基于深度學習的電子創(chuàng)新產(chǎn)品評論情感分析
2024-02-09 00:00:00檀為龍
消費電子 2024年11期
關鍵詞:深度學習
【關鍵詞】深度學習;電子創(chuàng)新產(chǎn)品;情感分析
引言
近年來,電子創(chuàng)新產(chǎn)品市場呈現(xiàn)出快速增長的態(tài)勢,消費者對產(chǎn)品的評價和反饋也愈發(fā)重要。在線評論作為消費者表達意見和感受的重要渠道,蘊含著豐富的情感信息[1]。對這些評論進行情感分析,有助于企業(yè)及時了解用戶對產(chǎn)品的滿意度、發(fā)現(xiàn)潛在問題,并據(jù)此調(diào)整產(chǎn)品設計和市場策略。傳統(tǒng)方法主要依賴人工構建的詞典和規(guī)則進行情感分類,但這種方法難以適應大規(guī)模、多樣化的評論數(shù)據(jù)[2]。近年來,隨著深度學習技術的興起,基于神經(jīng)網(wǎng)絡的情感分析方法逐漸嶄露頭角,深度學習模型能夠自動學習文本特征,實現(xiàn)更準確的情感分類。然而,針對電子創(chuàng)新產(chǎn)品評論的情感分析仍面臨諸多挑戰(zhàn)。本研究的意義在于,通過提出新的深度學習模型SCB,并對其進行實驗驗證和性能評估,為情感分析任務提供新的思路和方法。同時,通過對比實驗和參數(shù)優(yōu)化,本研究深入探討了影響深度學習模型性能的關鍵因素,為深度學習技術在自然語言處理領域的應用提供了有力支持。
一、深度學習與情感分析方法概述
深度學習作為機器學習領域的一個重要分支,致力于構建高度復雜且具有深層次結構的神經(jīng)網(wǎng)絡模型。這一范式通過無監(jiān)督學習的方式,自動且高效地從原始數(shù)據(jù)中提取并學習其內(nèi)在的高級特征表示,從而實現(xiàn)對數(shù)據(jù)深層次模式的理解與挖掘。深度學習的核心優(yōu)勢在于其依托一系列先進且強大的算法,這些算法構成了其理論與方法論的基石,其中卷積神經(jīng)網(wǎng)絡(Convolutional Neural Networks,CNN)、循環(huán)神經(jīng)網(wǎng)絡(Recurrent Neural Network, RNN)以及長短期記憶網(wǎng)絡(Long Short-Term Memory, LSTM)等模型尤為關鍵[3]。
CNN憑借卷積和池化機制在圖像處理中表現(xiàn)出色,能捕捉圖像空間特征;RNN專于處理序列數(shù)據(jù),動態(tài)建模時間序列;LSTM作為RNN的改進,通過記憶單元增強長序列處理能力,在語言模型和機器翻譯中成效顯著。這些核心算法推動了深度學習的廣泛應用,深刻影響了人工智能的發(fā)展。
情感分析作為一種關鍵性的自然語言處理技術,也被稱作意見挖掘或情感傾向識別。其核心在于通過細致的分析、處理、總結及邏輯推理,針對蘊含情感色彩的主觀性文本內(nèi)容,自動識別出文本作者對于特定話題所持有的態(tài)度傾向或情緒表達[4]。情感分析的策略主要可劃分為三大類別:一是依賴情感詞典的傳統(tǒng)方法,深度學習技術的深入發(fā)展,極大地推動著情感分析領域向更高效、更精準的方向邁進。深度學習模型,如CNN、RNN、LSTM等,能夠自動學習文本特征,充分利用文本的上下文關聯(lián)信息,實現(xiàn)對文本情感的精準分析[5]。此外,注意力機制和預訓練模型(如BERT、XLNET等)的引入進一步提升了情感分析的性能,使得該方法在處理復雜情感任務時更加高效和準確。當前,情感分析在輿情分析、內(nèi)容推薦、商品評價等多個領域具有廣泛應用。
二、模型構建與分析
(一)構建模型
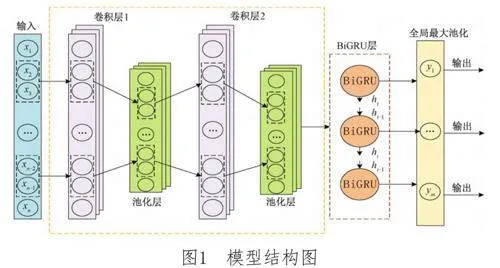
