融合CNN和Transformer的并行雙分支皮膚病灶圖像分割
2024-08-15 00:00:00陶惜婷葉青
計算機應用研究 2024年8期







摘 要:準確的皮膚病變自動分割對于協助醫生臨床診斷和治療至關重要。針對現有卷積結構能提取局部特征信息但無法建模長程依賴關系,而Transformer能提取全局上下文信息但存在細節信息丟失的問題,提出了一種融合CNN和Transformer的并行多尺度自動分割網絡PDTransCNN。首先以基于ResNet34的CNN分支和Transformer分支并行提取皮膚病圖像的特征信息,構建多級局部相關性和捕獲上下文信息間的長距離依賴關系;其次利用特征融合模塊FM互補兩分支特征間的關鍵信息,增強語義信息間的依賴關系;最后采用Transformer解碼單元逐步融合編碼塊和融合單元所提取到的語義信息得到最終分割結果。該模型在ISIC2016、ISIC2017和ISIC2018數據集上進行測試,其Dice系數分別高達91.72%、87.34%和90.01%,IoU值分別為85.6%、79.55%和83.67%。實驗結果表明,PDTransCNN相比其他分割模型具有更好的分割性能,能清晰有效地分割皮膚病變圖像。
關鍵詞:皮膚病變; 醫學圖像分割; CNN; Transformer; 特征融合
中圖分類號:TP391 文獻標志碼:A
文章編號:1001-3695(2024)08-044-2554-07
doi:10.19734/j.issn.1001-3695.2023.10.0600
Parallel dual-branch image segmentation of skinlesions fusing CNN and Transformer
Tao Xiting, Ye Qing
(School of Computer Science, Yangtze University, Jingzhou Hubei 434000, China)
Abstract:Accurate automatic segmentation of skin lesions is crucial to assist physicians in clinical diagnosis and treatment. Aiming at the problem that convolutional structure can extract local feature information but cannot model long-range dependencies, while Transformer can extract global context information but suffers from the loss of detail information, this paper proposed a parallel multi-scale automatic segmentation network PDTransCNN that integrated CNN and Transformer. Firstly, it constructed multi-level local correlation and captured long-range dependencies between contextual information by extracting the feature information of dermatological images in parallel with the CNN branch based on ResNet34 and Transformer branch. Secondly, it utilized the feature fusion module(FM) to complement the key information between the two branches of features and enhance the dependencies of the semantic information. Finally, it used the Transformer decoding unit to gradually fuse the semantic information extracted from the encoding block and the fusion unit in order to obtain the final segmentation result. The model was tested on ISIC2016, ISIC2017 and ISIC2018 datasets with Dice coefficients as high as 91.72%, 87.34% and 90.01%, and IoU values of 85.60%, 79.55% and 83.67%, respectively. The experimental results show that PDTransCNN has better segmentation performance compared to other segmentation models and can segment skin lesion images clearly and effectively.
