基于強化和模仿學習的多智能體尋路干擾者鑒別通信機制
2024-08-15 00:00:00李夢甜向穎岑謝志峰馬利莊
計算機應用研究 2024年8期



摘 要:現有的基于通信學習的多智能體路徑規劃(multi-agent path finding,MAPF)方法大多可擴展性較差或者聚合了過多冗余信息,導致通信低效。為解決以上問題,提出干擾者鑒別通信機制(DIC),通過判斷視場(field of view,FOV)中央智能體的決策是否因鄰居的存在而改變來學習排除非干擾者的簡潔通信,成功過濾了冗余信息。同時進一步實例化DIC,開發了一種新的高度可擴展的分布式MAPF求解器,基于強化和模仿學習的干擾者鑒別通信算法(disruptor identifiable communication based on reinforcement and imitation learning algorithm,DICRIA)。首先,由干擾者鑒別器配合DICRIA的策略輸出層識別出干擾者;其次,在兩輪通信中分別完成對干擾者與通信意愿發送方的信息更新;最后,DICRIA根據各模塊的編碼結果輸出最終決策。實驗結果表明,DICRIA的性能幾乎在所有環境設置下都優于其他同類求解器,且相比基線求解器,成功率平均提高了5.2%。尤其在大尺寸地圖的密集型問題實例下,DICRIA的成功率相比基線求解器甚至提高了44.5%。
關鍵詞:多智能體; 路徑規劃; 強化學習; 模仿學習; 干擾者鑒別通信
中圖分類號:TP391 文獻標志碼:A
文章編號:1001-3695(2024)08-032-2474-07
doi:10.19734/j.issn.1001-3695.2023.11.0555
Disruptor identifiable communication based on reinforcement and
imitation learning for multi-agent path finding
Li Mengtian1a,1b, Xiang Yingcen1a, Xie Zhifeng1a,1b, Ma Lizhuang1b,2
(1.a.Dept. of Film & Television Engineering, b. Shanghai Film Special Effects Engineering Technology Research Center, Shanghai University, Shanghai 200072, China; 2.Dept. of Computer Science & Engineering, Shanghai Jiao Tong University, Shanghai 200240, China)
Abstract:Most of the existing MAPF methods based on communication learning have poor scalability or aggregate too much redundant information, resulting in inefficient communication. To solve these problems, this paper proposed disruptor identifiable communication(DIC), which learned concise communication excluding non-disruptors by judging whether the agent in the center of the field of view would change its decision-making due to the presence of neighbors, and successfully filtered out redundant information. At the same time, this paper further instantiated DIC and developed a new highly scalable distributed MAPF solver: disruptor identifiable communication based on reinforcement and imitation learning algorithm(DICRIA). Firstly, the disruptor discriminator and the policy output layer of DICRIA identified the disruptor. Secondly, the algorithm updated the information of the disruptor and the communication wish sender in two rounds of communication respectively. Finally, DICRIA output