基于最大聯盟粗糙集的三支聚類
2024-08-15 00:00:00陳之琪萬仁霞岳曉冬陳瑞典
計算機應用研究 2024年8期













摘 要:針對鄰域粗糙集模型受鄰域參數影響大、刻畫樣本信息時不夠精細等問題,提出了一種基于最大聯盟理論的粗糙集模型。在標準化鄰域信息系統后,引入最大聯盟集來描述鄰域顆粒信息,使得鄰域粗糙集模型對信息的劃分更加精細,從而顯著降低了邊界域的不確定性。將該模型與三支聚類相結合,設計了一種基于最大聯盟粗糙集的三支聚類算法。在6個UCI公共數據集上進行對比實驗,結果表明,所提算法相較于對比算法具有更好的聚類質量,在處理邊界域樣本時具有更高的比較正確率。
關鍵詞:標準化鄰域信息系統; 最大聯盟集; 領域粗糙集; 邊界域; 三支聚類; 比較正確率
中圖分類號:TP391 文獻標志碼:A
文章編號:1001-3695(2024)08-007-2292-09
doi:10.19734/j.issn.1001-3695.2023.12.0582
Three-way clustering algorithm based on maximum coalition rough set
Chen Zhiqi1, Wan Renxia1, Yue Xiaodong2, Chen Ruidian3
(1.College of Mathematics & Information Science, North Minzu University, Yinchuan 750021, China; 2.School of Computer Engineering & Science, Shanghai University, Shanghai 200444, China; 3.Hongyang Institute for Big Data in Health, Fuzhou 350002, China)
Abstract:In order to address the limnK9/OI5+92Gg3hqxzIj3st+kscQHWd+Vpo2yVP+X3yw=itations of the neighborhood rough set model caused by neighborhood parameters and inadequate sample information representation, this paper proposed a rough set model based on the maximum coalition theory. By normalizing the neighborhood information system and utilizing the maximum coalition set to describe neighborhood granular information, the proposed model enabled finer information division and significant reduction of uncertainty in the boundary region. Combining the model with three-way clustering, this paper designed a three-way clustering algorithm based on maximum coalition rough set. Comparative experiments on six UCI public data sets show that the proposed algorithm has better clustering quality than the comparison algorithms, and has higher comparison accuracy when dealing with boundary region samples.
Key words:standardized neighborhood information system; maximum coalition set; neighborhood rough sets; boundary region; three-way clustering; comparison accuracy
0 引言
粗糙集理論是在1982年由波蘭數學家Pawlak教授[1]提出的一種用于處理不確定性知識或不一致信息的數據推理方法。經典Pawlak粗糙集模型是以等價關系和等價類為基礎的一種粒度計算模型,用于處理名義型數據,而無法直接處理數值型數據。為了突破這種限制,一些學者延伸拓展出了更多其他類型的粗糙集模型。Yao等人[2]通過引入條件概率提出了決策粗糙集模型。Azam等人[3]通過權衡策略將邊界域內的樣本劃分給正域或負域時的不確定性,使之達到最佳平衡,提出了博弈粗糙集模型。Lin[4]結合拓撲學中內點和閉包的知識,提出了鄰域模型的概念,該模型將空間中點的鄰域作為基本信息粒子對論域進行粒化。文獻[5,6]分別提出了1-step鄰域和k-step鄰域,并對鄰域信息系統的性質進行了詳細討論。胡清華等人[7]將鄰域的概念引入到粗糙集理論中,用鄰域關系代替嚴格的等價關系,提出了能夠處理混合型數據的鄰域粗糙集模型。Lin等人[8]將鄰域粗糙集和多粒度粗糙集相結合,構造了鄰域多粒度粗糙集模型。Wang等人[9]基于鄰域的思想,定義了局部近似集,提出了局部鄰域粗糙集模型。Wang等人[10]結合了δ鄰域和k近鄰顆粒的優點,提出了k最近鄰域粗糙集模型。當前,鄰域粗糙集已成為處理數值數據被廣泛使用的粗糙集模型之一。
聚類分析[11]是數據挖掘中的一項重要技術,是一種無監督的機器學習技術,已經廣泛地應用于多個領域,如模式識別、圖像處理、統計學、生物信息學、信息粒化等。所謂聚類,就是將數據集中相似度高的樣本劃分到相同類簇,相似度低的樣本劃分到不同類簇。大多數的傳統聚類算法都是硬聚類算法,要求聚類結果具有清晰的邊界,即元素要么屬于一個類,要么不屬于一個類。然而,在處理不確定信息時,考慮到當前可用信息的不充分性,若強制將元素劃分到某個類中,通常會導致較高的錯誤率或決策風險。
