基于深度半監督學習的小樣本金屬工件表面缺陷分割
2024-08-15 00:00:00徐興宇鐘羽中涂海燕佃松宜
計算機應用研究 2024年8期




摘 要:針對工業應用場景下缺少缺陷樣本的問題,提出了一種僅需要極少缺陷樣本的金屬工件表面缺陷分割方法。該方法結合了圖像生成技術和半監督學習策略,通過利用極少缺陷圖像提取的小尺寸缺陷圖像來訓練缺陷生成模型,然后將生成的缺陷圖像嵌入到正常圖像中以實現數據增廣。其次,采用半監督學習策略訓練分割網絡,以減小生成數據與真實數據分布之間的差異對模型的不良影響。在真實的金屬工件機器視覺檢測系統上的驗證結果表明,半監督的訓練策略提高了分割模型對真實缺陷的泛化能力,所提方法能夠在僅使用5張缺陷樣本圖像的條件下取得較高的分割精度。
關鍵詞:半監督學習;表面缺陷檢測;圖像分割;小樣本;數據增廣
中圖分類號:TP391.41 文獻標志碼:A 文章編號:1001-3695(2024)08-042-2540-06
doi: 10.19734/j.issn.1001-3695.2023.10.0560
Deep semi-supervised learning approach for few-shot segmentation of surface defects on metal workpieces
Xu Xingyu, Zhong Yuzhong, Tu Haiyan, Dian Songyi
(College of Electrical Engineering, Sichuan University, Chengdu 610065, China)
Abstract:
In response to the scarcity of defect samples in industrial applications, this paper proposed a method for segmenting surface defects in metal workpieces with only a minimal number of required defect samples. The method combined image gene-ration techniques with a semi-supervised learning strategy. It utilized small-sized defect patches, and extracted from a minimal number of defect images to train a defect generation model. Subsequently, the method integrated these generated defect images into normal images to facilitate data augmentation. Additionally, the method applied a semi-supervised learning strategy to train the segmentation network, aiming to mitigate the adverse effects of differences between generated and real data distributions. The experimental phase involved conducting tests on a real-world computer vision detection system for metal workpieces. The results demonstrate that the semi-supervised training strategy significantly enhances the segmentation model’s generalization ability to real defects. The method achieves high segmentation accuracy using only five defect sample images.
