基于數(shù)據(jù)增強(qiáng)策略和卷積神經(jīng)網(wǎng)絡(luò)的近紅外光譜分析研究
2024-10-17 00:00:00鄭運(yùn)楊思雨王濤鄧焯蘭維杰云永歡潘磊慶
分析化學(xué) 2024年9期
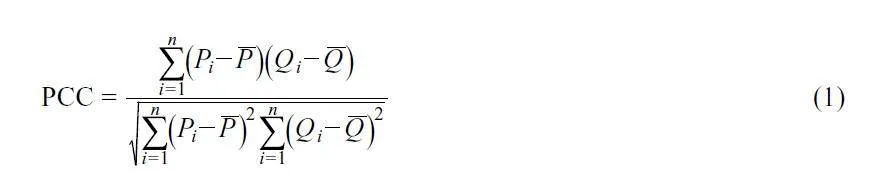

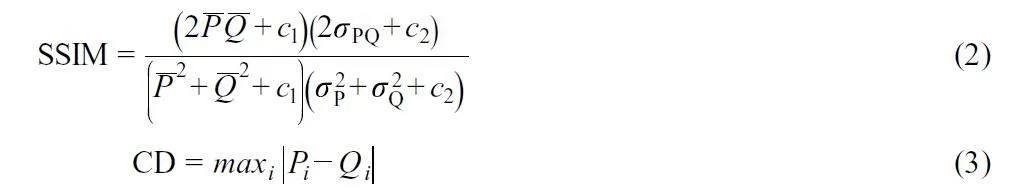
摘要 近紅外光譜技術(shù)結(jié)合化學(xué)計(jì)量學(xué)算法已廣泛應(yīng)用于食品和藥品等領(lǐng)域的定性和定量分析。然而,傳統(tǒng)化學(xué)計(jì)量學(xué)方法,特別是線性分類(lèi)方法,在解決多分類(lèi)問(wèn)題時(shí)的效果不佳。卷積神經(jīng)網(wǎng)絡(luò)(CNN)能夠提取數(shù)據(jù)中的深層次特征,適合處理非線性關(guān)系,但其建模性能依賴(lài)樣本量的大小和多樣性,而近紅外光譜樣本數(shù)據(jù)的采集和預(yù)處理過(guò)程通常耗時(shí)且費(fèi)力,獲取樣本成本較高。本研究提出了一種基于數(shù)據(jù)增強(qiáng)策略和CNN 的近紅外光譜定性分析方法。此數(shù)據(jù)增強(qiáng)策略分為兩步:(1) 分別采用Bootstrap 重采樣和生成對(duì)抗網(wǎng)絡(luò)(GAN)方法對(duì)3 個(gè)近紅外光譜數(shù)據(jù)集(藥片、咖啡和葡萄)進(jìn)行樣本擴(kuò)增;(2) 將原始樣本(Y)分別與Bootstrap 擴(kuò)增樣本(B)和GAN 擴(kuò)增樣本(G)進(jìn)行組合,得到3 種增強(qiáng)數(shù)據(jù)集(Y-B、Y-G 和Y-B-G)。在此基礎(chǔ)上,設(shè)計(jì)了適用于此數(shù)據(jù)集的CNN 模型結(jié)構(gòu),由2 個(gè)一維卷積層、1 個(gè)最大池化層和1 個(gè)全連接層組成。與偏最小二乘判別分析(PLS-DA)、支持向量機(jī)(SVM)和BP 神經(jīng)網(wǎng)絡(luò)(BP)的最優(yōu)模型相比,基于Y-B 數(shù)據(jù)集的CNN 模型對(duì)藥片(2 類(lèi))分析的平均準(zhǔn)確率分別提升了3.998%、9.364%和4.689%;基于Y-B-G 數(shù)據(jù)集的CNN 模型對(duì)咖啡(7 類(lèi))分析的平均準(zhǔn)確率分別提升了6.001%、2.004%和7.523%;基于Y-B 數(shù)據(jù)集的CNN 模型對(duì)葡萄(20 類(lèi))分析的平均準(zhǔn)確率分別提升了33.408%、51.994%和34.378%。此結(jié)果表明,基于數(shù)據(jù)增強(qiáng)策略和CNN 在不同數(shù)據(jù)集和分類(lèi)類(lèi)別中建立的模型均表現(xiàn)出更好的分類(lèi)準(zhǔn)確率和泛化性能。
關(guān)鍵詞 數(shù)據(jù)增強(qiáng);近紅外光譜;卷積神經(jīng)網(wǎng)絡(luò);化學(xué)計(jì)量學(xué)
近紅外光譜(NIRS)技術(shù)是一種快速、準(zhǔn)確且非破壞性的分析方法[1-2]。目前, NIRS 結(jié)合化學(xué)計(jì)量學(xué)算法已被廣泛應(yīng)用于食品和藥品的分類(lèi)鑒別[3-4]、產(chǎn)地溯源[5]和摻假檢測(cè)[6]等領(lǐng)域。然而,傳統(tǒng)的化學(xué)計(jì)量學(xué)方法,如偏最小二乘判別分析(PLS-DA)[7]、BP 神經(jīng)網(wǎng)絡(luò)(BP)[8]和支持向量機(jī)(SVM)[9]等在進(jìn)行定性分析時(shí),容易出現(xiàn)過(guò)擬合的問(wèn)題。