目前,已經有許多新的聚類策略被提出,用來解決傳統聚類方法存在的問題。Yao[12]于2010年提出了一種符合人類認知能力的三支決策模型,為粗糙集的正域、負域、邊界域提供了合理的語義解釋。錢文彬等人[13]針對不完備混合決策系統構造了三種決策風險下的三支決策模型。呂艷娜等人[14]通過改變粒度選擇方式重新構建多粒度空間,提出了基于深度置信網絡的代價敏感多粒度三支決策模型。于洪[15]將三支決策思想融入到傳統聚類中,提出了一種基于K-means的三支決策聚類算法,用核心域、邊界域和瑣碎域來表示一個類簇。劉強等人[16]利用元素的鄰域在二支聚類的結果上進行收縮和擴張,提出了一種基于ε鄰域的三支聚類算法。萬仁霞等人[17]考慮分類錯誤的風險代價,將數據對象屬于各個類簇的后驗概率作為決策評價函數,提出了基于三支決策的高斯混合聚類算法。花遇春等人[18]利用樸素貝葉斯確定兩樣本的共現概率,提出了基于共現概率的三支聚類模型。申秋萍等人[19]通過考慮近鄰的標簽,對二支聚類結果的臨界點和噪聲點進行重新劃分,提出了基于局部半徑的三支DBSCAN算法。相比于傳統的聚類方法,三支聚類在處理不確定性和模糊性較高的數據時更具優勢,更能適應實際情況中存在的多樣性和交叉性。
Pawlak[20]定義了具有支持、中立、反對評價的三值信息系統,給出了三值信息系統中計算輔助函數和距離函數的方法,用于確定不同代理間的沖突、中立和聯盟關系。然而,在任意聯盟集中,給定代理與其他代理之間都存在聯盟關系,但并非所有代理之間都是兩兩聯盟的。為此,Lang等人[21]在決策粗糙集理論的基礎上,提出了動態信息系統中的概率沖突集、中立集和聯盟集的增量構造方法,并給出了最大聯盟集的概念,使得最大聯盟集中任意兩代理之間都滿足聯盟關系。郭淑蓉[22]針對計算最大聯盟集時運算量較大的問題,通過將參數β區間化,把無限多個最大聯盟集的計算問題減少為有限多個,從而提高了計算效率。羅珺方等人[23]在不完備異構沖突信息系統中,定義了極大一致聯盟區間集族,并利用極大團的枚舉算法進行獲取。
使用粗糙集模型刻畫樣本信息時,本文希望通過壓縮邊界域來減少信息的不確定性,以提高分類精度。而最大聯盟集使得數據對象之間的關系更加緊密,且相較于δ鄰域顆粒信息,可以更為細致地刻畫樣本信息,為解決不確定性問題提供了新的思路。本文通過引入最大聯盟集的相關概念,提出了基于最大聯盟的鄰域粗糙集模型,并基于該模型設計了一種新的三支聚類算法。
1 預備知識
1.1 鄰域粗糙集
在決策分析中,通常各指標間的計量單位和數量級不盡相同,從而使得各指標之間不具備綜合性,數據標準化旨在消除各指標量綱之間的影響,有助于確保數據的質量和一致性。
定義1 設NS=(U,A,V,f,δ)為一個鄰域信息系統,其中論域U={x1,x2,…,xn},屬性集A=C∪D,C是條件屬性,D是決策屬性,值域V={Va|a∈A},f:U×A→V為信息函數,f(x,a)表示對象x在屬性a上的值,δ為鄰域半徑。對于任意實數p∈[1,+∞),ak∈A,xiU,映射函數(xi,ak)定義如下:
(xi,ak)=f(xi,ak)-fmin(x,ak)fmax(x,ak)-fmin(x,ak)×1pn
其中:fmax(x,ak)和fmin(x,ak)分別為對象x在屬性ak上的最大值和最小值。
映射函數將所有數據信息縮放到區間[0,1/pn]上,起到了標準化作用。后文中,本文用NSnorm=(U,A,V,f,δ)表示NS=(U,A,V,f,δ)標準化后的鄰域信息系統。
定義2[7] 設鄰域信息系統NSnorm=(U,A,V,f,δ),對于ak∈A,xi,xj∈U,則xi和xj之間的距離函數Δ(xi,xj)為
Δ(xi,xj)=(∑nk=1(xi,ak)-(xj,ak)p)1p
其中:當p=1時,為曼哈頓距離;當p=2時,為歐氏距離;當p=3時,為切比雪夫距離。
性質1 設鄰域信息系統NSnorm=(U,A,V,f,δ),對于xi,xj∈U,有0≤Δ(xi,xj)≤1。
證明 由定義1可知,0≤f(xi,ak)≤1/pn≤1,則0≤f(xi,ak)-f(xj,ak)≤1/pn。對于p∈[1,+∞),有0≤f(xi,ak)-f(xj,ak)p≤1/n,則0≤∑nk=1f(xi,ak)-f(xj,ak)p≤1,故而0≤(∑nk=1f(xi,ak)-f(xj,ak)p)1p≤1。
定義3[7] 設鄰域信息系統NS=(U,A,V,f,δ),對于xi∈U,特征子集BA,xi在B上的δ鄰域定義如下:δB(xi)={xj|xj∈U,ΔB(xi,xj)≤δ}
其中:ΔB(xi,xj)表示在特征子集B上xi和xj之間的距離,樣本xi的鄰域是由距離函數Δ、鄰域半徑δ和屬性集合B共同決定的。
定義4[7] 設鄰域信息系統NS=(U,A,V,f,δ),對于BA,XU,則X關于B的鄰域下近似集、上近似集、正域、負域和邊界域分別為
下近似集:NB(X)={xi|δB(xi)X,xi∈U}
上近似集:B(X)={xi|δB(xi)∩X≠,xi∈U}
正域:POSB(X)=N(X)
負域:NEGB(X)=U-(X)
邊界域:BNB(X)=(X)-N(X)
其中:(NB(X),B(X))稱為δ鄰域粗糙集。
1.2 最大聯盟集
定義5[21] 設鄰域信息系統NS=(U,A,V,f,δ),閾值α、β滿足0≤β<α≤1,對于BA,xU,x的概率沖突集、中立集和聯盟集分別為
a)沖突集:COαβ(x)={y∈U|ΔB(x,y)>α};
b)中立集:NEαβ(x)={y∈U|α≥ΔB(x,y)≥β};
c)聯盟集:ALαβ(x)={y∈U|ΔB(x,y)<β}。
由定義5可得,若β=δ,則ALαβ(x)=δ(x),即x的概率聯盟集就是x的δ鄰域。
定義6[21] 設鄰域信息系統NS=(U,A,V,f,δ),閾值α、β滿足0≤β<α≤1,BA,XU:
a)若x,y∈X,ΔB(x,y)<β,則稱X為一個聯盟集;
b)若X為一個聯盟集,并且不存在聯盟集Y,使得XY,則稱X為一個最大聯盟集。
