基于相互學習的短時交通流預測研究
2024-05-17 11:56:46劉忠偉閆豆豆安毅生
計算機測量與控制 2024年4期
關鍵詞:模型
劉忠偉,李 萍,周 盛,閆豆豆,李 穎,安毅生
(1. 云基智慧工程有限公司,廣東 深圳 518000;2. 長安大學 信息工程學院,西安 710064)
0 引言
隨著城市機動車保有量的不斷增加,城市道路日益擁擠。為改善這一狀況,交通管理部門提出了利用智能交通系統(ITS,intelligent transportation system)緩解擁堵問題。其中,交通流預測是智能交通系統的核心之一。通過收集歷史數據,可以預測未來某個時間段內的交通狀況,包括速度、流量和占有率等。根據預測時長[1],交通流預測可分為短期預測(5~30 min)和中長期預測(超過30 min)。交通流具有明顯的時空特性,不同道路之間復雜的空間相關性和時間依賴性給交通流預測帶來了挑戰。為了解決這些挑戰,過去幾十年中涌現了許多交通流預測方法。最初,線性回歸等統計分析模型被廣泛應用,但是統計理論模型屬于線性模型,在解決非線性問題時存在不足。受限于統計分析模型的不足,機器學習的發展促使研究者探索支持向量機(SVM,support vector machine)、K最近鄰(K-Nearest Neighbors)等基于數據驅動的方法進行交通預測。
1 交通流預測研究現狀
近年來,國內外對于交通流預測的方法大致可分為3大類:統計分析模型、機器學習模型和深度學習模型。
1)基于統計分析的預測模型:統計分析模型利用概率論和數理統計等相關數學理論建模,主要有歷史平均模型(HA,historical average)[2]、差分整合移動平均自回歸模型(ARIMA,autoregressive integrated moving average model)[3]、卡爾曼濾波器(Kalman filtering)[4]等。歷史平均模型計算過程簡單、速度快,但是模型是靜態的,預測的準確性較低。ARIMA模型的主要目標是將時間序列數據轉換為平穩序列,以便進行數學建模和預測,因此它對數據平穩性要求較高,主要適用于線性序列預測,但是交通流數據的不平穩性和多種非線性因素可能會降低ARIMA的預測性能。基于統計分析的模型在早期的交通流預測中表現較好,但它們假設交通流是靜止的,屬于線性預測,僅從概率的角度考慮空間依賴性,實際的交通流受多種因素影響,具有明顯的非線性和復雜的時空依賴性。
2)基于機器學習的預測模型:隨著交通數據量的急劇增長以及人工神經網絡的發展,研究者們開始使用機器學習進行交通流預測,相比于統計分析模型需要手工調參,機器學習模型比較靈活,可以在遍歷數據集時可以自動調整參數。常見的機器學習預測模型有:K近鄰(KNN,K-nearest neighbors)和支持向量回歸(SVR,support vector regression)等。K最近鄰算法是選取目標樣本所在特征空間K個最近的樣本,所選取K個樣本數中所占數量最大的類別即為目標樣本所屬類別。Zheng等人[5]提出了一種改進的KNN模型,在選擇K近鄰時引入了時間約束窗口并且對狀態向量之間距離的局部極小值進行排序,為控制極值的影響,文章在主成分分析基礎上,還提出了一種新的分析特征的算法,利用該模型來預測交通流。Hou等人[6]引入了兩層KNN算法模型對模式匹配過程做了改進,增加了狀態模式匹配使得當前狀態向量與歷史樣本趨勢和最小。支持向量機是一種二分類算法,算法思想是求解凸二次規劃的最優化。Wu等人[7]應用SVR預測旅行時間,與其他預測模型相比,SVR可以提升預測性能。
