基于多頻特征和紋理增強的輕量化圖像超分辨率重建
2024-08-15 00:00:00劉媛媛張雨欣王曉燕朱路
計算機應用研究 2024年8期










摘 要:現有基于卷積神經網絡主要關注圖像重構的精度,忽略了過度參數化、特征提取不充分以及計算資源浪費等問題。針對上述問題,提出了一種輕量級多頻率特征提取網絡(MFEN),設計了輕量化晶格信息交互結構,利用通道分割和多模式卷積組合減少參數量;通過分離圖像的低頻、中頻以及高頻率信息后進行特征異構提取,提高網絡的表達能力和特征區分性,使其更注重紋理細節特征的復原,并合理分配計算資源。此外,在網絡內部融合局部二值模式(LBP)算法用于增強網絡對紋理感知的敏感度,旨在進一步提高網絡對細節的提取能力。經驗證,該方法在復雜度和性能之間取得了良好的權衡,即實現輕量有效提取圖像特征的同時重建出高分辨率圖像。在Set5數據集上的2倍放大實驗結果最終表明,相比較于基于卷積神經網絡的圖像超分辨率經典算法(SRCNN)和較新算法(MADNet),所提方法的峰值信噪比(PSNR)分別提升了1.31 dB和0.12 dB,參數量相比MADNet減少了55%。
關鍵詞:圖像超分辨率重建;卷積神經網絡;輕量化;多頻率特征提取;局部二值模式算法
中圖分類號:TN911.73 文獻標志碼:A 文章編號:1001-3695(2024)08-038-2515-06
doi: 10.19734/j.issn.1001-3695.2023.09.0561
Lightweight image super-resolution reconstruction with multi-frequency feature and texture enhancement
Liu Yuanyuan, Zhang Yuxin, Wang Xiaoyan, Zhu Lu
(College of Information Engineering, East China Jiaotong University, Nanchang 330013, China)
Abstract:
Existing studies based on convolutional neural networks mainly focus on the accuracy of image reconstruction, ignoring problems such as excessive parameters, insufficient feature extraction, and resource waste. In response to the above, this paper proposed multi-frequency feature extraction network (MFEN), which designed a lightweight lattice information interaction structure and used channel segmentation with multi-mode convolution combination to reduce the number of parameters. By separating the low-frequency, mid-frequency, and high-frequency information of the image and extracting the feature heterogeneity, it improved the expressiveness and feature differentiation of the network, made the network pay more attention to the restoration of texture detail features, and reasonably allocated the computational resources. In addition, it integrated the local binary pattern (LBP) algorithm into the network to enhance texture