定理1[21] 設鄰域信息系統NS=(U,A,V,f,δ),XU且0≤β≤α≤1,則X為最大聯盟集的充要條件為
∩x∈XALαβ(x)=X
命題1[21] 設鄰域信息系統NS=(U,A,V,f,δ),MC={MC1,MC2,…,MCp}是論域U中全體最大聯盟集的集合,則
∩1≤i≤pMCi=U
1.3 三支聚類
Yu等人將三支決策引入到聚類算法中,提出了三支聚類方法。給定一個數據集U={x1,x2,…,xn},可獲得聚類結果C={C1,C2,…,Ck}。三支聚類在傳統的二支聚類結果中加入了邊界域的概念,用三個互不相交的集合表示一個類,即Co(Ci)、Fr(Ci)與Tr(Ci),分別稱為類Ci的核心域、邊界域和瑣碎域。其中,核心域中的對象確定屬于這個類,邊界域中的對象可能屬于這個類,瑣碎域中的元素肯定不屬于這個類,它們滿足如下性質:
a)Co(Ci)≠,i=1,2,…,k。
b)∪ki=1(Co(Ci)∪Fr(Ci))=U。
c)Co(Ci)∩Co(Cj)=,i≠j。
其中:性質a)要求每個類簇的核心域不能為空;性質b)確保所有對象都能被有效劃分;性質c)要求不同類簇的核心域之間沒有交集。
三支聚類的結果表示如下:
TC={(Co(C1),Fr(C1)),(Co(C2),Fr(C2)),…,(Co(Ck),Fr(Ck))}
劉強等人[16]利用每個類中元素的δ鄰域進行收縮和擴張,提出了一種基于動態鄰域的三支聚類算法。該算法的大致流程如下:
a)利用硬聚類算法對U進行聚類,得到聚類結果C={C1,C2,…,Ck};
b)對于每一類Ci,任取xj∈Ci,若δ(xj)Ci,則xj∈Co(Ci),否則xj∈Fr(Ci);
c)對于每一類Ci,任取xjCi,若δ(xj)∩Ci≠,則xj∈Fr(Ci);
d)得到最終聚類結果為
TC={(Co(C1),Fr(C1)),(Co(C2),Fr(C2)),…,(Co(Ck),Fr(Ck))}
2 基于最大聯盟粗糙集的三支聚類
本章定義了最大聯盟集的緊致度公式,用于確定每個對象最緊致的最大聯盟集,并將其作為一種新的鄰域顆粒信息與粗糙集模型相結合,構造了最大聯盟粗糙集模型,然后將該模型應用于聚類分析中,提出了基于最大聯盟的三支聚類算法。
2.1 基于最大聯盟的粗糙集模型
給定鄰域信息系統NSnorm=(U,A,V,f,δ),MC={MC1,MC2,…,MCp}是論域U中全體最大聯盟集的集合,MC(xi)={MC1(xi),MC2(xi),…,MCt(xi)}是論域U中包含xi的所有最大聯盟集的集合,其中t≤p。
定義7 樣本點xi的局部密度為
ρ(xi)=MCk(xi)∑xj∈MCk(xi)exp(-dij) if MCk(xi)>10if MCk(xi)=1
其中:|MCk(xi)|表示xi的最大聯盟集中的樣本點數量;dij表示樣本點xi與xj之間的距離,樣本點xi的局部密度是由集合的樣本數量和各點到該樣本點的距離共同決定的。
定義8 x,y∈MCk(xi),最大聯盟集MCk(xi)的緊致度定義如下:
Euclid Math OneTAp(MCk(xi))=ρ(xi)+12∑x∑yexp(-d(x,y))
分析上式可知,Euclid Math OneTAp反映了最大聯盟集MCk(xi)在空間中的緊密程度。將MC(xi)按緊致度從大到小依次排列{MC1′(xi),MC2′(xi),…,MCt′(xi)},得到與xi緊密程度最高的最大聯盟集MCbest(xi)=MC1′(xi)。
定義9 設NSnorm=(U,A,V,f,δ)是鄰域信息系統,XU,定義X基于最大聯盟集的下近似集、上近似集、正域、負域和邊界域分別為
下近似集:M(X)={xi|MCbest(xi)X,xi∈U}
上近似集:(X)={xi|MCbest(xi)∩X≠,xi∈U}
正域:MPOS(X)=M(X)
負域:MNEG(X)=U-(X)
邊界域:BM(X)=(X)-M(X)
稱(M(X),(X))為最大聯盟粗糙集。
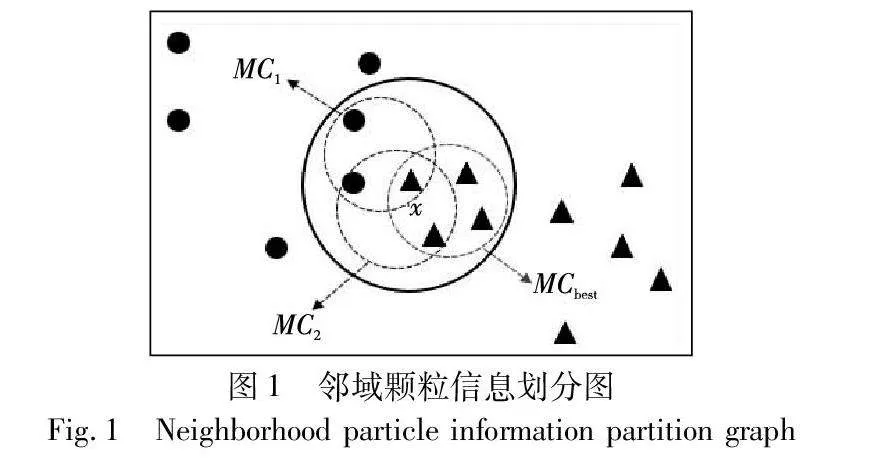
如圖1所示,采用δ鄰域和最大聯盟集分別刻畫樣本x的鄰域信息,其中,實心圓形和實心三角形分別代表兩類樣本,實線圓圈表示x的δ鄰域,虛線圓圈表示x的3個最大聯盟集,紅色虛線圓則表示與x緊密程度最高的最大聯盟集(參見電子版)。觀察x的δ鄰域,可以發現兩種類型的樣本都包含其中,根據δ鄰域粗糙集的定義,樣本x將被劃分到邊界域中。再分別觀察x的三個最大聯盟集,根據最大聯盟粗糙集的定義,在鄰域粒度MC1(x)下,樣本x將被錯誤地劃分到實心圓類別中;在鄰域粒度MC2(x)下,樣本x將被劃分到邊界域中;而在鄰域粒度MCbest(x)下,樣本x將被劃分到實心三角形類別中,從而得到最正確的劃分。
關于最大聯盟粗糙集,本文有以下一些重要性質。
性質2 設鄰域信息系統NSnorm=(U,A,V,f,δ),對于XU,有:
a)M(X)X(X);
b)M()=()=,M(U)=(U)=U;
c)M(X∩Y)=M(X)∩M(Y),(X∪Y)=(X)∪(Y);
d)若XY,則M(X)M(Y),(X)(Y);
e)M(X∩Y)M(X)∩M(Y),(X∩Y)(X)∩(Y);
f)M(~X)=~(X),(~X)=~M(X)。
證明 a)設xi∈M(X)MCbest(xi)X,因為xi∈MCbest(xi),所以xi∈X,故M(X)X;設xi∈XMCbest(xi)∩X≠xi∈(X),故X(X)。
b)由a)知,M(),而M(),所以M()=;假設()≠,則存在xi使得xi∈(),即MCbest(xi)∩≠,而MCbest(xi)∩=與假設矛盾,因此()=;xi∈UMCbest(xi)Uxi∈M(U)UM(U),由a)知,M(U)U,故M(U)=U;由a)知,U(U),但(U)U,因此(U)=U。
c)對于xi∈M(X∩Y)MCbest(xi)X∩YMCbest(xi)X∧MCbest(xi)Yxi∈M(X)∩M(Y),因此M(X∩Y)=M(X)∩M(Y);xi∈(X∪Y)MCbest(xi)∩(X∪Y)≠(MCbest(xi)∩X)∪(MCbest(xi)∩Y)≠MCbest(xi)∩X≠∨MCbest(xi)∩Y≠xi∈(X)∨xi∈(Y)xi∈(X)∪(Y),因此(X∪Y)=(X)∪(Y)。