3)基于深度學習的預測模型:相比于機器學習,深度學習模型可以更好地挖掘數據隱藏的特性,處理復雜的非線性問題,目前,隨著人工神經網絡以及深度學習的快速發展,越來越多的研究者將其應用到交通鄰域,以其強大的學習能力去提取交通大數據隱藏的時空特性,可以較為準確地預測未來時刻的交通狀況。
在提取時間特征方面,循環神經網絡(RNN,recurrent neural network)具有較好的性能。Ma等人[8]在真實數據集上利用RNN進行擁堵預測,但是RNN在建模較長序列時會產生梯度爆炸等一系列問題。Qu等人[9]將特征注入RNN,形成Feature Injected RNN (FI-RNNS),用堆疊的RNN去提取交通數據的序列特征,并將其與上下文因素結合,進一步挖掘交通數據潛在的時間特性。RNN的變體長短期記憶(LSTM,long-short term memory)和門控循環單元(GRU,recurrent neural network)可以有效解決模型訓練過程中梯度爆炸等問題,閻嘉琳等人[10]提出基于LSTM的城市交通道路預測模型,并在出租車GPS軌跡數據集上進行驗證。Zhang等人[11]考慮了天氣因素的影響,使用GRU進行城市交通流預測。
在提取空間特征方面,卷積神經網絡(CNN,convolution neural network) 具有強大的特征提取能力。Ma等人[12]提出了一種基于圖像的交通速度預測模型,將GPS軌跡數據作為輸入,通過矩陣變換將交通路網轉化為具有時空信息的圖像,圖像的兩個維度分別表示路網的時間維度和空間維度,然后使用CNN提取圖像特征進行交通流預測。Liu等人[13]提出了Conv-LSTM,將卷積和LSTM組合形成一種端到端的結構提取交通流的時空特征,然后使用雙向LSTM(Bi-LSTM)提取交通流的周期性特征。但是交通路網是一種典型的拓撲結構數據,將其處理為網格數據后使用CNN,忽略了路網本身的特征,因此研究者們嘗試將CNN泛化到圖域,形成圖卷積神經網絡GCN來處理交通路網、社交網絡等拓撲結構數據。Li等人[14]提出了一種擴散卷積循環神經網絡(DCRNN,diffusion convolutional recurrent neural network),使用GCN和GRU共同提取交通流的時空相關性,首先在圖上使用雙向隨機游走捕獲空間依賴性,然后使用GRU提取時間特征。Yu等人[15]提出了時空卷積網絡(STGCN,spatio-temporal graph convolutional networks),該模型由時空卷積塊堆疊而成,利用門控時間卷積和空間卷積提取出最基本的時間特征以及最相關的空間特征。由于GCN強大的空間特征提取能力,研究者們還嘗試將注意力機制和Transformer等神經網絡與GCN結合來預測交通流。Zheng等人[16]提出了一種圖上的多注意網絡(GMAN,graph multi-attention network),由多個注意力模塊堆疊而成,包括對空間特性建模的空間注意力模塊、對時間特性建模的時間注意力模塊以及自適應融合時空特征的門控融合機制。空間注意力機制根據鄰近節點對目標節點影響的大小分配不同的權值,時間注意力機制根據預測點歷史時刻的影響不同分配不同的權值。Tian等人[17]提出了一種包含時間注意力機制的深度學習網絡框架解決城市交通事故預測問題,實現了較好的預測性能。此外,Cai等人[18]將Transformer應用到圖上來建模時間相關性,并且設計了4種新的位置編碼策略編碼時間序列的連續性和周期性。Li等人[19]使用多目標粒子群優化算法優化深度信念網絡的一些參數,增強了交通流的多步預測能力。
