對抗條件下空中目標威脅評估方法 *
2024-03-18 07:22:24梁復臺周焰張晨浩宋子豪趙小瑞
現代防御技術 2024年1期
梁復臺,周焰 ,張晨浩 ,宋子豪 ,趙小瑞
(1. 空軍預警學院,湖北 武漢 430000;2. 中國人民解放軍31121 部隊,江西 南昌 330000)
0 引言
1988 年數據融合聯合指揮實驗室提出JDL(joint directors of laboratories)模型,其將威脅評估(threat assessment,TA)定義為數據融合系統中的高層次數據融合處理過程,其通過推理紅方意圖和目的,量化并判斷紅方行為對藍方的威脅程度[1]。文獻[2-3]對初始JDL 模型中威脅評估的解釋進行了擴展,文獻[2]指出威脅評估應該擴展為影響評估,包括威脅評估、行為分析和結果預測。同時,文獻[4]認為威脅評估不僅要對紅方能力及意圖進行分析,還要對藍方能力進行分析,將它們結合起來綜合分析,才算是威脅評估。在這個定義中,考慮了對抗雙方的能力,體現了威脅的對抗性。文獻[5]對JDL 數據融合模型進行了新修訂,強調了威脅評估中雙方行動計劃之間的互動,進一步明確了威脅評估的對抗性。
目前,戰場威脅評估的方法主要有:貝葉斯推理[6]、模糊推理[7]、多屬性決策理論[8]、案例推理[9]、專家系統或基于知識的方法[10]、遺傳算法[11]等。總結起來,主要分為2 類:一是建立威脅評估數學模型的方法;二是基于各種智能算法的威脅評估方法。建立威脅評估數學模型時,對屬性權重確定與方案排序是重點。采用基于智能算法的威脅評估方法,對數據的標記及模型的訓練是重點。兩種方法中無論是屬性權值確定還是訓練數據標記,其前提都需要確定威脅因素指標體系,但目前的研究中,大多只關注了紅方的靜態威脅,很少考慮雙方對抗因素,缺乏對戰場威脅動態演化過程的研究。
真實戰場環境中,威脅評估存在動態性和對抗性。受藍方預警探測、火力打擊兵器等反制力量及部署的影響,紅方空中目標的行動會做出相應調整,從而帶來其威脅程度的變化,這種變化趨勢給人工研判帶來挑戰,亟需智能化方法對紅方空中目標威脅變化趨勢提前預判以掌握戰場主動。
應用強化學習技術來解決對抗條件下的威脅評估問題,更適用于真實戰場環境,可以減少人工參與,同時提高威脅評估的智能化程度。本文將強化學習應用于威脅評估,是在靜態威脅評估方法基礎上,以紅方空中目標為智能體設計強化學習模型,通過雙方的對抗博弈,使得強化學習模型具備自主決策能力,再對紅方動態威脅進行預測,實現對抗條件下的紅方空中目標威脅評估。
1 方法框架
對抗條件下的目標威脅評估方法以強化學習技術為基礎。首先,通過對紅方空中目標、戰場環境及藍方反制力量的抽象,形成適合強化學習的戰場態勢表述。同時,以紅方目標為智能體,采用強化學習技術,使其具備自主決策的能力,進而可得到關于其下一步行動的預判。最后根據其行動預判得到紅方空中目標的狀態變化,通過威脅評估模型實現對紅方目標威脅的估計與預測。對抗條件下的目標威脅評估的基本框架如圖1 所示。
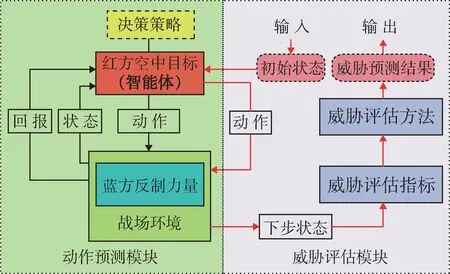
圖1 對抗條件下威脅評估框架Fig. 1 Diagram of threat assessment framework under confrontational conditions
對抗條件下的威脅評估框架主要由威脅評估模塊及動作預測模塊兩部分組成。
在動作預測模塊中,以紅方空中目標為智能體,建立強化學習模型,智能體和環境通過狀態、動作、獎勵進行交互的方式進行訓練,生成紅方空中目標決策策略。決策策略的形式由強化學習算法決定,可以是策略表,也可以是深度神經網絡。訓練完成后,輸入當前戰場態勢數據,可以根據決策策略輸出紅方空中目標下一步動作。