此外,隨著定性分析中類(lèi)別的增加,傳統(tǒng)化學(xué)計(jì)量學(xué)方法特別是線性分類(lèi)方法在面對(duì)多分類(lèi)問(wèn)題時(shí)效果通常不佳[10]。近年來(lái),隨著深度學(xué)習(xí)算法和理論的不斷發(fā)展,卷積神經(jīng)網(wǎng)絡(luò)(CNN)在近紅外光譜定性分析中的應(yīng)用得到了深入研究[11]。相較于傳統(tǒng)建模方法, CNN 憑借其“局部連接、權(quán)值共享”的特性和深層次特征提取的優(yōu)勢(shì),提升了模型的訓(xùn)練效率和建模效果[12]。但是, CNN 的建模效果與樣本數(shù)據(jù)的豐富度和多樣性密切相關(guān),而近紅外光譜樣本數(shù)據(jù)的采集和預(yù)處理過(guò)程耗時(shí)費(fèi)力,特別是一些珍貴樣本數(shù)據(jù)通常不易獲取[13]。
針對(duì)上述問(wèn)題,可采用數(shù)據(jù)增強(qiáng)方法進(jìn)行樣本擴(kuò)增[14],并在此基礎(chǔ)上設(shè)計(jì)CNN 的模型結(jié)構(gòu),以充分利用CNN 的優(yōu)勢(shì),實(shí)現(xiàn)建模效率和效果的共同提升。目前,關(guān)于一維光譜數(shù)據(jù)增強(qiáng)方法的研究主要集中在左右平移、隨機(jī)線性疊加和疊加噪聲等方面[15]。Chakravartula 等[16]采用CNN 模型結(jié)合傅里葉變換近紅外光譜(FT-NIR)進(jìn)行咖啡的摻假預(yù)測(cè),通過(guò)引入隨機(jī)偏移、乘法和斜率效應(yīng)擴(kuò)增光譜數(shù)據(jù)。結(jié)果表明,基于擴(kuò)增數(shù)據(jù)的CNN 具有更好的預(yù)測(cè)性能。TENG 等[17]采用噪聲添加法對(duì)芝麻油產(chǎn)品的樣本數(shù)據(jù)進(jìn)行擴(kuò)增,并使用CNN 模型進(jìn)行摻假分析,最終得到CNN 的準(zhǔn)確率高達(dá)100%;WOHLERS 等[18]采用改進(jìn)的高斯噪聲方法進(jìn)行數(shù)據(jù)增強(qiáng),研究結(jié)果顯示,基于數(shù)據(jù)增強(qiáng)的CNN 性能優(yōu)于PLS,并且可以有效防止過(guò)擬合現(xiàn)象;HUANG 等[19]結(jié)合噪聲添加和線性疊加方法對(duì)新冠患者和健康人體血清的拉曼光譜數(shù)據(jù)進(jìn)行數(shù)據(jù)增強(qiáng),所得CNN 模型的分類(lèi)準(zhǔn)確率達(dá)到96.77%。由此可見(jiàn),與基于原始數(shù)據(jù)集的CNN 模型相比,采用平移、線性疊加或噪聲添加方法進(jìn)行樣本擴(kuò)增后的增強(qiáng)數(shù)據(jù)集對(duì)CNN 模型的性能均有不同程度的提升,但這些方法僅對(duì)樣本數(shù)據(jù)進(jìn)行了簡(jiǎn)單擴(kuò)充,其數(shù)據(jù)的多樣性還有待提升。目前,關(guān)于生成對(duì)抗網(wǎng)絡(luò)(GAN)的一維光譜數(shù)據(jù)增強(qiáng)方法的研究較少。YU 等[20]采用GAN 方法對(duì)3 種菌株(溶血葡萄球菌(Staphylococcus hominis)、溶藻弧菌(Vibrio alginolyticus)和地衣芽孢桿菌(Bacillus licheniformis))的拉曼光譜進(jìn)行樣本擴(kuò)增,結(jié)果表明, GAN 數(shù)據(jù)增強(qiáng)方法不僅解決了訓(xùn)練數(shù)據(jù)不足的問(wèn)題,還能夠較全面地整合光譜的所有信息節(jié)點(diǎn),模型的分類(lèi)準(zhǔn)確率可達(dá)到100%。ZHANG 等[21]采用兩種GAN 變體(DCGAN和CGAN)對(duì)單倍體玉米籽粒的高光譜(HSI)進(jìn)行數(shù)據(jù)擴(kuò)增,發(fā)現(xiàn)兩種方法均能將各分類(lèi)模型的準(zhǔn)確率提高10%以上,并且CGAN 的效果高于DCGAN。綜上, GAN 數(shù)據(jù)增強(qiáng)方法對(duì)原始數(shù)據(jù)的特征提取較全面,并且擴(kuò)增樣本更具多樣性,其增強(qiáng)的數(shù)據(jù)集可提升建模性能。然而,基于GAN 和Bootstrap 重采樣法的數(shù)據(jù)增強(qiáng)策略在近紅外光譜研究中尚未見(jiàn)報(bào)道。
