一種修正評分偏差并精細聚類中心的協同過濾推薦算法
2024-03-16 13:38:40段剛龍
統計與決策 2024年4期
馬 鑫,段剛龍
(1.南開大學商學院,天津 300110;2.西安理工大學 a.經濟與管理學院;b.大數據分析與商務智能實驗室,西安 710054)
0 引言
近年來,推薦系統作為傳統搜索引擎的重要補充,成為幫助用戶專注有用信息和緩解信息過載的重要工具,而協同過濾是個性化推薦系統中使用最普遍的推薦算法[1]。為應對協同過濾算法的數據稀疏等問題,既有研究往往結合聚類、回歸、圖等算法[2,3]或矩陣分解、多模態數據融合、矩陣填充等技術[1,4,5]進行組合推薦。在聚類算法方面,劃分聚類算法因具有準確率高、可操作性強等優點,常被學者加以改進后用來對用戶進行聚類。改進方法主要有手肘法[6]、輪廓系數[7]、譜聚類[8]、粗聚類[9]等。雖然上述改進算法在一定程度上提升了基于劃分聚類的協同過濾推薦(Divide Clustering-based Collaborative Filtering Recommender,DC-CFR)算法的推薦效果,但仍存在以下不足:(1)評分失真且評分區分度小。現有產品評分多為“5 星評價”,離散、有限數值往往難以準確量化用戶的真實喜好,而這種偏差會進一步影響用戶聚類中高維稀疏評分向量間的空間距離測算,影響DC-CFR算法的表現;此外,受從眾效應和可得性效應的影響,用戶評分分布較為集中,信息量較小,通過空間距離或相關系數比較用戶間異同的難度較大。(2)初始聚類中心隨機。自由參數問題是劃分聚類算法的主要缺陷。相比于最佳聚類數的確定,初始聚類中心的選擇較少被討論和研究。而隨機初始聚類中心不僅易使聚類結果陷入局部最優,而且會增加聚類迭代次數,累積數據稀疏造成的用戶聚類偏差,影響DC-CFR 算法推薦效果。
鑒于此,本文提出一種基于評論情感挖掘與數據場聚類的協同過濾推薦算法(Comment Sentiment Mining and Data Field Clustering-based Collaborative Filtering Recommender,CSM-DFC-CFR),該算法首先利用高頻詞性路徑規則等無監督情感挖掘技術量化評論情感來修正用戶-產品評分矩陣中的評分;其次,利用數據場算法計算劃分聚類自由參數的取值;然后,通過基于相似用戶的聚類協同過濾推薦算法生成產品推薦列表;最后,在三個真實數據集上進行實驗,以驗證改進算法的推薦效果。
1 基于劃分聚類的協同過濾推薦算法
傳統的DC-CFR 算法是基于相似用戶的協同過濾推薦算法的一種改進算法,具有易理解、易復現、推薦結果新穎度高等優勢[10]。其基本思想是:在用戶-產品評分矩陣上,通過劃分聚類創建較少且包含目標用戶的聚類簇,以降低近鄰用戶檢索中的相似度計算次數,減小數據稀疏性對聚類效果的影響。