Key words:semi-supervised learning; surface defect detection; image segmentation; few-shot; data augmentation
0 引言
金屬工件的生產是一個多因素耦合的復雜過程,由于生產設備的設計不完善或運行過程中受磨損、受潮等因素影響,生產出的工件金屬表面可能存在各種類型的缺陷。金屬工件表面缺陷影響了工件的強度、疲勞性能,嚴重的表面缺陷甚至影響工件關聯設備的安全運行或降低設備使用壽命。因此,在生產過程中及時檢測和分析金屬工件的表面缺陷,是提高生產質量和工件可靠性的重要步驟。
在過去的研究中,許多基于傳統圖像處理的方法被用于金屬的表面缺陷檢測,包括基于閾值[1]、聚類[2]和頻譜[3]等方法。傳統的機器學習方法[4]也被應用于金屬表面缺陷檢測,主要包括特征提取及分類兩部分。但是,傳統圖像處理的方法通常基于人工提取缺陷特征,人力投入較大;另一方面,又容易受到環境變化的影響,泛化能力差[5]。
近年來,基于深度學習的計算機視覺方法被廣泛使用于檢測工業產品或材料中的缺陷[6]。部分學者基于目標檢測模型實現缺陷檢測與定位。蘇迎濤[7]提出了一種基于顯著區域提取和改進型YOLO-V3的缺陷檢測方法,實現了金屬齒輪加工端表面缺陷的快速檢測和定位。張乃雪等人[8]采用基于DETR的編碼-解碼結構對缺陷類別和位置進行預測,降低了參數量和計算復雜度。此外,部分學者通過語義分割模型實現表面缺陷的像素級檢測與分割。王一等人[9]基于U-Net語義分割模型,結合多尺度自適應形態特征提取及瓶頸注意力機制實現了金屬工件表面缺陷分割。Wang等人[10]提出一種改進的DeepLabV3+語義分割模型,在網絡中引入注意力機制,并將ASPP模塊替換為D-ASPP模塊,實現了磁柱缺陷的高精度分割。
然而,在多數的實際應用場景中,由于生產的良品率高、產品造價昂貴、不適于在其上人工模擬缺陷等原因,只能收集到極少數的缺陷樣本。因此,許多學者開始關注缺少缺陷樣本情況下的缺陷檢測算法研究。
小樣本學習指利用包含少量監督信息的數據實現學習任務[11],主要分為基于度量的元學習方法[12]、基于微調的方法[13]和基于數據增廣[14]的方法。目前小樣本的圖像分割算法研究側重于從少量支持圖像中獲得高質量的原型來準確地預測結果,包括PANet[15]、MSANet[12]等方法。許國良等人[16]提出了一種小樣本手機屏幕缺陷分割網絡,引入了協同注意力來加強支持圖像與查詢圖像之間的特征信息交互。這類方法從有限的支持集中提取實例知識,難以用于分割具有較大類內差異的工業產品缺陷。部分學者通過生成對抗網絡(GAN)[17,18]、變分自編碼器(VAE)[19]等生成模型生成更多的缺陷數據來擴充訓練集,從而提高模型性能[20]。Liu等人[21]使用GAN來評估缺陷圖像上的缺陷特征分布并生成缺陷,然后使用生成缺陷構建的數據集來訓練Faster R-CNN,實現缺陷檢測。然而,該類方法存在生成模型在缺少缺陷樣本的情況下難以優化的問題,生成的圖像質量低、多樣性低,導致生成數據與真實數據間存在分布差異,最終導致分割模型偏向生成數據過擬合。