d)設XY,則X∩Y=X,X∪Y=Y,所以M(X∩Y)=M(X),(X∪Y)=(Y),由c)知,M(X)∩M(Y)=M(X),(X)∪(Y)=(Y),故M(X)M(Y),(X)(Y)。
e)因XX∪Y,YX∪Y,所有M(X)M(X∪Y),M(Y)M(X∪Y),故M(X)∩M(Y)M(X∩Y);因為X∩YX,X∩YY,所以(X∩Y)(X),(X∩Y)(Y),故(X∩Y)(X)∩(Y)。
f)對于xi∈M(X)MCbest(xi)XMCbest(xi)∩~X=xi(~X)xi∈~(~X),因此M(X)=~(~X),故而M(~X)=~(X)。
性質3 設NSnorm=(U,A,V,f,δ)是鄰域信息系統,0≤β<α≤1且β=δ,XU,有:
a)MCbest(xi)δ(xi),xi∈U;
b)N(X)M(X);
c)(X)(X);
d)BM(X)BN(X)。
證明 a)由定理1可知,MC(xi)AL(xi)。又當β=δ時,AL(xi)=δ(xi),故MC(xi)δ(xi)。因為MCbest(xi)MC(xi),所以MCbest(xi)δ(xi)。
b)因為xi∈N(X)δ(xi)XMCbest(xi)X,則有xi∈M(X),所以N(X)M(X)。
c)因為xi∈(X)MCbest(xi)∩X≠δ(xi)∩X≠,則有xi∈(X),所以(X)(X)。
d)由b)和c)的證明可知,BM(X)=(X)-M(X)(X)-N(X)=BN(X)。
定義10 設NSnorm=(U,A,V,f,δ)是鄰域信息系統,屬性集A=C∪D,C是條件屬性,D是決策屬性,U/D={D1,D2,…,Dr}為論域U在決策特征D上的等價劃分。決策相對應的屬性子集的正域、負域和邊界域分別定義如下:
正域:MPOS(D)=∪rj=1M(Dj)
負域:MNEG(D)=U-∪rj=1(Dj)
邊界域:BM(D)=∪rj=1(Dj)-∪rj=1M(Dj)
顯然,正域和邊界域是互補的,正域是由所有決策類下近似的并集構成。
2.2 基于最大聯盟粗糙集的三支聚類算法
相對于經典粗糙集,最大聯盟粗糙集為數據對象提供了更加豐富的鄰域顆粒信息,將最大聯盟粗糙集模型與三支決策理論相結合,用產生的三支聚類結果代替傳統的二支聚類結果,有效規避了直接作出屬于某一類或不屬于某一類決策所帶來的潛在風險,將為分析數據對象間的關系提供更可靠的信息支持。
設對象集U的k個聚類結果是C={C1,C2,…,Ck},則Ci的核心域Co(Ci)和邊界域Fr(Ci)分別表示為Co(Ci)=M(Ci),Fr(Ci)=(Ci)-M(Ci)。三支聚類結果可以表示為
TC={(Co(C1),Fr(C1)),(Co(C2),Fr(C2)),…,(Co(Ck),Fr(Ck))}
基于最大聯盟粗糙集的三支聚類算法具體步驟如下:
輸入:數據集U={x1,x2,…,xn},參數k、q。
輸出:聚類結果{(Co(C1),Fr(C1)),(Co(C2),Fr(C2)),…,(Co(Ck),Fr(Ck))}。
a)利用硬聚類算法對U進行聚類,得到C={C1,C2,…,Ck};
b)對于任意xi,xj∈U,根據定義2計算任意兩點之間的距離Δ(xi,xj),找到每個樣本點xi的δ鄰域集δ(xi)={xj|xj≤q};
c)確定U中滿足條件∩x∈MCkδ(x)=MCk的所有最大聯盟集MC={MC1,MC2,…,MCp};
d)對于任意xi∈U,依次遍歷U中所有的最大聯盟MC,篩選出xi的所有最大聯盟集的集合MC(xi)={MC1(xi),MC2(xi),…,MCt(xi)},根據定義8中的緊致度公式,找到與xi緊密程度最高的最大聯盟集MCbest(xi);
e)對于每一類Ci,任取xj∈Ci,若MCbest(xi)Ci,則xj∈Co(Ci),否則xj∈Fr(Ci);
f)對于每一類Ci,任取xjCi,若MCbest(xi)∩Ci≠,則xj∈Fr(Ci);
g)通過步驟e)和f)得到Co(Ci)和Fr(Ci)(i=1,2,…,k),返回最終聚類結果{(Co(C1),Fr(C1)),(Co(C2),Fr(C2)),…,(Co(Ck),Fr(Ck))}。
其中,步驟c)可以簡化為:(a)如果δ(x)={x},則{x}是一個最大聯盟集,接下來僅需考慮U/{x|δ(x)={x}};(b)假設δ(x)=X,且X>1,取y∈X/{x},計算δ(x)∩δ(y)。若δ(x)∩δ(y)={x,y},則{x,y}是一個最大聯盟集,否則,取z∈{δ(x)∩δ(y)}/{x,y}。若δ(x)∩δ(y)∩δ(z)={x,y,z},則{x,y,z}是一個最大聯盟集,否則,重復上述直至滿足對于YX,∪x∈Yδ(x)=Y。
3 評價指標
3.1 不確定性評價
粗糙集理論中的不確定性度量是評價系統分類能力及提高分類精度的重要工具,國內外眾多學者對此進行了研究。設鄰域信息系統NS=(U,A,V,f,δ), C是條件屬性,D是決策屬性,A=C∪D,U/D={D1,D2,…,Dm}是對象集U在決策特征D上的等價劃分,本文采取以下三個指標進行評價:
a)鄰域近似精度[24]:
αδB(D)=∑mi=1Di∑mi=1Di
b)鄰域信息熵[24]:
Hδ(B)=1+1U∑|U|i=1nδB(xi)U lgUlg1|nδB(xi)|
c)加權鄰域信息熵[24]:
αH(d,B)=αδB(d)*Hδ(B)
3.2 聚類效果評價
本文選取三個經典的聚類指標準確率(ACC)、戴維森堡丁指數(DBI)和宏平均(Macro_F1)作為評估聚類算法的標準。
a)準確率(accuracy,ACC):
ACC=1N∑ki=1Ci
其中:數據集的大小為N,被成功劃分到類i的樣本數記為Ci,聚類數為k,ACC的取值為[0,1]。ACC值越大,表示聚類效果越好。本文通過計算核心域的樣本數據獲得ACC的取值。
b)戴維森堡丁指數(Davies-Bouldin index,DBI):
DBI=1k∑ki=1maxi≠j(S(Ci)+S(Cj)‖wi-wj‖2)