假設有用戶-產品評分矩陣M=[r1r2…rm]T,其中ri=(ri,1,ri,2,…,ri,n),m為用戶數,n為產品數,ri,j為用戶i對產品j的評分。隨機選擇k個用戶評分向量ri作為初始聚類中心C=[c1c2…ck]T,按歐氏距離大小將用戶歸到最近聚類中心:
更新聚類中心:
其中,|Ck|為第k個聚類中包含的用戶數。
當誤差平方和最小時聚類停止迭代:
計算目標用戶u與同簇用戶v的相似度:
預測用戶-產品評分矩陣中目標用戶缺失評分:
其中,為目標用戶u同簇用戶v的歷史評分均值,Nu為用戶u的最近鄰域。
將ru,j降序排列,選擇前z個較高評分對應的產品pj生成推薦列表。
2 基于評論情感挖掘與數據場聚類的協同過濾算法
2.1 評論情感挖掘算法
在線產品評論一直是用戶生成決策的重要信息來源。為進一步提升DC-CFR 算法在高維數據空間中的用戶聚類能力,本文利用一種無監督評論情感挖掘算法修正評分與用戶偏好間的偏差。
假設有用戶u的評論集合Tu={t1,t2,…,tm},m為歷史評論數,ti為用戶u對產品i的評論。
對評論t進行預處理,附加148612個詞的分詞詞庫和3451 個詞的停用詞詞庫,利用pkuseg 工具進行分詞并標注詞性,統計并生成10個高頻詞性路徑:
其中,n為名詞,a為形容詞,d為副詞,v為動詞,an為形容詞性名詞,l為習用語。
按Ruls路徑對評論t進行模糊匹配,生成詞對pt={(w1,s1),(w2,s2),…,(wf,sf)},f為詞對個數,wi為實體詞,si為情感詞。
計算實體詞wi與產品主題詞themei之間的互信息,剔除不相關實體詞及對應情感詞:
其中,I(wi,themei)為wi與themei之間的互信息,值越大表明關聯程度越強;p(wi,themei)為wi與themei共同出現的次數,p(wi)為wi單獨出現的次數,p(themei)為themei單獨出現的次數。
利用SingleRank算法計算Tu中實體詞wi的權重hwi,生成實體偏好向量Hu=(hw1,hw2,…,hwg),g為集合Tu中的實體詞數量。
計算評論t中的實體詞相對權重:
基于NTUSD[11]、Hownet[12]的研究以及自整理詞典,按[積極,中性,消極]=[5,3,1]的規則量化情感詞,生成評論t中情感詞si的情感值cssi。
評論t的整體情感值為:
設定評分修正幅度Δ,將Et調整到[-Δ,Δ]范圍:
修正用戶-產品評分矩陣中評論t的對應評分r:
2.2 數據場算法
受物理學場論啟發,數據場將數域空間中的數據對象當作相互作用的有質量粒子,任一數據對象均受其他對象的共同作用,且當無外力作用時,數據對象會相向運動并聚集成簇,類似劃分聚類過程,因此常被用于劃分聚類算法優化[13]。
