ChatGPT生成內容的權利保護研究
2024-01-07 21:47:25丁懿楠呂冬娟王先第
傳媒 2023年24期
丁懿楠 呂冬娟 王先第
摘要:ChatGPT的廣泛應用給版權管理帶來了新挑戰。若ChatGPT生成內容在其生成過程中有人類參與,同時其符合著作權法所規定之作品的其他構成要件,應將ChatGPT生成內容納入版權法保護的客體范圍,使之具有“可版權性”。本文繼而提出以下權利保護模式:賦予使用者ChatGPT生成內容的版權;將其生成內容細化,僅承認滿足版權構成要件的部分生成物的版權;作為新型數據產權進行保護。
關鍵詞:ChatGPT 生成內容 可版權性 數據主權
Chat Generative Pre-trained Transformer(以下簡稱為ChatGPT)是由OpenAI研發的建基于深度學習的自然語言處理技術,其模型經歷了GPT-1、GPT-2、GPT-3、GPT-3.5及GPT-4的迭代升級,其最新版本GPT-4被認為是OpenAI在擴展深度學習的重大突破,是革命性的科技進步。人工智能在經濟發展中的重要地位日益彰顯,《國務院關于印發新一代人工智能發展規劃的通知》(2017)、《生成式人工智能服務管理暫行辦法》(2023)、《關于發布〈網絡安全標準實踐指南——生成式人工智能服務內容標識方法〉的通知》(2023)、《北京市經濟和信息化局關于印發〈人工智能算力券實施方案(2023—2025年)〉的通知》(2023)等規定的出臺都體現了國家或地方層面對人工智能建設及相應制度保障的大力推動。
ChatGPT有效地提升了知識內容的生產速度,但同時也為版權管理帶來了難題。ChatGPT生成內容表現形式豐富,包括但不限于生成對話、文章、圖像、電子郵件、音頻、視頻等,筆者探討的ChatGPT生成內容為文字作品、音樂、美術等具備《著作權法》作品特征的內容。當前,我國現行《著作權法》對ChatGPT生成內容尚無明確規定,應加大對在現有著作權法律制度框架下ChatGPT生成內容的可版權性、版權歸屬及權力保護路徑的研究力度,推動完善相關法律,因應相關領域可能產生的法律風險,正面引導ChatGPT在版權領域的使用,使新興人工智能技術更好地服務于我國經濟社會發展。
一、ChatGPT暫時不宜被賦予版權法意義上的作者身份
ChatGPT生成內容構成作品不能直接獲得生成作品的著作權,即該著作權無法歸屬于人工智能自身,ChatGPT本身不具有《著作權法》意義上的人身權主體資格。當前,不論在我國還是美國,ChatGPT此類AI都沒有被賦予法律意義上的創作主體身份。美國版權法嚴格限制創作主體須為人類,我國《著作權法》第11條規定了作者原則上是自然人,法人或者非法人組織只有在特殊情形下才被視為作者。
截至目前,ChatGPT無法被視為作者。首先,ChatGPT很難被視為自然人,其只是硬件軟件的排列組合。ChatGPT亦不能被解釋為法人或非法人組織,因法人或非法人組織是自然人個體的集合。ChatGPT無法對生成內容承擔法律責任,基于權利、義務與責任的共生關系,既然無法獨立承擔責任,亦無法擁有作者身份這一權利。如國際學術期刊《自然》(Nature)禁止ChatGPT成為論文作者,其認為作者身份意味著須對論文承擔責任,而ChatGPT目前無法承擔此責任。再者,ChatGPT本身是計算機軟件作品,屬于著作權法保護的客體,賦予其主體資格與《民法典》中主體與客體二元對立基本原理相悖。綜上,ChatGPT不具有《著作權法》意義上的主體資格。因此,未經法律明確規定,暫時不能賦予ChatGPT作者身份,但這并不影響ChatGPT生成內容有獲得版權法或知識產權法保護的可能性。