動作預測模塊中,紅方空中目標具備一定的態勢感知能力,通過對藍方策略及反制力量的實時感知,不斷更新強化學習模型并生成相應策略。
在威脅評估模塊中,將當前戰場態勢輸入動作預測模塊,預測得到紅方空中目標下一步動作,根據該動作得到其下一步所處的狀態,然后根據預先建立的威脅因素指標,使用威脅評估算法或已經訓練完成的威脅評估模型,得出對抗條件下紅方空中目標的威脅預測評估結果。
2 威脅評估步驟
對抗條件下空中目標威脅評估過程可以分為兩個主要步驟。一是紅方空中目標動作預測;二是紅方空中目標威脅評估。
2.1 空中目標動作預測
對紅方空中目標動作進行預測,首先構建強化學習模型,其中重點是設計獎勵函數,然后進行模型訓練。
2.1.1 強化學習模型構建
強化學習是機器學習的范式和方法論之一[12]。其基本原理是讓智能體與環境不斷地交互反饋,利用交互樣本和反饋信息不斷更新策略且利用策略,最終獲得最優策略[13]。
強化學習的任務定義中主要有智能體和環境(此環境非戰場環境)兩個可以進行交互的對象,基本要素有智能體狀態、智能體動作、狀態轉移概率及獎勵函數[14]。通常通過四元數組(S,A,T,R)來定義強化學習的數學模型。按照本文方法設計思想,這里的智能體是紅方空中目標,環境包括戰場環境以及藍方兵力火力。
(1) 狀態空間
提取紅方空中目標所處的狀態,如目標位置區域、距離、航向角等,構建狀態空間。紅方空中目標所處的所有狀態S被定義為有限集{s1,s2,…,sn},集合的大小為n,即總共有n種狀態。
(2) 動作空間
紅方空中目標動作集A被定義為有限集{a1,a2,…,ak},集合的大小為k,即紅方空中目標可以執行k種動作。執行動作可以改變環境狀態,A(s) 表示在狀態s下可執行的動作集,很明顯A(s) ?A。通常,紅方空中目標處在一個連續的動作空間,可根據需要簡化為前進、拐彎、返回等。
(3) 轉換函數
轉換函數是在當前狀態st下執行動作at改變為新狀態st+1的概率分布。F(st,at,st+1)表示在狀態st執行at動作最后到達st+1狀態的概率,很明顯0 ≤F(st,at,st+1) ≤1。此外,對于所有狀態s和動作a,,st+1∈S。
(4) 獎勵函數
獎勵函數定義為R:S→R,其表示某一狀態或是在某一狀態執行某一動作的獎勵。智能體從環境中獲取當前狀態st和當前狀態的獎勵rt,根據策略執行動作at,環境返回給智能體執行完動作后的狀態st+1和獎勵rt+1,這就是智能體和戰場環境的一次交互。在空中目標狀態轉換過程中的獎勵由任務完成獎勵、任務區距離獎勵、航向角獎勵等綜合而成。
2.1.2 獎勵函數設計
強化學習的目的是實現獎勵最大化[15]。在空中目標的任務場景來說,獎勵函數由以下部分組成:
(1) 相對距離獎勵
紅方目標距離打擊目標的距離越近,完成任務的可能性越大,其獎勵函數為
式中:λ為距離獎勵系數;d為紅方目標距離任務區域距離。
(2) 視線角獎勵
紅方目標速度和視線角,視線角越小,完成任務的可能性越大,其獎勵函數為
式中:μ為視線角獎勵系數;θ為紅方目標與任務區域的視線角。
(3) 突防概率獎勵
紅方被藍方雷達探測的概率越低,其獎勵越高,其獎勵函數為
式中:p為藍方雷達探測概率。
(4) 抵達任務區的獎勵
紅方主要目的是避開藍方預警及攔截,并成功抵達任務區完成任務。其獎勵函數為
式中:σ為抵達任務區獎勵值,為常量。
在當前狀態st,紅方空中目標執行動作at的獎勵為
根據狀態集和動作集可構建獎勵矩陣:
式中:rij為在狀態si時執行動作aj的獎勵;n為狀態集元素數目;k為動作集元素數目。
2.1.3 訓練實現
可采用蒙特卡羅法、SARSA、Q-Learning 等強化學習算法進行訓練學習[16],得到紅方空中目標智能體的最優策略,根據該策略實現對紅方目標的威脅評估。本文采用Q-Learning 算法。
