基于改進DQN方法的滑翔制導炮彈彈道規劃
2024-01-05 00:31:50謝蕃葳王旭剛
彈道學報 2023年4期
謝蕃葳,王旭剛
(南京理工大學 能源與動力工程學院,江蘇 南京 210094)
超遠程滑翔制導炮彈滑翔段的彈道規劃一直以來都是研究的重點和難點,其既要滿足寬空域寬速域飛行過程中的強耦合、快時變以及強非線性的運動約束關系,還需要在被限制的控制空間內尋求最大作戰射程[1,2]。滑翔段的彈道規劃的實質是求解非線性帶約束最優控制問題,對應的動力學模型是時變非線性微分方程組。隨著非線性條件和約束條件的增多,目前該方程組難以通過解析的方式求得目標解。因此,現在的彈道規劃方法主要歸納為三類:間接方法[3,4]、直接方法[5,6]和智能啟發式方法[7-9]。
深度強化學習是采用深度神經網絡做函數擬合的一類新興強化學習算法,它不同于依靠大量最優彈道數據樣本進行彈道規劃訓練的深度學習方法[10],而是通過與環境的自主交互尋求最優規劃網絡參數。目前,強化學習的相關應用已經在圍棋[11]、電子競技[12]等場合中展示了在復雜環境下處理各種信息,并將信息轉換為規劃決策的能力。目前,基于深度強化學習的飛行器彈道規劃研究仍處于起步階段。文獻[13]在設定初速度與出射角的情況下,在彈丸的外彈道飛行過程利用Q-learning算法輸出控制指令,通過強化學習迭代計算實現彈道優化目標,導彈射程比無控時明顯增加。文獻[14]提出了一種基于網絡優選雙深度Q網絡的深度強化學習方法,保存了訓練過程當中的最佳網絡,突出了算法優越的性能表現。但文中對獎勵函數的落速懲罰沒有指明,沒有明確的約束限制指向。文獻[15]提出了一種無模型的強化學習和交叉熵方法相結合的在線航跡規劃算法,利用近端策略優化算法離線訓練智能體,可以在復雜多變的飛行空域中生成曲率平滑的航跡,擁有較高的突防成功率。文獻[16]利用深度確定性策略梯度算法訓練得到巡飛彈突防控制策略網絡,在1 000次飛行仿真下擁有82.1%的任務成功率,平均決策時間僅有1.48 ms。
然而,以上深度強化學習算法研究的重點主要集中在算法的應用性能上,算法本身的穩定性研究方面稍有欠缺。強化學習的相關研究領域普遍存在著訓練不穩定的問題。所以,為了建立穩定的深度強化學習訓練過程,本文以超遠程滑翔制導炮彈滑翔段作為研究對象進行彈道規劃,創新性提出了一種IM-DQN算法,采用無效經驗剔除的經驗池管理方法,將訓練過程中整體表現低效的回合樣本點全部剔除以保證提取樣本時避開這些低效環節,并且添加探索限制策略進行更新,保證訓練網絡效果不會大幅度跌塌,使得訓練效果更加穩定。