其中:S(Ci)表示第i類中的所有樣本元素到聚類中心wi的平均距離;‖wi-wj‖2表示類i與j之間的歐氏距離;k表示聚類數。DBI評價一個聚類結果好壞的依據是:要求類內元素相似度高,類間元素相似度低。DBI值越小,表示聚類結果越好,意味著簇內數據點更加緊密地聚集在一起,而簇與簇之間的區別更加明顯。
c)宏平均(Macro_F1)[25]:
Macro_F1=2MacroP×MacroRMacroP+MacroR
其中:MacroP=1k∑ki=1TPCiTPCi+FPCi,MacroR=1k∑ki=1TPCiTPCi+FNCi。TPCi表示core(Ci)中對象被正確分類為該類的數量,FPCi表示非core(Ci)中對象被錯誤分類為該類的數量,FNCi表示非core(Ci)中對象被正確分類為不屬于該類的數量。宏平均F1值綜合了精確率和召回率,用于衡量聚類結果的準確性和完整性。它是通過計算每個簇的F1值并求其平均值得到的,該值越大表示聚類結果越好。
由于三支聚類結果是由兩個區域近似表示的,所以僅使用硬聚類指標評價無法評估類簇的核心域和邊界域之間的關系,會導致評估結果不夠客觀和全面。因此,本文除選取上述三個常用的評價指標外,還選取了三個軟聚類評價指標對三支聚類效果進行評價:
d)所有正域的平均質量[26]:
γ=1n∑ki=1|Co(Ci)|
e)c個類簇的平均質量[27]:
α=1c∑ki=1|Co(Ci)||Co(Ci)|+|Fr(Ci)|
f)c個類簇的整體質量[27]:
α*=∑cj=1|Co(Ci)|∑cj=1|Co(Ci)|+|Fr(Ci)|
第一個軟聚類評價指標γ是由Maji提出的,用于衡量所有正域的平均質量,該值越大,表示聚類效果越好。在Maji的啟示下,Zhang提出了另外兩個軟聚類評價指標α和α*,分別用于衡量c個類簇的平均質量和整體質量。對于特定的類簇而言,核心域中的數據點越多,意味著有更多數據點被明確地歸屬于該類簇。也就是說,下近似與上近似中數據點數量的比率可以顯示聚類結果的質量。這兩個指標的數值越大,表示聚類效果越好。
4 實例分析與實驗驗證
4.1 實例分析
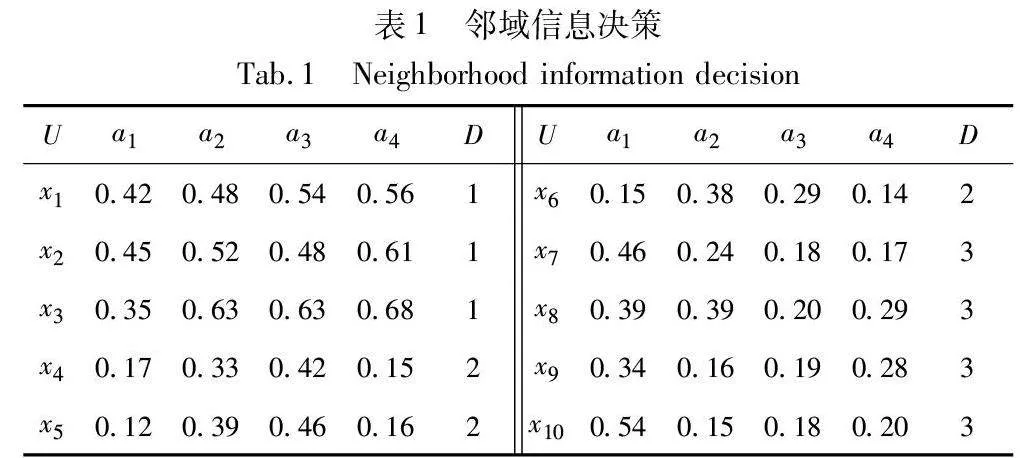
給定一個鄰域信息決策系統NS=(U,A,V,f,δ)[28],其中對象集U={x1,x2,x3,x4,x5,x6,x7,x8,x9,x10};條件特征集C={a1,a2,a3,a4};D為決策特征集,論域U在決策特征上等價劃分為U/D={D1,D2,D3},即D1={x1,x2,x3},D2={x4,x5,x6},D3={x7,x8,x9,x10},鄰域參數δ=β=0.25。通過鄰域信息決策表1對鄰域粗糙集模型和最大聯盟粗糙集模型進行不確定性度量。本文中的樣本(對象)的距離均采用歐氏距離進行計算。
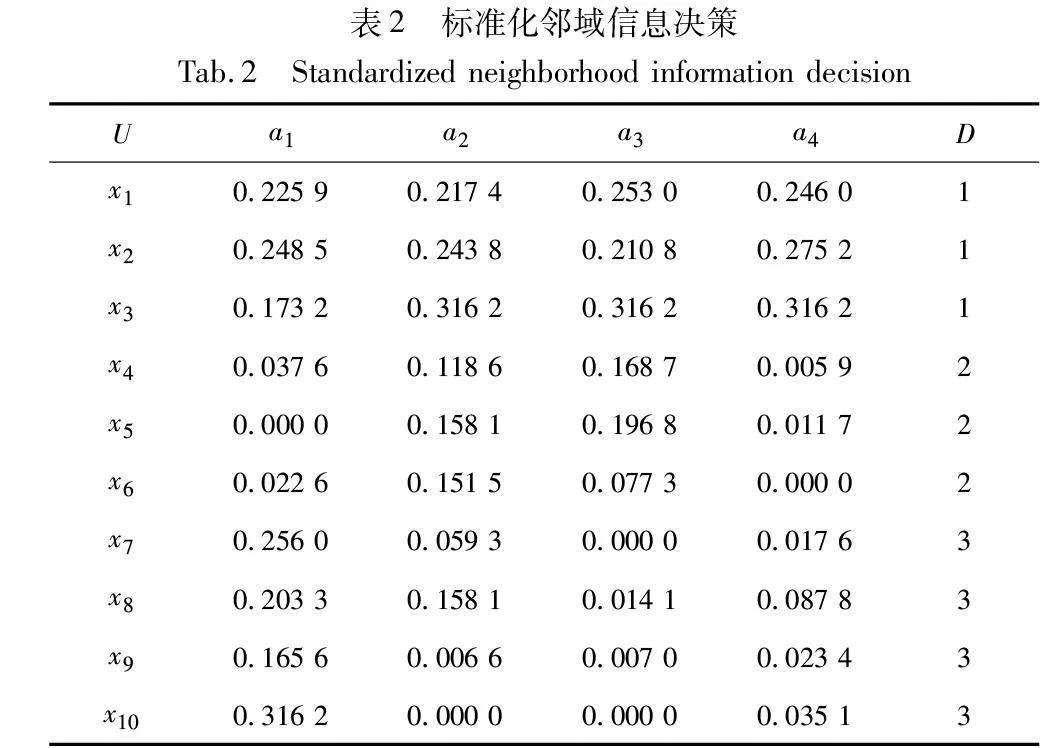
a)根據定義1中的映射函數,對該鄰域信息系統進行標準化處理,結果如表2所示。
b)找到每個對象的鄰域類δ(xi)和最優最大聯盟集MCbest(xi),結果如表3所示。
c)確定決策特征上等價劃分的上下近似集合,結果如表4所示。
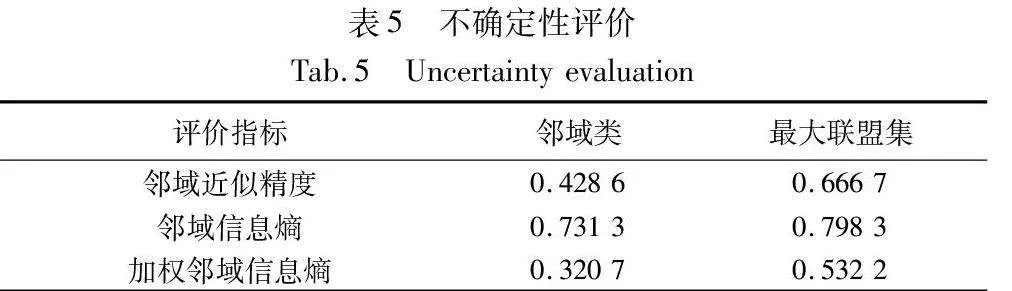
d)不確定性評價的結果如表5所示。
由表5的評價結果可知,最大聯盟粗糙集的鄰域近似精度、領域信息熵、加權鄰域信息熵均優于鄰域粗糙集模型。可以看出,相較于鄰域粗糙集模型,基于最大聯盟粗糙集提供了更精細的劃分信息,從而有效降低了邊界域的不確定性。
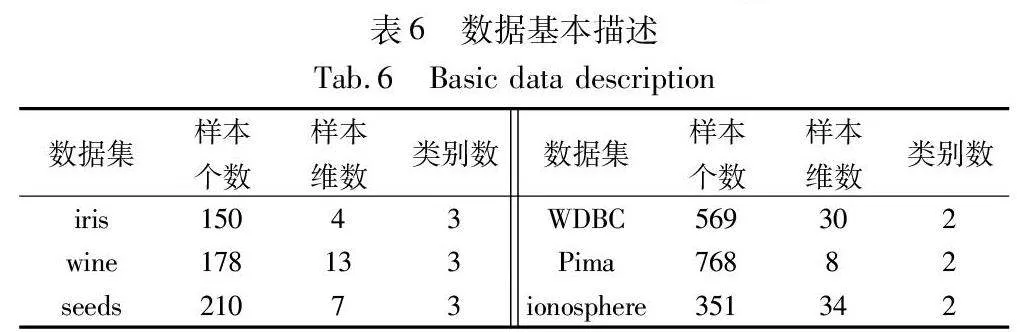
4.2 數據集上的實驗分析
為驗證基于最大聯盟粗糙集的三支聚類算法的有效性,本文選取了6組UCI數據集進行實驗,數據集的一些基本描述如表6所示。本次實驗采用Python編寫,在Windows 10企業版操作系統上運行,計算機配置為Intel CoreTM i5-4200U CPU,內存容量為16 GB,編碼環境選用Anaconda Spyder。
下面將本文所提出的基于最大聯盟粗糙集的三支聚類方法與基于k近鄰粗糙集的三支聚類方法[12](算法1)、基于δ鄰域粗糙集的三支聚類方法[16](算法2)、基于k最近鄰域粗糙集的三支聚類方法[10](算法3)進行比較。其中,算法3是將文獻[10]提出的k最近鄰域粗糙集模型引入三支聚類框架所得到的聚類算法。本實驗根據映射函數對數據進行標準化處理,針對部分實驗數據集特征維度較多的問題,采取PCA方法降維之后,選用傳統K-means算法進行初始聚類,算法1和3所用到的近鄰參數k取值為3,算法2和本文算法中所需鄰域參數δ取值相同,且取值在0~1。
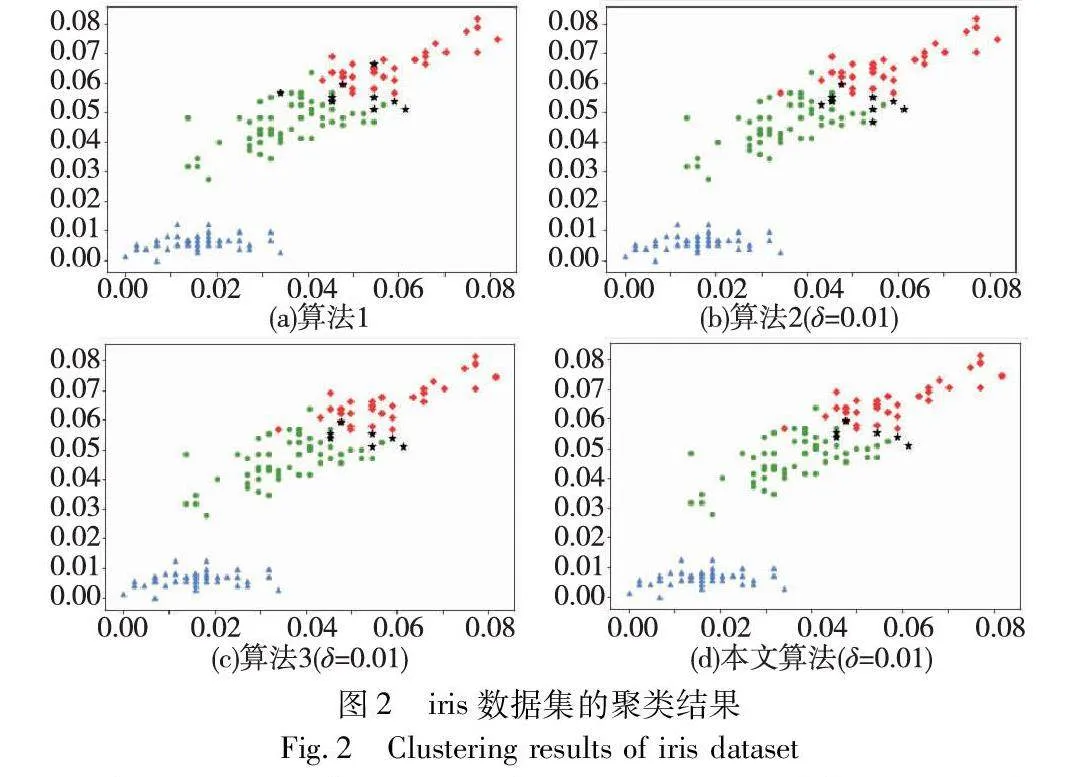
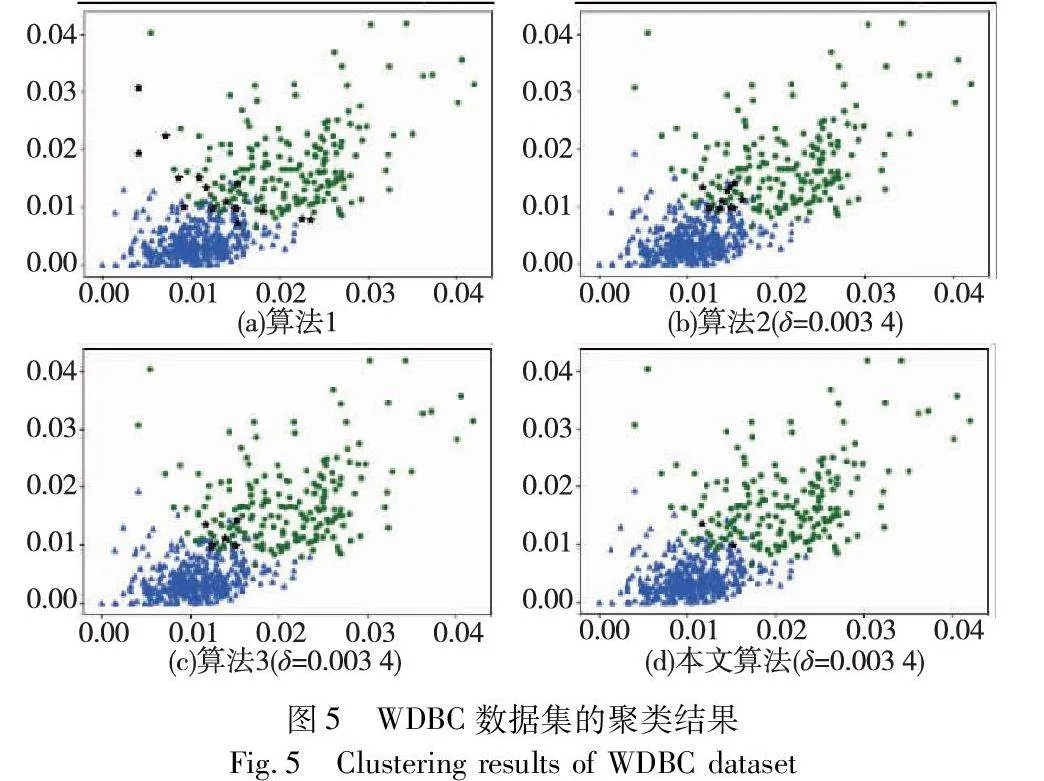
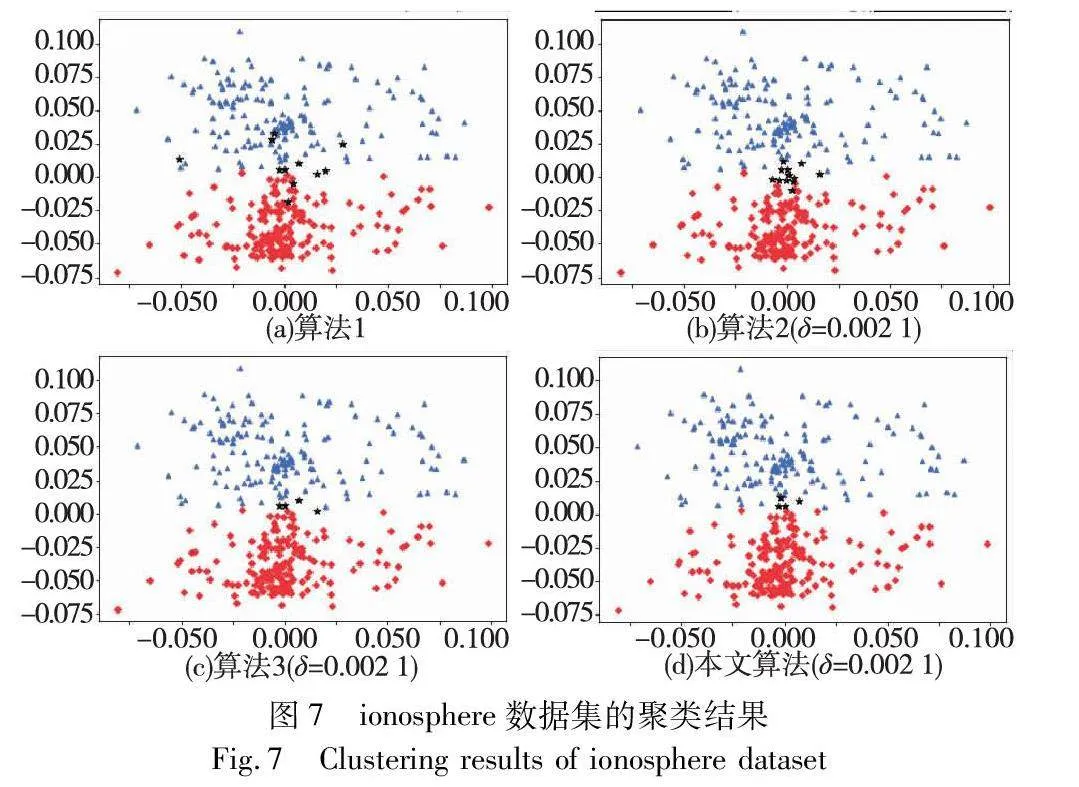
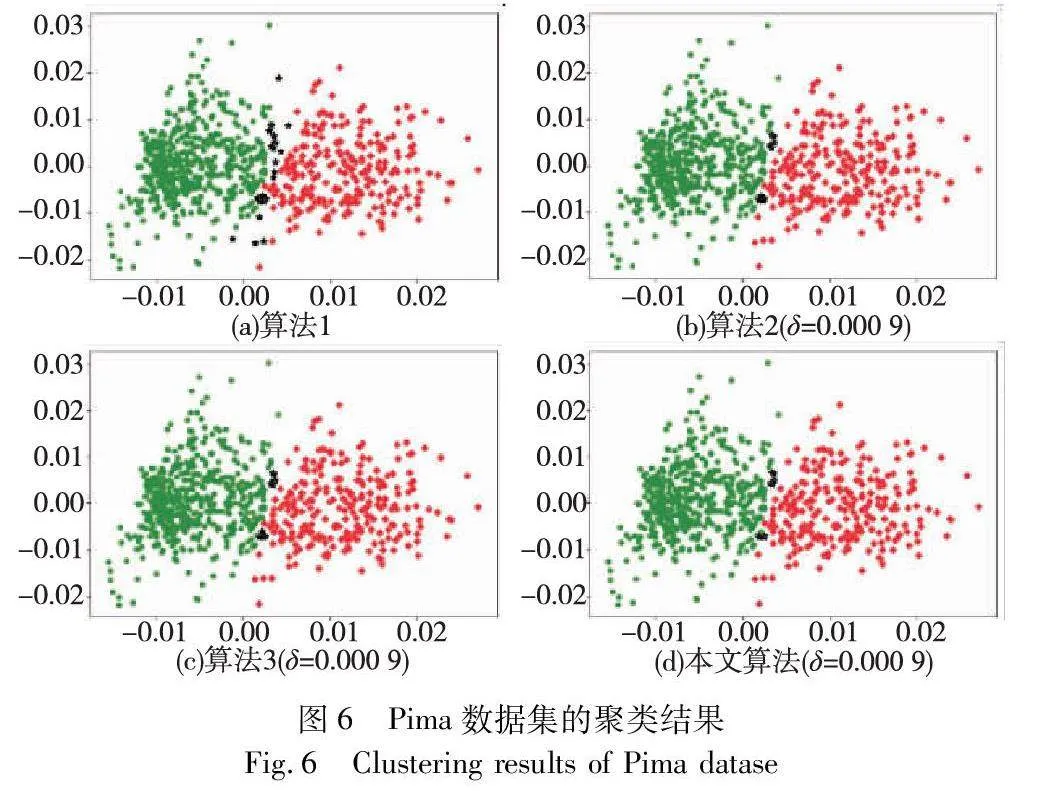
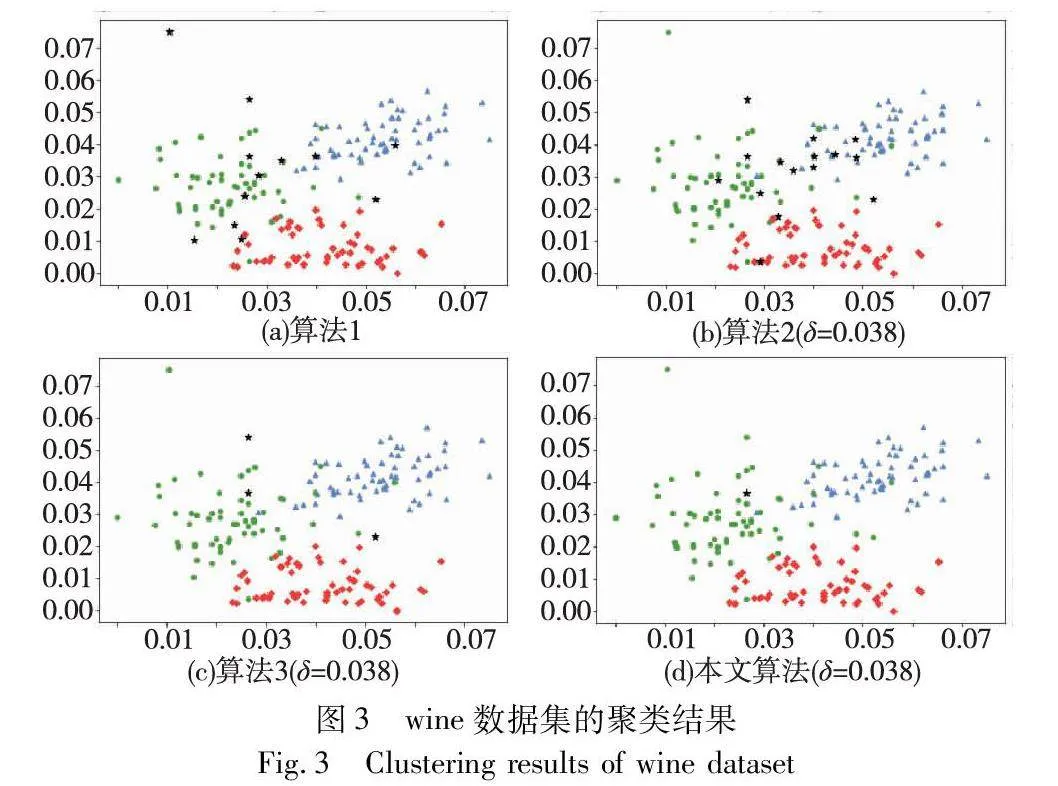
對實驗數據集分別進行三支聚類分析,得到如圖2~7所示的聚類結果對比圖。其中,每種顏色代表一個類簇,黑色五角星表示被劃分在邊界域的對象。在算法1~3和本文算法下,iris數據集邊界域內的樣本數量分別為9個、9個、7個和6個;wine數據集邊界域內的樣本數量分別為12個、15個、3個和1個;seeds數據集邊界域內的樣本數量分別為28個、15個、13個和8個;WDBC數據集邊界域內的樣本數量分別為17個、11個、7個和2個;Pima數據集邊界域內的樣本數量分別為23個、10個、10個和9個;ionosphere數據集邊界域內的樣本數量分別為11個、12個、4個和4個。可見,采用本文提出的聚類算法處理各個實驗數據集時,都能成功地將邊界域的樣本數量減至最少,可以更精確地劃分類與類的邊界域。
