基于深度強化學習的通信動態抗干擾決策模型
2024-05-19 14:11:46陳帥明
電腦知識與技術 2024年9期
陳帥明

摘要:隨著通信技術發展,頻譜資源有限,抗干擾能力不足,已廣泛影響通信質量和可靠性。為提升通信可靠性,將強化學習與VHF動態抗干擾決策相結合,綜合考慮通信信道切換和發射功率控制。提出基于深度強化學習算法的VHF動態抗干擾決策模型,使用仿真分析驗證強化學習決策模型的有效性。實驗結果表明,深度強化學習決策模型的抗干擾性能、收斂速度均優于傳統的強化學習算法,具有較高的吞吐量和較低的功耗。
關鍵詞:深度強化學習;VHF;動態抗干擾;決策模型
中圖分類號:TP3? ? 文獻標識碼:A
文章編號:1009-3044(2024)09-0089-04
開放科學(資源服務)標識碼(OSID)
0? 引言
隨著通信技術發展,民航、應急通信等領域VHF(Very High Frequency,VHF)無線通信系統抗干擾要求更加嚴格。GWON Y等基于強化Q學習技術提出了最佳信道訪問策略[1]。SLIMENI F在認知無線網絡場景中提出基于策略同步Q學習的信道分配策略[2]。HANAWAL M K等提出的零和博弈研究了跳頻和傳輸速率控制,但只分析了反應式掃頻干擾方式,對多種干擾環境并不適用[3]。同時,這些算法都只是利用信道切換來規避干擾,頻繁切換信道會增加系統成本,并不能帶來整體性能的提升。
對此,提出基于深度強化學習(Deep Reinforcement Learning,DRL)的VHF動態抗干擾決策模型,在多用戶場景下同時進行信道選擇和功率分配,將問題建模為Stackelberg博弈過程,既考慮通信信道的訪問與發射功率控制,又考慮快速適應環境變化的算法收斂速度。
1? 問題分析與建模
1.1? 系統模型
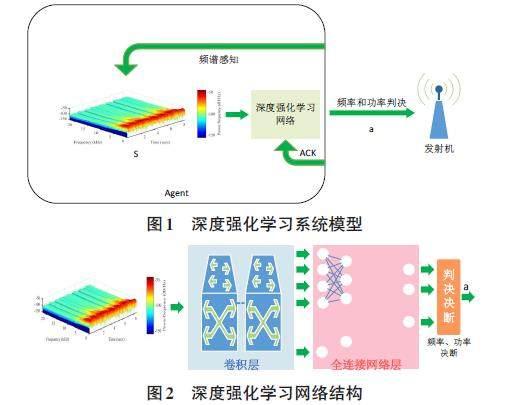
VHF無線通信環境中,發射機向接收機發送信號,成功接收后接收機發回ACK。發射控制在發射機側,代理感知頻譜,指導發射機選擇通信頻率和通信功率,并根據接收ACK和頻譜調整通信決策。
在時間t,發射機發射的信號功率為[pt,pt∈Ps,Ps]為發射機功率設置數值集合[card(Ps)=n],假設發射機的中心頻率為[ft,ft∈Fs,Fs]為發射機中心頻率設置數值集合[card(Fs)=m]。設置發射信號中頻帶寬為[bs],假設在時間t,干擾信號頻帶為[bj],干擾信號頻率的中心頻率為[fjt],干擾信號的功率譜密度[Jt(f)]。發射機至接收機的信道增益為[gs],干擾信道至發射機的信道增益為[gj],且環境噪聲的功率譜密度為[n(f)]。那么接收機所感知到的信噪比可以表示為:
[β(ft,pt)=gsptft-bs2ft+bs2(n(f)+gj(f-fjt))]? (1)
設[βth]為信號成功傳輸的門限值,那么表述成功通信功能的表達式為:
[u(ft,pt)=1? ?β(ft,pt≥βth)0? ?β(ft,pt<βth)]? ? (2)
因此,如果[u(ft,pt)=1],接收機會向發射機發回ACK信號。對于歸一化的數據吞吐量,用一次迭代表示N次通信,可以計算出歸一化的數據吞吐量為:
[U=n=1n=Nu(fn,pn)N]? ? (3)
其中[fn]為時刻n選擇的頻率,[pn]為時刻n選擇的功率。那么歸一化的能量消耗V就可以表示為:
[V=n=1n=NpnNph]? ? ?(4)
其中[ph]為功率集合[Ps]的最大功率。那么每個信號E使用的歸一化功率可以表示為:
[E=UV]? ? ? ?(5)
1.2? 問題模型
算法的優化目標是確保在每次通信中,發射機能夠選擇正確的通信信道,并達到最小的能耗。優化目標為:
[θ=min(β(f,p)),? s.t.β(f,p)≥βth]? (6)