the final policy according to the coding results of each module. Experimental results show that DICRIA’s performance is better than other similar solvers in almost all environment settings, and the algorithm increases the success rate by 5.2% on average compared to the baseline solver. Especially in dense problem instances with large-size maps, the algorithm even increases the success rate of DICRIA by 44.5% compared to the baseline solver.
Key words:multi-agent; path finding; reinforcement learning; imitation learning; disruptor identifiable communication(DIC)
0 引言
多智能體路徑規劃(MAPF)是為多個智能體尋找從起始位置到目標位置的無沖突路徑集合的問題。MAPF在許多領域都有著廣泛的應用,如城市道路網絡[1]、火車調度[2]、多機器人系統[3]等。
按照規劃方式不同,MAPF算法分為集中式規劃算法和分布式執行算法。集中式規劃算法是經典的MAPF算法,主要分為基于A*搜索[4~8]、基于沖突搜索[9~13]、基于代價增長樹[14~16]和基于規約[17,18]四種。然而,這些集中式規劃方法的局限性在于它們通常無法在保持高質量解決方案的同時擴展到更大的問題規模(更大的地圖、更多的智能體),且由于計算成本較高,往往無法滿足實際應用中的頻繁實時重新規劃的需求。關于傳統集中式規劃算法的詳細介紹可參考文獻[19]。
分布式執行算法是人工智能領域興起的基于學習的MAPF算法,由于采取部分可觀測性下的去中心化規劃,而在解決實際部署中的頻繁重規劃問題上表現出了較大的潛力,近年來引起了越來越多的關注。僅依賴局部觀測的去中心化規劃能夠讓MAPF問題輕松地擴展到任意的世界大小(地圖尺寸),但也嚴重限制了智能體可用的信息量,使它們難以完成需要高度協作的密集型MAPF任務。部分學者將強化學習與模仿學習相結合,采用傳統集中式規劃算法作為專家算法為強化學習提供指導[20,21],但由專家演示提供的著眼全局的指導信息不足以使智能體學會高效合作。另一部分學者則通過引入可學習的通信方法[22~25],允許智能體共享其信息,以彌補局部觀測信息量受限的缺陷。這相當于間接擴大了FOV的范圍,使智能體能夠獲取到其他智能體FOV內的觀測信息,從而增加單個智能體可用的信息量并促進團隊合作。但大多數采用通信的基于學習的MAPF方法的可擴展性都非常有限,通常無法在大小為40×40的地圖上解決包含超過64個智能體的問題實例。先進的SCRIMP[26]通過基于改進Transformer的全局通信來聚合上一個時間步所有智能體的消息,雖然有效緩解了可擴展性的問題,卻也造成了通信冗余,而這會在一定程度上損害智能體間的合作。并且,通信過去的消息(上一個時間步的消息)還存在滯后性的問題。因此,為多智能體路徑規劃設計一個能夠解決以上問題的通信機制十分重要且必要。
針對上述方法的局限性,本文提出干擾者鑒別通信機制DIC,并進一步將其實例化,開發了一個新的基于強化和模仿學習的MAPF求解器DICRIA。DIC通過忽略其他鄰居,只與那些對自身決策有影響的干擾者鄰居進行通信,有效避免了聚合不相關的信息,從而避免了通信冗余問題;同時降低了通信頻率,能夠提高多智能體規劃任務中的通信效率,幫助智能體更好地學會合作。具體地,其核心組件干擾者鑒別器將原始局部觀測與掩蔽局部觀測編碼后的結果輸入到DICRIA的策略輸出層,根據決策差異識別出對中央智能體實際有影響的干擾者鄰居。而后通信將分為發送通信意愿與給予反饋的兩輪過程。首輪過程中,智能體向干擾者發送攜帶有自身信息的通信意愿,干擾者根據接收到的通信意愿更新信息并反饋更新后的結果。在第二輪中,完成對意愿發送方信息的更新。DICRIA結合兩輪通信所聚合的信息與其他組成部分的編碼結果,并據此輸出最終的決策。實驗結果表明,本文新MAPF求解器幾乎在所有環境下,均在規劃平均所耗時間步數、沖突率及成功率上優于其他最先進的同類求解器,并通過消融實驗證明了本文提出的通信機制的有效性。本文的主要貢獻總結如下:
a)提出一種適用于MAPF問題的新通信機制:干擾者鑒別通信,簡稱DIC。其核心組件是干擾者鑒別器。在通信之前,由干擾者鑒別器為每個智能體鑒別其FOV內的干擾者,通過只與干擾者進行通信,DIC有效避免了通信冗余。并且,DIC可與任意集中訓練分散執行的強化學習框架兼容。
b)實例化DIC,開發了一種新的高度可擴展的分布式MAPF求解器:基于強化和模仿學習的干擾者鑒別通信算法DICRIA。智能體根據其視場內的局部觀測及由DIC聚合的干擾者信息獨立做決策。
