基于邊特征融合的行人軌跡預測算法研究
2024-01-15 09:59:58王紅霞李枝峻寧樞麟
長春師范大學學報 2023年12期
王紅霞,顧 鵬,李枝峻,寧樞麟
(沈陽理工大學信息科學與工程學院,遼寧 沈陽 110159)
0 引言
復雜場景中準確地對行人軌跡進行預測對自動駕駛系統至關重要[1]。行人作為自動駕駛的主要參與者,其軌跡更加自由、靈活、復雜,準確地對行人軌跡進行預測可以規避潛在的風險。行人軌跡預測的難點在于行人的軌跡受主觀因素的影響,同時也受到周圍行人運動的影響,對其精準預測有較高的難度。
傳統的行人軌跡預測通過手工提取行人交互特征,不僅有交互不足的缺點,而且缺少適配的數據集。隨著深度學習的興起,長短期記憶網絡(Long Short-Term Memory,LSTM)被用于序列預測,通過復雜的網絡模型再搭配更適配的數據集得到了更好的預測效果。ALAHI等[2]提出采用LSTM網絡提取行人運動軌跡信息,加入池化模塊,在池化模塊范圍內的行人共享信息,從而達到提取社交關系的目的。相對于單獨使用RNN網絡進行預測,考慮了行人交互,取得了更好的預測效果,缺點是池化操作不能區別對待行人之間的關系。生成對抗網絡[3](Generative Adversarial Networks,GAN)不需要復雜的模型,通過對抗學習達到更好的效果。GUPTA等[4]基于GAN網絡提出了(Social GAN,SGAN)模型,采用生成器-判別器模式訓練模型,提出新的損失函數鼓勵網絡預測多條軌跡,相比先前模型只是預測一條“平均好”的軌跡,在預測精度上有了很大提升,缺點是采用全局池化會加入無效交互且增大運算量,并且GAN模型不易訓練。為了解決交互不足的缺點,有學者提出采用注意力機制模塊提取信息[5-6],相對全局池化,在提取交互關系上有了一定改進,缺點仍是不能區別對待行人關系。
在對行人交互信息提取中,多數研究采用池化層進行交互,缺點是損失了大量信息,融入了無效交互。圖神經網絡(Graph Neural Network,GNN)的出現,將行人關系映射到圖中進行建模,更符合社交關系網絡。圖注意力網絡(Graph Attention Network,GAT)是GNN的變體。通過注意力機制(Attention Mechanism)對鄰居節點做聚合操作。HUANG等[7]基于GAT模型為每個鄰居節點分配注意力系數,然后通過加權求和得到節點新的特征向量,缺點是當前基于圖神經網絡的模型在提取行人之間交互信息所考慮的信息是片面的,忽略了邊特征在圖中的作用。