在設定衰減因子γ和獎勵集合r后,初始化價值矩陣Q,使其為0,價值矩陣Q表示智能體從經驗中學到的知識。在一個episode 中,智能體從任意初始狀態開始,不斷地依概率轉移函數從一個狀態轉到另一個狀態進行探索,直至達到目標,然后進入下一個episode,直至模型收斂。此時,智能體學到了達到目標狀態的最佳路徑。
價值矩陣Q的更新是通過狀態-動作價值函數來實現的[17],其表達式為
式中:折扣因子γ∈[0,1],用來調節長期收益的影響。
利用訓練得到的價值矩陣Q,藍方可以預測紅方目標下一步狀態,再通過對下一步狀態的威脅評估,實現在對抗條件下紅方目標威脅估計。
2.2 威脅評估建模
建立威脅評估模型主要包括建立威脅元素指標,設計評估方法2 個主要部分[18]。
2.2.1 建立威脅評估指標
建立威脅元素指標首要工作是確定并提取威脅影響因素。提取威脅因素,需處理好完整性、準確性和及時性的關系,即需要考慮威脅目標具體情況,確定威脅目標的各項性能,又需要結合戰場實際情況,明確目標運動過程特點,甚至還需考慮紅方行動意圖,搞清其任務目的。
為簡化問題,主要從空中目標作戰意圖、運動狀態、打擊能力、體系能力4 個方面表征目標威脅程度。空中目標作戰意圖一般由目標類型、目標國別、目標任務、出現空域等要素反映;運動狀態一般包括空中目標與打擊目標之間的視線角、相對距離、飛行速度、飛行高度等;打擊能力一般包括其感知能力、生存能力、載荷能力、人員素質等;體系能力一般包括空中目標編隊數量、編隊組成、伴隨保障、情報保障等。具體如圖2 所示。
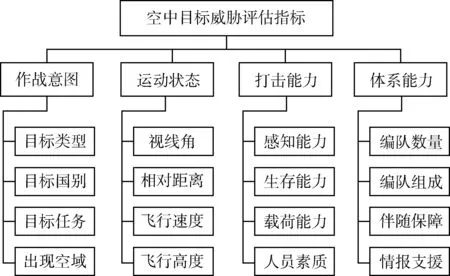
圖2 空中目標威脅評估指標體系Fig. 2 Aerial target threat assessment index
2.2.2 設計威脅評估方法
常用的威脅評估方法較多,本文將威脅評估視為分類問題,通過生成仿真數據,經過專家評估打分及一致性檢驗形成數據集,然后采用GA-BP(genetic algorithm-back propagation)算法進行訓練,使得模型具備威脅評估能力。
BP 網絡是人工神經網絡的一種,由多個神經元組成多層結構的非線性網絡,然后通過大量標記數據訓練,進行調整網絡模型權重和閾值,最終得到自變量與因變量間的擬合函數。雖然BP 網絡擬合能力很強,但在訓練過程中容易陷入局部最優。GA是一種搜索算法,具有很強的全局搜索能力,可用于解決最優化問題。因此,將GA 與BP 網絡相結合形成GA-BP 算法,應用遺傳算法搜尋最優初始網絡權重和閾值,能夠有效提升BP 網絡的擬合效果[19]。
雖然GA-BP算法訓練過程中需要更多次的迭代,但訓練完成后,威脅評估所消耗時間與BP網絡一樣。
3 仿真分析
為驗證本文威脅評估方法的有效性,設計一個紅方空中目標空襲的想定,結合此想定,評估對抗條件下紅方空中目標威脅。
3.1 仿真環境及參數設置
實驗平臺為64 位Windows10 系統,CPU 型號為Intel(R) Core(TM) i7-10700 CPU@2.90 GHz,內存為16 GB,基于Python 語言編程。
GA-BP 算法所用BP 網絡設計為3 層結構:輸入層,隱藏層,輸出層。輸入層神經元個數與威脅指標數目相一致;隱藏層共20 個神經元;輸出層5 個神經元,與威脅程度層級相對應,使用ReLU 激活函數。GA 算法種群規模為40,每個個體長度為BP 網絡所有權值和閾值數目相對應。進化次數為100次,交叉概率為0.4,變異概率為0.05。個體適應度函數為訓練數據預測誤差絕對值之和。
3.2 想定設計
