復雜環境下的飛行器在線航路規劃決策方法
2024-11-27 00:00:00楊志鵬陳子浩曾長林松毛金娣張凱
系統工程與電子技術 2024年9期




摘 要:
針對飛行器在線航路規劃問題,提出一種基于深度強化學習(deep reinforcement learning, DRL)的飛行器在線自主決策方法。首先對飛行器運動模型、探測模型進行了說明,然后采用DRL深度確定性策略梯度(deep deterministic policy gradient, DDPG)算法,對飛行器飛行控制策略模型框架進行了構建。在此基礎上,提出了一種基于課程學習(curriculum learning, CL)的CL-DDPG算法,將在線航路規劃任務進行分解,引導飛行器進行目標靠近、威脅規避、航路尋優策略學習,并設置相應的高斯噪聲幫助飛行器對策略進行探索和優化,實現了復雜場景下的飛行器自適應學習和決策控制。仿真實驗證明,CL-DDPG算法能夠有效提升模型的訓練效率,算法模型任務成功率更高,具有優秀的泛化性和魯棒性,能夠更好地應用于復雜動態環境下的在線航路規劃任務中。
關鍵詞:
在線航路規劃; 深度強化學習; 自主決策; 課程學習; 威脅規避
中圖分類號:
TJ 765
文獻標志碼: A""" DOI:10.12305/j.issn.1001-506X.2024.09.28
Online route planning decision-making method of aircraft" in
complex environment
YANG Zhipeng, CHEN Zihao, ZENG Chang, LIN Song*, MAO Jindi, ZHANG Kai
(System Design Institute of Hubei Aerospace Technology Academy, Wuhan 430040, China)
Abstract:
Aiming at the problem of online route planning for aircraft, an online autonomous decision-making method for aircraft based on deep reinforcement learning (DRL) is proposed. Firstly, the maneuvering model and detection model of the aircraft are explained, and then the deep deterministic policy gradient (DDPG) algorithm of DRL is employed to construct the frame of the aircraft policy model. On this basis, a curriculum learning (CL)-DDPG algorithm based on CL is proposed, which decomposes the online route planning task, guides the aircraft to learn the