語義增強的多視立體視覺方法
2024-03-25 02:04:54王若藍
計算機技術與發(fā)展 2024年3期
韓 燮,王若藍,趙 融
(1.中北大學 大數(shù)據(jù)學院,山西 太原 030051;2.山西省視覺信息處理及智能機器人工程研究中心,山西 太原 030051;3.機器視覺與虛擬現(xiàn)實山西省重點實驗室,山西 太原 030051)
0 引 言
計算機視覺領域的三維重建技術[1-2]已經應用于生活中的各個領域,如自動駕駛、文物修復、虛擬現(xiàn)實、智能家居等。多視立體視覺(Multi-Vision Stereo,MVS)[3]方法作為三維重建技術中的一種,使用人工設計的特征計算立體匹配的代價,聚合代價并進行視差計算和優(yōu)化,得到像素的深度值,實現(xiàn)場景的三維重建,是計算機視覺領域中的經典方法。
傳統(tǒng)的MVS方法主要分為四類,分別是基于點云擴散的MVS方法[4-5]、曲面演化的MVS方法[6]、基于體素的MVS方法[7-8]和基于深度圖的MVS方法[9-10]。
基于點云的MVS方法是將初始的點云生成面片,并對面片迭代地傳播以進行三維重建,難以并行化操作;曲面演化的MVS方法需要對待恢復場景的表面進行猜測,并根據(jù)多視圖之間的光度一致性進行迭代重建表面,易出現(xiàn)離散型錯誤;基于體素的MVS方法將場景空間表示為3D體素,通過標記場景表面的體素以實現(xiàn)重建,占用內存較大,不適用于大場景空間的重建任務;基于深度圖的方法將三維重建分解為多個根據(jù)立體圖像對進行單深度圖估計的小任務,快速靈活并且占用內存較小,適用于海量圖像的大場景重建任務。目前很多優(yōu)秀的MVS方法都是基于深度圖的MVS方法。
隨著深度學習技術在計算機視覺領域中的快速發(fā)展,將深度學習技術與多視立體視覺方法結合以提高重建效果也成為一種趨勢。深度學習技術中的卷積神經網(wǎng)絡[11](Convolutional Neural Networks,CNN)能夠從圖像中抽取高層語義特征,通過學習并利用場景全局語義信息,獲得更穩(wěn)健的匹配和實現(xiàn)更完整的重建。卷積神經網(wǎng)絡在許多基于深度學習技術的MVS方法中展現(xiàn)出了很大的優(yōu)勢。PVAMVSNet(Pyramid Multi-view Stereo Net with Self-adaptive View Aggregation)方法[12]提出了一種有效且高效的多視圖立體網(wǎng)絡,使用基于2D全連接卷積神經網(wǎng)絡的UNet網(wǎng)絡進行特征提取,并在自適應視圖聚合網(wǎng)絡的基礎上,配合多尺度圖像的輸入進行準確和完整的三維重建。