sensitivity, which further improved the network’s ability to extract details. It experimentally verifies that the proposed method balances complexity and performance well. In the 2X zooming experiments on the Set5 dataset, compared to the conventional image super-resolution algorithm (SRCNN) based on convolutional neural network and the newer algorithm (MADNet), the peak signal-to-noise ratio (PSNR) of the proposed method is improved by 1.31 dB and 0.12 dB respectively, and the number of parameters is reduced by 55% compared to MADNet.
Key words:image super-resolution reconstruction; convolutional neural network; lightweight; multi-frequency feature extraction; local binary patterns algorithm
0 引言
圖像超分辨重建是將低分辨率(low resolution,LR)圖像通過特定算法恢復出相應的高分辨率(high resolution,HR)圖像的一種技術[1],旨在彌補或克服圖像采集的環境或系統本身的限制,解決成像質量低、模糊等問題。相比于紋理邊緣不清晰的低分辨率圖像,高分辨率圖像包含更多像素,具有更多細節紋理信息,在視頻安全監控[2,3]、醫學影像分析[4]、衛星遙感圖像[5]等領域具有廣闊的應用前景。在實際采集圖像的過程中,受硬件限制和環境因素的影響,采集到的圖像分辨率往往無法達到人們的預期,而改進成像硬件制造工藝成本高昂、實際環境復雜,因此圖像超分辨率重建技術以成本低、效率高的優點成為主流的研究方向。
傳統圖像超分辨率通常采用基于插值的方法[6]、基于重建的方法[7]、基于示例的方法[8]等。這些方法大多是用淺層特征進行操作,特征表達能力有限,很大程度上限制了重建效果,而深度學習通過自訓練學習提取到表達效果更突出的深層特征,因此被廣泛應用在超分辨領域。2014年Dong等人[9]利用卷積神經網絡完成圖像超分辨率重建(super resolution convolutional neural network,SRCNN);隨后提出的FSRCNN[10]在SRCNN基礎上改進,直接將LR圖像送入網絡提取特征,極大地縮短了重建時間。文獻[11,26~29]通過改變特征提取、上采樣和加深網絡結構等方式提出新的網絡結構,其重建精度得到明顯提升。然而,高精度往往依賴較深的網絡結構,導致了過度參數化,進而需要長時間訓練和推理,加上實際應用中的設備存儲、計算能力有限,極大限制了過度參數化網絡在移動設備上的應用。而輕量化網絡結構核心是盡可能在保證重建精度的前提下,降低參數量和計算復雜度,使深度神經網絡可以部署在存儲空間和計算性能有限的設備上。
CARN[12]將1×1的卷積核與殘差結構級聯,以性能為代價換取較低參數量;IDN[13]通過切片操作,將長路徑和短路徑的局部特征有效結合在一起,使參數量和性能達到一定程度平衡;在此基礎上,IMDN[14]引入信息多蒸餾模塊,以此擴大提取特征的感受野,從而在低參數量的前提下提升網絡重建性能;LESRCNN[15]采用異形卷積結構分層次提取的方式,在保證性能的同時降低參數、提高效率;DRSA[16]通過自動調節殘差塊以適應學習輸入圖像特征,在不增加參數量的情況下提高了網絡性能。盡管以上方法降低了參數量,但輕量化超分辨率依舊存在問題,即忽略了圖像不同頻率信息之間的差異。低頻信息代表圖像主要成分,中頻信息代表圖像的主要邊緣結構[17],高頻信息代表圖像的邊緣和細節,不同頻率的信息需要的計算能力不同,若將特征圖中全部信息不分主次地重建,會導致資源的浪費,同時網絡提取細節特征的能力也將降低。