c)本文在一系列具有不同團隊規模、環境規模、障礙物密度的問題實例中進行了多方面的對比實驗。實驗結果證明了DICRIA在三項標準MAPF指標上的性能普遍優于其他先進的同類求解器。最突出的是,DICRIA成功地將基線求解器的成功率平均提高了5.2%,在密集型環境下,甚至提高了44.5%。
1 問題定義
1.1 MAPF問題定義
經典的MAPF以無向圖G=(V,E)和智能體集合A={a1,…,an}作為輸入,A中包含n個智能體。V為可通行的位置頂點集合,E為V中相鄰點間的連通邊的集合。每一個ai∈A都有一個唯一的起始頂點si∈V和一個唯一的目標頂點gi∈V。時間被離散化為時間步,在每一個時間步長上,智能體可以移動到相鄰的頂點,也可以在當前位置頂點等待。智能體的路徑是從si開始,到gi結束的由相鄰(表示移動動作)或相同(表示等待動作)的頂點組成的序列。通常假設智能體到達目標后便永遠停留在目標位置上。路徑的長度計算為智能體向目標移動的過程中執行的動作總數(包括移動和等待兩種動作),即其消耗的時間步數。智能體必須避免頂點沖突和交換沖突。當兩個智能體在同一個時間步上占據相同的頂點將發生頂點沖突,以相反的方向穿過同一條邊時將發生交換沖突。MAPF的解決方案是一組無沖突的路徑,由n個智能體的路徑組成。目標通常是最小化路徑成本總和,即所有智能體到達其目標所消耗的時間步數之和。有關MAPF問題更全面的定義可參考文獻[27]。
1.2 RL環境設置
與上述經典MAPF問題一致,本文將RL環境設置為離散的2D四鄰域網格環境,其中智能體、目標和障礙物各自占據一個網格單元。環境地圖是一個L×L的矩陣,其中0代表空單元格,1代表障礙物,地圖邊界之外的所有點均被視為障礙。每個問題實例中,本文在環境地圖上為n個智能體從空單元格中隨機選擇非重復的起始位置和相應的目標位置,并且確保每對起始-目標位置之間的連通性。動作空間的大小設置為5,包括原地等待和上下左右四個方向的移動動作。在每個時間步上執行決策動作之前,先檢查動作是否會導致沖突,若存在沖突則觸發沖突處理機制(將在第3章闡述)對動作進行調整,并允許智能體同時執行調整后的動作。當所有智能體均到達目標,或達到預定義的時間限制時(256個時間步),終止對問題實例的求解。本文假設通信不受障礙物阻礙。
MAPF環境被設置為部分可觀察,這更符合現實應用中機器人視野受限的實際情況。每個智能體只能訪問其視場(FOV)內的信息,FOV的大小為l×l,本文實驗中將l設置為奇數,以確保智能體位于FOV的中心。
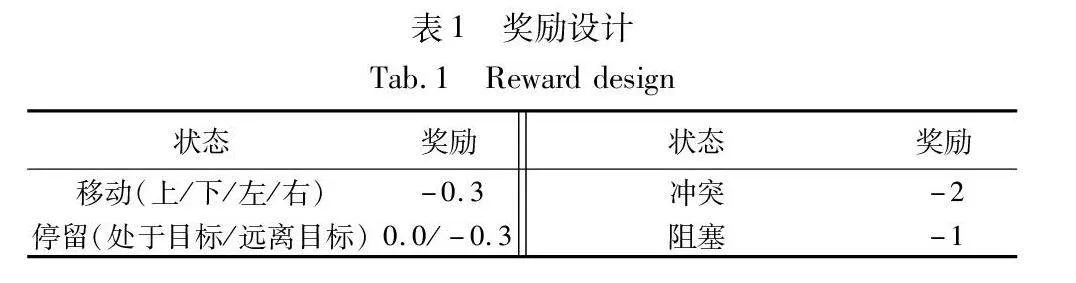
本文獎勵設計同SCRIMP[26],如表1所示。對除了位于目標位置之外的所有狀態都給予負獎勵以促進目標的達成。
2 干擾者鑒別通信機制DIC
受I2C[28]的啟發,本文提出了一種新的通信機制,稱為干擾者鑒別通信機制DIC。DIC有效彌補了現有MAPF求解器通信機制的缺陷,避免了聚合過多無用信息而造成通信冗余、降低通信效率的問題。
I2C通過兩個決策概率(考慮影響者時,被影響者的決策概率;掩蔽影響者時,被影響者的決策概率)之間的KL散度來度量一個智能體對另一個智能體決策的影響程度。當KL散度很小時,被影響的智能體選擇不與影響者通信;當KL散度較大,超過預定義的閾值時,則進行通信。然而,I2C的局限性在于KL散度閾值的設置高度依賴于經驗實驗,且在不同的問題中差異較大,具有偶然性。此外,I2C還需要已知所有其他智能體的聯合觀測和動作,而在現實的MAPF問題中,具有局部觀測性的智能體通常只能觀察到有限范圍內其他智能體的存在,且無法預測它們的動作。為此,本文提出DIC,其不依賴聯合觀測和動作,更適用于MAPF問題。
DIC的核心思想是,在訓練和執行期間有選擇的與部分鄰居進行通信。本文認為,距離較近的智能體彼此之間并不總是相關的,并不是所有鄰居都能提供有效信息。如果對鄰居的信息不作篩選和判斷,同SCRIMP一樣全盤接收,容易獲取到來自其他智能體的不相關且冗余的信息,聚合過多無用信息會間接降低實際有效的信息的正向指導效力,甚至會誤導模型,從而導致不明智的決策,損害智能體之間的合作。因此,有必要在通信之前對鄰居的信息進行篩選,為每個智能體找出那些能夠為其決策提供有效信息的相關鄰居,只與它們進行通信,能有效過濾冗余信息,降低通信成本,且有助于智能體更好地學習合作。而只有當鄰居智能體的存在引起FOV中央智能體的決策調整時,DIC才確定該鄰居是相關的和有影響力的。本文將那些會對中央智能體的決策產生影響的鄰居稱為干擾者(disruptor)。對干擾者的判斷僅基于智能體的局部觀測來學習,因此能夠在大規模的多智能體規劃問題中通過分散執行的方式有效部署。
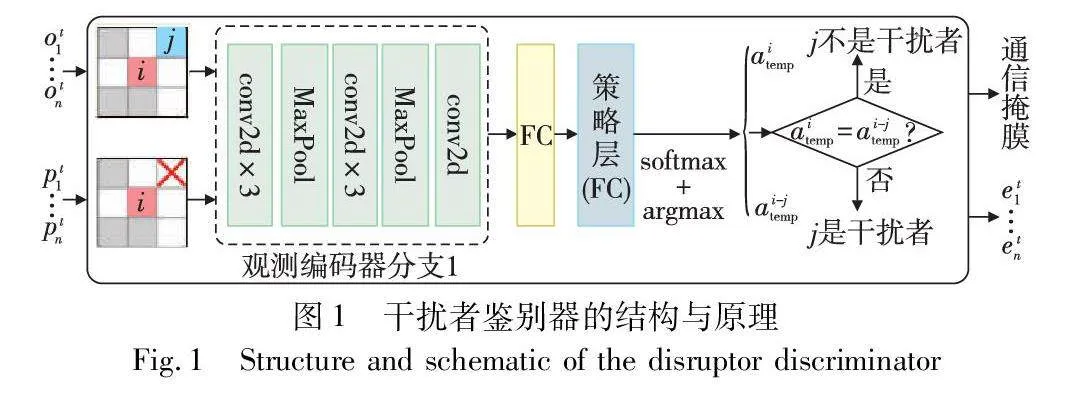