TransMVSNet方法[13]對特征提取步驟進行研究,提出了一個基于2D CNN的特征匹配轉換器,利用注意力聚合圖像內和圖像之間的遠程上下文信息,改善了三維重建的效果。CasMVSNet[14](Cascade Cost Volume for High-resolution Multi-view Stereo)在圖像的特征提取階段,使用特征金字塔網(wǎng)絡進行圖像特征的提取,在提取圖像的高級特征的同時,融合了多種不同尺度下的信息,有利于深度值的準確預測。目前,雖然基于深度學習的MVS方法利用卷積神經網(wǎng)絡大大提高了重建效果,取得了巨大的成功,但仍有一定的問題。在卷積神經網(wǎng)絡中,不同層次產生的特征圖的語義特征具有巨大差異。淺層的特征圖語義信息較少,但細節(jié)特征較多,目標位置準確;深層的特征圖語義信息豐富,但目標位置模糊。上述基于深度學習的MVS方法使用卷積神經網(wǎng)絡提取的包含高級語義特征但缺乏低級更精細表示的特征圖構建成本體,忽視了深層特征圖的語義信息缺陷,導致在弱紋理區(qū)域的重建效果較差。
針對上述問題,該文提出使用基于卷積層的長短期記憶神經網(wǎng)絡結構代替普通的CNN提取圖像特征,這有助于在空間上層層抽取圖像的高級特征時,利用長短期記憶神經網(wǎng)絡結構的記憶功能來增強高層特征圖中的低級語義信息,彌補了單純CNN提取的特征圖中低級特征缺失,提高了精細特征的表達,提升了弱紋理區(qū)域的重建效果。
與此同時,許多基于深度學習的主流MVS方法也致力于研究如何讓匹配代價或者深度圖預測更加精確[15-18]。其中,2019年Luo等人[16]設計了匹配置信度模塊,先學習聚合提取的圖像特征的像素級對應信息,再通過匹配置信度模塊對不同采樣平面匹配置信度進行聚合,該模塊可以有效地抑制數(shù)據(jù)的噪聲部分。Fast-MVSNet方法[17]在局部區(qū)域中利用CNN編碼像素之間的深度相關性,產生密集的高分辨深度,并利用高斯牛頓層(Gaussian Newton)對深度進行持續(xù)優(yōu)化。Luo等人又提出了AttMVS(Attention-Aware Deep Neural Network)方法[18],設計了一種新的注意增強匹配置信度模塊,在一般由圖像特征得到的像素級匹配置信度的基礎上加入了局部區(qū)域的上下文信息,逐層次聚合并正則化為概率體,增強了匹配置信度。在上述研究的基礎上,該文提出可見性網(wǎng)絡與紋理特征提取,通過提取紋理特征增加紋理信息,并將源圖像與參考圖像轉換為灰度圖,消除顏色對光照變化的敏感,然后使用CNN計算相似度之后歸一化,通過可見度值區(qū)別可見區(qū)域與不可見區(qū)域,并作用在特征提取網(wǎng)絡中,增強可見區(qū)域的特征,提高3D重建的魯棒性和完整性。