另一方面,部分學者通過利用半監督學習的方式來進行缺少缺陷樣本情況下的缺陷檢測任務。Rudolph等人[22]使用了一種歸一化流的半監督方法,在使用少量缺陷樣本的情況下實現了較好的缺陷像素級定位。半監督結合了監督與無監督的方法,利用少量標注數據訓練模型。自訓練[23]被認為是半監督學習中熵最小化的一種形式,利用模型自身的預測結果來監督后續訓練。Zhu等人[24]首先在標記數據上訓練教師模型,然后在大量未標記數據上生成偽標簽,展示了自訓練在跨域泛化任務上的有效性優于傳統的微調方法[25]。部分研究者將自訓練與GAN[26]、對比學習[27]等方法結合,實現了高精度的半監督圖像分割。
綜上所述,本文提出了一種基于深度半監督學習的小樣本金屬工件表面缺陷分割算法。其主要有以下貢獻:
a)針對缺少缺陷樣本的工業檢測場景,提出了一種僅需極少缺陷樣本的缺陷分割框架。所提出的方法結合圖像生成和半監督學習的技術,在僅利用5張缺陷樣本圖像和50張正常樣本圖像的條件下實現了高精度的缺陷分割。
b)針對生成模型在缺少訓練數據的情況下不易優化的問題,提出了一種利用少量缺陷樣本和大量正常樣本的數據增廣方法。該方法采用從原始圖像中提取的小尺寸缺陷圖像訓練DCGAN模型,再將生成的小尺寸缺陷圖像隨機嵌入正常圖像的工件區域。
c)針對生成數據與真實數據之間的分布差異,提出了對增廣后的數據采用半監督學習的策略訓練分割模型,以削弱模型對生成數據的過擬合。對利用生成模型數據增廣后的數據集部分標注后采用自訓練的策略進行訓練。
1 方法框架
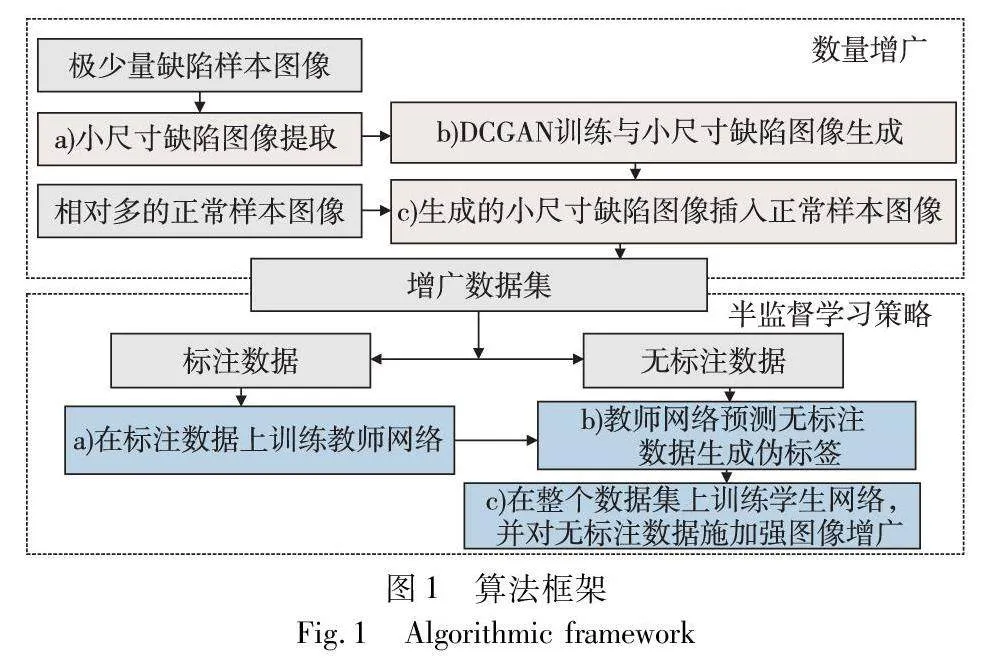
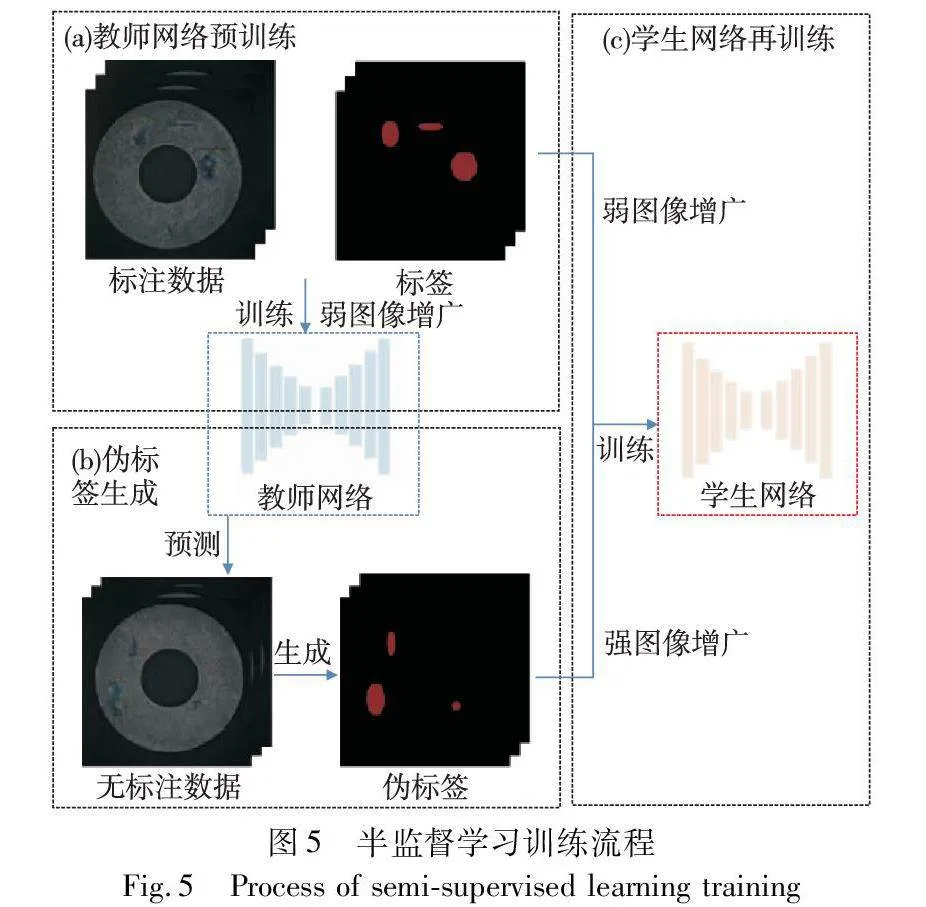
本文方法的整個流程主要由數據增廣和半監督學習策略兩部分組成,如圖1所示。
首先,本文方法利用少量缺陷樣本圖像和相對多的正常樣本圖像進行數據增廣。為了解決GAN等生成模型在缺少訓練數據的情況下難以優化的問題,使用從缺陷樣本圖像中提取的小尺寸缺陷圖像訓練DCGAN生成模型,旨在增加訓練數據量的同時提高生成缺陷圖像的質量。隨后,將訓練完成的生成模型生成的小尺寸缺陷圖像隨機嵌入正常樣本圖像,在保證背景信息真實性的同時充分利用了正常樣本數據。
其次,為了應對生成數據與真實數據之間分布差異對分割模型的負面影響,主要是由生成數據訓練的分割網絡偏向生成數據過擬合的問題,本文提出對生成數據利用半監督學習的策略訓練分割網絡。具體地,本文方法對上述數據增廣方法增廣后的增廣部分標注后,采用自訓練的框架訓練分割網絡,并在不同階段施加了不同強度的圖像增廣。其中,在教師網絡訓練階段施加弱圖像增廣,在學生網絡訓練階段對無標注數據施加CutMix在內的強圖像增廣策略(strong data augmentation,SDA)。
2 數據增廣
2.1 生成模型
鑒于可供訓練的數據量較少,StyleGAN[28]等復雜度高的模型在訓練的過程中不易收斂,通過增廣訓練集使其收斂容易過擬合,生成的圖像多樣性差;復雜度過低的模型,如原始的GAN模型,生成的圖像質量較差,圖像含有噪點且缺陷與背景邊界不清晰,與真實的缺陷圖像差別較大。各類不同復雜度的生成模型實驗結果如圖2所示。綜上所述,本文方法選擇模型復雜度相對較低的DCGAN[29]作為生成模型。
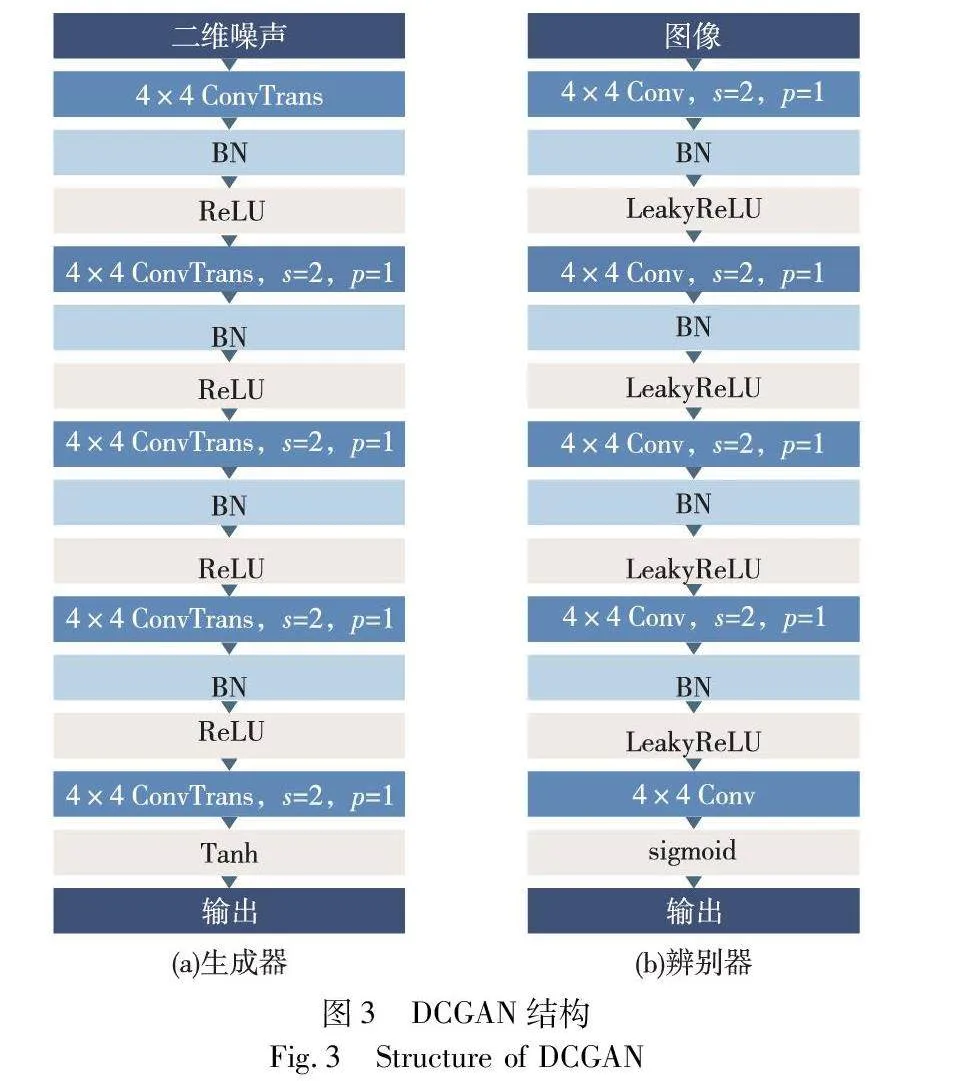
DCGAN是一種無監督的生成式對抗網絡,使用了卷積神經網絡作為生成器和判別器的架構,能夠處理圖像中的細節,生成更高質量的圖像。本文方法使用的DCGAN模型結構如圖3所示。
生成器以隨機噪聲向量為輸入,輸出一張圖像以模仿真實圖像的分布。由5個反卷積層組成,反卷積層之間交替使用批量歸一化層和ReLU激活函數,最后一層使用Tanh激活函數來約束生成像素值在-1~1。
判別器以圖像為輸入,輸出判斷圖像是否為真。由5個卷積層組成,卷積層之間交替使用批量歸一化層和LeakyReLU激活函數,最后一層使用sigmoid激活函數輸出0~1的概率值。
在對抗訓練過程中,生成器和判別器的損失函數均采用交叉熵損失。生成器和判別器的訓練交替進行,直到達到預定的迭代次數。
2.2 數據增廣流程