本研究創(chuàng)新性地提出了SCB模型,該模型結合了CNN和基于注意力機制的雙向門控遞歸單元(Bidirectional Gated Recurrent Unit,BiGRU),旨在開發(fā)一種高效針對序列數(shù)據(jù)的分類與預測模型。在SCB模型中,CNN層被用于捕捉序列數(shù)據(jù)中的局部特征,并執(zhí)行最大池化以提取關鍵信息;隨后,BiGRU層通過對特征雙向處理,全面把握序列數(shù)據(jù)的內(nèi)在信息。最終,輸出層通過全局最大池化進一步精選關鍵特征,并對序列進行壓縮。模型的訓練過程采用了反向傳播算法與Adam優(yōu)化器來優(yōu)化模型參數(shù),并引入Dropout機制以增強模型的魯棒性。這些設計確保了SCB模型在處理序列數(shù)據(jù)時能夠表現(xiàn)出色,兼具高穩(wěn)定性和準確性,具體如圖1所示。
(二)數(shù)據(jù)采集與預處理
本研究采用的數(shù)據(jù)集是通過網(wǎng)絡爬蟲技術從中關村在線收集的產(chǎn)品評論數(shù)據(jù)。在原始數(shù)據(jù)集中,用戶對電子創(chuàng)新產(chǎn)品的評價被細分為五個等級(1-5星)。然而,研究并未直接依賴這種簡單的星級劃分來評價情感傾向,而是采用了更為先進的深度學習方法,構建復雜的神經(jīng)網(wǎng)絡模型,旨在自動學習評價中的情感傾向。數(shù)據(jù)集經(jīng)過預處理后,最終包含100,000條評論,其中正面評價和負面評價各占50,000條,以此作為深度學習模型的訓練與測試數(shù)據(jù)。數(shù)據(jù)預處理階段應用了先進的自然語言處理技術,利用PyTorch分詞工具實現(xiàn)文本的高效分詞與預處理。為確保數(shù)據(jù)的純凈性和一致性,刪除了停用詞、標點符號及非中文字符。為了構建符合深度學習模型輸入要求的特征表示,研究根據(jù)模型的最大輸入長度(max_length)對評論進行了截斷或填充操作,使得所有評論數(shù)據(jù)具有相同的輸入長度。值得注意的是,整個預處理過程都未將平均評論長度作為固定長度,而是將其作為設置max_length參數(shù)的重要參考因素,以高效處理變長輸入序列,為后續(xù)的模型訓練與評估奠定了堅實的基礎。
三、實驗分析
(一)評價指標
對深度學習方法的評估主要關注準確性(α)、精確度(p)、召回率(r)和F1分數(shù)這四個性能指標。真正例(TP)指代成功識別的有害樣本,假正例(FP)表示被錯誤地判定為有害的良性樣本,真負例(TN)準確描述了被正確歸類為正常的樣本;假負例(FN)則反映了被誤標記為正常的異常樣本。p是一個關鍵指標,它聚焦于模型預測為正面評論中實際為正面的比例,從而有效評估模型對正面評論的預測準確度。另一方面,r則體現(xiàn)了模型正確識別出所有實際正面評論的能力,即正確預測的正面評論在實際所有正面評論中的占比,這對于全面捕捉實際正面評論至關重要。最后,F(xiàn)1分數(shù)作為精確度和召回率的調(diào)和平均值,綜合評估了模型的性能,特別是在數(shù)據(jù)不平衡的情況下,F(xiàn)1分數(shù)尤為重要,因為它能夠平衡精確度和召回率,進行更為全面的性能評估。具體如式(1)所示:
(二)實驗結果分析
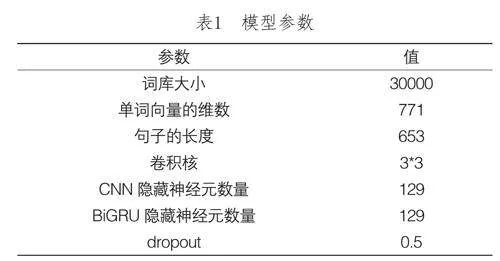
為了全面且精確地評估本文提出的深度學習模型性能,研究采用了10折交叉驗證與5×2交叉驗證兩種策略。在10折交叉驗證中,數(shù)據(jù)集被隨機且均衡地劃分為10個部分,每次使用其中的9個部分進行模型訓練,剩余的1個部分用于驗證,最終的性能評估是基于這10次驗證結果的平均值。而在5×2交叉驗證中,數(shù)據(jù)集被隨機分為兩個子集,這兩個子集交替用于訓練和測試,重復5次后取平均值作為最終的評價。此外,考慮到文本序列長度的多樣性,研究設定了統(tǒng)一的長度閾值,并試驗以最大句子長度和平均句子長度作為模型的固定輸入長度。由于在選擇平均句子長度作為輸入長度時,超長的句子會被截斷,從而可能導致上下文信息的丟失,影響模型的性能;因此,選擇合適的輸入長度是優(yōu)化模型性能的關鍵考量之一,具體如表1所示。

