一種結合神經網絡和敏感位置語義的軌跡隱私保護方法
2024-04-22 02:41:02梁陽罡申自浩劉沛騫
小型微型計算機系統 2024年4期
張 俊,梁陽罡,申自浩,王 輝,劉沛騫
1(河南理工大學 計算機科學與技術學院,河南 焦作 454000) 2(河南理工大學 軟件學院,河南 焦作 454000)
0 引 言
隨著基于位置服務和位置感知設備的廣泛發展,產生了大量的軌跡數據.這些數據可以幫助研究人員開展一系列的研究,例如:興趣點推薦[1]、船舶軌跡預測[2]等.
軌跡數據包含了大量的敏感信息,如果這些數據在沒有保護或處理不當的情況下直接發布,會引起嚴重的隱私泄露問題.惡意的攻擊者通過數據分析和挖掘的技術手段獲取用戶的敏感信息,包含用戶的生活習慣、家庭住址和職業信息等.
近年來,為了保護用戶的身份信息或敏感位置,Sweeney[3]提出了使用k-anonymity的方法,確保數據庫中的每個數據無法與其他k-1條數據區分開來.為了抵抗具有背景知識的攻擊者,Dwork[4]提出了差分隱私技術(Differential Privacy,DP)用于保護數據隱私.吳云乘等[5]提出了基于時空關聯性的差分隱私保護方法.冀亞麗等[6]提出了基于時空和群體特征的興趣區域的構建方法,根據訪問頻率對用戶的地方進行處理.
盡管現有的隱私保護方法在保護用戶敏感信息方面做出了很大的貢獻,但大多數研究人員考慮的是敏感位置或敏感區域等,他們中的大多數沒有考慮到位置語義特征所代表的含義,位置語義特征的外在表現是用戶的日常行為模式.一般來說,位置語義信息(Location Semantic Information,LSI)是通過停留點來體現的.停留點則是由用戶在一定范圍內長時間的停留而形成的,因此停留點表示的是用戶的日常活動等敏感信息,而這些信息可以用LSI代替.從敏感度的角度來說,使用位置語義敏感度代替位置敏感度.下文將“位置語義敏感度”簡稱為“語義敏感度”,“位置語義”簡稱為“語義”.
此外,Yuan等[7]提出了對敏感位置分級的策略,如果某個位置對用戶不敏感或敏感度低,但是從全局的角度(軌跡數據庫)考慮,假如該位置擁有極高的敏感度,那么該方法對類似這樣的位置在處理方面存在一定的局限性.Li等[8]提出了基于語義的敏感等級構建方法,但該方法并不適用于軌跡數據發布的隱私保護場景.
為了保護用戶的敏感位置語義,本文提出了一種結合神經網絡和敏感位置語義的軌跡隱私保護方法TP-SLS.首先,分別從局部(個人軌跡數據)和全局(所有用戶的軌跡數據)的角度考慮,提出了敏感度感知模型(Sensitivity Awareness Model,SAM),用于量化語義敏感度.然后,為了干擾用戶的敏感位置,本文構建了基于空間坐標、時間和語義敏感度的用戶構建敏感移動場景,并使用差分隱私技術干擾.最后,考慮到預測的軌跡可能存在廢數據,提出了基于強化學習和多屬性決策的軌跡優化方法.本文使用了一個真實的數據集評估了TP-SLS.實驗結果證明,TP-SLS在隱私保護強度和數據可用性兩個方面優于現有的方案.
1 相關工作
Xu等[9]提出了一種DP-LTOD的方法.他們使用聚類算法將具有相同興趣愛好的用戶劃劃分為同一個社區,然后使用啟發式軌跡混淆算法從原始軌跡中選擇最小差異的軌跡,最后使用DP技術平衡隱私保護和數據效用強度.Chen等[10]提出了一種DP-QIC的數據發布機制.該機制的核心是使用DP混淆相關屬性,通過挖掘敏感屬性與QI之間的潛在關系抵御攻擊.Chen等[11]提出了一種基于循環神經網絡和DP的方法.該方法基于原始軌跡,對速度屬性添加DP噪聲干擾,通過循環神經網絡生成新軌跡;最后,對新軌跡進行判別和處理,完成軌跡數據的發布.Qu等[12]提出了一種以GAN為驅動的個性化隱私保護方案.該方案為了解決由GAN引起的不可預知的隨機性問題,設計了一個P-GAN的模型.首先,將用戶按社區分類,按照社區邊緣的密度劃分出不同的親密度;然后,設計一個QoS函數,將親密度與隱私保護級別相關聯;最后,構造一個DP識別器用于擴展GAN,實現數據效用,滿足個性化的隱私保護需求.
