基于旋轉(zhuǎn)粒化的邏輯回歸算法
2024-08-15 00:00:00孔麗茹陳玉明傅興宇江海亮許進(jìn)程
計(jì)算機(jī)應(yīng)用研究 2024年8期
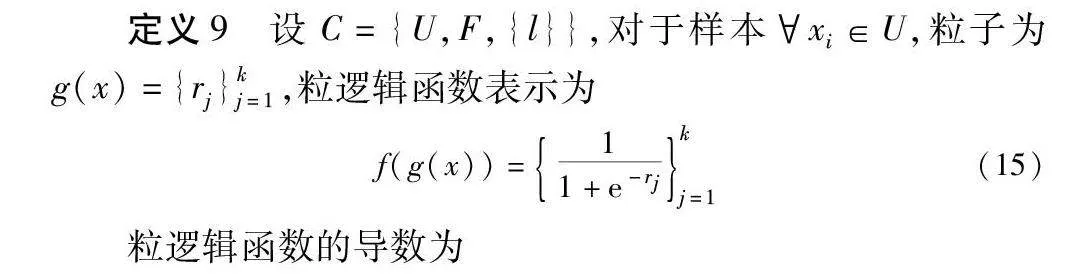





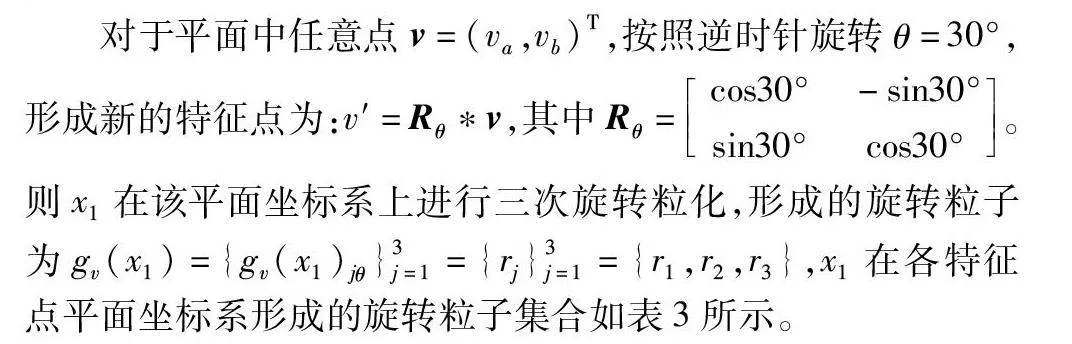



摘 要:邏輯回歸(LR)作為監(jiān)督學(xué)習(xí)的二元分類廣義線性分類器,在處理線性數(shù)據(jù)方面表現(xiàn)出結(jié)構(gòu)簡(jiǎn)單、解釋性強(qiáng),擬合效果好的特點(diǎn)。然而,當(dāng)面對(duì)高維、不確定性和線性不可分?jǐn)?shù)據(jù)時(shí),邏輯回歸的分類效果受到限制。針對(duì)邏輯回歸的固有缺陷,引入粒計(jì)算理論,借助粒化的優(yōu)勢(shì)提出一種新型的邏輯回歸模型:旋轉(zhuǎn)粒邏輯回歸。通過(guò)引入旋轉(zhuǎn)粒化理論,在特征兩兩組合形成的平面坐標(biāo)系上旋轉(zhuǎn)不同角度,構(gòu)建旋轉(zhuǎn)粒子,多平面坐標(biāo)系上粒化構(gòu)造旋轉(zhuǎn)粒向量。進(jìn)一步定義粒的大小、度量和運(yùn)算規(guī)則,提出旋轉(zhuǎn)粒邏輯回歸的損失函數(shù)。通過(guò)求解損失函數(shù),得到旋轉(zhuǎn)粒邏輯回歸的優(yōu)化解。最后,采用多個(gè)UCI數(shù)據(jù)集進(jìn)行實(shí)驗(yàn),從多個(gè)評(píng)價(jià)指標(biāo)比較的結(jié)果表明旋轉(zhuǎn)粒邏輯回歸模型的有效性。
關(guān)鍵詞:邏輯回歸; 粒計(jì)算; 向量旋轉(zhuǎn); 粒邏輯回歸; 損失函數(shù)
中圖分類號(hào):TP181 文獻(xiàn)標(biāo)志碼:A
文章編號(hào):1001-3695(2024)08-021-2398-06
doi:10.19734/j.issn.1001-3695.2023.11.0578
Logistic regression algorithm based on rotating granulation
Kong Liru1, Chen Yuming1, Fu Xingyu1, Jiang Hailiang1, Xu Jincheng2
(1.College of Computer & Information Engineering, Xiamen University of Technology, Xiamen Fujian 361024, China; 2.Xiamen Wanyin Intelligent Technology Co., Ltd., Xiamen Fujian 361024, China)
Abstract:LR serves as a generalized linear classifier for binary classification in supervised learning, exhibiting characteristics of simplicity in structure, strong interpretability, and effective fitting when dealing with linear data. However, its classification performance becomes limited when confronted with high-dimensional, uncertain, and linearly inseparable data. To address the inherent limitations of logistic regression, this paper introduced the theory of granular computing and proposed a novel logistic regression model called rotating granular logistic regression(RGLR). This paper introduced the theory of rotating granulation, where different angles of rotation were applied to pairs of features forming a plane coordinate system. This process constructed rotating granules by rotating pairs of features at various angles on the plane coordinate system, and granulated to form rotating granule vectors on multiple plane coordinate systems. This paper further defined the size, measurement, and operational rules of granules, and proposed a loss function for rotating granular logistic regression. The optimized solution of the rotating granular logistic regression was obtained by solving the value of the loss function. Finally, experiments are conducted using multiple UCI datasets, and the results compared across various evaluation metrics, indicate the effectiveness of the rotating granular logistic regression model.
