基于解糾纏表示學習的人臉反欺騙算法
2024-08-15 00:00:00周毅巖石亮張遨岳曉宇
計算機應用研究 2024年8期











摘 要:針對現有人臉反欺騙模型面對不同應用場景識別精度低、泛化性能不佳的問題,引入解糾纏表示學習,提出一種基于解糾纏表示學習的人臉反欺騙方法。該方法采用U-Net架構和ResNet-18作為編/解碼器。首階段訓練中,通過輸入真實樣本使得編碼器僅學習到真實樣本相關信息。第二階段,構建對抗性學習網絡,輸入不具標簽的樣本,將預訓練的編碼器輸出和新編碼器輸出進行特征融合,由解碼器重建圖像,在鑒別器中與原始圖像進行對抗訓練,以實現特征的解耦。模型與一些經典人臉反欺騙方法相比,有著更好的檢測性能,在OULU-NPU數據集的數個實驗中,最低的檢測錯誤率僅為0.8%,表現優于STDN等經典檢測方法。該人臉反欺騙方法通過分階段訓練的方式,使得模型在對抗性訓練中獲得了相比端到端模型更具判別性的特征表示,在欺騙特征圖輸出階段采用多分類策略,減小了不同的圖像噪聲對分類結果的影響,在公開數據集上的實驗驗證了算法的有效性。
關鍵詞:人臉反欺騙; 解糾纏表示學習; 多分類; 域泛化
中圖分類號:TP311 文獻標志碼:A
文章編號:1001-3695(2024)08-036-2502-06
doi:10.19734/j.issn.1001-3695.2023.11.0554
Face anti-spoofing algorithm based on disentangled representation learning
Zhou Yiyan, Shi Liang, Zhang Ao, Yue Xiaoyu
(School of Computer Science, Jiangsu University of Science & Technology, Zhenjiang Jiangsu 212114,China)
Abstract:To solve the problems of low recognition accuracy and poor generalization performance of existing face anti-spoofing models in different application scenarios, this paper adopted the idea of disentangled representation learning and proposed a face anti-spoofing method based on disentangled representation learning. This method adopted U-Net architecture and ResNet-18 as the encoder-decoder. In the first stage of training,it inputted real samples so that the encoder only learned information related to real samples. In the second stage, this paper built an adversarial learning network, inputted samples without labels, feature fusion of the pre-trained encoder output and the new encoder output, reconstructed the image by the decoder, and performed adversarial training with the original image in the discriminator to achieve feature decoupling. Compared with some classic face anti-spoofing methods, the model paper achieved better detection performance. The lowest detection error rate in several experiments on the OULU-NPU data set is only 0.8%, which is better