DIC對干擾者的判斷由干擾者鑒別器來完成,圖1顯示了鑒別器的結構與完整的鑒別流程。在3×3的FOV中,灰色方格代表障礙物,彩色方格代表智能體,紅色的“×”表示從智能體i的局部觀測中掩蔽掉智能體j(參見電子版)。以簡單的局部場景為例,假設智能體i的FOV內只有一個鄰居智能體j。智能體i的局部觀測表示為oi(原始局部觀測),從oi中掩蔽掉智能體j,得到i的掩蔽局部觀測oi-j。通過在oi中將j對應位置處的信息設置為某個特殊的值(例如0)來實現這種掩蔽。然后,智能體i分別基于oi和oi-j,使用決策模型(跳過通信塊)計算出兩個臨時的決策,對應生成兩個臨時的動作。具體地,利用本文決策模型中觀測編碼器的第一個分支(將在第3.1節闡述),oi和oi-j作為其輸入值,將該分支的輸出結果經過一個全連接(FC)層處理后直接輸入到策略輸出頭(將在第3.4節闡述),為i的兩種局部觀測分別計算出對應動作空間中所有動作的概率分布,并將概率最大的動作確定為最終的臨時動作aitemp和ai-jtemp。如果aitemp和ai-jtemp相互匹配,則意味著智能體j的存在不會影響i的決策,即j與i不相關,不是i的干擾者,i不與j通信;否則,j確定為i的干擾者,i需要與j進行通信。
當為智能體i鑒別出所有干擾者j之后,DIC的通信將分兩輪進行。本文將這兩輪的通信過程形象化地描述為智能體之間發送通信意愿(wish)以及給予反饋(feedback)的信息交流過程。在第一輪中,智能體i向其所有干擾者j發送wish,wish中包含自身信息以及鄰居的相對位置。干擾者可能收到來自不同意愿發送者的wish,并根據收到的所有wish更新自身的信息。在第二輪中,所有干擾者j將feedback回復給智能體i,feedback中包含更新后的自身信息及鄰居的相對位置。智能體i根據接收到的feedback完成信息的更新。
3 MAPF求解算法DICRIA
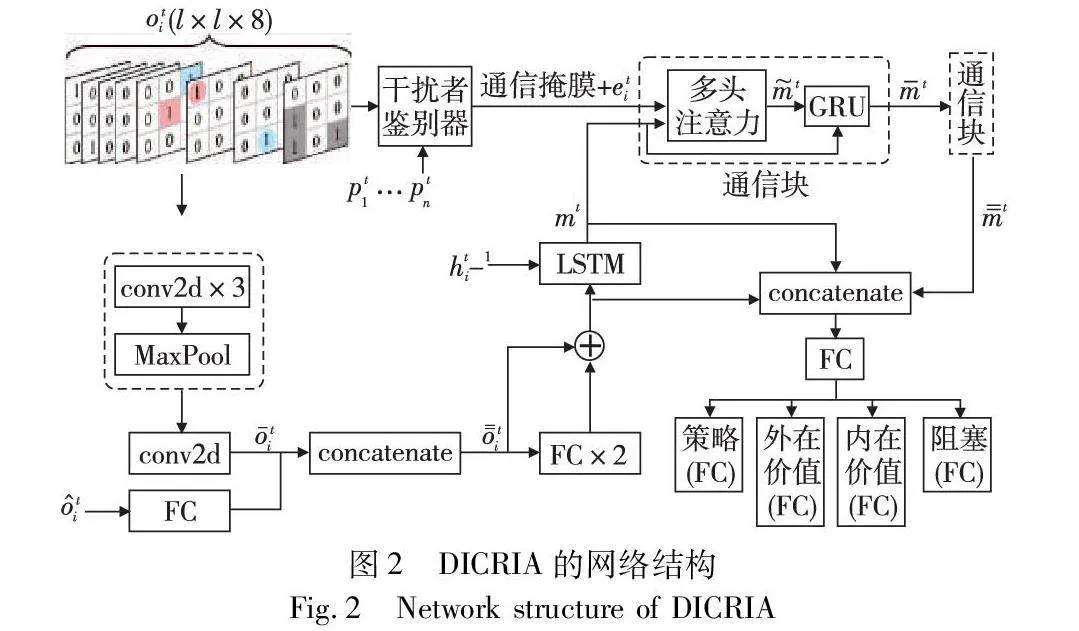
本文參考SCRIMP[26],為解決 MAPF問題開發了一種新的求解器:DICRIA,其實例化了在第2章詳細介紹的新通信機制。DICRIA的網絡結構如圖2所示,由觀測編碼器(綠色)、干擾者鑒別器(黃色)、通信模塊(紫色)和輸出頭(藍色)四個主要部分組成(參見電子版)。干擾者鑒別器的詳情如圖1所示。FOV內8通道的局部觀測以3×3的網格示例,其中彩色方塊表示智能體,彩色圓形表示顏色對應的智能體的目標,灰色方塊表示障礙物。本章將分別描述這四個組成部分。
3.1 觀測編碼器
觀測編碼器由7個卷積層、2個最大池化層、3個全連接(FC)層和1個LSTM單元組成。在LSTM單元之前,被分成了兩條并行的分支,分別處理當前時間步智能體的局部觀測和智能體的觀測向量兩個不同的輸入值。
分支1的輸入,即當前時間步智能體的局部觀測oti(i=1,…,n)的形狀為l×l×8,由8個二進制矩陣組成。前四個是DHC[23]提出的啟發式通道,分別對應上下左右四個移動動作,當且僅當智能體通過采取該動作更接近其目標時,對應通道上的相應位置被標記為1,以此編碼單智能體最短路徑的多種選擇。其余四個通道分別表示智能體的位置、中心智能體自己的目標位置(如果在FOV內)、FOV內其他智能體目標的投影位置以及FOV內的障礙物。分支2的輸入是智能體的觀測向量ti,包含7個分量:智能體當前位置與其目標沿x軸的歸一化距離dxti、沿y軸的歸一化距離dyti、總歐氏距離dti、外在獎勵ret-1i、內在獎勵rit-1i、智能體上一個時間步的位置與其在緩沖區中存儲的歷史位置間的最小歐氏距離dmint-1i(均在第3.4節介紹)以及上一個時間步的動作at-1i。
智能體i的局部觀測oti首先通過分支1被編碼為ti,具體經過了兩個相同的子模塊(3個卷積和1個最大池化層)和一個單獨的卷積層。同時,長度為7的觀測向量ti在分支2中由一個FC層獨立編碼,然后將分支2的輸出與ti串連得到o=ti。接著,o=ti與其自身經過兩個FC層編碼后的結果相加,并和上一個時間步LSTM的輸出ht-1i一起輸入LSTM單元,從而賦予了智能體跨時間步聚合過去信息的能力。
3.2 干擾者鑒別器
該鑒別器需要當前時間步智能體的局部觀測oti和當前位置pti作為輸入,根據oti計算出掩蔽局部觀測oti-j(j∈Ni,Ni是i的FOV內所有鄰居智能體的集合),根據pti計算鄰居智能體在FOV內的相對位置eti。然后,按照第2章中描述的鑒別流程,為每個智能體找出各自的干擾者,由此確定t時刻,i的通信范圍為Ci={j|aitemp≠ai-jtemp}j∈Ni,aitemp和ai-jtemp為第2章中描述的臨時動作。Ci最終被編碼為通信掩膜,并和eti一起作為干擾者鑒別器的輸出值饋入通信模塊。
3.3 通信模塊
通信模塊由兩個相同的計算塊組成,分別對應兩輪通信。通信采用圖卷積,以多頭點積注意力[29]作為卷積核,后跟一個GRU。本文將兩輪通信描述為智能體之間發送通信意愿(wish)和給予反饋(feedback)的過程。