本研究提出了一種基于數(shù)據(jù)增強(qiáng)策略和CNN 的近紅外光譜定性分析方法,即利用GAN 和Bootstrap重采樣法對(duì)3 個(gè)近紅外光譜數(shù)據(jù)集(藥片、咖啡和葡萄)進(jìn)行樣本擴(kuò)增,并將原始樣本(Y)分別與Bootstrap擴(kuò)增樣本(B)和GAN 擴(kuò)增樣本(G)進(jìn)行組合,得到3 種增強(qiáng)數(shù)據(jù)集(Y-B、Y-G 和Y-B-G)。在此基礎(chǔ)上,結(jié)合設(shè)計(jì)的CNN 模型,與3 種傳統(tǒng)建模方法(PLS-DA、SVM 和BP)進(jìn)行了分類(lèi)效果對(duì)比,旨在滿(mǎn)足CNN模型的樣本需求并為提升CNN 模型在不同數(shù)據(jù)集與分類(lèi)類(lèi)別中的泛化能力提供新思路。
1 實(shí)驗(yàn)及原理
1.1 數(shù)據(jù)來(lái)源
1.1.1 藥片數(shù)據(jù)集
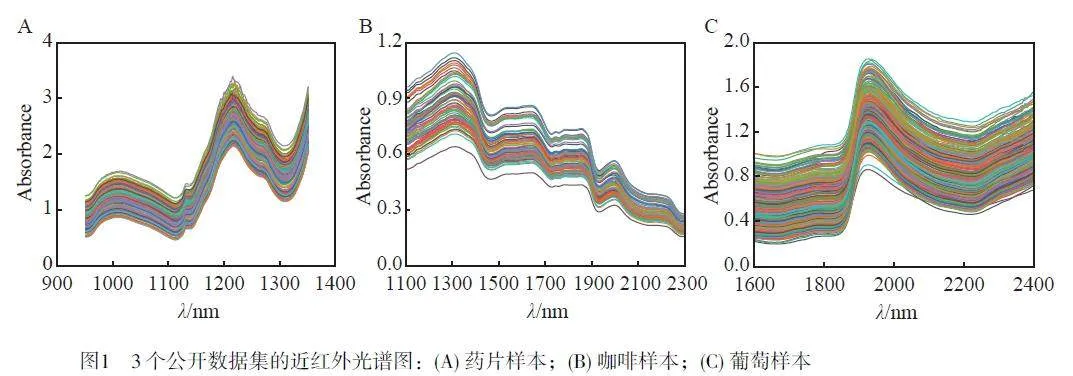
藥片樣本來(lái)源于公開(kāi)數(shù)據(jù)(https://ucphchemometrics.com/datasets/)。研究對(duì)象為2 種不同活性物質(zhì)劑量(15 和20 mg)的藥片,每類(lèi)包含80 個(gè)樣本。其近紅外光譜數(shù)據(jù)波數(shù)范圍為7398.337~10507.3 cm–1,即波長(zhǎng)范圍為951.7193~1351.6551 nm。每個(gè)樣本進(jìn)行128 次掃描,并取平均值作為讀數(shù)。藥片樣本的近紅外光譜如圖1A 所示。
1.1.2 咖啡數(shù)據(jù)集
咖啡樣本來(lái)源于公開(kāi)數(shù)據(jù)(https://nirpyresearch.com/analysis-ground-coffee-nir-spectroscopy/)。研究對(duì)象為7 種不同強(qiáng)度的咖啡,每類(lèi)包含10 個(gè)樣本。其近紅外光譜數(shù)據(jù)波長(zhǎng)范圍為1100~2300 nm, 波長(zhǎng)間隔為2 nm,每個(gè)樣本進(jìn)行20 次掃描,并取平均值作為讀數(shù)。咖啡樣本的近紅外光譜如圖1B 所示。
1.1.3 葡萄數(shù)據(jù)集
葡萄樣本來(lái)源于公開(kāi)數(shù)據(jù)(https://hdl.handle.net/10261/124880)。研究對(duì)象為20 種不同品種的葡萄,每類(lèi)包含20 個(gè)樣本。其近紅外光譜數(shù)據(jù)波長(zhǎng)范圍為1595.7~2396.3 nm, 波長(zhǎng)間隔為8.7 nm, 每個(gè)樣本進(jìn)行5 次掃描,并取平均值作為讀數(shù)。葡萄樣本的近紅外光譜如圖1C 所示。
1.2 模型原理
1.2.1 模型代碼和實(shí)驗(yàn)環(huán)境
本研究所用模型的詳細(xì)代碼和參數(shù)請(qǐng)見(jiàn)https://github.com/Cuzzzzy/Bootstrap_GAN_CNN/tree/master。