Key words:logistic regression; granular computing; rotating vector; rotating granular logistic regression; loss functions
0 引言
模糊集和模糊計(jì)算概念由美國(guó)學(xué)者Zadeh[1]在1965年提出,模糊集通過(guò)隸屬函數(shù)表示元素和集合之間的關(guān)系。1996年Lin等人[2]首次提出粒計(jì)算理論。粒計(jì)算強(qiáng)調(diào)事物多層次、多粒度表示,使用新的表示方法對(duì)復(fù)雜知識(shí)做新表示,處理不確定性數(shù)據(jù)。加拿大院士Pedrycz提出多種粒分類[3]和粒聚類算法[4]。1997年,Zadeh[5]指出,模糊邏輯和人類推理能力是相似的,模糊信息粒化基于人類推理方法去粒化信息。除了模糊信息粒化,還有很多粒化方法,如粗糙集粒化和陰影集粒化。文獻(xiàn)[6]總結(jié)并討論不同條件下的粒化方法。進(jìn)入21世紀(jì)后,國(guó)內(nèi)越來(lái)越多的學(xué)者投身到粒計(jì)算的研究中。Lin等人[7,8]成功將粒計(jì)算應(yīng)用到知識(shí)發(fā)現(xiàn)和數(shù)據(jù)挖掘領(lǐng)域。文獻(xiàn)[9,10]通過(guò)定義鄰域關(guān)系構(gòu)建鄰域粒化。文獻(xiàn)[11~13]基于粒計(jì)算理論闡述不確定性,并將信息熵引入粒計(jì)算領(lǐng)域。Yu等人[14]提出多粒度融合學(xué)習(xí)來(lái)學(xué)習(xí)不同粒度模式下的決策。2014年,Qian等人[15]設(shè)計(jì)出一種并行屬性近似算法,以提高屬性近似問(wèn)題的粒計(jì)算操作效率。文獻(xiàn)[16]提出基于概念格的粒度結(jié)構(gòu),并應(yīng)用于概念分析中。Chen等人[17]從集合和向量的角度定義了粒的結(jié)構(gòu),并進(jìn)一步研究粒的不確定性和距離度量。Li等人[18]將提升算法與粒KNN算法集成,進(jìn)一步提高KNN算法的性能。粒計(jì)算是一種從人類認(rèn)知的角度定義的算術(shù)模型,與人類的邏輯、認(rèn)知和記憶高度相似,粒計(jì)算能夠分析與處理復(fù)雜數(shù)據(jù),將復(fù)雜的對(duì)象細(xì)粒度分解而求解問(wèn)題,并廣泛應(yīng)用于機(jī)器學(xué)習(xí)領(lǐng)域[19~23]。
邏輯回歸是一種數(shù)學(xué)模型,可以估計(jì)屬于某一類的概率。在數(shù)據(jù)科學(xué)中,邏輯回歸是一種分類方法[24]。許多研究者在工程領(lǐng)域使用了回歸模型,并開(kāi)展了出色的研究工作,如健康科學(xué)[25]、文本挖掘[26]和圖像分析[27]。然而,傳統(tǒng)的邏輯回歸方法只能從當(dāng)前的樣本特征中學(xué)習(xí)。但數(shù)據(jù)集中多個(gè)獨(dú)立樣本的特征之間仍存在一些聯(lián)系,這被傳統(tǒng)的邏輯回歸方法所忽視。當(dāng)數(shù)據(jù)維度過(guò)高時(shí),邏輯回歸分類器可能會(huì)出現(xiàn)退化現(xiàn)象。粒化處理可以通過(guò)引入粒計(jì)算使分類過(guò)程具有結(jié)構(gòu)化和層次化,從而提高了數(shù)據(jù)分類[28]的準(zhǔn)確性和魯棒性。
本文利用粒計(jì)算處理模糊、不確定性數(shù)據(jù)的優(yōu)勢(shì)以及邏輯回歸在處理二元分類問(wèn)題時(shí)具有良好性能的特點(diǎn)將粒計(jì)算和邏輯回歸相結(jié)合,兩者結(jié)合有助于更全面地處理復(fù)雜數(shù)據(jù),提出一種旋轉(zhuǎn)粒邏輯回歸方法。該方法基于粒計(jì)算理論,通過(guò)建立特征點(diǎn)平面坐標(biāo)系,在特征點(diǎn)平面坐標(biāo)系上旋轉(zhuǎn)多個(gè)角度對(duì)樣本進(jìn)行旋轉(zhuǎn)粒化,形成旋轉(zhuǎn)粒子,多平面坐標(biāo)系上的粒化構(gòu)造成旋轉(zhuǎn)粒向量。進(jìn)一步定義粒的大小、度量和運(yùn)算規(guī)則,提出粒邏輯回歸的損失函數(shù)。將邏輯回歸的思想和粒計(jì)算理論相結(jié)合提出粒邏輯回歸算法。使用UCI數(shù)據(jù)集進(jìn)行實(shí)驗(yàn)測(cè)試表明,本文算法得到的分類效果優(yōu)于傳統(tǒng)邏輯回歸算法,為分類算法探索一條新的途徑。
1 粒向量與粒化
首先將特征歸一化并且將樣本粒化成多個(gè)粒子。通過(guò)定義粒和粒度計(jì)算,將粒化后的粒子輸入到旋轉(zhuǎn)粒邏輯回歸模型中,輸出樣本預(yù)測(cè)標(biāo)簽,具體步驟介紹如下。