1 問題描述
滑翔制導炮彈在彈道頂點展開鴨舵進行滑翔,本文聚焦智能規劃方法在滑翔段的適用性問題,為了突出研究問題的重點,給出了典型滑翔運動模型,攻角為控制參數,其三自由度運動模型為[17]:
(1)
式中:x、y是慣性坐標系下的位置,v、θ、m分別是炮彈飛行速度、彈道傾角、炮彈質量。阻力Fx和升力Fy計算公式如下:
(2)
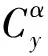
超遠程滑翔制導炮彈的彈道規劃往往期望在有限制條件下實現最大射程,因此將連續問題離散化,建立目標優化函數。
(3)
式中:vf表示落速,vc為落速限制,tf表示終止時間。xa表示離散后一個步長ts內通過執行a動作得到的航程距離。
針對滑翔段軌跡優化問題,提出用深度強化學習方法訓練深度神經網絡,將非線性規劃問題離散化,轉化為序列決策問題。它根據此時的狀態和內置深度神經網絡可以在毫秒級快速輸出對應的控制動作,然后迭代狀態和控制指令得到一條最優規劃曲線,避免了在飛行過程中求解復雜的非線性規劃問題,通過地面訓練的方式減少了空間飛行過程中的計算量,規劃流程如圖1。
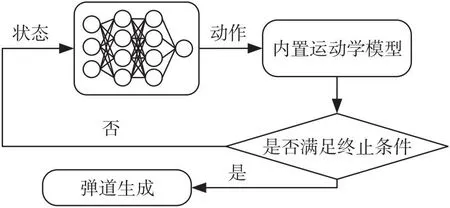
圖1 基于神經網絡的彈道規劃Fig.1 Trajectory planning based on neural network
滑翔初始數據參數設定見表1。

表1 滑翔初始參數設定Table 1 Initial glide parameter setting
本文研究的是滑翔段無動力滑翔,為保證飛行過程中的穩定性,飛行過程中的控制量具有嚴格限制,設置攻角幅值的約束為α∈[0,12°],綜合考慮尋優空間的大小與尋優時間的長短,將控制攻角離散化,控制攻角取值為0~12°之間的整數。
2 基于強化學習方法的彈道規劃
2.1 DQN方法
