基于Electra語言模型的地理命名實體識別
2024-05-19 10:16:18袁躍飛楊久東賈聞遠
電腦知識與技術 2024年9期
袁躍飛 楊久東 賈聞遠

摘要:地理命名實體識別是構建高質量地理知識圖譜的關鍵環節,需要從大量的非結構化文本中提取地理實體名稱,為了提高識別效率和自動化水平,文章選取百度百科和中文地址要素解析任務的部分數據構建語料庫,采用輕量化語言模型Electra與CRF相結合對唐山市地區的地理命名實體進行了自動識別研究。研究表明:Electra-CRF語言模型有很好的魯棒性,以唐山市百度百科詞條為例進行模型評估,該方法對于地理命名實體的平均解析準確率達80%以上,可以運用在構建地理知識圖譜或者地理知識庫的命名實體識別任務當中。
關鍵詞:ELECTRA;地理命名實體;混淆矩陣
中圖分類號:P281? ? ? 文獻標識碼:A
文章編號:1009-3044(2024)09-0005-03
開放科學(資源服務)標識碼(OSID)
人們在獲取或者處理某地的地理信息時,首先就要通過地理命名實體檢索或者定義該命名實體地理信息的內容,因為這些名稱是地理信息表達的主體中心,就如同句子的主語一樣,那么地理命名實體識別勢必成為構建高質量地理知識圖譜重要環節,隨著大數據時代的到來,文本作為主要的信息載體其中蘊含著大量的地理信息,并且具有更新快速的特點,與人們生活環境息息相關。如何有效地從非結構化的文本中提取這些地理信息成為處理這些數據的核心問題。命名實體識別是人工智能領域里自然語言處理的基礎任務之一,主要是從大量的文本信息中識別實體和其對應的類型然后添加到知識庫或者構建知識圖譜,比如地名、機構名、建筑物名等。深度學習技術的出現,為中文文本的處理提供有力的技術支撐。
目前針對地理命名實體識別的問題,隨著深度學習技術的不斷發展逐漸增多。余云秀在地理領域對嵌套命名實體識別任務進行分層建模,采用條件隨機場和雙向門遞歸單元神經網絡兩種模型展開研究[1]。王曙針對自然語言中地理實體的描述特點,提出了顧及上下文特征的詞向量表達方法和基于深度信念網絡的地理實體識別模型[2]。張凱針對標注進展緩慢的效率問題,研究地理實體信息半自動標注流程,通過引入迭代的思想,構建面向增量學習模型的迭代算法[3]。馬孟鋮等提出一種多特征融合的中文地名、機構名實體識別方法,該方法以條件隨機場為框架,結合實驗語料的特點,選取統計特征,將局部特征、復合特征與規則知識庫相融合,對中文語料進行命名實體識別[4]。
本文采用輕量級的ELECTRA預訓練語言模型與CRF相結合構建地理命名實體識別模型,并評估該模型的性能,以期在地理信息知識圖譜構建實體提取方面提供技術參考。
1 ELECTRA-CRF模型
1.1 模型介紹
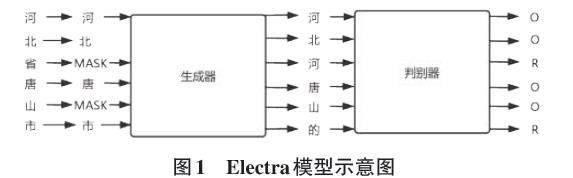
Electra語言模型是谷歌和斯坦福大學共同研發的一種新型的基于生成模型的預訓練模型,因為它小巧的模型體積和良好的模型性能受到廣泛關注。Electra模型主要是通過用小的生成模型替代普通的學習模型來提高效果,該模型的做法是先假設句子中每個字符都是由原字符經過隨機替換得到的,然后用一個小型的生成模型去學習替換原字符的規律。
Electra模型由兩部分組成,分別是生成器和判別器。生成器和判別器都采用了Transformer網絡結構。在Electra中,生成器使用了12個Transformer塊,每個塊都包含12個自注意力機制頭和前饋神經網絡層。判別器也使用了12個Transformer塊,每個塊也包含12個自注意力機制頭和前饋神經網絡層。