2 知識蒸餾相關理論
知識蒸餾是一種有效的模型壓縮方法,其核心思想是將來自復雜教師模型的知識遷移到簡單的學生模型上,從而提高學生模型的泛化能力。教師模型通常擁有較強的預測精度,但其訓練過程比較復雜;相反,學生模型參數較少,訓練過程較為簡單,但其預測能力相對較弱。因此,知識蒸餾技術可以通過教師網絡輸出的軟標簽來監督學生網絡的學習,從而提升學生模型的預測性能。根據蒸餾的方式和知識類型,知識蒸餾可分為離線蒸餾、在線蒸餾以及自蒸餾。在離線蒸餾中,教師模型經過預先訓練,并生成軟標簽供學生模型使用。基于響應的知識蒸餾、基于特征的知識蒸餾以及基于關系的知識蒸餾則是離線蒸餾中按知識類型劃分的3種主要方法。其中,基于響應的知識蒸餾主要側重于對教師網絡最后一層的邏輯輸出進行處理,讓學生網絡去模仿教師網絡的輸出。2014年Hithon[20]首次提出了基于響應的知識蒸餾,同時也提出了蒸餾溫度T的概念,在高溫T下,學生網絡模仿教師網絡的輸出,蒸餾溫度則是用來軟化教師網絡的軟目標輸出,當溫度系數值不斷增大,得到的輸出標簽更加平滑。基于特征的知識蒸餾,其核心思想是學習教師網絡層與層之間的關系,從而提升學生網絡的性能,Romero等人[21]提出的FitNets表示學生能夠直接模仿教師網絡的特征激活值。基于特征的知識蒸餾可以在學生網絡學習時提供更多的信息,但是由于教師網絡與學生網絡中間層存在維度差異,以及在兩個網絡上如何選取對應中間層操作較為困難。Park等人[22]提出了基于關系的知識蒸餾,重點關注模型內部特征之間的關系,而不僅僅是模型輸出。這種蒸餾方法方法認為捕捉和模仿教師模型內部特征之間的相互作用和依賴關系,可以幫助學生模型更全面地理解任務,從而學到更豐富的知識。
傳統的離線蒸餾存在局限性,需要提前訓練一個復雜的教師網絡,會耗費大量的時間和計算資源,且學生網絡不能學習教師網絡所蘊含的所有知識,為了解決這些問題,研究者們在傳統知識蒸餾的基礎上提出了在線知識蒸餾,即無需提取訓練復雜的教師模型,教師模型和學生模型在學習過程中互相更新。其中以Zhang等人[23]提出的深度相互學習策略(DML,deep mutual learning)為代表,兩個或多個學生模型可以在訓練過程中互相學習,互相監督,打破了傳統的知識蒸餾預先設定好的強弱關系,無需提前訓練復雜的教師模型,將傳統的單向知識遷移更新為雙向遷移,即訓練過程中兩個或多個模型互為教師,互為學生。Zhai等人[24]將相互學習策略泛化到圖上,提出了圖相互學習模型(MGL,mutual graph learning) 將相互學習由規則網格推廣到圖域。
自蒸餾是一種特殊的在線蒸餾,指在沒有新增復雜模型的情況下找到一個教師模型,同樣可以提供有效增益給學生模型,意味著教師網絡與學生網絡應用同一個主體網絡,或者直接將自身的信息作為蒸餾損失的監督,是模型內部的知識遷移。2019年,Zhang等人[25]提出了一種自蒸餾的方式,用模型的深層部分蒸餾和監督淺層部分。2021年,Kim[26]等人提出了漸近式自蒸餾(PS-KD,progressive self-knowledge distillation),用前邊幾輪的模型去蒸餾后邊幾輪模型訓練。