Key words:skin lesions; medical image segmentation; CNN; Transformer; feature fusion
0 引言
黑色素瘤是一種具有高度侵襲性的惡性皮膚腫瘤,產生于皮膚中的黑色素細胞。據世界衛生組織統計[1],2020年黑色素瘤病例高達325 000例,其中死亡病例約57 000例,年增長速度約3%~5%,是發病率增長最快的腫瘤之一。早期黑色素瘤外觀上與痣相似,癥狀不明顯,若病發早期及時干預治療,其5年內存活率高達98%,而晚期黑色素瘤擴散到身體其他部位,其存活率低于15%[2],這種差異表明惡性皮膚病的早期診斷和治療極為重要。
目前,皮膚病的檢查方法大多采用安全無創的皮膚鏡技術,分割皮膚病灶圖像為正常區域和病變區域可為醫生判斷惡性皮膚病提供關鍵依據。然而在臨床診斷中,病變區域本身情況復雜,存在圖像對比度低、病變邊界模糊,以及氣泡、頭發和標尺等不良殘留物的干擾,醫生根據經驗診斷病灶耗時耗力且主觀性強,難免出現誤診和漏診的情況。因此,輔助醫生評估和診斷的皮膚病灶區域自動分割方法被廣泛研究,在臨床領域具有極高的應用價值。
傳統的皮膚病分割方法是基于紋理和結構等物理特征的,只提取了圖像的表層信息,如基于閾值[3]、基于區域[4]、基于邊緣的分割算法等,依賴于手工設計特征,無法刻畫圖像豐富的內在信息,易受毛發、噪聲等干擾因素影響,分割效果有待提高。
近年來,隨著深度學習技術的興起,基于卷積神經網絡的一系列架構應用于圖像分割領域。Long等人[5]提出了全卷積神經網絡,端到端的編解碼結構首次實現了像素級別的圖像分割。2015年,在該架構基礎上,Ronneberger等人[6]提出具有跳躍連接的編解碼U型網絡(U-Net),編碼器與解碼器完全對稱用于特征提取,編解碼器之間的跳躍連接實現了淺層特征和深層特征的融合,輔以醫學圖像獨特的結構特點,該模型成為醫療分割領域的最佳模型之一。在這之后,醫學圖像的分割算法大多是基于U-Net的結構變體,如U-Net++[7]、Attention U-Net[8]等。Tang等人[9]提出在上下文過程中采用多階段U-Net,配合深度監督機制實現端到端的精準皮膚分割。Double U-Net[10]通過兩級嵌套的U型結構細化分割結果,并引入ASPP模塊獲取不同尺度的感受野和多尺度信息,用于解決皮膚病灶區域大小各異的問題。王雪等人[11]在U-Net中引入多尺度特征融合模塊來獲取皮膚病變區域的多尺度信息。梁禮明等人[12]構造雙U型皮膚病分割算法,粗分U型網絡和細分U型網絡分別提取圖像的粗粒度特征和細粒度特征,增強特征學習能力。卷積分割模型不斷改善優化,但受限于卷積固有的歸納偏置,模型感受野有限,難以獲取全局上下文信息,缺乏長距離依賴。而全局信息關系到皮膚病灶的定位,背景與像素之間的長距離依賴對醫學圖像的精細級分割至關重要。
自然語言處理領域的Transformer模型可編碼遠程依賴關系,用于解決卷積架構的感受野局限性。Dosovitskiy等人[13]提出的ViT模型首次將Transformer應用于圖像識別領域,其主要任務是分類,無法解決分割任務中的像素級密集預測問題。2021年提出的Swin-Transformer[14]可用作各類視覺任務中的通用骨干網絡架構,包括圖像分類、圖像分割和目標檢測等具體任務。采用移動窗口多頭注意力,代替原有多頭注意力獲取非局域窗口之間的信息交互,使計算復雜度隨圖像大小線性增長,降低平方級增長的計算量。
雖然Transformer能建模全局上下文,但對細粒度信息的提取具有局限性。為同時具備CNN的局部細節提取能力和Transformer的全局信息建模能力,多數策略是將CNN和Transformer合并研究。Chen等人[15]提出的TransUNet模型,整體結構由CNN和Transformer混合而成,利用CNN提取淺層特征并將提取的特征圖輸入Transformer編碼全局信息,在多器官分割和皮膚病變分割任務中取得優異成績。Zhang等人[16]融合并行CNN分支和Transformer分支,將CNN提取的不同分辨率特征圖與Transformer上采樣特征圖像結合以捕獲皮膚病灶對等特征。梁禮明等人[17]提出多尺度Transformer的U型編解碼皮膚病分割網絡,分層編碼器獲取圖像的粗細粒度特征信息,融合解碼器利用皮膚病灶的多尺度特征信息來生成分割結果。普鐘等人[18]利用基于Transformer的雙通道融合模塊代替U型網絡中的跳躍連接,減輕Transformer和CNN編解碼器間的語義差異。結果表明此種架構可獲得更精準的分割結果,現有皮膚病分割工作大多采用卷積代替部分Transformer層或按順序堆疊兩者,未考慮兩者空間和位置的相關性及兩者特征融合時的信息缺失或冗余。