strategies of target approach, threat avoidance, and air route optimization. The corresponding Gaussian noises are set to help the aircraft explore and optimize the strategy. And, the adaptive learning and decision-making control of the aircraft in complex scenarios are realized. Simulation experiments show that the CL-DDPG algorithm can effectively improve the training efficiency of the model. The algorithm model has higher task success rate, excellent generalization and robustness, and can be better applied to online route planning tasks in complex dynamic environments.
Keywords:
online route planning; deep reinforcement learning (DRL); autonomous decision-making; curriculum learning; threat avoidance
0 引 言
飛行器航路規劃是指為飛行器規劃出滿足任務需求、飛行器自身特性、外界環境約束等因素的航路,屬于飛行器任務規劃系統中的關鍵一環[1-3]。考慮到在執行射前航路規劃任務時,需關注飛行器禁避飛區、殘骸落區、景象匹配等環境約束,飛行器航路計算和規劃效率面臨巨大的挑戰[4-5]。與此同時,隨著空天防御、電子對抗等技術的發展,飛行器在復雜動態的戰場環境中面臨各種先進火力打擊、電磁干擾等壓制措施,其射前規劃的航跡成果可能無法滿足實時戰場環境約束,大大影響飛行任務的執行效率[6-8]。因此,針對復雜多約束場景,提出一種飛行器在線自主航路規劃方法,提升飛行器臨機決策能力,具有重要意義。
近年來,學者將經典A*[9]、蟻群算法[10]、快速搜索隨機樹[11]等路徑規劃方法用于飛行器航路規劃研究中,取得了一定的成果。文獻[12]提出一種動態引導A*算法,引入動態變化引導點和引導策略,對飛行器航跡規劃效率進行了優化。文獻[13]設計一種基于改進蟻群算法的無人飛行器路徑規劃方法,在初始信息素矩陣基礎上,結合視場機制和逃出策略對搜索策略進行了優化,然后利用logistic混沌模型對全局信息素更新方式進行了改進,最終在二維柵格地圖中完成仿真驗證了算法的有效性。這些方法在解決簡單靜態環境下的航路規劃問題,具有較高效率。當飛行場景復雜動態變化時,需實時對環境進行建模解算并處理海量數據,算法難以收斂,大大影響飛行器航路規劃效率。