綜上所述,現有的隱私保護機制一定程度上滿足了不同的隱私保護需求,但大多數沒有考慮到語義信息,并且沒有很清晰的描述出語義的敏感度問題.基于此,TP-SLS考慮到了語義敏感度的問題且構造一個SAM模型用于量化語義敏感度權重.與以往工作不同的是,本文沒有使用速度或者語義屬性構建移動場景.而是基于語義敏感度,構建了敏感移動場景,并且使用差分隱私進行干擾.最后,使用神經網絡技術的優勢,提出了一種將神經網絡和敏感位置語義相結合的軌跡隱私保護方法.
2 預備知識
2.1 Transformer network
Transformer network[13]是一個編碼器-解碼器結構和僅依賴于自注意力的多層堆棧模型.它的每一層都是一個由點積組成的自回歸模型的多頭自注意力機制,可以表示為:
(1)

2.2 深度Q網絡
在人工智能領域中,強化學習(Reinforcement Learning,RL)是一個重要的分支.RL的核心是智能體與環境的交互,這個過程使用馬爾科夫決策過程(Markov Decision Process,MDP)來表示.五元
Q-learning是強化學習的主要算法之一.但如果動作和狀態空間的維度復雜性很高時,由于Q-table(一個存儲動作和狀態的表格)的限制,使得Q-learning無法或難以完成復雜的任務.為了解決復雜任務的應用場景,Mnih等[14]提出了一種基于神經網絡的方法用于估計Q函數(期望獎勵函數,Q表示一個動作的期望獎勵),即深度Q網絡(Deep Q Network,DQN).DQN包含了兩個神經網絡,分別是估計值網絡和目標值網絡.估計值網絡和目標網絡的輸出分別是Q估計值和Q目標值,DQN的目的是確保這兩個值盡可能的接近.這個過程可以用一個損失函數表示.
Loss(θ)=E[(Qtarget-Q(st,at;θ))2]
(2)
其中Q(st,at;θ)表示時刻t的Q估計值,θ表示網絡參數,Qtarget是目標值,為:
Qtarget=r+λmaxat+1Q(st+1,at+1;θ)
(3)
其中,r表示獎勵值,Q(st+1,at+1;θ)表示時刻t+1的Q估計值.
2.3 相關定義
定義1.(ε-差分隱私)對于兩個數據庫D1和D2,如果它們之間最多存在一個數據差異,D1是較大的數據庫,D2是較小的數據庫,那么可以說D1和D2是相鄰數據庫.如果存在一個隨機算法L,使得相鄰數據庫的輸出結果Q滿足:
Pr[L(D1)∈Q]≤oε×Pr[L(D2)∈Q]
(4)
那么可以說滿足ε-差分隱私,ε是差分隱私參數.其中,Pr表示概率,o表示自然常數.
定義2.(靈敏度)對于任意一個查詢函數f,ff∈F(D)屬于實數集,f的靈敏度Qf定義為:
(5)
其中‖·‖1表示曼哈頓距離.
定義3.(拉普拉斯機制)拉普拉斯機制是目前最常見的處理機制,通過在查詢結果中加入符合拉普拉斯分布的噪聲η保護數據的安全,可以表示為:
(6)
其中λ是噪聲參數.
定義4.(語義點)語義點p是一個三元組,p=(lat,lon,ls),其中lat和lon表示空間坐標,如WGS84坐標參考系統中的緯度(lat)和經度(lon),ls表示語義(語義是興趣點(point-of-interest,POI)的描述,可以通過LBS數據庫查詢).
在本文中,ls表示的是“小語義”,例如一個POI的語義描述是“食品、快餐店、肯德基”,語義描述級別從大到小,表示的是“肯德基”.