文獻[18]將特征分為低頻和高頻信息進行處理,使網絡專注于信息量更大的特征,提高其判別能力;文獻[19]利用Sobel算子和分段平滑圖像生成高頻和低頻映射后分別提取感知特征,從而提高網絡性能,但這兩種方法都忽略了中頻信息的作用。此外,圖像中的紋理特征包含細微結構和細節信息,通過利用這些特征可以使重建出的高分辨率圖像更加清晰真實,而深度學習方法并未對該特征的提取有針對性體現。
針對以上問題,本文提出了一種基于輕量級的多頻率特征提取網絡,主要貢獻包括:a)提出了輕量化晶格信息交互結構,利用通道分割技術和多模式卷積組合,減少冗余信息重復處理次數,降低參數量;將不同信息進行自適應交互,促進通道間信息的流動,以獲得更優的重構能力;b)提出了多頻率特征提取模塊。將圖像的低頻、中頻、高頻特征信息有效分離并實現特征異構提取,充分利用不同頻率信息的特點,分配更多計算資源給細節紋理使其便于重建;結合各頻率信息特點設計連接方式,采取逐步細化提取思想,增強了低頻信息的流動和高頻信息的修復;c)充分發揮傳統算法在紋理分析和特征提取方面的優勢,將LBP特征提取算法嵌入到MFEN內部。通過窗口滑動機制,在不同位置上對圖像進行特征提取,以獲取全局紋理信息,從而顯著提高模型對整幅圖像紋理特征的感知能力。
1 網絡結構
1.1 整體框架
本文提出的MFEN,采用輕量化晶格信息交互結構,在保持低參數量的同時進行不同頻率信息的異構提取和交互,并結合LBP特征提取算法,提升網絡對細節特征的提取能力。MFEN結構如圖1所示,主要由初級特征提取模塊、特征層次提取模塊和上采樣模塊三個模塊組成。
初級特征提取模塊使用兩個連續的3×3的卷積對輸入ILR提取初級特征,即
FIFE=HIFE(ILR)=fconv(fconv(ILR))(1)
其中: fconv(·)表示3×3卷積。為了進一步提取特征,將輸出饋送到特征層次提取模塊FFHE,分淺層、深層特征兩部分進行提取,使模型能夠在多層次上學習和表示圖像的特征。淺層特征提取將初級特征提取的輸出FIFE利用LBP算法fLBP提取出全局紋理信息,再加到末端的輸出,以此增加網絡對紋理的提取能力,可表示為
FFHE=FDFE+fLBP(FIFE)(2)
其中:FDFE表示深層特征提取。為了挖掘圖像內部信息的聯系、充分提取細節特征,深層特征提取FDFE部分通過級聯四個多頻率特征提取塊HiMFEB(·),逐步提取深層特征。采用密集連接思想,每一個多頻率特征提取塊的輸入均由前面所有多頻率特征提取塊的輸出連接組成,以充分利用不同層級不同頻率的特征,增強模型的表達能力,可表示為
FDFE=FiMFEB=HiMFEB(FIFE) i=1
HiMFEB(F1MFEB) i=2
HiMFEB(concat(Fi-1MFEB,…,F1MFEB)) i=3,4(3)
其中:concat(·)表示沿通道維度的連接操作。上采樣模塊Fup用一個3×3卷積細化深層特征,再用一個3×3卷積調整特征維度,像素洗牌操作生成放大倍數的三通道特征圖,完成圖像重建,可表示為
Fup=Hup(FFHE)=fup(fconv(fconv(FFHE)))(4)
其中: fup(·)表示像素洗牌。
為了達到優質的重建效果,本文采用常用的L1函數作為損失函數,主要計算輸入圖像和目標圖像各像素間差值的平均絕對值,其公式為
Euclid Math OneLAp(θ)=1N∑Ni=1(‖HMFEN(IiLR)-IiHR‖1)(5)
其中:θ為擬合網絡參數的集合;IHR為目標圖像;N為ILR和IHR圖像對的個數。
此外,本文采用全局和局部殘差連接,解決網絡提取特征過程中的特征消失以及梯度爆炸等問題。如圖1所示,在網絡最外層,將輸入經過雙線性上采樣操作后連接到網絡末端,使特征層次提取部分更注重細節的恢復;在網絡特征層次提取內部,也采用了殘差連接操作,通過LBP特征提取算法處理后連接到末尾,提高網絡對細節紋理信息的提取能力。
1.2 輕量化晶格信息交互結構
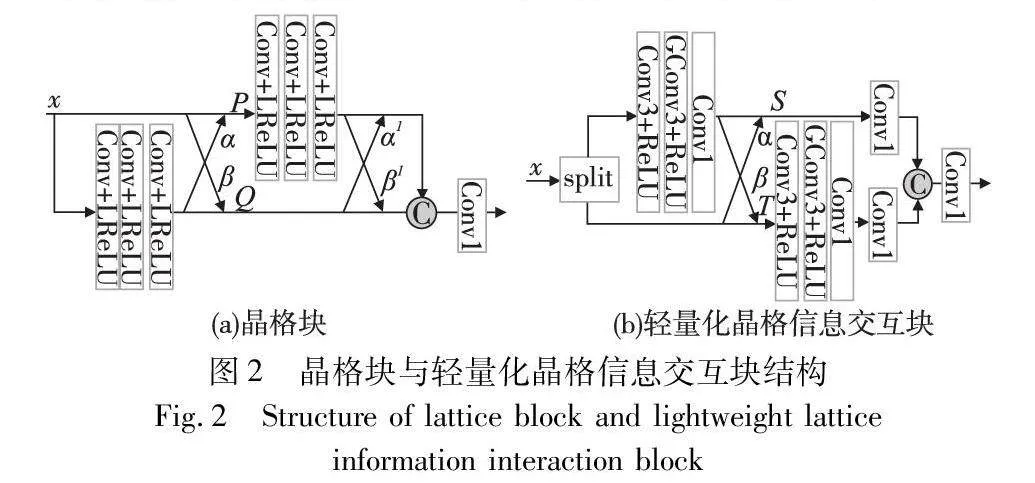
如圖2(a)所示,晶格塊[20]借鑒了晶格濾波器[21] 的思想,并將雙蝶型結構作為其關鍵特征,利用注意力機制計算出各分支的權值參數自適應組合殘差塊,賦予結構對雙殘差塊進行多種線性組合的能力,從而擴展表示空間,實現更強大的網絡。
