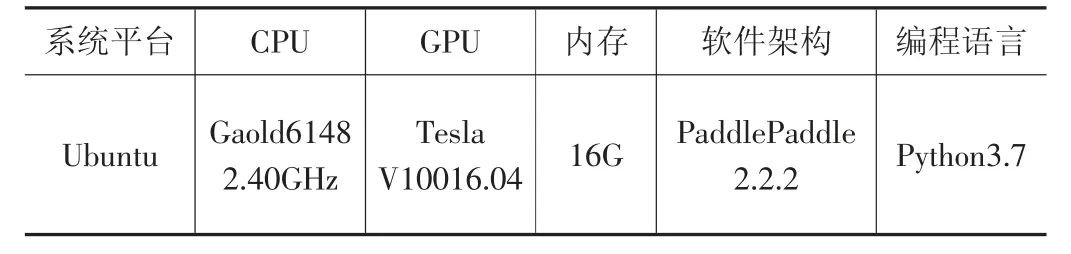
表1 試驗用軟件環境
在上述試驗條件及本文上一章節所描述的模型方法的基礎上,進行仿真測試,其具體步驟為:在訓練之前,對數據集進行預處理,包括圖像縮放、裁剪、亮度調整等,以適應YOLOv5 的輸入要求和提高模型的性能。根據數據集和目標設置合適的訓練參數,如學習率、批大小、迭代次數等。同時,確保計算資源(如GPU)的充足性,以加快模型訓練的速度。在訓練完成后,使用測試集對模型進行評估,計算模型的精度、召回率、F1 值等指標,以評估模型的性能。其輸出的融合度圖像如圖3。
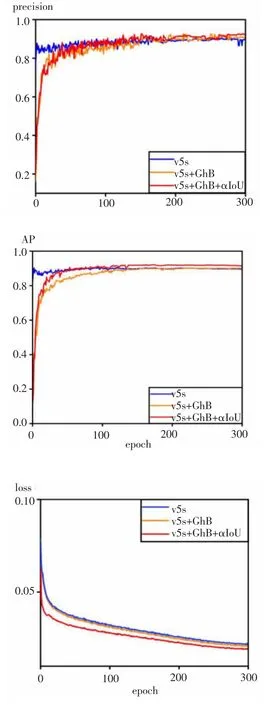
圖3 仿真測試融合度對比圖
圖中YOLOv5s 簡寫為v5s ,Ghost-BottleNeck 模塊簡寫為GhB,v5s+GhB+αIoU 即為本文提出的SD -YOLOv5 行人檢測方法,GFLOPs 和參數量是衡量神經網絡模型計算量和參數數量的指標。檢測速度是指目標檢測的推理速度,以毫秒(ms)為單位。GIoU 和αIoU 是兩種不同的定位損失函數,αIoU 相對于GIoU 有更好的性能。總的來說,這段文字描述了通過增加GhB 模塊、改變定位損失函數以及使用SAHI 策略對YOLOv5 進行改進優化后,在VOC 數據集上提高了目標檢測的性能,包括AP 的提升、計算量和參數量的減少、檢測速度的減少等。這些改進使得YOLOv5 在保持一定精度的同時,降低了參數量和計算量,提高了檢測器的邊界框定位準確性和抵抗噪音的能力,并在推理過程中通過SAHI 策略進行了優化,提高了AP 和推理速度。
3 深度學習下人行過街控制模型在實際交通信號控制中的應用
基于上文中研究結論,本節將圖片識別融入交通信號控制中以提升道路安全性,通過圖片信息識別分析實現基于自適應的路口交通信號變化,適應不同時段車流人流。研究分別采用基于圖像學習的交通控制策略和另外兩種平峰高峰常用交通控制策略作為研究對比,通過某處交通路口實地試驗獲得結果如圖4。
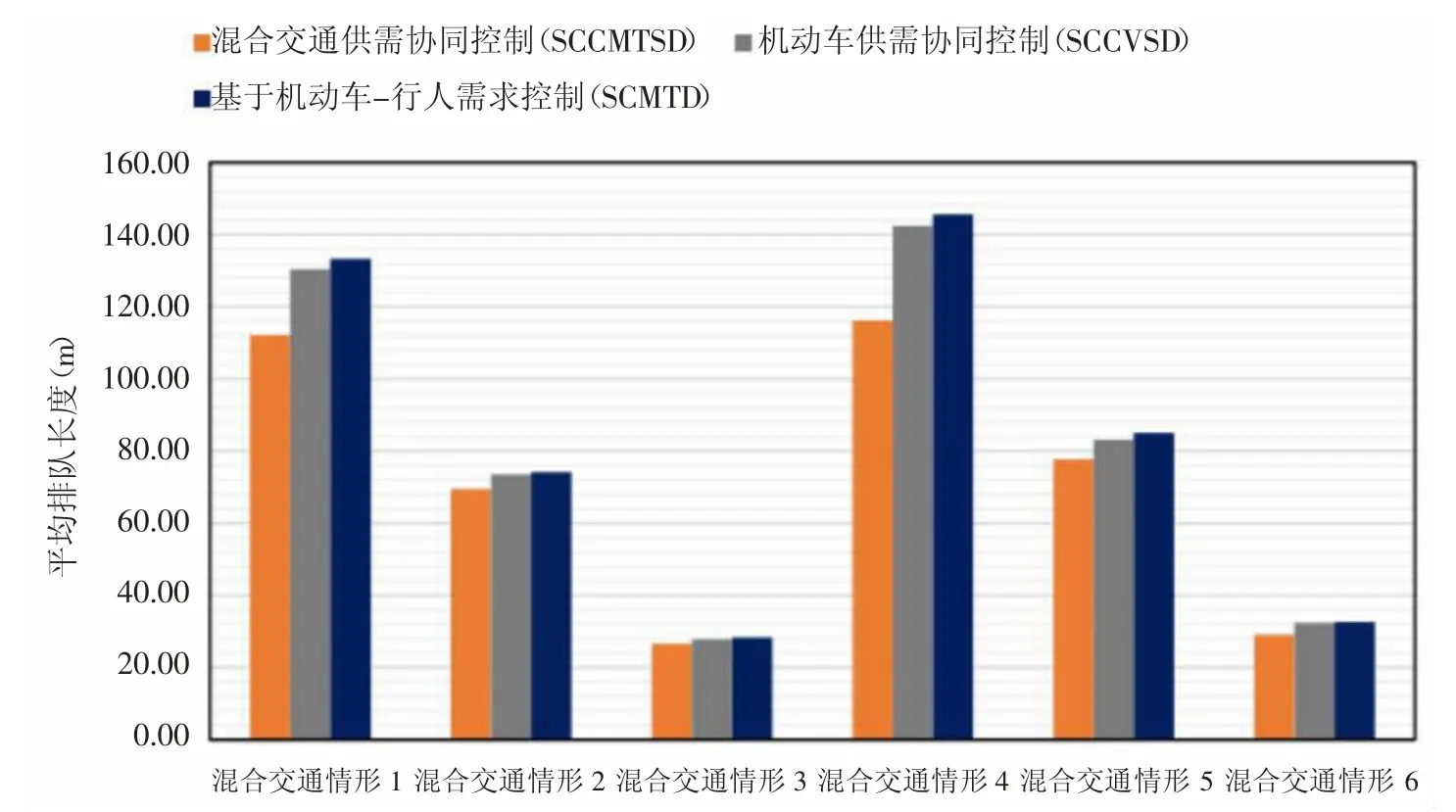
圖4 6 種不同混合交通模式下排隊時長比較