隨著人工智能技術的發展,深度強化學習(deep reinforcement learning, DRL)以其出色的環境感知能力和自主決策能力在智能體自主導航和路徑規劃研究中備受關注[14-17]。在DRL中,智能體利用神經網絡感知環境并執行動作。進而獲得獎勵或懲罰反饋。通過不斷與環境交互和自適應學習,最終實現狀態輸入到動作輸出的有效映射。文獻[18]利用DRL方法對視覺感知和運動控制進行端對端聯合訓練,實現機器人物品運輸任務中的自主路徑規劃。文獻[19]通過構建目標驅動的馬爾可夫決策模型,解決DRL算法需要針對不同導航目標重新學習策略的問題;同時,針對性地設計非稀疏獎勵函數實現無人飛行器的自主航路規劃和避障導航。文獻[20]構建基于魯棒化深度確定性策略梯度(robust deep deterministic policy gradient, Robust-DDPG)算法的部分觀測馬爾可夫決策模型,用于引導無人飛行器在有限環境中進行局部障礙感知和規避,并通過仿真實驗驗證了方法的有效性。
盡管DRL算法在航路規劃領域取得了一定的成果。然而,現有的研究存在如:模型過于簡化、目標點位置單一、環境威脅區域固定等問題,任務場景較為簡單,難以滿足復雜動態多約束戰場環境下的飛行器在線航路規劃需求[21-23]。考慮到飛行器在執行任務時,需關注航跡有效性、飛行安全性、飛行效率等多項飛行器很難在有限的訓練時間內完成系統性的任務學習。因此,面對復雜多約束的戰場環境,引導智能體進行高效學習,實現飛行器自主威脅感知規避和在線航路規劃決策,具有重要意義。
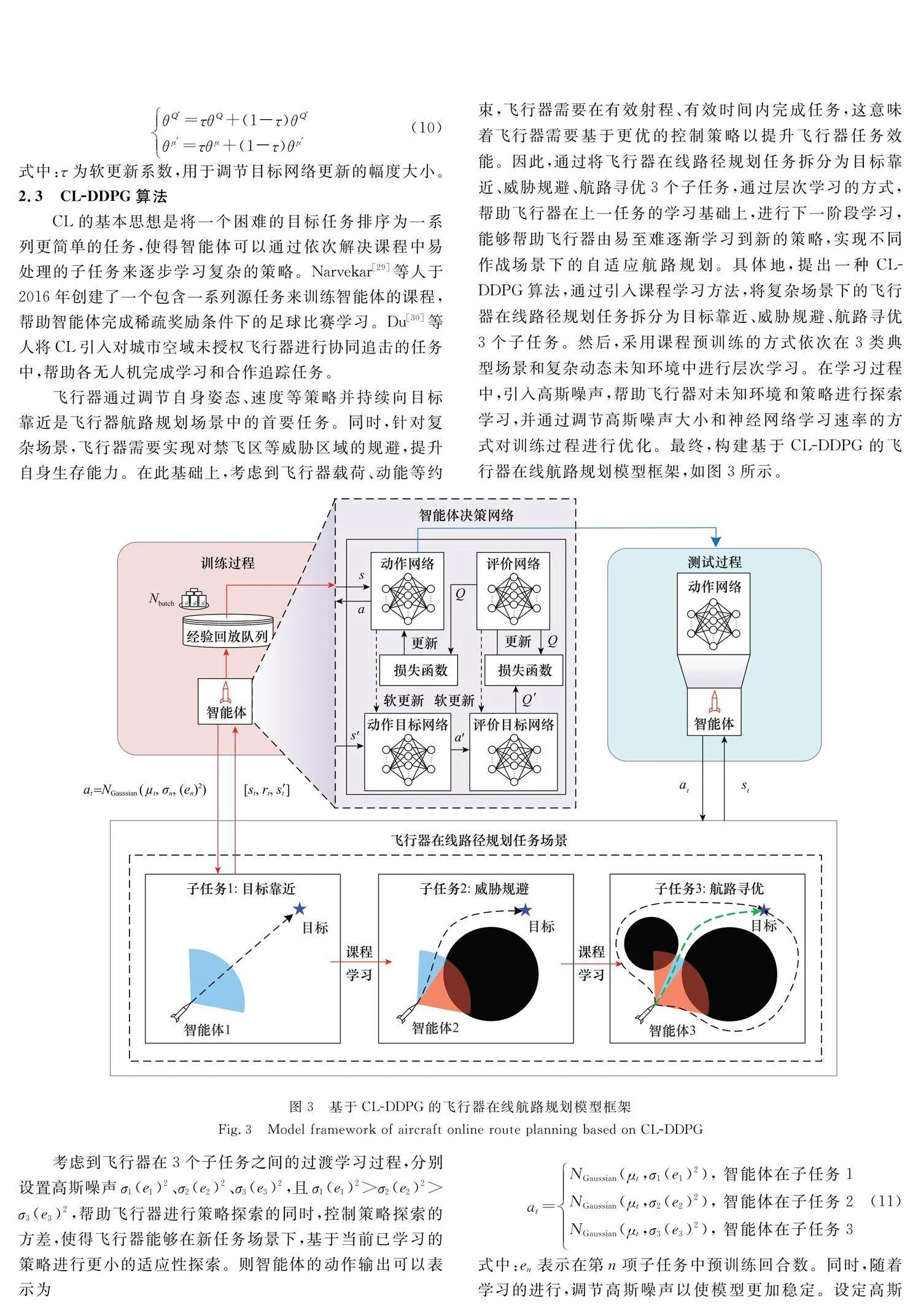
本文所進行的在線航路規劃研究代表了DRL在飛行器決策控制領域中的潛在應用之一。具體地,通過設計飛行器運動模型和探測模型,完成飛行器模型構建;引入深度確定性策略梯度(deep deterministic policy gradient, DDPG)方法,根據飛行器飛行特性和姿態控制要求構建部分可觀測馬爾可夫決策模型,并針對飛行任務完成獎勵函數設計;在此基礎上,提出一種課程學習(curriculum learning CL-DDPG)方法,將飛行器飛行任務分解為目標靠近、威脅規避、航路尋優3個子任務,用以引導飛行器通過CL完成復雜場景下的在線航路規劃預學習,有效提升訓練效率和模型泛化性能。最后,結合仿真結果,驗證了CL-DDPG算法對飛行器在線航路規劃的有效控制。
1 飛行器模型
1.1 飛行器運動模型
飛行器通過配備動態三維信息處理、航姿參考系統和全球定位/慣性導航系統(global positioning system-inertial navigation system, GPS-INS)慣性導航等設備,能夠實現精確導航定位和定高飛行[24]。為重點關注本研究中航路規劃和在線決策問題,對飛行器機動模型進行簡化,即假設飛行器保持定高巡航飛行,而不考慮飛行器起飛、著落中的俯仰姿態變化和飛行過程中的滾轉運動。本文在東北天坐標系中,構建了四自由度飛行器運動模型,如圖1所示。
4 仿真實驗
4.1 仿真環境
本章節的仿真實驗在Windows 10、Python 3.6、Tensorflow 1.14.0環境下,基于tkinter平臺對飛行器在線航路規劃模型進行了設計和訓練。任務場景為100 km×80 km的二維有限區域,如圖4所示。