DQN方法起源于Q-learning方法,采用一個價值表格記錄下每個狀態下的動作,并且賦予每個動作相應的值,以表明此狀態下各動作的優劣。但隨著狀態空間和動作空間的變大,整個價值表格的容量空間也會隨之變大,如果狀態空間是連續的,則無法使用Q-learning方法。因此,Q-learning方法可以解決離散狀態空間問題,而無法解決連續狀態空間問題。面對此類連續空間問題,DQN采用一個神經網絡結構代替價值表格,即動作價值網絡Q(st,at,μi),輸入當前的狀態和動作即可得到相應的動作價值Q值,解決了連續空間狀態維度爆炸的問題。
為了使訓練過程更加穩定,DQN算法采用了相同神經元個數和參數配置的雙網絡結構,分別是當前評估價值網絡μ和目標價值網絡ω。在每次訓練開始前,在給定的參數范圍內初始化狀態參數;在訓練過程中,動作的選擇遵循貪心策略,即在開始訓練的一段時間內,網絡模型會在動作空間內隨機選擇動作,但隨著訓練的不斷推進,一段時間后會逐步根據當前的動作價值網絡的最大值選擇最優動作。
根據當前狀態和動作輸出下一階段的狀態參數,輸入當前經驗樣本et=(statrtst+1)到記憶經驗池容積De=(e1e2…et)當中,記憶經驗池方法有效打破了樣本之間的關聯關系,提高了數據利用率,每一次在固定時間步長之后從經驗池容積當中提取小批量樣本重新計算其動作價值,DQN算法誤差更新如下式[18]:
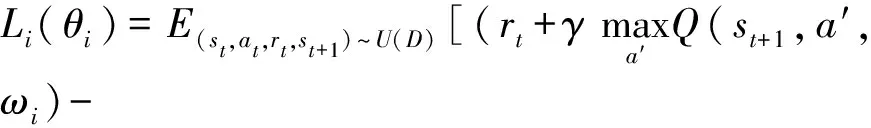
(4)
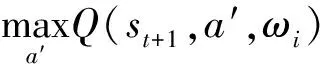
2.2 IM-DQN算法
傳統DQN方法在前期訓練的時候,參數通過經驗池樣本中隨機抽取一批樣本進行更新,里面包含的低性能數據樣本,不利于網絡模型的最優解。本文提出IM-DQN算法,在傳統DQN的原先經驗池方法[19]基礎上添加優秀經驗保存,在更替網絡方面添加了限制探索率的策略模式,具體實現過程如下:
①優秀經驗保存會剔除表現低效的整個回合樣本點,只保留優秀回合樣本,網絡模型在隨機抽取樣本的時候不再從低效回合樣本中學習經驗。
②傳統DQN方法在每固定回合后,無條件將目標價值網絡參數替換為評估價值網絡參數。限制探索率方法與之相比增加了一個限制探索率,如果多次訓練出來的評估價值網絡的一個回合獎勵值低于目標價值網絡的一個回合獎勵值乘以限制探索率的值,則這次更新停止反而將評估價值網絡重新替換為目標價值網絡,否定了網絡模型這一輪回合的探索工作。IM-DQN算法流程[20]如圖2所示。
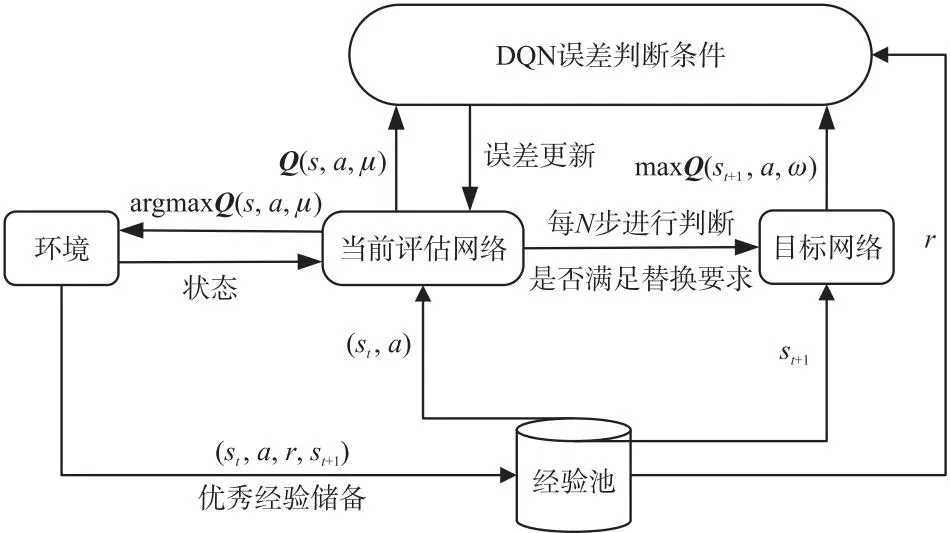