定義5.(語義軌跡數據庫)語義軌跡數據庫Dls={Tls1,Tls2,…,Tlsu}是特定類型的時空數據庫,表示所有用戶在一個固定空間內的連續變化.其中,Tls=p1,p2,…,pn,pi表示語義點.
定義6.(個人語義敏感權重)個人語義敏感權重表示用戶與語義的親密程度,記為γ,個人語義敏感權重集合ST表示為:
ST={(ls1,γ1),(ls2,γ2),…,(lsq,γq),Ui}
(7)
其中Ui是用戶標識.特別說明的是,如果某個語義不在集合ST中,它的語義敏感度權重等于0.
3 TP-SLS方法
TP-SLS利用DP干擾語義敏感權重,使用神經網絡處理時間序列軌跡數據.TP-SLS如圖1所示,分為4個步驟:
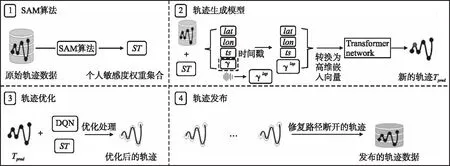
圖1 TP-SLS體系結構Fig.1 TP-SLS architecture
步驟1.基于語義軌跡數據庫Dls,提出了一個敏感度感知算法SAM量化語義敏感權重.
步驟2.將添加噪聲后的語義敏感度權重引入軌跡數據中,并使用Transformer network訓練一個軌跡預測模型.
步驟3.引入DQN優化預測的軌跡數據.
步驟4.修復由于停留點的變更而導致的路徑不相連,完成軌跡數據的發布.
3.1 SAM算法
SAM算法的目的是量化語義敏感度權重,為構建用戶的語義敏感移動場景和優化軌跡提供數據支撐.SAM由3個算法構成,分別是語義訪問頻率分級算法(Semantics access frequency classification algorithm,SAFC)、異常值感知算法(Outliers-aware algorithm,OLA)和語義敏感度權重分配算法(semantics sensitivity weight allocation algorithm,SSWA).其中,SAFC算法基于個人軌跡數據庫初始化個人語義敏感度公式,OLA算法用于解決SAFC算法無法處理的全局(軌跡數據庫)語義敏感度問題,SSWA算法將OLA算法和SAFC算法結合起來,得到一個全新的語義敏感度公式,并計算語義敏感度權重.
3.1.1 SAFC算法
SAFC算法的核心思想是將訪問停留點的頻率,轉換為訪問語義的頻率.然后,利用聚類算法將頻率相近的語義聚類,根據頻率分級.最后,初始化語義敏感度公式.處理過程為:
步驟1.從用戶軌跡數據中提取停留點的頻率,并對語義相同的停留點的訪問頻率fr做累加計算處理.用戶的語義頻率如式(8)所示:
LS={(ls1,fr1),(ls2,fr2),…,(lsq,frq),Ui}
(8)
步驟2.令樣本z=(ls,fr),樣本空間Z=(z1,z2,…,zq).對相似頻率的樣本數據分割,用光譜聚類算法將Z分為κ個子集,記為C=(c1,c2,…,cκ).
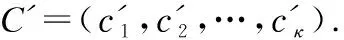
步驟4.基于C′劃分語義敏感度級別.存在映射函數f1和f2如式(9)和式(10)所示:
(9)
f2:(δ1,δ2,…,δκ)→(1,2,…,κ)
(10)
令sn表示c′的語義數量.同一個敏感度級別中的語義敏感度權重相同,將敏感度權重記為γ.那么,δ1的權重是γ1,δ2的權重是γ2,δκ的權重是γκ.粗糙語義敏感度權重公式STr表示為:
sn1·γ1+sn2·γ2+…+snκ·γκ
(11)
其中,γ1>γ2>…>γκ.
算法1描述了SAFC算法.