研究所用數(shù)據(jù)分析軟件包括Python3.11 和MATLAB R2024a;硬件設(shè)備包括Intel(R) Core(TM) i7-12650H2.30 GHz 處理器、512G 內(nèi)存和NVIDIA GeForce RTX 4050 顯卡。
1.2.2 GAN和Bootstrap 擴(kuò)增原理
分別采用GAN 和Bootstrap 兩種方法對(duì)藥片、咖啡和葡萄數(shù)據(jù)集進(jìn)行樣本擴(kuò)增。在藥片(2 類(lèi))中,每類(lèi)擴(kuò)增至1600 個(gè)樣本,兩種方法共生成6400 個(gè)樣本;在咖啡(7 類(lèi))中,每類(lèi)擴(kuò)增至200 個(gè)樣本,共生成2800 個(gè)樣本;在葡萄(20 類(lèi))中,每類(lèi)擴(kuò)增至400 個(gè)樣本,共生成16000 個(gè)樣本。
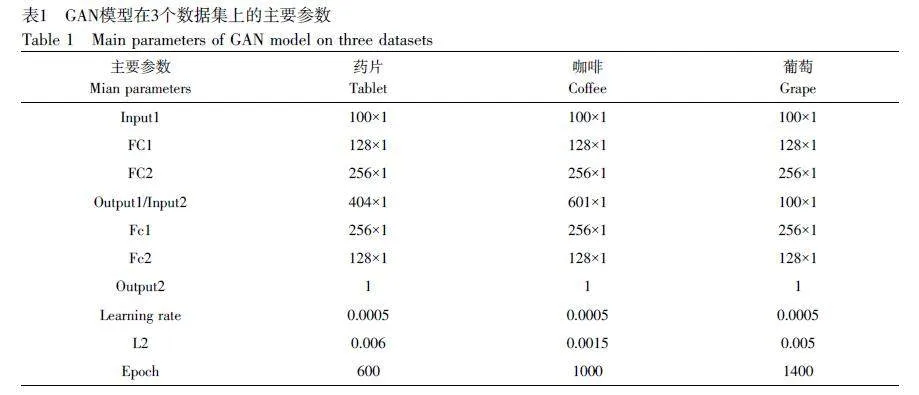
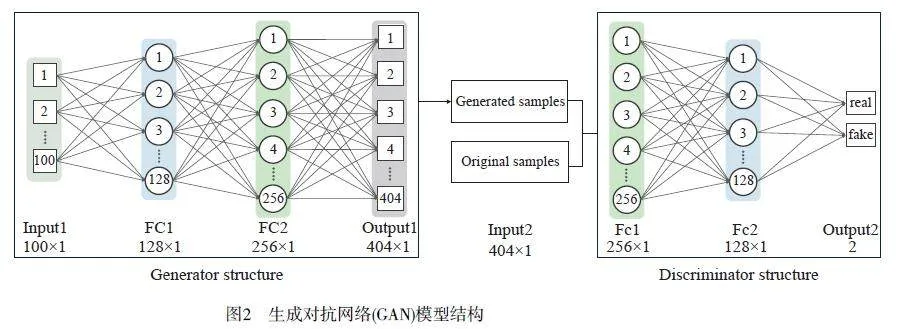
GAN 的模型結(jié)構(gòu)(以藥片為例)如圖2 所示,由生成器(Generator)和判別器(Discriminator)兩部分組成,生成器用于生成數(shù)據(jù),判別器用于判別數(shù)據(jù)的真?zhèn)巍⑸善骱团袆e器的輸入層、全連接層和輸出層分別命名為Input1、Input2、FC1、FC2、Fc1、Fc2、Output1 和Output2,其中, FC1 和FC2 層后設(shè)置了批量歸一化(BN)層,模型主要參數(shù)見(jiàn)表1。Bootstrap 方法是對(duì)原始樣本進(jìn)行重復(fù)采樣,即多次有放回的隨機(jī)采樣(圖4),每次生成1 個(gè)新的樣本數(shù)據(jù)集,從而實(shí)現(xiàn)樣本擴(kuò)增。
1.2.3 CNN模型原理
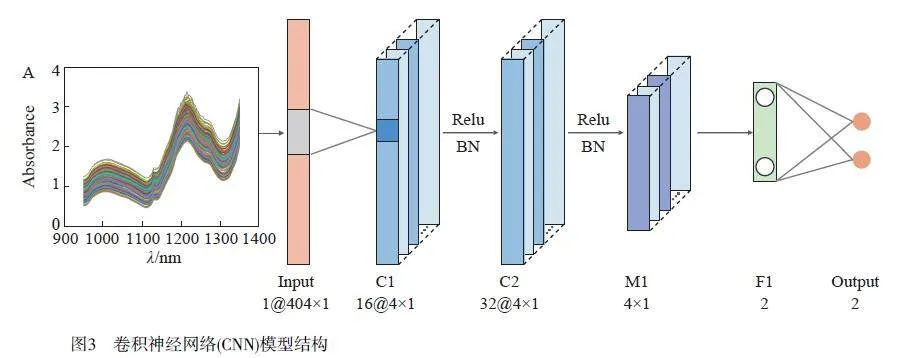
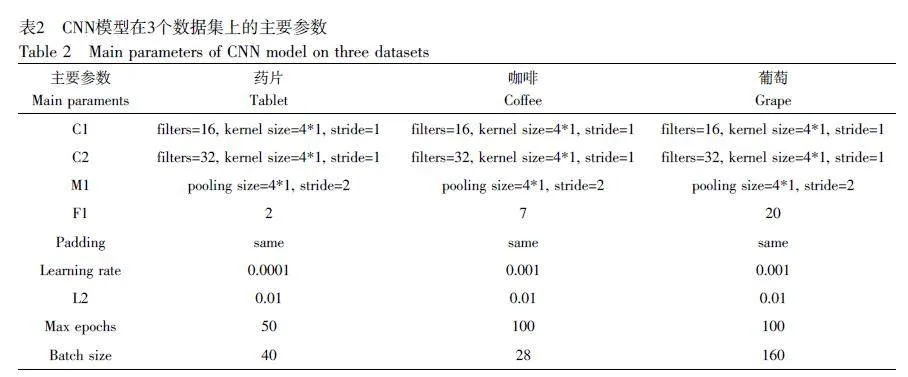
設(shè)計(jì)的CNN 模型結(jié)構(gòu)(以藥片為例)如圖3 所示,由2 個(gè)一維卷積層、1 個(gè)最大池化層和1 個(gè)全連接層組成,分別命名為C1、C2、M1 和F1,模型主要參數(shù)見(jiàn)表2。
1.3 模型評(píng)價(jià)
1.3.1 數(shù)據(jù)集劃分
本研究對(duì)3 個(gè)近紅外光譜數(shù)據(jù)集(藥片、咖啡和葡萄)與各自對(duì)應(yīng)的3 種增強(qiáng)數(shù)據(jù)集(Y-B、Y-G 和Y-B-G)采用Kennard-Stone(KS)方法按8∶2 的比例,選取樣本數(shù)據(jù)作為訓(xùn)練和測(cè)試集,用于后續(xù)實(shí)驗(yàn)。
1.3.2 增強(qiáng)數(shù)據(jù)質(zhì)量評(píng)價(jià)指標(biāo)
通過(guò)引入皮爾遜相關(guān)系數(shù)(PCC)、結(jié)構(gòu)相似性指數(shù)(SSIM)和切比雪夫距離(CD)評(píng)價(jià)增強(qiáng)數(shù)據(jù)與真實(shí)數(shù)據(jù)之間的差異。
PCC、SSIM 和CD 值分別用于度量?jī)蓚€(gè)數(shù)據(jù)集P 和Q 之間的相關(guān)性、結(jié)構(gòu)相似性和最大差異。當(dāng)PCC 和SSIM 值接近于1、CD 值接近于0 時(shí),表示增強(qiáng)數(shù)據(jù)的質(zhì)量好,反之亦反。PCC、SSIM 和CD 值可由公式(1)~(3)計(jì)算:
其中, P 代表原始數(shù)據(jù)集的平均光譜;Q 代表增強(qiáng)數(shù)據(jù)集的平均光譜;P 和Q分別代表P 和Q 的平均值;i 代表數(shù)據(jù)集中第i 個(gè)波長(zhǎng)點(diǎn);n 代表數(shù)據(jù)集的波長(zhǎng)點(diǎn)總數(shù); PQ 代表P 和Q的協(xié)方差; p和Q 代表P和Q 的標(biāo)準(zhǔn)差;c1 和c2為常數(shù)項(xiàng)。