為解決上述問題,針對現有皮膚病分割方法的局限,從局部信息提取、上下文信息建模和特征融合角度進行研究,提出了一種基于CNN和Transformer的并行雙分支皮膚病分割網絡(parallel dual-branching Transformer-CNN,PDTransCNN)。該架構首先分別運行基于CNN和Transformer的編碼器分支,用于特征提取和捕獲長距離信息,接著是提出的特征融合模塊(fusion module,FM)在不同層次上獲取多尺度融合特征,跳躍連接獲取的多尺度融合特征和編碼器上下文信息的同時,將其輸入基于Transformer的解碼器分支中,得到最終分割結果,提升分割精度。
本文主要貢獻如下:
a)為有效利用不同深度學習模型的優勢,提出了結合CNN和Transformer兩個深度學習模型來構建并行雙分支編碼器。CNN編碼器以ResNet34為骨干網絡提取上下文局部信息,Transformer編碼器在Transformer基礎上添加局部模塊LU來捕獲patch內部的局部關系和結構,Enchanced MLP代替MLP層區分特征并捕獲長距離依賴。
b)針對特征融合,提出多尺度特征融合模塊FM獲取皮膚病灶的多尺度信息,利用空間注意力單元、通道注意力單元和全局-局部卷積相關性單元,融合來自兩個分支不同分辨率的特征,將生成的三個特征圖及掩碼圖像進行跨域融合得到不同域的多尺度融合特征。
c)Transformer解碼器逐步融合來自上下文和跳躍連接兩條路徑的特征,增強特征表示能力。采用深度監督策略獲取階段及最終分割結果,構建損失函數。
d)為評價提出的PDTransCNN模型,使用不同分割模型在ISIC2016、ISIC2017、ISIC2018三個公開皮膚病數據集上進行對比實驗,結果驗證了該方法的有效性,取得了較好的分割結果。
1 方法
醫學圖像分割實質是像素級分類任務,同時獲取皮膚病灶的全局和局部信息是提升分割性能的關鍵。CNN受限于固定的卷積核,感受野有限,無法建模全局信息,Transformer的自注意力機制通過計算可得全局上下文信息,但在切分和拉伸patch過程中易丟失內部信息。本文提出將ResNet34作為CNN骨干,結合Transformer模型構建雙分支網絡,融合來自雙分支提取的特征,提高模型表達能力。在這部分,首先說明PDTransCNN的總體結構,然后介紹兩個分支的工作流程,之后闡述兩分支的特征融合模塊FM如何融合和提取信息,最后簡要說明解碼過程。
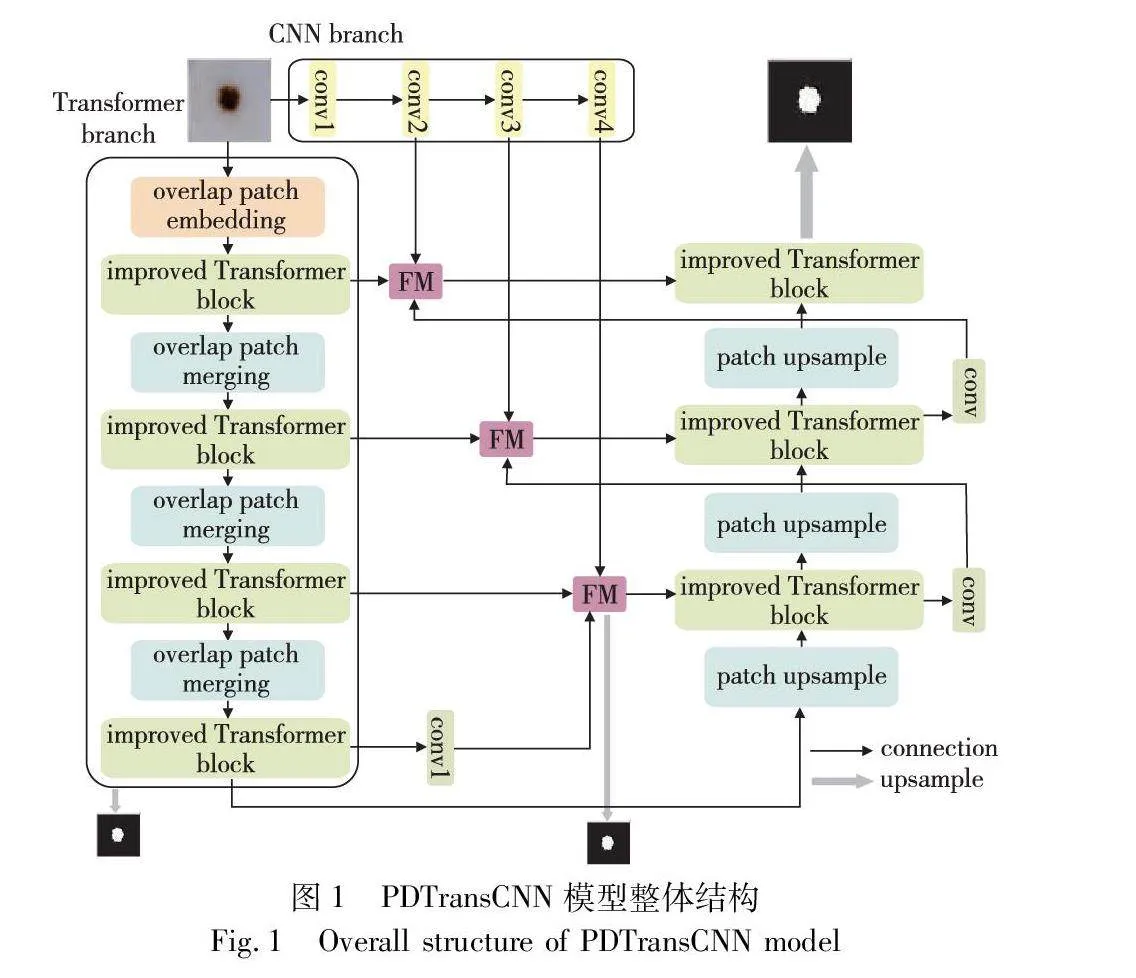
1.1 框架總體
圖1展示了本文模型的整體結構,針對皮膚圖像的數據特點,模型由兩個并行的分支組成。CNN分支中直接輸入圖像,逐漸增加感受野并提取局部信息。Transformer分支首先將皮膚病圖像劃分為若干個小的切片,再將切片展平成一個序列,通過線性映射層變換維度后,進入improved Transformer塊提取全局信息并對特征圖進行下采樣。然后用FM模塊整合兩個分支上對應分辨率的特征圖及掩碼圖像,將生成的融合特征圖及編碼后的特征圖拼接饋送到Transformer解碼器中,變形和上采樣提取的特征圖用于解碼,得到輸出特征圖,并與兩階段的輸出特征圖按比例劃分創建總損失函數,實現分割信息的補充。
1.2 Transformer分支-編碼器
皮膚病灶分割存在整體定位和細節獲取兩個挑戰,目標整體定位的關鍵是利用全局信息突出特征對象,而傳統U-Net模型只運用卷積提取特征,感受野局限導致無法提取全局信息并造成特征丟失情況。基于此,使用能獲取全局上下文特征的Transformer塊代替卷積構建Transformer編碼器分支。
對于Transformer分支,如圖1所示,輸入圖像大小為x0∈Euclid ExtraaBpC×H×W,其中C、H、W分別表示輸入圖像的通道數、高度和寬度。首先將圖像劃分為N=HM×WM個小切片,其中M表示切片的尺寸,每個切片的形狀為C×M×M。切片劃分好后,將切片塊展平為一個序列,進入輸出維度為D的線性映射層,得到原始序列向量x∈Euclid ExtraaBpN×D,這里的維度D取值為64。
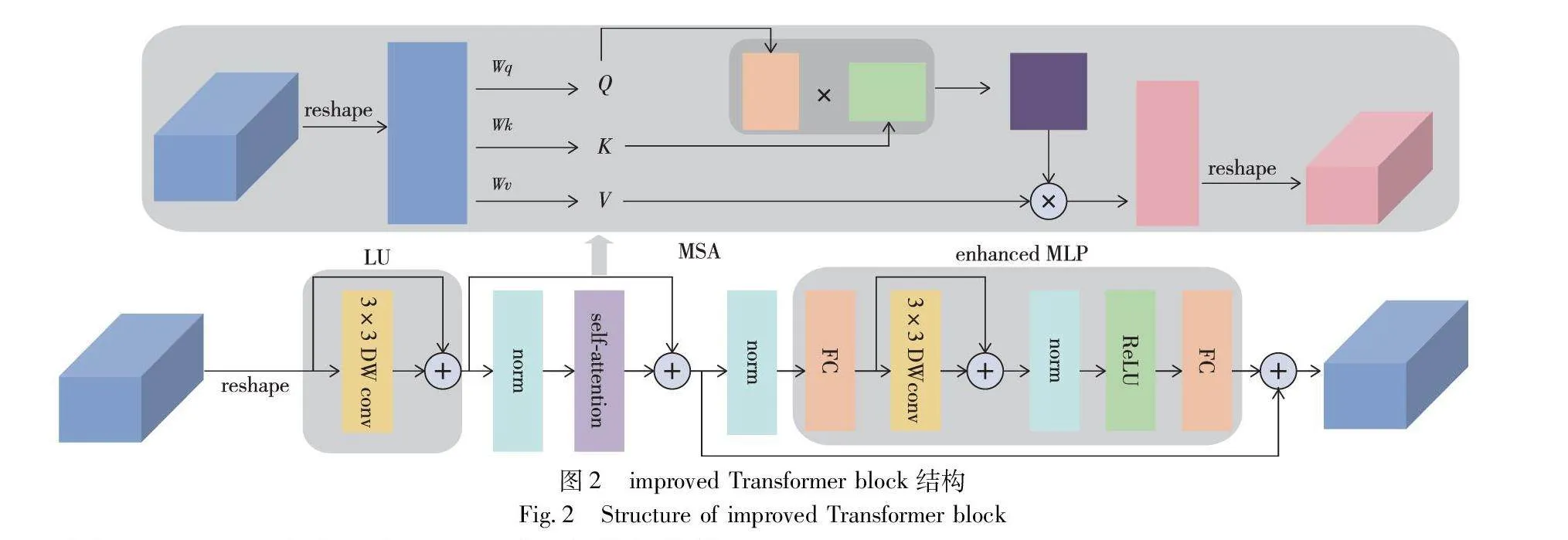
如圖2所示,improved Transformer block包含局部模塊(local unit,LU)、L層多頭自注意力(multi-head self-attention,MSA)和增強多層感知機(enchanced multi-layer perception,Enchanced MLP)。LU模塊利用DW卷積和殘差結構獲取切片內部信息,增強特征表達能力。自注意力中缺乏位置信息,Enchanced MLP模塊對齊并區分提取特征,在前饋網絡中引入深度卷積傳遞位置信息,在深度卷積之前應用殘差連接,在連接后運用層歸一化,可用式(1)(2)表示:
x′in=DWConv(FC(xin))+FC(xin)(1)
xout=FC(ReLU(LN(x′in)))(2)
所以說第L層的總輸出Zl可用式(3)~(5)表示:
z′l-1=DWConv(zl-1)+zl-1(3)
z′l=MSA(LN(z′l-1))+z′l-1(4)
zl=EnchancedMLP(LN(z′l))+z′l(5)
其中:DWConv(·)代表卷積核為3×3的深度卷積操作;FC(·)代表線性映射;ReLU(·)代表使用ReLU激活函數進行非線性變換和梯度傳播,LN(·)代表層歸一化操作。最后improved Transformer層的輸出序列向量為zl∈Euclid ExtraaBpN×D,將其變形為zl∈Euclid ExtraaBpH4×W4×D。