than classic detection methods such as STDN. The face anti-spoofing method used staged training to enable the model to obtain a more discriminative feature representation than the end-to-end model in adversarial training. It adopted a multi-classification strategy in the deception feature map output stage to reduce the impact of different image noises on classification results, and experiments on public data sets verified the effectiveness of the algorithm.
Key words:face anti-spoofing; disentangled representation learning; multiclass classification; domain generalization
0 引言
隨著人臉識別技術在各行各業中被廣泛應用,如何防止人臉識別系統被偽造的圖像攻擊[1]得到了業界的廣泛關注。對人臉識別系統的攻擊類型通常包括打印人臉圖像、播放視頻回放、佩戴成本更高的3D面具。為了解決上述手段對人臉識別系統的攻擊,許多人臉反欺騙方法應運而生,主要包括了傳統機器學習方法和基于深度學習的方法[2]。傳統的機器學習方法利用局部特征提取方式,如LBP(local binary pattern)[3]、HOG(histogram of oriented gradient)[4]提取的手工特征作為圖像的特征紋理,并使用支持向量機等經典分類器進行二元分類。基于動態特征的人臉反欺騙方法使用諸如眨眼[5]、嘴巴運動和頭部運動[6]等動態線索來檢測打印欺騙攻擊。但基于動態特征的人臉反欺騙方法在面對面具剪洞或者化妝等攻擊類型時很容易失效。傳統機器學習的方法無法應對越來越多樣的攻擊類型。
隨著深度學習的發展,許多研究引入了神經網絡作為特征提取工具,并將基于深度學習方法的人臉反欺騙簡述為二元分類問題[7]。Yang等人[8]利用 LSTM(long short term memory),將時間信息作為輔助監督,使用SASM(spatial anti-spoofing module)模塊提取不同的維度特征,獲得了不錯的效果。Yu等人[9]構建的中心差分卷積網絡在卷積算子上作出創新,網絡對提取欺騙人臉樣本特征取得了很大成效。劉偉等人[10]將CNN(convolutional neural network,CNN)與LBP和多層離散余弦相融合,先將圖像進行LBP和多層DCT(discrete cosine transform)處理,再經過CNN提取特征圖像并分類。深度學習方法對比機器學習方法在性能方面具有優越性,但上述方法在面對同一數據庫時識別率通常較好,面對跨數據集測試時則表現出較大的不穩定性。為了有效地學習更具有判別性的特征,研究人員還采用了輔助監督的方法,如深度信息[11]、反射方法[12]。Liu等人[13]建立了CNN-RNN(convolutional neural networks-recurrent neutral network)框架,利用深度圖和rPPG(remote photoplethysmography)信號進行輔助監督。文獻[14] 將欺騙人臉分解為欺騙噪聲和真實人臉信息,利用噪聲作分類。輔助監督方法有助于提取更具判別性的特征,但人臉反欺騙模型性能還取決于具有一致目標的輔助監督任務。此外,現有的輔助信息可能不適合所有的攻擊類型。在研究中,不可能定義所有輔助信息來對人臉反欺騙模型進行訓練,其關鍵是使模型學習真實人臉和偽造人臉的區分本質,以避免網絡對訓練數據的過度擬合。解糾纏表示學習是將模型的潛在表示分離為可解釋部分的有效方法,進一步提高了模型的魯棒性。例如文獻[15,16]通過融合端到端架構中的特征,使用對抗性訓練來獲得解糾纏表示。文獻[17] 構建了CSM-GAN(covered style minin-generative adversarial network)框架,設置風格生成器和對抗性風格鑒別器形成生成對抗性網絡,利用風格轉移技術實現人臉反欺騙。Zhou等人[18]提出一種域自適應生成對抗式網絡,通過域內頻譜混合來擴展目標數據分布,減少了域內差距。這類依靠生成對抗網絡的方法,普遍對生成器和鑒別器存在很大程度依賴,其生成器鑒別器的穩定性將在很大程度上影響獲取解纏的特征表示效果。