綜上所述,該文在VA-MVSNet方法的基礎上進行改進,主要貢獻體現(xiàn)在以下三個方面:
(1)提出了一種使用ConvLSTM網(wǎng)絡的新型特征提取網(wǎng)絡。在對圖像進行特征提取的同時,通過使用每層的特征圖來預測最終的特征圖,在深層的特征圖語義中豐富缺失的淺層的語義信息,進行穩(wěn)健的全局語義信息聚合。
(2)提出了一種可見性網(wǎng)絡,首先進行灰度圖像的提取,排除光照變化的影響,其次突出可見區(qū)域的特征,并指導特征圖的生成,加深了可見區(qū)域在特征圖中的影響,有助于提高三維重建效果。
(3)對圖像進行紋理特征的提取,增加紋理特征的影響,提升目標場景的三維結構的重建效果。
1 網(wǎng)絡架構
文中方法的整體網(wǎng)絡架構如圖1所示。假設圖像大小為(H×W×3),深度假設的范圍為D,方法的輸入由1個參考圖像和N-1個源圖像構成。該方法在VA-MVSNet方法的基礎上主要通過ConvLSTM語義聚合網(wǎng)絡、可見性網(wǎng)絡和紋理特征提取模塊進行語義特征的提取和增強,之后通過可微單應性變換扭曲到參考圖像的相機視錐內建立3D特征體(H×W×D×C),之后使用VA-MVSNet方法的自適應視圖聚合方法得到代價體,最后使用3D正則化網(wǎng)絡進行深度圖的預測。
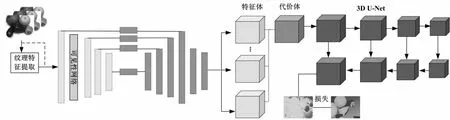
圖1 網(wǎng)絡架構
該方法主要通過在特征提取階段利用語義增強的思想進行改進,即特征提取時的ConvLSTM語義聚合網(wǎng)絡(第1.1節(jié))、可見性網(wǎng)絡(第1.2節(jié))、紋理特征提取模塊(第1.3節(jié)),以增強特征圖中的語義信息,提升三維結構的重建效果。
1.1 ConvLSTM語義聚合網(wǎng)絡
在基于深度學習的多視圖立體重建方法中,特征提取網(wǎng)絡通常由深層卷積神經網(wǎng)絡組成,以提取更抽象的高層語義特征。雖然這些特征更高級、更抽象,但缺少了低層語義信息所具備的優(yōu)勢,過分強調高層特征會影響到細節(jié)語義信息的提取和準確位置的獲取,不利于提升整體三維重建效果。ConvLSTM是一種特殊的循環(huán)神經網(wǎng)絡,可以記憶很久之前的信息,捕捉和學習長期依賴關系,并提取空間特征,非常適合于處理和預測具有長時間間隔和延遲的卷積神經網(wǎng)絡之間的圖像[19]。