常用的patch merging操作忽略了patch塊之間的相關性,導致patch周圍特征的丟失。本文使用overlap patch merging模塊對特征圖下采樣,在切分patch時,讓每個patch之間存在重疊部分,其操作類似于卷積核在特征圖上的移動,通過修改K、S、P三個參數的值控制特征圖的分辨率,K表示patch的大小,S表示相鄰patch間的距離,P表示填充的大小。每次合并操作后,特征圖的尺寸減半,通道數翻倍。
根據空間分辨率,Transformer分支的編碼器部分可分為四個階段。第一階段由patch嵌入層和兩個improved Transformer塊組成;第二至第四階段由用于下采樣的overlap patch merging塊及提取長程依賴關系的improved Transformer塊構成,每階段improved Transformer塊的數量分別為2、6、2。四個階段中,每階段的輸出特征圖分別用g1、g2、g3和g4表示,其大小分別為H4×W4×C、H8×W8×2C、H16×W16×4C、H32×W32×8C。保存四個不同分辨率的特征圖,以便后續與CNN分支對應特征圖的融合。
1.3 CNN分支
CNN分支通過ResNet34的編碼塊創建特征提取網絡,實現高分辨率圖像到低分辨率圖像的轉換。經過預訓練的ResNet34自然特征豐富,能為皮膚病灶的分割提高初始權重,獲取皮膚圖像局部上下文特征和豐富的空間細節信息。如圖1所示,conv1表示使用7×7的卷積核提取信息并修改通道數,然后依次經過ResNet34的三個塊conv2、conv3和conv4,每個塊都將特征圖下采樣2倍,將conv2的輸出t1∈H4×W4×C、conv3的輸出t2∈H8×W8×2C和conv4的輸出t3∈H16×W16×4C的特征圖與Transformer分支對應相同分辨率的特征圖進行特征融合,增強Transformer分支解碼器的表示能力。
1.4 特征融合模塊
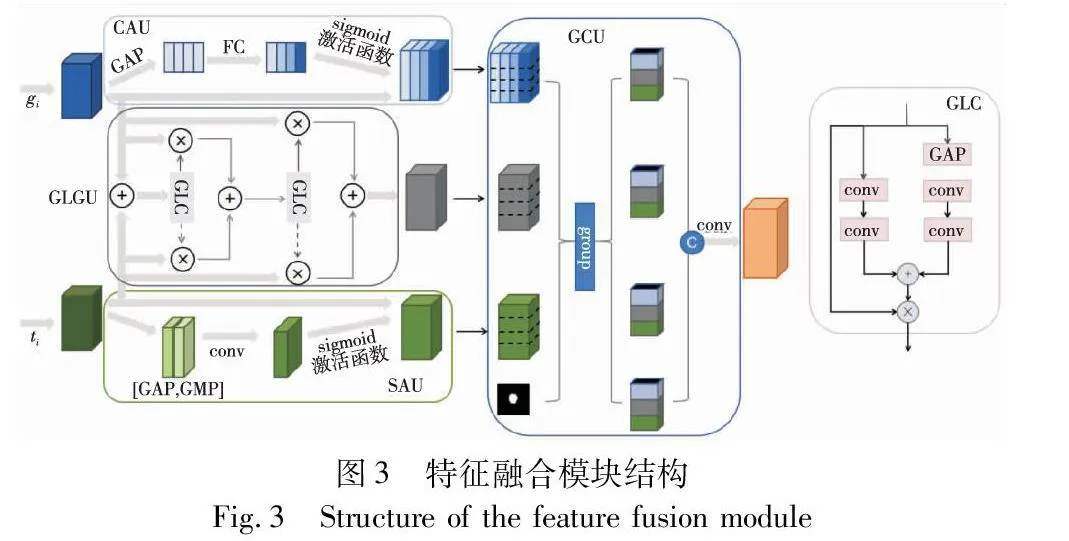
考慮到皮膚病變分割目標尺度各異、形狀多變復雜,同時一些病灶邊緣模糊且伴有毛發遮擋的問題,需充分結合來自Transformer分支和CNN分支的全局和局部特征信息,因此本文提出一個特征融合模塊FM,有效融合不同分辨率的特征細節信息。該模塊設計了通道注意力單元(channel attention unit,CAU)、空間注意力單元(spatial attention unit,SAU)、全局-局部卷積相關性單元(global-local conv unit,GLCU)和組跨域融合單元(group cross-domain unit,GCU)四個小模塊,如圖3所示。
第一塊是通道注意力單元(CAU),將來自Transformer編碼器分支的輸出特征gi作為該模塊的輸入,用于獲取特征圖不同通道的重要程度,找到特征圖關鍵通道上的重要信息并抑制其他通道的無關信息,提高特征表示能力。同時improved Transformer塊中使用自注意力建模長距離依賴,將CAU應用于Transformer分支,相當于實現自注意力和通道注意力的混合,豐富注意力特征圖的細節信息,緩解皮膚鏡圖像低對比度、顏色差異相近產生的噪聲干擾。CAU的實現為文獻[19]提出的SE-Block模塊,包含壓縮和擴張兩部分,壓縮部分將輸入特征圖gi∈Euclid ExtraaBpCi×Hi×Wi經過全局平均池化變換維度為Ci×1×1。擴張部分使用兩個全連接層(FC),經過第一個FC層將通道數變換為Cg/r,r代表壓縮比,設置為16,經過ReLU激活函數激活相關性大的有效通道后進入第二個FC層恢復原始通道數Cg,通過sigmoid函數進行不同通道間的非線性映射,與原始輸入特征圖相乘得到加權后的通道注意力特征圖gi′。
第二塊是空間注意力單元(SAU),淺層CNN特征存在噪聲,將來自CNN分支的輸出特征ti作為該模塊的輸入,加權特征圖的空間位置,抑制背景噪聲的影響,增強局部邊界細節特征信息。采用文獻[20]提出的CBAM模型中的空間注意力模塊,將輸入特征圖ti∈Euclid ExtraaBpCi×Hi×Wi沿通道軸進行最大池化和平均池化操作,產生兩個大小為1×Hi×Wi的通道注意力圖,并將它們在維度方向上拼接。然后利用7×7的卷積操作獲取特征之間的空間關系以便學習關鍵位置的重要信息,經過sigmoid函數后與初始特征圖相乘得到空間注意力圖ti′,如式(6)所示。
ti′=sigmoid(conv7×7 (AvgPool(ti)+MaxPool(ti)))ti(6)
第三塊是全局-局部卷積相關性單元(GLCU),目前處理兩個特征圖時,大多采用單一的加或乘操作,忽略了特征圖之間的對應關系和相關性。如圖3所示,GLC是GLCU的子模塊,將輸入劃分為兩個部分,這兩部分唯一不同之處在于通過逐點卷積交互空間位置前,一部分利用全局平均池化聚合了空間信息。將生成的特征圖經過sigmoid函數后與初始圖像對應元素相乘形成殘差結構,如式(7)(8)所示。
convx(x)=LN(conv(ReLU(LN(conv(x)))))(7)
GLC(x)=xsigmoid(convx(GAP(x))⊕convx(x))(8)