1.1 粒化
粒計(jì)算是處理不確定性信息的有效工具。設(shè)C={U,F(xiàn),{l}}為一分類系統(tǒng),其中U={x1,x2,…,xn}為樣本集合,F(xiàn)={f1,f2,…,fh}為樣本特征集合,{l}為樣本的類別標(biāo)簽;給定單樣本x∈U,對(duì)于單特征f∈F,v(x,f)∈[0,1]表示樣本x在特征f上歸一化后的值;該樣本x對(duì)應(yīng)的標(biāo)簽值為y∈{0,1}。
定義1 設(shè)h維特征集為F={f1,f2,…,fh},任意選取兩個(gè)特征fa,fb∈C進(jìn)行組合,形成特征點(diǎn)平面坐標(biāo)系〈fa,fb〉或〈fb,fa〉,其中第一個(gè)元素為橫坐標(biāo),第二個(gè)元素為縱坐標(biāo)。以下本文只考慮這種情況〈fa,fb〉,其中fa為橫坐標(biāo),fb為縱坐標(biāo)。
對(duì)于給定樣本x∈U,其在特征點(diǎn)平面坐標(biāo)系〈fa,fb〉中的值為〈v(x,fa),v(x,fb)〉,簡(jiǎn)寫(xiě)為〈va,vb〉。h維特征集F={f1,f2,…,fh}中,所有特征兩兩組合,則形成了特征點(diǎn)平面坐標(biāo)系集合,含有h×(h-1)/2個(gè)平面坐標(biāo)系。對(duì)于給定樣本x∈U,所有特征值兩兩組合,則形成了h×(h-1)/2個(gè)平面特征點(diǎn)值。
定義2 設(shè)特征點(diǎn)平面坐標(biāo)系為〈fa,fb〉,對(duì)于平面中任意點(diǎn)v=(va,vb)T,按照逆時(shí)針旋轉(zhuǎn)θ角度,形成新的特征點(diǎn)為v′=Rθ*v,其中Rθ=cos θ-sin θsin θcos θ。
定義3 給定數(shù)據(jù)集C={U,F(xiàn),{l}},對(duì)于任一樣本x∈U,其在特征點(diǎn)平面坐標(biāo)系〈fa,fb〉的值為v=(va,vb)T,則x在該平面坐標(biāo)系上進(jìn)行旋轉(zhuǎn)粒化,形成的旋轉(zhuǎn)粒子定義為
gv(x)={gv(x)jθ}kj=1={rj}kj=1={r1,r2,…,rk}(1)
其中:gv(x)是一個(gè)集合;rj是集合中的一個(gè)元素,rj=Rjθ*v表示樣本x在特征點(diǎn)平面坐標(biāo)系〈fa,fb〉上旋轉(zhuǎn)jθ角度后的點(diǎn)。定義gv(x)為旋轉(zhuǎn)粒子,gv(x)j為粒子gv(x)的第j個(gè)粒核。粒子由粒核組成,是一個(gè)有序集合,其元素是平面上的點(diǎn);因此,旋轉(zhuǎn)粒子也是點(diǎn)的有序集合。
樣本x在決策特征l上進(jìn)行擴(kuò)展粒化,形成標(biāo)簽粒子,定義為
gl(x)={gl(x)j}kj={l}kj=1(2)
其中:l為樣本x的標(biāo)簽值。在邏輯回歸分類器中,標(biāo)簽值為0和1。
定義4 設(shè)C={U,F(xiàn),{l}}為數(shù)據(jù)集,對(duì)于任一樣本x∈U,從特征集F中任選特征組合成m個(gè)平面坐標(biāo)系,構(gòu)成集合為P={v1,v2,…,vm},其中va=〈fax,fay〉,則x在特征點(diǎn)平面坐標(biāo)系集P上的旋轉(zhuǎn)粒向量定義為
GP(x)=(gv1(x),gv2(x),…,gvm(x))T(3)
其中:gvm(x)是樣本x在特征點(diǎn)平面坐標(biāo)系vm上的旋轉(zhuǎn)粒子。因va=〈fax,fay〉,所以旋轉(zhuǎn)粒向量可表示為
GP(x)=(gf1x(x),gf1y(x),gf2x(x),gf2y(x),…,gfmx(x),gfmy(x))T(4)
為方便計(jì)算,則旋轉(zhuǎn)粒向量表示為
G(x)=(g1(x),g2(x),…,g2m(x))T(5)
粒向量G(x)由粒子組成,而粒子是一個(gè)有序集合的形式。因此,粒向量的元素是有序的集合,與傳統(tǒng)向量不一樣,傳統(tǒng)向量的元素是一個(gè)實(shí)數(shù)。
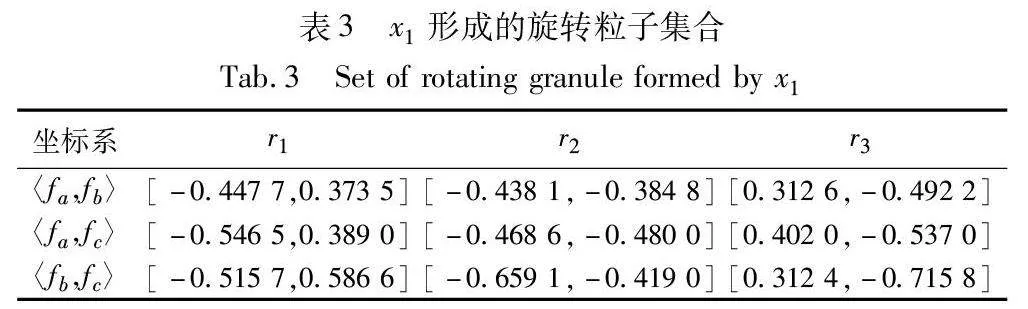
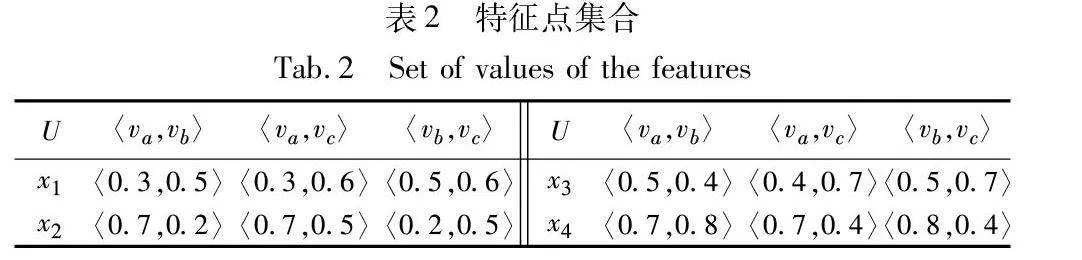
例1 數(shù)據(jù)集C={U,F(xiàn),{l}}如表1所示,U={x1,x2,x3,x4}為樣本集合,F(xiàn)={fa,fb,fc}為特征集合,l為類別標(biāo)簽,設(shè)旋轉(zhuǎn)角度θ為30°,旋轉(zhuǎn)次數(shù)為三次。數(shù)據(jù)集如表1所示。