針對上述問題,本文提出一種結合邊特征的時空圖自注意力預測模型(Spatial-Temporal Graph Network with Edge Feature Generative Adversarial Networks,STGEF-GATv2)對行人軌跡進行預測。采用編碼器-解碼器結構作為主體結構,引入邊特征提取模塊,將行人歐式距離構建鄰接矩陣,輸入到特征融合層,將輸出結果用作邊特征,增加了GAT可學習信息。空間交互采用更加有效的GATv2模塊[8]替換GAT模塊,采用更少的頭,提升精度的同時降低了模型復雜度。最后,STGEF-GATv2模型采用模塊時空信息融合模塊[7],可以更好地提取行人間的時空交互信息,從而提高預測模型的精確度。
1 模型描述
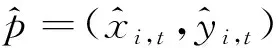
2 模型架構
2.1 軌跡預測模型
STGEF-GAT模型的架構如圖1所示,主要采用編碼器-解碼器模型。本文在編碼器采用LSTM模型學習行人運動軌跡隱藏狀態,將行人的相對位置坐標輸入特征提取模塊后與LSTM網絡的隱藏狀態進行融合,采用GATv2來提取行人空間上的交互特征。另外采用一個LSTM學習行人空間交互的隱藏信息,解碼器采用LSTM網絡,以時間特征、空間特征、交互特征[10]結合高斯噪聲作為輸入,未來的軌跡作為輸出,最終通過反向傳播進行模型訓練。
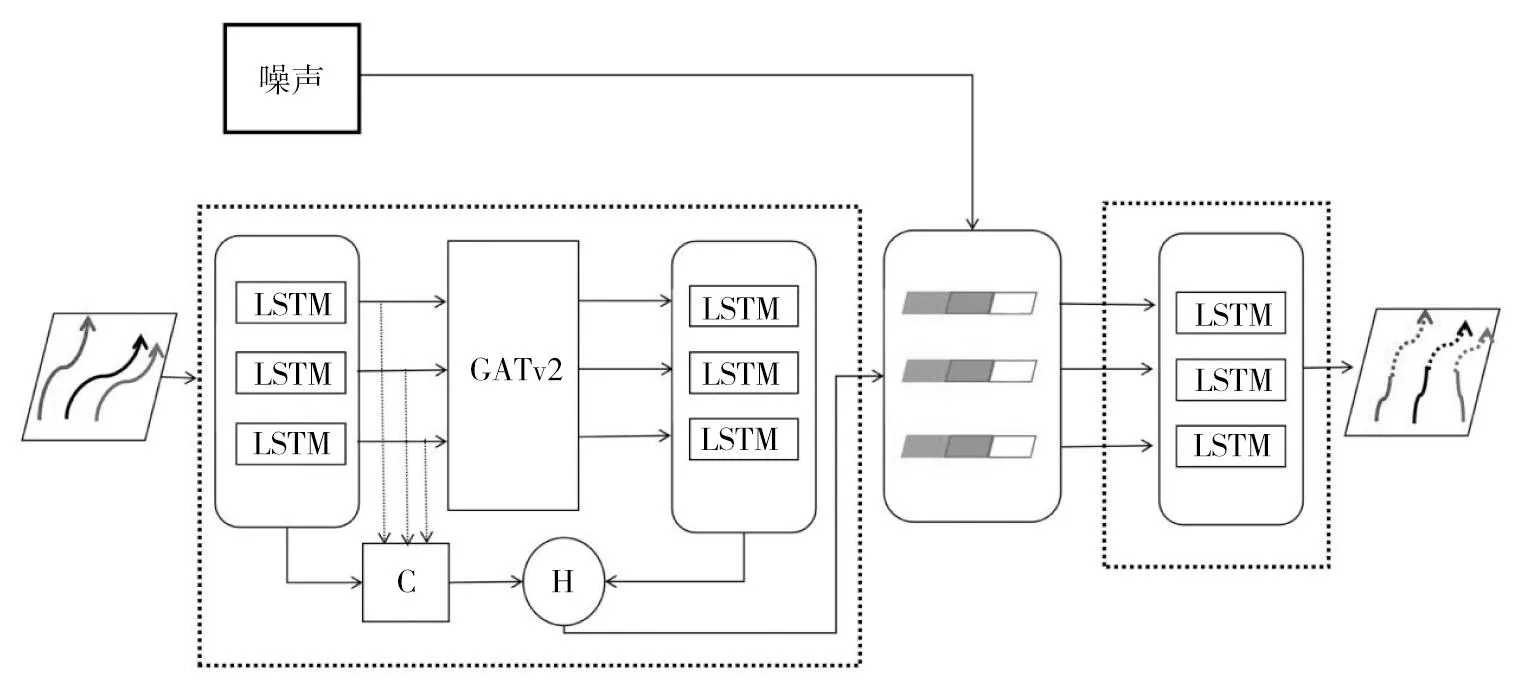
圖1 行人軌跡預測模型架構圖
2.2 邊特征增融合
原始GAT結構有一個缺陷,在學習注意力機制時不使用任何邊的可用信息,為解決這一缺點本算法通過添加歸一化層,如圖2所示,輸入行人軌跡相對位置坐標,構建歐式距離鄰接矩陣,歸一化后進行維度映射。最后與相對位置坐標經過LSTM后的隱藏特征進行融合,增加了節點邊特征向量的信息,提供GAT層更豐富的學習信息。上述過程的計算表達式為:
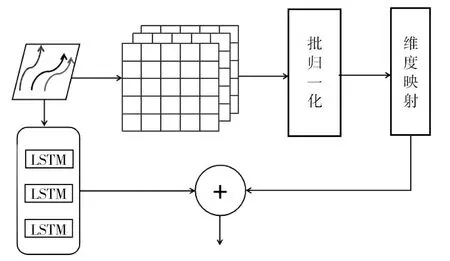
圖2 邊特征融合模塊示意圖
(1)
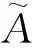
進行歸一化的原因是為了減少過擬合,加快模型收斂,此處采用GCN(Graph Convolutional Neural Network)中的歸一化方法,保證了圖的對稱性,并且有利于神經網絡的學習。