1.3.3 模型效果評(píng)價(jià)指標(biāo)
準(zhǔn)確率(Acc)是定性分析中最常用的評(píng)價(jià)指標(biāo),指模型分類(lèi)預(yù)測(cè)正確的樣本數(shù)與樣本總數(shù)的比率,通常情況下,模型的準(zhǔn)確率越接近于1,說(shuō)明模型的分類(lèi)效果越好。本研究采用30 次平均準(zhǔn)確率作為建模效果評(píng)價(jià)指標(biāo),即計(jì)算模型運(yùn)行30 次所得準(zhǔn)確率的平均值。Acc通過(guò)公式(4)計(jì)算:
Acc (%) = Np/Nt × 100 (4)
其中, NP 為正確分類(lèi)的樣本數(shù), Nt 為樣本的總數(shù)。
2 結(jié)果與討論
2.1 GAN 和Bootstrap 擴(kuò)增過(guò)程
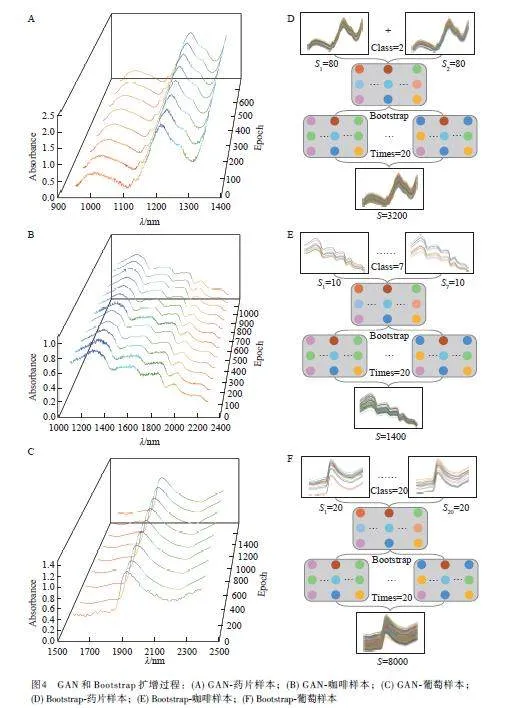
GAN 方法在3 個(gè)數(shù)據(jù)集(藥片、咖啡和葡萄)上的擴(kuò)增過(guò)程分別如圖4A~4C 所示,隨著迭代次數(shù)增加,逐漸與原始樣本(Y)的光譜特征相似,最佳迭代次數(shù)分別為600、1000 和1400 次。Bootstrap 方法在3 個(gè)數(shù)據(jù)集(藥片、咖啡和葡萄)上的擴(kuò)增過(guò)程分別如圖4D~4F 所示,對(duì)每個(gè)類(lèi)別均進(jìn)行20 次重采樣,最終擴(kuò)增樣本總數(shù)分別為3200、1400 和8000。
2.2 增強(qiáng)數(shù)據(jù)集的質(zhì)量評(píng)價(jià)
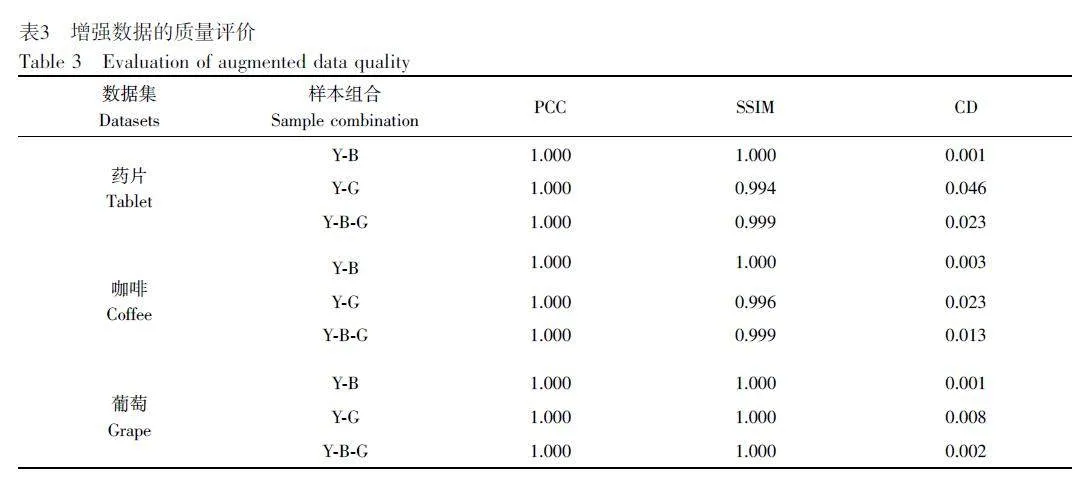
由表3 可知,在藥片、咖啡和葡萄數(shù)據(jù)集中,各自對(duì)應(yīng)的3 種增強(qiáng)數(shù)據(jù)集(Y-B、Y-G 和Y-B-G)的PCC 和SSIM 值均接近于1,而CD 值均接近于0。這說(shuō)明增強(qiáng)數(shù)據(jù)集與原始數(shù)據(jù)集的線性相關(guān)性、結(jié)構(gòu)相似性較高且波長(zhǎng)間差異較小,增強(qiáng)數(shù)據(jù)的質(zhì)量較好。
2.3 增強(qiáng)數(shù)據(jù)集的建模效果
在3 個(gè)數(shù)據(jù)集(藥片、咖啡和葡萄)中,各自對(duì)應(yīng)的3 種增強(qiáng)數(shù)據(jù)集(Y-B、Y-G 和Y-B-G)和原始數(shù)據(jù)集(Y)的平均光譜對(duì)比分別如圖5A~5C所示,可以看出曲線擬合效果非常好,說(shuō)明接近真實(shí)采樣數(shù)據(jù)。
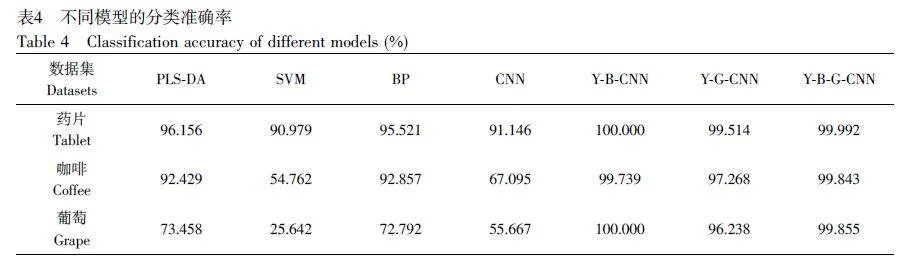
分別使用PLS-DA、SVM、BP 和CNN 對(duì)3 個(gè)原始數(shù)據(jù)集進(jìn)行建模分析,并與基于增強(qiáng)數(shù)據(jù)集的CNN 模型進(jìn)行分類(lèi)效果對(duì)比,在不同數(shù)據(jù)集上得到的平均準(zhǔn)確率見(jiàn)表4。在藥片原始數(shù)據(jù)集中, 4 種模型(PLS-DA、SVM、BP 和CNN)的平均準(zhǔn)確率分別為96.156%、90.979%、95.521%和91.146%;基于3 種增強(qiáng)數(shù)據(jù)集的CNN 模型(Y-B-CNN、Y-G-CNN 和Y-B-G-CNN)的平均準(zhǔn)確率分別為100.000%、99.514%和99.992%。