其中,紅色點表示飛行器初始位置,藍色點表示目標點位置,深色黑色為威脅區域,紅色扇形包絡表示飛行器探測區域。具體地,設定任務仿真步長Δt為1 s。訓練過程中,設定任務中飛行器初始位置為環境左上角隨機生成,其中x0∈[5,15],y0∈[5,15]。目標位置在xtarget∈[85,95], ytarget∈[65,75]區域隨機生成,單位為km。設定飛行器初始航向為目標朝向。
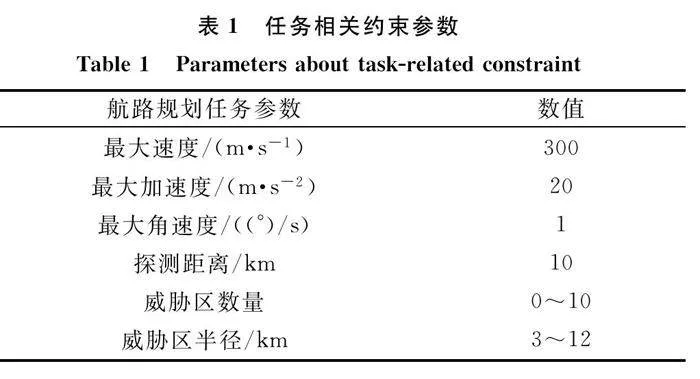
本研究分別在3個子任務場景中進行預訓練,再在威脅區數量、位置隨機的未知場景中進行少量訓練。在目標靠近子任務中,設置障礙物數量為0;在威脅規避子任務中,設置威脅區數量為3,半徑為10 km,且兩兩威脅區邊界間距大于15 km;在航路尋優子任務中,設置威脅區域為3組,每組兩個,共6個,半徑為10 km,每組內兩個威脅區邊界間距小于5 km,其他參數如表1所示。
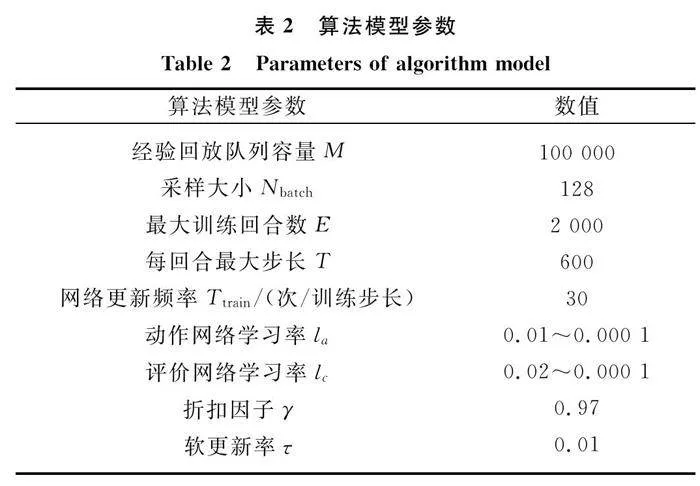
在基于CL-DDPG的在線航路規劃決策模型中,分別構建17×128×64×2、19×128×64×1結構的全連接型動作神經網絡和評價神經網絡。在每一訓練回合中,當飛行器完成任務、發生碰撞或回合內仿真步數達到最大步數時,視為該輪訓練結束,環境重置并進入新一輪訓練。當經驗回放隊列充滿數據時,神經網絡模型將基于Adam-Optimizer算法進行更新。初始化動作網絡學習率和價值網絡學習率分別為0.01、0.02,設定其以每回合0.99的衰減率衰減至0.000 1時停止衰減。詳細模型參數如表2所示。
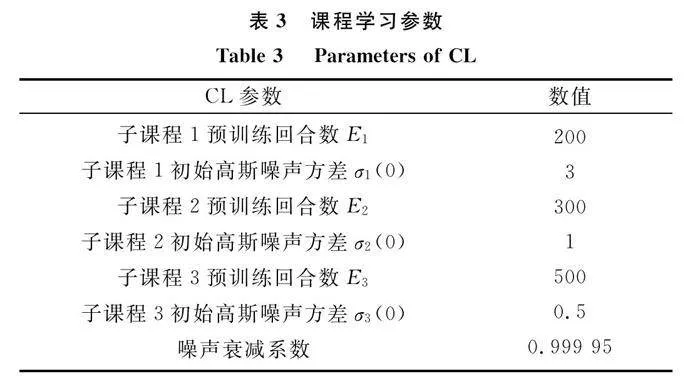
在基于傳統DDPG算法學習下的飛行器航路規劃模擬訓練中,大約1 000回合后,飛行器獎勵函數才開始緩慢上升并逐漸收斂至穩定。因此,設定子課程1、2、3預訓練回合數分別為200、300、500,通過子CL的方式,將前1 000回合進行子課程劃分。此外,針對CL預訓練,分別設定各子CL中的高斯噪聲方差和衰減系數,如表3所示。當完成預訓練后,訓練場景更新為威脅區數量、位置隨機的復雜未知場景,此時不再采用高斯噪聲對動作進行處理,訓練進行至最大訓練回合后結束。
4.2 實驗結果與分析
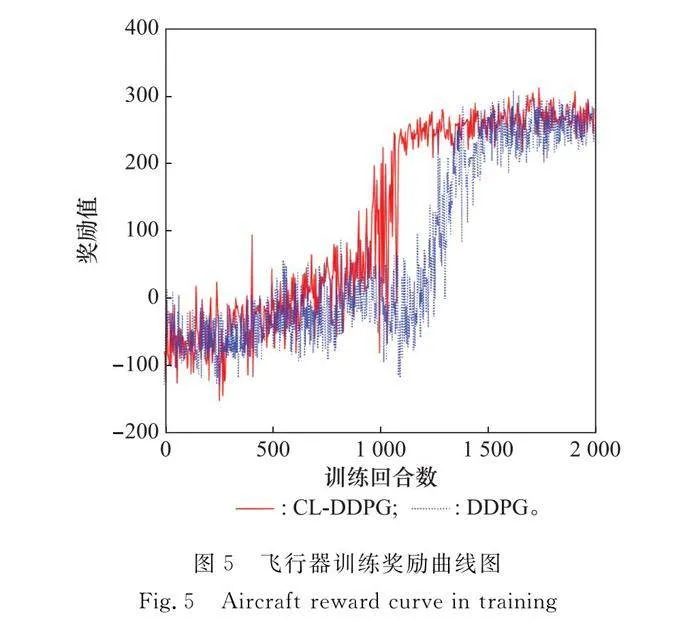
基于上述實驗場景和參數設定,分別基于CL-DDPG和DDPG算法對飛行器在線航路規劃模型進行訓練,并收集飛行器學習獎勵如圖5所示。
圖5中橫坐標為訓練回合數,縱坐標為每回合內飛行器獲得的獎勵值。可以看出,在開始訓練階段,兩種算法所得到的回合獎勵很少。隨著飛行器與環境交互不斷學習,回合獎勵曲線逐漸上升。訓練至423回合左右時,CL-DDPG曲線開始上升,雖然中間存在一定波動,但在1 054回合時上升至265左右獎勵值,并收斂至穩定。而DDPG算法下,獎勵函數曲線在1 100回合左右才出現明顯上升狀態,最終上升至1 510回合后收斂至穩定狀態。對比可以得出,本文提出的CL-DDPG算法相較DDPG算法在總訓練過程中收斂速度更快,并且在收斂后所獲取的獎勵波動幅度更小,這意味著CL-DDPG算法有效提升了訓練效率,具有更穩定的性能優勢。