特征集F={fa,fb,fc},若選取兩個(gè)特征fa,fb∈F進(jìn)行組合,形成特征點(diǎn)平面坐標(biāo)系〈fa,fb〉或〈fb,fa〉,其中第一個(gè)元素為橫坐標(biāo),第二個(gè)元素為縱坐標(biāo)。以下本文只考慮〈fa,fb〉這種情況,其中fa為橫坐標(biāo),fb為縱坐標(biāo)。
對(duì)于給定樣本x1∈U,其在特征點(diǎn)平面坐標(biāo)系〈fa,fb〉中的值為〈v(x1,fa),v(x1,fb)〉,簡(jiǎn)寫(xiě)為〈va,vb〉。三維特征集F={fa,fb,fc}中,所有特征兩兩組合,則形成特征點(diǎn)平面坐標(biāo)系集合,含有三個(gè)平面坐標(biāo)系。同時(shí)形成三個(gè)平面特征點(diǎn)值。樣本特征點(diǎn)集合如表2所示。
對(duì)于平面中任意點(diǎn)v=(va,vb)T,按照逆時(shí)針旋轉(zhuǎn)θ=30°,形成新的特征點(diǎn)為:v′=Rθ*v,其中Rθ=cos30°-sin30°sin30°cos30°。則x1在該平面坐標(biāo)系上進(jìn)行三次旋轉(zhuǎn)粒化,形成的旋轉(zhuǎn)粒子為gv(x1)={gv(x1)jθ}3j=1={rj}3j=1={r1,r2,r3},x1在各特征點(diǎn)平面坐標(biāo)系形成的旋轉(zhuǎn)粒子集合如表3所示。
表3中每一行粒核r1、r2、r3組合形成x1在該平面上的旋轉(zhuǎn)粒子gv(x1)。則x1在特征點(diǎn)平面坐標(biāo)系集P上的所有粒子組合形成的旋轉(zhuǎn)粒向量為
GP(x)=(gv1(x),gv2(x),gv3(x))T
1.2 粒子的運(yùn)算
定義5 設(shè)g={sj}kj=1,f={tj}kj=1為兩個(gè)粒子,則兩個(gè)粒子的加、減、乘、除運(yùn)算定義為
g+f={sj+tj}kj=1(6)
g-f={sj-tj}kj=1(7)
g×f={sj×tj}kj=1(8)
g/f={sj/tj}kj=1(9)
定義6 設(shè)粒向量為G(xi)=(g1(xi),g2(xi),…,gm(xi))T,G(xk)=(g1(xk),g2(xk),…,gm(xk))T,則這兩個(gè)粒向量的點(diǎn)乘為
G(xi)·G(xk)=G(xi)TG(xk)=g1(xi)*g1(xk)+
g2(xi)*g2(xk)+…+gm(xi)*gm(xk)(10)
兩個(gè)粒向量的點(diǎn)乘結(jié)果為一個(gè)粒子。因此,本文可以通過(guò)構(gòu)造一個(gè)權(quán)值粒向量,讓樣本的粒向量與權(quán)值粒向量進(jìn)行點(diǎn)乘運(yùn)算,其結(jié)果也為一個(gè)粒子。
定義7 設(shè)粒子為gc(x)={rj}kj=1,其大小定義為
q(gc(x))=∑kj=1rj(11)
若q(gc(x))>0,則粒子大小為正;反之,粒子大小為負(fù)。
粒邏輯回歸分類模型的學(xué)習(xí)訓(xùn)練過(guò)程就是優(yōu)化確定權(quán)值粒向量與偏置粒子的值,預(yù)測(cè)樣本類別則通過(guò)學(xué)習(xí)得到的粒邏輯回歸模型來(lái)分類。對(duì)于輸入的樣本進(jìn)行粒化和粒邏輯回歸模型計(jì)算后,輸出粒子,通過(guò)度量粒子的大小確定樣本的類別。輸出結(jié)果為正,則判定為正例類別;輸出結(jié)果為負(fù),則判定為負(fù)例類別。
定義8 設(shè)m維粒向量為G(xi)=(g1(xi),g2(xi),…,gm(xi))T,則粒向量的范粒子定義為
a)粒向量-1范粒子。
‖G(xi)‖1=∑mj=1gj(xi)(12)
b)粒向量-2范粒子。
‖G(xi)‖2=∑mj=1gj(xi)*gj(xi)=G(xi)·G(xi)(13)
c)粒向量-p范粒子。
‖G(xi)‖p=(∑mj=2gpj(xi))1p(14)
粒向量范粒子運(yùn)算的結(jié)果是粒子。范粒子運(yùn)算提供了一種從粒向量轉(zhuǎn)換為粒的方法。
2 粒邏輯回歸算法
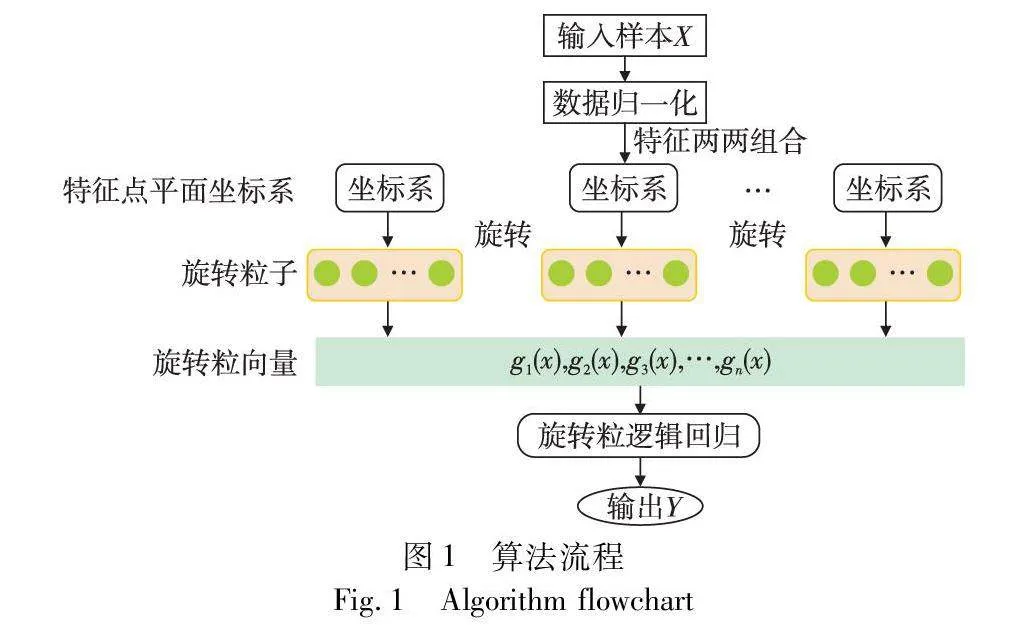
為了構(gòu)建旋轉(zhuǎn)粒邏輯回歸系統(tǒng),本文首先定義了旋轉(zhuǎn)粒邏輯函數(shù)。算法流程如圖1所示。
定義9 設(shè)C={U,F(xiàn),{l}},對(duì)于樣本xi∈U,粒子為g(x)={rj}kj=1,粒邏輯函數(shù)表示為
f(g(x))=11+e-rjkj=1(15)
粒邏輯函數(shù)的導(dǎo)數(shù)為
f′(g(x))=ddrjf(rj)kj=1=11+e-rj1-11+e-rjkj=1(16)
邏輯回歸是一個(gè)線性分類模型。為了得到粒邏輯回歸模型,需要導(dǎo)入粒線性方程。文獻(xiàn)[21,22]定義了粒狀線性回歸模型。
