基于高光譜技術(shù)的杏品種判別
2024-01-15 08:14:32王潤(rùn)潤(rùn)張淑娟蘇立陽王林杰盧心緣孫海霞
農(nóng)產(chǎn)品加工 2023年23期
王潤(rùn)潤(rùn),張淑娟,蘇立陽,王林杰,盧心緣,孫海霞
(山西農(nóng)業(yè)大學(xué)農(nóng)業(yè)工程學(xué)院,山西晉中 030800)
杏的種類繁多,其營養(yǎng)成分和口感差異很大,因此需要探究一種快速、無損的品種判別方法,以滿足消費(fèi)者對(duì)不同品種杏的消費(fèi)需求。
光譜技術(shù)作為新型的無損檢測(cè)手段,在農(nóng)產(chǎn)品品質(zhì)檢測(cè)和品種判別等方面具有廣泛的應(yīng)用。李翠玲等人[1]利用葉綠素?zé)晒夤庾V結(jié)合反射光譜的分析方法鑒別甜瓜種子品種,判別正確率達(dá)到98.0%。趙旭婷等人[2]基于高光譜技術(shù)研究競(jìng)爭(zhēng)性自適應(yīng)重加權(quán)算法結(jié)合極限學(xué)習(xí)機(jī)對(duì)油桃品種進(jìn)行判別,預(yù)測(cè)集相關(guān)系數(shù)為0.931。李雄等人[3]建立柚子品種判別模型,結(jié)果表明去差異化后750~930 nm 波段范圍判別模型的預(yù)測(cè)相關(guān)系數(shù)達(dá)到0.86。劉飛等人[4]基于油菜籽皮紅外光譜信息對(duì)油菜籽的品種和產(chǎn)地進(jìn)行判別,最優(yōu)判別正確率分別為97.9%和98.4%。張鵬等人[5]運(yùn)用近紅外光譜技術(shù),研究蘋果品種(嘎啦、喬納金、金冠、寒富) 的近紅外判別模型,對(duì)未知樣品判別正確率為85.00%~95.00%。