基于多維度并聯卷積神經網絡與質譜數據的芬太尼分類模型研究
2024-04-22 10:48:48薛凌云劉亦安
杭州電子科技大學學報(自然科學版) 2024年1期
唐 龍,薛凌云,徐 平,劉亦安
(杭州電子科技大學自動化學院,浙江 杭州 310018)
0 引 言
過去7年,由于北美非法制造芬太尼和芬太尼類似物導致的阿片類藥物過量死亡人數增加[1],導致國際社會對這些物質更廣泛地擴展到非法藥物市場感到擔憂[2]。在美國[3]和加拿大[4]的許多地區非法芬太尼在很大程度上取代了海洛因作為主要阿片類藥物使用。有效阻止這一問題的主要方法是提高現有的檢測和處理芬太尼及其類似物[5]的能力。通常,研究人員通過傳感技術[6]采集未知物質的光譜,如紅外光譜[7],拉曼光譜[8]和質譜[9]。質譜方法不僅可以用于芬太尼及其衍生物檢測[10-13],還可以分離多組混合物,便于混合樣品中的芬太尼檢測。綜上所述,我們選擇利用質譜數據進行芬太尼的分類。
近些年來,學者對芬太尼類似物的分類技術進行了研究。主成分分析(PCA)[14]被用來降低芬太尼類似物的質譜維度,然后分層聚類算法被用于識別芬太尼類似物[15]。當總類別已知時,可用于芬太尼類似物的分類和定性分析。近年來,基于相似性度量的光譜庫搜索方法被應用于芬太尼類似物的分類[16-19],其中基于孿生網絡和質譜庫搜索的方法可以獲得最佳的分類性能[19]。盡管基于孿生網絡和質譜庫搜索的方法可以在芬太尼類似物之間上獲得相對較好的分類性能,但在非芬太尼類似物和芬太尼類似物上效果不佳。而區分非芬太尼類似物和芬太尼類似物是阻礙毒品傳播的有效途徑。一種基于峰值和基于相似度特征提取方法被用來芬太尼分類,并且實現了99%的檢測概率[20]。但由于手動提取特征需要大量的領域知識,這是一個繁瑣,費時又易出錯的過程。因此,應開發更有效的模型來分類。而深度學習方法不僅無需手工參與,而且可以提取更深層次、更為抽象的特征。但是在芬太尼分類領域僅發現基于孿生網絡和質譜庫搜索的方法利用深度學習的方法[19],而該方法用于解決小樣本的分類問題。因此我們嘗試將新的深度學習方法應用于芬太尼分類,從而達到更好的分類效果。
目前,質譜數據分析方法主要包括經典的庫匹配[21]、遺傳算法[22]、卡方檢驗[23]、主成分分析(PCA)[24]、人工神經網絡[25]和支持向量機(SVM[26])。還有一些組合方法[27],如PCA和SVM、小波和神經網絡、VAE和全連接網絡。隨著近幾年深度學習的快速發展,神經網絡已經被廣泛應用到質譜領域,特別是在質譜用于癌癥分類[28-30]的領域中已經有了大量使用深度學習的例子。Qiang Hu等人中提出一種將質譜的一維譜圖拼接為二維圖像的方式,并且利用卷積神經網絡進行特征提取[30]。該方法可以更有效地識別具有相似質譜的化合物[30]。目前,深度卷積網絡在圖像領域已得到廣泛應用,學者先后提出GoogLeNet、ResNet、MobileNet等深度學習網絡模型。
在本文數據集中非芬太尼類物質樣本數量是芬太尼類物質的18倍,數據分布不均衡。而經樣本分布不均衡集訓練的分類器,判別結果可能會偏向數量多的類別。導致傳統的分類方法在芬太尼數據中分類效果不佳,分類敏感性很差,分類準確度較低。
基于上述討論,本文提出了一種高效的芬太尼質譜分類模型。在模型中使用一種特殊的卷積特征提取模塊(Fusion模塊)。它可以增強網絡對不同特征尺寸的適應性,來提高模型的分類性能。該模型將一維原始數據與拼接圖像數據輸入到并行二維卷積層和一維卷積層進行特征提取,來避免圖片拼接時丟失的一維空間信息。最終通過特征融合的手段將上述并行網絡的特征融合進行分類。該模型利用Focal loss[25]損失函數作為損失函數來解決樣本不均衡問題。
1 方法
1.1 基于多維度并聯卷積神經網絡與質譜數據的芬太尼分類模型
基于多維度并聯卷積神經網絡模型結構如圖1所示:

(a)一維卷積神經網絡;(b)二維改進神經網絡
圖1所示為基于多維度并聯卷積神經網絡模型的整體結構,該網絡左邊部分為一維卷積神經網絡,右邊為二維改進卷積神經網絡。二維改進神經網絡由兩串聯Fusion模塊組成。該結構既能保證對增強為二維圖像數據的處理,又能對保留原始空間結構的一維數據進行處理。因此該網絡包含更多的特征信息,從而提高分類精度。
由于Sigmoid是使用范圍最廣的一類激活函數,具有指數函數形狀,它在物理意義上最接近生物神經元,輸出層激活函數采用公式(1)中Sigmoid。優化器采用隨機梯度下降(SGD)。在公開數據集中NIST05,正負樣本的分布是不平衡的。普通的損失函數,均方損失方法對于稀疏和不平衡的質譜數據,并沒有取得很好的分類效果。此外,一些難分樣本,如異構體很難區分。考慮到Focal loss對解決目標檢測中的極端不平衡問題是有效的[31],因此引入公式(2)中的Focal loss作為目標函數來解決樣本不均衡問題。
(1)
其中x為輸入。
Fcalloss=-α(1-pt)γlog(pt)
(2)
其中權重α平衡正樣本和負樣本,pt是一個樣本的模型的估計概率,γ是一個調制因子,γ越大,簡單樣本損失的貢獻會越低。對于兩個超參數,通常來講,當γ增大時,α應當適當減小。實驗中γ取2、α取0.25時效果最好。
1.2 一維卷積神經網絡

(3)巨量淤泥的出路令項目實施單位感到棘手。河道清淤工程中,采用堆場把淤泥堆放在指定的位置等其自然干燥是目前主要的處理方式,但堆場存放會占用大量土地資源,且巨量淤泥長年累月堆放處置不現實。同時,這些堆場的淤泥水分難以蒸發,只在表面形成一層硬殼,形成沼澤地。

圖2 一維卷積運算示意圖
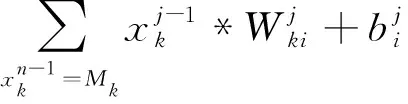
(3)
1.3 數據預處理
其中阿芬太尼、卡芬太尼、芬太尼、瑞芬太尼和舒芬太尼的質譜被選作參考譜。因為這五種化合物是因為它們廣為人知,而且存在大多數參考庫中[20]。在質譜庫檢索中Qiang Hu等人提出了一種譜圖拼接的方法,取得很好的分類效果[30]。此研究借鑒這種拼接方式對質譜進行數據增強。
如圖3所示,每個質譜數據分為20段,每個段長度為40。將查詢樣本譜圖和經典參考譜圖的每段譜段按順序堆放。將樣本對堆放成40×40的矩陣。拼接操作如圖3所示。質譜數據經上述操作之后可以作為輸入,利用二維卷積神經網絡進行分類。

圖3 拼接操作
1.4 Fusion模塊
本文提出的Fusion模型共有9層,深度為7,模型結構如圖4所示。傳統Inception結構的優勢在于利用1×1卷積進行降維操作,并結合不同尺寸小卷積操作與池化操作達到獲取不同感受野特征信息、減少參數量的目的。然而由于使用了大量1×1卷積,導致大量不必要的冗余參數產生。針對以上情況,本文提出的Fusion模型結構,將5個通道共用一層1×1卷積來降低參數。由于質譜數據比較稀疏,所以我們利用1×1卷積將5個通道數據通過線性組合壓縮到1個通道,來降低參數量。最大池化層(Max Pooling)可以保留主要的特征的同時減少參數和計算量,并且防止過擬合,提高模型的泛化能力。由于訓練中會存在梯度消失的問題,采用縮放指數線性單元(SeLU)作為激活函數。根據該激活函數得到的網絡具有自歸一化功能,從而避免了梯度爆炸和梯度消失。SeLU公式為

圖4 Fusion模型結構
SeLU(x)=scale×(max(0,x)+min(0,α×(ex-1)))
(4)
其中scale=1.050 700,α=1.673 26,x為輸入。
2 實驗與討論
2.1 實驗數據
從美國國家標準與技術研究所(使用NIST05 MS搜索演示軟件分發的庫集合)和繳獲藥物科學工作組獲得了3718個EI質譜,網站:https://www.swgdrug.org/ms.htm。這一組質譜數據中包括195芬太尼的類似物的質譜,如芬太尼、卡芬太尼、和舒芬太尼,并且獲得了3523個非芬太尼物質。本文中將每個質譜數據強度值歸一化,使每個光譜中單個峰的最大強度為1000。處理后的質譜數據如圖5所示,質譜特征比較稀疏。歸一化公式如下:
(5)

(a)為芬太尼質譜圖;(b)為非芬太尼質譜圖。
其中I代表維質譜強度,x代表維度,I*表示歸一化后的強度。
對數據進行利用主成分分析進行二維可視化如圖6所示,樣本之間的距離越遠,說明其組間的代謝產物的差距越大。從圖6中可以直觀看出樣本之間混疊嚴重,說明其組間的質譜特征不明顯。