受晶格塊和SA[22]中通道分割的啟發,本文設計的輕量化晶格信息交互模塊如圖2(b)所示,引入通道分割機制,將所有特征圖分為兩部分并行操作,減少對冗余信息重復處理的次數,使計算量和參數量降低;然后將兩部分特征進行充分提取后,用單蝶形結構即一次上下分支自適應信息交互,達到提高模塊效率的目的;最后使用低廉的逐點卷積對兩部分特征壓縮融合,得到特征信息。具體介紹如下。
首先將輸入通道分為兩部分,使其在低參數量的同時運行速度也得到了提高,即
Si-1(x),Ti-1(x)=split(x)(6)
其中:split(·)表示沿通道維度分割。之后將上分支經過f(·)提取特征,即3×3卷積、ReLU、分組卷積、ReLU、1×1卷積,再對兩分支使用注意力機制得到不同的組合系數后,自適應地進行信息交互,使上下分支信息組合更多樣,即
Si(x)=concat(f(Si-1(x)),αTi-1(x))
Ti(x)=concat(Ti-1(x),βf(Si-1(x)))(7)
其中:α、β為通道注意力機制計算得到的權值。由于特征圖按通道維度分為兩分支,而整個特征由多個特征圖沿通道維度串聯,所以使用通道注意力機制生成權值,詳細計算如下:
設M=[m1,m2,…,mn]代表輸入的n個特征圖,每個特征圖維度為H×W。其中,第o個特征圖Fo通過空間維度收縮統計Zo為
Zo=favgpool(Fo)=1H×W ∑Hi=1 ∑Wj=1Fo(i, j)(8)
特征圖Fo的注意力統計權值為
α=δ(W2σ(W1Zo))(9)
其中:δ代表sigmoid函數;σ代表ReLU函數。同理β也由此計算得出。之后將下分支經過f′(·),即3×3卷積、ReLU、分組卷積、ReLU、1×1卷積操作,采用卷積和分組卷積組合的方式,在確保充分提取特征的前提下降低參數量的使用。最后兩分支以低經濟的1×1卷積進行通道壓縮后融合,得到低頻特征圖FLFE,即
FC=concat(fconv1(Si(x)),fconv1(f′(Ti(x))))
FLFE=fconv1(FC)(10)
其中: fconv1(·)代表1×1卷積。
1.3 多頻率特征提取模塊
對圖像特征的恢復和增強是超分辨率的主要任務,而圖像信息是由低頻、中頻和高頻信息構成。因此本文設計多頻率特征提取塊,將不同頻率分離后嵌入輕量化晶格信息交互結構中進行處理,使注意力更有針對性地集中在特定頻率上提取特征,進而在提高模型提取信息精準度的同時計算資源也得到了充分利用。多頻率特征提取塊FMFEB由三個模塊組成,如圖3所示,分別是:a)低頻率特征提取塊(low-frequency feature extraction block,LFB);b)中頻率特征提取塊(mid-frequency feature extraction block,MFB);c)高頻率特征提取塊(high-frequency feature extraction block,HFB)。通過分層提取,模塊獲得圖像在不同尺度上的表示,同時對不同頻率的信息采用不同的處理策略,在更高頻率的層次上有選擇地應用更精細的處理,從而降低了整體的計算負擔。因此,該模塊首先將信息輸入到LFB模塊中進行處理,隨后將處理后的信息輸入MFB模塊,并與輸入信息進行串聯融合,形成HFB的輸入,使高頻特征提取塊的信息更加豐富,從而提取出更多的細節信息。可用式(11)表示:
FLFE=HLFB(F0), FMFE=HMFB(FLFE)
FHFE=HHFB(concat(FLFE,FMFE)), FMFEB=FHFE(11)
其中:FLFE、FMFE、FHFE分別表示低、中、高頻特征提取塊的輸出。
1.3.1 低頻特征提取塊
低頻信息為圖像中變化緩慢的部分,如平滑的表面或漸變,包括大塊的背景、平坦的區域和一般性的圖像整體結構。低頻信息的提取可以捕捉到圖像的整體結構和主要特征。過往的研究[18] 表明低頻信息并不需要大量的計算及特殊的方式便可有效提取,因此出于對低參數量的追求和奧卡姆剃刀原理的考慮,如圖3(a)所示,在設計LFB時,并未改變輕量化晶格信息交互結構的內部設計模式,使用了組合卷積的方式,達到輕量高效提取低頻特征的目的,將更多的計算資源分配給中高頻特征進行處理,從而降低整體的計算資源。