在第一輪中,智能體i向所有的干擾者j∈Ci發送wish,wish中包含自身信息,即oti和ti經過觀測編碼器處理后的輸出信息mti∈mt(mt是LSTM單元的輸出值),以及鄰居智能體的相對位置eti。干擾者可能收到來自不同意愿發送者的多條wish,由此干擾者j的wish接收范圍可表示為C~j={i|j∈Ci}。然后,干擾者j根據收到的所有wish使用多頭點積注意力更新自身信息mtj∈mt,同時保持意愿發送方i的信息在本輪不變,得到第一輪通信的輸出結果t。具體地,在每個獨立的注意力頭h中,首先將i∈j的自身信息mti通過矩陣WhQ映射為query,再將mti與eti的串連分別通過矩陣WhK和WhV映射為key和value。干擾者j與i∈j在第h個注意力頭中的關系則可以計算為
whji=softmax(WhQmtj·(WhK[mti,eti])TdK)(1)
其中:dK是keys的維度。在每個注意力頭h中,以whji為權重對value進行加權求和,并將所有頭的輸出串連后通過一個神經網絡層fnn,得到干擾者j的注意力輸出值tj:
tj=fnn(concat(∑i∈jwhjiWhV[mti,eti],h∈Euclid Math OneHAp))(2)
最后,將干擾者j計算注意力前的自身信息mtj與tj經過GRU聚合,得到最終更新后的信息tj。
在第二輪中,所有干擾者j將feedback回復給智能體i,feedback中包含更新后j的自身信息(j的第一輪通信結果tj)及etj。同理,意愿發送方i根據收到的所有feedback(來自j∈Ci)完成對自身信息的更新,更新方法與第一輪相同。與此同時,干擾者的信息在本輪保持不變。經過兩輪通信之后,通信模塊的最終輸出為m=t。
3.4 輸出頭
輸出頭由5個全連接(FC)層組成。其中,一個是公共FC層,用于編碼LSTM單元的輸入(不包括ht-1i),LSTM單元的輸出mt以及通信模塊的輸出m=t三者的串連。余下的FC層用于將公共FC層的輸出分別編碼成策略(policy)、外在獎勵的預測狀態值(extrinsic value)、內在獎勵的預測狀態值(intrinsic value)及可學習的阻塞預測值(blocking)四個不同的輸出值。
policy是模型的決策,即當前時間步智能體的策略。具體為動作空間中每個動作的概率值,概率值最大的動作便是模型為智能體選出的在當前時間步的最佳動作。
本文采用了SCRIMP對沖突決策的處理機制和用于鼓勵探索的內在獎勵設計。當模型輸出的決策將導致沖突時,則會觸發沖突處理機制。該機制以使未來收益最大化為準則,進行比較判斷,選出一個勝者智能體來執行其首選動作,與之沖突的其他智能體則重新選擇一個新動作,以此來解決智能體間的沖突。當與障礙物沖突時,則使智能體停留在原地并給予懲罰。而內在獎勵是指遠離熟悉的區域所獲得的獎勵,相對地,執行動作空間中的動作而獲得的獎勵被稱為外在獎勵。當智能體的當前位置與其歷史位置間的距離超過一個閾值時,便給予內在獎勵,以此鼓勵探索,從而增大其到達目標的可能性。外在和內在獎勵的預測狀態值便是模型對當前時間步所能獲得的真實外在和內在獎勵的估計,這兩個輸出值同時也在沖突處理機制中用于打破對稱性,幫助選擇最終被允許執行首選動作的勝者智能體。
最后,blocking用于指示一個智能體是否阻礙其他智能體更早到達其目標,并隱式地幫助智能體理解它們可能受到的額外阻塞懲罰(表1)。
關于沖突處理機制和內在獎勵的詳細介紹、兩個預測狀態值和blocking更具體的用法及作用請參見SCRIMP[26]。訓練使用的損失函數及超參數的設置均同SCRIMP,具體見下一節。
3.5 訓練設置
在MAPF問題中,一個問題實例的完整求解過程被稱為一個episode。設置一個episode的最大求解時間為256個時間步,超過時限仍未完成求解的問題實例被判定為求解失敗。訓練的截止時間為3×107個時間步,由外層while循環來判斷是否達到訓練的終止條件。在每一輪while循環開始之前,根據預定的比例隨機選擇網絡是通過IL還是RL進行訓練,IL被選中的概率設置為0.1。在每一輪while循環中,本文借助Ray 1.2.0使用16個進程并行收集數據,并將epoch設置為10,batch size設置為1 024。優化器選用Adam優化器,lr為10-5。策略優化的損失函數如下:
Lπ(θ)=1T1n∑Tt=1∑ni=1min(rti(θ)AtiEuclid ExtravBp,clip(rti(θ),1-,1+)AtiEuclid ExtravBp)(3)
rti(θ)=πθi(ati∣oti,ti,ht-1i,mt1,…,mtn)πθoldi(ati∣oti,ti,ht-1i,mt1,…,mtn)(4)
其中:θ表示神經網絡的參數;rti(θ)是裁剪概率比;πθi和πθoldi分別是智能體i的新舊策略;是裁剪超參數,值為0.2;AtiEuclid ExtravBp是優勢函數的截斷版。
4 實驗評估
本文模型在第1章描述的環境中進行訓練和測試。訓練時,每個問題實例中環境地圖的尺寸被隨機確定為10、25或40,障礙物的密度從0~0.5的三角分布中隨機采樣,峰值為0.33(與基線算法相同),且智能體個數固定為8。本文為測試設置了5種不同的地圖尺寸和智能體個數的組合:{[8,10],[16,20],[32,30],[64,40],[128,40]},前者是智能體個數,并將每種組合的障礙物密度固定為0、0.15和0.3(DHC[23]和PICO[25]的最高測試密度)。為每種組合的每個障礙物密度各隨機生成100個問題實例,總共在100×3×5=1500個問題實例上進行了實驗評估。除非特別說明,在訓練和測試階段FOV的大小均被設置為3×3。