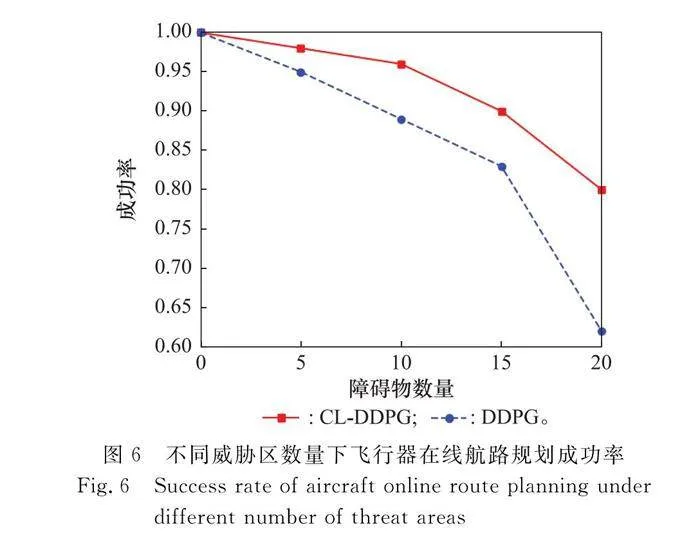
測試過程中,保持飛行器發射點和目標點位置不變,分別統計100次測試回合下兩種算法在不同威脅區數量下的任務成功率,如圖6所示。
可以看出,經自適應學習的兩種算法模型都可以有效完成在線航路規劃任務。隨著環境的逐漸復雜化,DDPG模型成功率明顯下降,當障礙物數量為20時,顯著下降至61%,而CL-DDPG算法模型仍可以穩定至80%,具有較高的成功率,更能滿足復雜環境下飛行器飛行任務需求。
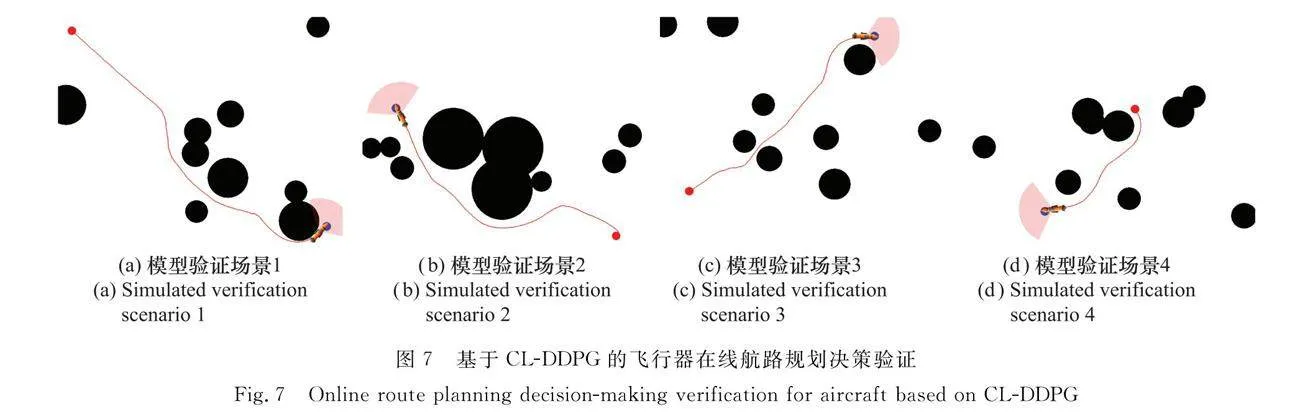
為了滿足飛行器發射區、目標點可變的任務規劃需求,本文對仿真任務場景進行了改變,設定飛行器發射點、目標點位置隨機生成,設定起始航向隨機生成,部分測試結果如圖7所示。可以看出,隨著飛行器起始點和目標點的改變,飛行器依然可以規劃出有效路徑,實現對目標區域的規避,有效完成在線航路規劃任務。其中,航路沒有明顯冒險、繞飛等行為,能夠滿足真實任務場景需求,體現了模型很好的通用性能。
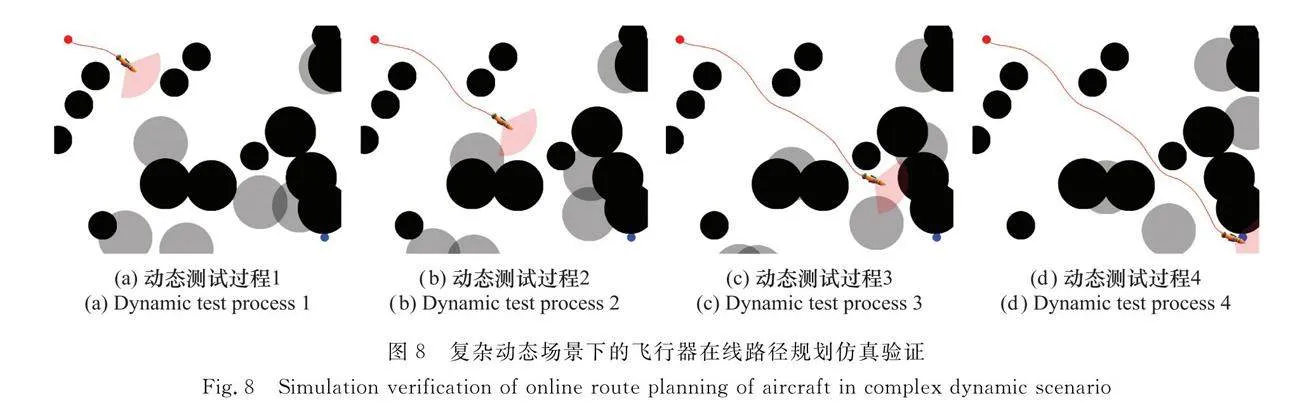
為了驗證模型在復雜動態場景下的表現,本文將測試環境中威脅區數量添加至20,并設定部分威脅區能隨機移動,以模擬敵方機動攔截威脅區域,測試如圖8所示,其中淺黑色區域為移動威脅區。
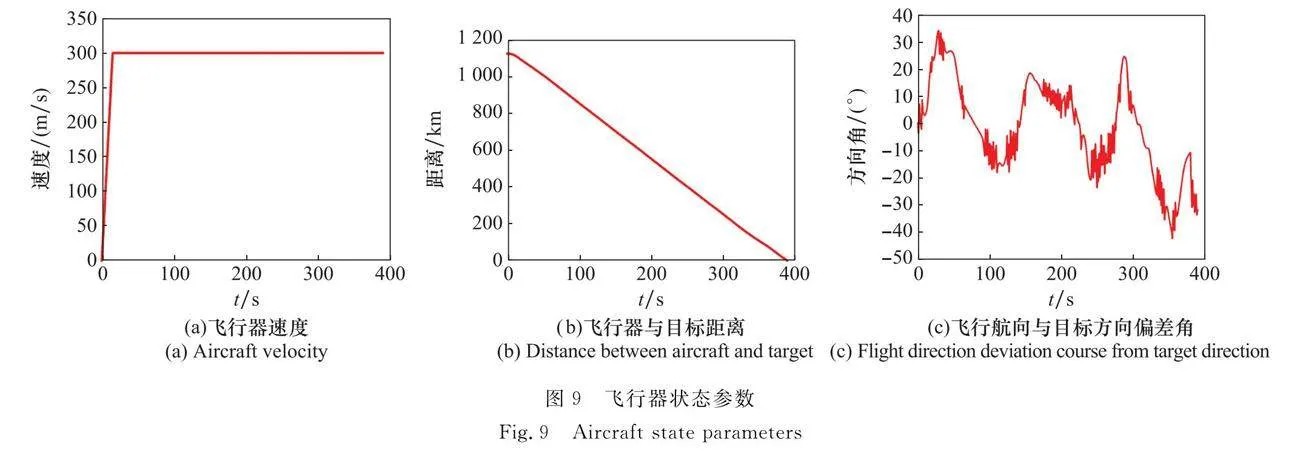
可以看到,隨著測試開始,飛行器持續向目標進行機動規劃,并在圖8(a)所示處躲避完第一個威脅區后重新將航向調整為目標方向。隨著飛行任務推移,飛行器持續有效進行自主規避決策,并在196 s時完成了對移動威脅區的規避,這體現了算法有效的泛化性,能夠應用于復雜動態任務場景中。在307 s時,飛行器從兩個威脅區域之間尋優穿過,這體現了經過課程學習和預訓練的飛行器,能夠尋優到較優航路解,以滿足任務要求。最終,在仿真進行至389 s時,飛行器有效完成了在線航路規劃任務。此外,為了分析飛行器在線航路規劃具體過程,對該次測試下的飛行速度、與目標距離、航向偏差角進行收集展示,如圖9所示。可以看出,任務開始后,飛行器快速加速至最高速度300 m/s并持續向目標點飛行,與目標點距離逐漸減小。盡管在任務過程中,出現了一些轉彎、規避等行為,但飛行器能夠很好地保持自身姿態,且飛行航向與目標方向偏差角持續保持在±40°之間,體現了算法在復雜動態環境中的良好穩定性。復雜動態未知場景下的飛行器在線路徑規劃模型泛化性測試如圖10所示。在復雜環境下,當發射點、目標點隨機指定時,飛行器都能夠很好地完成在線航路規劃決策。在此基礎上,當環境中的威脅區隨機生成、位置隨機動態改變時,飛行器都表現出了優秀的臨機決策能力,能夠完成有效威脅評估和自主規避,體現了算法良好的泛化性能。
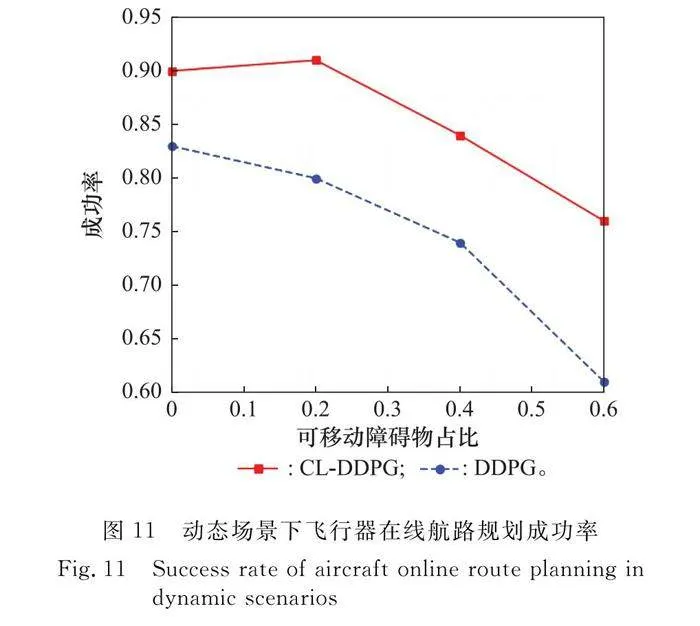
圖11記錄統計了100個復雜動態場景中,飛行器在線航路規劃決策的成功率表現。該測試場景中,發射點、目標點隨機生成,且初始距離大于50 km,環境中威脅區總數量設置為15保持不變。圖11中,橫坐標表示為可移動障礙物數量占比,縱坐標表示任務成功率。