將在無線環境中選擇通信中心頻率和功率的優化問題建模為一個由4元組[(S,A,R,P)]描述的馬爾可夫決策過程(Markov decision process,MDP) [4]。在時間t的代理感應頻譜為[St∈S],T是用來決定頻率和通信功率的時間段[at∈A]。在信號發送以后,我們得到了帶有獎勵信息[rt∈R]的ACK確認信息。用P作為過渡概率,當T足夠大時,可證明該抗干擾決策過程是一個馬爾可夫決策過程,該過程中的轉移矩陣可定義為:
[P(ST+1|ST,ST-1,...,ST-∞)]
[=P(sT+1,sT,...,st-T+2|sT,sT-1,...,sT-∞)]
[=P(st+1|st,st-1,...,st-∞)]? ? ? ? (7)
假設只需用限制歷史信息來預測下一時刻的狀態,且需求小于K。這意味著在決定[at]確認之后,[St+1]獨立于[Sk,Sk-1,...,Sk-∞],抗干擾決定已經確認,因此傳輸矩陣可以寫為:
[P(St+1|St,St-1,...,St-∞,at)]
[=P(st+1|st-T+1,at)]
[=P(St+1|St,at)]? ? ? (8)
因此,該過程是一個馬爾可夫決策過程(MDP) ,使用深度強化學習(DRL) 算法來處理MDP中的最優信道和功率決策問題。
2? 基于深度強化學習決策模型構建
DRL結合了深度學習的特征來提取特征和強化學習來處理未知環境下的任務,需要考慮環境中的多元變量[5],如圖1和圖2所示。
DRL網絡的輸入信息是S,稱為頻譜瀑布。S通過信號能量在以[?f]的頻率為間隔感知[St]的過程中產生,即[st=st,f0,st,f0+?f,...st,f],對應到[?t]時間為[St=St,St-?t,...,St-T],其中[f0]是信號能量檢測的起始頻率,f是感知過程的結束頻率,T是頻譜瀑布的時間長度,[St,f0]的計算過程如下:
[St,f0=10logf0f0+?f(gsU(f)+gjJ(f)+n(f))df)] (9)
由于S是時域疊加頻域疊加能量域的三維信息,所以狀態空間很大。在深度強化學習網絡的設計中,使用卷積層提取頻譜中的信息,利用全連接網絡對提取的頻譜信息進行合成。DRL網絡的輸出由信道頻率和功率聯合決定,網絡設計結構如圖3所示。
DRL網絡的輸出是傳輸功率和傳輸信道[at=(ft,pt),at∈A]共同的傳輸動作,其中A包含的動作數量為[n×m],因為集合[(Ps)=n],集合[(Fs)=m],如圖3中所示。接收機以ACK信號的形式送回通信決斷[at]的反饋[rt],[rt]的計算過程如下:
[r(at)=u(ft,pt)×(1-c(pt-plph-pl))] (10)
其中[ph]是集合[Ps]中的最大值,[ph=supPs],[pl]是集合[Ps]中的最小值,[pl=infPs]。[c∈(0,1)]是一個決策因子。各個動作對應的目標函數定義為:
[η=(r(a)+λmaxQ(S',a';θi-1))] (11)
其中[Q(S',a';θi-1)]是DRL的網絡函數,λ是學習率,S'是執行a之后的下一狀態,[θi-1]是第i-1次迭代中的網絡權重。根據定義的目標函數,損耗函數可定義為:
[L(θi)=[Q(S,a;θi)-ηi]2] (12)
基于最小化損失函數L,用梯度下降算法優化網絡權值θ。重放存儲器是用來保存訓練數據的數據集,并且重放存儲器M的大小為m。M中存儲的數據滿足先進先出(FIFO) 的原理。例如,在DRL的第k次迭代中,[M=ek,ek-1,...,ek-m+1],而[ek=(Sk,ak,ηk,Sk+1)].最終,在算法1中呈現出了提出的學習算法。需要注意的是,i不同于t。t是運行算法的時間,但i是更新DRL網絡的迭代次數。
3? 仿真分析驗證
3.1? 模擬仿真結果和分析
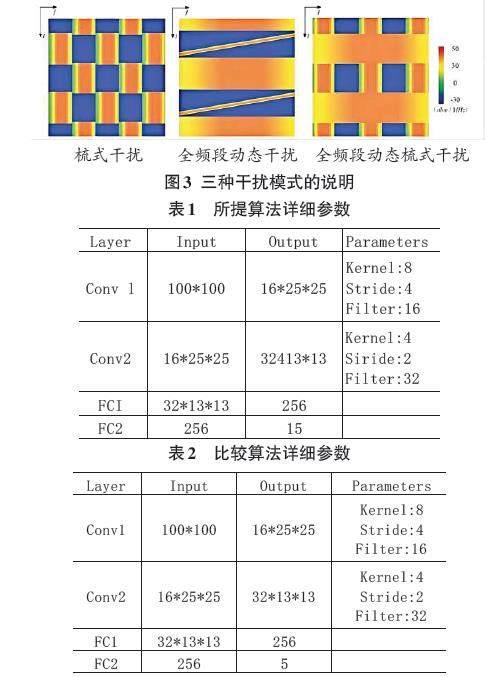