最后進行相加操作,相較于拼接操作和乘法操作的特征融合,采用加法融合使維度更低,減少運算量,降低模型復雜度,同時預測精度并沒有降低。
2.3 GAT變體GATv2
在圖結構中行人交互關系如圖3所示。GAT是GNN模型中重要的一種變體,多頭注意力機制能進一步提升注意力層的表達能力,如圖4所示[11]。

圖3 行人交互關系示意圖
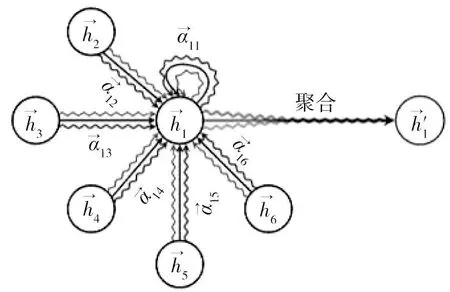
圖4 多頭注意力機制示意圖
首先計算鄰居節點及自身的注意力系數,然而BRODY等[8]發現GAT的注意力有很強的局限性,在GAT中每個節點都只關心鄰居節點,BRODY認為不論自身節點特征怎么變,得到的注意力權重的計算結果都是相同的,將這種注意力稱為靜態注意力。BRODY通過改進GAT提出了GATv2,由公式(2)演變到公式(3)。經過實驗可知,采用兩個頭的實驗結果比原有GAT四個頭甚至更多頭的實驗效果好,降低了模型復雜度,減少了運算量,最后通過公式(4)對注意力系數進行加權求和,得到新的節點特征向量。
(2)
其中,‖表示拼接操作,wgat表示共享權重矩陣,hi,t表示節點的特征,aT是一個注意力核函數,目的是進行維度映射。L為激活函數,αij,t為t時刻權重系數。
(3)
與式(2)不同,式(3)先進行特征拼接[hi,t‖hj,t],然后再與權重矩陣wgat相乘。經過激活函數L,再與注意力核函數相乘。
對得到的注意力系數進行加權求和,得到新特征向量,為加強GAT學習能力,采用多頭注意力機制,如公式(4)所示。
(4)
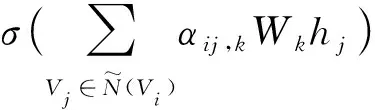
2.4 軌跡編碼器模塊
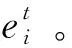
(5)
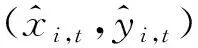
將節點特征輸入長短期記憶網絡模型,學習行人運動的隱藏信息,數學表達式如下:
mi,t=T(mi,t-1,ei,t;Wm),
(6)
其中,Wm為LSTM權重系數,mi,t為t-1時刻運動隱藏信息,ei,t為節點特征,T表示循環神經網絡。
將運動隱藏特征和邊特征融合模塊進行相加操作:
Mi,t=mi,t+H,
(7)
其中,mi,t表示運動隱藏信息,H表示邊特征提取結果,來自公式(1),此融合操作對應圖1中的C模塊。