在咖啡原始數(shù)據(jù)集中, 4 種模型(PLS-DA、SVM、BP 和CNN)的平均準(zhǔn)確率分別為92.429%、54.762%、92.857%和67.095%;基于增強(qiáng)數(shù)據(jù)集的CNN 模型(Y-B-CNN、Y-G-CNN 和Y-B-GCNN)的平均準(zhǔn)確率分別為99.739%、97.268%和99.843%。在葡萄原始數(shù)據(jù)集中, 4 種模型(PLS-DA、SVM、BP 和CNN)的平均準(zhǔn)確率分別為73.458%、25.642%、72.792%和55.667%;基于增強(qiáng)數(shù)據(jù)集的CNN 模型(Y-B-CNN、Y-G-CNN 和Y-B-G-CNN)的平均準(zhǔn)確率分別為100.000%、96.238%和99.855%。
以上結(jié)果表明,基于3 種原始數(shù)據(jù)集的4 種模型(PLS-DA、SVM、BP 和CNN)的分類(lèi)準(zhǔn)確率隨著分類(lèi)類(lèi)別數(shù)增多而逐漸呈下降趨勢(shì);與基于原始數(shù)據(jù)集的4 種模型相比,基于增強(qiáng)數(shù)據(jù)集的CNN 模型在不同的數(shù)據(jù)集和分類(lèi)類(lèi)別中均保持較高的分類(lèi)準(zhǔn)確率。這說(shuō)明本研究設(shè)計(jì)的CNN 模型通過(guò)大量擴(kuò)增樣本數(shù)據(jù)的訓(xùn)練,提取到了較完整的特征信息,提升了分類(lèi)準(zhǔn)確率和泛化性能,在3 種不同類(lèi)型的定性分析過(guò)程中均具有優(yōu)異且穩(wěn)定的性能。
2.4 傳統(tǒng)分類(lèi)模型在不同預(yù)處理下的建模效果
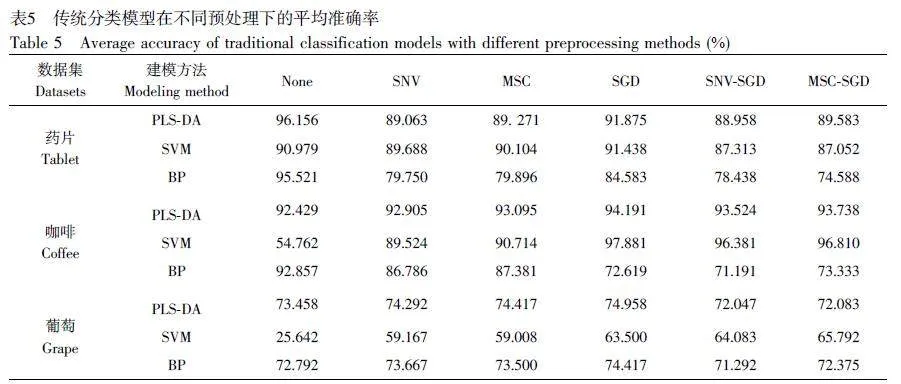
對(duì)3 個(gè)原始數(shù)據(jù)集(藥片、咖啡和葡萄)分別采用5 種預(yù)處理方法:標(biāo)準(zhǔn)正態(tài)分布(SNV)、多元散射校正(MSC)、一階導(dǎo)數(shù)平滑(SGD)、多元散射校正+一階導(dǎo)數(shù)平滑(MSC-SGD)和標(biāo)準(zhǔn)正態(tài)分布+一階導(dǎo)數(shù)平滑(SNV-SGD)。結(jié)合3 種傳統(tǒng)分類(lèi)模型(PLS-DA、SVM 和BP)進(jìn)行分類(lèi)預(yù)測(cè),得到的平均準(zhǔn)確率見(jiàn)表5。在藥片數(shù)據(jù)集中,與無(wú)預(yù)處理相比, PLS-DA 和BP 經(jīng)5 種預(yù)處理后的建模效果均有所下降;SVM經(jīng)SGD 預(yù)處理后與無(wú)預(yù)處理相比,建模效果有所提升,平均準(zhǔn)確率提升至91.438%,而經(jīng)SNV、MSC、MSC-SGD 和SNV-SGD 預(yù)處理后的平均準(zhǔn)確率下降。在咖啡數(shù)據(jù)集中,與無(wú)預(yù)處理相比, PLS-DA 經(jīng)5 種預(yù)處理后的建模效果均有所提升,其中效果最好的是SGD 預(yù)處理,平均準(zhǔn)確率提升至94.191%; 與無(wú)預(yù)處理相比, SVM 經(jīng)5 種預(yù)處理后,建模效果提升較大,其中效果最好的是SGD 預(yù)處理,平均準(zhǔn)確率提升至97.881%;與無(wú)預(yù)處理相比, BP 經(jīng)5 種預(yù)處理后建模效果下降。在葡萄數(shù)據(jù)集中,與無(wú)預(yù)處理相比,PLS-DA 經(jīng)SNV、MSC 和SGD 預(yù)處理后的建模效果有所提升,而經(jīng)SNV-SGD 和MSC-SGD 預(yù)處理后平均準(zhǔn)確率下降;與無(wú)預(yù)處理相比, SVM 經(jīng)5 種預(yù)處理后的建模效果均有所提升,其中效果最好的是MSCSGD預(yù)處理,平均準(zhǔn)確率提升至65.792%;與無(wú)預(yù)處理相比, BP 經(jīng)SNV、MSC 和SGD 預(yù)處理后的建模效果有所提升,而經(jīng)SNV-SGD、MSC-SGD 預(yù)處理后的平均準(zhǔn)確率下降。因此,并非所有預(yù)處理都能提升建模效果。