基于實驗所得的聚類結果,將本文算法與其他三種算法的評價指標進行對比,評價結果如表7所示。本文提出的基于最大聯盟粗糙集的三支聚類算法在wine、seed、WDBC和Pima數據集上的各個評價指標都有所提升,說明本文算法在這些數據集上的聚類效果明顯優于其他三種聚類算法。在ACC評價指標方面,本文算法在wine和WDBC數據集上表現最為突出,聚類準確率分別為94.94%和92.44%,同時,在其他數據集上本文算法的準確率也都是最高的。在DBI評價指標方面,本文算法在wine、seed、WDBC和Pima數據集上都具有最小的DBI值,說明對于這四種數據集,本文算法所得到的聚類結果相同,簇內數據點更加緊密,而不同簇之間的距離更遠,聚類效果更好,然而,本文算法在iris數據集上的DBI值略遜于算法3,在ionosphere數據集上的DBI值略遜于算法2,但由于差值較小,對聚類效果的影響有限。在宏平均F1評價指標方面,本文算法的F1值都是最高的,表明本文算法相較于其他三種算法在不同類別上的分類性能最好。
在γ評價指標方面,本文算法也表現出極佳的效果,在各個數據集上該指標值均達到95%以上,說明本文算法對數據集中大部分數據點都進行了明確劃分,僅保留較少部分數據點于邊界域中,得到的聚類結果中所有正域的平均質量更高。在α和α*評價指標方面,相較于其他三種算法,本文算法在各個數據集上的指標值均最高,并且都大于90%,說明本文算法所得到的類簇平均質量和整體質量都更高,聚類效果更好。
4.3 參數δ分析
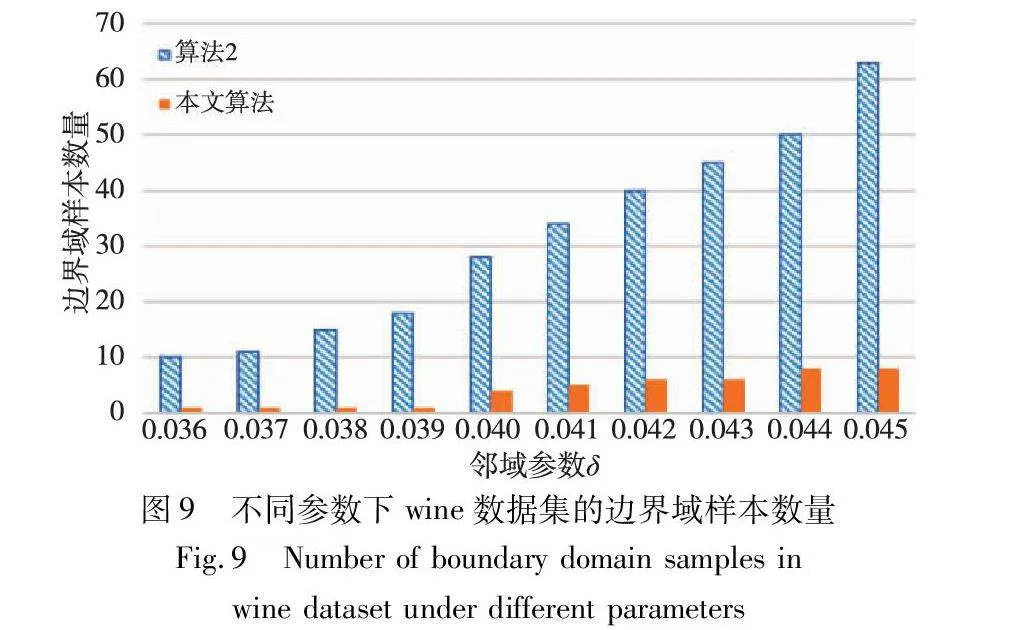
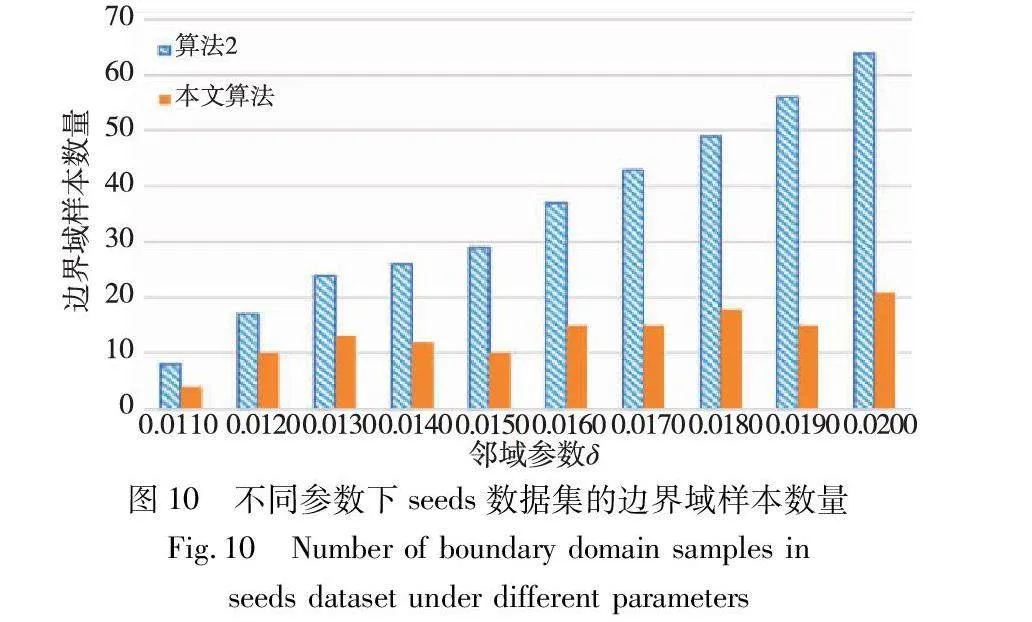
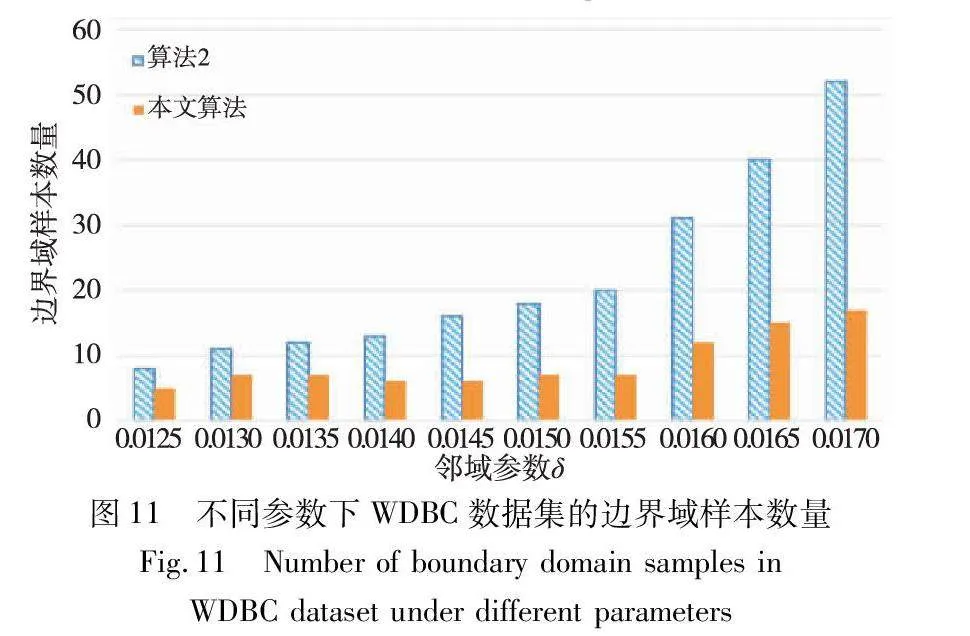
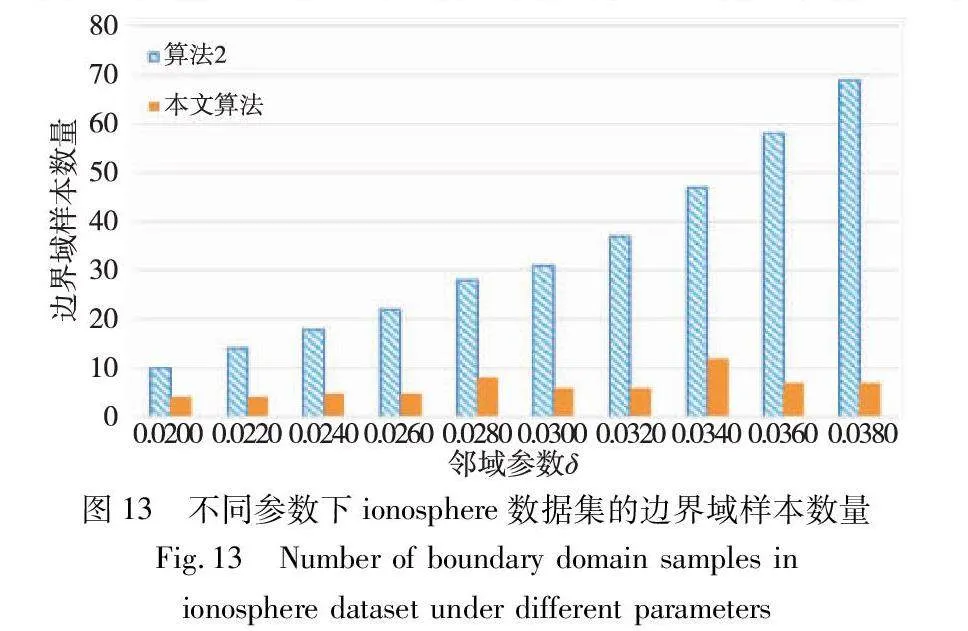
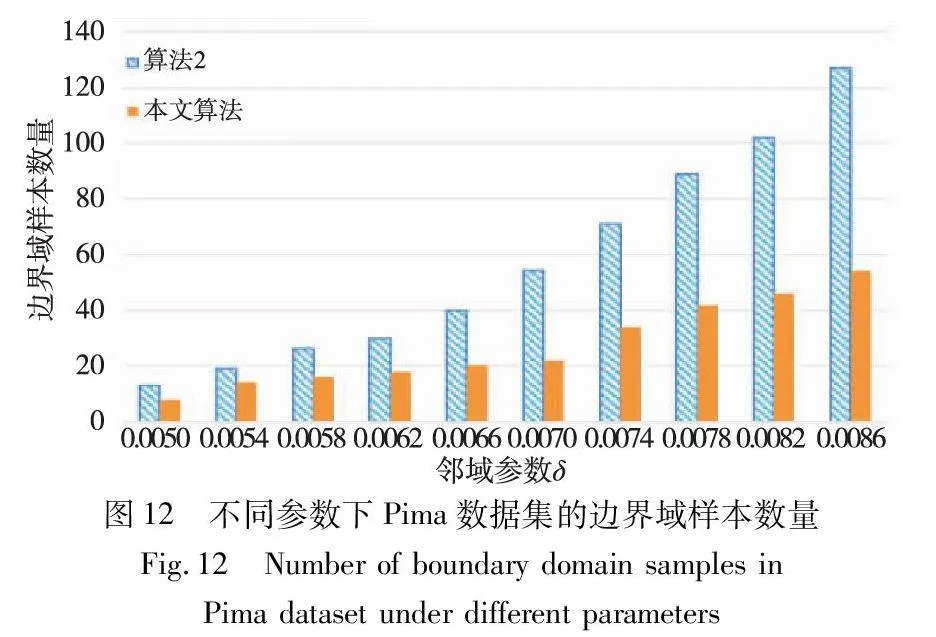
邊界域的劃分,是三支聚類效果和質量最直接的反映。本文算法中,鄰域半徑δ的取值直接影響三支聚類邊界域的劃分,在不同的δ取值下,算法得到的邊界域不同,從而影響三支聚類的精度。為了分析參數δ對邊界域產生的影響,本文針對各個實驗數據集,分別考察了鄰域參數δ在給定取值區間上產生邊界域對象的情況,并與同為基于δ鄰域技術的算法2進行對比,實驗結果如圖8~13所示。
隨著δ值的增加,算法2中的δ鄰域顆粒信息不斷擴大,使得該算法在三支劃分階段將較多的樣本歸于邊界域中,增大了聚類結果的不確定性。然而,本文算法所使用的鄰域顆粒信息MCbest,相對于鄰域參數δ的取值大小并不呈現單調關系,受參數影響較小,從而產生相對穩定的三支聚類結果。從圖8~13可以看出,隨著δ值的增加,算法2得到的邊界域樣本個數呈明顯的上升趨勢,而本文算法得到的邊界域樣本個數保持相對穩定,這表明本文算法在不同鄰域參數δ下可以得到較為穩定的聚類結果,相較于算法2受鄰域參數δ的影響較小。
為進一步觀測同一類型算法在給定相同參數下的性能差異,本文給出了比較劃分正確率的概念。針對本文算法和算法2,在給定δ值下的比較正確率(CACCBN)定義如下:
CACCBN=NCPBNB算法2-NB本文算法
其中:NB表示算法產生的邊界域中包含的樣本數;NCPB表示兩比較算法的邊界域相對補集中被正確劃分到正域的樣本數。
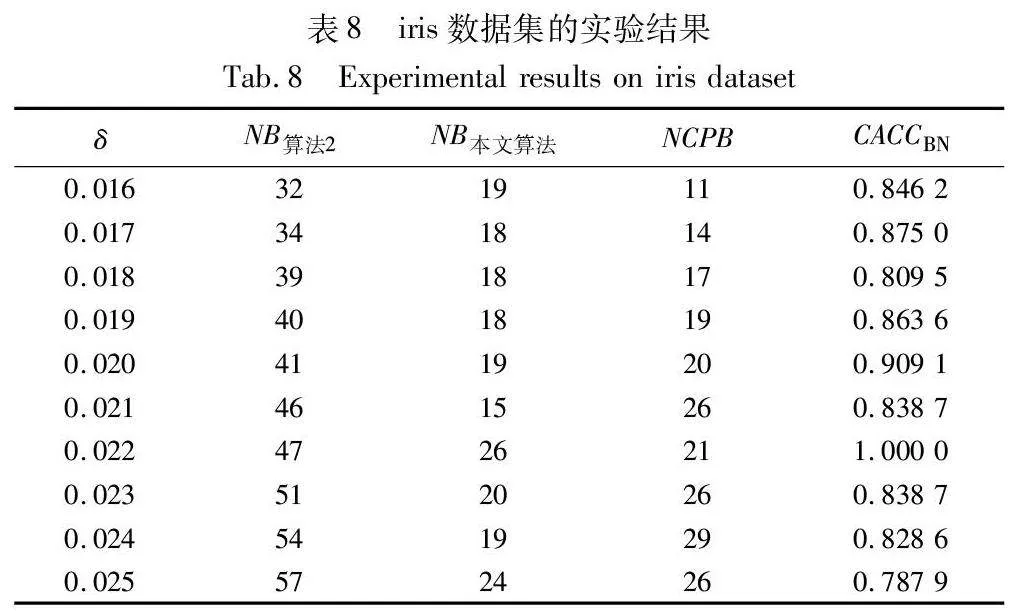
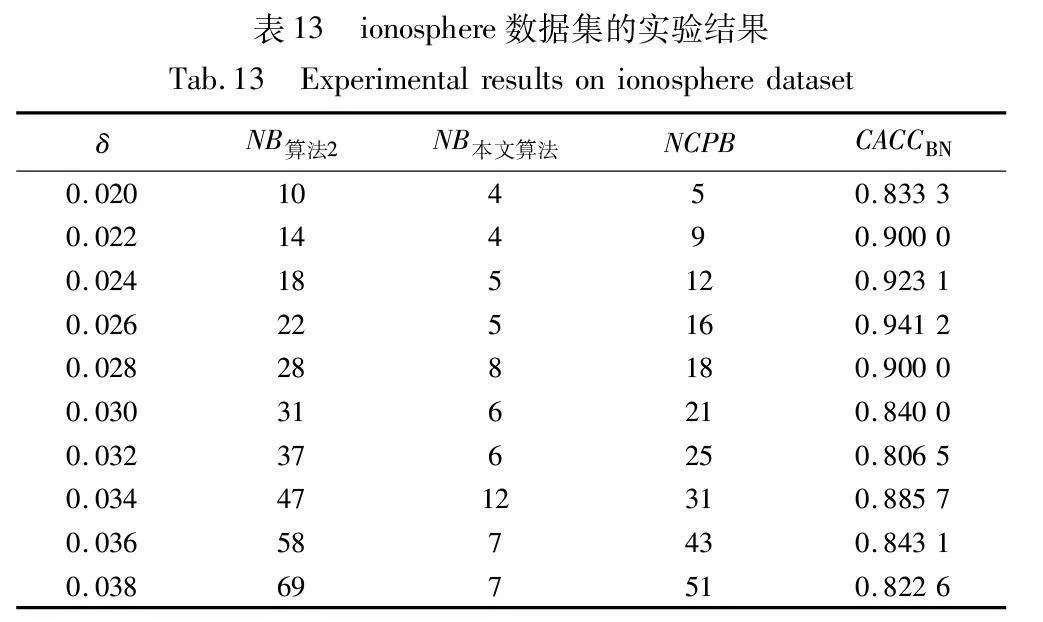
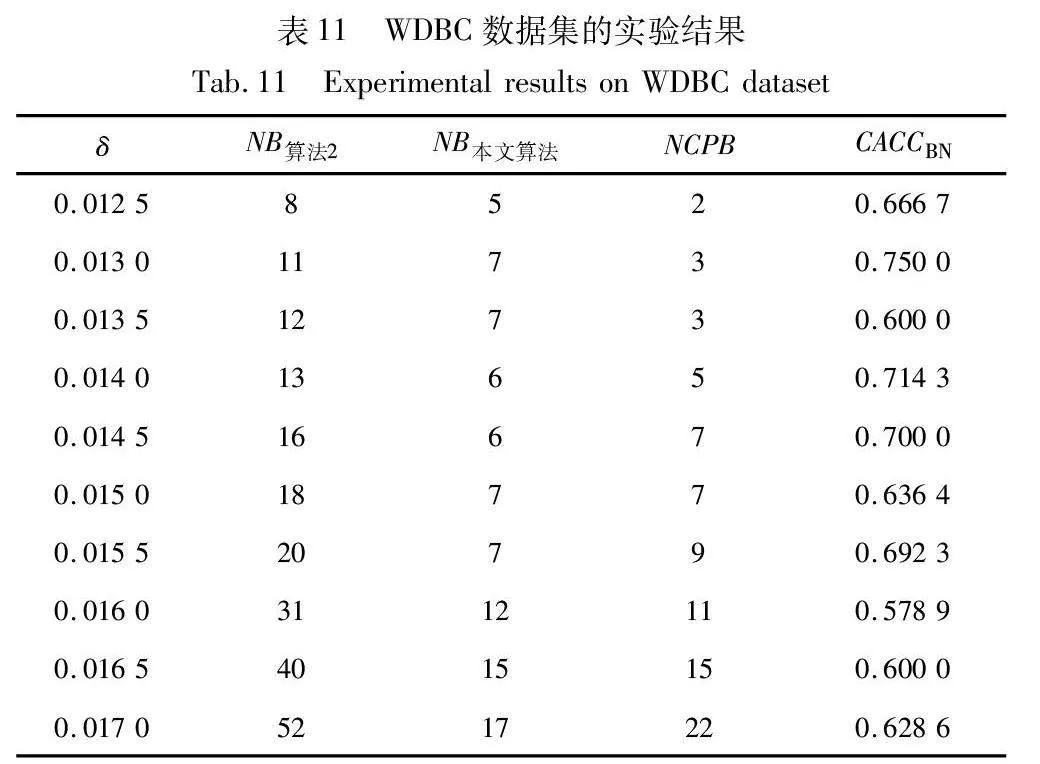
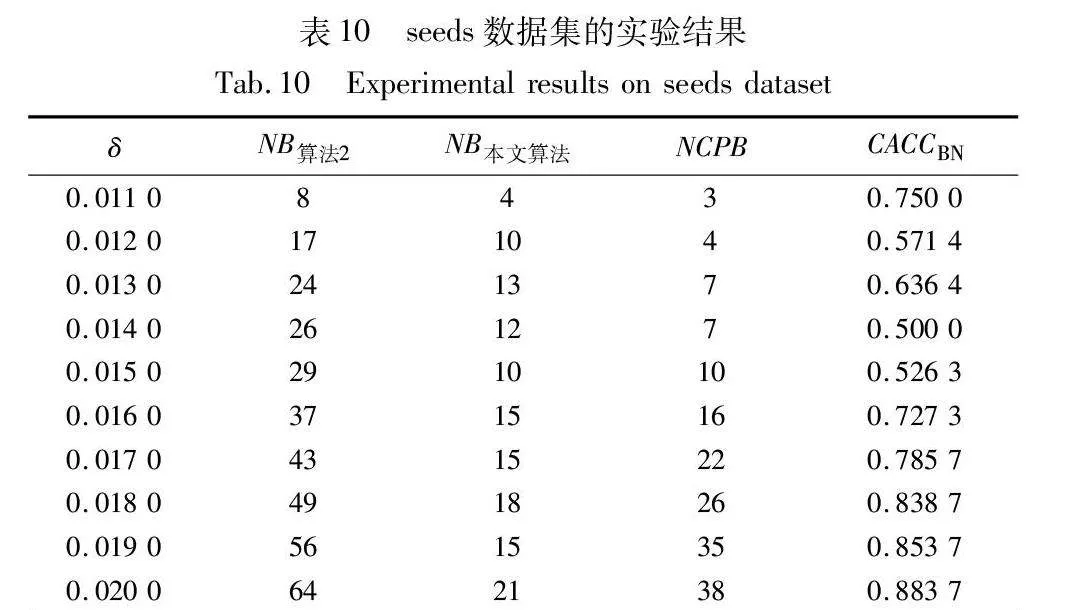
當CACCBN<0時,表明本文算法的邊界域包含更多樣本,本文算法性能低于算法2;當CACCBN>0時,表明本文算法的邊界域包含更少樣本,本文算法性能優于算法2。CACCBN的絕對值越大,說明兩個算法差異性越大。當NB算法2=NB本文算法時,表明兩個算法產生的邊界域包含的樣本一樣多,算法性能接近,這時計算比較正確率CACCBN失去意義。結果如表8~13所示。
由表8~13的實驗結果可知,對于iris數據集,本文算法比較正確率整體較高,且當δ取值為0.022時,所有被處理的樣本均得到了正確的劃分,比較正確率達到100%;對于wine數據集,本文算法比較正確率均達到90%以上,且當δ取值為0.036、0.037、0.038和0.039時,比較正確率均達到100%;對于seeds數據集,除δ取值為0.012、0.013、0.014和0.015時比較正確率相對較低外,在其余六個取值上比較正確率均達到70%以上;對于WDBC數據集,本文算法比較正確率大多穩定在60%~70%;對于Pima數據集,當δ取值為0.058時,比較正確率最高,達到90%;對于ionosphere數據集,本文算法的比較正確率最小值為80.65%,最大值為94.12%。因此,本文算法在處理邊界域樣本時,可以較大程度地將樣本劃分到正確類別。
綜上所述,本文基于最大聯盟粗糙集的三支聚類算法的聚類效果普遍更好,在保留邊界域信息的同時,有效提高了核心域的精度。
5 結束語
本文在給出標準化鄰域信息系統的定義基礎上,通過引入最大聯盟集的概念,定義了一種新的鄰域顆粒信息,使得樣本鄰域信息的刻畫更為細致。將該鄰域顆粒信息與粗糙集理論相結合,構造了最大聯盟粗糙集模型,該模型在一定程度上提高了正域的分類精度,降低了邊界域的不確定性。將最大聯盟粗糙集模型應用于三支聚類分析中,提出了基于最大聯盟粗糙集的三支聚類算法。在6個UCI數據集上進行對比實驗的結果表明,本文算法有效提高了聚類結果的準確率,所有正域的平均質量均超過95%,類簇的整體質量和平均質量均超過90%。本文算法在不同鄰域參數δ下邊界域樣本的比較正確率相對較高,可以較大程度地將邊界域樣本劃分到正確類別。
粗糙集理論為解決多屬性決策和不確定性問題提供了重要思路,然而在實際決策中,決策任務通常呈現出多視角、多粒度、多層次等復雜特性,單一結構化的決策方法有時無法應對這類復雜的決策問題。為此,下一步工作將考慮從粒計算的角度出發,從不同粒度層次中提取有效信息,探索更適用于解決實際決策問題的粗糙集模型和聚類方法。