1.3.2 中頻特征提取塊
圖像中頻信息代表圖像的邊緣信息,而高頻信息是對中頻信息內細節、紋理、邊緣、噪聲處理方面的進一步強化。基于此思想,設計MFB使后續能更好地提取出高頻信息。用雙插值上采樣fbilinear(·)處理可使圖像平滑化,用高斯低通濾波器fgausconv(·)處理可使圖像模糊化。因此,如圖3(b)所示,將經過插值放大后的圖像與插值放大并經高斯低通濾波器處理后的圖像之間做差,再經過卷積和激活函數的操作得出中頻信息fM。表達式如下:
F1=fbilinear(favgpool(x)),
F2=fgausconv(F1),
F3=F1-F2
F4=fsigmoid(fconv(F3)+x),
F5=fconv(x)·F4,
fM=f(F5)(12)
其中: favgpool(·)代表全局平均池化; fsigmoid(·)代表sigmoid函數。提取的中頻信息嵌入輕量化晶格信息交互塊,中頻信息與特征信息自適應組合,增加模型對邊緣特征的提取力。即將式(7)中的f(·)替換成式(12)中f(·),即為中頻特征提取塊。中頻特征有效的提取將圖像分解為不同的結構,有助于模型后續對高頻特征即細節特征的處理和利用。
1.3.3 高頻特征提取塊
提取高頻信息是圖像超分辨重建技術的關鍵,因此設計HFB。如圖3(c)所示,為了得到模糊圖像信息即低頻信息,將LFB和MFB的輸出結合作為輸入圖像信息x,經過池化的縮放操作后,采用最近鄰上采樣將圖像信息尺寸放大到最初尺寸。最后將輸入圖像信息與得到的低頻信息做差,經過卷積和激活函數的處理得到高頻信息fH。表達式如下:
F6=x-fbilinear(favgpool(x)),
F7=fsigmoid(fconv(F6)+x)
F8=fconv(x)·F7, fH=f(F9)(13)
將提取的高頻信息嵌入輕量化晶格信息交互塊,高頻信息與特征信息自適應結合,增加模型對紋理細節特征的提取力。即將式(7)中的f(·)替換成式(13)中的f(·),即為高頻特征提取塊。
1.4 LBP特征提取算法
紋理特征提取是超分辨的關鍵性任務之一,而卷積神經網絡作為近些年主流方法,并未對該特征的提取有針對性體現,因此本文把傳統特征提取算法局部二值模式(LBP)引入神經網絡,使模型更精準地提取關鍵特征信息。LBP是一種描述圖像局部紋理的算法。與傳統卷積類似,LBP是通過滑動窗口來提取圖像的紋理。原始的LBP算子定義3×3窗口,將中心像素作為基點,把鄰域像素值與其比較,若鄰域像素值大于等于基點值,則標記為1,否則標記為0。如前所述從窗口的左端開始順時針比較,得到一個8位的二進制值。再將其轉換為十進制值,正好對應8位圖像的灰度值。利用這個方法遍歷整個圖像,得到提取的紋理圖像。表達式為
LBP(xc,yc)=∑p-1p=02pq(ip-ic)(14)
其中:(xc,yc)為中心像素坐標;p為鄰域的第p個像素;ip為鄰域像素的灰度值;ic為中心像素的灰度值;q(·)為符號函數,表達式如下:
q(x)=1 x≥00 x<0(15)
傳統的LBP算法僅具有灰度不變性。為了適應更多尺寸的紋理特征,同時也滿足旋轉不變性,本文將更精細化的圓形LBP算法引入模型的殘差連接分支上。如圖1所示,將特征層次提取模塊的輸入采用LBP算法提取出局部紋理信息,再連接至末端融合輸出。值得一提的是,LBP算法機理是通過圖像本身的像素值進行局域性的運算,無須額外參數量,因此以更經濟的方式傳遞了紋理信息,進一步增強了網絡對細節的修復能力。
2 實驗結果與分析
2.1 訓練細節
本文提出的網絡模型輸入和輸出數據形式為RGB圖像,使用雙三次插值對訓練HR圖像進行下采樣合成LR圖像。訓練時從LR圖像隨機裁剪出16個特定大小的色塊作為一個batchsize輸入,每個LR色塊的大小為64×64。模型由Adam優化器訓練,其中β1=0.9,β2=0.999,epsilon=10-8,學習率初始化為1E-4,每200個epoch將衰減一半,整體通過L1損失函數經過1 000次訓練。模型使用PyTorch框架實現,在單個NVIDIA 2080Ti GPU上完整運行僅僅需要兩天時間。
2.2 數據集