為解決劃分聚類算法的自由參數問題,尤其是隨機初始聚類中心的選擇問題,本文提出了一種數據場算法,可一次性確定最佳聚類數和最優初始聚類中心,減少聚類迭代次數,避免數據稀疏性引起的用戶聚類偏差累積。
假設有修正評分后的用戶-產品評分矩陣R=[r1r2…rm]T,其中,ri=(ri,1,ri,2,…,ri,n),m為用戶數,n為產品數,ri,j為用戶i對產品j的評分,U為用戶集合。
計算數據場中各用戶ui的相互作用勢值:
其中,d為歐氏距離,mj為用戶uj的質量,滿足Σm=1,σ為數據對象之間的相互作用力里程。
對于用戶質量mi和作用里程σ,給定計算公式:
其中,|Ngi|為與用戶ui相距不超過1/4分位數距離的用戶數,φ(ui)為對應σ取值下用戶ui的勢值,argmin 為獲取最小值對應σ的函數。
利用隨機爬山法計算數據場的勢值極大值,將極大值對應用戶評分向量作為初始聚類中心C=[c1c2…ck]T,最佳聚類數k即為|C|。
2.3 改進的協同過濾推薦算法
本文首先通過評論情感挖掘算法修正評分偏差,使評分更加接近用戶真實偏好,得到更加準確的用戶-產品評分矩陣;然后,利用數據場算法計算用戶聚類的最佳聚類數和最優初始聚類中心;最后,通過基于劃分聚類的協同過濾推薦算法為目標用戶生成推薦結果。
2.3.1 算法模型構建
本文提出的基于評論情感挖掘與數據場聚類的協同過濾推薦算法(CSM-DFC-CFR)模型見圖1。
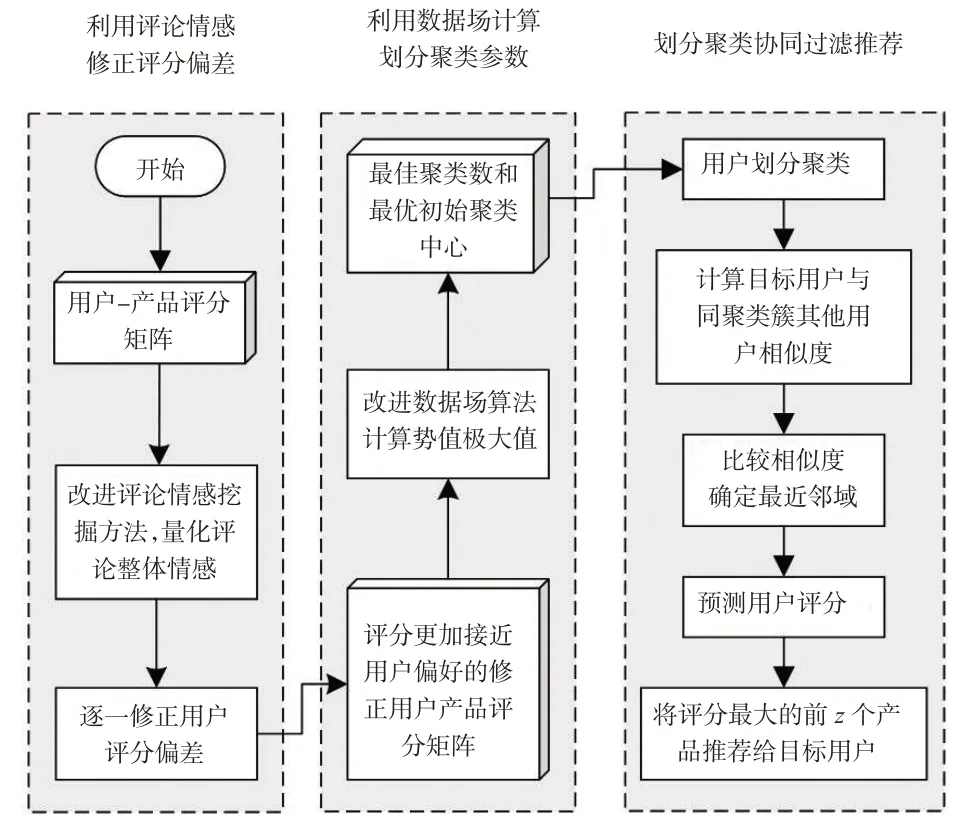
圖1 基于評論情感挖掘與數據場聚類的協同過濾算法模型
2.3.2 算法描述
圖1所示模型包含三大模塊,具體描述如下:
(1)利用評論情感修正用戶評分模塊。首先,利用高頻詞性路徑規則匹配評論文本中的實體詞與情感詞,并借助互信息剔除無關實體詞及對應情感詞;然后,利用混合情感詞詞典對情感詞進行量化,計算評論中各實體詞的相對權重;最后,按實體詞相對權重對各量化情感值進行加權以獲得評論總體情感值,在[-Δ,Δ]區間內對用戶評分進行修正。
(2)利用數據場計算劃分聚類參數模塊。基于評分修正后更加接近用戶真實喜好的用戶-產品評分矩陣,先計算各用戶質量m和數據場作用里程σ,再將其作為勢函數參數,計算用戶之間的相互作用勢值,利用啟發式隨機爬山法挖掘勢值分布規律,尋優勢值極大值。
(3)劃分聚類協同過濾推薦模塊。首先,將勢值極大值點對應評分向量和勢值極大值點個數分別作為劃分聚類的聚類數和初始聚類中心,對用戶進行迭代聚類;然后,計算目標用戶與同聚類簇用戶相似度,并按相似度大小降序排列生成最近鄰域Nu;最后,基于鄰域用戶相似度和非共有評分預測目標用戶可能評分,按評分高低生成長度為z的產品推薦列表。
2.3.3 算法流程
綜上所述,CSM-DFC-CFR算法步驟如下:
3 算法驗證
3.1 數據來源與處理