定義10 設(shè)C={U,F(xiàn),{l}},對(duì)于樣本xi∈U,粒向量為G(xi)=(g1(xi),g2(xi),…,gm(xi))T,權(quán)值粒向量W=(w1,w2,…,wm,b)T,粒回歸方程定義為
Reg(x)=W·G(x)=w1×g2(x)+w2×g2(x)+…+wm×gm(x)+1×b(17)
將粒線性回歸應(yīng)用于粒度邏輯函數(shù),得到粒度邏輯回歸模型。
定義11 設(shè)C={U,F(xiàn),{l}},粒向量為G(x),權(quán)值粒向量W,粒邏輯回歸如下所示。
fRGLR(x)=f(Reg(x))=11+e-W·G(x)kj=1(18)
旋轉(zhuǎn)粒邏輯回歸是關(guān)于粒子的函數(shù),通過(guò)樣本條件粒向量與權(quán)值粒向量的內(nèi)積計(jì)算,結(jié)果為決策粒子。同時(shí),標(biāo)簽值進(jìn)行粒化后形成標(biāo)簽粒子。因此,條件粒子與決策粒子進(jìn)行比較,將其差異按照梯度方向回傳修正權(quán)值粒核向量,從而形成旋轉(zhuǎn)粒邏輯回歸分類器。
2.1 粒邏輯回歸損失函數(shù)
粒邏輯回歸模型中,輸入是一個(gè)樣本的旋轉(zhuǎn)粒向量,輸出是一個(gè)決策粒子,決策粒子可以與構(gòu)成粒損失函數(shù)的標(biāo)簽粒子進(jìn)行比較。為了優(yōu)化粒邏輯回歸模型的參數(shù),需要定義其損失函數(shù)。
定義12 給定訓(xùn)練數(shù)據(jù)集T={(x1,y1),(x2,y2),…,(xn,yn)},其中xi為h維特征向量,xi∈XRh,yi∈{0,1},i=1,2,…,n。訓(xùn)練集T粒化為GT={(G(x1),g(y1)),(G(x2),g(y2)),…,(G(xn),g(yn))},其中G(xi)=(g1(xi),g2(xi),…,gh(xi))T為粒向量,g(yi)為標(biāo)簽粒子。粒邏輯回歸的損失函數(shù)定義為
L(g(yi),fRGLR(G(xi)))=-1n
∑ni=1[g(yi)log(fRGLR(G(xi)))+(1-g(yi))log(1-fRGLR(G(xi)))](19)
其中:1為1-粒子。
2.2 粒邏輯回歸算法
算法1 旋轉(zhuǎn)粒邏輯回歸學(xué)習(xí)算法
輸入:訓(xùn)練集T={(x1,y1),(x2,y2),…,(xn,yn)},其中xi為h維特征向量,其中xi∈XRh;yi是l-維標(biāo)簽向量,yi∈YRl,i=1,2,…,n;學(xué)習(xí)率為η(0<η≤1)。
輸出:W,b。
a)訓(xùn)練集T旋轉(zhuǎn)粒化為
GT={(G(x1),g(y1)),(G(x2),g(y2)),…,(G(xn),g(yn))};
b)構(gòu)建旋轉(zhuǎn)粒邏輯回歸模型,并隨機(jī)初始化權(quán)值粒向量W=(w1,w2,…,wm)T和偏置粒子b;
c)將粒向量輸入旋轉(zhuǎn)粒邏輯回歸模型,得到?jīng)Q策粒子;
d)計(jì)算決策粒子和標(biāo)簽粒子的損失函數(shù)L,根據(jù)梯度方向,反向傳播修正權(quán)重粒向量和偏置粒子;
e)步驟c)d)循環(huán)多次,直至損失函數(shù)收斂或迭代達(dá)到最大次數(shù);
f)輸出權(quán)值粒向量W=(w1,w2,…,wm)T和偏置粒子b。
3 實(shí)驗(yàn)分析
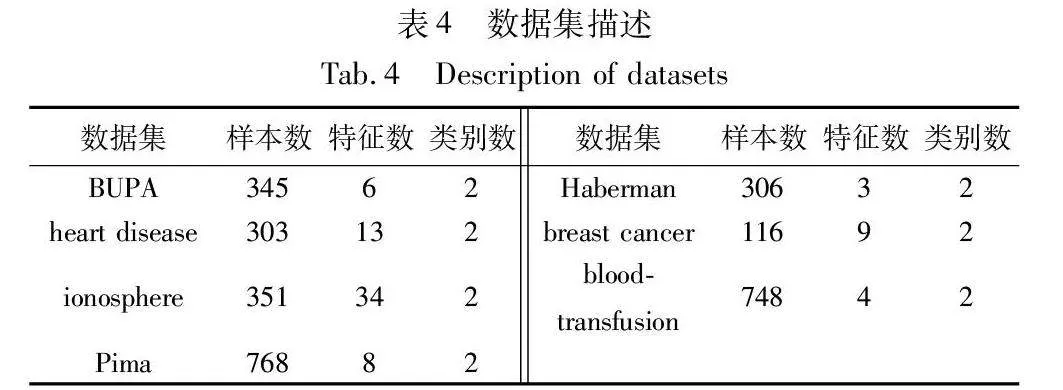
實(shí)驗(yàn)采用BUPA、heart disease、ionosphere、Pima、Haberman、breast cancer、blood-transfusion七個(gè)UCI數(shù)據(jù)集來(lái)驗(yàn)證本文算法的有效性,具體描述如表4所示。
由于每個(gè)數(shù)據(jù)集的特征值域是不同的,所以要對(duì)粒化后的粒子采用最大最小值歸一化,將每個(gè)特征的值域轉(zhuǎn)為[0,1],最大最小值歸一化公式為
Xnorm=X-XminXmax-Xmin(20)
使用accurancy、F1-score、ROC曲線、AUC四個(gè)指標(biāo)作為評(píng)估指標(biāo),其中,準(zhǔn)確率,F(xiàn)1-score表達(dá)式如下:
accuracy=TP+TNTP+TN+FP+FN(21)
precision(P)=TPTP+FP(22)
recall(R)=TPTP+FN(23)
F1=2×P×RP+R(24)