所設計的想定如圖3 所示。紅方出動轟炸機編隊,任務目標是轟炸藍方某港口。藍方在港口部署了防空導彈,其預警與攔截能力范圍由綠圈給出,同時,藍方前出一個海基預警攔截編隊與空基預警攔截編隊,海基預警攔截編隊能力范圍由圖中紅圈給出,空基預警攔截編隊能力范圍由圖中藍圈給出。
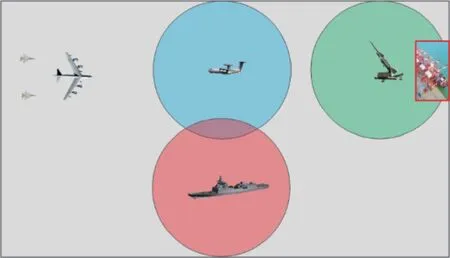
圖3 作戰想定圖示Fig. 3 Operational scenario diagram
為簡化問題,本文將對抗場景抽象成適合強化學習的戰場態勢表示,在其基礎上進行威脅評估。
3.3 過程及分析
以紅方轟炸機空中目標為智能體,建立其狀態空間、動作空間。根據雙方兵力火力、戰場環境及交互關系,將紅方轟炸機目標可能所處的區域抽象成6 種狀態,構建狀態空間{s1,s2,s3,s4,s5,s6},如圖4所示。
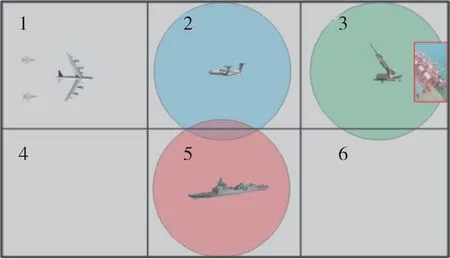
圖4 狀態空間圖示Fig. 4 State space diagram
在狀態空間基礎上,定義動作為“進入某狀態”,形成6 個動作組成的動作集,以動作a3為例,其表示“進入狀態s3”。
將狀態空間及動作空間表示成有向圖的形式,如圖5 所示。狀態為節點,節點3 為目標節點,代表紅方轟炸機空中目標的任務終點s3。動作為邊,部分節點間為雙向邊,表示這2 種狀態間可以相互轉換。

圖5 有向圖圖示Fig. 5 Directed graph
在狀態s下執行動作a定義為等概率事件。然后,根據2.1 節獎勵函數的定義,獎勵函數相關參數設定為:距離獎勵系數λ為50,目標距離任務區域距離d離散化為1,2,3,4,分別表示紅方目標到目標區域所需跨越的區域方格數。視線角獎勵系數μ為50,θ離散化為0,90,分別表示紅方目標與目標區域間的視線角。突防概率獎勵方面,考慮到海基與陸基雷達存在著一定的低空盲區,將海基預警、陸基預警與空基預警的探測概率p分別設為0.75,0.75和1。抵達任務區獎勵值σ為100,后退獎勵為0。經過計算可得R矩陣為
將其表現在有向圖中,如圖6 所示。
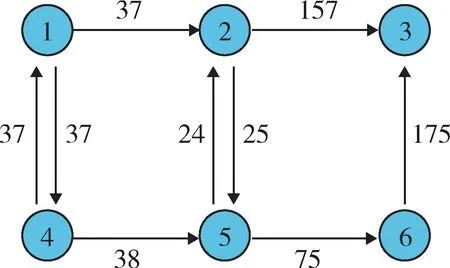
圖6 獎勵值標注Fig. 6 Reward value annotation
經過強化學習訓練,不斷更新,得到最終的Q矩陣:
將其表現在有向圖中,如圖7 所示。
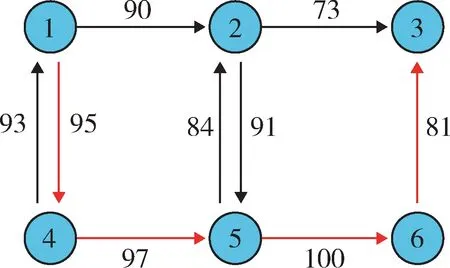
圖7 Q 值標注Fig. 7 Q value annotation
從圖7 中可以看出,紅方目標最優攻擊路線有2條:①從節點1 進入,經過4,5,6 節點,到達節點3 目標節點;②從節點4 進入,經過5,6 節點,抵達節點3目標節點。
一般而言,空中目標在攻擊時將選擇最優攻擊路徑。將紅方目標最優路徑所經過節點時的各項評估指標分別輸入已經訓練好的BP 模型,便可實現對抗條件下紅方空中目標的威脅估計。
將最優路徑所經歷的節點逐個輸入評估模型,可得紅方目標在4,5,6 節點威脅等級分別為3,4,5,在1,2 節點的威脅等級分別為2,3。而在不考慮藍方對抗因素時,紅方目標在4,5,6 節點威脅等級分別為1,3,5,在1,2 節點的威脅等級分別為3,5。相比較而言,考慮了藍方對抗因素的威脅評估結果更符合戰場實際情況,紅方空中目標在防守更薄弱的空域出現時構成的威脅更大。
在考慮藍方策略變化的情況下,只需對紅方空中目標的強化學習模型進行更新,根據藍方策略變化情況更新模型的狀態空間,即可按照上述過程生成相應的應對策略。
4 建議
隨著現代聯合作戰樣式的廣泛實踐,紅藍雙方在多維多域空間的對抗日益激烈。尤其是在信息化、智能化條件下,戰場態勢感知能力得到極大增強,紅方威脅與藍方反制密切相關,威脅評估更多體現為動態過程。對威脅評估概念的理解已不能僅僅局限于某一時刻的威脅,而是要在對紅方能力及意圖分析基礎之上,綜合考慮藍方能力及兵力部署對紅方的影響,開展對抗條件下的威脅評估研究。