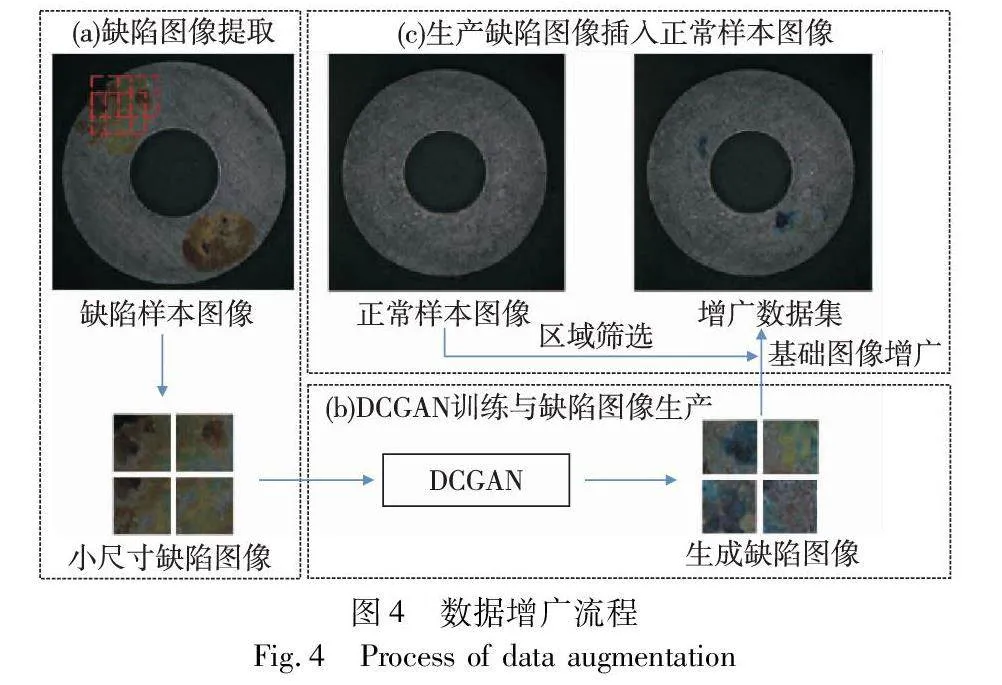
在工程實際中,經常只能獲得極少量的缺陷樣本圖像,而沒有缺陷的正常樣本圖像相對容易獲取。因此,本文設計了利用少量缺陷樣本圖像和相對多的正常樣本圖像的數據增廣策略。數據增廣的方法如圖4所示。
由于缺陷樣本圖像數量極少,直接用完整工件的缺陷樣本圖像來訓練生成模型會導致網絡訓練不充分,甚至不收斂。另外,生成的缺陷圖像可能會受到背景的影響,使生成的圖像具有不同的缺陷特征。考慮到以上問題,本文方法從原始的缺陷樣本圖像中提取小尺寸缺陷圖像作為DCGAN的訓練數據。具體地,從分辨率大小為640×640像素的原始缺陷數據圖像中人工提取分辨率為64×64的小尺寸缺陷圖像,所提取的圖像可能不完整覆蓋整個缺陷,且圖像之間互有重疊區域,旨在增加訓練樣本和豐富樣本多樣性。
DCGAN訓練完成后,將生成器生成的小尺寸缺陷圖像隨機插入到正常樣本圖像中。這樣做有利于生成的缺陷圖像具有更高的特征一致性,同時保持了圖像背景的真實性。具體地,對小尺寸缺陷圖像進行隨機旋轉、隨機水平翻轉、隨機高寬比和隨機縮放等基礎圖像增廣操作,以模擬缺陷的不同大小、形狀和方向。其次,使用閾值分割篩選出工件區域,以保證缺陷圖像能夠被插入到工件表面而不是背景區域,使得生成的數據更加真實合理。最后,將基礎圖像增廣后的隨機小尺寸缺陷圖像嵌入到隨機正常樣本圖像的工件表面隨機區域,同時對生成的缺陷圖像和待插入區域的邊緣進行模糊化處理,使插入的缺陷圖片與背景融合得更加自然。
通過批量進行上述操作,構建出了一個由生成的小尺寸缺陷圖像和正常數據圖像合成的增廣數據集,為后續的分割模型提供了更多多樣化的訓練樣本。
3 半監督學習策略
生成模型會引入一些噪聲和變化,導致生成數據的分布與真實數據的分布不完全一致。這種分布差異可能會對全監督學習方法產生負面影響,使訓練出的模型向生成數據過擬合,無法有效泛化到真實的缺陷上。在半監督學習中,由于沒有對整個增廣數據集進行標注,可以降低模型對數據分布差異的敏感性,進而提高模型在真實缺陷上的泛化能力。本文方法通過利用半監督訓練的方法來緩解分布差異對模型的負面影響,采用了自訓練的半監督學習框架,并在后續實驗中證明了該方法的有效性。
本文方法將增廣數據集隨機拆分成兩部分:其中一部分進行人工像素級標注,作為標注數據Dl={(Ili,Yli)}Nli=1;另一部分作為無標注數據Du={Iui}Nui=1。標注數據所占比例將在消融實驗部分進行探討。本文方法參考文獻[30]設計用于缺陷分割的自訓練算法流程,如圖5所示。
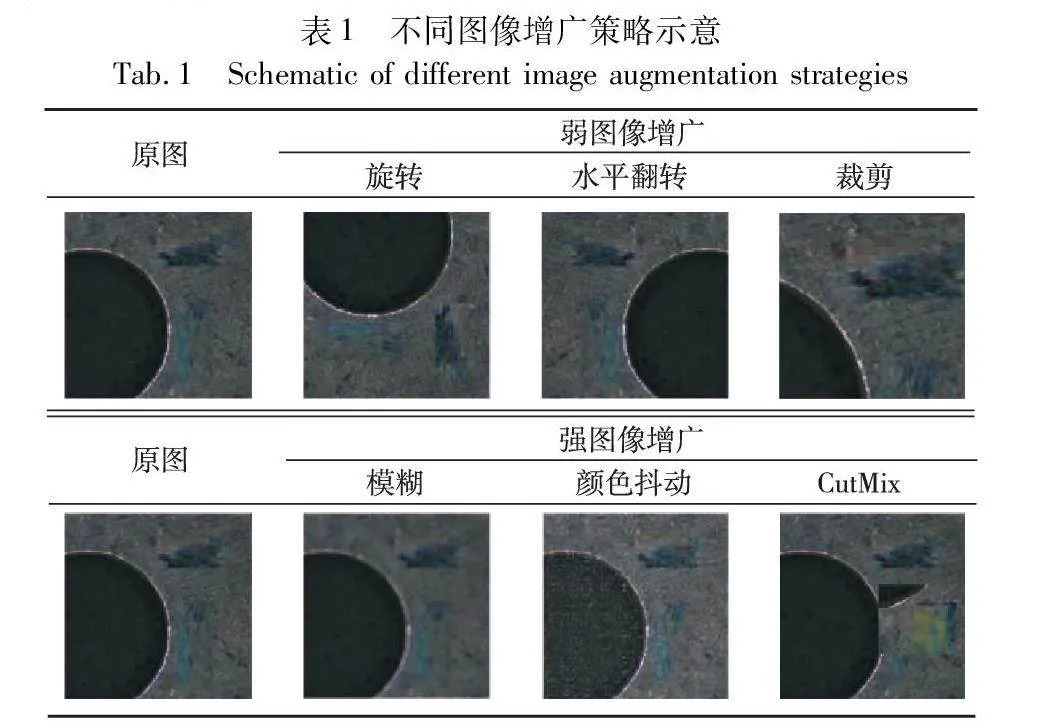
特別地,在不同階段分別施加了強、弱兩種圖像增廣策略。本文方法使用的各類圖像增廣策略如表1所示。
其中,弱圖像增廣策略包括隨機旋轉、隨機水平翻轉、裁剪等。像素級標注的數據通常是寶貴的資源,對標注數據施加的圖像增廣強度需要慎重考慮,過強的圖像增廣可能引入更多的噪聲和變化,從而使原始標簽信息變得模糊和不可靠。較弱的增廣策略對圖像紋理、特征改變幅度較小,使教師網絡能夠更好地學習標注數據的細節和邊界信息,提高教師網絡對無標簽數據的預測精度,最終提高半監督方法的性能。
SDA包括弱圖像增廣的全部策略以及隨機模糊、顏色擾動和CutMix[31]。強數據增廣策略對圖像紋理、特征改變較大,更多差異更大的樣本可以提高訓練數據的多樣性和覆蓋范圍,從而使模型更好地學習數據的不變性和抗擾動性,從而提高模型的魯棒性和泛化能力。此外,CutMix方法在保留了CutOut[32]等方法區域性丟棄優勢的同時,增廣后的圖像不會出現非信息像素,削弱了圖像混合后的不自然問題,能夠進一步提升分割模型的性能。
3.1 教師網絡預訓練
本文方法對標注數據施加弱圖像增廣策略,利用標注數據訓練教師網絡。教師網絡訓練的損失可以表述為
LT=CrossEntropy(T(Il),Yl)(1)