綜上所述,知識蒸餾是一種通過知識遷移和蒸餾損失來提高模型預測精度的方法。這種方法可以滿足交通流預測對于精準性的高要求。因此,在本文中,采用知識蒸餾技術對交通流預測模型進行了優化。
3 模型架構
3.1 預測問題定義
交通流預測是根據部署在道路上N個檢測器預先收集到的數據來預測未來時刻的交通狀況[27]。交通路網可以定義為G=(V,E,W),其中V為節點的集合,E為兩個節點之間邊的集合,W∈RNⅹN對應圖G的鄰接矩陣。實際應用中,節點即為部署在道路上的檢測器,收集到的交通信息包括速度、流量、占有率等。對于一個交通網絡,Xt∈RNⅹC表示在t時間步交通網絡中所有節點的特征的集合,C表示特征的數目。通過給定M0個歷史時刻的交通數據去測未來M個時刻內所有節點的交通特征,即交通流預測問題可定義為:
(1)
其中:f(·)是一個經過訓練的可學習的函數,可以將歷史時刻的交通數據映射到未來時刻。
3.2 DCRNN模型
本文以DCRNN作為基準模型,將交通流建模為有向圖上的擴散過程,通過圖上的隨機游走捕捉交通流的空間特征,使用門控單元GRU提取時間特征,將序列到序列框架和預定采樣相結合進行交通流預測。圖1即為DCRNN的網絡架構,是一種編碼器-解碼器結構,其中編碼器的功能是將一個長度不固定的輸入序列轉化成一個固定長度的上下文變量,在該變量中編碼輸入序列信息;解碼器將該變量中的信息進行解碼生成一個輸出序列。

圖1 DCRNN模型圖
首先對歷史交通流數據集按照時間步長進行劃分,將路網建模為有向圖,圖中節點表示部署在道路上的檢測器。然后將經過劃分處理后的數據作為解碼器的輸入,解碼器由擴散卷積層堆疊而成,以此來提取圖中各個節點之間隱藏的空間相關性。使用門控循環單元GRU提取時間依賴性,這是一種具有強大功能的循環神經網絡RNN的變體,用擴散卷積代替GRU中的矩陣相乘,產生了擴散卷積門控循環單元DCGRU。編碼器的最終輸出作為解碼器的輸入,解碼器的結構與編碼器類似,進行最終的預測輸出。為了解決訓練過程和測試過程中輸入數據分布不一致的問題,DCRNN在訓練過程中采用計劃采樣,網絡將以概率p選擇真實值作為下一步的輸入,以1-p的概率選擇模型自身的輸出作為下一步的輸入。
3.3 基于相互學習策略的模型優化
DCRNN模型能夠有效地提取交通數據中隱藏的時空相關性,并預測未來交通狀況。然而,該模型在自身特征感知和提取方面存在一定的局限性。本文受到知識蒸餾中相互學習策略的啟發,對DCRNN進行了優化。利用兩個或多個網絡在訓練過程中相互學習,相互協同完成知識的傳遞,并在不增加模型復雜度的前提下優化模型的預測性能。為了降低訓練過程中的參數量,只使用兩個未經訓練的DCRNN模型構建基于相互學習的預測模型。首先將處理后的數據輸入兩個模型,分別經過兩個模型的softmax層輸出預測值,使用KL(Kullback-Leibler Divergence,用于計算不同概率分布之間的差異)散度衡量兩個網絡預測值的匹配度,KL值越小,則表示兩個網絡之間的匹配度越高。除KL值之外,使用交叉熵損失(CE,cross entropy)來衡量每個模型的預測值與真實值的差異。綜上,在搭建的預測模型中,每個學生網絡的損失由兩部分組成:傳統的監督損失CE以及與同伴網絡的匹配損失KL。圖2是優化模型DMCRNN(Diffusion Mutual Convolutional Recurrent Neural Network)的結構,其中P1和P2分別表示兩個網絡在訓練過程中輸出的預測概率,利用KL(P2||P1)計算兩個網絡預測概率之間的差異,KL值越小,表示兩個預測值之間的差異越小。P1與P2之間KL散度計算公式如下:
(2)

圖2 基于相互學習的預測模型
即網絡1的損失為相互學習損失以及自身損失以權值系數進行疊加,可表示為:
L1=LC1+DKL(P2||P1)
(3)
同理可得網絡2的損失:
L2=LC2+DKL(P1||P2)
(4)
模型在每一次迭代過程中均采用相互學習算法,對DCRNN模型進行優化,兩個網絡分別利用對方的預測值去更新各自的參數,直至收斂。不同于傳統的知識蒸餾為單向蒸餾,即知識僅從教師網絡遷移到學術網絡,而相互學習是一種雙向蒸餾,兩個網絡在訓練過程中不斷更新優化,直到參數收斂。基于相互學習的DCRNN模型優化算法框架如表1所示,經過優化后可以提升DCRNN模型的預測性能。

表1 數據集基本信息
4 實驗
為了驗證基于相互學習算法預測模型的有效性,該研究在兩個真實數據集(METR-LA和PEMS-BAY)上進行實驗并與其他幾種基準模型進行對比。
算法:基于相互學習的交通流預測算法
輸入:訓練數據,學習率r
初始化:DCRNN網絡Net1和DCRNN網絡Net2
t=0
do:t=t+1隨機抽取數據:
從Net1中計算預測值y1和真實值ytrue;
從Net2中計算預測值y2和真實值ytrue;
計算Net1的隨機梯度并更新網絡參數:
a.計算誤差E1=(y1-ytrue)2;
b.計算Net1的梯度dE1/dw1;
c.更新Net1的參數w1_new=w1-r*dE1/dw1;
更新Net1的預測值y1;
計算Net2的隨機梯度并更新網絡參數:
a.計算誤差E2= (y2-yt rue)2;
b.計算Net2的梯度dE2/dw2;
c.更新Net2的參數w2_new=w2-r*dE2/dw2;
更新Net2的預測值y2
While:目標函數未收斂
4.1 數據預處理
METR-LA:該數據集采樣于美國洛杉磯高速公路上的207個傳感器,其中包含2012年3月1日到2012年6月7日所收集到的交通速度等信息。數據采集頻率為5 min一次,包含34 272條交通數據。
PEMS-BAY:該數據集來源于加州高速公路,包含灣區325個檢測器,數據采集頻率為每五分鐘一次,包含從2017年1月1日到2017年5月31日所收集到的流量、速度等信息,總共有52 116條交通數據。
如表1所示,本文主要使用兩個數據集中的速度信息,按照7∶2∶1的比例劃分數據集,其中訓練集占70%,測試集占20%,驗證集占10%。為了提高模型在梯度下降時收斂速度,對數據集采用Z-Score來標準化:
(5)
其中:z表示歸一化后的數據,x表示原始輸入數據,μ,σ分別表示均值和方差。
構建圖的鄰接矩陣是交通流預測模型提取空間相關性的關鍵,DCRNN模型采用基于距離的方法建立圖的鄰接矩陣,利用交通路網上檢測器之間的距離來計算節點之間的緊密程度,加權鄰接矩陣計算公式為:
(6)
其中:dist(vi,vj)≤κ,Wij表示兩個檢測器vi和vj所連接的邊的權值,dist(vi,vj)表示vi和vj在路網上的距離,σ表示距離的標準差,k表示閾值。
4.2 實驗設置