本文使用PyTorch 1.11.0編寫代碼,Python版本為3.7。全部實驗在配備有兩個NVIDIA GeForce RTX 4090 GPUs和一個Intel Xeon Gold 6133 CPU @ 2.50 GHz(80核,160線程)的服務器上運行,系統環境為Ubuntu 20.04。
4.1 與基線求解器比較
本文測試了DICRIA與基線求解器SCRIMP在EL、CR和SR三項指標上的性能。其中:EL表示求解一個問題實例所消耗的時間步數(最晚到達目標的智能體的路徑長度);CR表示與包括地圖邊界的靜態障礙物的沖突率,計算方式為式(5);SR表示成功求解(所有智能體均在時限內到達目標)的實例在全部測試實例中的占比,衡量在給定時限內完成MAPF任務的能力。EL和CR越小代表策略越好,SR越大越好。SCRIMP的FOV大小設置為其原工作中的3×3,與本文設置相同。
CR=沖突數EL×智能體數×100%(5)
表2展示了在各項指標上的比較結果。在不同環境配置中,智能體個數在8、16、32、64和128之間變動;地圖大小在10~40變動;障礙物密度在0、0.15和0.3之間變動。所有數據均為相應環境配置下隨機生成的100個問題實例上測試結果的平均值。表中,EL的計算排除了求解失敗的情況(超過256個時間步);“—”表示無有效結果。每種環境配置下,各項指標最好的結果以粗體顯示。
如表2所示,在EL和SR這兩項指標上,DICRIA在所有情況下均優于SCRIMP。在其無法解決的環境配置下,DICRIA仍然具有相當的成功率。尤其在地圖大小為40×40,障礙物密度為0.15,包含128個智能體的密集型實例下,本文求解器的成功率是91%,而SCRIMP僅為2%,DICRIA的成功率相比SCRIMP甚至提高了44.5%。在地圖尺寸(40×40)和智能體個數(128)保持不變時,將障礙物的密度從0.15增加到0.3,SCRIMP將無法完成任何任務,成功率為0%,而DICRIA仍然具有34%的成功率。這主要是因為SCRIMP采用全局通信機制,無論距離遠近,無論是否相關,每個智能體都會與環境中的所有其他智能體進行通信,而這顯然會聚合大量冗余信息。雖然其通信機制中的可學習權重能夠區分信息的重要性,在一定程度上緩解這一問題,但在全局通信所引入的大量無關信息面前,這一點補救措施所起的作用十分有限。尤其在此密集型的問題實例下,SCRIMP全局通信機制的缺陷更是加倍體現了出來,最終導致了0%成功率這一糟糕的結果。與之相反,全局通信的劣勢正是本文新通信機制的優勢所在。DIC在局部FOV內篩選通信對象,只與實際相關的干擾者鄰居交換信息。不僅從距離上摒除了“遠房親戚”無關信息的干擾,而且還會對近鄰是否影響自身決策作進一步的判斷,故而能夠有效過濾冗余信息,并以顯著的優勢超越全局通信機制,獲得可觀的成功率。統計結果顯示,本文成功將基線求解器的SR平均提高了5.2%。
在CR方面,DICRIA在絕大多數情況下優于SCRIMP,但在[128,40,0.15]和[128,40,0.3]的環境配置下略高于SCRIMP的CR值。造成這種情況的一個可能的原因是,在密集型環境中,大量智能體試圖搶占有限的可移動的位置節點,導致彼此的決策具有較強的相關性,SCRIMP通過全局通信而引入的更完備的信息將更有利于智能體在此環境下進行全局范圍內的協調,而DICRIA基于局部FOV的通信機制卻不可避免地具有一定程度上的局部最優性問題。但這種差異僅在個別情況下存在,且微乎其微,并不影響最終的成功率。
4.2 與其他MAPF求解器比較
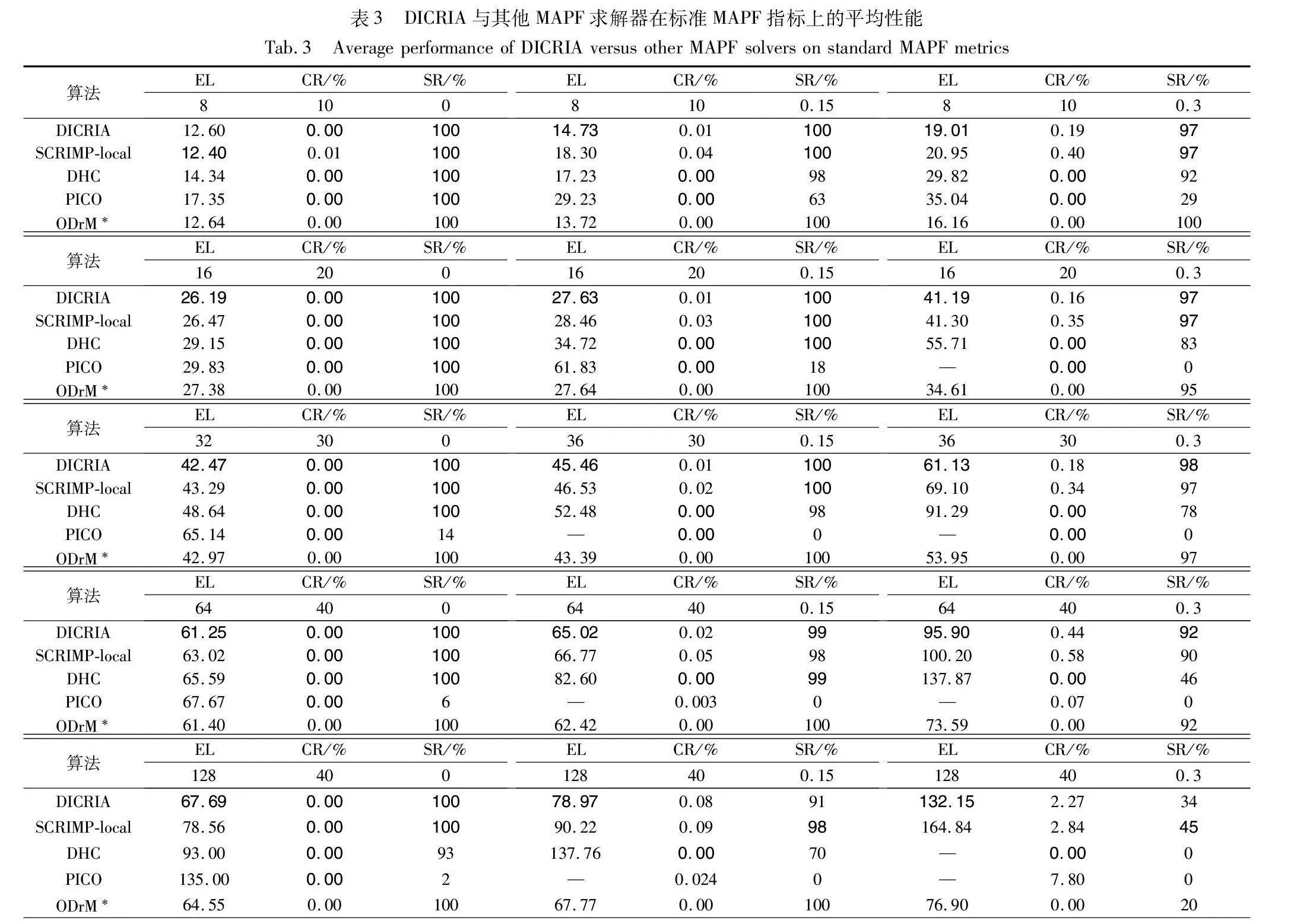
本文將DICRIA與其他先進的基于學習的MAPF求解器進行了比較,包括DHC[23]、PICO[25]以及SCRIMP-local[26]。其中,DHC和PICO的實現來自各自的文獻,且FOV的大小均保留其工作中的原始設置,分別為9×9和11×11。SCRIMP-local是本文通過限制通信范圍得到的SCRIMP的擴展版本,規定只與歐氏距離不超過5的鄰居進行通信,其FOV大小同SCRIMP,為3×3。此外,本文還額外測試了傳統集中式算法ODrM*[6],作為性能參考。
表3顯示了在不同環境配置的問題實例下,不同算法的三項標準MAPF指標的平均性能。與表2相同,EL的計算排除了求解失敗的情況(基于學習的方法超過256個時間步,ODrM*超過5 min未完成求解);“—”表示無有效結果。除了ODrM*,其他算法在各項指標上的最好結果以粗體顯示。總體而言,DICRIA幾乎在所有情況下都具有最低的EL值,這意味著相比其他求解器,DICRIA獲得了路徑最短即質量最高的解。