如圖4 所示,在6 種不同混合交通模式下,本文提出的人車協同深度學習模型均取得了控制優勢,對于降低車輛急停和長時間等候均有明顯的緩解效果,從時間分布情況看,特別在高峰時段(混合交通情況4 中)模型下的控制策略效果最為顯著,其根本原因在于本算法在人車飽和狀態下,通過識別和預判人車走向,最大程度減少人車沖突情況的產生,合理給予交通信號臨時性的時間控制改變,通過減少控制時間的方式減少了不要的等候時間損失。
綜合上述不難看出,混合交通流供需協同信號控制方案相比其他兩種信號控制方案,在釋放車輛方面表現更好。特別是在交通流過飽和的情況下,混合交通流供需協同信號控制方案的改善效果更為明顯。相對于基于機動車-行人需求的控制方法,混合交通流供需協同信號控制方案的機動車釋放量提升百分比可達到10.8%和10.4%。優化模型通過SD-YOLOv5 實時優化相位相序和配時,提高綠燈的有效利用率,盡可能釋放到達交叉口的車輛。
4 總結
本文基于人工智能策略及深度學習,研究了行人過街交通信號控制器的設計與策略。提出了一種基于人工智能策略的行人過街交通信號控制器設計與策略,并在實際交通信號控制中取得了一定的應用效果。研究結論總結了混合交通流供需協同信號控制方案相比其他信號控制方案的優勢,并強調了優化模型在最大限度利用時空資源和避免交叉口癱瘓方面的效果。具體研究結論如下:
①通過在人的行為模式判斷中引入間隙理論,利用YOLOv5s 模型進行人車混合跟蹤識別與預測的設計。詳細描述了該模型的結構和優化措施,如圖像增強、特征提取和預測輸出等步驟。
②通過SD-YOLOv5 算法的仿真試驗說明了對改進后的SD-YOLOv5 方法進行實驗的條件和步驟。描述了實驗結果的一些評估指標,如平均精度(AP)、計算量和參數量等,以及改進后模型在性能上的提高。
③通過深度學習下人行過街控制模型在實際交通信號控制中的應用驗證了將圖片識別與交通信號控制相結合的應用場景和布設。通過實地試驗的結果,證明了優化模型對于降低車輛急停和等待時間的效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
電子制作(2018年11期)2018-08-04 03:25:42