在數據集的設置上,使用DIV2K數據集訓練模型,該數據集覆蓋了多種場景,包括人物、動植物、自然風景、建筑物等,有利于訓練模型在不同類型圖像上的泛化能力,其中包括用于訓練集的800張多類型高質量圖像,以及用于驗證和測試的200張圖像。
使用四個基準數據集作為測試數據集,分別是Set5、Set14、B100、Urban100。每個數據集都包含不同的圖像類型和特征。Set5和Set14數據集分別包含5張和14張高分辨率圖像,相對較小的規模使得算法在短時間內可以快速進行評估;B100數據集包含100張高分辨率圖像,大樣本規模有助于更全面地了解算法的泛化能力和穩健性;Urban100數據集包含100張城市景觀的高分辨率圖像,可以用于測試算法在包含復雜場景和細節的圖像上的性能。
2.3 消融實驗
2.3.1 多頻率提取研究
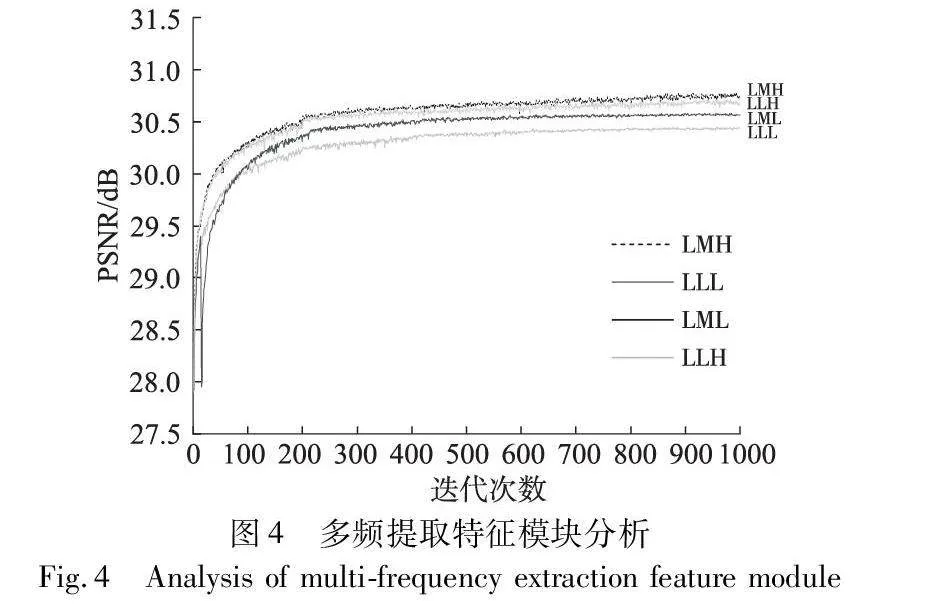
為了驗證本文提出的多頻率特征提取的有效性,將多頻提取特征模塊內部替換成三種不同結構進行消融實驗,相應結果如表1和圖4所示。表1中,LLL表示三個常規的特征提取塊,LML表示兩個常規特征提取塊中加一個中頻特征提取塊,LLH表示兩個常規特征提取塊和一個高頻特征提取塊,LMH表示本文提出的結構,即一個低頻特征提取塊、一個中頻特征提取塊以及一個高頻特征提取塊。從表中數據可知,本文設計的結構效果均優于不做任何頻率分離的特征提取和只做中頻或高頻分離的特征提取的效果;圖4是四種結構訓練1 000次的精度折線圖,從圖中可以明顯看出,使用LMH模塊的MFEN模型在250個周期后趨于穩定,此外,相較于三個未使用LMH模塊的MFEN模型,其在PSNR數值上提升了0.42 dB,該結果證明了LMH模塊的有效性。
2.3.2 輕量化晶格信息交互結構研究
對于這部分研究,分兩個方向進行實驗說明:
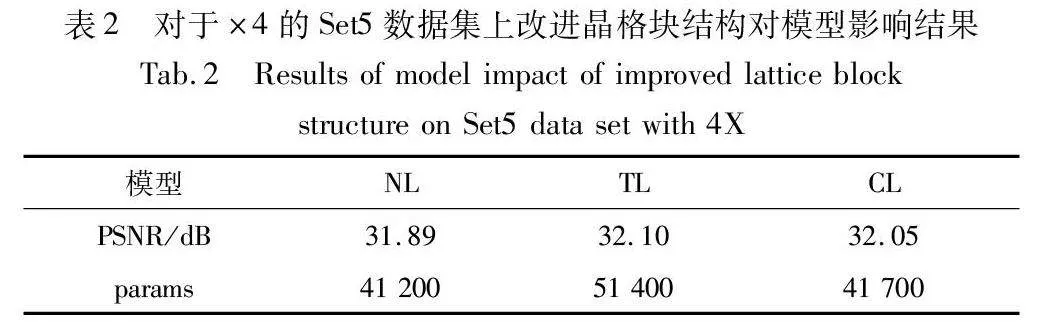
首先將傳統的晶格塊結構(TL)替換模型的輕量化晶格信息交互結構(CL)進行訓練,結果如表2所示,傳統晶格塊模型效果比本文模型的效果高0.05 dB,然而參數量多了近十萬。由于本文研究輕量級模型,綜合精度與參數量來考慮,本文模型更具優勢。
其次將傳統卷積塊組合(NL),即conv3+ReLU+conv3+ conv1替換模型中改進的晶格塊,為公平比較,替換的模塊與本文結構具有近似的復雜性。結果如表2所示,在參數量相近的前提下,本文模型提高了0.16 dB。
2.3.3 LBP研究
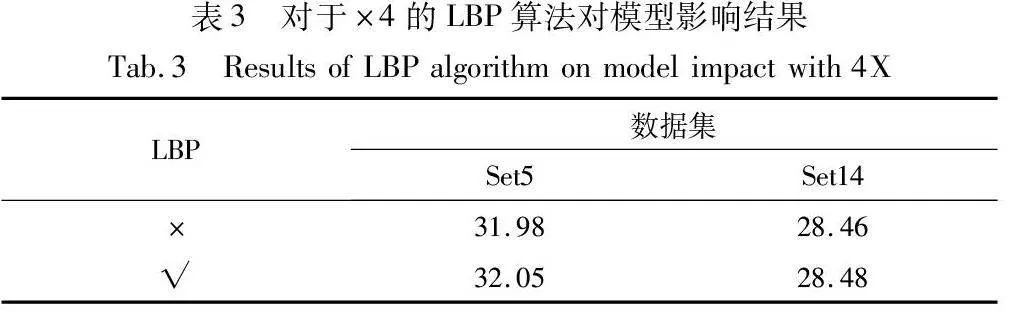
LBP算法作用是反映圖像的局部細節紋理,圖5是使用LBP算法后可視化圖像,反映出來圖像中的輪廓以及細節紋理,因此從理論上該算法是有效的;為進一步驗證LBP算法在模型中對紋理特征感知的有效性,設計在放大因子為4的前提下將LBP算法從模型中刪除后進行訓練。實驗結果如表3所示。在兩個數據集上,有LBP算法的模型效果(PSNR)均更佳。
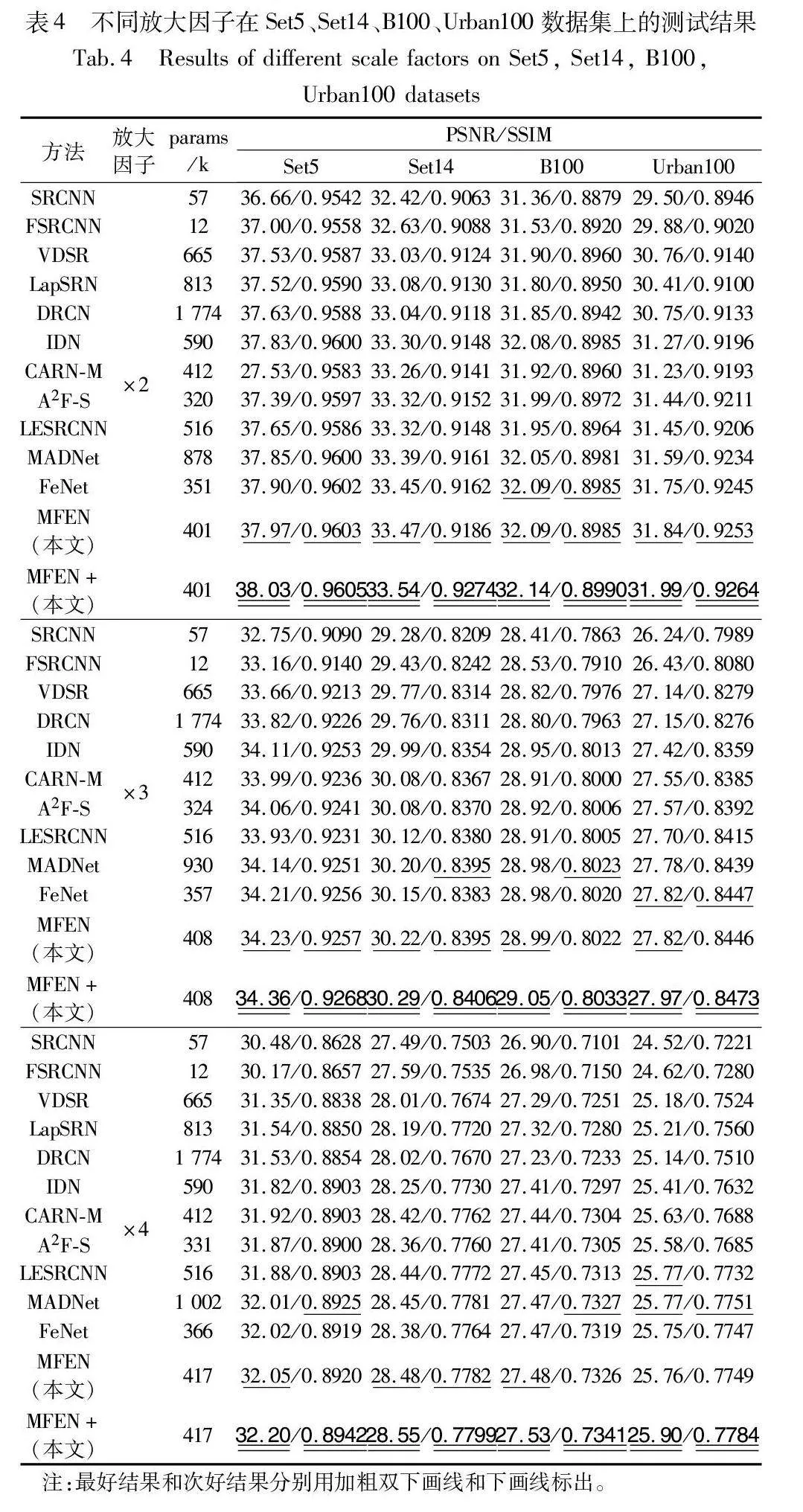
2.4 結果對比分析
為了驗證MFEN的有效性,與其他經典先進的方法進行比較,其中SRCNN[9] 、FSRCNN[10]、DRCN[11] 、VDSR[23]和LapSRN[24]為圖像超分辨的經典深度學習模型,代表了圖像超分辨領域的關鍵發展,IDN[13] 、CARN-M[12]、LESRCNN[15]、MADNet[25]、A2F-S[26]和FeNet[5]為輕量化圖像超分辨領域經典先進模型的代表。同時采用自集成方式進一步評估本文模型,用“+”標記。為了結果的可比較性,所有的測試都在四個公共數據集上進行:Set5、Set14、B100和Urban100。
此處的經典先進模型使用的是通用數據。在參數和精度的綜合評估下,MFEN模型在不同公開數據集中取得了更好的效果。此外,MFEN+模型的PSNR值和SSIM值的各個比例因子都全面超越其他SISR模型。
以數據集Set5為例,MADNet模型的參數量比MFEN模型要高出一倍有余,其PSNR值和SSIM值都略低于MFEN,其中在放大因子為2的情況中,MFEN的PSNR值比MADNet高出0.12 dB;與參數量相當的CARN-M模型相比,MFEN在放大因子為4時表現力略微遜色的情況下,也高出了0.13 dB;對于不同放大因子,MFEN的PSNR值和SSIM值已全面超越參數量較小的FeNet模型。