關于CR,DICRIA的CR始終低于SCRIMP-local,但大多數情況下還是高于DHC和PICO的。這可能是因為本文的內在獎勵設置鼓勵智能體探索新的區域,在此過程中遇到障礙的可能性會不可避免地增加。相比之下,DHC和PICO傾向于讓智能體留在熟悉的區域,以此逃避探索未知可能帶來的懲罰,因為長期停留在安全區會具有更低的CR值。然而,在成功率上DICRIA完勝DHC與PICO。尤其當智能體增加到32個以上,環境規模擴大到30×30時,DHC與PICO表現出了明顯的性能下降,PICO幾乎無法完成任何實例的求解。
本文注意到在[128,40,0.15]和[128,40,0.3]的環境配置下,DICRIA的SR低于SCRIMP-local。本文懷疑這是因為在密集型環境中,由于智能體決策的強相關性,個體的決策對更遠處的其他智能體仍會造成影響。DICRIA依靠3×3的FOV范圍來篩選通信對象,可能并沒有覆蓋到全部潛在的干擾者,所能獲取到的信息量在該情況下也顯得不夠充分,不足以支持智能體學會良好的配合。而SCRIMP-local由于額外設置了更大的通信范圍(歐氏距離不超過5),更能滿足密集環境下的通信需求,又因為減輕了原版SCRIMP全局通信冗余的問題,從而獲得了更高的成功率。在第4.3節中,當FOV的大小調整為5×5時,在同樣的環境配置(128個智能體,地圖大小40×40,障礙物密度0.15和0.3)下, DICRIA的SR分別為99%和55%,均超越了SCRIMP-local(98%和45%),驗證了這一猜想。
此外,DICRIA在大多數情況下與傳統算法ODrM*具有相似的性能。特別是在需要智能體高度協作的最困難任務中(128個智能體,地圖大小40×40,障礙物密度0.3),DICRIA的成功率(34%)明顯超越了ODrM*(20%)。
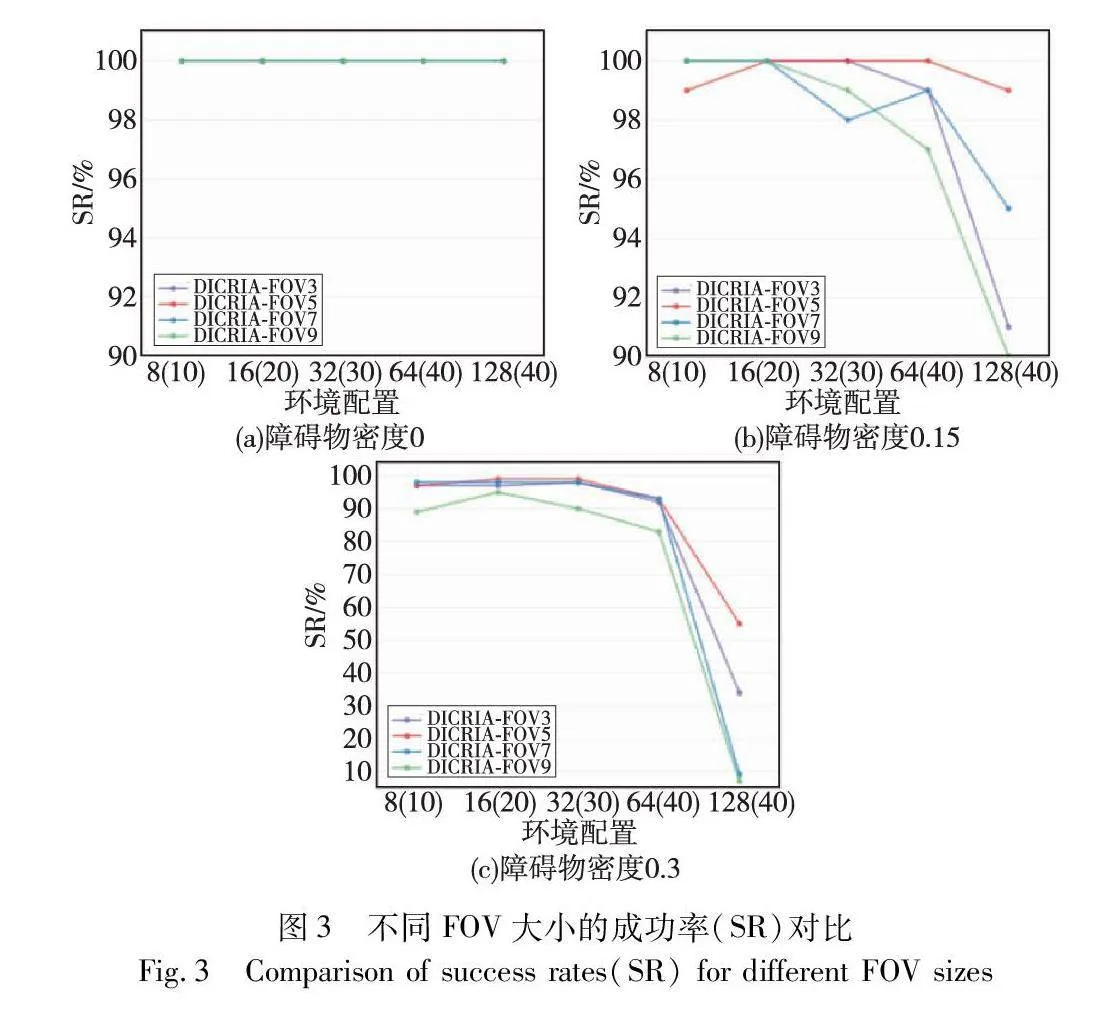
4.3 FOV大小的影響
本文進一步測試了不同FOV的大小對模型性能的影響。根據測試結果發現,相較于SR,改變FOV的大小對EL和CR的影響并不明顯,因此圖3只展示了在SR上的對比結果。圖中,8、16、32、64、128是智能體個數,括號中為對應的環境地圖的尺寸。圖3(a)~(c)分別是障礙物密度為0、0.15和0.3時的結果。如圖3所示,當FOV的大小為5×5時,DICRIA實現了最佳性能。值得注意的是,隨著FOV尺寸的增大,訓練和測試時間也明顯增長,因此需要在模型性能與時間成本之間有所權衡。
4.4 通信的消融
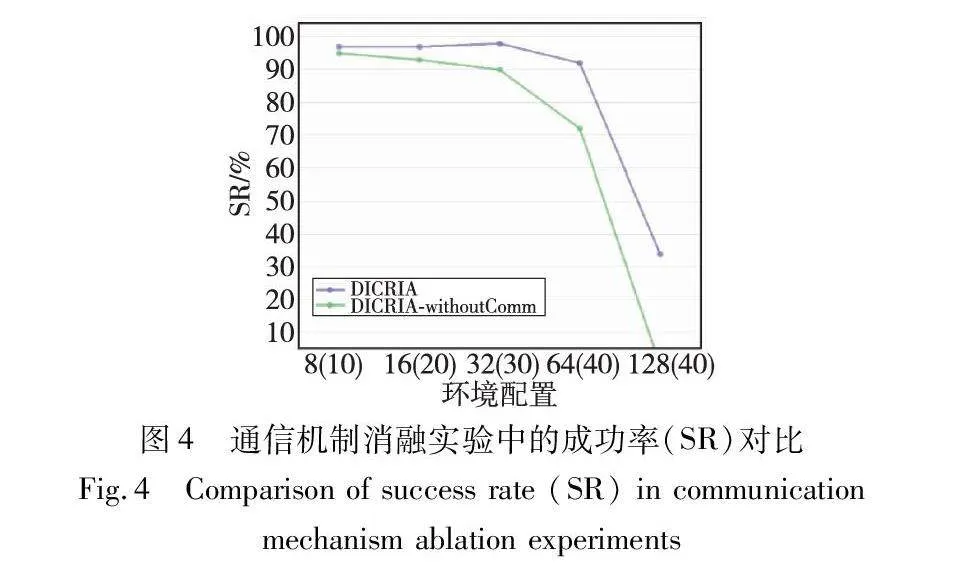
為了驗證本文通信機制的有效性,通過完全刪除干擾者鑒別器及通信模塊,開發了DICRIA的無通信版本——DICRIA-withoutComm。同時為了提高訓練和評估的速度,仍然將FOV的大小設置為3×3(與訓練原始DICRIA的設置相同),而不是采用在第4.3節確定的性能最佳的5×5。圖4只展示在對比最明顯且最重要的指標SR上的結果。障礙物密度固定為0.3。顯然,在智能體分布較密集的大型環境中,DICRIA-withoutComm表現出了性能的急劇下降,該結果充分證明了DIC的有效性。
5 結束語
在基于RL或IL的MAPF求解方案中引入通信的學習被證明是一種有效的方法,可以解決部分可觀測性下完全去中心化規劃導致的可用信息量受限的問題。本文考慮到現有基于學習的MAPF求解器通信方法的局限性,提出干擾者鑒別通信機制DIC。DIC憑借由干擾者鑒別器根據原始局部觀測與掩蔽局部觀測求得的決策差異來識別FOV內的干擾者,通過排除非干擾者的簡潔通信過程而有效過濾掉了不相關的信息,避免了通信冗余。本文又進一步實例化了DIC,開發了一種新的基于強化和模仿學習的MAPF求解器:DICRIA,既保留了DIC能夠實現高效通信的優點,還具有較高的可擴展性。在一系列具有不同環境配置的問題實例上的實驗結果表明,DICRIA在三項標準MAPF指標上的性能普遍優于其他最先進的同類求解器。幾乎在所有環境配置中,本文模型具有比基線求解器及其擴展版本更低的CR值。這說明通過篩選和收集相關的、實際有影響力的干擾者的信息進行通信,DICRIA有效加強了智能體間的合作,使得它們能夠以更協調的方式完成任務。本文還成功地將基線求解器的SR平均提高了5.2%。特別在大尺寸地圖的密集型問題實例下,DICRIA的成功率相比基線求解器,提升高達44.5%。此外,對通信機制的消融實驗充分證明了DIC的有效性。
最后,需要說明的一點是,雖然本文的干擾者鑒別通信機制給模型帶來了實際的性能提升,且具有諸多上述優點,但干擾者鑒別器篩選通信對象、過濾冗余信息的過程也將產生額外的計算成本。將在未來的工作中,探尋能夠更好地平衡成本與性能的優化方案。
參考文獻:
[1]Choudhury S, Solovery K, Kochenderfer M,et al. Coordinated multi-agent pathfinding for drones and trucks over road networks[C]//Proc of the 21st International Conference on Autonomous Agents and Multiagent Systems. London: AAMAS Press, 2022: 272-280.