圖2 IM-DQN算法流程框圖Fig.2 Flowchart of Improved DQN algorithm
2.3 基于IM-DQN算法的彈道規劃
本文將IM-DQN算法思想移入到彈道規劃當中。算法采用了3步式的設計思路:狀態空間設計、狀態轉移方式設計以及獎勵值函數設計。
狀態空間設計:針對滑翔段飛行場景,滑翔制導炮彈滑翔橫向距離x、當前高度y、飛行速度v、彈道傾角θ及動作值作為狀態空間,定義為S=(xyvθα)。
狀態轉移方式設計:在IM-DQN算法當中,確定當前狀態參數之后,動作價值網絡本身就是策略網絡,在有限的動作空間內選取最大動作,相當于一個非線性函數映射當前狀態下最佳動作。確定了當前狀態、動作選取以及運動學模型,再通過數值方法求解相關非線性方程確定下一狀態參數。
獎勵值函數設計:為提高樣本效率和完成約束限制條件,本文采取連續獎勵項和懲罰項相結合的獎勵函數設置,設計如下式所示:
r(s)=rx+rp
(5)
式中:rx為每一步的航程獎勵函數,只與當前點到初始點的距離有關。rp為約束懲罰項。綜合以上兩點,現對獎勵函數具體設計如下式:
(6)
(7)
設置rx的目的是壓縮每一步的獎勵,促使著滑翔制導炮彈朝著更遠的方向飛行。設置rp的作用是在炮彈落速低于約束限制之后給予一個懲罰措施。需要注意的是,相比于最優控制求解過程的強制約束,DQN的約束往往呈現的是一種弱約束限制,它只是促使著彈道規劃落速朝著限制點運動,結果不一定嚴格滿足約束,而是在約束附近搖擺不定。
IM-DQN在訓練過程中的步驟如下:
①初始化記憶經驗池De,設置神經網絡的超參數,初始化評估價值網絡μ和目標價值網絡ω。
②外循環:初始滑翔制導炮彈的滑翔起點狀態參數s0,然后進入到內循環當中。
③內循環:內循環是一個訓練回合里面的工作循環。首先在每一步由貪心策略選取動作a,執行動作a即可得到下一狀態st+1,采用優秀經驗保存機制存放(starst+1)到經驗池De當中;在隔了N個步長后將經驗池De中隨機采樣一批樣本(si,a,r,si+1)進行價值判定,當提取的樣本滿足終止條件時:yj=rj,而在其它情況下,其價值均為:yj=rj+γmaxa′Q(st+1,a′,ω),再進行梯度計算loss=[yj-Q(st,at,μt)]2,以此更新評估網絡μ。傳統DQN算法是在一定步數后無條件更換目標價值網絡,而IM-DQN算法會根據限制探索率進行更新,若滿足更新限制率,則ω=μ,反之則μ=ω。