可以看出,相比于DDPG算法,CL-DDPG算法模型成功率明顯更高。當可移動威脅區占比提高時,CL-DDPG算法模型始終表現出更好的任務完成率,在可移動威脅區數量占比60%時依然保持76%成功率,明顯高于DDPG算法模型61%的成功率。這意味著經過CL預訓練的飛行器,在復雜動態未知場景下在線航路規劃決策的成功率更高,模型魯棒性更好。
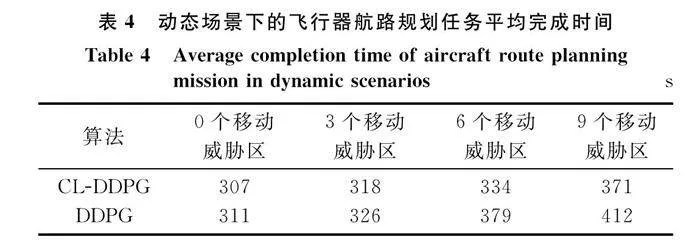
同時,表4記錄了圖11測試過程中所有成功回合的仿真時間數據。可以看出,簡單場景下,兩種算法下飛行器航路規劃總時間無明顯差異,隨著環境中可移動的威脅區數量增多,CL-DDPG算法下飛行器航路規劃模型展現了更好的適應性,飛行器能夠以較短時間完成在線航路規劃任務。這體現了經過目標靠近、威脅規避、航路尋優的課程學習后,飛行器能夠在航路規劃任務中制定更為合理的策略,使得飛行器能夠在更短時間內到達目標點,提升了任務完成效率。
5 結束語
本文對復雜環境下的飛行器航路規劃問題展開研究,提出一種DRL在線決策方法。針對DRL算法的訓練速率低、泛化性差等問題,提出一種CL預訓練方法,將飛行器在線規劃任務分解為目標靠近、威脅規避、航路尋優3個子課程,并引導飛行器智能體進行策略探索和學習。仿真結果表明,提出的一種基于CL-DDPG的飛行器在線航路規劃決策方法,訓練速率快,在復雜動態未知場景中表現出了更好的泛化性和魯棒性,具有一定應用價值。未來的工作將構建更為精確的飛控模型,以支持飛行器六自由度飛行,推動算法模型在真實的任務場景中進行優化部署。
參考文獻
[1] GUI X H, ZHANG J F, PENG Z H. Trajectory clustering for arrival aircraft via new trajectory representation[J]. Journal of Systems Engineering and Electronics, 2021, 32(2): 473-486.
[2] NIKLAS G, TOBIAS B, DIRK N. Deep reinforcement learning with combinatorial actions spaces: an application to prescriptive maintenance[J]. Computers amp; Industrial Engineering, 2023, 179(1): 109165.
[3] WANG X Y, YANG Y P, WANG D, et al. Mission-oriented cooperative 3D path planning for modular solar-powered aircraft with energy optimization[J]. Chinese Journal of Aeronautics, 2022, 35(1): 98-109.
[4] LI B, YANG Z P, CHEN D Q, et al. Maneuvering target tracking of UAV based on MN-DDPG and transfer learning[J]. Defence Technology, 2021, 17(2): 457-466.