算法1.語義訪問頻率分級算法(SAFC)
輸入:Tls
輸出:STr
1.從Tls中提取所有的語義并去重,存儲到Fls
2.forlsinFlsdo
3. 初始化Γ=0
4. forpinTlsdo
5. 獲取p的語義ls′
6. ifls=ls′ then
7. Γ←Γ+1
8. end if
9. end for
10.將(ls,Γ)保存到LS
11.end for
12.LS轉換為Z
13.Z轉換為矩陣并使用Spectral Clustering算法得到C
14.計算C中每一個簇的中位數并排序得到C′
15.使用映射函數f1和f2并根據權重映射得到粗糙語義敏感度公式STr
16.returnSTr
3.1.2 OLA算法
一般而言,用戶訪問一個POI的頻率越高,說明用戶對這個POI的敏感度越高.但是訪問頻率低的POI語義,它的敏感度也可能非常高.算法1無法處理上述的POI.具有上述特征的POI屬于異常值,OLA算法的目的是為了尋找這些異常值.為了更好的理解OLA算法,下面給出一個例子說明SAFC算法的局限性和OLA算法的應用場景.
用戶A是一個普通公司員工,他由于生病訪問了醫院.用戶B是一名醫生,他的工作地點在醫院.在SAFC算法中,對于“醫院”語義,用戶A的敏感度等級低,用戶B的等級高.相比之下,用戶A的“醫院”語義敏感度等級應該更高,因為用戶A的身份對于“醫院”的差異性高.在軌跡數據中,如果其他用戶擁有“醫院”語義,由于其他用戶的混淆,擁有“醫院”的用戶越多,用戶A就越安全.由此,語義的敏感度級別不僅依賴于個人語義數據,還依賴于其他用戶的語義數據.那么,OLA算法需要度量語義的信息量,用于判斷語義是否屬于異常值.OLA算法的核心思想是利用熵權法計算所有語義的權重,并使用標準差篩選出偏離總體趨勢的異常值.OLA算法分為兩個步驟.
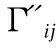
(12)
(13)
算法2描述了OLA算法.
算法2.異常值感知算法(OLA)
輸入:Dls
輸出:STun:語義異常值的集合
1.從Dls中提取所有的語義并去重,記為LSall
2.基于LSall和用戶標識構建語義-頻率數據表格
3.forlsinLSalldo
4. forTlsinDlsdo
5. 初始化Γ=0
6. 獲取Tls的語義與對應的頻率并對頻率做累加計算操作,記為Tls′
7. if ?ls′(ls′∈Tls′),ls=ls′ then
8. Γ←Γ′(Γ′∈ls′)
9. end if
10. 基于用戶標識和語義信息,將Γ存儲到語義-頻率數據表格
11. end for
12.end for
13.基于語義-頻率數據表格,使用熵權法計算語義權重
14.使用公式(13)計算ζ
15.基于ζ篩選語義異常值,并保存到STun
16.returnSTun
3.1.3 SSWA算法
SSWA算法的核心思想是將SAFC算法和OLA算法相結合,重置語義敏感度公式,并基于可行域計算語義敏感度權重.算法3描述了SSWA算法.
算法3.語義敏感度權重分配算法(OLA)
輸入:C′,STun
輸出:ST

2.forlsuninSTundo
5. end if
6.end for
7.使用SAFC算法中描述的方法,重置語義敏感度權重公式,記為STre
8.基于1>γ1>γ2>…>γκ>0和STre構建語義權重可行域
9.在可行域中隨機選擇一個點,記為frp

11.forc′ inC′ do
使用映射函數f1和f2獲取c′的敏感度等級,將對應的權重γ賦予敏感度等級δ
12. 將c′中的語義與γ保存到ST
13.end for
14.returnST
3.2 軌跡生成模型
在本節中,構建一個用戶敏感度移動場景用于訓練Transformer network模型,用于預測軌跡.由于軌跡數據的復雜性,對軌跡數據做預處理,處理過程分為3個步驟.
步驟1.基于時間序列,將軌跡數據中的坐標點連接起來.用戶的原始軌跡數據如公式(14)所示:
Traw:(lat1,lon1,ts1)→
(lat2,lon2,ts2)→…
→(latn,lonn,tsn)
(14)
其中,ts表示時間序列.
步驟2.將添加噪聲后的語義敏感度權重用于擴展Traw.如公式(15)所示:
(15)
但是,由于軌跡數據的復雜性,編碼變得非常困難.根據Nguyen等[15]提出的“regularization term”的方法,本文將任意時刻的坐標數據構造為一個高維嵌入向量ei,ei∈he.關系映射如圖2所示.