本研究系統(tǒng)性地探究了詞匯表大小對深度學習模型性能的調(diào)節(jié)作用。實驗首先從包含50,000個單詞的廣泛詞匯表開始,依據(jù)單詞頻率逐步縮減,每次減少5,000個單詞進行迭代。分析結果顯示,當詞匯表規(guī)模調(diào)整至約30,000個單詞時,模型展現(xiàn)出最優(yōu)性能。這表明,選擇適當?shù)脑~匯表大小對于優(yōu)化深度學習模型性能至關重要。接著,實驗考察了不同訓練迭代次數(shù)對模型性能的影響,發(fā)現(xiàn)隨著訓練迭代的增加,模型性能先提升后降低,在迭代8次時達到最佳性能,之后模型開始出現(xiàn)過擬合現(xiàn)象。為了提升模型的能力,實驗引入dropout機制,并通過微調(diào)dropout值發(fā)現(xiàn),設定為0.5時,模型性能達到最佳平衡,既保持了高訓練精度,又有效避免了過擬合。此外,實驗還對比了加權詞與未加權詞向量在模型中的應用效果,發(fā)現(xiàn)加權詞向量通過情感詞典的精細處理,能更顯著地突出情感特征,從而提升模型在情感分析任務中的性能。最后,實驗為了全面評估SCB模型的性能,在同一數(shù)據(jù)集上將其與支持向量機(Support Vector Machine,SVM)、CNN和BiGRU等情感分析模型進行對比,結果顯示深度學習模型,尤其是CNN和BiGRU,性能明顯優(yōu)于傳統(tǒng)機器學習模型SVM,其整合注意力機制能進一步提升模型的分類性能。最終,結合CNN、BiGRU和注意力機制的SCB模型,在性能上超越了其他幾種模型,充分證明了其優(yōu)越性和有效性。實驗結果如表2所示。
實驗數(shù)據(jù)揭示了深度學習模型,尤其是CNN和BiGRU,相較于傳統(tǒng)的機器學習模型SVM,展現(xiàn)出更為出色的性能。不僅如此,通過在深度學習模型中融入注意力機制,模型的分類性能得到了顯著提升。尤為值得注意的是,本研究提出的SCB模型,通過結合深度學習技術,包括CNN、BiGRU以及注意力機制,其整體性能超越了其他幾種在情感分析任務中廣泛應用的深度學習模型,從而充分彰顯了SCB模型在情感分析領域的優(yōu)越性。
結語
隨著網(wǎng)絡的快速發(fā)展,大量蘊含價值信息的電子產(chǎn)品評論應運而生。為更有效地挖掘和利用這些信息,本文專注于提取產(chǎn)品特征并進行深入的情感分析。為此,本文構建了一個結合CNN和BiGRU的SCB模型,該模型實現(xiàn)了對文本情感的精準分析。實驗結果顯示,SCB模型在準確性、精確度、召回率和F1分數(shù)等多項性能指標上均表現(xiàn)出色,顯著超越了其他幾種主流的情感分析深度學習模型。為了進一步提升模型性能,研究深入探究了詞匯表大小、訓練迭代次數(shù)以及dropout值等關鍵參數(shù)對模型性能的影響,并據(jù)此優(yōu)化了模型設置。此外,加權詞向量的使用也有效強化了句子中的情感特征表達,使SCB模型取得了更為優(yōu)異的性能。綜上所述,本研究提出的SCB模型在情感分析任務中展現(xiàn)出了顯著的有效性和優(yōu)越性,為相關領域的研究提供了新的思路和方法。
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現(xiàn)代商貿(mào)工業(yè)(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現(xiàn)代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