[5] LIU C S, ZHANG S J. Novel robust control framework for morphing aircraft[J]. Journal of Systems Engineering and Electronics, 2013, 24(2): 281-287.
[6] OBAJEMU O, MAHFOUF M, MAIYAR L M, et al. Real-time four-dimensional trajectory generation based on gain-sche-duling control and a high-fidelity aircraft model[J]. Engineering, 2021, 7(4): 495-506
[7] 趙巖, 吳建峰, 高育鵬. 基于多智能體導航的高超飛行器信息融合方法[J]. 系統工程與電子技術, 2020, 42(2): 405-413.
ZHAO Y, WU J F, GAO Y P. Information fusion method of hypersonic vehicle based on multi-agent navigation[J]. Systems Engineering and Electronics, 2020, 42(2): 405-413.
[8] 陳宗基, 張汝麟, 張平, 等. 飛行器控制面臨的機遇與挑戰[J]. 自動化學報, 2013, 39(6): 703-710.
CHEN Z J, ZHANG R L, ZHANG P, et al. Flight control: challenges and opportunities[J]. Acta Automatica Sinica, 2013, 39(6): 703-710.
[9] DUCHON F, BABINEC A, KAJAN M, et al. Path planning with modified a star algorithm for a mobile robot[J]. Procedia Engineering, 2014, 96(1): 59-69.
[10] LIU J H, YANG J, LIU H P, et al. An improved ant colony algorithm for robot path planning[J]. Soft Computing, 2017, 21(1): 5829-5839.
[11] LI X Q, QIU L, AZIZ S, et al. Control method of UAV based on RRT* for target tracking in cluttered environment[C]∥Proc.of the 7th International Conference on Power Electronics Systems and Applications-Smart Mobility, Power Transfer amp; Security, 2017.
[12] 楊杰. 具有端點方向約束的快速航跡規劃方法研究[D]. 武漢: 華中科技大學, 2013.