因此,該文提出了一個基于ConvLSTM的語義聚合網(wǎng)絡。該網(wǎng)絡利用ConvLSTM的記憶功能和空間相關性提取功能,將高層語義和低層語義聚合,生成特征圖。這樣生成的特征圖,除了具備更高層次的語義信息之外,還具備更低層次的語義信息,避免了普通多層卷積神經網(wǎng)絡的缺點,從而提高了整體場景空間的重建效果。ConvLSTM的內部運行過程如圖2所示。
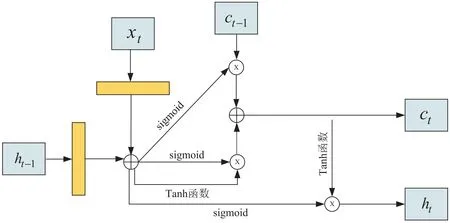
圖2 ConvLSTM內部運行圖
該方法利用ConvLSTM的優(yōu)勢通過疊加多個ConvLSTM層設計了基于ConvLSTM語義在每個時間步上產生的隱藏狀態(tài),可以在這些隱藏狀態(tài)上應用一個卷積層來提取中級特征,然后將這些特征輸入到后續(xù)的層中進行處理,進而增加底層語義信息的權重,如圖3所示。

圖3 ConvLSTM語義聚合網(wǎng)絡圖
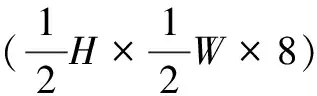
1.2 可見性網(wǎng)絡結構
圖像內容隨著不同視角的變化而有所不同。不同視角可能會產生遮擋,這可能會大大減少圖像中的有用信息,進而影響良好的三維重建效果。此外,顏色對光照變化的敏感性也增加了三維重建的難度。為了克服這些問題,該文提出一種使用灰度圖像以及卷積神經網(wǎng)絡來表達可見性的方法,這有助于增強可見區(qū)域的判別特征,并抑制不可見區(qū)域的影響,從而提高三維重建的效果,如圖4所示。
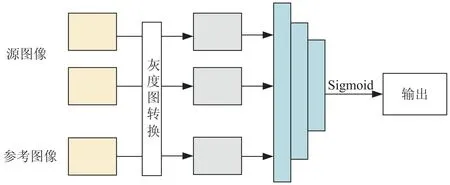
圖4 可見性網(wǎng)絡結構
卷積層的輸出特征圖的通道數(shù)對模型的性能和效果有著重要的影響。首先,較大的輸出通道數(shù)可以增加卷積層的自由度,從而使得模型能夠學習到更多、更復雜的特征,這樣可以提高模型的判別性和泛化能力,使得模型更加適用于復雜的任務。其次,卷積核的輸出通道數(shù)也可以控制特征圖的維度和質量。具體來說,較大的輸出通道數(shù)可以使得特征圖的維度更高,包含更多的特征信息,從而提高模型的表達能力,同時,增加輸出通道數(shù)還可以降低特征圖中的噪聲和冗余信息,使得特征圖的質量更高,進而提高模型的準確率和魯棒性,與此同時,使用權值共享的方式,即對輸入數(shù)據(jù)中的不同位置使用相同的卷積核,從而可以使模型具有平移不變性,能夠識別輸入數(shù)據(jù)中的不同位置的相同特征。