遵循網站robots協議,利用爬蟲采集了2015年6月17日至2020 年5 月9 日某知名電商平臺1190 個類目下153129 個商品的評分及評論文本,從中隨機抽取三組數據作為實驗數據集,分別占原始評分數據的0.8%(數據集1)、0.9%(數據集2)和1.1%(數據集3)。同時,剔除歷史評分總數為0的用戶行和產品列,并按用戶評分時間先后將前80%數據作為訓練集,后20%數據作為測試集,以供模型訓練使用。實驗數據集的統計特征如表1所示。
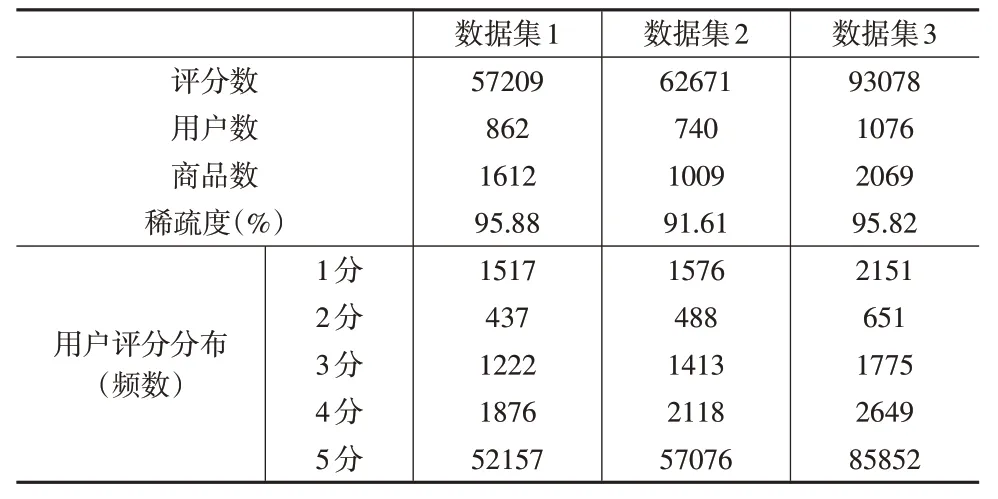
表1 預處理后實驗數據集統計特征
3.2 評價指標與對照算法
采用精度Precision(見公式(15))、召回率Recall(見公式(16))和F1-Score(見公式(17))共三種常見評價指標對算法推薦效果進行評價[10,14]。特別地,所有評價指標均依據產品推薦列表R(u)和測試集用戶選擇列表T(u)計算得出。
關于對照算法,選擇基于用戶的協同過濾推薦(U-CFR)算法、基于K-means的協同過濾推薦(KM-CFR)算法、融合Canopy和K-means的協同過濾推薦(CKM-CFR)算法、基于評論情感挖掘的協同過濾推薦(CSM-CFR)算法、基于數據場聚類的協同過濾推薦(DFC-CFR)算法以及本文所提算法(CSM-DFC-CFR)共六種算法在三個實驗數據集上進行實驗,所有實驗結果的數據為1折15次交叉實驗結果的平均值。
3.3 實驗結果
3.3.1 參數影響
對于評分修正幅度Δ,分別取值為0.1、0.2、0.3、0.4和0.5,探討Δ的最佳取值。由圖2 可知,CSM-DFC-CFR 算法精度在Δ=0.4時最優(召回率也相對較優),算法表現最佳。
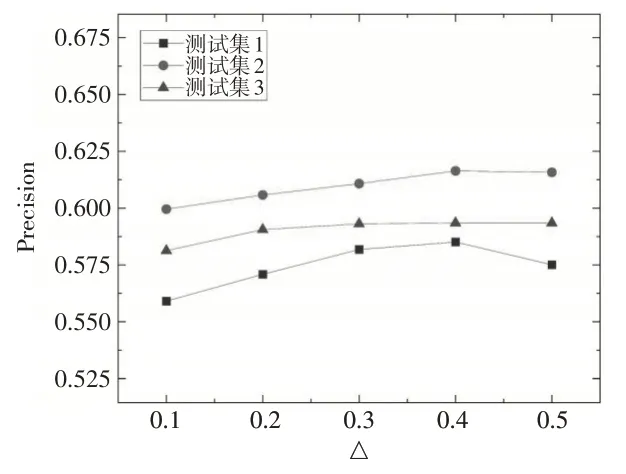
圖2 不同評分調整幅度Δ對CSM-DFC-CFR算法精度影響
對于最近鄰域大小|Nu|,很容易理解,最近鄰數量增加會降低目標用戶與鄰居之間的評分相似度,如果取值過大,那么勢必會影響算法表現。參照文獻[15],將所有算法最近鄰域大小取值為5。此外,參照文獻[16],令各算法推薦列表長度z=15。
3.3.2 算法性能分析
不同對照算法在三個測試集中的1折15次Precision、Recall和F-Score表現如圖3所示。對比U-CFR算法和CSMDFC-CFR 算法的兩種變體算法(CSM-CFR 和DFC-CFR)的結果發現,評論情感挖掘修正用戶評分和數據場聚類方法均能提升協同過濾算法的性能,且數據場聚類的方法對算法推薦效果正向作用更大。此外,進一步對比CSM-DFC-CFR及其兩種變體算法可以發現,評論情感挖掘修正用戶評分和數據場聚類兩種方法的結合要比任意一種方法對算法推薦性能的提升效果都要明顯。對比U-CFR、KM-CFR、CKM-CFR 和CSM-DFC-CFR 算法,結果表明,本文所提CSM-DFC-CFR算法在三個不同評價指標上推薦性能均最佳,CKM-CFR 算法次之,而KM-CFR和U-CFR算法較差。