針對上述問題,本文提出了一種解糾纏表示學習的人臉反欺騙算法;采用分階段訓練的方式使得編碼器在一階段學習到真實樣本特征,從而使得模型在后續的對抗性訓練中保持足夠的穩定性;輸入不具有標簽的圖像,經過解碼器的圖像重建后,構建對抗性訓練使得模型獲得具有判別性的解糾纏特征表示;在欺騙特征圖輸出階段,采用多分類策略,弱化環境多樣性的影響,使得模型識別率進一步上升。
1 相關工作
1.1 解糾纏表示學習
解糾纏表示學習是一種無監督的學習方法,核心思想是將模型提取的圖像特征進行進一步分離,使得深度學習模型學習到對于人臉反欺騙任務更為有效的判別性特征。基于對抗性的解糾纏表示學習網絡如圖1所示,編碼器、生成器和鑒別器構成網絡主干。編碼器網絡輸出特定的特征表示,并作為生成器的輸入,生成器生成與輸入具有一致風格的圖像。編碼器和內容鑒別器的任務具有一致性,得到風格鑒別器輸出后,進行極大化或者極小化優化,使得鑒別器(風格)和編碼器進行對抗性學習。根據風格鑒別器與輸入圖像的標簽的匹配,進行生成器的訓練,以生成對應風格的圖像。為了學習分離耦合特征,將生成對抗式訓練和解糾纏表示學習進行組合。因此,網絡目的是對耦合特征表示的對抗訓練。網絡融合了不同風格圖像,使得所獲得的特征表示對合成保留內容的圖像具有包容性,而且對風格變化具有排斥性,這種對耦合的特征表示進行分離的對抗性訓練有利于提升模型的分類性能 [19]。
1.2 多分類研究
由于攻擊媒介的多樣性,導致了模型在學習不同攻擊類型時存在不同模式的圖像噪聲。打印樣本圖像由于打印設備與紙張材質問題,通常出現顏色不均、人臉面部細節丟失;因為播放設備的影響,重放視頻攻擊樣本通常出現摩爾紋,偶有反光、過度曝光現象。真實人臉圖像呈現的色彩均衡、細節清晰; OULU-NPU數據集的真實人臉、打印人臉、重放人臉三種樣本類型由圖2展示。由圖可見,三種類型樣本如上所述,出現相對應的差異 [20]。
2 算法
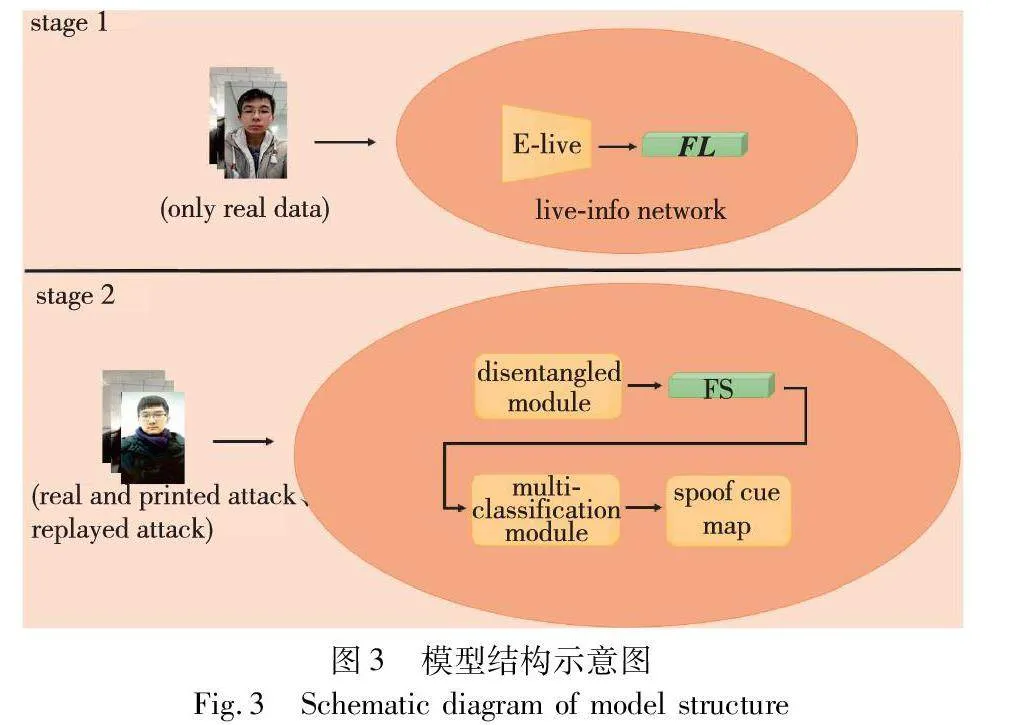
本文假設每個欺騙樣本都由其對應的真實信息和相關欺騙信息所組成。真實圖像和欺騙圖像的真實信息部分是相關聯的,獲得具有判別性的解耦特征是模型區分欺騙樣本的關鍵。為了獲得具有顯著區分性的特征表示,本文提出了一種基于解糾纏表示學習的人臉反欺騙算法。模型結構如圖3所示。
在第一階段訓練中,真實信息網絡僅僅學習到與真實樣本相關的特征信息。本文E-live為基于U-Net[13]框架Encoder編碼器,真實樣本經過E-live編碼器編碼后輸出特征表示FL, FL∈Euclid ExtraaBp512,FL僅與真實樣本相關。在第二階段訓練中,解糾纏模塊(disentangled module)采用第一階段預訓練的E-live作為固定的編碼器,采用對抗學習的方式對提取解糾纏進行特征表示,解糾纏模塊輸出特征表示FS,FS∈Euclid ExtraaBp512,FS作為輸入在多分類模塊(multi-classification module)中再次進行處理,得到兩種類型的欺騙特征圖,并利用特征圖進行分類決策。
2.1 預訓練
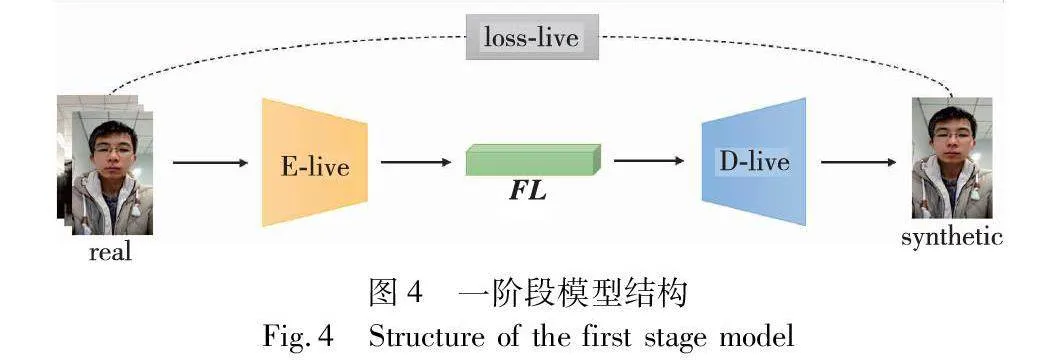
在第一階段,只輸入真實樣本,使得Encoder-Decoder模型只學習到真實樣本的特征參數,編碼器E-live與D-live是自動編碼解碼器,輸入真實樣本后,經過編碼器E-live,輸出特征表示FL,FL經過解碼器進行解碼得到重建圖像。這一訓練階段使用Loss MAE(mean absolute error,MAE)函數約束模型提取真實特征、重建真實人臉圖像。圖4為一階段模型結構圖。
圖中real代表輸入的真實樣本數據,synthetic為解碼器輸出的重建圖像,FL代表圖像經過編碼器編碼后的特征表示。本階段主要用于獲取E-live模塊在訓練中得到的權重參數。
設X表示真實樣本訓練數據,D為D-live解碼器。真實特征網絡可以產生輸出syn=D-live(E-live(X))。損失函數為
Lr=EX~PX(syn-X)(1)
其中:syn為合成樣本;X為真實樣本。