為了測(cè)試算法的有效性,分別采用傳統(tǒng)邏輯回歸模型、基于旋轉(zhuǎn)粒化的邏輯回歸模型在不同數(shù)據(jù)集上進(jìn)行旋轉(zhuǎn),對(duì)不同旋轉(zhuǎn)次數(shù)的準(zhǔn)確率做對(duì)比。同時(shí)采用十折交叉驗(yàn)證進(jìn)行實(shí)驗(yàn),將每個(gè)數(shù)據(jù)集隨機(jī)分成10份,其中一份為測(cè)試集,其余為訓(xùn)練集。再選另一份為測(cè)試集,其余為訓(xùn)練集,共測(cè)試10次,分類精度為10次的平均值。
3.1 旋轉(zhuǎn)次數(shù)的影響
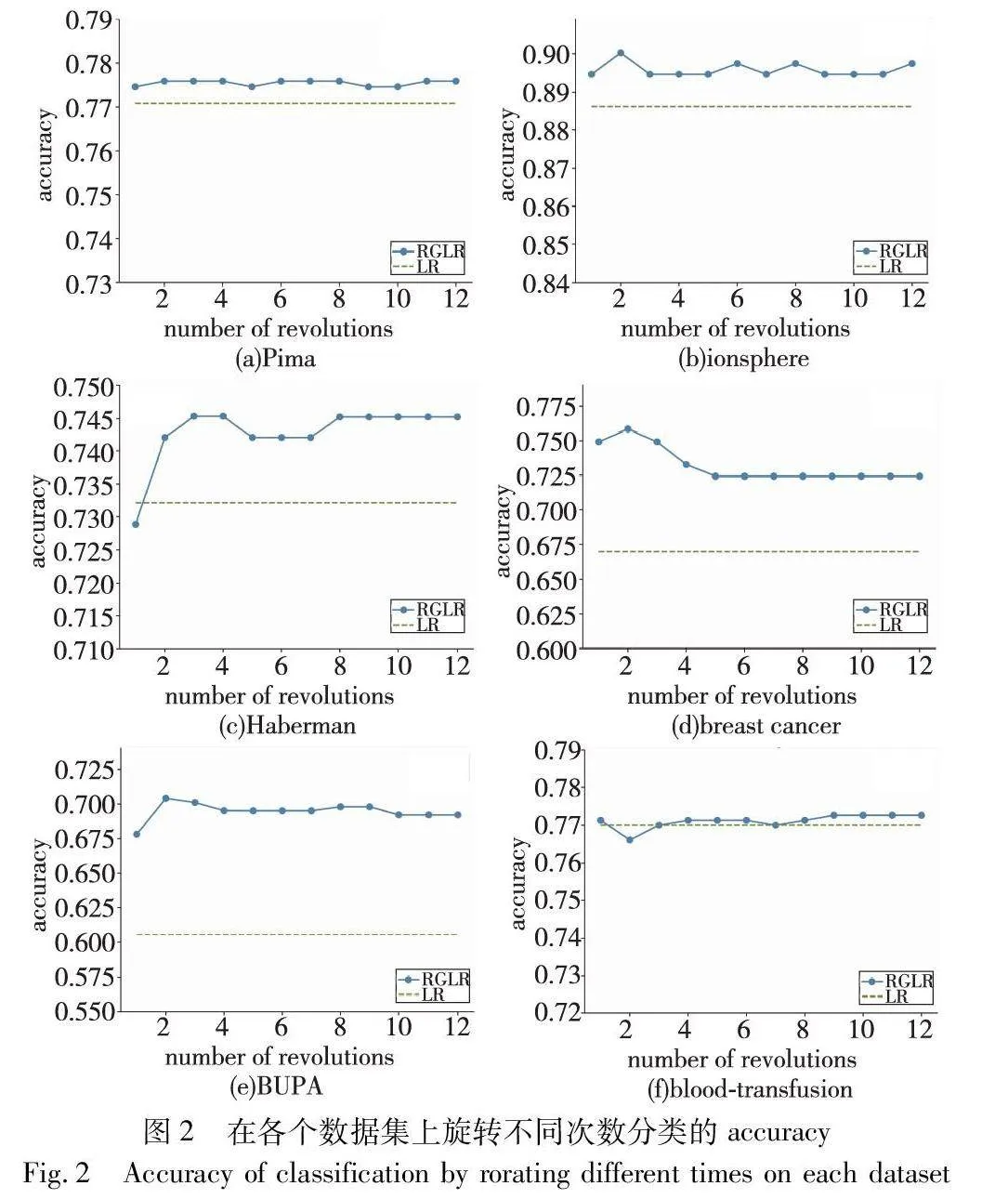
旋轉(zhuǎn)粒化過(guò)程需要設(shè)置旋轉(zhuǎn)角度與旋轉(zhuǎn)次數(shù)的參數(shù),實(shí)驗(yàn)中設(shè)置粒化角度θ為30°,旋轉(zhuǎn)次數(shù)為1~12。本節(jié)實(shí)驗(yàn)主要測(cè)試旋轉(zhuǎn)粒化次數(shù)參數(shù)的影響。七個(gè)UCI數(shù)據(jù)集的結(jié)果取六個(gè)(包括Pima、ionosphere、Haberman、breast cancer、BUPA、blood-transfusion),實(shí)驗(yàn)結(jié)果如圖2所示。
由圖2可知,旋轉(zhuǎn)粒邏輯回歸(RGLR)算法的accuracy在Pima、ionosphere、breast cancer、BUPA數(shù)據(jù)集上始終高于經(jīng)典邏輯回歸算法(LR)。在Pima數(shù)據(jù)集中,RGLR的準(zhǔn)確率始終高于LR,準(zhǔn)確率之差為0.003 9~0.005 20。在ionosphere數(shù)據(jù)集中,當(dāng)旋轉(zhuǎn)次數(shù)達(dá)到2時(shí),RGLR的準(zhǔn)確率達(dá)到峰值0.894 5且始終高于LR算法。在Haberman數(shù)據(jù)集中,RGLR的準(zhǔn)確率曲線隨準(zhǔn)確率先上升后保持平穩(wěn),當(dāng)旋轉(zhuǎn)次數(shù)為1時(shí),RGLR的準(zhǔn)確率為0.728 9,低于LR,但在旋轉(zhuǎn)2~12次時(shí),RGLR的準(zhǔn)確率始終高于LR,準(zhǔn)確率之差為0.009 8~0.013 2。在breast cancer數(shù)據(jù)集中,RGLR的準(zhǔn)確率曲線始終高于LR,且在旋轉(zhuǎn)次數(shù)為2時(shí)達(dá)到峰值0.758 3,準(zhǔn)確率之差為0.054 5~0.088 6。在BUPA數(shù)據(jù)集中,RGLR的準(zhǔn)確率曲線始終高于LR,準(zhǔn)確率之差為0.086 5~0.098 4。在blood-transfusion數(shù)據(jù)集中,當(dāng)旋轉(zhuǎn)次數(shù)為2時(shí),RGLR的準(zhǔn)確率低于LR,在其他旋轉(zhuǎn)次數(shù)時(shí),RGLR的準(zhǔn)確率比LR略高或相等。
從旋轉(zhuǎn)次數(shù)上看,對(duì)于不同數(shù)據(jù)分布的數(shù)據(jù)集、不同的旋轉(zhuǎn)次數(shù)都會(huì)對(duì)最終分類性能造成影響,且并非旋轉(zhuǎn)次數(shù)越多,分類性能越好。從總體上看,除了blood-transfusion數(shù)據(jù)集,RGLR算法的accuracy均高于LR,均能找到合適的旋轉(zhuǎn)次數(shù)使得accuracy達(dá)到最高值,超過(guò)經(jīng)典LR算法。與LR算法相比,RGLR算法在算法進(jìn)行之前就預(yù)先對(duì)數(shù)據(jù)進(jìn)行粒化,利用旋轉(zhuǎn)粒向量使得算法對(duì)特征信息少的數(shù)據(jù)分類性能提高。
3.2 分類算法比較
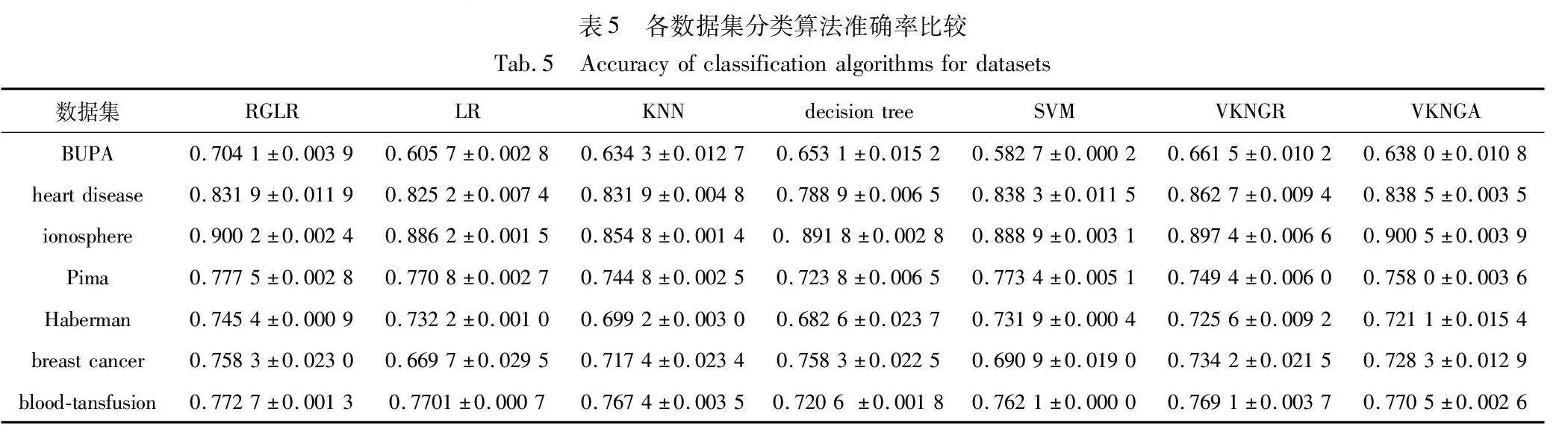
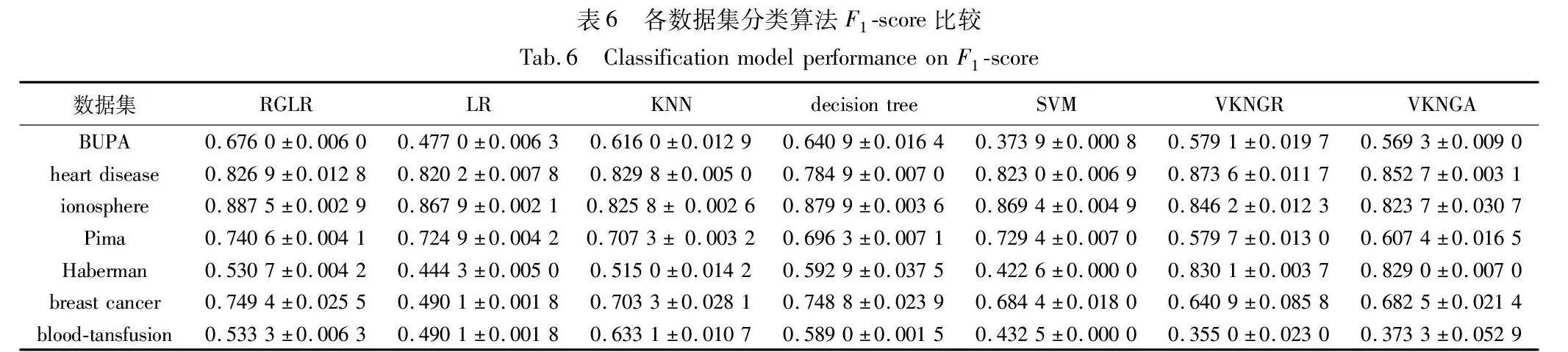
經(jīng)典的機(jī)器學(xué)習(xí)模型有K近鄰、決策樹(shù)、SVM等。本文采用準(zhǔn)確率、F1-score來(lái)評(píng)價(jià)預(yù)測(cè)算法的性能。對(duì)比了LR、K近鄰、決策樹(shù)、SVM以及基于粒向量的K近鄰分類器[29],其中基于粒向量的K近鄰分類算法包括基于相對(duì)粒向量距離的K近鄰分類器(VKNGR)和基于絕對(duì)粒向量距離的K近鄰分類器(VKNGA)。數(shù)據(jù)集中使用十次交叉驗(yàn)證求均值的方法得出均值和方差。各分類算法準(zhǔn)確率如表5所示,各分類算法F1-score比較如表6所示,結(jié)果保留四位小數(shù)。