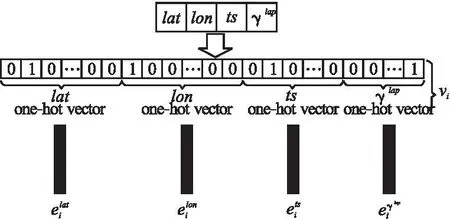
圖2 軌跡數據轉換方法Fig.2 Trajectory data conversion method
轉化后的軌跡數據如公式(16)所示:
(16)

(17)
3.3 軌跡優化
圖3 DBSCAN處理坐標點Fig.3 DBSCAN dealing with coordinate points
在優化的過程中,為了盡量貼合預測的軌跡數據,需要考慮相鄰POI之間的距離(dis)和方位角(ath)兩個屬性.另外,考慮到用戶的敏感語義問題,還需要另外一個屬性:語義敏感度權重γ.
對于上述的3個屬性,使用多屬性決策模型之加權算法平均算子計算POI的期望值,記為POIr.對于dis和ath兩個屬性,使用Vincenty公式的逆解計算.計算距離的公式記為Vd,計算方位角的公式記為Va.dis和ath是固定型,固定值如公式(18)所示:
(18)
其中,i γ是偏離型,固定值為1.3個屬性的歸一化如公式(19)所示.其中,σpoi表示當前POI的語義敏感度權重. (19) 由于動作和狀態空間的復雜性高,引入了DQN.DQN中,智能體在每個時刻t的狀態是st=(latt,lont,lsnt,st∈S,其中latt和lont表示t時刻POI的坐標,lsnt表示位置序列號,同一個查詢范圍內的所有POI共享lsn.對于獎勵值和狀態,使用d-狀態池算法進行預處理.算法4描述了d-狀態池算法. 算法4.d-狀態池算法 輸入:Ppre,ST 輸出:Sset:狀態集合,Spoir:POI期望值集合 2.定義一個集合POIall,存儲指定聚集點查詢范圍內的所有POI信息. 3.初始化lsn=0,γpoi=0 4.forppreinPpredo 6.lsn←lsn+1 7. 根據公式(18)計算距離和方位角的固定值 9. end for 10. forpoiinPOIalldo 11.dis=Vd(ppre,poi),ath=Va(ppre,poi) 12. iflspoi∈STthen 13. 將對應的權重賦予γpoi 14. else 15.γpoi←0 16. end if 17. 使用多屬性決策計算POIr 18. 將POIr壓入Spoir 19. 將(latpoi,lonpoi,lsn)壓入Sset/*latpoi和lonpoi是poi的坐標*/ 20. end for 21.end for 22.returnSset,Spoir 此外,獎勵值由智能體的“移動方向”確定,使用lsn引導智能體的“移動方向”.如公式(20)所示: (20) 對于優化后的軌跡,可能存在由于停留點的變化而導致相鄰停留點之間的路徑斷開,使用Ye等[17]提出的一種路徑補償方法修復斷開的路徑.修復完成后,完成軌跡數據發布. 本文使用微軟研究院的T-Drive數據集[18]和高德地圖API驗證TP-SLS方案的有效應.T-Drive數據集收集了10357輛出租車的GPS數據,其中包含超過1500萬個GPS點.SMA算法和d-狀態池算法需要獲取停留點的語義信息和停留點周圍的所有POI信息.由于T-Drive數據集只包含位置信息,需要一個LBS服務來完成這項工作.在本節中,將TP-SLS方案與NGTMA[19]和RNN-DP[11]進行了比較.本文選取10-80名用戶,分別設置隱私參數ε=0.1和ε=0.2,在隱私保護強度和數據效用兩個方面做對比. 使用互信息(Mutual Information,MI)來衡量在不同隱私預算下,TP-SLS的隱私保護強度.MI越低,隱私保護強度越高.如圖4所示,MI隨著ε的增加而增加.這說明ε與隱私保護強度有關,隱私保護強度隨著ε的增加而降低.當ε的值較低時,TP-SLS方法具有優勢. 