該模型只從真實樣本中學習信息,所以得到的權重參數只與真實樣本相關,經Encoder提取的所有特征都看做是真實特征。
2.2 解糾纏表示學習
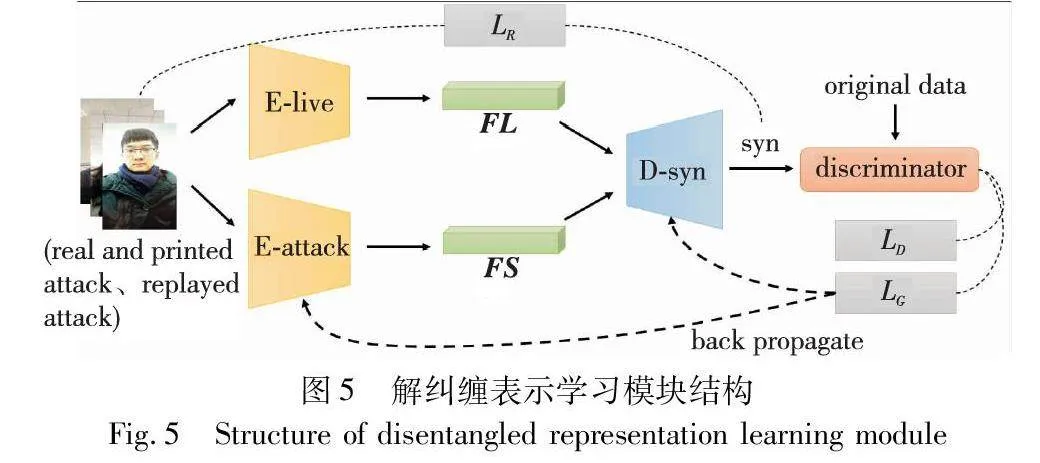
在第二階段,使用真實樣本、打印攻擊樣本和重放攻擊樣本作為訓練數據。分別采用編碼器E-attack與E-live對訓練樣本進行編碼,E-live在第一階段訓練完畢,沒有學習到關于欺騙圖像的任何信息,可以專注于提取與攻擊樣本具有共性的、可被識別為真實樣本的特征。圖5為解糾纏表示學習模塊。
特征表示FL為E-live所編碼的特征向量,使用Element-wise Addition方法合并兩種特征表6dad9d51343e7064e7f47c0753a2f9570095b2ce24dffcffd85679b9a7002ac5示FL與FS。E-attack與D-syn分別為基于U-Net[13]框架的編碼器與解碼器。D-syn接收合成的特征表示進行解碼,輸出合成圖像Syn,Syn與原始數據經過鑒別器D(discriminator)進行對抗學習,使得E-attack提取更具欺騙性的特征表示FS。
實驗使用回歸損失LR和生成對抗式損失函數來約束與原始數據X相似的輸出Syn。本文將生成的數據Syn和原始數據X作為鑒別器D的輸入,它將對輸入樣本進行鑒別。通過上述過程,從而將具有區分性的欺騙特征從無關特征中剝離提取。
LGen=EX~PX[(D(Syn)-1)2](2)
LDis=EX~PX[(D(X)-1)2]+EX~PX[(D(Syn)2](3)
損失函數LR由下式給出:
LR=EX~PXSyn-X22 (4)
2.3 多分類的欺騙特征圖輸出
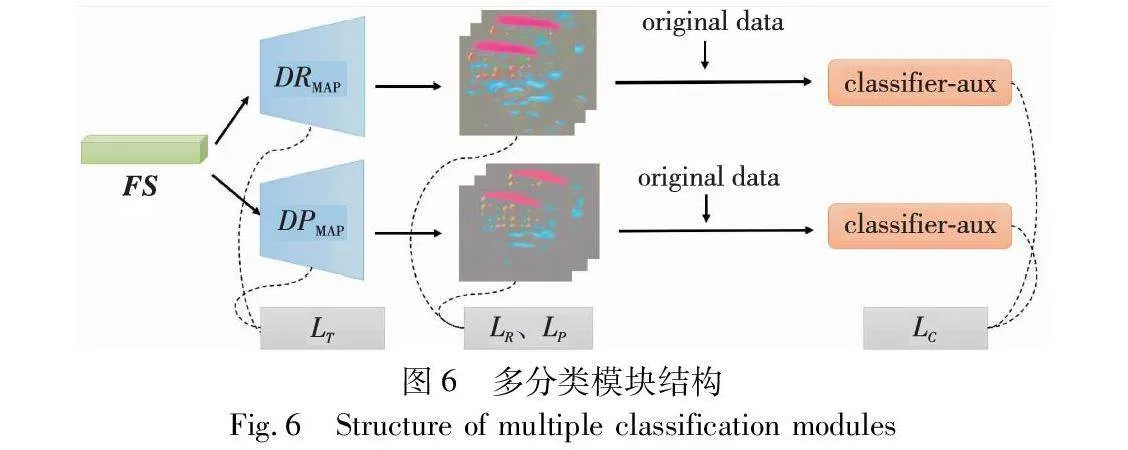
在欺騙特征提取模塊中,將解糾纏模塊中經過解糾纏處理的欺騙特征作為解碼器DPMAP與DRMAP的輸入來生成不同類別的欺騙特征映射。圖6為多分類模塊結構。
解糾纏過程中編碼器E-attack經過類似生成對抗式學習后,所編碼的特征表示FS更具有欺騙性,用FS作為輸入,使用雙解碼器DRMAP與DPMAP進行解碼,分別獲得打印欺騙特征圖與重放欺騙特征圖。Classifier-aux作為二元分類器,分別輸入欺騙特征圖疊加原始數據。分類器僅對解碼過程起輔助監督作用。
損失函數LT用于最小化真實人臉圖像的欺騙映射,并將真實數據和欺騙數據耦合的特征分開,將更能區分攻擊樣本的欺騙特征剝離出來。本文在解碼器的最后三層中應用了損失函數LT。LT由兩部分組成:
LT=LH+LN(5)
其中:損失LN計算所有有效三元組的三元組損失,并對正值的三元組進行平均化。
LN =1N∑Ni=1max(‖fai+fpi‖22-‖fai-fni‖22+α,0)(6)
其中:fai、fpi、fni分別表示第i三元組的錨樣本、正樣本和負樣本的特征向量;N表示三元組的數量;α是預設的邊距常量。本文選定真實樣本特征向量作為錨樣本。
在LH的計算中,對于每個fai,本文設置具有最大歐氏距離的一組(fai,fpi)作為正值。正樣本索引j選自L且j≠i,其中L表示當前批次中所有真實樣本的集合。對于每個fai,找出具有最小歐氏距離的一組(fai,fnk)為負值。欺騙樣本索引k選自N,N表示當前批次中所有欺騙樣本的集合。T表示三元組的數量。m是預定義的邊距常量。對于每個三元組(fai,fpi,fni),本文計算每個三元組的損失,然后取其平均值:
LH =1T∑Ti=1max(max‖fai-fpj‖22-min‖fai-fnk‖22+m,0)(7)
其中:j∈L,k∈N。經過DRMAP與DPMAP解碼后生成兩類型特征圖,分別命名為欺騙特征圖RMAP和PMAP,為使欺騙特征圖的類型得到區分,本文使用LP與LR來幫助訓練解碼器將特征分流,并在分流過后使用Lc利用鑒別器進行輔助訓練,目的在于增強區分性。本文使用損失函數LP與LR來使得欺騙特征得到分流:
LP=EX~PX‖RMAP-IPrint‖1(8)
LR=EX~PX‖RMAP-IReplay‖1(9)
其中:IPrint,IReplay為對應樣本標簽。Classifier-aux是一種二值分類器,用來輔助加強解碼器對真實樣本與欺騙樣本的區分性。本文將欺騙特征圖與原始數據重疊,與原始數據分別作為輔助分類器的輸入。分類器Classifier-aux的損失Lc由下式給出:
Lc = 1N∑Ni=1zi ln qi+(1-zi)ln qi(10)
其中:N是樣本數量;zi是二進制標簽;qi是分類器預測值。