3 仿真實驗設計及結果分析
3.1 實驗仿真流程及參數設置
本文以滑翔制導炮彈為研究對象開展彈道規劃,為了更大程度模擬真實作戰情況以及探索更多狀態空間,訓練過程中在表1的滑翔參數基礎上添加隨機擾動:滑翔初始高度為57.5~58.5 km,初始速度為1 250~1 300 m/s,初始彈道傾角為-3°~0°。網絡學習率設置為η=0.01,折扣因子γ=0.99,經驗池容量ND=20 000,采樣規模ba=64,訓練時間步長設置為5 s。仿真實驗全部網絡采用同一種結構,設置兩個隱藏層,每層64個神經元,中間全部采用tanh激活函數進行連接。具體網絡結構及激活函數設置設計見表2。為更直觀的顯示規劃算法性能表現,設置參照組最大升阻比方法、GPM方法與強化學習算法進行橫向性能比較。
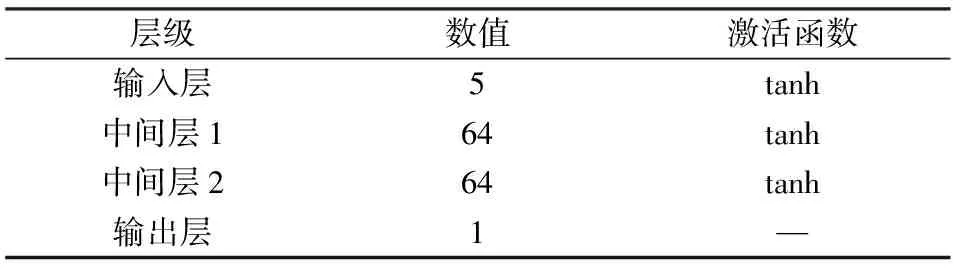
表2 網絡結構Table 2 Network structure
考慮到最大升阻比方法無法對落速進行約束,本文設計了兩種實驗,最大升阻比方法、DQN方法、IM-DQN方法3種實驗在無落速約束條件下進行仿真對比;GPM、IM-DQN方法2種實驗在有約束條件下進行仿真對比。
3.2 無落速約束仿真
無落速仿真實驗選擇rx作為獎勵函數,不再考慮懲罰約束項。為更方便觀察獎勵值的變化趨勢,本文設計每100個值取一次平均值作為平均獎勵值點。分別設計DQN和IM-DQN算法在10 000、30 000和50 000這三組不同訓練回合下的對比實驗,為盡可能減少訓練過程的偶然性對實驗的影響,每種回合分別訓練10次取其中最優網絡參數。兩種方法的具體獎勵趨勢如圖3和圖4所示。
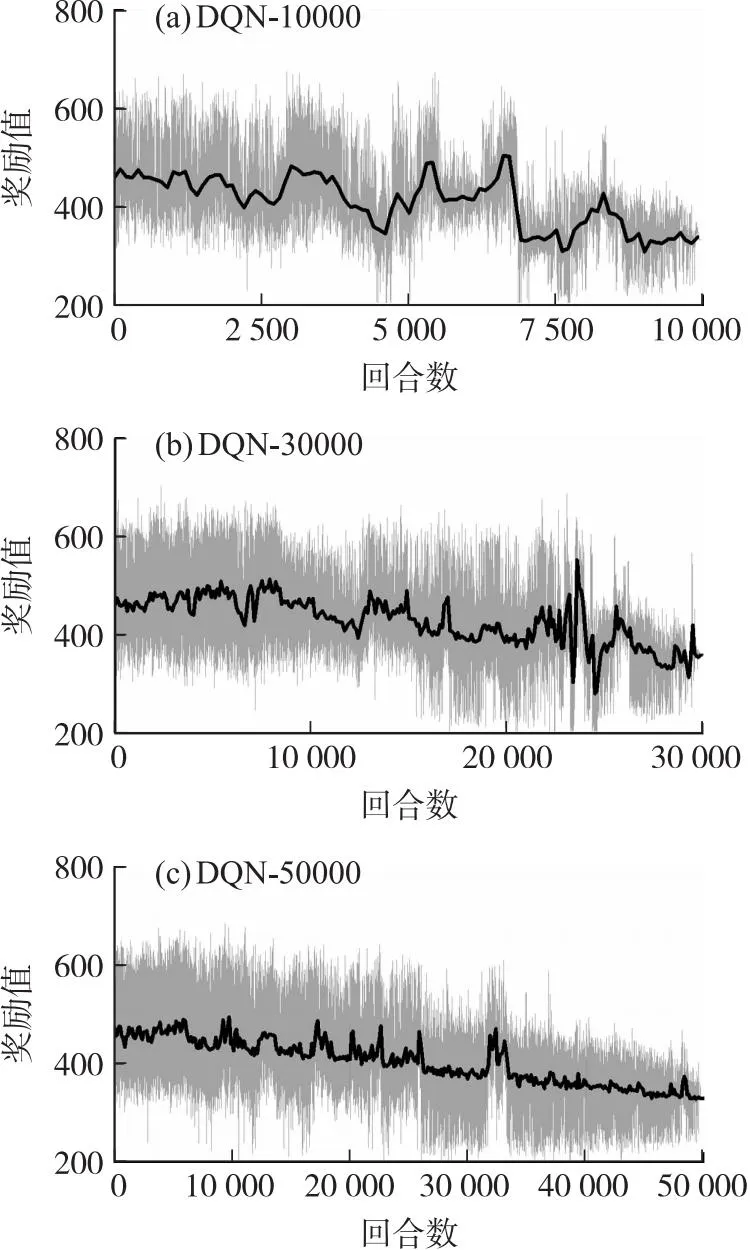
圖3 無約束下的DQN算法獎勵趨勢圖Fig.3 Unconstrained DQN algorithm reward trend graph
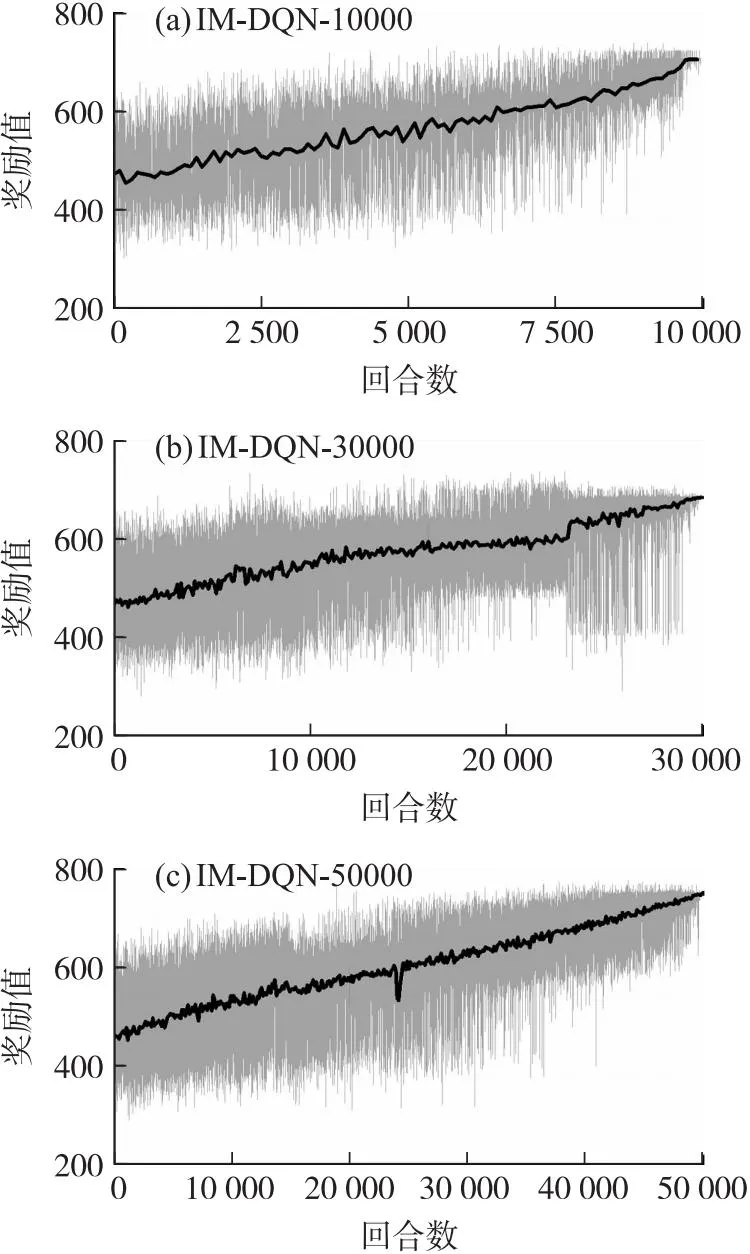
圖4 無約束下的IM-DQN算法獎勵趨勢圖Fig.4 Unconstrained IM-DQN algorithm reward trend graph