其中:LN(·)表示批歸一化操作;GLC(x)表示GLC模塊的輸出結果;表示對應元素相乘;⊕表示對應元素相加。給定分別來自CNN、Transformer分支的特征圖gi、ti∈Euclid ExtraaBpCi×Hi×Wi,經過加權平均自適應生成融合了gi和ti關鍵信息的特征圖mi′,如下所示。
mi=GLC(ti⊕gi)gi+(1-GLC(ti⊕gi))ti(9)
mi′=GLC(mi)gi+(1-GLC(mi))ti(10)
第四塊是組跨域融合單元(GCU),通過分組聚合不同層次的特征,有效集成不同關鍵特征用于多尺度特征融合。GCU有四個輸入:空間注意力特征圖、通道注意力特征圖、融合相關性特征圖和解碼器階段產生的掩碼圖像。解碼器每階段的輸出經過卷積產生對應的掩碼圖像協助多尺度特征融合。將三個特征圖都沿通道軸分為四塊,每組連接各個特征圖的一塊并級聯掩碼圖像,獲得四組融合特征。各組利用不同的擴張速率(1,2,5,7)提取不同尺度信息。拼接四組并使用1×1卷積生成跨域融合特征圖,增強來自不同域的特征并實現特征間的交互。
1.5 Transformer分支-解碼器
解碼器由三個階段組成,每階段堆疊上采樣、跳過連接和improved Transformer塊。編碼器第四階段的輸出作為解碼器的輸入d∈H32×W32×8C。解碼器的每個階段,首先將輸入特征2倍上采樣,然后利用跳過連接級聯來自FM模塊的相同分辨率的融合特征,并將連接后的特征饋送到解碼塊,在解碼器中實現上下文交互并創建長距離依賴。三個階段的輸出分別為d1∈H16×W16×4C,d2∈H8×W8×2C,d3∈H4×W4×C,最后使用擴展率為4的上采樣操作恢復圖像大小,并通過卷積調整通道數,為分割類別數獲得最終預測結果S1。
1.6 損失函數
本文采用加權IoU損失函數LIoU和二進制交叉熵損失函數LBCE進行模型訓練,并使用深度監督方法額外監控Transformer編碼器分支第四階段的輸出S2和FM第三融合階段的輸出S3,輔助模型訓練學習,改善梯度流,最終的損失函數公式如式(11)~(14)所示。
LBCE=-[ylogy′+(1-y)log(1-y′)](11)
LIoU=1-yy'y+y'-yy'(12)
L=LIoU+LBCE(13)
Loss=αL(y,S1)+βL(y,S2)+γL(y,S3)(14)
其中:y表示真實分割標簽圖像;y'表示模型預測值;α、β、γ作為超參數表示不同階段的權重,設置為0.5、0.3、0.2。
2 實驗和結果分析
2.1 實現方法
PDTransCNN模型以待分割皮膚病灶圖像為輸入,以訓練完成的網絡模型作為輸出,i表示不同階段,具體實驗步驟如下:
a)Transformer分支特征提取,將輸入圖像映射為嵌入向量,利用自注意力機制建模獲取全局上下文信息gi,詳細實現過程參見1.2節。
b)CNN分支特征提取,基于ResNet34組成的CNN特征提取網絡獲取皮膚圖像豐富的局部信息ti,詳細實現過程參見1.3節。
c)多尺度特征融合,為有效結合CNN分支和Transformer分支的編碼特征,利用通道注意力增強gi特征表示能力,空間注意力增強ti局部細節信息,并利用卷積相關性單元加強兩特征圖之間的對應關系,分組集成關鍵特征來獲取多尺度特征融合圖fi,詳細實現過程參見1.4節。
d)特征融合圖fi與全局上下文特征圖gi拼接后通過Transformer解碼器逐步上采樣,并將每階段解碼結果通過卷積生成對應掩碼送入步驟c)的下階段特征融合模塊,采樣至原始圖像大小獲取最終分割圖像Si,詳細實現過程參見1.5節。
e)構建損失函數計算真實值和分割圖像Si的差值,并反向傳播訓練模型,計算評價指標。直至訓練次數達標,獲取訓練好的模型,詳細實現過程參見1.6節。
2.2 數據集和實驗設置
為驗證本文網絡結構,在國際皮膚成像協會(The International Skin Imaging Collaboration,ISIC)發布的ISIC2016[21]、ISIC2017[22]和ISIC2018[23]三個公共數據集上進行綜合實驗。ISIC2016數據集包含900張訓練圖片和379張測試圖片,將訓練圖片按8∶2劃分為訓練集和驗證集。ISIC2017數據集包含2 750張圖片,其中訓練圖片2 000張,驗證圖片150張,測試圖片600張。ISIC2018數據集包含2 594張訓練圖片、100張驗證圖片和1 000張測試圖片。每組數據都包含原圖像和經專家手動標注的分割標準圖像,圖像分辨率都在450pi×600pi以上,本文統一將所有圖像重塑為224pi×224pi大小,并通過翻轉、剪裁等數據增強操作增加數據多樣性。
所有實驗基于PyTorch深度學習框架,處理器CPU為Intel Xeon Gold 5120,內存容量32 GB,顯卡為NVIDIA GRID T4-16Q,操作系統為Windows 10,實驗仿真平臺為SageMaker Studio Lib,開發工具為PyCharm 2022.1.2社區版,編程語言為Python 3.8。訓練過程中使用Adam算法優化模型,初始學習率為7E-5,一階和二階矩估計的指數衰減率分別為0.5和0.999,權重衰減為1E-5,實驗進行25輪迭代,批處理大小設置為16。
2.3 評價指標