二、ChatGPT生成內容的可版權性
在技術層面上,ChatGPT的生成內容一方面是算法、規則和模板的應用結果,另一方面有一定程度的人類介入,可從《著作權法》所規定的作品認定基本原理的角度來判斷其生成內容是否屬于《著作權法》意義上的作品,對其生成內容進行著作權構成要件的審查。
ChatGPT生成內容是否構成作品的關鍵在于其是否滿足《著作權法》所規定作品的全部構成要件:第一,須具有獨創性;第二,限于文學、藝術、科學領域;第三,須屬于人類的智力成果范疇;第四,能以一定的形式表現。ChatGPT、Midjourney、MusicLM、Stable Diffusion此類利用人工智能生成的文章、繪畫、音樂是否滿足要件二和四的爭議并不大,爭議焦點主要在于是否滿足要件一和三。鑒于此,判斷ChatGPT生成內容是否屬于作品,關鍵在于判斷其是否具有獨創性及是否屬于人類的智力成果。
以下列兩個關于人工智能生成內容判例的涉案文字作品為例(見表1),北京知識產權法院和深圳南山區法院都沒有否認AIGC生成內容具有滿足獨創性要件的可能性,司法實踐中爭議聚焦在其生成內容是否屬于人類的智力成果。在威科案中,北京知識產權法院審判認為“智力活動”的主體不能是動物或機器,須是人類。法院認為,雖在研發和適用中都有自然人參與,但生成報告并非完全傳遞了研發者或用戶的思想和情感表達,故軟件研發者或用戶都不是作者。騰訊Dreamwriter案亦沒有突破人類創作主體這一構成要件的限制,其通過把創作時間和過程向前延伸,將前期研發開發行為也納入“智力活動”全過程中,體現了研發者的個性化選擇,以此補足了“智力活動”的人格化要件,最后法院判定該文章屬于作品。
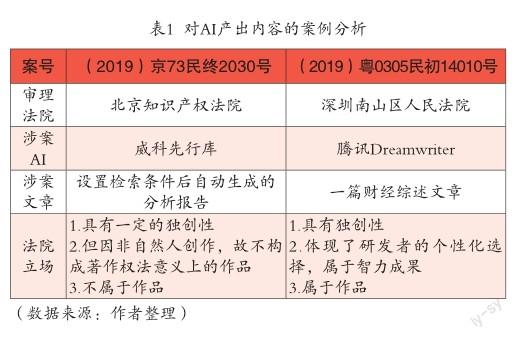
首先,對于ChatGPT生成物可版權性的判斷,仍應以是否具有“獨創性”作為判定基準之一。如前所述,ChatGPT生成內容有算法算力的應用結果,亦需自然人進行篩選、編輯或再加工,其創作過程仍體現了創作者的意愿,涉及自然人“自由與創造性的選擇”,故人工智能生成內容有滿足具有作品屬性的可能性。英美法系和大陸法系對“獨創性”的要求不同,前者對“獨創性”中“創”的要求仍遠低于后者,如美國Feist案體現了“獨立創作及極端最低限度的創造性”標準。在司法實踐中,據北京互聯網法院(2019)京73民終2030號民事判決書可知,法院認為雖該人工智能算法自動生成物具有一定的獨創性,但其不是自然人的創作成果,故不構成著作權法意義上的作品。但該法院并沒有否認人工智能算法生成物滿足獨創性要件的可能性。同時,通過上述(2019)粵0305民初14010號案件可知,深圳南山區法院最終認定騰訊公司所主張的Dreamwriter軟件生成的文章構成《著作權法》所保護的作品,認為人工智能生成內容在外在表達上滿足最低程度的獨創性要求,因此可以構成著作權法意義上的作品。
其次,討論ChatGPT生成物是否屬于作品的另一關鍵還在于認定作品是否屬于人類的“智力成果”范疇。從ChatGPT模型的演進過程來看,ChatGPT對海量數據進行統計分析和機器學習,然后進行人工標注和反饋,之后使用訓練好的算法和數據通過自然語言輸出技術形成相關內容。其生成內容仍有人類的介入,無法脫離人類對于其設計、數據訓練等內容的選擇與思考,凝結了人類的智識與創造,仍是人類創作意志的延伸。即使人的介入程度變得越來越低,當前仍然不存在自我生成的算法。