YANG J. Research on fast route planning method adapted to directional endpoint constraints[D]. Wuhan: Huazhong University of Science and Technology, 2013.
[13] 高科, 宋佳, 艾紹潔, 等. 高超聲速飛行器再入段LQR自抗擾控制方法設計[J]. 宇航學報, 2020, 41(11): 1418-1423.
GAO K, SONG J, AI S J, et al. LQR active disturbance rejection control method design for hypersonic vehicles in reentry phase[J]. Journal of Astronautics, 2020, 41(11): 1418-1423.
[14] MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533.
[15] LILLICRAP T P, HUNT J J, PRITZEL A, et al. Continuous control with deep reinforcement learning[EB/OL]. [2023-04-30].http:∥www.arxiv.org/abs/1509.02971.
[16] HUANG C Q, DONG K S, HUANG H Q, et al. Autonomous air combat maneuver decision using Bayesian inference and moving horizon optimization[J]. Journal of Systems Engineering and Electronics, 2018, 29(1): 86-97.
[17] WALKER O, VANEGAS F, GONZALEZ F, et al. A deep reinforcement learning framework for UAV navigation in indoor environments[C]∥Proc.of the IEEE Aerospace Confe-rence, 2019.
[18] LEVINE S, FINN C, DARRELL T, et al. End-to-end training of deep visuomotor policies[J]. The Journal of Machine Learning Research, 2016, 17(1): 1334-1373.
[19] 張運濤. 面向無人機自主避障導航的深度強化學習算法研究[D]. 南京: 東南大學, 2021.
ZHANG Y T. Research on deep reinforcement learning for autonomous obstacle avoidance and navigation of UAV[D]. Nanjing: Southeast University, 2021.
[20] WAN K F, GAO X G, HU Z J, et al. Robust motion control for UAV in dynamic uncertain environments using deep reinforcement learning[J]. Remote Sensing, 2020, 12(4): 640-660.
[21] ZHANG C M, ZHU Y W, YANG L P, et al. An optimal gui-dance method for free-time orbital pursuit-evasion game[J]. Journal of Systems Engineering and Electronics, 2022, 33(6): 1294-1308.
[22] LI Y F, SHI J P, JIANG W, et al. Autonomous maneuver decision-making for a UCAV in short-range aerial combat based on an MS-DDQN algorithm[J]. Defence Technology, 2022, 18(9): 1697-1714.
[23] ZHANG H, JIAO Z X, SHANG Y X, et al. Ground maneuver for front-wheel drive aircraft via deep reinforcement learning[J]. Chinese Journal of Aeronautics, 2021, 34(10): 166-176.
[24] LIU Q, SHI L, SUN L L, et al. Path planning for UAV-mounted mobile edge computing with deep reinforcement learning[J]. IEEE Trans.on Vehicular Technology, 2020, 69(5): 5723-5728.
[25] LI Y H, WANG H L, WU T C, et al. Attitude control for hypersonic reentry vehicles: an efficient deep reinforcement learning method[J]. Applied Soft Computing, 2023, 123(1): 108865.
[26] RUMMERY G A, NIRANJAN M. On-line Q-learning using connectionist systems[D]. Cambridge: University of Cambridge, 1994.
[27] 王冠, 茹海忠, 張大力, 等. 彈性高超聲速飛行器智能控制系統設計[J]. 系統工程與電子技術, 2022, 44(7): 2276-2285.
WANG G, RU H Z, ZHANG D L, et al. Design of intelligent control system for flexible hypersonic vehicle[J]. Systems Engineering and Electronics, 2022, 44(7): 2276-2285.
[28] YANG Q M, ZHU Y, ZHANG J D, et al. UAV air combat autonomous maneuver decision based on DDPG algorithm[C]∥Proc.of the IEEE 15th International Conference on Control and Automation, 2019: 37-42.
[29] NARVEKAR S, SINAPOV J, LEONETTI M, et al. Source task creation for curriculum learning[C]∥Proc.of the ICAAMS 18th International Conference on Autonomous Agents amp; Multiagent Systems, 2016: 566-574.
[30] DU W B, GUO T, CHEN J, et al. Cooperative pursuit of unauthorized UAVs in urban airspace via multi-agent reinforcement learning[J]. Transportation Research Part C: Emerging Technologies, 2021, 128(1): 103-122.
作者簡介
楊志鵬(1995—),男,工程師,碩士,主要研究方向為飛行器任務規劃。
陳子浩(1995—),男,工程師,碩士,主要研究方向為飛行器航路規劃。
曾 長(1987—),男,高級工程師,碩士,主要研究方向為飛行器系統總體設計。
林 松(1986—),男,高級工程師,碩士,主要研究方向為飛行器任務規劃。
毛金娣(1988—),女,高級工程師,碩士,主要研究方向為飛行器航路規劃。
張 凱(1990—),男,高級工程師,博士,主要研究方向為飛行器系統總體設計。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2020年6期)2020-02-01 06:28:50
中國生殖健康(2019年11期)2019-01-07 01:28:02
領導決策信息(2018年50期)2018-02-22 06:17:16
商周刊(2017年5期)2017-08-22 03:35:26
中國衛生(2016年2期)2016-11-12 13:22:16