[2]Mohanty S, Nygren E, Laurent F, et al. Flatland-RL: multi-agent reinforcement learning on trains[EB/OL]. (2020-12-11). https://arxiv.org/abs/2012.05893.
[3]Cartucho J, Ventura R, Veloso M. Robust object recognition through symbiotic deep learning in mobile robots[C]//Proc of IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, NJ: IEEE Press, 2018: 2336-2341.
[4]Ferguson D, Likhachev M, Stentz A. A guide to heuristic-based path planning[C]//Proc of International Workshop on Planningunder Uncertainty for Autonomous Systems: International Conference on Automated Planning and Scheduling. Palo Alto, CA: AAAI Press, 2005: 9-18.
[5]Standley T. Finding optimal solutions to cooperative pathfinding problems[C]//Proc of the 24th AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press, 2010: 173-178.
[6]Wagner G, Choset H. Subdimensional expansion for multirobot path planning[J]. Artificial Intelligence, 2015, 219(2): 1-24.
[7]Ren Zhongqiang, Rathinam S, Likhachev M, et al. Enhanced multi-objective A* using balanced binary search trees[C]// Proc of the 15th International Symposium on Combinatorial Search. Palo Alto, CA: AAAI Press, 2022: 162-170.
[8]Ren Zhongqiang, Rathinam S, Choset H. Loosely synchronized search for multi-agent path finding with asynchronous actions[C]//Proc of IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway, NJ: IEEE Press, 2021: 9714-9719.
[9]Sharon G, Stern R, Felner A,et al. Conflict-based search for optimal multi-agent pathfinding[J]. Artificial Intelligence, 2015, 219(2): 40-66.
[10]Barer M, Sharon G, Stern R,et al. Suboptimal variants of the conflict-based search algorithm for the multi-agent pathfinding problem[C]//Proc of the 21st European Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2014: 961-962.
[11]Rahman M, Alam M A, Islam M M,et al. An adaptive agent-specific sub-optimal bounding approach for multi-agent path finding[J]. IEEE Access, 2022, 10: 22226-22237.
[12]Li Jiaoyang, Ruml W, Koening S. EECBS: a bounded-suboptimal search for multi-agent path finding[C]//Proc of AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2021: 12353-12362.
[13]Andreychuk A, Yakovlev K, Surynek P,et al. Multi-agent pathfin-ding with continuous time[J]. Artificial Intelligence, 2022, 305: 103662.
[14]Shaaron G, Stern R, Goldenberg M,et al. The increasing cost tree search for optimal multi-agent pathfinding[J]. Artificial Intelligence, 2013, 195: 470-495.
[15]Walker T T, Sturtevant N R, Felner A. Extended increasing cost tree search for non-unit cost domains[C]//Proc of the 27th International Joint Conference on Artificial Intelligence.Palo Alto, CA: AAAI Press, 2018: 534-540.
[16]Walker T T, Sturtevant N R,Felner A, et al. Conflict-based increa-sing cost search[C]//Proc of the 31st International Conference on Automated Planning and Scheduling. Palo Alto, CA: AAAI Press, 2021: 385-395.
[17]Yu Jingjin, LaValle S M. Planning optimal paths for multiple robots on graphs[C]//Proc of International Conference on Robotics and Automation.Piscataway, NJ: IEEE Press, 2013: 3612-3617.
[18]Surynek P, Felner A, Stern R,et al. Efficient SAT approach to multi-agent path finding under the sum of costs objective[C]//Proc of the 22nd European Conference on Artificial Intelligence. [S.l.]: IOS Press, 2016: 810-818.
[19]劉志飛, 曹雷, 賴俊, 等. 多智能體路徑規劃綜述[J]. 計算機工程與應用, 2022, 58(20): 43-62. (Liu Zhifei, Cao Lei, Lai Jun, et al. Summary of multi-agent path planning[J]. Computer Engineering and Applications, 2022, 58(20): 43-62.)
[20]Sartoretti G, Kerr J, Shi Yunfei, et al. PRIMAL: pathfinding via reinforcement and imitation multi-agent learning[J]. IEEE Robotics and Automation Letters, 2019,4(3): 2378-2385.
[21]Lin Chen, Wang Yaonan, Yang Mo,et al. Multi-agent path finding using deep reinforcement learning coupled with hot supervision con-trastive loss[J]. IEEE Trans on Industrial Electronics, 2023, 70(7): 7032-7040.
[22]Li Qingbiao, Lin Weizhe, Liu Zhe,et al. Message-aware graph attention networks for large-scale multi-robot path planning[J]. IEEE Robotics and Automation Letters, 2021, 6(3): 5533-5540.
[23]Ma Ziyuan, Luo Yudong, Ma Hang. Distributed heuristic multi-agent path finding with communication[C]//Proc of IEEE International Conference on Robotics and Automation. Piscataway, NJ: IEEE Press, 2021: 8699-8705.
[24]Ma Ziyuan, Luo Yudong, Pan Jia. Learning selective communication for multi-agent path finding[J]. IEEE Robotics and Automation Letters, 2021,7(2): 1455-1462.
[25]Li Wenhao, Chen Hongjun, Jin Bo,et al. Multi-agent path finding with prioritized communication learning[C]//Proc of International Conference on Robotics and Automation. Piscataway, NJ: IEEE Press, 2022: 10695-10701.
[26]Wang Yutong, Xiang Bairan, Huang Shinan,et al. SCRIMP: scalable communication for reinforcement and imitation learning based multi-agent pathfinding[C]//Proc of International Conference on Autonomous Agents and Multiagent Systems. London: AAMAS Press, 2023: 2598-2600.
[27]Stern R, Sturtevant N, Felner A,et al. Multi-agent pathfinding: definitions, variants, and benchmarks[C]//Proc of the 12th Annual Symposium on Combinatorial Search. Palo Alto, CA: AAAI Press, 2019: 151-159.
[28]Ding Ziluo, Huang Tiejun, Lu Zongqing. Learning individually inferred communication for multi-agent cooperation[C]//Proc of the 34th Annual Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2020: 22069-22079.
[29]Vaswani A, Shazeer N, Parmar N,et al. Attention is all you need[C]//Proc of the 31st International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2017: 5998-6008.