基于Pytorch框架訓練DMCRNN模型,訓練時采用內含4張型號為GeForceRTX 3090顯卡的服務器,具體的環境配置以及參數設置如表2、表3所示。
表2 硬件條件

表3 實驗參數設置
實驗過程中利用1小時的歷史數據去預測未來1小時內的交通狀況。并且訓練過程中利用dropout和early stopping機制防止模型過擬合,隨機擴散時最大擴散步長為2。
4.3 評估指標
在評估優化后的模型預測性能時,采用如下3個指標評估真實值與預測值之間的差異:
1)平均絕對誤差(MAE,mean absolute error),可以直觀顯示出真實值與預測值之間的偏差,直觀反映模型的預測結果,計算公式如下:
(7)
2)平均絕對百分比誤差(MAPE,mean absolute percentage error),可以評價真實值與預測值之間的符合程度,反映模型預測的準確程度,計算公式如下:
(8)
3)均方根誤差(RMSE,root mean square deviation),可以反映出真實值與預測值差值的變化,反映模型預測的精確程度。計算公式如下:
(9)
其中:n為時間步長,yi和f(xi)分別表示第i個時間步的真實值和預測值,3個指標的數值越小,表示模型的預測精度越高。
4.4 基準模型介紹
為驗證優化算法的有效性,我們在兩個真實的數據集上進行了實驗,并將實驗結果與目前具有代表性的7種模型進行了比較。
HA[2]:歷史平均模型,即計算歷史數據的平均值。
ARIMA[3]:差分整合移動平均自回歸模型,一種預測未來值的時間序列分析方法。
VAR[28]:向量自回歸模型,可以捕獲交通流序列之間的成對關系,是一種更先進的時間序列模型。
SVR[7]:支持向量機模型,利用支持向量機來解決回歸問題,是一種線性模型。
FNN[29]:前饋神經網絡模型,其中包含多個隱藏層。
LSTM[10]:長短期記憶網絡,屬于RNN的變體,在長時間序列問題上表現較好。
DCRNN[14]:擴散卷積遞歸神經網絡,利用擴散卷積網絡和GRU分別提取空間特征和時間特征。
4.5 實驗結果分析
我們在兩個真實數據集上進行實驗,根據預測結果,利用上述3個評估指標對預測性能進行分析。表4和表5分別展示了DCMRNN模型與其他基準模型在兩個數據集上的性能比較,我們選取了15 min,30 min和1 h這3個時間步長進行比較。從表中可以看出本文提出的模型在兩個數據集上的3種誤差均是最低的,即預測結果更加接近真實值。尤其是隨著時間步長的增加,其預測效果更好。從表3和表4中可以看出隨著預測時間步長的增加,DMCRNN模型與其他模型三項指標之間的差值越大,表明了該模型在較長時間步預測時仍具有較好的性能,模型具有魯棒性。在METR-LA數據集上MAE值相較于DCRNN下降了0.15,MAPE下降了0.4%,RMSE下降了0.55;在PEMS-BAY數據集上MAE值相較于DCRNN下降了0.12,MAPE下降了0.2%,RMSE下降了0.31,表明增加相互學習算法后的模型優化效果顯著。
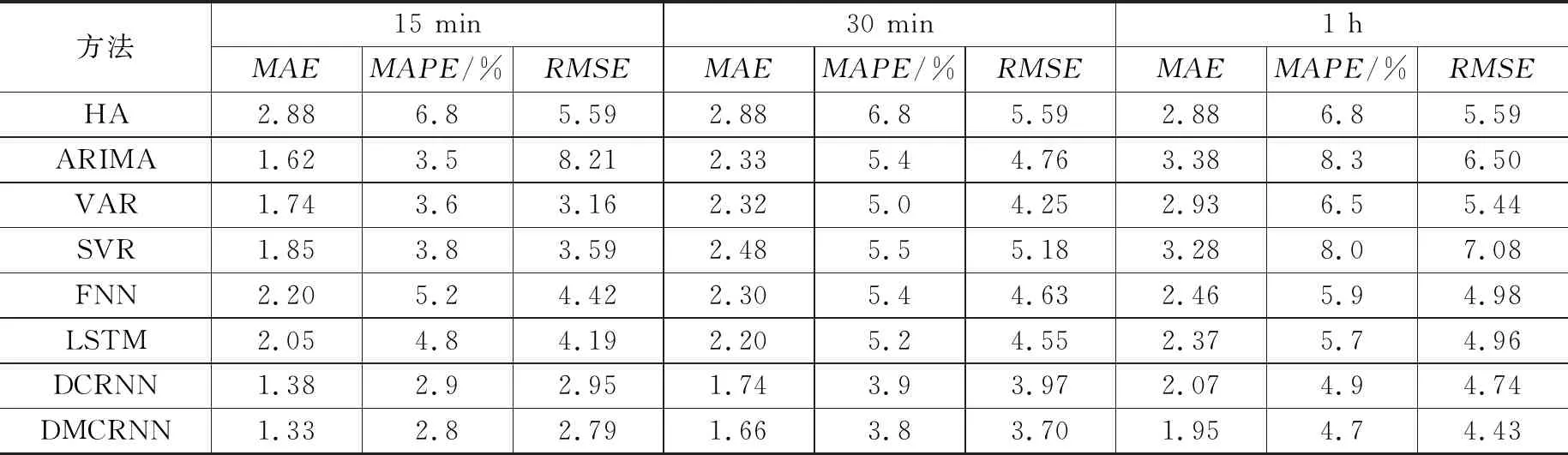
表5 DCMRNN與基準模型在PEMS-BAY數據集上的性能比較
為了進一步比較DMCRNN模型與基準模型DCRNN,