其中:T表示將圖像I映射到教師網絡的輸VoRHwGJ/uexTAFGyoeey2A==出空間;CrossEntropy表示交叉熵。
3.2 偽標簽生成
本文方法利用訓練完成的教師網絡預測無標簽數據Du,預測得到的獨熱硬標簽作為無標簽數據的偽標簽D^u={(Iui,Y^ui)}Nui=1。首先將無標簽數據輸入已經訓練完成的教師網絡中,獲得對應的像素級預測結果。隨后,應用硬閾值篩選策略,基于像素的預測概率值閾值,過濾掉不可靠的預測結果。最后,每個像素的偽標簽轉換為獨熱編碼形式。
硬閾值的選擇對于自訓練生成至關重要,其影響了模型對無標簽數據的利用,一般需要由實驗測試確定。閾值過低會導致過多錯誤預測帶來的噪聲疊加,降低模型分割精度。閾值過高會導致模型在無標簽數據上過于保守,只學到與教師網絡同質化的信息而難以泛化到真實數據。
3.3 學生網絡再訓練
在施加弱圖像增廣的標注數據和施加強圖像增廣策略的無標注數據上訓練學生網絡S,訓練完成的學生網絡將作為最終的分割模型進行精度測試。學生網絡訓練的損失可以表述為
LS=LlS+λLuS(2)
LlS=CrossEntropy(S(Il),Yl)(3)
LuS=CrossEntropy(S(Iu),Y^u)(4)
其中:LlS為監督損失;LuS為無監督損失;λ為權衡系數,用于調節標注數據和無標注數據在訓練時的權重;S表示將圖像I映射到學生網絡的輸出空間。
4 實驗與分析
4.1 實驗平臺
為了獲得清晰的工件圖像并進行工件的工業檢測,本文采用了一種具有多種檢測功能的機器視覺檢測系統,如圖6所示。其中缺陷檢測模塊的成像系統由1 200萬像素高清工業相機、2倍遠心鏡頭、環形白色光源和石英玻璃載物臺組成。
成像系統所采集的圖片在工控機上完成處理與結果輸出。所采用的工控機操作系統為Windows 10,計算機相關參數CPU為Intel CoreTM i7-12700;GPU為NVIDIA GeForce RTX3090 24 GB;64 GB RAM。所使用的模型基于PyTorch深度學習框架搭建神經網絡,安裝了CUDA V11.3用于GPU加速。
4.2 實驗設置
1)實驗數據 本文通過上述機械視覺系統采集了5張缺陷樣本圖像和50張正常樣本圖像。按照缺陷檢測的精度需求,將原始圖像放縮為分辨率為640×640的圖像用作后續實驗。按第2章的數據增廣方法,將采集的圖像增廣為總數量為600張的增廣數據集,其中隨機選取500張作為訓練集,100張作為生成數據測試集。由于在生成圖像上的測試結果不能準確衡量模型對真實缺陷的分割效果,本文另外采集了15張缺陷樣本圖像作為真實數據測試集,用于衡量本方法的真實分割性能。若無特殊說明,本文所有實驗精度皆為真實數據集的測試精度。
2)模型選擇 半監督算法中的學生網絡和教師網絡采用相同的分割網絡。分割網絡模型并非本文方法的主要創新點。在多個分割網絡上進行測試之后,最終選擇了ResNet50作為Backbone的DeepLAbV3+[33]網絡作為分割網絡,并集成在了機械視覺系統中。本文所有模型訓練均選取50個epoch,采用Adam優化器,batch size設置為4,初始學習率設置為0.001,每10個epoch學習率降低10倍。
3)評價指標 選擇交并比(intersection over union, IoU)、精準率(precision)、召回率(recall)和F1得分(F1-score)四個評價指標分析模型的分割性能。
交并比用于度量模型預測的分割結果與實際標簽之間的重疊程度,計算公式為
IoU=TPTP+FP+FN(5)
其中:FP表示假陽性結果;TP表示真陽性結果;FN表示假陰性結果;TN表示真陰性結果。
精確率用于度量模型對缺陷類別像素的分類準確性,計算為
precision=TPTP+FP(6)
召回率用于度量模型在捕獲所有真實缺陷像素方面的效率,計算公式為
recall=TPTP+FN(7)
F1得分表示精準率和召回率的調和平均數,計算公式為