該模型結構借鑒了對抗網絡的思想,共訓練兩個神經網絡模型,左邊生成器用來隨機屏蔽原始文本中的單詞,進行預測學習。右邊判別器判定單詞是否與原始文本一致,如果一致則為真,如果不同則為假。
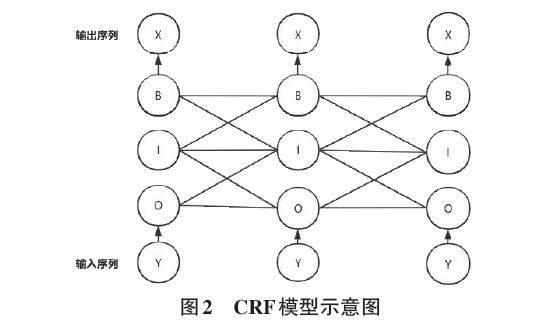
1.2 CRF層
在模型中Electra的判別層學到了語料中單個字符對應標注的最大概率,沒有考慮標簽間的規則,為了增加標簽之間的規則對識別結果的約束,這時候加入CRF層這種序列標注模型通過相鄰的標簽關系進行聯合概率分析,給出最優的標簽序列,提高識別結果的準確性。
2 實驗設計與結果分析
2.1 數據集
本文數據集采用阿里達摩院機器智能技術團隊在CCKS2021大會中發布的地址評測的數據集“中文地址要素解析任務”和“地址文本相關匹配任務”的部分數據和百度百科詞條的部分數據。詳情如表1所示。
2.2 標注策略
文本數據標注是給數據貼上特征標簽,然后通過這些特征訓練深度學習模型使它學習到在眾多文本中識別這些特征的能力,所以樣本的標注策略直接影響到模型的實驗效果。現在常用的標注體系為BIO、BIOE、BIOES三種標注體系,本實驗采用BIO的標注方法,如表2、表3所示。
2.3 評價指標
混淆矩陣是用于衡量分類模型性能的一種工具,也被稱為誤差矩陣。它是一個 N×N 的矩陣,其中 N 是分類的類別數量。該矩陣對于每個類別給出了實際類別和預測類別的匹配情況,通常以行表示真實類別,以列表示預測類別。其主要作用是通過各種指標(如準確率、召回率、F1分數等)來評估分類算法的性能。
在混淆矩陣中,對角線上的元素表示正確分類的樣本數量,非對角線上的元素表示錯誤分類的樣本數量。例如,對于二元分類問題,混淆矩陣為:
精確率Precision=TP/(TP+FP)? ? ? ? (1)
召回率 recall=TP/(TP+FN)? ? ? ? ? ?(2)
[F1=2Precision*recallPrecision+recall]? ? ? ? ? ? ? ? ? ?(3)
其中,TN 表示真實為負例,被預測為負例的樣本數;FP 表示真實為負例,被預測為正例的樣本數;FN 表示真實為正例,被預測為負例的樣本數;TP 表示真實為正例,被預測為正例的樣本數。
通過混淆矩陣,可以實體類別計算出各種評估指標,精確率(Precision) 、召回率(Recall) 和F1分數等,有助于我們進一步了解分類模型的性能,從而更好地進行模型調優和預測。本次實驗中,模型評估階段也利用了混淆矩陣,分別計算出每種實體類別的評估參數。
2.3 實驗環境
2.4 模型搭建
本次實體識別實驗中,根據上文整理的實體識別數據集的數據量和數據特征,對Electra模型判別器后半部分權重參數進行微調,這個過程旨在幫助模型捕捉到真實文本數據的語言特征,同時提高模型在判斷不真實文本數據時的魯棒性和準確性。最后將Electra模型中堆疊的Transformer編碼器輸出的語義向量輸入至CRF層中,并將每個實體類別的得分值通過CRF進行轉換,從所有可能的序列中判別出最優序列。模型結構如圖3所示。
2.5 超參數設置