學習行人空間交互信息可表示為:
gi,t=T(gi,t-1,Gi,t;W),
(8)
其中,Gi,t為節點經過多頭圖注意力機制的向量,gi,t-1為歷史空間交互向量,W為長短期記憶網絡的權重。
將時間空間信息進行融合:
hi,t=σ(Mi,t)‖σ(gi,t),
(9)
其中,σ(·)為不同的多層感知器,目的是在相同維度進行拼接。
最后將結果拼接高斯噪聲,提升模型的魯棒性和泛化能力。
Ti,Tobs=hi,t‖z,
(10)
其中,z表示高斯噪聲,hi,t為由式(9)學習到的時空信息的融合結果,Ti,Tobs為融合后的特征向量。
2.5 軌跡解碼器模塊
軌跡預測是通過行人相對位置8個步長信息,結合學習到的時空交互信息,預測下一個步長位置信息。然后將預測位置信息結合前7個步長進行新的預測,以此類推預測12個步長信息。預測的相對位置信息由公式(12)得到。
di.Tobs+1=T(di,Tobs,ei,Tobs;W),
(11)
(xi,t+1,yi,t+1)=M(di,Tobs+1,Wσ),
(12)
其中,ei,Tobs表示相對位置特征向量,di,Tobs為上一步長隱藏信息,di,Tobs+1為預測下一步長信息,W為LSTM的權重,Wσ為MLP權重,經過嵌入函數M,得到下一相對位置坐標。
3 實驗與分析
3.1 實驗數據和環境
采用ETH[12]和UCY[13]兩個公共數據集進行模型評估。數據集由實際生活中行人豐富的交互信息組成,其中ETH數據集包含兩個場景:UNIV和HOTEL。UCY數據集包含三個場景:ZARA01、ZARA02和UNIV。數據集將行人真實位置轉換為世界坐標系下的位置信息。實驗采用留一法,使用其中4個數據集進行訓練和驗證,在剩余1個數據集進行測試。
超參數設置:使用Adam優化器進行參數優化,學習率設為0.001,批處理大小設為64,訓練輪數為600。實驗環境:操作系統為Ubuntu 20.04,處理器顯卡型號為2080Ti,PyTorch版本為1.2,Cuda版本為11.3,所有實驗都是在相同的硬件環境下進行。
3.2 評價指標
實驗時,在模型中輸入8個時間步長(3.2 s)的行人真實軌跡,輸出預測的未來12個時間步長(4.8 s)的行人軌跡。與之前的研究相同,本文使用兩個指標來評估預測誤差。
3.2.1 平均位置誤差
平均位置誤差(Average Displacement Error,ADE)為每一時間步的預測坐標與真實坐標之間的均方誤差,計算公式如下:
(13)
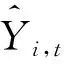
3.2.2 最終位置誤差
最終位置誤差(Final Displacement Error,FDE)為在預測的最后一個時間步T,預測坐標與真實坐標的誤差。計算公式如下:
(14)
3.3 消融實驗
為驗證所提出的邊特征融合模塊和GATv2的有效性,采取調整算法模塊的方法。并在公開數據集UCY和ETH上對ADE和FDE兩個指標進行對比,如表1和表2所示,其中加粗黑體為最好的預測結果。算法1為基礎算法,只采用GAT進行特征提取,不添加任何改進;算法2在基礎算法上采用邊特征融合模塊;算法3在基礎算法上將GAT模塊替換成GATv2模塊;算法4在基礎算法上同時加入邊特征融合模塊和GATv2模塊。
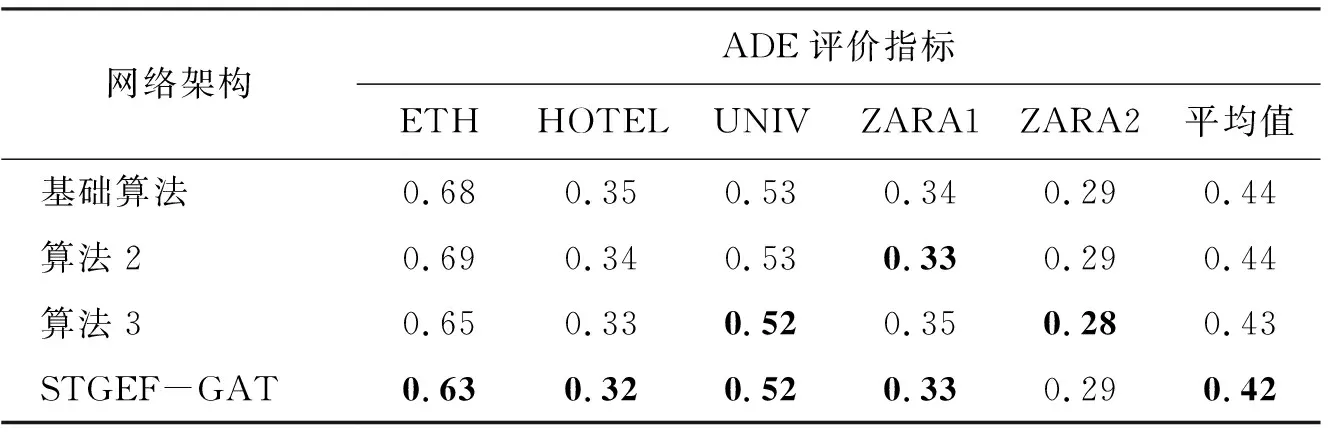
表1 本文算法消融實驗ADE指標
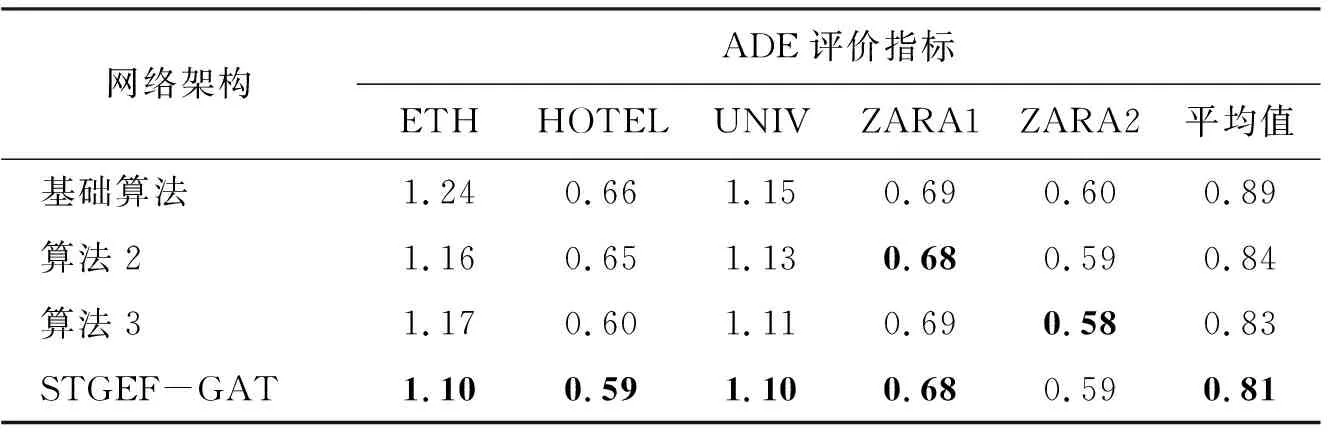
表2 本文算法消融實驗FDE指標
由表1和表2可以看出,當基礎算法增加邊特征后在五個數據集下比較兩個指標,若有一定的提升,或者不變,則表明該模型能有效地利用邊的信息。在基礎算法上替換GATv2模塊,除了ZARA1的ADE略有下降,FDE不變,其他指標都有提升,且單獨使用GATv2模塊的效果要好于邊特征融合,提升效果明顯。最后融合算法2和算法3后,兩種評估指標在ETH、HOTEL、UNIV上都有很好的提升,在ZARA1上的效果和邊特征融合效果一樣,在ZARA2上指標略有下降。分析原因是ZARA1、ZARA2數據集中行人密度小,行人交互性不強,增加太多交互關系,產生了一定的過擬合問題。實驗結果證明,邊特征融合和GATv2模塊的應用均可提升預測精度。
3.4 實驗結果分析
為了評估STGEF-GAT算法的性能,本文選取了七種算法(Linear、LSTM、S-LSTM、S-GAN、Sophie[14]、STGAT、STGEF-GATv2)進行ADE和FDE的對比,如表3和表4所示。所有算法的行人觀測時間為3.2 s,行人預測時間為4.8 s。表中黑體為最好預測結果。
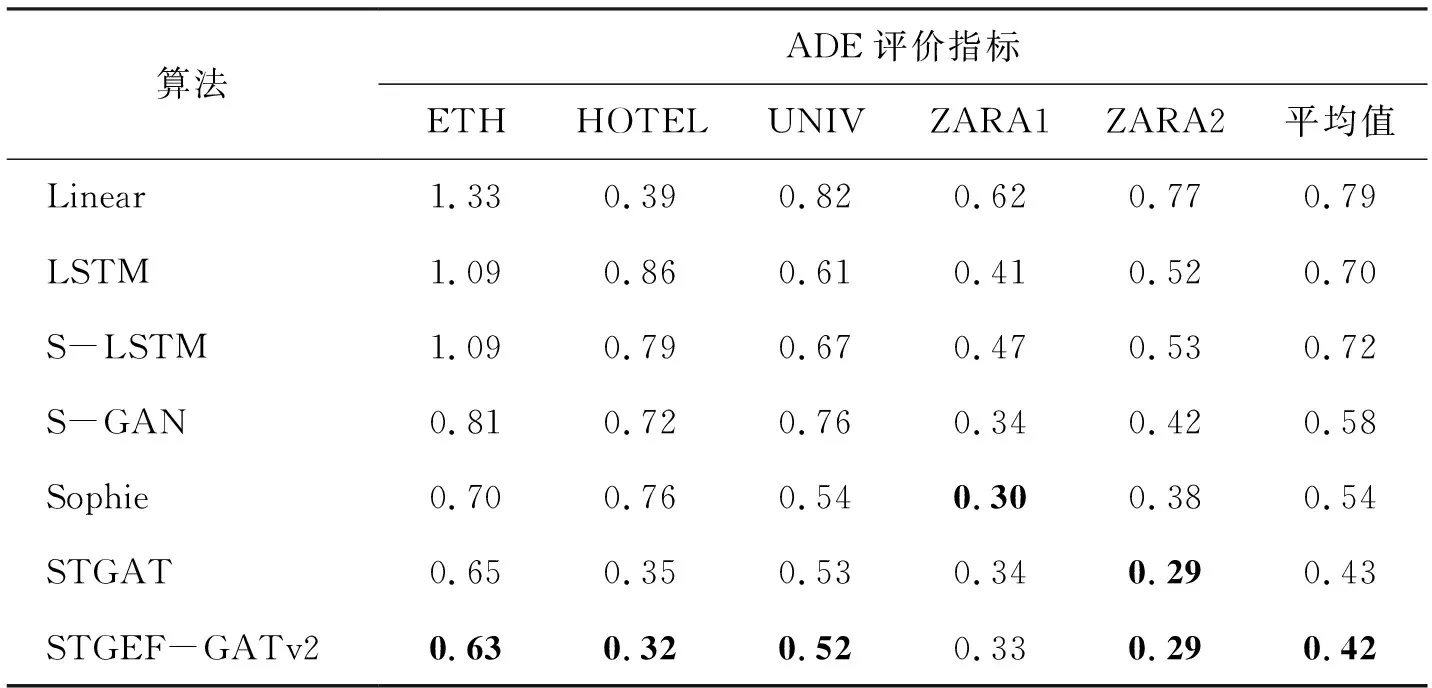
表3 本文算法與其他算法的ADE指標比較