F1=2×precision×recallprecision+recall(8)
4.3 實驗結果
4.3.1 訓練策略對分割性能的影響
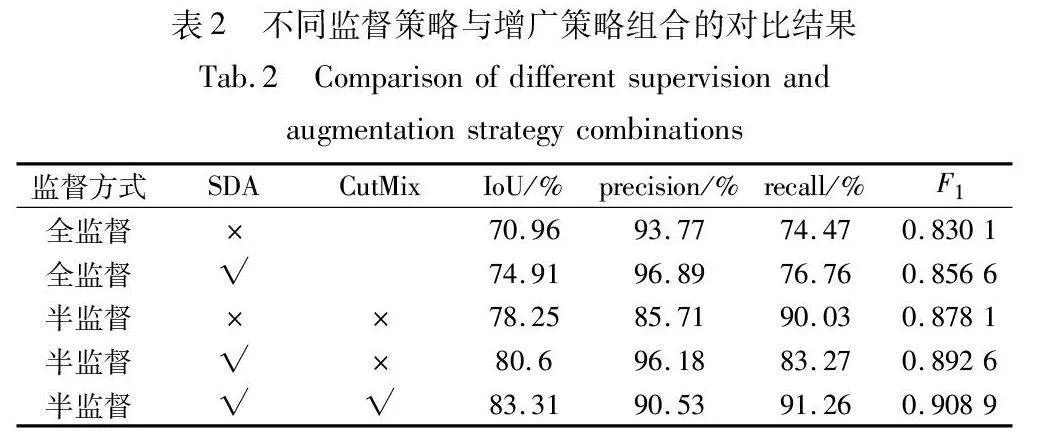
為了驗證本文方法的有效性,進行了不同監督方式和不同增廣策略組合的對比實驗,如表2所示。其中常規的全監督方法和半監督方法在所有訓練階段都僅使用弱圖像增廣策略。
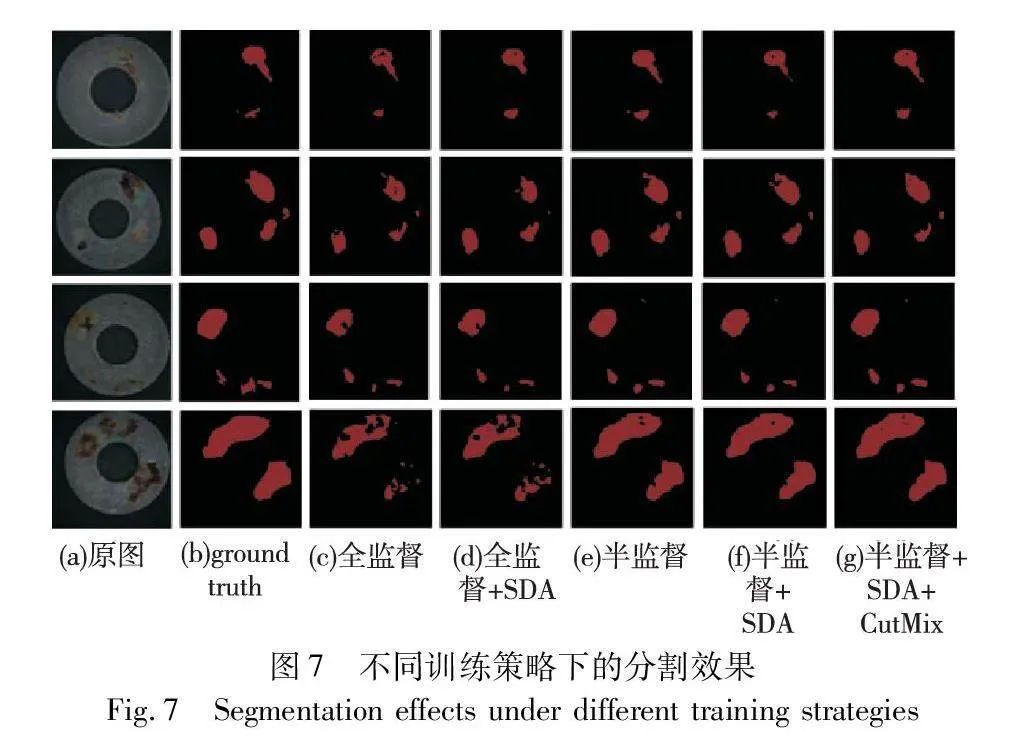
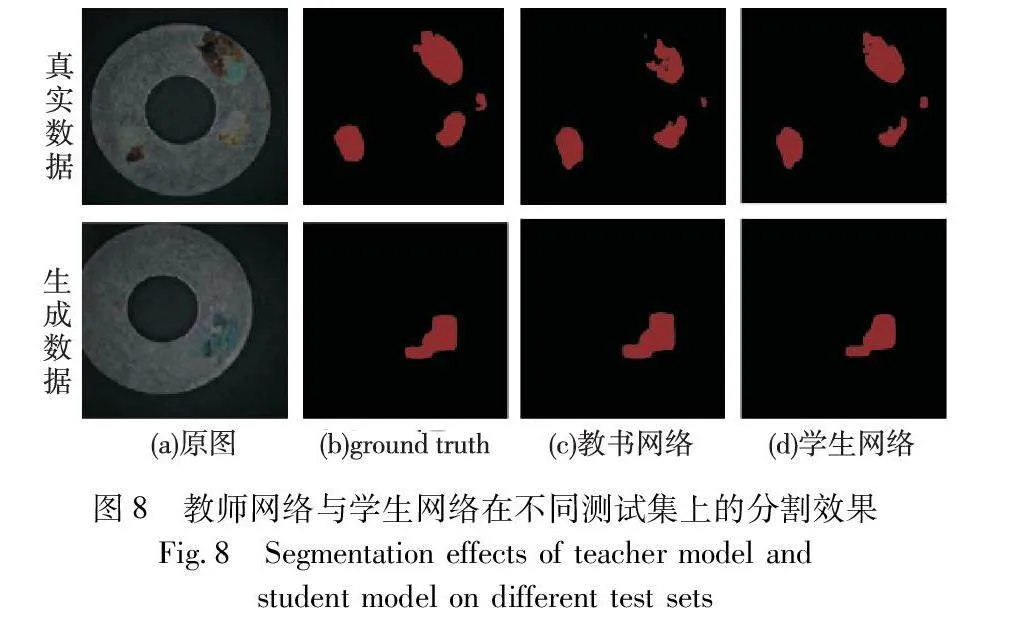
如表2所示,全監督方法下的評價指標除了精確率外,都維持在較低水平。與全監督學習相比,半監督學習可以對生成數據實現更高的分割精度。常規半監督方法比全監督方法的IoU提高了7.29百分點,召回率提高了15.56百分點。得益于半監督訓練過程中對無標簽數據的訓練誤差削弱了學生網絡訓練過程中對生成數據的過擬合,通過半監督學習訓練后的分割網絡能夠更有效地預測缺陷類別。在半監督學習的訓練過程中對無標注數據施加更強的圖像增廣策略,可以有效提高模型性能,在其中添加CutMix增廣方法可以進一步提升模型性能。此外,與改變監督方式相比,為全監督學習方法施加強圖像增廣策略提升甚微,這表明本文方法帶來的精度提升不是主要來源于SDA的效果,而是得益于半監督的訓練策略。不同訓練策略的分割效果及教師網絡與學生網絡在不同測試集上的分割效果如圖7、8所示。
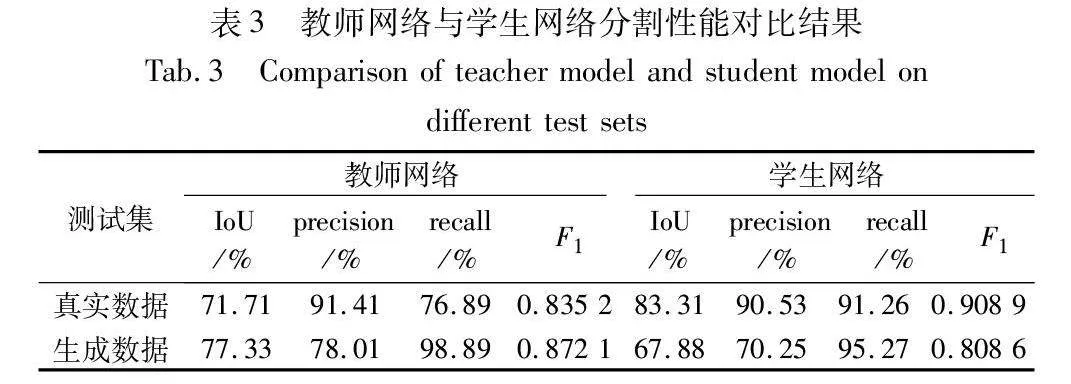
表3展示了1/10比例的半監督方法下,教師網絡和學f2cdf80f58b8a1e23f5549167e197f59910acc48a59f42e97ff46e4c6f83130c生網絡分別在生成數據測試集和真實數據測試集上的分割精度。僅使用標注數據訓練的教師網絡對生成數據的檢測精度顯著高于真實數據,其對生成數據的召回率高達98.89%,而對真實數據的分割精度處于較低水平,表明對生成數據進行全監督學習會導致一定程度偏向生成數據的過擬合。通過部分標簽和部分偽標簽訓練出的學生網絡相較于教師網絡在真實數據上的分割精度顯著提高,IoU提升了11.60百分點,召回率提升了14.37百分點。由上面的數據表明,半監督學習的訓練策略有效削弱了模型對于生成數據的過擬合,提高了模型對真實缺陷的泛化能力。
4.3.2 與現有算法對比實驗與分析
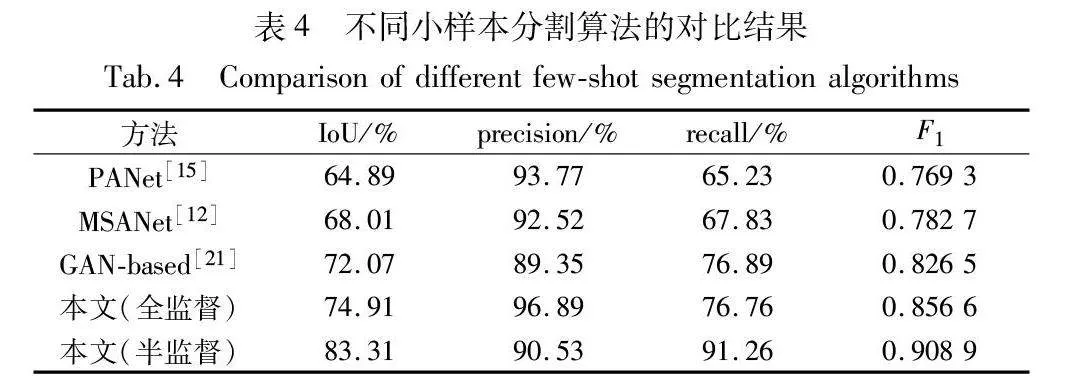
為了證明所提方法的先進性,與現有的小樣本分割算法進行了對比實驗,所有方法僅采用了前述5張標注的缺陷樣本圖像作為原始的監督信號。實驗結果如表4所示,MSANet、PANet等基于原型對比的度量方法應用于缺陷分割任務時,IoU和召回率較低。支持集所能提供的原型難以泛化到與其差異更大的缺陷樣本上,在預測新的缺陷圖像時容易漏檢。另一方面,基于GAN的數據增廣方法在缺乏缺陷數據的情況下效果更佳,但由于生成圖像無法充分包含未知的缺陷特征,容易導致網絡過擬合。所提方法利用生成模型對缺陷圖像進行增廣,模擬了缺陷的紋理和形狀,并利用半監督的訓練策略削弱了過擬合,在維持高精確率的情況下,達到了最高的IoU和召回率。
4.3.3 不同標注數據占比對分割性能的影響
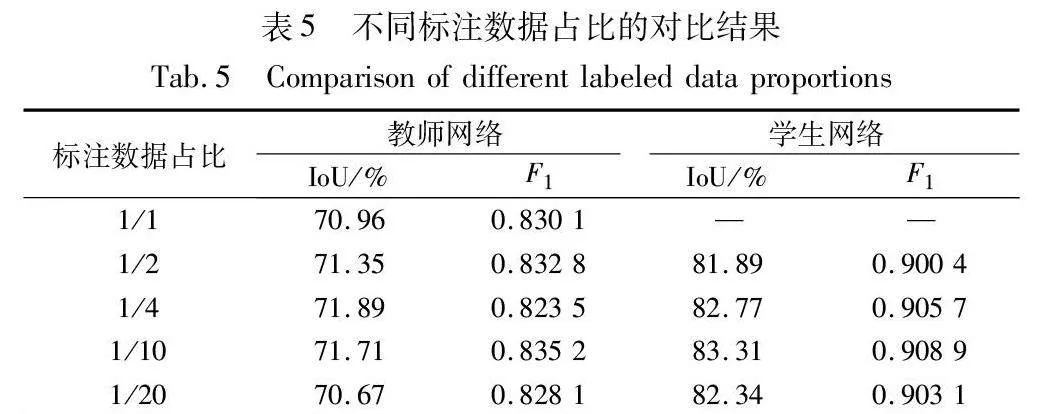
本文進行了四種不同標注數據占比下的半監督實驗,與全監督方法的結果對比如表5所示。
由表5可得,從1/20的標注數據占比到全監督的方法,教師網絡對真實數據的檢測精度都維持在較低水平,顯示出一定程度的過擬合。另外,也反映出僅利用圖像生成的數據增廣方法對模型的分割精度提升有限,當參與監督訓練的增廣圖像達到125張時,教師網絡的精度就已經飽和。而對于任意不同比例的半監督算法,訓練完成的學生網絡對真實缺陷依然擁有較高的泛化能力,IoU保持在80%以上,F1得分保持在0.9以上,模型在標注數據占比為1/10時取得最高精度。