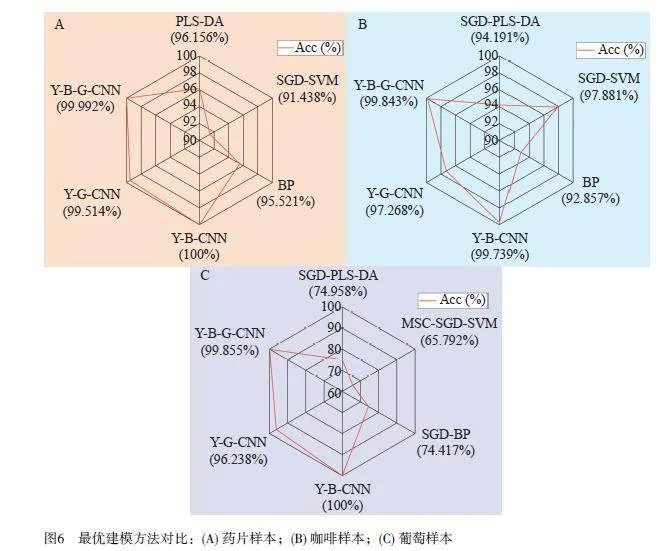
2.5 最優(yōu)建模方法對(duì)比
3 個(gè)近紅外光譜數(shù)據(jù)集(藥片、咖啡和葡萄)中分別對(duì)應(yīng)的3 種增強(qiáng)數(shù)據(jù)集(Y-B、Y-G 和Y-B-G)與原始數(shù)據(jù)集(Y)的最優(yōu)建模方法對(duì)比如圖6 所示。在藥片(2 類(lèi))中, PLS-DA、SVM、BP 和CNN 模型的最優(yōu)建模方法的平均準(zhǔn)確率分別為96.156%、91.438%、95.521%和100.000%。在咖啡(7 類(lèi))中, PLSDA、SVM、BP 和CNN 模型的最優(yōu)建模方法的平均準(zhǔn)確率分別為94.191%、97.881%、92.857%和99.843%。在葡萄(20 類(lèi))中, PLS-DA、SVM、BP 和CNN 模型的最優(yōu)建模方法的平均準(zhǔn)確率分別為74.958%、65.792%、74.417%和100.000%。上述結(jié)果表明,基于增強(qiáng)數(shù)據(jù)集的CNN 建模方法在不同數(shù)據(jù)集和分類(lèi)類(lèi)別情況下的準(zhǔn)確率均得到最優(yōu)結(jié)果,表明本方法具有很好的分類(lèi)效果和泛化能力。
3 結(jié)論
基于CNN 的近紅外光譜分析模型對(duì)于樣本的數(shù)量和多樣性需求較高,本研究采用GAN 和Bootstrap兩種方法進(jìn)行樣本擴(kuò)增,并將其與原始樣本組合,得到了具備豐度和深度的增強(qiáng)數(shù)據(jù)集。在此基礎(chǔ)上,設(shè)計(jì)了一種適用于此數(shù)據(jù)集的CNN 模型結(jié)構(gòu),并應(yīng)用于3 個(gè)近紅外光譜數(shù)據(jù)集(藥片、咖啡和葡萄)中。與傳統(tǒng)分類(lèi)模型進(jìn)行建模效果相比,基于數(shù)據(jù)增強(qiáng)策略的CNN 模型對(duì)于3 個(gè)不同數(shù)據(jù)集和二分類(lèi)、多分類(lèi)問(wèn)題中均具有更好的分類(lèi)準(zhǔn)確率和泛化能力。結(jié)果表明,在3 種數(shù)據(jù)集中,本研究提出的數(shù)據(jù)增強(qiáng)策略不僅生成了與原始樣本差異較小、質(zhì)量高的虛擬樣本數(shù)據(jù),經(jīng)過(guò)組合后還提升了樣本數(shù)據(jù)的多樣性,這使得CNN 模型得到充分訓(xùn)練,并提取到較全面的特征信息,進(jìn)而提升了模型的分類(lèi)準(zhǔn)確率和泛化能力。此外,在數(shù)據(jù)增強(qiáng)過(guò)程中發(fā)現(xiàn), Bootstrap 方法的樣本擴(kuò)增步驟較GAN 更簡(jiǎn)便,并且質(zhì)量評(píng)價(jià)和分類(lèi)效果在各數(shù)據(jù)集中表現(xiàn)更好,這可能是因?yàn)? 個(gè)數(shù)據(jù)集的共性特征較強(qiáng),而本方法是否適用于更多類(lèi)別或定量分析還有待進(jìn)一步驗(yàn)證。盡管GAN 方法在各數(shù)據(jù)集中取得較好的擴(kuò)增效果,但此模型受數(shù)據(jù)集和參數(shù)影響較大,并且需要調(diào)節(jié)的參數(shù)較多,因此有必要進(jìn)一步開(kāi)發(fā)自適應(yīng)的GAN 模型以增強(qiáng)其普適性。
References
[1] GOPAL J, MUTHU M. TrAC, Trends Anal. Chem. , 2024, 171: 117504.