參考文獻:
[1]Pawlak Z. Rough sets[J]. International Journal of Computer and Information Sciences, 1982, 11(5): 341-356.
[2]Yao Yiyu, Yan Zhao. Attribute reduction in decision-theoretic rough set models[J]. Information Sciences, 2008, 178(17): 3356-3373.
[3]Azam N, Yao Jingtao. Interpretation of equilibria in game-theoretic rough sets[J]. Information Sciences, 2015, 295: 586-599.
[4]Lin T Y. Neighborhood systems:a qualitative theory for fuzzy and rough sets[J]. Advances in Machine Intelligence and Soft Computing, 1997, 4: 132-155.
[5]Yao Yiyu. Relational interpretations of neighborhood operators and rough set approximation operators[J]. Information Sciences, 1998, 111(1-4): 239-259.
[6]Wu Weizhi, Zhang Wenxiu. Neighborhood operator systems and approximations[J]. Information Sciences, 2002, 144(1-4): 201-217.
[7]胡清華, 于達仁, 謝宗霞. 基于鄰域粒化和粗糙逼近的數值屬性約簡[J]. 軟件學報, 2008,19(3): 640-649. (Hu Qinghua, Yu Daren, Xie Zongxia. Numerical attribute reduction based on neighborhood granulation and rough approximation[J]. Journal of Software, 2008,19(3): 640-649.)
[8]Lin Guoping, Qian Yuhua, Li Jinjin. NMGRS: neighborhood-based multigranulation rough sets[J]. International Journal of Approximate Reasoning, 2012, 53(7): 1080-1093.
[9]Wang Qi, Qian Yuhua, Liang Xinyan, et al. Local neighborhood rough set[J]. Knowledge-Based Systems, 2018, 153: 53-64.
[10]Wang Changzhong, Shi Yunpeng, Fan Xiaodong, et al. Attribute reduction based on k-nearest neighborhood rough sets[J]. Internatio-nal Journal of Approximate Reasoning, 2019, 106: 18-31.
[11]賀玲, 吳玲達, 蔡益朝. 數據挖掘中的聚類算法綜述[J]. 計算機應用研究, 2007, 24(1): 10-13. (He Ling, Wu Lingda, Cai Yichao. Survey of clustering algorithms in data mining[J]. Application Research of Computers, 2007, 24(1): 10-13.)
[12]Yao Yiyu. Three-way decisions with probabilistic rough sets[J]. Information Sciences, 2010, 180 (3): 341-353.
[13]錢文彬, 彭莉莎, 王映龍, 等. 不完備混合決策系統的三支決策模型與規則獲取方法[J]. 計算機應用研究, 2020, 37(5): 1421-1427. (Qian Wenbin, Peng Lisha, Wang Yinglong, et al. Three-way decisions model and rule acquisition method for incomplete decision systems[J]. Application Research of Computers, 2020, 37(5): 1421-1427.)
[14]呂艷娜, 茍光磊, 張里博, 等. 深度置信網絡的代價敏感多粒度三支決策模型研究[J]. 計算機應用研究, 2023, 40(3): 833-838. (Lyu Yanna, Gou Guanglei, Zhang Libo, et al. Research on cost-sensitive multi-granularity three-way decision model for deep belief network[J]. Application Research of Computers, 2023, 40(3): 833-838.)
[15]于洪. 三支聚類分析[J]. 數碼設計, 2016, 5(1): 31-35. (Yu Hong. Three-way cluster analysis[J]. Peak Data Science, 2016, 5(1): 31-35.)