4.3.4 不同分割模型對分割性能的影響
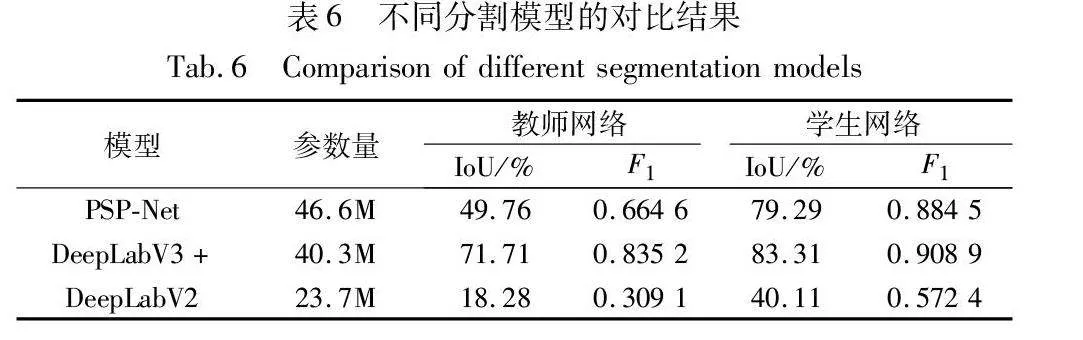
為了證明本文方法在不同分割模型上的通用性,選用了三種主流的語義分割模型進行對比實驗。本文選擇PSP-Net[33]、DeepLabV3+和DeepLabV2[34]在相同1/10數據標注的數據集條件下進行對比實驗,利用各自實驗最高分割精度進行對比,如表6所示。
表6的數據表明,使用標注數據訓練的三種網絡都出現了不同程度的過擬合,經過半監督的訓練流程后,分割網絡在真實缺陷上的泛化能力得到了不同程度的增強。其中, DeepLabV2模型在僅使用標注數據訓練的條件下對生成數據的過擬合尤為嚴重,對真實缺陷的泛化能力極低,但是在經過半監督的訓練過后,IoU提升了21.83百分點,分割精度顯著提高。PSP-Net和DeepLabV3+模型參數量相近,都是復雜度相對較高的模型,在全監督或者半監督的教師網絡階段對真實缺陷仍有一定的泛化能力,在通過半監督的訓練流程后,泛化能力亦得到了進一步提升。
5 結束語
針對工業場景下缺少缺陷樣本的問題,本文提出了一種利用圖像生成技術和半監督學習的小樣本缺陷分割算法。該算法首先利用極少量缺陷樣本圖像和相對多的正常樣本圖像進行數據增廣,結合DCGAN生成模型擴充了可訓練的數據量;此外,該算法對增廣數據集部分標注之后采用自訓練的訓練策略,并在不同階段施加不同的圖像增廣策略,削弱了分割模型對生成數據的過擬合。本文方法在真實的視覺系統上利用金屬工件進行了實驗。實驗表明,該方法能夠在僅使用5張缺陷樣本圖像的條件下滿足系統對缺陷的高精度分割需求。通過各種基準測試的對比實驗,證明了本文設計的半監督學習訓練策略可以改善分割模型對生成數據的過擬合,有效緩解了生成數據與真實數據之間的分布差異對分割精度的影響。
參考文獻:
[1]Sharifzadeh M,Alirezaee S,Amirfattahi R,et al. Detection of steel defect using the image processing algorithms [C]// Proc of the 6th International Conference on Electrical Engineering. Piscataway,NJ: IEEE Press,2008: 125-127.
[2]Bulnes F G,Usamentiaga R,García D F,et al. Vision-based sensor for early detection of periodical defects in Web materials [J]. Sensors,2012,12(8): 10788-10809.
[3]Gayubo F,Gonzalez J L,de la Fuente E,et al. On-line machine vision system for detect split defects in sheet-metal forming processes [C]// Proc of the 18th International Conference on Pattern Recognition. Piscataway,NJ: IEEE Press,2006: 723-726.
[4]Ghorai S,Mukherjee A,Gangadaran M,et al. Automatic defect detection on hot-rolled flat steel products [J]. IEEE Trans on Instrumentation and Measurement,2012,62(3): 612-621.