本文采用Dice相似系數(Dice similarity coefficient,DSC)、準確率(accuracy,ACC)和交并比(intersection over union,IoU)來評估模型在皮膚鏡圖像上的分割性能。DSC指標衡量分割標簽和預測結果的相似度,取值在0~1,其值越高表示預測結果與標簽契合度越高。ACC計算正確分類像素的數量與總像素數量間的比值,準確率越高,模型判斷病變和正常區域的能力越強。IoU表示預測值與真實值之間的交并比,各指標計算公式如下:
DSC=2TP2TP+FP+FN(15)
ACC=TP+TNTP+TN+FP+FN(16)
IoU=TPTP+FP+FN(17)
其中:TP表示真陽性,代表病灶區域被正確分割;FN表示真陰性,代表正常區域被正確分割;FP表示假陽性,代表正常區域誤分割為病灶區域;FN表示假陰性,代表病灶區域誤分割為正常區域。
2.4 分割結果
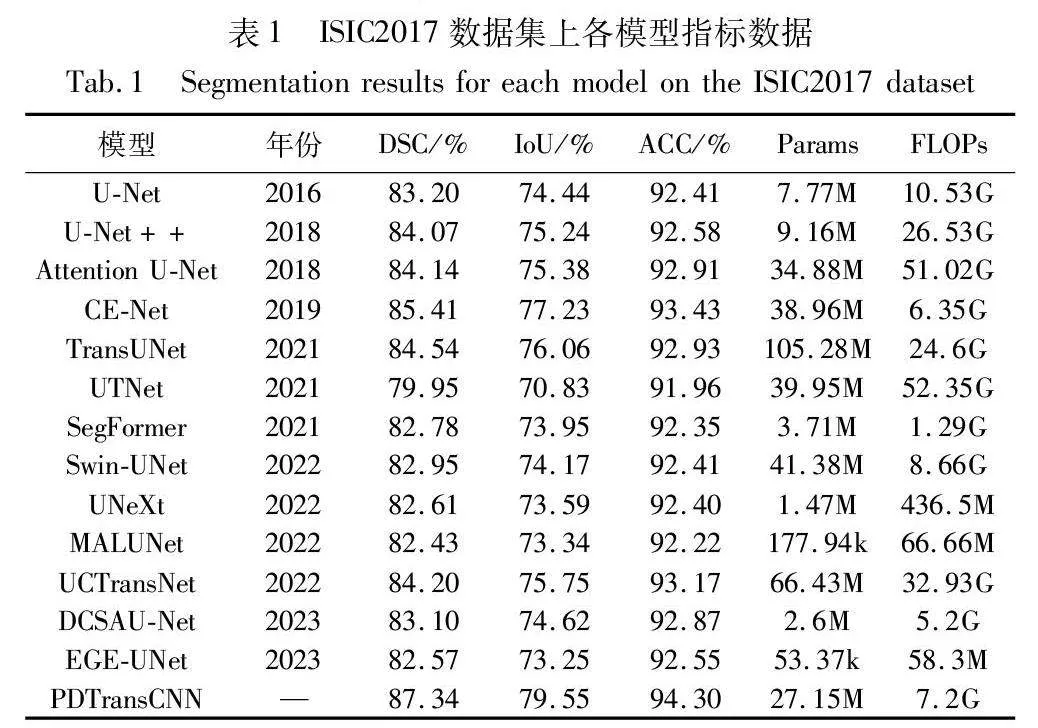
為驗證本文模型PDTransCNN的有效性,根據上述訓練設置參數和相同配置環境,選取U-Net、U-Net++、Attention U-Net、CE-Net[24]、TransU Net、UTNet[25] 、SegFormer[26]、Swin-UNet[27]、UNeXt[28]、MALUNet[29]、UCTransNet[30]、DCSAU-Net[31]、EGE-UNet[32]等語義分割基礎網絡和醫學分割先進方法在ISIC2016、ISIC2017、ISIC2018三個皮膚病公開數據集上進行對比實驗,不同網絡預測的分割性能指標如表1、2所示。
從表1可得在ISIC2017數據集上本文網絡PDTransCNN分割性能優異,在DSC、IoU和ACC指標上性能較好,分別達到87.34%、79.55%和94.30%。U-Net、U-Net++等模型是基于U形結構構建的,可捕獲局部上下文信息和定位像素,但其缺乏全局信息,TransUNet、Swin-UNet等模型利用了Transformer建立長距離特征依賴關系,獲取豐富的全局信息,但缺失細粒度局部信息。PDTransCNN與醫學分割基礎模型U-Net相比,在各項指標上分別提高了4.14、5.11和1.89百分點。比次優網絡CE-Net在DSC指標上提高1.93百分點,IoU指標上提高2.32百分點,ACC指標上提升0.87百分點。相較于其他先進對比模型,PDTransCNN在三個指標中都達到最佳值,表明該模型能較為精準地區分皮膚病變區域像素和正常區域像素,其預測結果與真實值高度相似,CNN和Transformer的雙向多尺度融合應用,使本文模型更好地感知并獲取細節信息和關鍵特征,降低病變區域誤分割的概率,提升分割精度。
此外,本文還對比分析了各醫學圖像分割模型的參數量和計算復雜度,結果如表1所示。PDTransCNN為了能提取更豐富有效的特征上下文信息,采用并行雙分支結構分別獲取全局和局部復雜信息,特征融合模塊互補融合缺失信息,模塊結構相對復雜,導致模型的參數量和計算復雜度稍高。相對于U-Net、U-Net++模型,本文參數量較高,但計算復雜度降低了3.33G和19.33G,相較于TransUNet、UCTransNet、UTNet等基于CNN和Transformer的模型,PDTransCNN參數量和計算復雜度大幅度降低,但相較于SegFormer、EGE-UNet等輕量級模型,PDTransCNN參數量和計算量指標相對較高。這是一個權衡的過程,但對于醫療領域,分割精度和準確性是至關重要的目標,增加的參數有利于提升模型分割效果。綜合DSC等性能指標、參數量和計算復雜度,PDTransCNN在保持較高分割精度的同時具有適宜的參數量和計算復雜度。
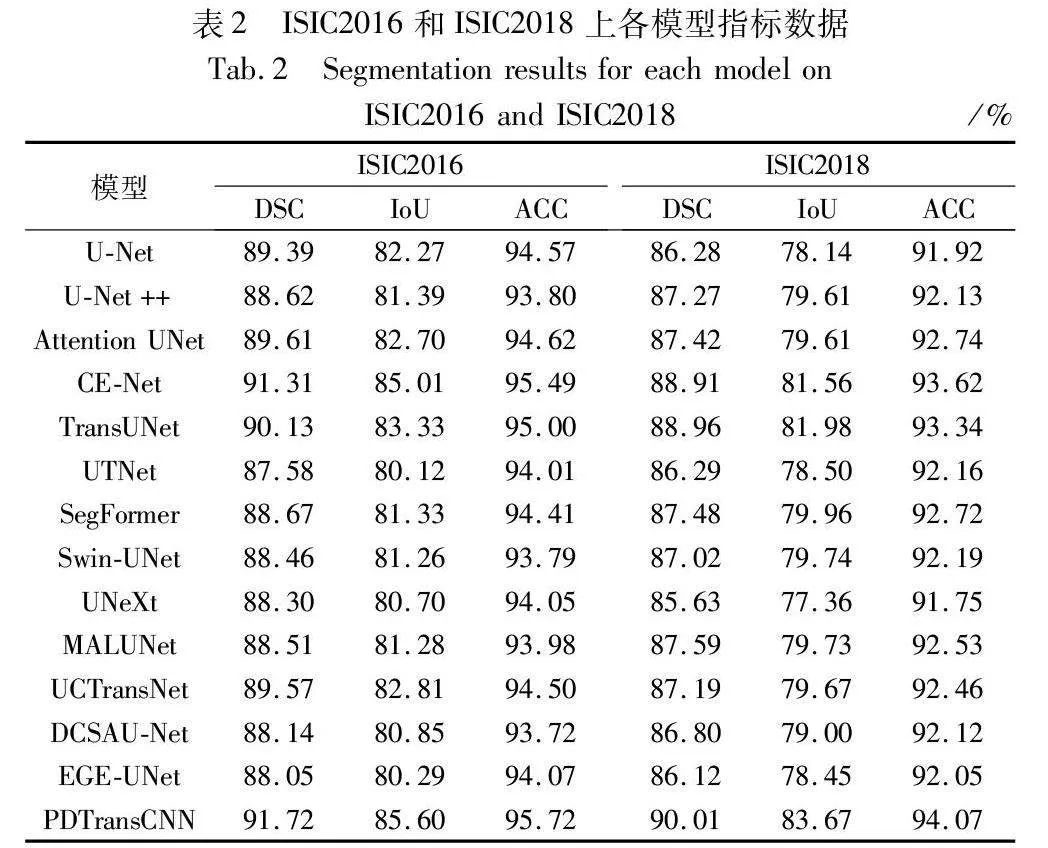
表2展示了各模型在ISIC2016和ISIC2018數據集上的測試結果,其中DSC值達到91.72%和90.01%,IoU值達到85.60%和83.67%,ACC值達到95.72%和94.07%。比ISIC2016數據集上的次優網絡CE-Net在各項指標上分別提升了0.41百分點、0.59百分點和0.23百分點。與ISIC2018數據集上的次優網絡TransUNet相比,DSC值提升1.05百分點,IoU提升1.69百分點,ACC提升0.73百分點。PDTransCNN的分割預測結果更接近真實掩碼圖像。
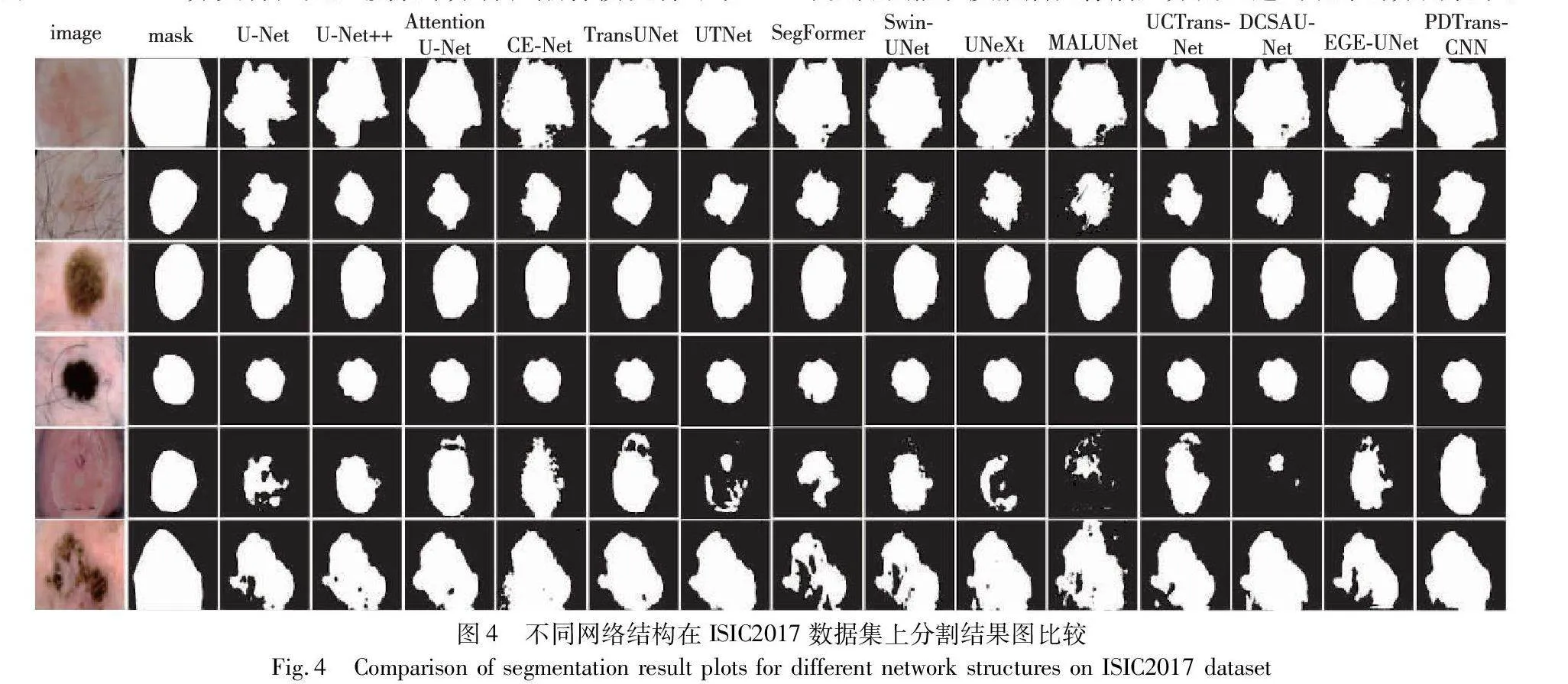
為更直觀地反映PDTransCNN相較于其他算法的優越性,圖4可視化展示了14種網絡在ISIC2017數據集上的分割結果,圖中每行表示一例病例,每列表示使用的模型,image表示原圖,mask表示專家對原圖的分割結果。第三幅和第四幅病變圖像中,病灶區域邊緣輪廓清晰,且與正常皮膚組織區分度明顯,各模型都產生良好的分割結果。在第一幅圖像中,從左到右病變區域顏色逐漸變淺,淺色區域與正常區域像素差異小,邊界模糊,U-Net和U-Net++未利用全局信息,導致難以定位邊緣位置,其他模型都未完整分割病變區域,分割結果不完整。第二幅圖像中存在毛發遮擋,且病變區域與皮膚組織顏色相近,UTNet等不能有效區分細節顏色相似的地方。第五幅和第六幅圖像病變區域顏色深淺不一,存在漏檢誤檢現象,U-NeXt、SegFormer難以獲取細節特征易誤分背景和病變區域。相比之下,本文模型具有獲取局部細粒度信息和建模全局上下文信息的能力,同時多尺度特征融合強化特征信息,使其能較為平滑地分割病灶,皮膚邊緣輪廓細節信息更加明顯,漏檢和誤檢較為輕微,分割結果更貼近真實掩碼圖像,但仍存在缺少部分邊緣細節的情況。