[16]劉強, 施虹, 王平心, 等. 基于鄰域的三支決策聚類分析[J]. 計算機工程與應用, 2019, 55(6): 140-144. (Liu Qiang, Shi Hong, Wang Pingxin, et al. Three-way clustering analysis based on neighborhood[J]. Computer Engineering and Applications, 2019, 55(6): 140-144.)
[17]萬仁霞, 王大慶, 苗奪謙. 基于三支決策的高斯混合聚類研究[J]. 重慶郵電大學學報:自然科學版, 2021, 33(5): 806-815. (Wan Renxia, Wang Daqing, Miao Duoqian. Gaussian mixture clustering based on three-way decision[J]. Journal of Chongqing University of Posts and Telecommunications:Natural Science Edition, 2021, 33(5): 806-815.)
[18]花遇春, 趙燕, 馬建敏. 基于共現概率的三支聚類模型[J]. 西北大學學報:自然科學版, 2022, 52(5): 797-804. (Hua Yuchun, Zhao Yan, Ma Jianmin. Three-way clustering model based on co-occurrence probability[J]. Journal of Northwest University:Natural Science Edition, 2022, 52(5): 797-804.)
[19]申秋萍, 張清華, 高滿, 等. 基于局部半徑的三支DBSCAN算法[J]. 計算機科學, 2023, 50(6): 100-108.(Shen Qiuping, Zhang Qinghua, Gao Man, et al. Three-way DBSCAN algorithm based on local eps[J]. Computer Science, 2023, 50(6): 100-108.)
[20]Pawlak Z. An inquiry into anatomy of conflicts[J]. Information Sciences, 1998, 109(1-4): 65-78.
[21]Lang Guoming, Miao Duoqian, Cai Mingjie. Three-way decision app-roaches to conflict analysis using decision-theoretic rough set theory[J]. Information Sciences, 2017, 406: 185-207.
[22]郭淑蓉. 基于區間直覺模糊信息系統的三支沖突分析[D]. 太原: 山西師范大學, 2022. (Guo Shurong. Three-way conflict analysis based on interval-valued intuitionistic fuzzy information system[D]. Taiyuan: Shanxi Normal University, 2022.)
[23]羅珺方, 張碩, 胡夢君. 不完備異構沖突信息系統中的極大一致聯盟區間集族[J]. 計算機科學與探索, 2023, 11(3): 1-12. (Luo Junfang, Zhang Shuo, Hu Mengjun. A family of maximum consistent alliances interval sets in an incomplete heterogeneous conflict information systems[J]. Computer Science and Exploration, 2023, 11(3): 1-12.)
[24]陳玉明, 曾志強, 田翠華. 鄰域粗糙集中不確定性的熵度量方法[J]. 計算機科學與探索, 2016,10(12): 1793-1800. (Chen Yuming, Zeng Zhiqiang, Tian Cuihua. Uncertainty measures using entropy and neighborhood rough sets[J]. Computer Science and Technology, 2016, 10(12): 1793-1800.)
[25]Uysal A K. On two-stage feature selection methods for text classification[J]. IEEE Access, 2018, 6: 43233-43251.
[26]Maji P, Pal S K. RFCM: a hybrid clustering algorithm using rough and fuzzy sets[J]. Fundamenta Informaticae, 2007, 80(4): 475-496.
[27]Zhang Kai. A three-way C-means algorithm[J]. Applied Soft Computing Journal, 2019, 82: 105536.
[28]梁海龍, 謝珺, 續欣瑩, 等. 新的基于區分對象集的鄰域粗糙集屬性約簡算法[J]. 計算機應用, 2015,35(8): 2366-2370. (Liang Hailong, Xie Jun, Xu Xinying, et al. New attribute reduction algorithm of neighborhood rough set based on distinguished object set[J]. Journal of Computer Applications, 2015,35(8): 2366-2370.)