從實(shí)驗(yàn)中可以得出,RGLR算法在BUPA、Pima、Haberman、breast cancer、blood-transfusion數(shù)據(jù)集上要明顯優(yōu)于其他算法。除在heart disease、ionosphere數(shù)據(jù)集上準(zhǔn)確率相對(duì)較低,在其他數(shù)據(jù)集上與其他算法相比,大部分情況準(zhǔn)確率更高。
由表5可知,當(dāng)使用accuracy作為性能評(píng)估指標(biāo)時(shí),在BUPA、Pima、Haberman和blood-tansfusion數(shù)據(jù)集中RGLR算法的得分要高于其他六種算法的得分。在breast cancer數(shù)據(jù)集中, RGLR算法的得分與決策樹(shù)得分相同且比經(jīng)典LR算法高出0.088 6。在heart disease數(shù)據(jù)集中RGLR算法得分雖然大于LR算法的得分,但低于VKNGR的得分。在ionosphere數(shù)據(jù)集中RGLR準(zhǔn)確率得分略低于擁有最高得分的VKNGA算法。
由表6可知,當(dāng)使用F1-score作為性能評(píng)估指標(biāo)時(shí),在BUPA、ionosphere、Pima和breast cancer數(shù)據(jù)集中,RGLR的F1-Score高于其他六種算法的F1-score得分,在數(shù)據(jù)集heart disease和Haberman上,VKNGR F1-score高于包括RGLR在內(nèi)的其他六種算法的F1-score,在blood-transfusion數(shù)據(jù)集中,KNN的F1-score高于其他六種算法的F1-score。
3.3 ROC曲線對(duì)比
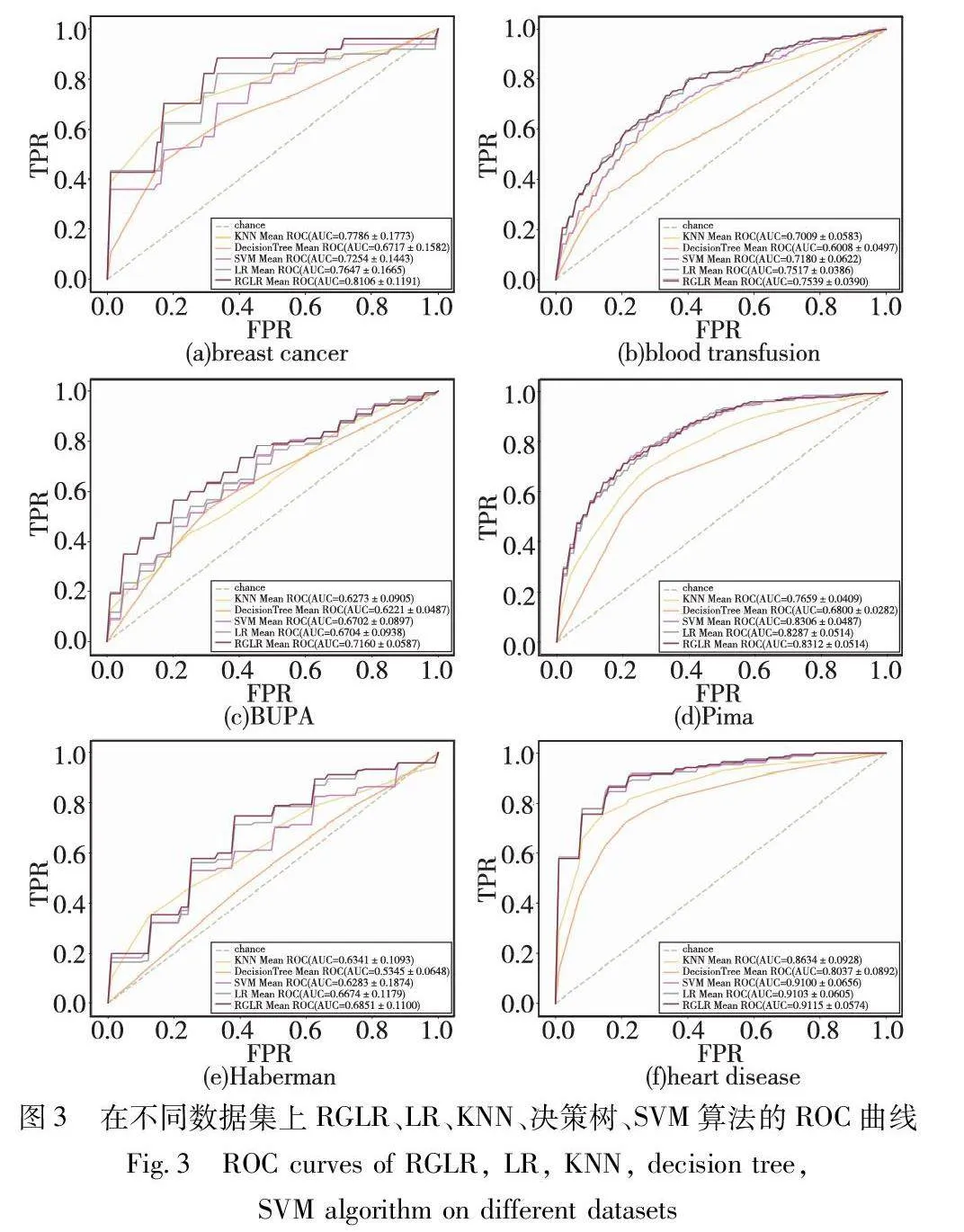
RGLR、LR、KNN、決策樹(shù)和SVM在七個(gè)UCI數(shù)據(jù)集的結(jié)果取六個(gè)數(shù)據(jù)集(包括breast cancer、blood-transfusion、BUPA、Pima、Haberman和heart disease)進(jìn)行十折交叉驗(yàn)證的接受者操作特性ROC曲線如圖3所示。
由圖3可知,在同一數(shù)據(jù)集上,不同的分類算法ROC曲線不同。在ROC曲線中,偏離對(duì)角線表現(xiàn)出更好的性能。在breast cancer、blood-transfusion、BUPA和Haberman 數(shù)據(jù)集上RGLR的ROC曲線明顯更靠近左上角,其AUC值最高,表明RGLR的分類效果更好。在Pima和heart disease數(shù)據(jù)集上RGLR、LR和SVM三種算法的ROC曲線接近,但RGLR的AUC值最高,表明RGLR的分類效果更好。
從以上實(shí)驗(yàn)可知,在大部分?jǐn)?shù)據(jù)集上旋轉(zhuǎn)粒邏輯回歸算法的分類性能均優(yōu)于邏輯回歸算法,優(yōu)于大部分的其他算法。與傳統(tǒng)算法不同,旋轉(zhuǎn)粒邏輯回歸算法利用旋轉(zhuǎn)粒化技術(shù)在結(jié)構(gòu)上突破,引入了更為復(fù)雜的特征表示和模型的非線性建模能力,同時(shí)在不同角度和方向上引入了新的特征變換,這不僅提高了對(duì)高維數(shù)據(jù)集的適應(yīng)能力,還能夠捕捉到數(shù)據(jù)中更加復(fù)雜的模式和結(jié)構(gòu),且提升了算法的分類性能,使得算法對(duì)于不同類型的數(shù)據(jù)集都有一個(gè)不錯(cuò)的效果。
4 結(jié)束語(yǔ)
傳統(tǒng)邏輯回歸分類器不具備處理模糊數(shù)據(jù)的性能,對(duì)于難以處理的YF3nzPUO1phk6pBKtjf00Q==高維、不確定性數(shù)據(jù),其分類效果不佳。本文從樣本的粒化角度出發(fā),通過(guò)定義粒向量的形式,還提出了一種新型的邏輯回歸分類模型:旋轉(zhuǎn)粒邏輯回歸。通過(guò)引入粒計(jì)算理論,樣本在特征構(gòu)成的平面坐標(biāo)系上不同角度的旋轉(zhuǎn),構(gòu)建旋轉(zhuǎn)粒子,多平面坐標(biāo)系上的粒化構(gòu)造成旋轉(zhuǎn)粒向量。進(jìn)一步定義旋轉(zhuǎn)粒的大小、度量和運(yùn)算規(guī)則,提出粒邏輯回歸的損失函數(shù)。最后,進(jìn)行實(shí)驗(yàn)分析,驗(yàn)證了旋轉(zhuǎn)粒K近鄰模型的正確性與有效性。在未來(lái)的工作中,可以研究粒的局部粒化方法,提高粒化速度與粒化性能;可以研究粒的度量方法,提高粒分類器的分類精度。
參考文獻(xiàn):
[1]Zadeh L A. Fuzzy sets[J]. Information and Control, 1965,8(3): 338-353.