2.4 訓練測試
加權計算上述損失函數的總和作為第二訓練階段的最終損失,由式(11)給出:
LR=λ1LLrecon+λ2LGen+λ3LT+λ4LR+λ5LP+λ6Lc(11)
其中:λ1、λ2、λ3、λ4和λ5是與上述損失函數相關聯的權重,在實驗中,它們的值分別被設置為4、1、3、3、3、4。訓練完成時,計算生成的RMAP與PMAP各自平均值作為欺騙分數,利用欺騙分數作三分類決策。在測試階段,將輸入測試數據得到的兩種分數與原有的兩種欺騙分數進行對比,差值較大的作為分類結果。在測試階段,需要使用編碼器E-attack和解碼器DPMAP與DRMAP。
2.5 網絡結構和實現細節
本文方法的編碼器和解碼器的基本結構框架如圖7所示,本文基于U-Net[21]架構進行了模型的設計。在預訓練階段,本文采用基于ResNet-18[21]的0~4層作為編碼器,接著進行下采樣。解碼器與編碼器結構對應,而對每一層的特征圖采用雙線性插值法上采樣,在解碼器的最后一層設置Tanh激活函數來獲得輸出圖像。在對抗性訓練階段,為了獲得判別性特征表示,對預訓練的編碼器停止更新參數。將兩編碼器輸出的特征表示進行合成,因為兩編碼器輸出相同規格的特征表示,考慮到后續重建圖像,選擇逐元素相加的方式將特征表示疊加。由于解碼器得到的是經過疊加的特征表示,需要對解碼器進行相應的調整,本文在與基本模型結構相同的基礎上,增加一次上采樣,使得解碼器輸出和原始圖像具有相同規格的合成圖像,進而通過鑒別器完成對抗性訓練。在欺騙特征圖獲取時,與基本模型結構相同,采用四個解碼塊組成的解碼器進行欺騙特征圖的輸出,在使用分類器輔助監督時,為了獲得更好的監督效果,采用相乘方式進行原始數據與特征圖疊加。
3 實驗設計與分析
3.1 數據庫
基于OULU-NPU和CASIA-FASD、Replay-Attack三種數據集,本文設計了一系列實驗對打印攻擊和重放攻擊兩種常見的欺詐人臉攻擊方式進行訓練和測試。
1)OULU-NPU數據集[22] 該數據集由芬蘭奧盧大學和中國西北工業大學研究人員共同創建,包括20個訓練集、20個測試集和15個驗證集。數據集共有4 950個視頻,這些視頻由不同的6種設備所拍攝。共設置了4種不同的光照背景條件,即跨光照環境實、跨攻擊制作設備實驗、跨數據采集設備實驗、跨所有條件實驗。圖8分別展示了真實樣本與打印攻擊樣本、重放視頻攻擊樣本三種類型。
2)CASIA-FASD 該數據集由Zhang等人[23]創建,其中包含20個訓練集和30個測試集,每個集合包含一個人的真臉和攻擊,共50個人。其中,每個人的集合中均包括3個不同光照、不同角度的真臉,以及彎曲攻擊、剪洞攻擊和視頻共9個攻擊。圖9展示了三種攻擊的示意圖。
3)Replay-Attack 該數據集是Chingovska等人[24]在2012年提出的。該數據集分為訓練集、驗證集和測試集,每種集合均包括真臉和攻擊。為了增加分類識別提高難度,本數據集的攻擊類型分為手持和固定。圖10為Replay-Attack樣本示意圖。
3.2 評價指標
本文選擇了五個常用的指標來評估FAS任務的性能:攻擊呈現分類錯誤率(attack presentation classification error rate,APCER)、真實分類錯誤率(bona fide presentation classification error rate,BPCER),平均分類錯誤率(average classification error rate,ACER)、等錯誤率(equal error rate,EER)、模型評價指標(area under curve,AUC)。上述指標除AUC外,其余數值越低,代表模型表現越優秀。AUC描述二分類器分類能力,X軸為FPR(false positive rate),Y軸為TPR(true positive rate)構成一條曲線下面積。即隨機選取正樣本和負樣本,正樣本預估概率大于負樣本預估概率的概率。AUC數值越大,說明模型性能越好。上述指標數值越低,說明網絡性能越好。
APCER=FPTN+FP,BPCER=FNFN+TP,APCER=APCER+BPCER2
其中:TP表示模型把正樣本預測為負樣本的數量;TN表示模型把正樣本預測為負樣本數量;FP為模型把負樣本預測為正樣本的數量;FN為模型把正樣本預測為負樣本的數量[18]。
3.3 實驗配置