圖3、4和5展示了兩個模型在METR-LA數據集的3種評價指標以及損失可視化。圖3、4和5中灰色線條表示基準模型DCRNN在驗證過程中的指標變化,黑色線條表示我們的模型DMCRNN的指標變化,可以看出我們的模型相比于DCRNN,誤差可以收斂到更低。圖6為兩個模型訓練過程中損失曲線可視化圖,其中我們提出的模型DMCRNN收斂速度更快。圖7是兩個模型在測試集上RMSE的比較,橫坐標表示時間步長,縱坐標表示RMSE,可以看出隨著預測時間步長的增加,兩個模型之間的差異變大,即我們提出的模型在較長時間步時表現較好。
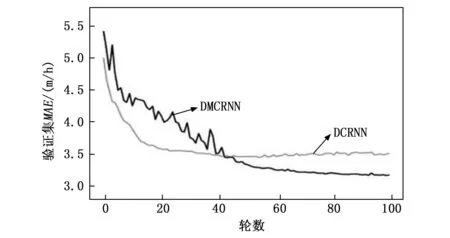
圖3 驗證集MAE可視化曲線圖

圖4 驗證集MAPE可視化曲線

圖5 驗證集RMSE可視化曲線圖

圖6 訓練集損失可視化
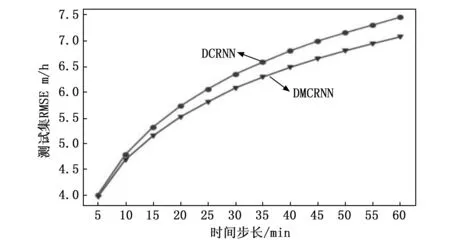
圖7 兩個模型在不同時間步長上的RMSE比較
4.6 實驗參數分析
基于相互學習優化過程中有兩個重要的超參數,第一個是不同溫度系數對蒸餾結果的影響,第二個是不同的權重系數對兩部分損失函數的影響。這兩個參數都來源于損失函數,損失函數是模型性能的關鍵之一,溫度T表示蒸餾溫度,來源于KL散度的計算過程中,會對網絡的性能產生影響;而參數α表示兩種損失在總損失中的比重。
實驗過程中觀察到T=8時驗證集上MAE以及損失曲線最終收斂的值比其他溫度更低,因此選用T=8作為基準蒸餾溫度;將α系數設置為[0.1,0.3,0.5,0.7,0.9,0.99]進行實驗,結果顯示當α等于0.9或者0.1時,效果最差。α=0.9表示相互學習損失權重過大,網絡自身的損失權重過低,極大影響了模型的預測性能。α=0.1表示相互學習損失權重過低,網絡之間相互學習能力變弱,同樣影響了預測性能。其他3個不同的權重系數對模型的影響整體相差不大,其中α=0.5在驗證集上MAE以及損失曲線最終收斂的值較其他兩個權重系數的曲線收斂結果更低一點。最終選取α=0.5作為最佳權重系數。
4.7 相互學習可擴展性實驗
為了驗證相互學習算法的普適性,實驗中選取了Shang等人[30]提出的(GTS,graph for time series)模型進行驗證,GTS是一種新的圖優化方法,當圖未知的時候,該方法可學習圖結構以增強對多個多元時間序列的預測。GTS也是以DCRNN為基準模型,通過優化圖結構從而大幅度提升了預測性能。因此將GTS作為基準模型,增加相互學習算法,使兩個GTS網絡作為學生模型互相學習。同樣在METR-LA和PEMS-BAY兩個數據集上進行實驗,表7選取了1小時的預測結果進行對比,實驗結果可以看出,在增加相互學習算法的GTS模型預測誤差相比于原來均有所降低,尤其是在METR-LA數據集上,再次證明了相互學習算法的有效性。

表7 擴展實驗結果
5 結束語
本文提出了一種基于相互學習策略的交通流預測優化模型(DMCRNN)。該模型以DCRNN為基準模型,引入相互學習算法,并在兩個真實數據集上進行了實驗,取得了較好的結果。與其他基準模型進行對比證明了相互學習策略可以有效提高模型的預測性能。同時,設計了擴展性實驗驗證相互學習在其他模型上的效果,證明了相互學習的普適性。總之,優化后的模型表現良好,但訓練過程中會生成兩個模型,并聯運算,導致訓練時間相比基準模型較長,并且會生成兩份優化參數。然而,在實際應用中只需要其中一個模型的優化參數。因此,未來工作可以考慮通過優化模型之間的并聯方式來減少訓練時間。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