圖5展示了一個3通道的數(shù)據(jù)經過一個大小為3的卷積核作用的過程。
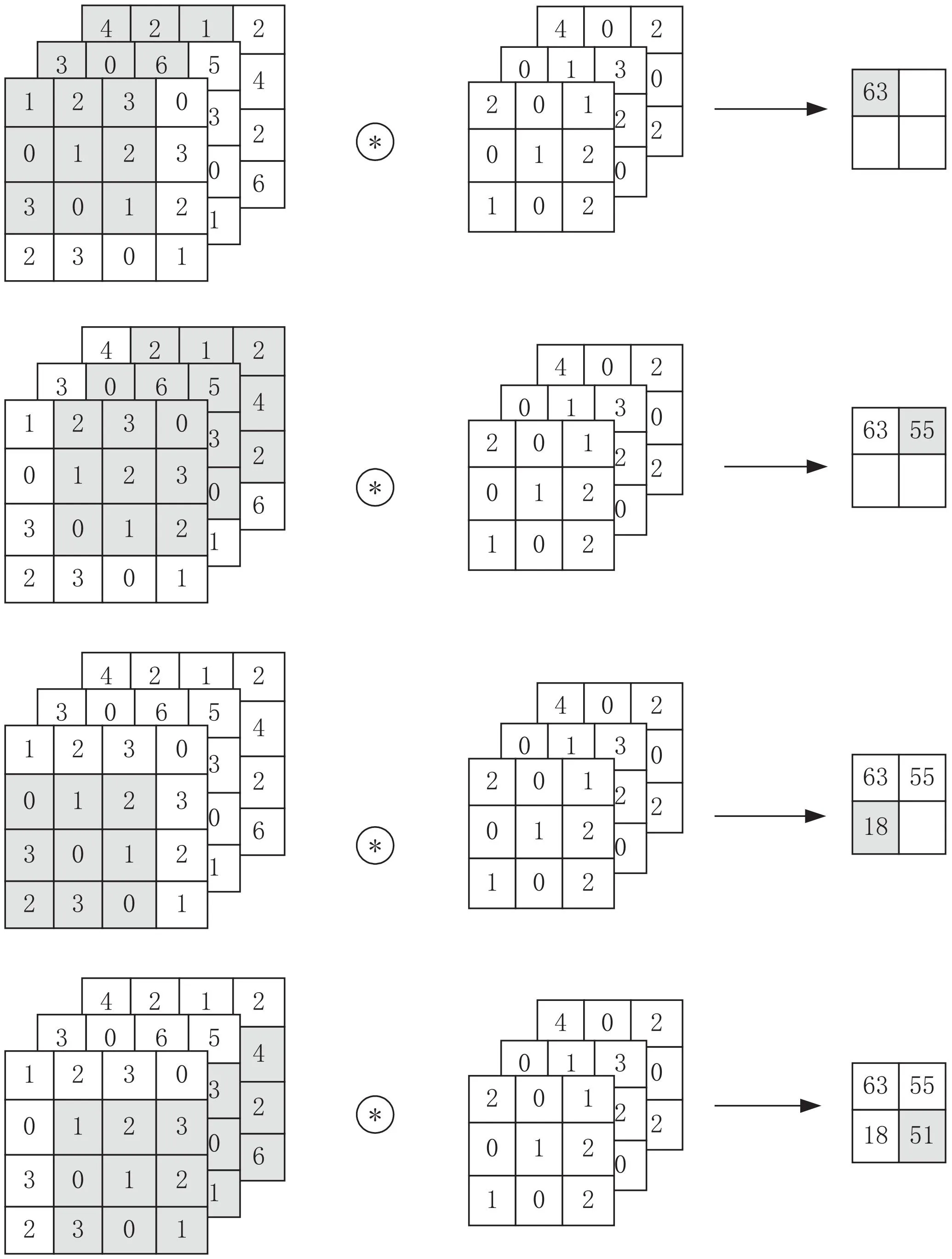
圖5 卷積計算過程
因此,該方法使用PIL庫內的函數(shù)對RGB圖像進行灰度的轉換之后,使用了5層卷積網(wǎng)絡進行提取,通道數(shù)逐漸疊加,卷積核使用(3,1,1)的卷積核,然后經過激活函數(shù)形成可見性度量值并與ConvLSTM語義聚合網(wǎng)絡提取的低級特征相乘,繼續(xù)進行網(wǎng)絡中高級特征的提取。
1.3 紋理特征提取
在特征抽取過程中,該文采用經典的局部二值化模型(Local Binary Pattern,LBP)抽取圖像中的紋理特征,以改善紋理區(qū)域的重構結果,體現(xiàn)圖像中每個像素與局部區(qū)域內像素之間的關系。LBP算法可以使用不同的鄰域半徑和鄰域像素數(shù)量來生成不同尺度的紋理特征。一般來說,LBP算法會計算每個像素的LBP值,并將其與周圍像素的LBP值進行比較,從而得到該像素的紋理特征向量。在實際應用中,可以使用LBP算法提取圖像的紋理特征,并將其作為分類器的輸入,從而實現(xiàn)圖像分類和識別等任務。
該方法使用圓形范圍半徑為1的LBP算子對輸入圖像進行紋理特征的提取,并設置領域像素點的數(shù)量為8,LBP算子如圖6所示。
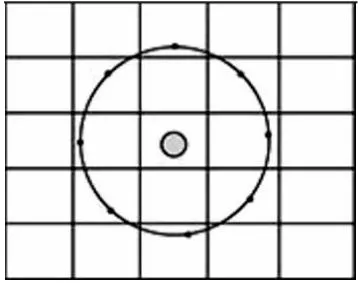
圖6 LBP(8,1)算子
該方法將彩色的三維圖像(H×W×3)轉成灰度圖像,并對灰度圖像進行LBP算子運算,得到對應的LBP特征圖,部分LBP特征圖如圖7所示,然后將LBP特征圖與輸入圖像在通道方向上進行拼接,作為ConvLSTM語義聚合網(wǎng)絡的輸入(H×W×4)。

圖7 LBP特征圖示例
2 實驗結果與分析
該方法在DTU[20]數(shù)據(jù)集上訓練,按照一般的做法,在訓練時,將所輸入圖像的尺寸設定為W×H=640×512,并且設置輸入圖像的數(shù)量為5。深度假設的范圍是425 mm至935 mm,從這個范圍內采樣假定的深度值,深度平面的數(shù)量是192,當前的網(wǎng)絡是在PyTorch上實現(xiàn)的,并且利用Adam進行16個epoch的端到端的訓練,初始的學習速率是0.001,每個epoch衰減是0.9。批量長度設為4。對于測試,該方法在原始輸入圖像分辨率為1 600×1 184的DTU數(shù)據(jù)集上評估,使用7個圖像視圖,D=192進行深度平面掃描,并使用MVSNet方法中使用的訓練損失,如式1所示。對于Tanks and Temples數(shù)據(jù)集[21],輸入圖像的分辨率設置為1 920×1 056。