圖6 芬太尼與非芬太尼物質數據進行行主成分分析2D
圖6中黃色的點代表芬太尼及其類似物的樣本,紫色的點代表非芬太尼及其類似物。
2.2 實驗數據劃分

表1 加入參譜圖的數據劃分

表2 不加入參譜圖的數據劃分
其中阿芬太尼、卡芬太尼、芬太尼、瑞芬太尼和舒芬太尼的質譜被選作參考譜。因為這五種化合物是因為它們廣為人知,而且存在大多數參考庫中。
2.3 實驗設計
實驗總體方案如下:
實驗1:將原始一維質譜作為輸入,利用傳統機器學習算法中的線性判別算法(LDA)、主成分分析(PCA)+支持向量機(SVM)和遺傳算法(Ga)+支持向量機(SVM),以及深度學習算法中一維卷積神經網絡進行分類。將原始一維質譜和5條參考譜圖一起作為輸入,輸入到一維卷積的6個通道中,利用一維卷積神經網絡進行分類。
實驗2:將原始一維質譜與參考譜圖拼接后的二維圖像數據作為輸入,利用我們改進的卷積神經網絡(兩串聯Fusion模塊)進行分類。并且與深度學習算法中殘差神經網絡(Resnet-18)和移動網絡(MobileNet V1)進行對比。
實驗3:將原始一維質譜以及拼接后的二維圖像數據作為輸入,利用本文提出的基于多維度并聯卷積神經網絡模型進行分類。
2.4 實驗環境
實驗環境:PyTorch深度學習開發框架,采用Python作為開發語言。實驗采用的CPU為Intel酷睿i7-9700F,GPU為單個NVIDIA GeForce RTX 2080。在訓練過程中選用隨機梯度下降(SGD)作為優化器,batch size設置為1,初始學習率設定為0.0025,epoch為100。
2.5 實驗評價指標
為了評估分類方法的有效性,由于數據集不平衡,我們使用了3個評價指標。分別為準確性、敏感性和特異性的評價標準分別定義如下:

(6)

(7)
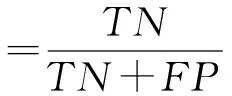
(8)
其中TP:被模型預測為正類的正樣本;TN:被模型預測為負類的負樣本;FP:被模型預測為正類的負樣本;FN:被模型預測為負類的正樣本。
2.6 實驗結果
將原始一維質譜為輸入進行分類,在傳統機器學習模型中,PCA+SCM模型分類精度最高,高達97.96%。一維卷積神經網絡的分類精度98.60%。而將原始一維質譜和5條參考譜圖一起作為輸入,利用一維卷積神經網絡進行分類,分類精度高達98.60%。在加入參考譜圖后一維卷積神經網絡的分類精度為99.38%,提升了0.78%.將原始一維質譜與參考譜圖拼接后的二維圖像數據作為輸入,Resnet-18、MobileNet V1和二維改進神經網絡的分類精度分別是99.38%、99.41%和99.43%。將原始一維質譜以及拼接后的二維圖像數據作為輸入,利用本文提出的基于多維度并聯卷積神經網絡模型進行分類,分類精度為99.73%。
2.7 討論
由表3可以看出,實驗一中深度學習算法分類精度比傳統機器算法的分類精度要高。在加入參考譜圖后一維卷積網絡的分類精度得到了提升,說明加入參考譜圖有利于提高網絡的分類性能。實驗2中的分類精度高于實驗1中的分類精度,可以得出結論,將一維譜圖拼接成二維圖像數據,是一種可行的轉換手段。其中二維改進神經網絡取得了與最好分類精度,充分體現了Fusion模塊具有功能強大的優勢。實驗3中基于多維度并聯卷積神經網絡模型分類精度達到了99.73%,優于其他分類方法。由此可知基于多維度并聯卷積神經網絡模型結構的對提升芬太尼數據分類準確的具有一定效果。

表3 實驗分類結果
3 結束語
本文針對傳統分類方法對該數據集分類準確度不高的問題,提出了基于多維度并聯卷積神經網絡,提高了芬太尼數據分類靈敏度和準確度。結果顯示該方法的分類性能優于許多已有的分類方法。不同于手動提取特征的傳統分類方法,該方法能夠自動提取特征,不僅為芬太尼分類提供了新的思路,甚至可以用于對蛋白組學和代謝組學的質譜數據分類中。本文方法在深度學習分類器的訓練上需要花費較長時間,網絡的結構也較為復雜,因此對于優化模型參數,加快模型訓練速度,還需進一步的研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