[2]Lin T Y. Granular computing on binary relations I: data mining and neighborhood systems[J]. Rough Sets in Knowledge Discovery, 1998, 2: 165-166.
[3]Fu Chen, Lu Wei, Pedrycz W, et al. Fuzzy granular classification based on the principle of justifiable granularity[J]. Knowledge-Based Systems, 2019, 170: 89-101.
[4]Zhou Yanjun, Ren Huorong, Li Zhiwu, et al. Anomaly detection based on a granular Markov model[J]. Expert Systems with Applications, 2022, 187: 115744.
[5]Zadeh L A. Toward a theory of fuzzy information granulation and its centrality in human reasoning and fuzzy logic[J]. Fuzzy Sets and Systems, 1997, 90(2): 111-127.
[6]Lu Wei, Ma Cong, Pedrycz W, et al. Design of granular model: a method driven by hyper-box iteration granulation[J]. IEEE Trans on Cybernetics, 2023, 53(5): 2899-2913.
[7]Lin T Y. Approximate computing in numerical analysis variable interval computing[C]//Proc of IEEE International Conference on Systems, Man and Cybernetics. Piscataway, NJ: IEEE Press, 2019: 2013-2018.
[8]Lin T Y, Zadeh L A. Special issue on granular computing and data mining[J]. International Journal of Intelligent Systems, 2004, 19(7): 565-566.
[9]Yue Xiaodong, Zhou Jie, Yao Yiyu, et al. Shadowed neighborhoods based on fuzzy rough transformation for three-way classification[J]. IEEE Trans on Fuzzy Systems, 2020, 28(5): 978-991.
[10]Zhan Jianming, Zhang Xiaohong, Yao Yiyu. Covering based multigranulation fuzzy rough sets and corresponding applications[J]. Artificial Intelligence Review, 2020, 53(2): 1093-1126.
[11]Gao Can, Zhou Jie, Miao Duoqian, et al. Granular-conditional-entropy based attribute reduction for partially labeled data with proxy labels[J]. Information Sciences, 2021, 580: 111-128.
[12]Zhang Xianyong, Gou Hongyuan, Lyu Zhiying, et al. Double-quanti-tative distance measurement and classification learning based on the tri-level granular structure of neighborhood system[J]. Knowledge-Based Systems, 2021, 217: 106799.
[13]Zhang Xianyong, Yao Hong, Lyu Zhiying, et al. Class-specific information measures and attribute reducts for hierarchy and systematicness[J]. Information Sciences, 2021, 563: 196-225.
[14]Yu Ying, Tang Hong, Qian Jin, et al. Fine-grained image recognition via trusted multi-granularity information fusion[J]. International Journal of Machine Learning and Cybernetics, 2023, 14(4): 1105-1117.
[15]Qian Jin, Miao Duoqian, Zhang Zehua, et al. Parallel attribute reduction algorithms using mapreduce[J]. Information Sciences, 2014, 279: 671-690.
[16]Shao Mingwen, Wu Weizhi, Wang Xizhao, et al. Knowledge reduction methods of covering approximate spaces based on concept lattice[J]. Knowledge-Based Systems, 2020, 191: 105269.
[17]Chen Yumin, Qin Nan, Li Wei, et al. Granule structures, distances and measures in neighborhood systems[J]. Knowledge-Based Systems, 2019, 165: 268-281.
[18]Li Wei, Chen Yumin, Song Yuping. Boosted K-nearest neighbor classifiers based on fuzzy granules[J]. Knowledge-Based Systems, 2020, 195: 1-13.
[19]Xia Shuyin, Liu Yunsheng, Ding Xin, et al. Granular ball computing classifiers for efficient, scalable and robust learning[J]. Information Sciences, 2019, 483: 136-152.
[20]陳玉明, 董建威. 基于粒計(jì)算的非線性感知機(jī)[J]. 數(shù)據(jù)采集與處理, 2022, 37(3): 566-575. (Chen Yuming, Dong Jianwei. Non-linear perceptron based on granular computing[J]. Journal of Data Acquisition and Processing, 2022, 37(3): 566-575.)
[21]Chen Linshu, Shen Fuhui, Tang Yufei, et al. Algebraic structure based clustering method from granular computing prospective[J]. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 2023, 31(1): 121-140.
[22]Chen Linshu, Zhao Lei, Xiao Zhenguo, et al. A granular computing based classification method from algebraic granule structure[J]. IEEE Access, 2021, 9: 68118-68126.
[23]Mendel J M, Bonissone P P. Critical thinking about explainable AI(XAI) for rule-based fuzzy systems[J]. IEEE Trans on Fuzzy Systems, 2021, 29(12): 3579-3593.
[24]Nibbering D, Hastie T J. Multiclass-penalized logistic regression[J]. Computational Statistics & Data Analysis, 2022, 169: 107414.
[25]Jawa T M. Logistic regression analysis for studying the impact of home quarantine on psychological health during COVID-19 in Saudi Arabia[J]. Alexandria Engineering Journal, 2022, 61(10): 7995-8005.
[26]Li Chenggang, Liu Qing, Huang Lei. Credit risk management of scientific and technological enterprises based on text mining[J]. Enterprise Information Systems, 2021, 15(6): 851-867.
[27]張旭, 柳林, 周翰林, 等. 基于貝葉斯邏輯回歸模型研究百度街景圖像微觀建成環(huán)境因素對(duì)街面犯罪的影響[J]. 地球信息科學(xué)學(xué)報(bào), 2022, 24(8): 1488-1501. (Zhang Xu, Liu Lin, Zhou Hanlin, et al. Using Baidu street view images to assess impacts of micro-built environment factors on street crimes: a Bayesian logistic regression approach[J]. Journal of Geoinformation Science, 2022, 24(8): 1488-1501.)
[28]Chen Yumin, Cai Zhiwen, Shi Lei, et al. A fuzzy granular sparse learning model for identifying antigenic variants of influenza viruses[J]. Applied Soft Computing, 2021, 109: 107573.
[29]陳玉明, 李偉. 粒向量與K近鄰粒分類器[J]. 計(jì)算機(jī)研究與發(fā)展, 2019, 56(12): 2600-2611. (Chen Yuming, Li Wei. Granular vectors and K-nearest neighbor granular classifiers[J]. Journal of Computer Research and Development, 2019, 56(12): 2600-2611.)