(1)
其中,D(p)表示預測深度圖,DGT(p)表示真值深度圖。
2.1 實驗環(huán)境
該方法的研究與實驗均在Linux環(huán)境下進行,操作系統(tǒng)是Ubuntu 20.04,使用2塊NVIDIA RTX TITAN的GPU卡進行實驗,具體信息如表1所示。

表1 實驗環(huán)境信息
2.2 數(shù)據(jù)集
DTU數(shù)據(jù)集是一個大規(guī)模的MVS數(shù)據(jù)集,包括49或64個視角,并且提供了真實點云和深度圖,可以將通過實驗得到的預測值與其進行比較。每個視角由一幅圖像和對應的相機參數(shù)組成,圖像的原始尺寸為1 600×1 200像素,包含8位RGB顏色。124個場景中包含80個測試場景。其中,59個場景包含49個攝像機位置,21個場景包含64個攝像機位置。
為了提升MVS方法在大規(guī)模場景重建中的泛化能力,Arno Knapitsch等人提供了Tanks and Temples數(shù)據(jù)集。該數(shù)據(jù)集基準更大,更多樣化,包括完整的大型室外結構以及復雜的室內環(huán)境。這個數(shù)據(jù)集包括兩組不同的場景:中等和高級。中等組包括各種建筑,如雕像、大型車輛和房屋,鏡頭路徑從外向內。該方法選擇中等組場景進行泛化實驗。
2.3 評價指標
點云的準確度、完整度、F-Score等是評價三維重構算法性能的重要指標。在不同的算法或數(shù)據(jù)集下,點云準確度和完整度的度量并不完全一致,F-Score的計算方法也不完全一樣。
(1)準確度(Accuracy)。
假設G為真實點云集,R為預測點云集,對于一個預測點云r∈R,當滿足式2的條件時,對預測點云中的任何點,將被視為與重構點云中的點相匹配的很好:
(2)
其中,λ是與場景有關的被指派給該數(shù)據(jù)組的參數(shù)。將較大的場景設定為較大的數(shù)值。在DTU數(shù)據(jù)集,其準確度并非以百分數(shù)來度量,而以絕對平均數(shù)來度量。平均絕對值愈小,準確度愈小時,則表示該方法的精度愈高,如式3所示。
(3)
(2)完整度(Completeness)。
完整度是指真實點云在重建后的點云中可以匹配的像素點百分比的度量。同準確度一樣,對于一個真實點云r∈R,就會認為對于重建后的點云,該點具有良好的匹配性,如式4所示。