從上面獎勵趨勢圖可以得出,傳統DQN算法的訓練過程呈現出一種強隨機性,它的最終序列動作很難尋求到航程最優值。反觀IM-DQN方法,在不同回合下它們的獎勵值全部呈現一個逐步上升的趨勢。表3為兩種方法的最終訓練結果。
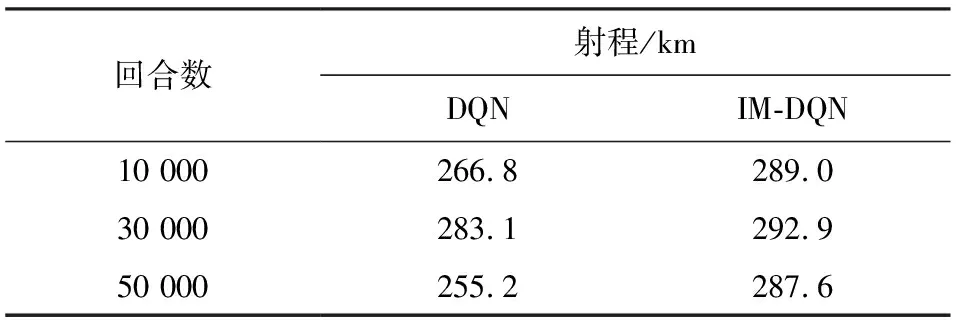
表3 無約束下兩種算法的最優訓練結果Table 3 The optimal training results of the two algorithms without constraints
根據對比結果看出IM-DQN方法訓練結果更加穩定。兩種算法皆在30 000訓練回合數達到航程最大值,故選取30 000回合數作為最終訓練回合數。本小節對比了IM-DQN方法、DQN方法和最大升阻比方法,3種算法的性能表現如圖5所示。
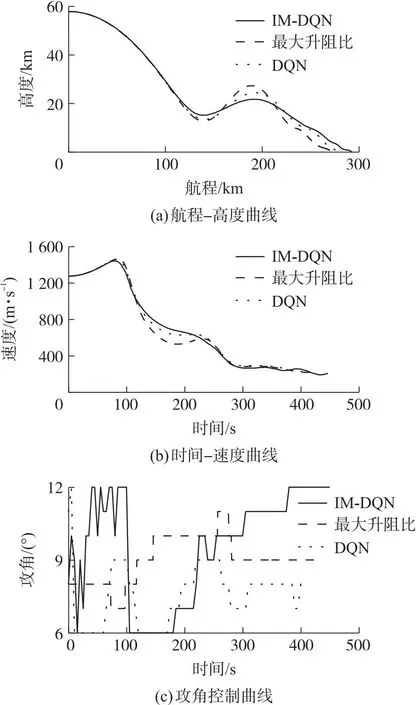
圖5 3種算法下的性能效果Fig.5 Performance effects of the three algorithms
對比圖5的仿真結果可以得出,IM-DQN方法相較于DQN方法和最大升阻比方法的射程都有所提升,其中相較于DQN方法和最大升阻比方法分別提升了9.8 km和19.5 km,說明IM-DQN方法在無約束條件下具有較好的優化性能。飛行過程中該方法對應的速度曲線相較于其它兩種方法更加平滑。3種方法的具體性能如表4所示。
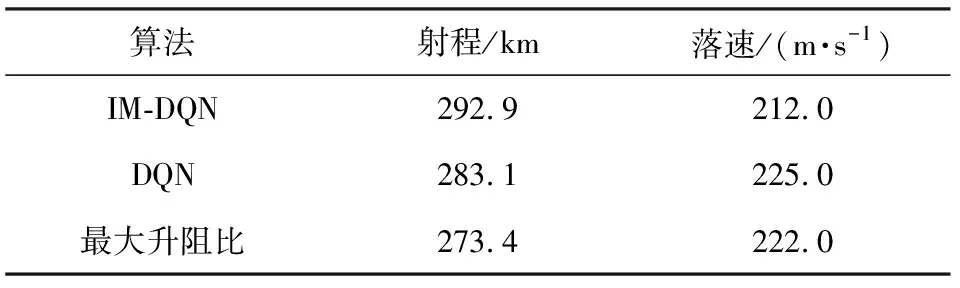
表4 無約束下的三種方法性能比較Table 4 Performance comparison of three methods without constraints
3.3 有落速約束仿真
有落速約束下的獎勵函數選用公式(5),完整考慮連續獎勵項和約束懲罰項。在有落速約束下選取合適的訓練回合次數,同樣設置10 000、30 000和50 000共3組不同訓練回合,每組重復訓練10次,各選其中性能表現最好的一組作為實驗參照組。為觀察獎勵值點的位置情況,3種訓練回合下皆以等差的形式取400個點作為觀察對象。獎勵值點及其相關表現如圖6和圖7所示。
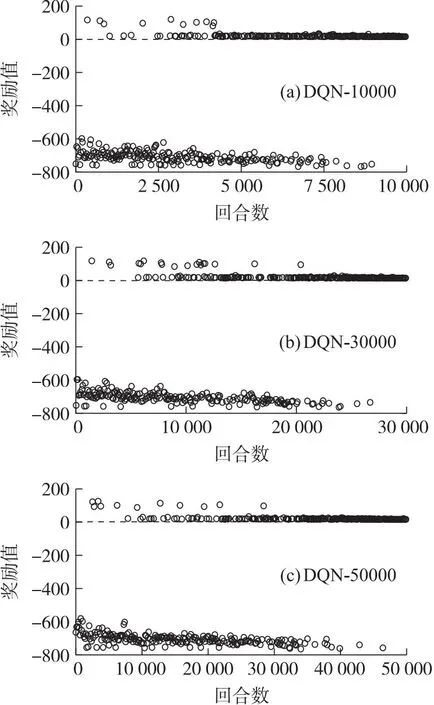