圖6隨機選取了定量比較中的四個模型進行定性比較,從更直觀的角度證明了MFEN模型的優勢,分別在放大因子為2的Set14數據集、放大因子為4的Urban100和B100數據集上進行視覺比較。可以看出,本文模型重建出的SR相比于其他模型而言,本文模型從視覺效果和紋理細節角度都更接近HR圖。例如本文模型重建出的Set14圖像中胡須和褶皺都更加明顯清晰;在Urban100的建筑物輪廓信息中,VDSR、DRCN、IDN等模型恢復的輪廓發生了不同程度的模糊與扭曲,而本文模型較清晰完整地恢復出了輪廓信息。
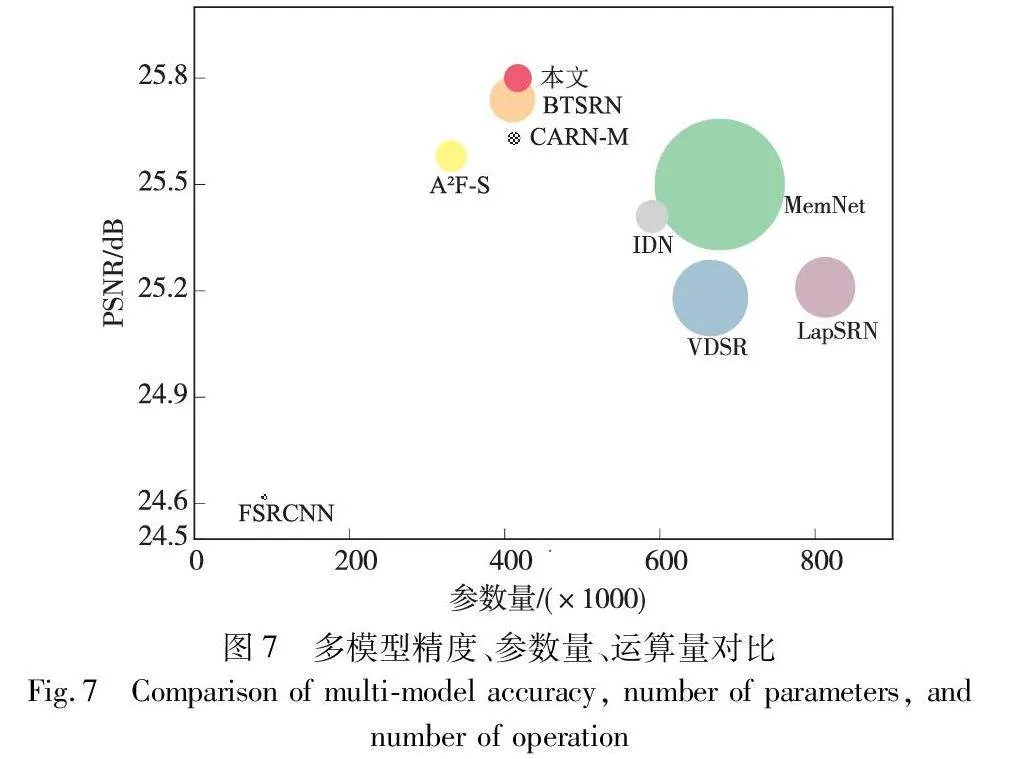
為了從精度、參數量和計算量三個方面對模型進行比較,將本文模型與多個經典模型和輕量模型進行對比,即FSRCNN、VDSR、IDN、MemNet、LapSRN、CARN-M、A2F-S、BTSRN,并以圖7的形式展現,橫坐標代表參數,縱坐標代表精度,而圓圈的面積與計算量成正比。如圖7所示,在參數量、運算量都要高的情況下,MemNet、VDSR、LapSRN模型比本文模型精度反而更低;在運算量相當的情況下,A2F-S、IDN精度比本文更低;在參數量相當的情況下,BTSRN比本文模型精度略低、運算量略大。綜上本文模型從以上三個方面綜合結果最佳。
3 結束語
針對圖像超分辨率重建網絡中常見的參數量過大、頻率信息利用不充分、計算資源分配不合理等問題,本文提出了一種基于多頻率特征提取的輕量級網絡。其中設計的輕量化信息交互結構利用通道分割、簡化思想以及內部卷積組合的設計,使網絡在保持性能的同時達到輕量化的效果,并采用通道注意力機制生成通道權值進行高效信息交互;設計的多頻率特征提取模塊,將不同頻率信息分離并提取特征,使網絡整體性能和效率提升;同時在殘差路徑上嵌入LBP特征提取算法,提取出局部細節紋理信息,增強網絡對細節紋理的提取能力。實驗表明,MFEN在精度和參數量的綜合評估下具有良好的重建性和優勢。后續將重點研究如何進一步提升圖像超分辨率重建網絡的泛化能力,解決由于數據集的類型差異較大而導致的性能衰減問題。
參考文獻:
[1]王拓然,程娜,丁士佳,等. 基于自適應注意力融合特征提取網絡的圖像超分辨率 [J]. 計算機應用研究,2023,40(11): 3472-3477. (Wang Tuoran,Cheng Na,Ding Shijia,et al. Image super-resolution based on adaptive attention fusion feature extraction network [J]. Application Research of Computers,2023,40(11): 3472-3477.)
[2]孫磊,張洪蒙,毛秀青,等. 基于超分辨率重建的強壓縮深度偽造視頻檢測 [J]. 電子與信息學報,2021,43(10): 2967-2975. (Sun Lei,Zhang Hongmeng,Mao Xiuqing,et al. Super-resolution reconstruction detection method for deep fake hard compressed videos [J]. Journal of Electronics & Information Technology,2021,43(10): 2967-2975.)
[3]Gao Guangwei,Tang Lei,Wu Fei,et al. JDSR-GAN: constructing an efficient joint learning network for masked face super-resolution [J]. IEEE Trans on Multimedia,2023,25: 1505-1512.
[4]Chen Chao,Raymond C,Speier W,et al. Synthesizing MR image contrast enhancement using 3D high-resolution ConvNets [J]. IEEE Trans on Biomedical Engineering,2023,70(2): 401-412.