本文首先對數據進行預處理,即視頻重采樣。本文對視頻進行圖像采樣,采樣率為每3幀保存一幅圖像。裁剪圖像使用Dlib[25]的人臉目標檢測算法來對每張圖像進行裁剪,將所有裁剪區域的大小都調整為224×224。最后,對數據集進行重采樣,以保持真實圖像和兩種攻擊圖像的比例為1∶1∶1。
訓練階段,采用Adam[26]作為優化算法,初始學習率為5E-4,訓練Batch大小為32。模型分為一個兩階段的訓練過程,本文在第一階段訓練了10個Epoch的真實樣本來獲取權重參數。在第二階段,將預先訓練好的編碼器E-live加載為固定的編碼器,以進一步訓練解纏模塊。對于訓練中所使用的數據集,解糾纏模塊的損失函數可以在大約10個Epoch之后收斂。
本文的實驗硬件為NVIDIA GeForce GTX 4060(8 GB),框架為基于Python 的PyTorch框架。
3.4 實驗結果
3.4.1 模塊間對比實驗
為了驗證解糾纏原理中假設圖像存在具有區分性的真實特征與欺騙特征,實驗在OULU-NPU數據集上采集樣本,通過t-SNE[27]提取真實特征FL和欺騙特征FS的特征分布并進行可視化,真實樣本和欺騙樣本的FL高度重疊,而相比之下,兩者的FS有明顯區別。可視化分布如表1所示。
其中,藍色表示真實樣本特征分布,紅色則表示欺騙樣本的特征分布(見電子版)。實驗對模型的兩個編碼器E-live和E-attack的輸出特征FL和FS進行特征分布的可視化,以證明本文的多分類解糾纏表示學習策略是合理的。本文采用OULU-NPU數據集,從測試集中隨機選擇1 000個真實樣本和1 000個欺騙類型樣本。如表1所示,由E-live所輸出的特征分布不具明顯界限,說明其提取到的特征不具有區分性,屬于欺騙無關特征。而由E-attack所輸出的顯示,其特征分布具有明顯界限,模型提取到了具有區分性的欺騙特征。
3.4.2 數據集內部測試
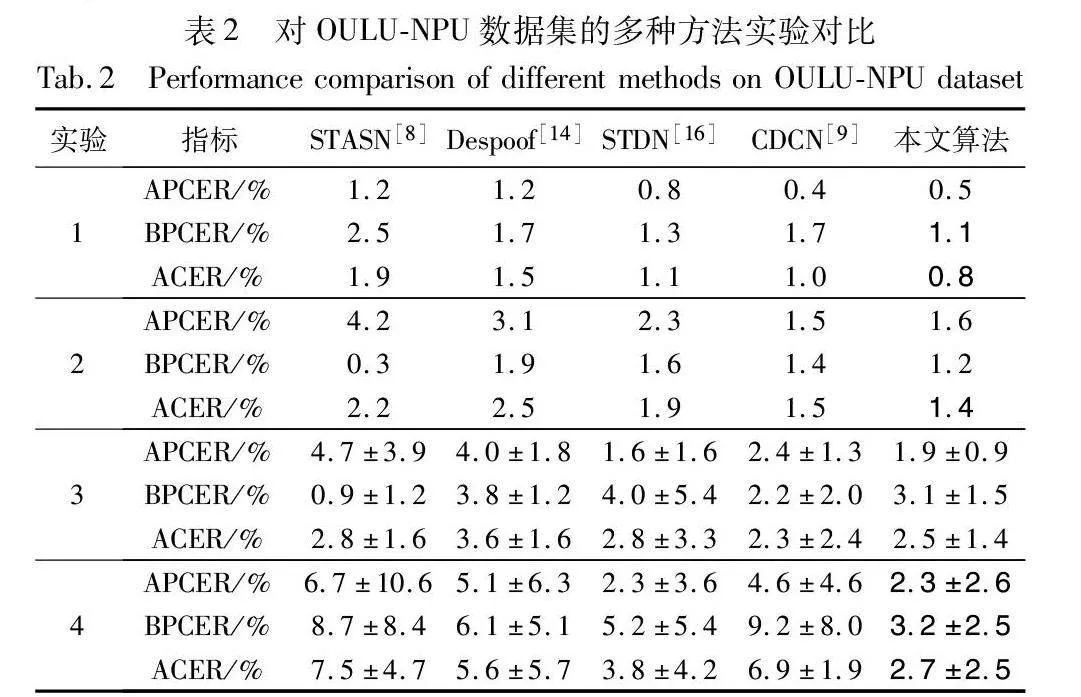
分別在OULU-NPU、CASIA-FASD和Replay-Attack數據集上進行數據集內部的訓練和測試,實驗結果如表2~4所示。采用基于解糾纏表示學習的人臉反欺騙方法在上述四種數據集的不同評價指標下,與其他的人臉反欺騙方法相比具有優越性。不同類型的欺騙樣本的特征信息存在明顯共性,采取多分類策略增加了解糾纏模型對不同欺詐樣本類型的關注度,提升了對打印樣本攻擊和視頻重放樣本攻擊的共性欺騙信息學習,深化了模型對欺騙特征的解耦程度,提升了檢測任務的識別率。
如表2所示,在OULU-NPU的數據集分別基于四個實驗條件與其他優秀方法進行了對比,其中粗體表示本文在該項獲得了最優結果。本文分別在跨所有條件實驗、跨攻擊制作設備實驗、跨光照環境實驗條件下獲得了最優結果。對比STDN方法,在實驗1中,本文方法APCER指標降低了0.3%,BPCER則下降了0.2%,說明本文采用分階段訓練、三元組函數輔助監督,有效地提升了模型性能。
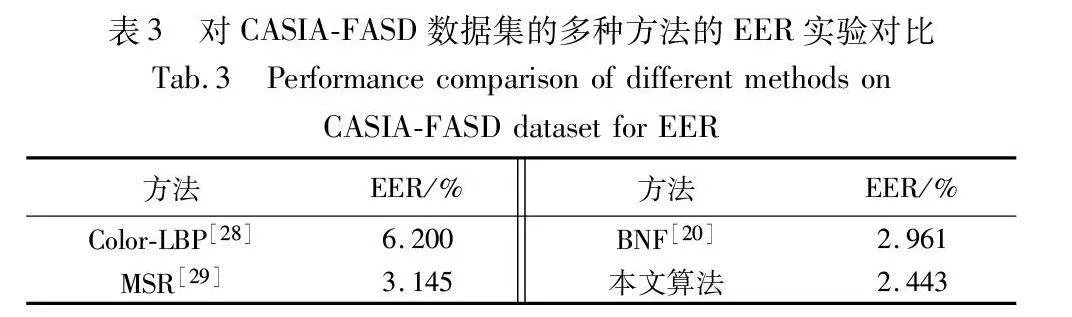
表3為本文方法與其他優秀人臉反欺騙方法在CASIA-FASD數據集的內部測試。在EER指標表現上,與BNF相比,其具有一定優勢。
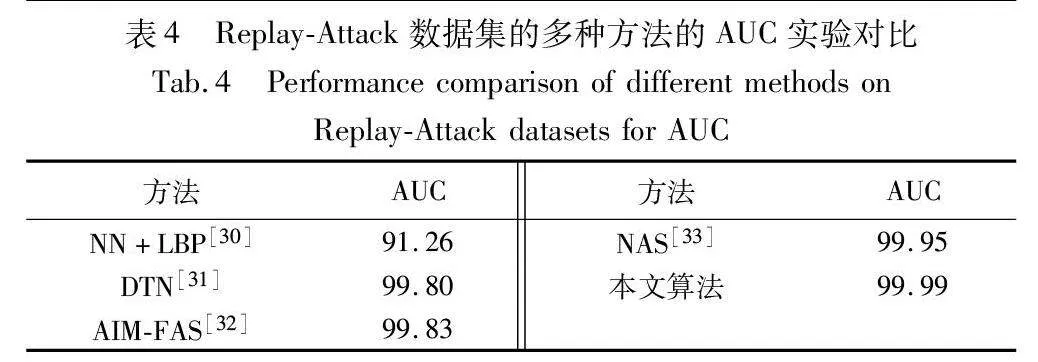
表4為基于解糾纏表示學習的人臉反欺騙方法與其他方法在Replay-Attack數據集上的AUC指標對比。由表可見,本文方法在AUC指標上表現優秀,獲得了99.99。相比其他方法,在Replay-Attack數據集上,基于解糾纏表示學習的人臉反欺騙方法表現更為優異。
3.4.3 跨數據集測試
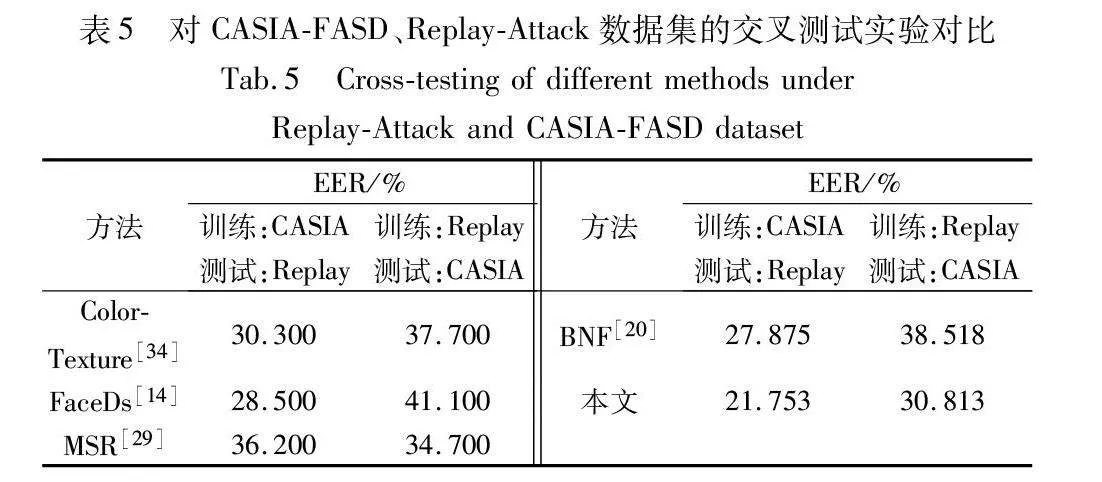
為了進一步研究基于解糾纏表示學習的人臉反欺騙方法的泛化能力,本文在CASIA-FASD、Replay-Attack數據集上設計了交叉訓練與測試,實驗結果如表5所示。可以看出,與其他方法相比,采用基于解糾纏表示學習的人臉反欺騙方法,模型泛化性能得到了改善。
表5為本文算法與其他近年來人臉反欺騙方法在CASIA-FASD、Replay-Attack數據集上進行的實驗結果對比與分析。經過在CASIA-FASD數據集訓練,在Replay-Attack數據集進行測試,實驗結果顯示,本文算法相比BNF的EER錯誤率有了一定下降,表明解糾纏表示學習方法相比其他不對特征進行解耦的算法,在魯棒性方面具有一定優勢;其次,安排測試集與訓練集進行交換,得出的實驗結果顯示,本文方法的EER錯誤率仍然最低。實驗結果證明了采取多分類策略的解糾纏表示學習方法的有效性。