楊春艷等人[6]基于傅里葉變換紅外光譜技術(shù),利用逐步判別分析法對(duì)金銀花品種和產(chǎn)地進(jìn)行判別研究,正確率依次達(dá)93.20%和96.13%。吳振等人[7]利用無機(jī)元素結(jié)合多元統(tǒng)計(jì)分析對(duì)我國5 類柚子品種進(jìn)行有效區(qū)分。有研究采用熒光光譜的一階導(dǎo)數(shù)光譜建立判別模型,卓椒3 號(hào)、卓椒4 號(hào)、卓椒5 號(hào)辣椒種子的品種判別正確率均達(dá)到100.0%。
選取4 種不同品種的杏作為研究對(duì)象,采集其光譜信息;對(duì)比優(yōu)選多種預(yù)處理方法;采用RC 和SPA 方法提取特征波長(zhǎng),結(jié)合PLSR 方法建模判別,為建立不同品種杏的種類判別提供參考,為杏產(chǎn)業(yè)鏈的發(fā)展提供技術(shù)支持。
1 材料和方法
1.1 試驗(yàn)材料
以“6-1”杏、網(wǎng)紅杏、晉梅杏和扁杏4 種杏為試驗(yàn)對(duì)象,試驗(yàn)中所使用的樣本均為2022 年7 月份在山西省晉中市太谷區(qū)果樹所獲得。采摘時(shí)挑選形狀相近、成熟度統(tǒng)一、無病蟲害、質(zhì)量均勻的杏。試驗(yàn)共采集600 個(gè)樣本,“6-1”杏、網(wǎng)紅杏、晉梅杏和扁杏4 種杏樣本各150 個(gè),根據(jù)Kennard-Stone(K-S)算法,按3∶1 的比例分別對(duì)4 個(gè)品種的試驗(yàn)樣本劃分校正集與預(yù)測(cè)集,每個(gè)品種校正集樣本數(shù)為113 個(gè),預(yù)測(cè)集樣本數(shù)37 個(gè)。校正集樣本總數(shù)452,預(yù)測(cè)集樣本總數(shù)148 個(gè)。