有學者從創作主體角度和實現著作權制度的基本目標角度出發,認為人工智能不屬于法律意義上的人,故其生成內容不是智力成果,賦予人工智能生成物版權保護并不能激勵人工智能,因此對人工智能生成內容的作品屬性持否定態度。對此,筆者也認為只有人類才能創作作品,但不能僅僅因為人工智能不具有法律主體資格而否認ChatGPT生成內容具有可版權性。ChatGPT的智能算法中有或強或弱人類的介入,除了研發團隊的智力貢獻外,用戶其實亦是ChatGPT發展的重要推動者。如用戶可用喜歡的作家風格翻譯枯燥的外文書籍或文字材料,其翻譯過程其實已經大大超出了單純文本分析的范疇。
我國《著作權法》第11條規定了作者原則上是自然人,法人或非法人組織只有在特殊情形下才被“視為”作者,第3條亦強調作品須是人類的智力成果。ChatGPT生成內容仍無法脫離自然人對其設計、數據訓練等內容的選擇與思考,其在一定程度上仍是該自然人創作意志的延伸,這一因素使得ChatGPT生成物具有自然人的智力成果屬性。據深圳市南山區人民法院(2019)粵0305民初14010號民事判決書可知,法院認為原告團隊運用人工智能Dreamwriter軟件所生成的文章內容符合文字作品的形式要求,且體現了原告創作意圖及其個性化選擇與安排,具有一定的獨創性,故認定其屬于原告創作的法人作品。該案充分地說明了人工智能生成的智力成果有獲得版權保護的可能性。
綜上分析,筆者認為ChatGPT生成內容具有可版權性。對于滿足現行《著作權法》所規定之作品的全部構成要件的,應當對其提供著作權模式的保護。
三、ChatGPT生成內容的權利保護路徑探究
目前,學界對于ChatGPT生成內容知識產權保護的討論主要集中于對ChatGPT生成內容的定性和權利歸屬的爭議上,在現行《著作權法》框架下對ChatGPT生成內容進行保護仍是缺失的,就ChatGPT生成內容的法律保護路徑亦并未達成共識。為進一步鼓勵人工智能算法工具的發展,可具體分為以下三種情況認定ChatGPT生成內容的版權歸屬及其保護路徑。
1.情況一:生成內容版權歸屬創作者。若ChatGPT生成內容滿足作品的全部構成要件,應認可其生成內容的作品屬性,并將該ChatGPT生成內容的版權賦予使用者。可考慮把人工智能創作過程向后延伸,將用戶在使用過程中對ChatGPT的訓練(如ChatGPT根據用戶的指令承認錯誤、修正回復等)和用戶使用ChatGPT生成的內容視為一個整體。ChatGPT輸出的內容體現了用戶的個人意志和選擇,如同時也滿足著作權法所要求的其他構成要件,則屬于著作法意義上的作品。在此種情況下,可將作者身份讓渡給用戶,即使用者。如OpenAI官網用戶使用條款第3(a)條中寫明將ChatGPT輸出內容的所有權利、所有權和利益給予用戶。ChatGPT的研發設計者仍可通過計算機軟件來進行私權保護,以避免雙重保護。
2.情況二:僅承認部分生成內容的版權。細化ChatGPT生成內容,僅承認滿足版權構成要件的部分生成物的版權。2023年2月,藝術家Kristina Kashtanova申請注冊Midjourney生成的繪畫Zarya of the Dawn的版權。美國版權局拒絕為Midjourney生成的部分注冊版權,但承認該藝術家在故事設計、文字描述指令、視覺圖像元素的選擇與編排這部分的版權。可進一步細化ChatGPT生成內容,僅承認滿足版權構成要件的部分生成物的版權。由于用戶沒有擁有完整的著作權,后續作品的流通可能會出現權屬爭議糾紛等問題。