圖6 有約束下的DQN算法獎勵值點圖Fig.6 Constrained DQN algorithm rewards value point plot
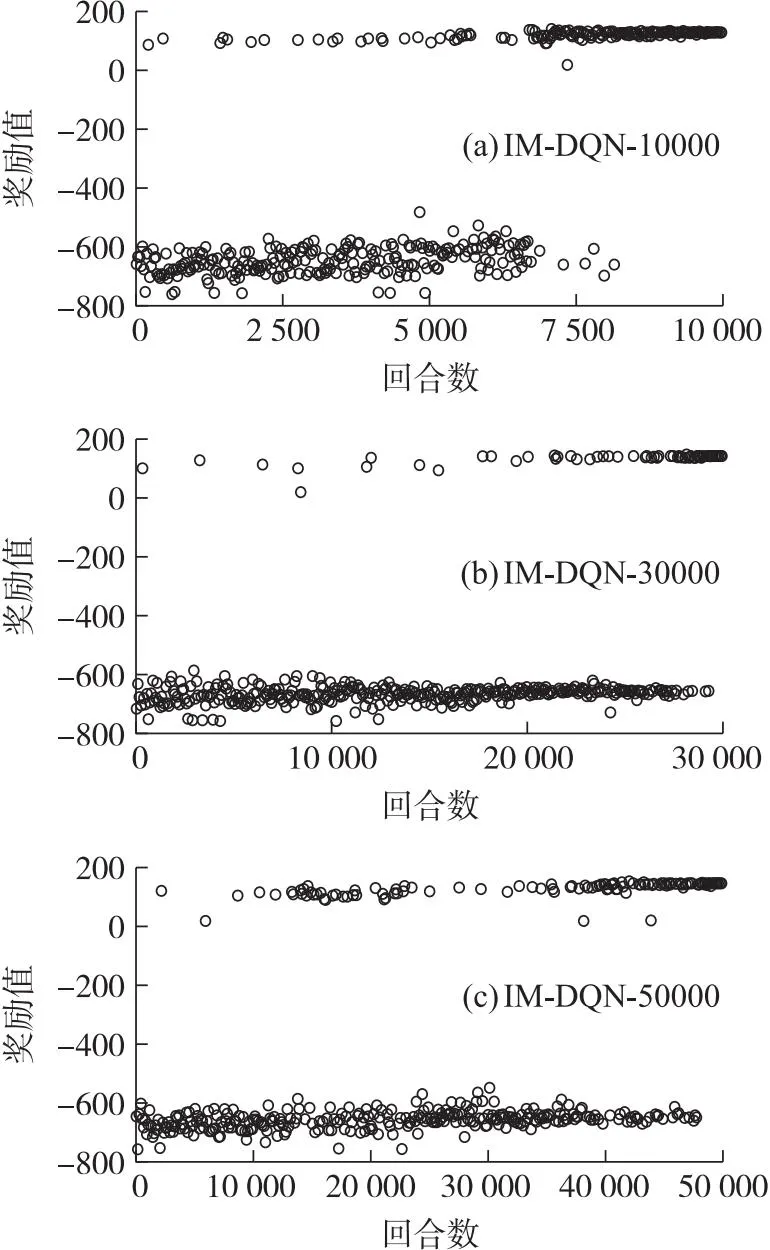
圖7 有約束下的IM-DQN算法獎勵值點圖Fig.7 Constrained IM-DQN algorithm rewards value point plot
由圖6和圖7可以得出,兩種方法的獎勵值點在不同訓練回合的末端皆落于零值以上,說明兩種訓練方法都可以良好的滿足落速約束限制。但從性能表現來看,IM-DQN方法訓練結果的獎勵值點最后在150附近起伏,而DQN方法的3種訓練回合的結果獎勵值僅有15,在圖6中基本與右零刻度線重合,說明了航程性能上的差異。兩種方法的具體性能如表5所示。
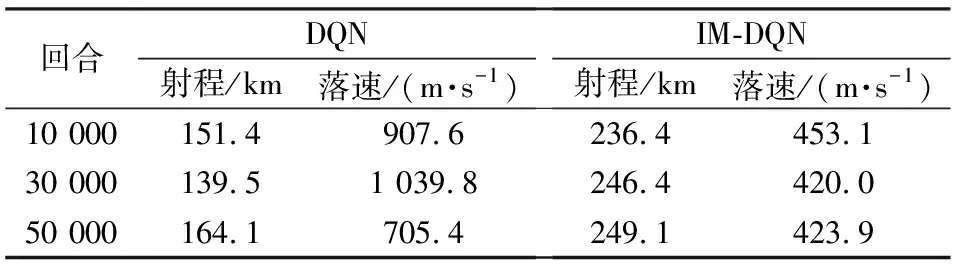
表5 有約束下兩種算法的最優訓練結果Table 5 Optimal training results of two algorithms under constraints
根據上述仿真實驗結果可知,在有限次數訓練下,傳統DQN方法的性能效果完全無法跟相同訓練回合下的IM-DQN方法相比。在有約束條件下,DQN方法難以尋求到最優動作價值網絡,它僅僅滿足了約束限制,但不能在有約束下尋求最優。從不同訓練回合可以看出DQN方法隨著訓練回合數增加,網絡性能逐漸發生變化,這種情況說明要想通過DQN方法完全體現出其最優性能網絡可能還需要更多的訓練回合數,這同時也延長了前期訓練的準備時間,不利于實際作戰的應用。從圖7及表5可以得出,不同于于無約束情況下,當問題復雜之后,隨著訓練回合的增多,網絡所呈現的效果也就越好,綜合考慮下選取50 000訓練回合數的神經網絡作為有約束下的動作價值網絡。為觀察IM-DQN具體性能表現情況,本小節設計基于最優控制理論的高斯偽譜法作為仿真對比參照組,通過GPOPS工具箱可以得到最優控制規劃曲線。IM-DQN方法與GPM的具體性能效果對比仿真如圖8所示。
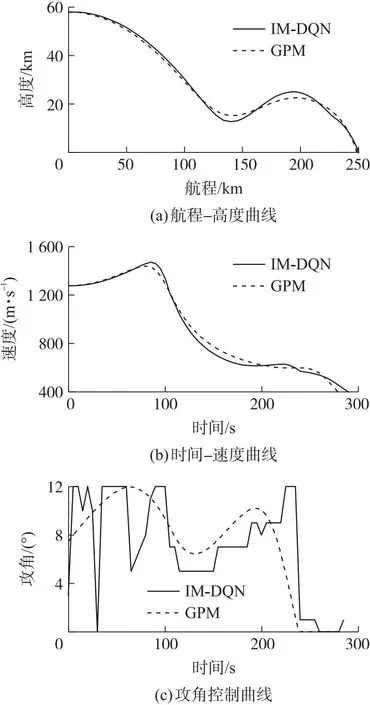
圖8 兩種算法下的性能對比效果Fig.8 Performance comparison between the two algorithms