3.5 消融實驗
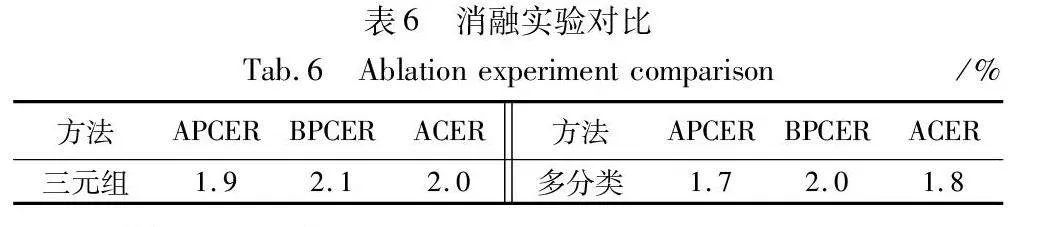
在OULU-NPU數據集基于跨光照環境條件下進行消融實驗, 分別為去除三元組損失輔助監督、 去除多分類進行實驗。
從表6可知,本文三元組函數約束對解糾纏表示學習過程起到推動作用,同時,多分類策略對模型欺騙特征圖輸出起到了一定的作用。
3.6 特征圖可視化
本文設置實驗對解碼器的輸出分別進行可視化,以描述具體如何檢測欺騙攻擊。實驗使用OULU-NPU數據集測試模型,生成的欺騙特征圖如圖11所示。
從圖11的真臉欺騙特征圖可以看出,對于真實人臉,網絡所輸出欺騙特征圖幾乎空白,對于打印攻擊和重放攻擊的特征圖,則出現了有明顯網絡重點關注的區域,意味著其欺騙系數較大。
4 結束語
本文提出了基于解糾纏表示學習的人臉反欺騙算法,通過對一般對抗性解糾纏學習表示網絡的改進,采取分階段訓練方式,使得模型在經過與真實人臉特征解耦的過程中穩定地獲得了更有效的判別性特征信息,深化了模型的解耦程度;多分類策略降低了環境因素對檢測任務造成的不利影響。經過對實驗結果進行對比與分析,驗證了基于解糾纏表示學習的人臉反欺騙算法的有效性。
參考文獻:
[1]張帆, 趙世坤, 袁操, 等. 人臉識別反欺詐研究進展[J]. 軟件學報, 2022, 33(7): 2411-2446. (Zhang Fan, Zhao Shikun, Yuan Cao, et al. Research progress of face recognition anti-spoofing[J]. Journal of Software, 2022, 33(7): 2411-2446.)
[2]盧子謙, 陸哲明, 沈馮立, 等. 人臉反欺詐活體檢測綜述[J]. 信息安全學報, 2020, 5(2): 18-27. (Lu Ziqian, Lu Zheming, Shen Fengli, et al. A survey of face anti-spoofing[J]. Journal of Information Security, 2020, 5(2): 18-27.)
[3]黃子軒. 基于混合紋理的人臉活體檢測算法設計與實現[D]. 武漢:華中科技大學, 2023. (Huang Zixuan. Design and implementation of face anti-spoofing algorithm based on mixed texture[D]. Wuhan: Huazhong University of Science and Technology, 2023.)
[4]劉航. 基于Haralick和HOG特征的人臉活體檢測[J]. 計算機與網絡, 2020, 46(15): 53. (Liu Hang. Face liveness detection based on Haralick and HOG features[J]. Computers and Networks, 2020, 46(15): 53.)
[5]郭華. 基于視頻的人臉活體檢測研究[D]. 北京:北方工業大學, 2021. (Guo Hua. Research on face anti-spoofing algorithm based on video[D]. Beijing: North China University of Technology, 2021.)
[6]Singh A K, Joshi P, Nandi G C. Face recognition with liveness detection using eye and mouth movement[C]//Proc of International Conference on Signal Propagation and Computer Technology. Pisca-taway, NJ: IEEE Press, 2014: 592-597.
[7]陳俊廷. 基于深度信息輔助監督的活體人臉檢測算法研究與應用[D]. 濟南:濟南大學, 2022. (Chen Junting. Research and application of face anti-spoofing algorithm with depth supervision[D]. Jinan :Jinan University, 2022.)