[5]Zhang Yanxi,You Deyong D,Gao Xiangdong,et al. Welding defects detection based on deep learning with multiple optical sensors during disk laser welding of thick plates [J]. Journal of Manufacturing Systems,2019,51: 87-94.
[6]Valente A,Wada C,Neves D,et al. Print defect mapping with semantic segmentation [C]// Proc of IEEE/CVF Winter Conference on App-lications of Computer Vision. Piscataway,NJ: IEEE Press,2020: 3540-3548.
[7]蘇迎濤. 基于顯著區域提取和改進型 YOLO-V3 的金屬齒輪加工端表面缺陷檢測方法 [D]. 重慶:重慶大學,2020. (Su Yingtao. Surface defect detection method for metal gear machining based on salient region extraction and improved YOLO-V3[D]. Chongqing:Chongqing University,2020.)
[8]張乃雪,鐘羽中,趙濤,等. 基于Smooth-DETR的產品表面小尺寸缺陷檢測算法 [J]. 計算機應用研究,2022,39(8): 2520-2525. (Zhang Naixue,Zhong Yuzhong,Zhao Tao,et al. Detection method for small-size surface defects based on Smooth-DETR [J]. Application Research of Computers,2022,39(8): 2520-2525.)
[9]王一,龔肖杰,程佳. 基于改進U-Net的金屬工件表面缺陷分割方法 [J]. 激光與光電子學進展,2023,60(15): 1524001. (Wang Yi,Gong Xiaojie,Cheng Jia. Surface defect segmentation method of metal workpiece based on improved U-Net [J]. Advances in Lasers and Optoelectronics,2023,60(15): 1524001.)
[10]Wang Jun,Hou Mengjie,Zhang Ruiran,et al. Magnetic column defect recognition based on DeepLab V3+ [C]// Proc of China Automation Congress. Piscataway,NJ: IEEE Press,2022: 2618-2623.
[11]張睿,楊義鑫,李陽,等. 自監督學習下小樣本遙感圖像場景分類 [J]. 中國圖像圖形學報,2022,27(11): 3371-3381. (Zhang Rui,Yang Yixin,Li Yang,et al. Self-supervised learning based few-shot remote sensing scene image classification [J]. Journal of Image and Graphics,2022,27(11): 3371-3381.)
[12]Iqbal E,Safarov S,Bang S. MSANet: multi-similarity and attention guidance for boosting few-shot segmentation [EB/OL]. (2022-06-20). https://arxiv.org/abs/2206.09667.
[13]Nakamura A,Harada T. Revisiting fine-tuning for few-shot learning [EB/OL]. (2019-10-03). https://arxiv.org/abs/1910.00216.
[14]Mehrotra A,Dukkipati A. Generative adversarial residual pairwise networks for one shot learning [EB/OL]. (2017-03-23). https://arxiv.org/abs/1703.08033.
[15]Wang Kaixin,Liew J H,Zou Yingtian,et al. PANet: few-shot image semantic segmentation with prototype alignment [C]// Proc of IEEE/CVF International Conference on Computer Vision. Piscataway,NJ: IEEE Press,2019: 9196-9205.
[16]許國良,毛驕. 基于協同注意力的小樣本的手機屏幕缺陷分割 [J]. 電子與信息學報,2022,44(4): 1476-1483. (Xu Guoliang,Mao Jiao. Few-shot segmentation on mobile phone screen defect based on co-attention [J]. Journal of Electronics & Information Technology,2022,44(4): 1476-1483.)
[17]Goodfellow I,Pouget-Abadie J,Mirza M,et al. Generative adversarial networks [J]. Communications of the ACM,2020,63(11): 139-144.
[18]He Xiangjie,Chang Zhengwei,Zhang Linghao,et al. A survey of defect detection applications based on generative adversarial networks [J]. IEEE Access,2022,10: 113493-113512.
[19]Doersch C. Tutorial on variational autoencoders [EB/OL]. (2021-01-03). https://arxiv.org/abs/1606.05908.
[20]Chen Jingwen,Chen Jiawei,Chao Hongyang,et al. Image blind denoising with generative adversarial network based noise modeling [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2018: 3155-3164.
[21]Liu Jie,Zhang B G,Li Li. Defect detection of fabrics with generative adversarial network based flaws modeling [C]// Proc of Chinese Automation Congress. Piscataway,NJ: IEEE Press,2020: 3334-3338.
[22]Rudolph M,Wandt B,Rosenhahn B. Same but different: semi-supervised defect detection with normalizing flows [C]// Proc of IEEE/CVF Winter Conference on Applications of Computer Vision. Pisca-taway,NJ:IEEE Press, 2021: 1907-1916.
[23]吳仕科,梁宇琦. 基于偽標簽自細化的弱監督實例分割 [J]. 計算機應用研究,2023,40(6): 1882-1887. (Wu Shike,Liang Yuqi. PLSR: weakly supervised instance segmentation via pseudo-label self-refinement [J]. Application Research of Computers,2023,40(6): 1882-1887.)
[24]Zhu Yi,Zhang Zhongyue,Wu Chongruo,et al. Improving semantic segmentation via efficient self-training [J]. IEEE Trans on Pattern Analysis and Machine Intelligence,2024,46(3): 1589-1602.
[25]Souly N,Spampinato C,Shah M. Semi supervised semantic segmentation using generative adversarial network [C]// Proc of IEEE International Conference on Computer Vision. Piscataway,NJ: IEEE Press,2017: 5689-5697.
[26]Wang Yuchao,Wang Haochen,Shen Yujun,et al. Semi-supervised semantic segmentation using unreliable pseudo-labels supplementary material [EB/OL]. (2022-03-08). http://arxiv.org/pdf/2203.03884.pdf.
[27]Karras T,Samuli L,Aittala M,et al. Analyzing and improving the ima-ge quality of StyleGAN [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2020: 8107-8116.
[28]Radford A,Metz L,Chintala S. Unsupervised representation learning with deep convolutional generative adversarial networks [EB/OL]. (2016-01-07). https://arxiv.org/abs/1511.06434.
[29]Yang Lihe,Zhuo Wei,Qi Lei,et al. ST++: make self-training work better for semi-supervised semantic segmentation [C]// Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2022: 4258-4267.
[30]Yun S,Han D,Chun S,et al. CutMix: regularization strategy to train strong classifiers with localizable features [C]// Proc of IEEE/CVF International Conference on Computer Vision. Piscataway,NJ: IEEE Press,2019: 6022-6031.
[31] DeVries T,Taylor G W. Improved regularization of convolutional neural networks with CutOut [EB/OL]. (2017-11-29). https://arxiv.org/abs/1708.04552.
[32]Chen L C,Zhu Yukun,Papandreou G,et al. Encoder-decoder with Atrous separable convolution for semantic image segmentation [C]// Proc of European Conference on Computer Vision. Cham:Springer,2018: 833-851.
[33]Zhao Hengshuang,Shi Jianping,Qi Xiaojuan,et al. Pyramid scene parsing network [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2017: 6230-6239.
[34]Chen L C,Papandreou G,Kokkinos I,et al. DeepLab: semantic image segmentation with deep convolutional nets,Atrous convolution,and fully connected CRFs [J]. IEEE Trans on Pattern Analysis and Machine Intelligence,2017,40(4): 834-848.