3.情況三:確立新型數據產權保護方式。若ChatGPT生成內容的全部或部分都不能滿足作品的全部構成要件,可通過確立新型數據產權的方式對其進行保護。《中共中央、國務院關于新時代加快完善社會主義市場經濟體制的意見》(2020)、《中共中央、國務院關于構建數據基礎制度更好發揮數據要素作用的意見》(2022)(以下簡稱“數據二十條”)、《國家知識產權局辦公室關于確定數據知識產權工作試點地方的通知》(2022)、《深圳市數據產權登記管理暫行辦法》(2023)、《北京市數據知識產權登記管理辦法(試行)》(2023)都為ChatGPT生成內容權利保護提供了新的思考角度。“數據二十條”提出建立合法合規的數據產權制度。目前,若ChatGPT生成內容全部或部分都不滿足《著作權法》的全部構成要件,不能被認定為作品的,但若其生成內容屬于經過算法加工具有智力成果屬性的數據,應歸入知識產權法保護的范疇。知識產權領域的立法應更具前瞻性,在ChatGPT產出物產生各類法律糾紛前,規范其產出物的秩序,為ChatGPT產出物確立新型數據產權。
四、結語
綜上分析,對ChatGPT生成內容的權利保護可根據不同情況,考慮采用如下路徑。一是若ChatGPT產出物在其生成過程中滿足《著作權法》中所規定版權的全部構成要件,應認可ChatGPT生成內容的作品屬性,使之獲得《著作權法》的保護。但這并不意味著ChatGPT生成內容的著作權直接屬于人工智能自身,并不是要以此肯定ChatGPT的法律主體資格或地位,對民事法律中的法律主體性仍不宜進行突破;同時,鑒于法律主體擴張可能帶來的風險,目前亦不宜賦予ChatGPT以“電子人”(Electronic personhood)的身份。另外,對于ChatGPT生成內容的權利歸屬可賦予其使用者。二是將生成內容細化,僅承認滿足版權構成要件的部分生成物的版權。三是若ChatGPT生成內容的全部或部分都不滿足作品的全部構成要件,則通過確立新型數據產權的方式對其進行保護。在制度選擇上,應秉持開放態度,積極探索和應對ChatGPT所帶來的挑戰,持續推動和優化著作權領域的立法,促進ChatGPT更好地服務于人類的創作活動,推進我國社會主義科學和文化事業繁榮發展。
作者丁懿楠系北京外國語大學國際關系學院《國際論壇》編輯部編輯
呂冬娟系澳門城市大學法學院助理教授
王先第系澳門城市大學法學院碩士研究生
本文系北京外國語大學中央高校基本科研業務費專項資金“外國語言文學學科影響力排名及數據庫建設”(項目編號:2021JS003)、全國高等學校文科學報研究會編輯學研究重點項目“新時代學術期刊編輯如何應對人工智能技術的挑戰”(項目編號:ZD2023013)的階段性研究成果。
參考文獻
[1]王遷.論人工智能生成的內容在著作權法中的定性[J].法律科學(西北政法大學學報),2017(05).
[2]李偉民.人工智能智力成果在著作權法的正確定性——與王遷教授商榷[J].東方法學,2018(03).
[3]叢立先,李泳霖.聊天機器人生成內容的版權風險及其治理——以ChatGPT的應用場景為視角[J].中國出版,2023(05).
[4]鄧建鵬,朱懌成.ChatGPT模型的法律風險及應對之策[J].新疆師范大學學報(哲學社會科學版),2023(05).
[5]韓雨瀟.生成式人工智能作品版權歸屬問題研究[J].揚州大學學報(人文社會科學版),2023(04).
【編輯:楊石華】