[8]Yang Xiao, Luo Wenhan, Bao Linchao, et al. Face anti-spoofing: model matters, so does data[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2019: 3502-3511.
[9]Yu Zitong, Qin Yunxiao, Li Xiaobai, et al. Multi-modal face anti-spoofing based on central difference networks[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway, NJ: IEEE Press, 2020: 2766-2774.
[10]劉偉, 章琬苓, 項世軍. 基于LBP-MDCT和CNN的人臉活體檢測算法[J]. 應用科學學報, 2019, 37(5): 609-617. (Liu Wei, Zhang Wanling, Xiang Shijun. Face anti-spoofing based on LBP-MDCT and CNN[J]. Journal of Applied Science, 2019, 37(5): 609-617.)
[11]高文龍. 基于圖像與深度信息融合的人臉識別研究[D]. 沈陽:東北大學, 2020. (Gao Wenlong. Face recognition based on image and depth information[D]. Shenyang: Northeastern University, 2020.)
[12]Kim T, Kim Y H, Kim I, et al. BASN: enriching feature representation using bipartite auxiliary supervisions for face anti-spoofing[C]//Proc of IEEE/CVF International Conference on Computer Vision Workshops. Piscataway, NJ: IEEE Press, 2019: 494-503.
[13]Liu Yaojie, Jourabloo A, Liu Xiaoming. Learning deep models for face anti-spoofing: binary or auxiliary supervision[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2018: 389-398.
[14]Jourabloo A, Liu Y, Liu X. Face de-spoofing: anti-spoofing via noise modeling[C]//Proc of European Conference on Computer Vision. Cham:Springer, 2018: 290-306.
[15]Zhang K Y, Yao Taiping, Zhang Jian, et al. Face anti-spoofing via disentangled representation learning[C]//Proc of the 16th European Conference on Computer Vision. Cham:Springer, 2020: 641-657.
[16]Liu Yaojie, Stehouwer J, Liu Xiaoming. On disentangling spoof trace for generic face anti-spoofing[C]//Proc of the 16th European Confe-rence on Computer Vision. Cham:Springer, 2020: 406-422.
[17]Wu Yiqiang, Tao Dapeng, Luo Yong, et al. Covered style mining via generative adversarial networks for face anti-spoofing[J]. Pattern Recognition, 2022, 132: 108957.
[18]Zhou Qianyu, Zhang K Y, Yao Taiping, et al. Generative domain adaptation for face anti-spoofing[C]//Proc of European Conference on Computer Vision. Cham: Springer, 2022: 335-356.
[19]陳莉明, 田茂, 顏佳. 解糾纏表示學習在跨年齡人臉識別中的應用[J]. 計算機應用研究, 2021, 38(11): 3500-3505. (Chen Liming, Tian Mao, Yan Jia. Application of disentangled representation learning in cross-age face recognition[J]. Application Research of Computer, 2021, 38(11): 3500-3505.)
[20]黃新宇, 游帆, 張沛, 等. 基于多分類及特征融合的靜默活體檢測算法[J]. 浙江大學學報:工學版, 2022,56(2): 263-270. (Huang Xinyu, You Fan, Zhang Pei, et al. Silent living body detection algorithm based on multi-classification and feature fusion[J]. Journal of Zhejiang University: Engineering Science, 2022,56(2): 263-270.)
[21]Feng Haocheng, Hong Zhibin, Yue Haixiao, et al. Learning genera-lized spoof cues for face anti-spoofing[EB/OL]. (2020). https://arxiv.org/abs/2005. 03922.
[22]He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Deep residual learning for image recognition[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2016: 770-778.
[23]Zhang Zhiwei, Yan Junjie, Liu Sifei, et al. A face antispoofing database with diverse attacks[C]//Proc of the 5th IAPR International Conference on Biometrics. Piscataway, NJ: IEEE Press, 2012: 26-31.
[24]Chingovska I, Anjos A, Marcel S. On the effectiveness of local binary patterns in face anti-spoofing[C]//Proc of International Conference of Biometrics Special Interest Group. Piscataway, NJ: IEEE Press, 2012: 1-7.
[25]King D E. Dlib-ml: a machine learning toolkit[J]. The Journal of Machine Learning Research, 2009, 10: 1755-1758.
[26]Kingma D, Ba J. Adam: a method for stochastic optimization[EB/OL]. (2017-01-30). https://arxiv.org/abs/1412.6980.
[27]Van der Maaten L, Hinton G. Visualizing data using t-SNE[J]. Journal of Machine Learning Research, 2008, 9(11):2579-2605.
[28]Boulkenafet Z, Komulainen J, Hadid A. Face anti-spoofing based on color texture analysis[C]//Proc of IEEE International Conference on Image Processing. Piscataway, NJ: IEEE Press, 2015: 2636-2640.
[29]Chen Haonan, Hu Guosheng, Lei Zhen, et al. Attention-based two-stream convolutional networks for face spoofing detection[J]. IEEE Trans on Information Forensics and Security, 2019, 15: 578-593.
[30]Xiong Fei, AbdAlmageed W. Unknown presentation attack detection with face RGB images[C]//Proc of the 9th IEEE International Conference on Biometrics Theory, Applications and Systems. Piscataway, NJ: IEEE Press, 2018: 1-9.
[31]Liu Yaojie, Stehouwer J, Jourabloo A, et al. Deep tree learning for zero-shot face anti-spoofing[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE Press, 2019: 4675-4684.
[32]Qin Yunxiao, Zhao Chenxu, Zhu Xiangyu, et al. Learning meta mo-del for zero-and few-shot face anti-spoofing[C]//Proc of AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press, 2020: 11916-11923.
[33]Yu Zitong, Wan Jun, Qin Yunxiao, et al. NAS-FAS: static-dynamic central difference network search for face anti-spoofing[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2020, 43(9): 3005-3023.
[34]Boulkenafet Z, Komulainen J, Hadid A. Face spoofing detection using color texture analysis[J]. IEEE Trans on Information Forensics and Security, 2016, 11(8): 1818-1830.