(4)
其中,λ是由數(shù)據(jù)集分配的與場景相關的參數(shù)。對于比較大的場景設置為較大的值。距離的定義與倒角距離定義相同,在DTU數(shù)據(jù)集中,完整度是指真實點云與預測點云之間的相對距離,平均絕對距離越小,認為其準確度越優(yōu)秀,如式5所示。
(5)
(3)F-score。
F-score是衡量多視立體視覺方法性能的重要指標,是對準確度與完整度的調和平均值。在DTU數(shù)據(jù)集中,F-score設置為完整度與準確度兩者的平均數(shù),稱作平均值;在Tanks and Temples數(shù)據(jù)集中,F-score設置為真實點云G與預測點云R之間的差異百分比與預測點云R與實際點云G之間的差異百分比的調和平均值,值越高,表明該方法的性能越優(yōu)秀。
對于一個預測點云r∈R,它到真實點云的距離定義如式6所示,則設預測點云R與實際點云G之間的差異小于某一特定閾值d的比例為P(d),如式7所示。
(6)
(7)
同樣,對于一個真實點云g∈G,它到預測點云的距離定義如式8所示,則真實點云G與預測點云之間差異程度的指標可以用式9所示。
(8)
(9)
則F-score的計算公式如式10所示。
(10)
2.4 結果分析
該方法在DTU數(shù)據(jù)集的定量結果如表2所示,定性結果如圖8、圖9所示。
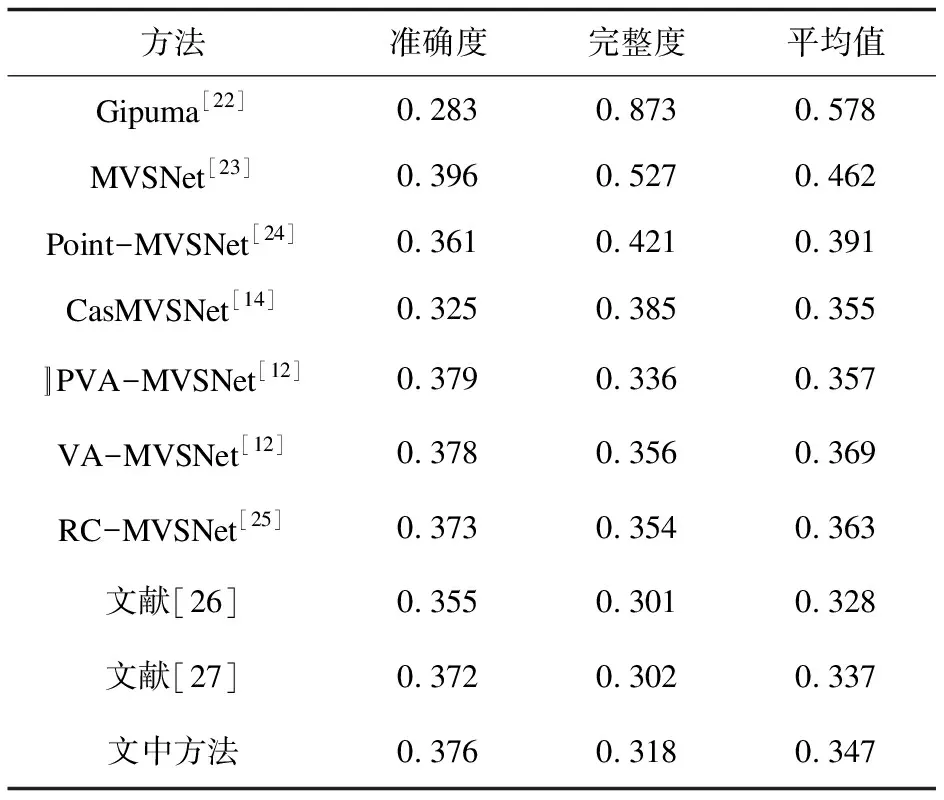
表2 DTU數(shù)據(jù)集指標結果對比

圖8 點云結果對比

圖9 局限性展示
由表2可知,該方法在完整度上面表現(xiàn)不錯,比VA-MVSNet方法提高了0.038,同時實現(xiàn)了具有競爭力的整體性能,但通過與一些經典的方法以及先進方法的比較,還有所差距,與基礎網(wǎng)絡性能以及所用方法有關,還需進一步改善與提高。
除了在重建的三維點云模型上的定量比較,圖8、圖9展示了文中方法與其他先進方法的定性比較。
得益于集成了高層語義特征信息和低層語義特征信息以及多尺度特征信息的ConvLSTM語義聚合網(wǎng)絡,該方法能夠為弱紋理區(qū)域估計更完整和更精細的空間表面。由圖8可看出,該方法在精細結構處的重建效果更好,驗證了該方法的有效性,但是由圖9也可以看出,該方法也具有一定的局限性,重建的精準度不足,重建場景模糊。