2.5 消融實驗
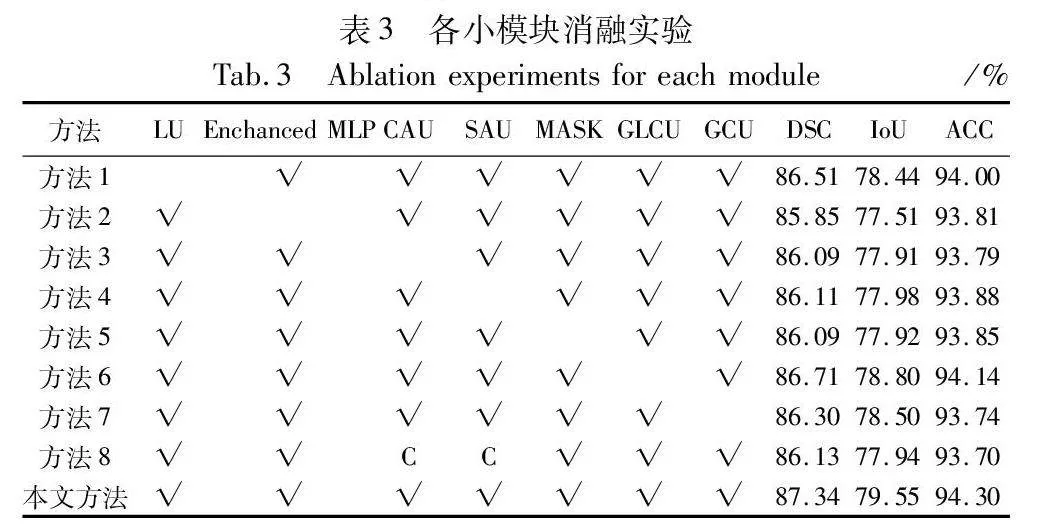
2.5.1 各模塊消融實驗
PDTransCNN模型共具有若干個小模塊,為探討不同小模塊對模型性能的影響,利用控制變量的方法在ISIC2017數據集上進行各模塊消融實驗。如表3所示,方法1~9的編號分別代表添加對應模塊所獲得的量化指標。C表示交換通道注意力和空間注意力的輸入特征為對應分辨率的CNN分支特征圖和Transformer分支特征圖。移除部分特征融合模塊將導致高低級特征融合時丟失部分空間信息并獲取無關通道信息,缺失關鍵的多尺度信息特征。CAU塊篩選有效通道信息,掩碼圖像輔助特征融合,豐富特征像素。實驗結果表明各模塊的有效性,任一模塊缺失將導致總體模型性能下降,相較于對比模型,本文方法能在皮膚病圖像病灶分割上達到最好的分割效果。
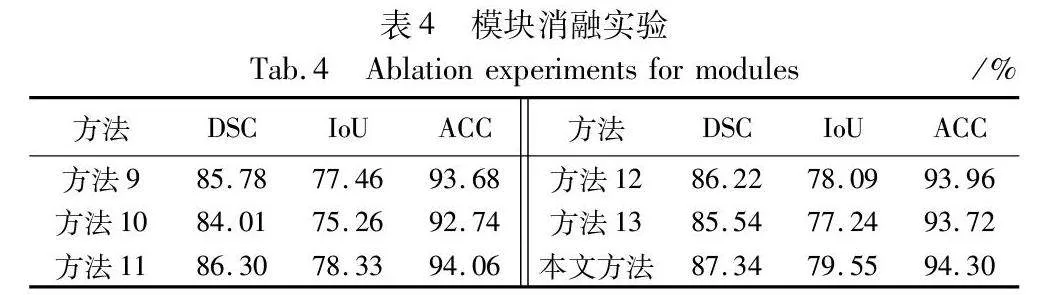
2.5.2 組合模塊消融實驗
表4展示了基于本文完整模型下,使用單分支及組合模塊后的實驗數據,默認使用深度監督機制。方法9只以ResNet34為編碼器分支,方法10只以Transformer為編碼器分支,方法11以CNN和Transformer并行雙分支為編碼器的基礎上加入特征融合模塊,不利用深度監督機制,方法12以CNN和Transformer并行雙分支為基礎加入普通卷積作為融合模塊,方法13以CNN和Transformer并行雙分支為基礎,使用Transformer block代替improved Transformer block。由表4可知,將CNN和Transformer分支并行利用添加到PDTransformer網絡中后,指標有大幅度提升,相較于單分支結構,DSC值分別提高了1.56百分點、3.33百分點,IoU值提高了2.09百分點、4.29百分點。同時學習圖像的局部細節特征和全局依賴信息能實現病變區域的整體定位和邊緣信息的獲取。特征融合模塊取代普通卷積能更好地互補高低級分辨率特征,減少圖像關鍵信息的丟失,提取網絡的深層特征和淺層特征。improved Transformer block模塊利用殘差思想和DW卷積提取豐富全面的特征信息,減少切片內的信息丟失。消融實驗闡明了本文網絡雙分支結構和組合模塊對于分割性能提升的有效性。
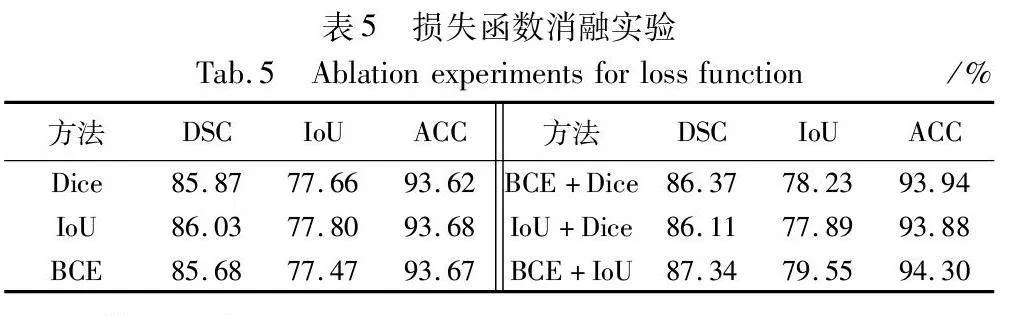
2.5.3 損失函數消融實驗
為驗證本文采用的目標損失函數的有效性,在本文模型結構基礎上,和常用損失函數DiceLoss、IoULoss、BCELoss以及兩者結合的BCEDiceLoss、IoUDiceLoss進行比較,實驗結果如表5所示。本文所用的BCEIoULoss性能優于其他對比損失函數,比次優BCEDiceLoss在DSC和IoU指標上分別高出0.97百分點和1.32百分點。單獨使用IoU或DSC損失函數訓練,難以解決病變分割面臨的正負樣本不平衡問題,結合兩者能綜合考慮像素和區域級別的信息,緩解正負樣本不平衡問題,產生最好的分割效果。
2.6 模型的應用
PDTransCNN主要應用于皮膚病灶自動分割,流程如圖5所示。首先對皮膚鏡圖像進行預處理,包括統一圖像分辨率、數據增強和圖像歸一化操作,使網絡能更好地學習圖像特征并加快收斂速度。隨后將網絡送入PDTransCNN模型,同時經過CNN分支和Transformer分支后,在Transformer解碼器模塊融合特征融合模塊所提取的多尺度特征,輸出各階段皮膚病灶的分割結果并進行結果評估,最后將評估結果與初始皮膚鏡圖像一起顯示在分割信息中。還可將訓練好的模型用于新的皮膚鏡圖像數據,生成對應的分割信息,為后續診斷、治療或研究提供支持。
3 結束語
為解決CNN結構存在的歸納偏置和Transformer結構的局部細節信息缺失問題,本文提出了一種用于皮膚病灶分割的融合CNN和Transformer的并行混合結構,通過并行分支對圖像進行特征提取,并利用空間注意力單元、通道注意力單元和全局-局部卷積相關性單元構成強化關鍵特征信息的特征融合模塊,交互來自兩分支的細粒度特征,最大程度地利用多尺度信息。此外,采用深度監督機制構建損失函數,通過參數調整增強模型學習能力。對比13種經典的分割網絡,在ISIC2016、ISIC2017、ISIC2018三個數據集上進行測試,實驗證明本文網絡可較好地分割皮膚病變圖像,分割精度較高,在皮膚疾病的實際診療中有一定的參考價值。在未來的研究中,模型還存在輕量化的空間,降低模型參數量,優化模型至能實際應用到多種醫學圖像分割任務中。
參考文獻:
[1]Sung H, Ferlay J, Siegel R L, et al. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries[J]. CA: a Cancer Journal for Clinicians, 2021,71(3): 209-249.