圖4 隱私保護強度Fig.4 Privacy protection intensity 為了衡量TP-SLS的數據可用性,使用豪斯多夫距離(Hausdorff Distance,HD).HD是對兩組點之間距離的測量,它在評估兩組數據的相似性領域有廣泛的應用.圖5展示了對比結果.當數據大小相同時,ε增加,HD降低,說明隱私保護強度降低,數據可用性提高.表明了ε值較小時,TP-SLS方法具有優勢. 圖5 數據可用性Fig.5 Data availability 在性能實驗分析中,TP-SLS使用真實世界的數據,與其他兩個方案在隱私保護強度和數據可用性兩個方面進行了比較. 4.3.1 隱私保護強度分析 與NGTMA和RNN-DP相比.TP-SLS在MI的度量上到達最低值.ε=0.1時,最大提升0.00108和0.00044;ε=0.2時,最大提升0.00413和0.00219.TP-SLS量化了語義敏感度權重,每個語義都有屬于自己的權重指標,語義敏感度權重和語義是密切相關的.在一定程度上,語義敏感度可以代替語義去構建用戶的敏感活動場景.那么,對語義敏感度添加噪聲,相當于對敏感語義進行了干擾.同時,使用Transformer network用于處理軌跡數據,它對于序列數據的處理性能遠遠超過現有的一些神經網絡模型,尤其是對于長序列數據的處理. 4.3.2 數據可用性分析 通過對比,TP-SLS的HD最小,這表明TP-SLS在數據可用性方面有更好的表現.ε=0.1時,最大提升2.89059和1.57608;ε=0.2時,最大提升1.2889和0.39621.TP-SLS使用了Q-learning作為優化機制,使用了Transformer network作為預測機制.同時,對于優化軌跡,考慮到了軌跡中相鄰POI之間的距離和方位角,這兩個屬性決定了軌跡的走向,在一定程度上提升了數據的可用性.最后,考慮到了由于POI的改變而導致的路徑斷開問題. 本文提出了一個基于敏感位置語義的軌跡隱私保護方法,使用Transformer network預測用戶的軌跡.此外,本文提出了一個敏感-感知模型量化用戶的語義敏感度,并將語義敏感性引入原始軌跡數據,同時使用差分隱私技術干擾語義敏感度,從而干擾用戶的敏感位置,建立一個四元組的用戶敏感移動場景.為了解決預測的軌跡數據存在廢數據的問題,提出了基于DQN的優化軌跡算法.通過理論和實驗證明,TP-SLS方案可以更好地保護隱私,提高數據的可用性.在局限性方面,由于TP-SLS方案需要使用LBS數據庫來提取停留點的語義信息,如果LBS數據庫提供的數據精度不夠,可能會影響隱私保護結果和數據可用性.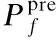

3.4 軌跡數據發布
4 實驗與性能分析
4.1 隱私保護強度
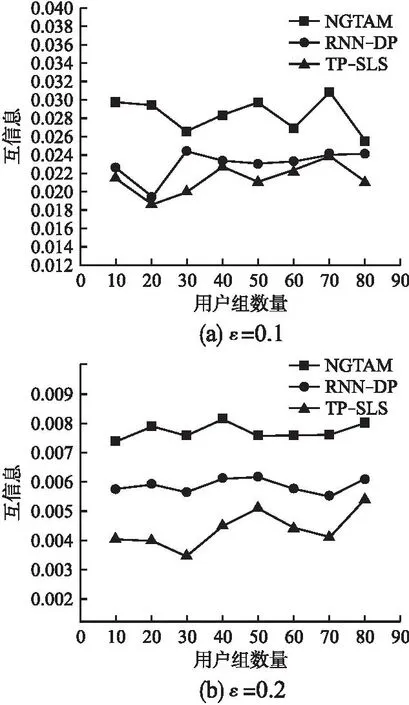
4.2 數據可用性

4.3 結果分析
5 結束語
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
財經(2017年2期)2017-03-10 14:35:35
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
財經(2016年15期)2016-06-03 07:38:02
現代語文(2016年21期)2016-05-25 13:13:44
商用汽車(2016年4期)2016-05-09 01:23:12
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
大連民族大學學報(2015年2期)2015-02-27 08:28:11