1.2 光譜信息采集
采用由北京卓立漢光有限公司開發(fā)的“Gaia Sorter”高光譜分選儀采集不同品種杏的光譜信息。
平均光譜曲線見圖1。
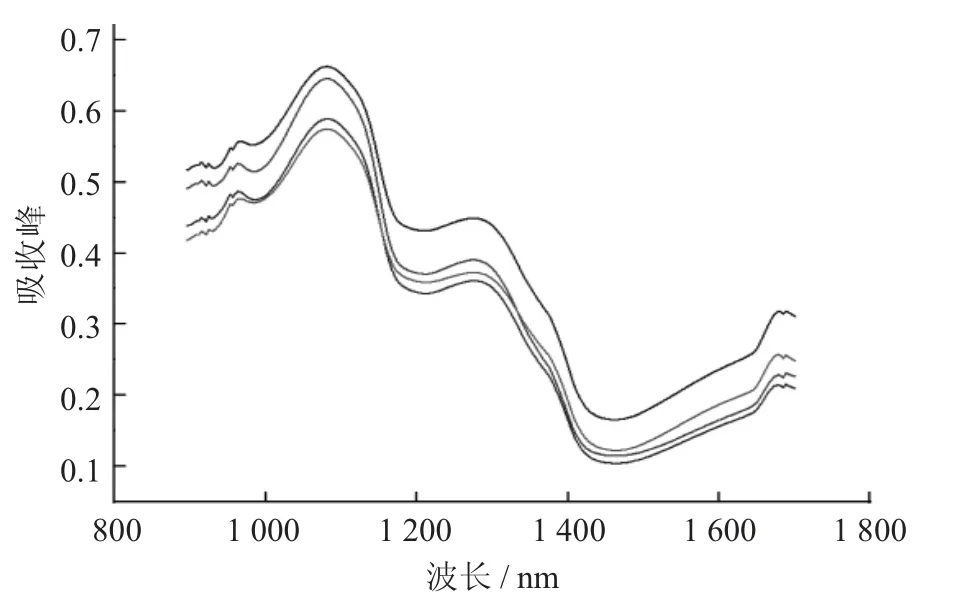
圖1 平均光譜曲線
由圖1 可知,4 種杏光譜反射率曲線整體趨勢(shì)一致,只存在吸收強(qiáng)度上的差異,可能與杏的品種、形狀、大小和質(zhì)地有關(guān)。因此,推測(cè)杏的品種將導(dǎo)致其光譜的差異。光譜曲線分別在1 080,1 275 nm 附近存在突出吸收峰,而在985,1 211,1 462 nm 附近存在波谷。其中,985 nm 附近的波谷是由O-H 基團(tuán)的二倍頻振動(dòng)導(dǎo)致的;1 275 nm 附近的波峰則是與C-H 的3 倍頻伸縮振動(dòng)有關(guān)。
1.3 數(shù)據(jù)處理方法及評(píng)價(jià)指標(biāo)
1.3.1 光譜數(shù)據(jù)的預(yù)處理
由于獲得的原始光譜數(shù)據(jù)不僅會(huì)提取樣本的有效信息,同時(shí)也包含了儀器、背景、環(huán)境等與樣本無關(guān)的冗余信息,為了降低這些冗余信息的影響,研究采用的光譜預(yù)處理方法包括SG、MA、MF、Baseline、SNV、MSC。
1.3.2 提取特征波長(zhǎng)
原始光譜數(shù)據(jù)包含波段范圍寬作為輸入模型計(jì)算時(shí)間過長(zhǎng),且存在信號(hào)譜帶重疊。因此,建模時(shí)需要篩選特征波長(zhǎng),從而減少建模時(shí)間、簡(jiǎn)化建模過程、提高模型的穩(wěn)定性。采用的方法主要有RC 方法、SPA 方法。
1.3.3 偏最小二乘回歸分析