[2]Fontanillas P, Alipanahi B, Furlotte N A, et al. Disease risk scores for skin cancers[J]. Nature Communications, 2021, 12(1): 1-13.
[3]Yen J C, Chang F J, Chang S. A new criterion for automatic multilevel thresholding[J]. IEEE Trans on Image Processing, 1995, 4(3): 370-378.
[4]Tremeau A, Borel N. A region growing and merging algorithm to color segmentation[J]. Pattern Recognition, 1997, 30(7): 1191-1203.
[5]Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press, 2015: 3431-3440.
[6]Ronneberger O, Fischer P, Brox T. U-Net: convolutional networks for biomedical image segmentation[C]//Proc of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer, 2015: 234-241.
[7]Zhou Zongwei , Siddiquee M M R, Tajbakhsh N, et al. U-Net++: a nested U-Net architecture for medical image segmentation[C]//Deep Learning in Medical Image Analysis and Multimodal Learning for Cli-nical Decision Support. Cham:Springer, 2018: 3-11.
[8]Oktay O, Schlemper J, Folgoc L L, et al. Attention U-Net: learning where to look for the pancreas[EB/OL]. (2018-05-20). https://arxiv.org/abs/1804.03999.
[9]Tang Yujiao, Yang Feng, Yuan Shaofeng. A multi-stage framework with context information fusion structure for skin lesion segmentation[C]//Proc of the 16th IEEE International Symposium on Biomedical Imaging. Piscataway, NJ: IEEE Press, 2019: 1407-1410.
[10]Jha D, Riegler M A, Johansen D, et al. DoubleU-Net: a deep convo-lutional neural network for medical image segmentation[C]// Proc of the 33rd IEEE International Symposium on Computer-based Medical Systems. Piscataway, NJ: IEEE Press, 2020: 558-564.
[11]王雪. 基于U-Net多尺度和多維度特征融合的皮膚病變分割方法[J]. 吉林大學學報:理學版, 2021, 59(1): 123-127. (Wang Xue. Skin lesion segmentation method based on U-Net with multi-scale and multi-dimensional feature fusion[J]. Journal of Jilin University:Science Edition, 2021, 59(1): 123-127.)
[12]梁禮明, 彭仁杰, 馮駿,等. 基于多尺度特征融合雙U型皮膚病變分割算法[J]. 計算機應用研究, 2021, 38(9): 2876-2880. (Liang Liming, Peng Renjie, Feng Jun, et al. Skin lesion image segmentation algorithm based on multi-scale feature fusion double U-Net[J]. Application Research of Computers, 2021, 38(9): 2876-2880.)
[13]Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16×16 words: Transformers for image recognition at scale[EB/OL]. (2021-06-03). https://arxiv.org/abs/2010.11929.
[14]Liu Ze, Lin Yutong, Cao Yue, et al. Swin Transformer: hierarchical vision transformer using shifted windows[C]//Proc of IEEE/CVF International Conference on Computer Vision. Piscataway, NJ: IEEE Press, 2021: 9992-10002.
[15]Chen Jieneng, Lu Yongyi, Yu Qihang, et al. TransUNet: transfor-mers make strong encoders for medical image segmentation[EB/OL]. (2021-02-08). https://arxiv.org/abs/2102.04306.
[16]Zhang Yundong, Liu Huiye, Hu Qiang. TransFuse: fusing transfor-mers and CNNs for medical image segmentation[C]//Proc of the 24th International Conference on Medical Image Computing and Computer Assisted Intervention. Cham: Springer, 2021: 14-24.
[17]梁禮明, 周瓏頌, 尹江,等. 融合多尺度Transformer的皮膚病變分割算法[J]. 吉林大學學報 :工學版, 2024,54(4):1086-1098. (Liang Liming, Zhou Longsong, Yin Jiang, et al. Fusion multi-scale transformer skin lesion segmentation algorithm[J]. Journal of Jilin University :Engineering and Technology Edition, 2024,54(4):1086-1098.)
[18]普鐘, 張俊華, 黃昆,等. 融合多注意力機制的脊椎圖像分割方法[J]. 計算機應用研究, 2023, 40(4): 1256-1262. (Pu Zhong, Zhang Junhua, Huang Kun, et al. Spinal image segmentation method with multi-attention[J]. Application Research of Computers, 2023, 40(4): 1256-1262.)
[19]Hu Jie, Shen Li, Sun Gang. Squeeze-and-excitation networks[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2018: 7132-7141.
[20]Woo S, Park J, Lee J Y, et al. CBAM: convolutional block attention module[C]//Proc of European Conference on Computer Vision. Cham: Springer, 2018: 3-19.
[21]Gutman D, Codella N C F, Celebi E, et al. Skin lesion analysis toward melanoma detection: a challenge at the international symposium on biomedical imaging(ISBI) 2016, hosted by the international skin imaging collaboration (ISIC)[EB/OL]. (2016-05-04). https://arxiv.org/abs/1605.01397.
[22]Codella N C F, Gutman D, Celebi M E, et al. Skin lesion analysis toward melanoma detection: a challenge at the 2017 international symposium on biomedical imaging(ISBI) , hosted by the international skin imaging collaboration(ISIC)[C]//Proc of the 15th IEEE International Symposium on Biomedical Imaging. Piscataway, NJ: IEEE Press, 2018: 168-172.
[23]Codella N, Rotemberg V, Tschandl P, et al. Skin lesion analysis toward melanoma detection 2018: a challenge hosted by the internatio-nal skin imaging collaboration(ISIC)[EB/OL]. (2019-03-29). https://doi.org/10.48550/arXiv.1902.03368.
[24]Gu Zaiwang, Cheng Jun, Fu Huazhu, et al. CE-Net: context encoder network for 2D medical image segmentation[J]. IEEE Trans on Medical Imaging, 2019, 38(10): 2281-2292.
[25]Gao Yunhe, Zhou Mu, Metaxas D N. UTNet: a hybrid transformer architecture for medical image segmentation[C]//Proc of Internatio-nal Conference on Medical Image Computing and Computer-Assisted Intervention. Cham:Springer, 2021: 61-71.
[26]Xie Enze, Wang Wenhai, Yu Zhiding, et al. SegFormer: simple and efficient design for semantic segmentation with transformers[J]. Advances in Neural Information Processing Systems, 2021, 34: 1a7788ea1267ab3a3eb788c29d228d87ce93eff219cfa0211dc55ff10e27bc6e12077-12090.
[27]Cao Hu, Wang Yueyue, Chen J, et al. Swin-UNet: UNet-like pure transformer for medical image segmentation[C]//Proc of European Conference on Computer Vision. Cham: Springer, 2022: 205-218.
[28]Valanarasu J M J, Patel V M. UNeXt: MLP-based rapid medical image segmentation network[C]//Proc of International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer, 2022: 23-33.
[29]Ruan Jiacheng, Xiang Suncheng, Xie Mingye, et al. MALUNet: a multi-attention and light-weight U-Net for skin lesion segmentation[C]//Proc of IEEE International Conference on Bioinformatics and Biomedicine. Piscataway, NJ: IEEE Press, 2022: 1150-1156.
[30]Wang Haonan, Cao Peng, Wang Jiaqi, et al. UCTransNet: rethinking the skip connections in U-Net from a channel-wise perspective with transformer[C]//Proc of AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2022: 2441-2449.
[31]Xu Qing, Ma Zhicheng, He Na, et al. DCSAU-Net: a deeper and more compact split-attention U-Net for medical image segmentation[J]. Computers in Biology and Medicine, 2023, 154: 106626.
[32]Ruan Jiacheng , Xie Mingye , Gao Jingsheng, et al. EGE-UNet: an efficient group enhanced U-Net for skin lesion segmentation[C]//Proc of International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer, 2023: 481-490.