在模擬仿真中,發射機、接收機和干擾機都是在100MHz~110MHz的頻譜環境中。其中發射機以100kHz的間隔每1ms進行一次全波段感知,每5ms發送一次信號。發射功率分別選擇30dbm、35dbm、40dbm,發射機的信號帶寬為2MHz。中心頻率[f∈101,103,105,107,109],這意味著發射機具有[3×5=15]組動作。發射機的解調閾值為10db。對于代理機,決策因子設置為c=0.4,學習速率λ=0.2,代理機每1ms執行一次全頻帶感知。通道增益[gj=0.01,gs=0.01]。干擾信號和傳輸信號都是提升的余弦波形和偏離因子[η=0.4]。一次迭代的N是100。幾個模擬中考慮干擾模式:
1) 動態梳狀干擾:干擾信號中心頻率從101MHz、105MHz、109MHz至103MHz、107MHz。干擾頻帶為2MHz,干擾功率為40dbm。
2) 掃描、全波段動態干擾:每25 ms重復發生全波段干擾。這個掃描速度為0.4GHz/s,干擾功率為50dbm。
3) 梳式和全頻段動態干擾:干擾方式從梳式干擾(干擾信號中心頻率為101MHz、105MHz、109MHz)到每25ms全頻段干擾,干擾功率為50dbm。
在圖4中,結果表明在傳輸用戶的大功率信號時,干擾信號完全可以忽略。因此,高功率方案可以達到最大吞吐量,但能耗也是最高的。所提出和比較的算法需要訓練來提高吞吐量。可以看出,該算法經過40次迭代后,可達到最大吞吐量的95%。從圖5中可以看出,該算法可以在40次迭代中降低接近最低點的能量成本。在圖6中雖然總是有一個頻率可以避免干擾信號,但該算法可以正確地選擇低功率頻率,保持功率以低成本運行,如在40次迭代后保持低功率方案。
4? 結束語
根據研究,深度強化學習在動態抗干擾系統中具有優勢,能夠自動學習并調整策略,實時調整系統的抗干擾策略,通過與環境的交互,不斷嘗試不同的策略,并通過獎勵信號來評估策略的好壞。
本文研究了抗干擾通信中的功率和通信頻率的優化問題,將該問題表述為馬爾可夫決策過程(MDP) ,提出了基于深度強化學習(DRL) 的抗干擾算法決策模型,該算法可以同時切換頻率和功率。仿真結果表明,該算法在降低能耗的同時,實現了高吞吐量。
參考文獻:
[1] GWON Y,DASTANGOO S,FOSSA C,et al.Competing Mobile Network Game:embracing antijamming and jamming strategies with reinforcement learning[C]//2013 IEEE Conference on Communications and Network Security (CNS).October 14-16,2013.National Harbor,MD,USA.IEEE,2013:28-36.
[2] SLIMENI F,SCHEERS B,CHTOUROU Z,et al.Jamming mitigation in cognitive radio networks using a modified Q-learning algorithm[C]//2015 International Conference on Military Communications and Information Systems (ICMCIS).May 18-19,2015.Cracow,Poland.IEEE,2015:1-7.
[3] HANAWAL M K,ABDEL-RAHMAN M J,KRUNZ M.Joint adaptation of frequency hopping and transmission rate for anti-jamming wireless systems[J].IEEE Transactions on Mobile Computing,2016,15(9):2247-2259.
[4] 李芳,熊俊,趙肖迪,等.基于快速強化學習的無線通信干擾規避策略[J].電子與信息學報,2022,44(11):3842-3849.
[5] 郭振焱.復雜對抗環境下的通信抗干擾策略生成方法[D].成都:電子科技大學,2022.
【通聯編輯:朱寶貴】