偏最小二乘回歸(PLS) 可以進(jìn)行多變量數(shù)據(jù)分析,其原理是:先將各種變量數(shù)據(jù)矩陣分解為多種主成分?jǐn)?shù)據(jù)矩陣,并計(jì)算每個(gè)矩陣的貢獻(xiàn)率,再優(yōu)選出貢獻(xiàn)率較大的成分進(jìn)行回歸分析。
1.3.4 模型評(píng)價(jià)標(biāo)準(zhǔn)
采用決定系數(shù)R2和均方根誤差RMSE 2 個(gè)值來判別模型的效果。
計(jì)算公式為:
式中:yi——樣本的實(shí)測(cè)值;
n——樣本數(shù)量。
2 結(jié)果與分析
2.1 光譜數(shù)據(jù)的預(yù)處理
試驗(yàn)采用SG、MA、Baseline、MF、SNV 和MSC共6 種預(yù)處理方法后建模,分析不同預(yù)處理所建模型的預(yù)測(cè)能力。
不同預(yù)處理建立PLSR 模型結(jié)果見表1。
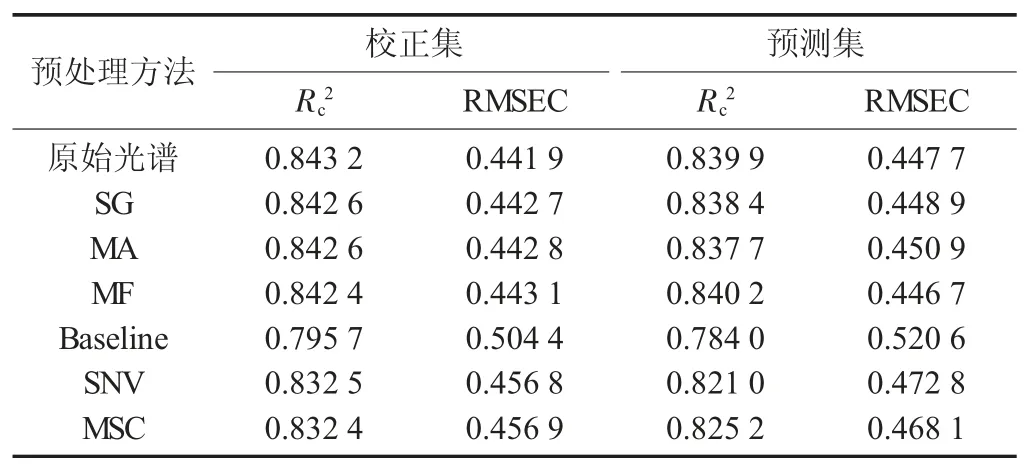
表1 不同預(yù)處理建立PLSR 模型結(jié)果
由表1 可知,除MF 預(yù)處理外,其余5 種預(yù)處理建立的PLSR 模型的Rc2和Rp2都有所減小,RMSEC和RMSEP 都有所變大。MF 預(yù)處理后的Rc2和Rp2分別 為0.842 4 和0.840 2,RMSEC 和RMSEP 分 別0.443 1 和0.446 7,MF 預(yù)處理最優(yōu)。
2.2 特征波長(zhǎng)選擇
2.2.1 RC 方法提取特征波長(zhǎng)
回歸系數(shù)法(RC) 是利用全波段光譜數(shù)據(jù)建立PLSR 模型,然后計(jì)算回歸系數(shù),再利用局部極值法來確定特征波長(zhǎng),共選出10 個(gè),分別為956,1 023,1 084,1 144,1 176,1 262,1 386,1 469,1 634,1 666 nm。