[5]Wang Zheyuan,Li Liangliang,Xue Yuan,et al. FeNet: feature enhancement network for lightweight remote-sensing image super-resolution [J]. IEEE Trans on Geoscience and Remote Sensing,2022,60: 1-12.
[6]Han J W,Suryanto,Kim J H,et al. New edge-adaptive image interpolation using anisotropic Gaussian filters [J]. Digital Signal Processing,2013,23(1): 110-117.
[7]Su Jian,Xu Zongben,Shum H Y. Image super-resolution using gradient profile prior [C]// Proc of IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway,NJ: IEEE Press,2008: 24-26.
[8]Li Bo,Liu Risheng,Cao Junjie,et al. Online low-rank representation learning for joint multi-subspace recovery and clustering [J]. IEEE Trans on Image Processing,2018,27(1): 335-348.
[9]Dong Cao,Chen C L,He Kaiming,et al. Image super-resolution using deep convolutional networks [J]. IEEE Trans on Pattern Analysis and Machine Intelligence,2016,38(2): 295-307.
Iowzw/mP+oY10KUWrKcYGw==[10]Dong Cao,Loy C C,Tang Xiaoou. Accelerating the super-resolution convolutional neural network [C]// Proc of European Conference on Computer Vision. Cham: Springer,2016: 391-407.
[11]Kim J,Lee J K,Lee K M. Deeply-recursive convolutional network for image super-resolution [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2016: 1637-1645.
[12]Ahn N,Kang B,Sohn K A. Fast,accurate,and lightweight super-resolution with cascading residual network[C]// Proc of the 15th European Conference on Computer Vision.Berlin: Springer,2018: 252-268.
[13]Hui Zheng,Wang Xiumei,Gao Xinbo. Fast and accurate single image super-resolution via information distillation network [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ: IEEE Press,2018: 723-731.
[14]Hui Zheng,Gao Xinbo,Yang Yunchu,et al. Lightweight image super-resolution with information multi-distillation network [C]// Proc of ACM International Conference on Multimedia.New York: ACM Press,2019: 2024-2032.
[15]Tian Chunwei,Zhuge Ruibin,Wu Zhihao,et al. Lightweight image super-resolution with enhanced CNN [J]. Knowledge-Based Systems,2020,205: 106235.
[16]Park K,Soh J W,Cho N I. A dynamic residual self-attention network for lightweight single image super-resolution [J]. IEEE Trans on Multimedia,2021,25: 907-918.
[17]葉盛楠,蘇開娜,肖創柏,等. 基于結構信息提取的圖像質量評價 [J]. 電子學報,2008,36(5): 856-861. (Ye Shengnan,Su Kaina,Xiao Chuangbo,et al. Image quality assessment based on structural information extraction [J]. Acta Electronica Sinica,2008,36(5): 856-861.)
[18]Parichehr B,Pau R,Carles F T,et al. Frequency-based enhancement network for efficient super-resolution [J]. IEEE Access,2022,10(1): 57383-57397.
[19]Zhang Zicheng,Sun Wei,Min Xiongkuo,et al. A no-reference deep learning quality assessment method for super-resolution images based on frequency maps [C]// Proc of IEEE International Symposium on Circuits and Systems. Piscataway,NJ:IEEE Press,2022: 3170-3174.
[20]Luo Xiaotong,Qu Yanyun,Xie Yuan,et al. Lattice network for lightweight image restoration [J]. IEEE Trans on Pattern Analysis and Machine Intelligence,2023,45(4): 4826-4842.
[21]Li Bodong,Gao Xieping. Lattice structure for regular linear phase paraunitary filter bank with odd decimation factor [J]. IEEE Signal Processing Letters,2013,21(1): 14-17.
[22]Zhang Qinglong,Yang Yubin. SA-Net: shuffle attention for deep convolutional neural networks [C]// Proc of IEEE International Confe-rence on Acoustics. Piscataway,NJ:IEEE Press,2021: 2235-223.
[23]Kim J,Lee J K,Lee K M. Accurate image super-resolution using very deep convolutional networks [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2016: 1646-1654.
[24]Lai Weisheng,Huang Jiabin,Ahuja N,et al. Deep Laplacian pyramid networks for fast and accurate super-resolution [C]// Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press,2017: 624-632.
[25]Lan Rushi,Sun Long,Liu Zhenbing,et al. MADNet: a fast and lightweight network for single-image super resolution [J]. IEEE Trans on Cybernetics,2021,51(3): 1443-1453.
[26]Wang Xuehui,Wang Qing,Zhao Yuzhi,et al. Lightweight single-image super-resolution network with attentive auxiliary feature learning [C]// Proc of the 15th Asian Conference on Computer Vision Workshops. Cham: Springer,2021: 1-17.
[27]盤展鴻,朱鑒,遲小羽,等. 基于特征融合和注意力機制的圖像超分辨率模型 [J]. 計算機應用研究,2022,39(3): 884-888. (Pan Zhanhong,Zhu Jian,Chi Xiaoyu,et al. Image super-resolution model based on feature fusion and attention mechanism [J]. Application Research of Computers,2022,39(3): 884-888.)
[28]Mehri A,Behjati P,Sappa A D. TnTViT-G: transformer in transfor-mer network for guidance super resolution [J]. IEEE Access,2023,11: 11529-11540.
[29]楊樹媛,曹寧,郭斌,等. 基于雙模式聯合三邊濾波器的深度圖像超分辨率方法 [J]. 計算機應用研究,2021,38(11): 3472-3477. (Yang Shuyuan,Cao Ning,Guo Bin,et al. Depth map super resolution based on dual mode joint trilateral filter [J]. Application Research of Computers,2021,38(11): 3472-3477.)