與此同時,該文使用在DTU數(shù)據(jù)集上訓練好的參數(shù)模型在Tanks and Temples數(shù)據(jù)集的中級數(shù)據(jù)集上進行泛化能力的驗證。由表3的數(shù)據(jù)對比可以看出,該方法在一些場景如Family,Francis,Light-house,Panther上的重建結果較好,具有一定的泛化能力,在其他場景泛化能力不足,可以分析得到其他方法如PVA-MVSNet方法結合多尺度信息進行三維重建是有可取之處的。
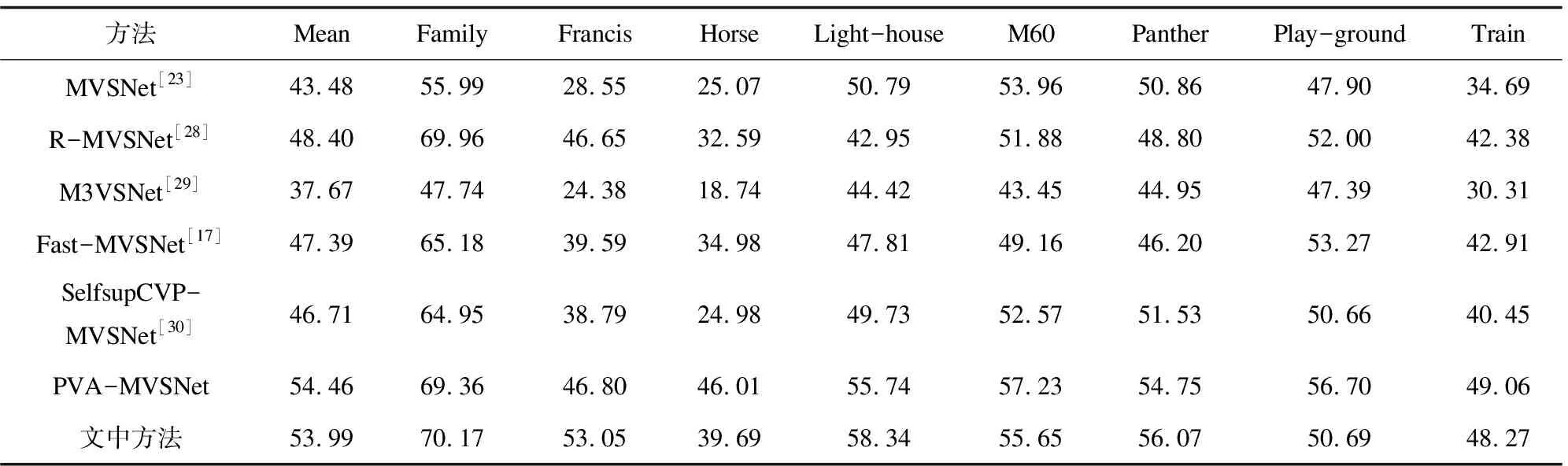
表3 Tanks and Temples數(shù)據(jù)集指標結果對比
除此之外,在本節(jié)中,進行消融實驗來定量分析該方法中關鍵組件的優(yōu)勢和有效性。對于以下所有研究,均在DTU數(shù)據(jù)集上進行實驗和評估,并使用準確性和完整性衡量重建質量。
本節(jié)比較了ConvLSTM語義聚合網(wǎng)絡、可見性網(wǎng)絡以及紋理特征提取的有效性。定量結果如表4所示。由表4可知,ConvLSTM語義聚合網(wǎng)絡、可見性網(wǎng)絡都可以顯著提高重建標準的結果,并且互補,以取得最佳效果。
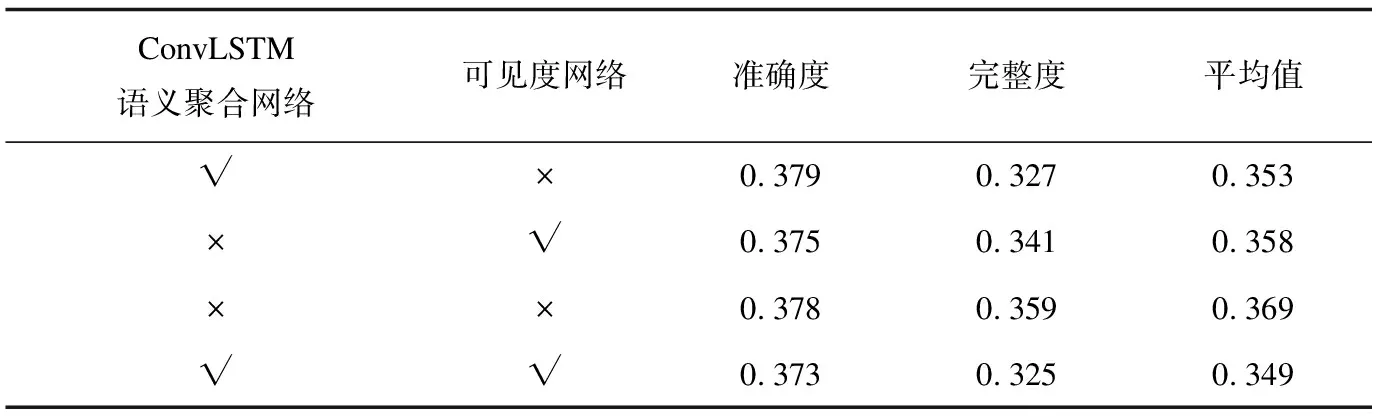
表4 不同組件的消融實驗在DTU數(shù)據(jù)集的結果
3 結束語
該文提出了一種具有語義增強功能的多視立體視覺方法。該方法通過使用ConvLSTM語義聚合網(wǎng)絡增強高層特征圖中的低層語義信息,增強了細節(jié)語義特征以及多尺度語義信息,利于弱紋理區(qū)域的重建,同時通過紋理特征提取模塊提取圖像的紋理特征,加深了紋理語義信息在高層特征圖的影響,提升了三維重建的整體效果,有效地提高了低紋理表面的性能,這兩個模塊是輕量級、有效和互補的。除此之外,提出了一種可見性網(wǎng)絡,一定程度上排除了光照變化的影響,突出了可見區(qū)域的特征,加深了可見區(qū)域在特征圖中的影響,有助于提高三維重建效果。在DTU數(shù)據(jù)集和Tanks and Temples數(shù)據(jù)集上的實驗,證實了該方法的合理性和有效性。
后續(xù)的工作將考慮不同層次的語義特征與匹配成本體之間的關系,進一步研究不同語義特征對于匹配代價的影響,以更準確地進行代價匹配。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫(yī)學工程學報(2017年6期)2017-02-10 05:11:45
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
河南科技(2014年23期)2014-02-27 14:19:15