在文本輸入階段,句子最大截斷長度設置為128,每個訓練批次內,句子數量為16。在詞向量表示階段,采用了預訓練模型Electra,向量維度為Electra默認的768維,在語義編碼階段,采用了Electra默認的12層Transformer編碼器,在模型訓練階段,將損失率設置為0.1,學習率設置為5e-5,訓練周期為10個epoch,具體參數設置如表6所示。
2.6 實驗結果與分析
按照實體標簽分類進行模型性能評估,總體效果較好,其中行政區、道路、河流和景點準確率維持在較高水平,行政區和河流實體在訓練樣本為2:1的情況下F值變化不明顯,對比原文本和輸出文本,兩者語義環境相似度較高,對簡單實體樣本數量的提升不會對模型性能有顯著的提升,機構類實體識別準確率較差,對比原文本和輸出文本,發現機構實體大都由多種實體嵌套而成,導致模型識別出的文本邊界與原文本相差較大,5類實體平均P值為80.05,R值為87.92,F1值為0.82,故此可以得出模型在簡單語義環境中的識別效果較好,可以用于地理命名實體識別任務當中。部分識別結果如表7所示。
3 結論
地理命名實體是從大量的非結構化文本中獲取地理信息的基礎,本文針對當前海量文本中地理命名實體識別中面臨的挑戰,研究了基于深度學習的地理命名實體識別方法,采用了輕量化語言模型Electra結合CRF對唐山市地區的地理命名實體進行自動識別實驗,實驗結果表明該模型的平均解析準確率在80%以上,可以應用在簡單語義環境的地理命名實體識別任務中。
下一步將在以下方面進行研究:
(1) 模型在特定的語義環境中識別能力不足,應在數據特征約束和數據標注方面進一步加強。
(2) 后續加入能夠捕捉雙向語義信息的BiLSTM,以期模型能擁有更好的效果。
參考文獻:
[1] 余云秀.基于分層標注的地理領域嵌套命名實體識別研究[D].南京:東南大學,2018.
[2] 王曙.自然語言驅動的地理知識圖譜構建方法研究[D].南京:南京師范大學,2018.
[3] 張凱.基于增量學習的地理實體信息半自動標注方法研究[D].南京:南京師范大學,2020.
[4] 馬孟鋮,艾斯卡爾·艾木都拉,吐爾地·托合提.基于條件隨機場多特征融合的中文地名、機構名實體識別[J].現代計算機,2019(12):13-17.
[5] 丁家偉,劉曉棟.基于ELECTRA-CRF的電信網絡詐騙案件文本命名實體識別模型[J].信息網絡安全,2021(6):63-69.
[6] 李發東,王海起,孔浩然,等.聯合詞匯增強的中文細粒度地理命名實體識別模型研究[J].地球信息科學學報,2023,25(6):1106-1120.
[7] 湯潔儀,李大軍,劉波.基于BERT-BiLSTM-CRF模型的地理實體命名實體識別[J].北京測繪,2023,37(2):143-147.
[8] 王穎潔,張程燁,白鳳波,等.中文命名實體識別研究綜述[J].計算機科學與探索,2023,17(2):324-341.
[9] 何玉潔,杜方,史英杰,等.基于深度學習的命名實體識別研究綜述[J].計算機工程與應用,2021,57(11):21-36.
[10] 佘文浩,李衛榜,楊茂,等.基于ELECTRA與神經網絡模型的中文醫療知識圖譜實體識別[J].西南民族大學學報(自然科學版),2023,49(2):197-205.
[11] 楊盈,邱芹軍,謝忠,等.人在回路學習增強的地理命名實體識別[J].測繪通報,2023(8):155-160,177.
【通聯編輯:李雅琪】
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