[2] CHEN Y, GAO S K, DONG Y Y, MA X, LI J R, GUO M M, ZHANG J C. J. Anal. Test. , 2022, 6(4): 393-400.
[3] HUO Xue-Song, CHEN Pu, DAI Jia-Wei, WANG Hai-Peng, LIU Dan, LI Jing-Yan, XU Yu-Peng, CHU Xiao-Li. J. Instrum.Anal. , 2022, 41(9): 1301-1313.
霍學(xué)松, 陳瀑, 戴嘉偉, 王海朋, 劉丹, 李敬巖, 許育鵬, 褚小立. 分析測(cè)試學(xué)報(bào), 2022, 41(9): 1301-1313.
[4] YUN Y H, LI H D , DENG B C, CAO D S. TrAC, Trends Anal. Chem. , 2019, 113: 102-115.
[5] DENG Z W, WANG T, ZHENG Y, ZHANG W L, YUN Y H. Trends Food Sci. Technol. , 2024, 144: 104344.
[6] WANG Z Z, WU Q Y, KAMRUZZAMAN M. Food Control, 2022, 138: 108970.
[7] CHEN Xiao, HUAN Ke-Wei, ZHAO Huan, FAN Heng-Ye, HAN Xue-Yan. Chin. J. Anal. Chem. , 2021, 49(10): 1743-1749.
陳笑, 宦克為, 趙環(huán), 范恒曄, 韓雪艷. 分析化學(xué), 2021, 49(10): 1743-1749.
[8] ZHANG J, LIU G, LI Y, GUO M, PU F, WANG H. J. Food Compos. Anal. , 2022, 111: 104590.
[9] YU S, HUAN K, LIU X. Infrared Phys. Technol. , 2023, 135: 104958.
[10] ZHU Xiang-Rong, LI Gao-Yang, JIANG Jing, XIE Yun-He, SHAN Yang. J. Chin. Inst. Food Sci. Technol. , 2019, 19(5):263-269.
朱向榮, 李高陽(yáng), 江靖, 謝運(yùn)河, 單楊. 中國(guó)食品學(xué)報(bào), 2019, 19(5): 263-269.
[11] LIU X Y, AN H L, CAI W S, SHAO X G. TrAC, Trends Anal. Chem. , 2024, 172: 117612.
[12] SHI Y, HE T, ZHONG J, MEI X, LI Y, LI M, ZHANG W, JI D, SU L, LU T, ZHAO X. Talanta, 2024, 268: 125266.
[13] YANG B, CHEN C, CHEN F, CHEN C, TANG J, GAO R, LV X. Spectrochim. Acta, Part A, 2021, 260: 119956.
[14] CHEN Pu, DAI Jia-Wei, LI Jing-Yan, XU Yu-Peng, LIU Dan, CHU Xiao-Li. Chem. Reagents, 2023, 45(6): 105-112.
陳瀑, 戴嘉偉, 李敬巖, 許育鵬, 劉丹, 褚小立. 化學(xué)試劑, 2023, 45(6): 105-112.
[15] TAN Ai-Ling, CHU Zhen-Yuan, WANG Xiao-Si, ZHAO Yong. Spectrosc. Spectral Anal. , 2022, 42(3): 769-775.
談愛(ài)玲, 楚振原, 王曉斯, 趙勇. 光譜學(xué)與光譜分析, 2022, 42(3): 769-775.
[16] CHAKRAVARTULA S S N, MOSCETTI R, BEDINI G, NARDELLA M, MASSANTINI R. Food Control, 2022, 135:108816.
[17] TENG Y, CHEN Y, CHEN X, ZUO S, LI X, PAN Z, SHAO K, DU J, LI Z. Food Chem. , 2024, 436: 137694.
[18] WOHLERS M, MCGLONE A, FRANK E, HOLMES G. Chemom. Intell. Lab. Syst. , 2023, 240: 104924.
[19] HUANG Jie-Lun, ZENG Wan-Dan, YANG Rui-Jun, WU Min, XUE Qing-Shui, XIA Zhi-Ping. Chin. J. Anal. Lab. , 2022,41(7): 750-754.
黃杰倫, 曾萬(wàn)聃, 楊瑞君, 吳敏, 薛慶水, 夏志平. 分析試驗(yàn)室, 2022, 41(7): 750-754.
[20] YU S X, LI H F, LI X, FU Y V, LIU F H. Sci. Total Environ. , 2020, 726: 138477.
[21] ZHANG L, NIE Q, JI H Y, WANG Y Q, WEI Y G, AN D. J. Food Compos. Anal. , 2022, 106: 104346.
海南省重點(diǎn)研發(fā)項(xiàng)目(No. ZDYF2024XDNY197)、海南省自然科學(xué)基金項(xiàng)目(Nos. 323QN202, 322CXTD523)、國(guó)家自然科學(xué)基金項(xiàng)目(No. 22164008)和海南省院士團(tuán)隊(duì)創(chuàng)新中心平臺(tái)資助。