4.1 建立知識與數據雙驅動的威脅評估指標體系
在空中目標威脅評估指標選取及體系建立方面,需要考慮眾多影響因素,所選取的評估指標既要具有代表性,還應具有廣泛性,能從不同角度、不同層次體現目標的威脅程度。隨著戰爭樣式的發展,戰場環境日趨復雜,“戰爭迷霧”效應凸顯,爆炸式增長的戰場大數據已給人腦的信息處理能力帶來極大的挑戰,人工選取威脅影響因素并建立指標體系的方法已經難以適應形勢的發展。隨著人工智能技術的發展,深度學習、強化學習等技術為威脅指標體系的構建帶來了極大的促進。人工選取威脅影響因素依賴人的經驗,體現了知識驅動,人工智能較多地依賴歷史數據,體現了數據驅動。如將二者進行有效結合,將極大克服傳統人工構建威脅評估指標體系的不足,增強其合理性。
4.2 開展對抗條件下智能化評估方法的研究
預警防空作戰實踐具有很強的對抗性。在體系作戰框架下,紅方空中目標具有很強的態勢感知能力,對藍方的兵力火力部署及能力變化反應比較敏感,威脅的對抗性體現較為明顯。相比傳統靜態的威脅評估方法,研究對抗條件下的威脅評估問題能夠對威脅的變化趨勢更好地預測,對指導預警防空作戰具有更大現實意義。由于強化學習方法可以通過與環境交互獲得行為指導,在對抗中實現智能體的自主學習,從而在對抗條件下的威脅評估中得以應用。但隨著戰場紅藍雙方對抗的激烈程度提高,戰場態勢變化劇烈,在使用基于經典強化學習的目標威脅評估方法時,存在著目標狀態空間與動作空間進一步擴大,或者為連續空間的情況,從而帶來維數爆炸的問題。深度強化學習技術具有強大的處理復雜、高維環境特征的能力,在該場景的應用中具有廣闊的前景。
4.3 提高威脅評估結果的可解釋性和可信度
人工智能技術的運用,為解決對抗條件下的威脅評估問題帶來契機,但同時也存在著結果可解釋性不強、可信度難評價的問題。此問題的存在,為該技術的應用帶來一定的局限。對于用戶來說,具有高可信度的方法更有利于輔助決策。人工智能技術的可解釋性要從數據采集、算法設計與實施、結果展示等環節入手。方法設計與實施存在著一定的“黑盒”特征,但數據采集與結果展示環節的解釋相對較為容易,解釋越透徹越能增加評估方法的可信度。很多人工智能方法對數據都有很強的依賴性,比如經典機器學習、深度學習等。大規模的、區分度高的、涵蓋問題特征分布的數據集是智能化方法取得較好效果的基礎,其訓練得到的模型具有更強的泛化能力。根據不同方法的特點,從方法實施的不同階段,設計相適應的評價指標,綜合運用各種可視化手段,均能提高可信度,促進用戶對評估方法的理解與運用。
5 結束語
本文提出了一種對抗條件下空中目標威脅評估方法,在建立威脅評估模型的基礎上,根據強化學習的思想,得出紅方目標的最優路徑,并根據最優路徑對目標的下一步威脅進行評估,實現對抗條件下空中目標的威脅評估。經過仿真案例分析,該方法對紅方目標的威脅進行評估更符合戰場實際。但同時,也應看到在使用基于經典強化學習的目標威脅評估方法時,還存在著諸多不足,對此,提出3條建議便于對此類問題的進一步研究。
猜你喜歡
動漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16
兒童故事畫報(2019年5期)2019-05-26 14:26:14
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文周刊·小學一年級版(2016年28期)2017-06-03 00:28:49
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