RC 提取特征波長(zhǎng)見圖2。
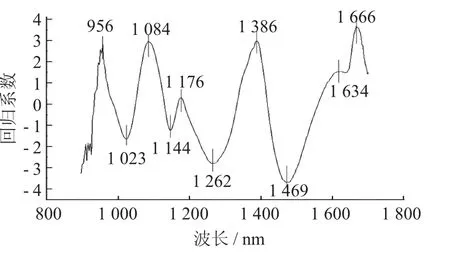
圖2 RC 提取特征波長(zhǎng)
2.2.2 SPA 方法提取特征波長(zhǎng)
連續(xù)投影算法(SPA) 是通過計(jì)算樣本波長(zhǎng)之間的投影,并將投影向量的最大值定為樣本的特征波長(zhǎng)值。
特征參數(shù)數(shù)量與均方根誤差關(guān)系圖見圖3,特征參數(shù)優(yōu)選分布圖見圖4。
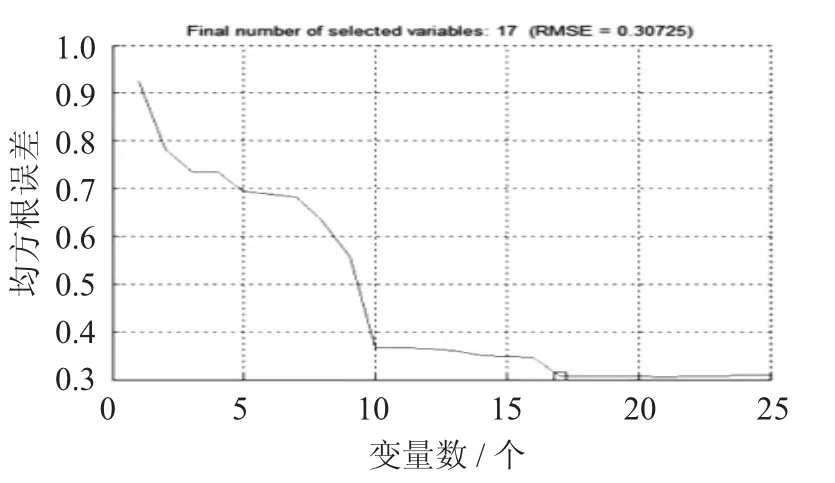
圖3 特征參數(shù)數(shù)量與均方根誤差關(guān)系圖
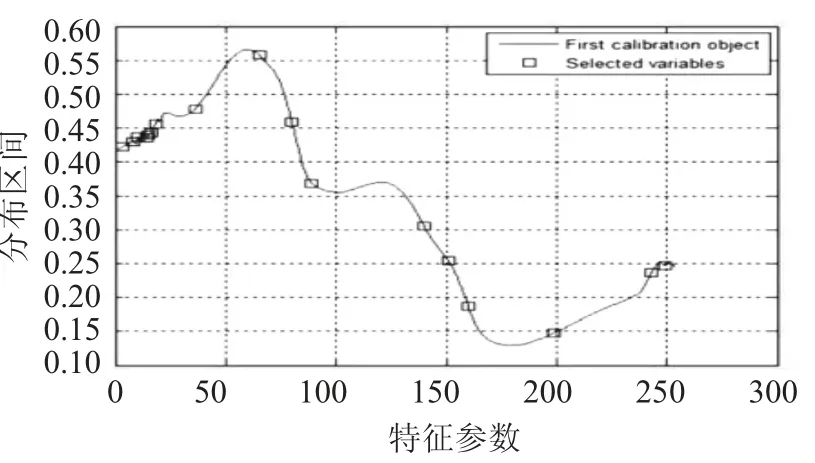
圖4 特征參數(shù)優(yōu)選分布圖
由圖3 可知,當(dāng)最終選擇變量數(shù)為17 個(gè)時(shí),均方根誤差最小,提取的17 個(gè)特征波長(zhǎng)值分別是902,918,924,937,940,943,950,1 007,1 100,1 147,1 176,1 338,1 373,1 402,1 526,1 666,1 685 nm。
2.3 建模結(jié)果分析
將4 類不同品種的杏樣本進(jìn)行賦值作為判別依據(jù),“6-1”杏賦值為1;網(wǎng)紅杏賦值為2;晉梅杏賦值為3;扁杏賦值為4。在建立判別模型的過程中會(huì)出現(xiàn)非整數(shù)的情況,需要采用閾值進(jìn)行判別。