表3和表4的實驗結果證明了邊特征融合和GATv2模塊的有效性,在五個不同的數據集上有較好的表現,除ZARA1數據集的ADE和FDE指標低于Sophine模型,其余四個數據集的ADE和FDE指標都要高于所比較的算法,最終平均值全部高于所比較的算法預測,達到了提高模型精度的目的。
3.5 定性評價
為了更好地展示模型的預測效果,對模型進行軌跡可視化展示和權重分配可視化展示,以下兩種有效的可視化展示模塊來自于文獻[7]。在ZARA1數據集四個不同場景下的可視化軌跡預測如圖5所示,其中實線代表觀測軌跡,虛線代表預測軌跡,與虛線相近的實線表示真實軌跡。由圖5可以很好地看出STGEF-GATv2模型的有效性。

圖5 不同場景的可視化圖
從圖5的場景3可以看出,同向行走的預測軌跡和真實軌跡基本相符。逆向行走對行人預測軌跡影響較大,導致預測位置發生偏移,且距離位置越近,影響越大,如場景1和場景2相反行走的行人,當兩人發生交互時對預測同樣產生較大的影響,如場景4。分析原因是當兩人交互時,行人之間交互影響增強,從而導致預測位置發生偏移。綜上所述,預測可視化很好地展示了模型預測的精度。
為了更好體現模型是否與周圍行人產生聯系,對目標行人為周圍行人分配的注意力權重進行可視化分析,如圖6所示。軌跡上的黑點表示不同時間的步長,箭頭代表行人前進的方向,沒有圓圈代表目標行人的軌跡,圓圈的大小和權重分配成正比,權重越大圓圈越大。

圖6 權重分配可視化圖
在圖6的場景1和場景2中,同向行走的行人相較于逆向行駛的人會分配得到更低的權重,表明與預測行人同向行駛的人有較小的影響力,反之有較大的影響力;在場景3和場景4中,同向后方行走人員相較于同向前方行走人員對目標行人影響更小,分配得到更少的權重。不足的是對于靜止不動的行人(場景2),始終分配最大的權重。綜上所述,該算法可以有效分配目標行人和周圍行人的權重信息,充分表明了該模型的有效性。
4 結語
行人邊特征提取模塊能有效解決圖注意網絡邊信息的缺失問題,此模塊為圖自注意力層提供更多可學習信息。采用GAT的變體GATv2,可以用更少的頭和層數達到更好的預測效果,降低了模型復雜度,同時也提升了模型的預測準確度。將預測結果進行可視化研究分析,可以更直觀地感受該模型軌跡預測效果。為驗證模型的有效性,在ETH和UCY兩個數據集上進行實驗,結果顯示,平均位置誤差和最終位置誤差兩個指標都有所提升。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