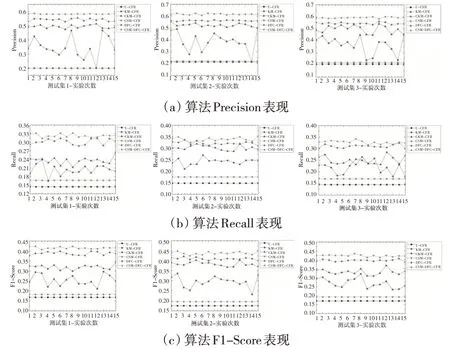
圖3 不同測試集中推薦算法的性能表現
3.3.3 算法有效性分析
為充分證明本文所提算法的有效性,進一步利用Kruskal-Wallis 檢驗方法對CSM-DFC-CFR 與U-CFR、KM-CFR、CKM-CFR和CSM-CFR算法的1折15次交叉驗證結果進行組間差異比較。表2的結果表明,在95%的置信區間內,各測試集CSM-DFC-CFR算法的性能表現均顯著優于其他對照算法(P<0.05)。還可以發現,雖然CSMDFC-CFR 與DFC-CFR 算法在各評價指標結果之間并不存在顯著組間差異,但平均而言,CSM-DFR-CFR 算法的Precision、Recall 和F1-Score 均優于DFC-CFR 算法。以上結果充分證明了本文所提推薦算法的有效性,算法的優化思路與實際數據相吻合。
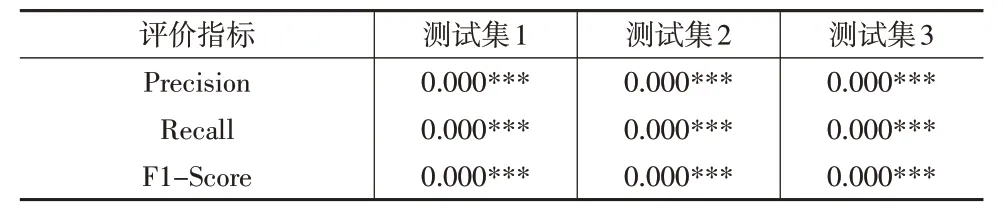
表2 CSM-DFC-CFR和對照算法的性能差異比較
4 結束語
本文針對當前DC-CFR 算法存在的評分失真和區分度小以及自由參數問題,提出了一種基于評論情感挖掘和數據場聚類的協同過濾推薦算法。其中,評論情感挖掘是指利用無監督情感挖掘技術對評論整體情感進行量化,通過加權方式修正用戶評分,以提升評分區分度(細化了評分粒度),縮小評分與用戶真實喜好之間的偏差。數據場聚類是指利用數據場計算最佳聚類數和最優初始聚類中心,對用戶進行劃分聚類,以縮小最近鄰域檢索范圍,優化高維數據聚類表現。三個真實數據集的實驗結果表明,與其他算法相比,本文所提算法在Precision、Recall和F1-Score指標上的表現均最優。值得注意的是,本文未處理虛假用戶評論,即假定評論中不存在不實消費經歷及對商品實體的鼓吹或誹謗[17],未來將考慮運用文體或元數據特征識別并剔除虛假評論,對本文算法進行改進。
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
家庭醫學(下半月)(2020年4期)2020-05-30 12:42:50
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
中國生殖健康(2018年5期)2018-11-06 07:15:40
商用汽車(2016年11期)2016-12-19 01:20:16
發明與創新(2016年6期)2016-08-21 13:49:38
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