當(dāng)判別值大于等于0.5,小于1.5 時(shí)判別為“6-1”杏;當(dāng)判別值大于等于1.5,小于2.5 時(shí)判別為網(wǎng)紅杏;當(dāng)判別值大于等于2.5,小于3.5 時(shí)判別為晉梅杏;當(dāng)判別值大于等于3.5,小于4.5 時(shí)判別為扁杏;當(dāng)判別值不在這些區(qū)間內(nèi)則為判別錯(cuò)誤。
基于全波段、RC 和SPA 的PLSR 判別模型見圖5。
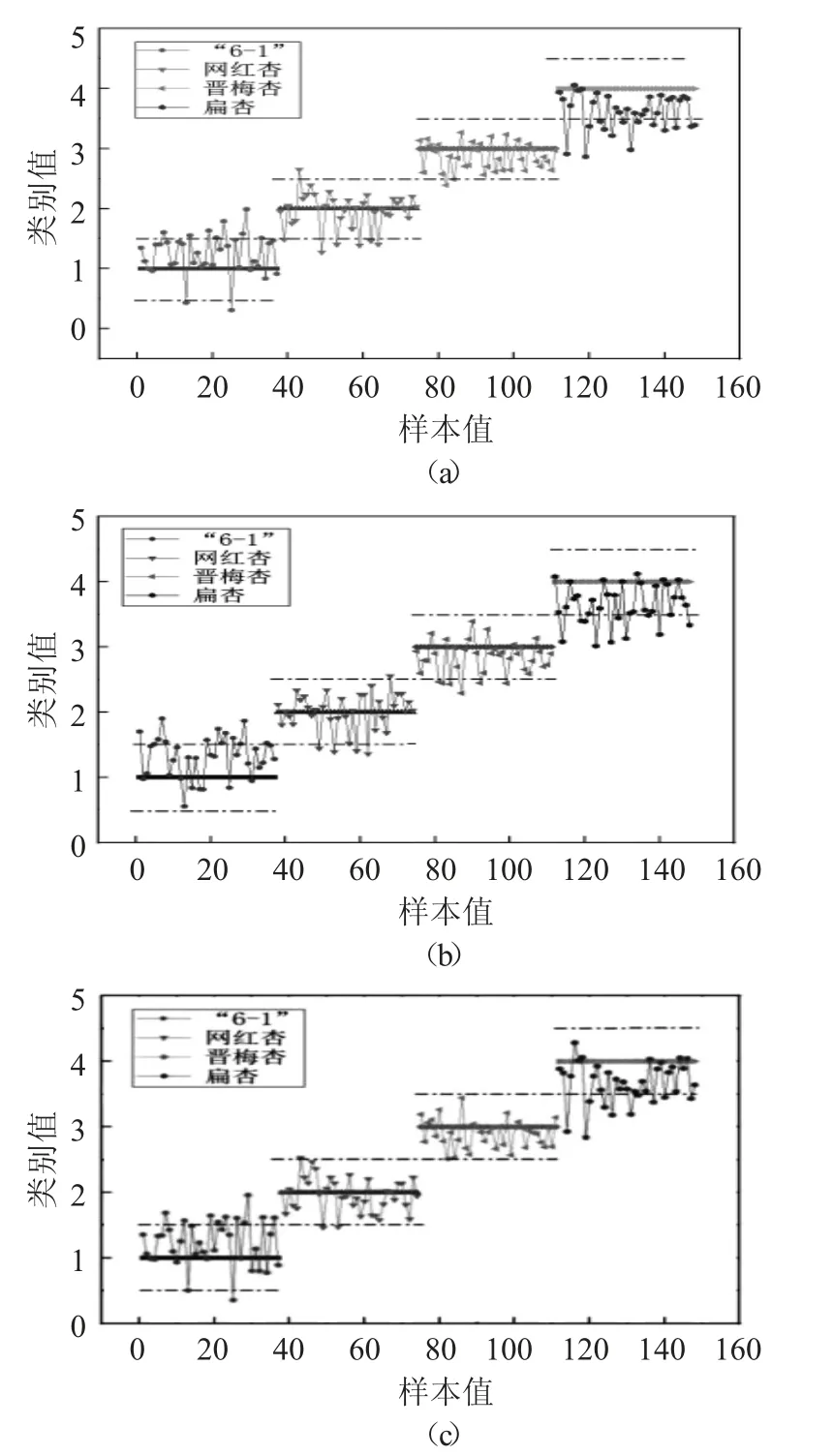
圖5 基于全波段、RC 和SPA 的PLSR 判別模型
由表2 可知,通過比較NOR(全波段) -PLSR、RC-PLSR、SPA-PLSR 這3 種方法預(yù)測(cè)的建模效果,發(fā)現(xiàn)SPA-PLSR 的建模效果最好,預(yù)測(cè)集的綜合判別率高達(dá)84.44%。
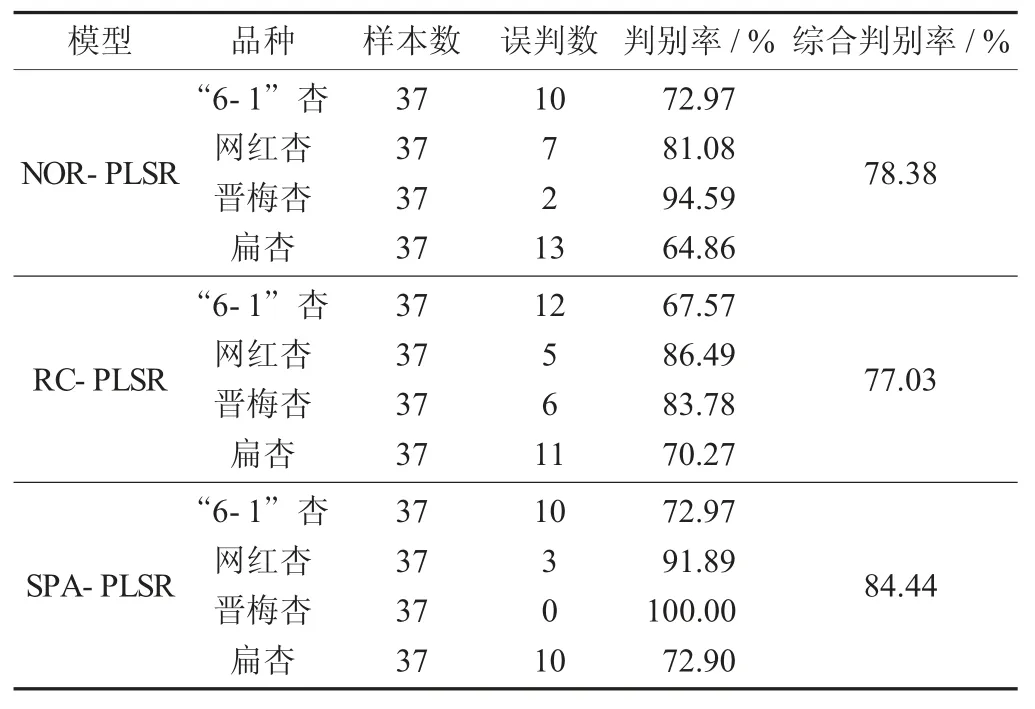
表2 各模型判別結(jié)果統(tǒng)計(jì)
各模型判別結(jié)果統(tǒng)計(jì)見表2。
3 結(jié)論
通過采集“6-1”杏、網(wǎng)紅杏、晉梅杏和扁杏4 個(gè)品種的光譜信息,采用SG、MA、Baseline、MF、SNV 和MSC 共6 種預(yù)處理方法,建立PLSR 模型,MF 方法預(yù)處理效果最優(yōu)。針對(duì)預(yù)處理后的光譜數(shù)據(jù),采用RC 和SPA 方法選取特征波長(zhǎng)建模。結(jié)果表明,SPA-PLSR 模型效果最佳,總判別率達(dá)到了84.44%,4 個(gè)品種的判別率分別達(dá)到了72.97%,91.89%,100.00%,72.90%。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