圖8和表6是IM-DQN和GPM算法的性能結果對比,由圖可以得出IM-DQN方法規劃曲線與GPM十分相似,甚至結果值還略高于GPM,這也展示了強化學習在與環境交互過程中的優越性能,它擁有著在約束條件下尋求最優性能網絡參數的能力。強化學習之所以可以在有約束條件下尋求到了最優性航程網絡參數,是因為深度強化學習在探索過程中帶有記憶性,并且賦予這種記憶價值,這種價值不同于深度學習限制于數據樣本自身的局限性,強化學習的記憶基于與環境的交互過程,在環境交互中評定動作的優劣程度,使得深度強化學習可以突破單純深度學習的局部樣本最優解。但在神經網絡訓練過程中有許多因素會導致網絡性能崩塌,本文IM-DQN方法添加了低效經驗池剔除和探索限制率的組合策略,使得網絡的魯棒性更高,不容易在訓練過程中發生崩塌。隨著學習過程的逐漸增加,網絡也積累著更多的知識從而做出更優的指令。

表6 有約束下的兩種方法性能比較Table 6 Performance comparison of two methods under constraints
4 結論
本文利用強化學習與環境交互的特點,提出了一種基于IM-DQN的滑翔制導炮彈彈道規劃方法,在傳統DQN算法的基礎上,利用低效經驗池剔除加限制探索率策略,有效解決了傳統DQN學習效率低,獎勵曲線方向不明確的問題。仿真結果證明,IM-DQN方法很好地解決了傳統強化學習方法在尋求最優控制過程中網絡崩塌現象無法尋求到最優解的問題,為智能彈道規劃提供一種新的選擇。
猜你喜歡
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
領導決策信息(2018年50期)2018-02-22 06:17:16
商周刊(2017年5期)2017-08-22 03:35:26
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
中國衛生(2016年2期)2016-11-12 13:22:16
Coco薇(2016年2期)2016-03-22 02:42:52
中國工程咨詢(2016年4期)2016-02-14 07:28:28
Coco薇(2015年1期)2015-08-13 02:47:34
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
