Ko-LLaMA:基于LLaMA的朝鮮語大語言模型
2025-01-26 00:00:00龐杰閆曉東趙小兵
外語學刊 2025年1期



提 要:在本文中,我們通過擴展LLaMA現有的詞表,增加額外的20,000個朝鮮語Token,從而提高其對朝鮮語的編碼和語義理解的能力;并且進一步使用朝鮮語數據進行繼續預訓練,使用朝鮮語指令微調數據集對模型進行SFT(Supervised Fine-Tuning),并分析不同數據量對指令精調效果的影響,經過繼續預訓練和指令微調后的模型顯著提高了理解和遵循朝鮮語指令的能力。實驗結果表明,新提出的模型Ko-LLaMA顯著提高了原版LLaMA在理解和生成朝鮮語內容方面的能力。此外,在朝鮮語文本分類數據集YNAT上對Ko-LLaMA與擅長少數民族語言的CINO模型及CINO的多種模型組合以及原版LLaMA和GPT-3.5進行了效果對比。結果表明,Ko-LLaMA的朝鮮語文本分類能力遠超CINO和CINO的組合模型以及LLaMA和GPT-3.5等未經過朝鮮語語料進行詞表擴充和繼續預訓練的大語言模型。
關鍵詞:朝鮮語;大語言模型;詞表擴充;繼續預訓練;指令微調
中圖分類號:H08 """"文獻標識碼:A """"文章編號:1000-0100(2025)01-0001-8
DOI編碼:10.16263/j.cnki.23-1071/h.2025.01.001
Ko-LLaMA: A Korean Large Language Model Based on LLaMA
Pang Jie Yan Xiao-dong Zhao Xiao-bing
(Minzu University of China, Beijing 100081, China; National Language Resources Monitoring and
Research Center for Minority Languages, Beijing 100081, China; Key Laboratory of
Ethnic Language Intelligent Analysis and Security Governance of" MOE, Beijing 100081, China)
Large language models have gained immense popularity in the last couple of years, with models like ChatGPT and GPT-4 revolutionizing natural language processing research and taking exciting steps towards artificial general intelligence (AGI). Despite several large language models being open-sourced, such as LLaMA, these models primarily focus on English and Chinese corpora, with limited applicability to other languages. For minority languages such as Korean, the applicability of large language models is even more limited. In this paper, we enhance the applicability of" LLaMA to the Korean language by extending its exis-ting vocabulary with an additional 20,000 Korean tokens, improving its ability to encode and semantically understand Korean. We further continue pre-training the model with Korean data, fine-tune the model with a Korean instruction dataset (SFT: Supervised Fine-Tuning), and analyze the impact of varying amounts of data on the fine-tuning effect. The model after continued pre-training and instruction fine-tuning significantly improves the model’s ability to understand and execute Korean instructions. With the proposed approach, the capability of" LLaMA to understand and generate Korean text is greatly enhanced, and its ability to follow instructions is strengthened. Experimental results show that the newly proposed model, Ko-LLaMA, significantly outperforms the original LLaMA in terms of understanding and generating Korean content. Furthermore, in the comparison of effectiveness on the YNAT dataset for fresh language text classification, Ko-LLaMA was compared against the CINO model, which excels in minority languages, along with various combinations of CINO models, original LLaMA, and GPT-3.5. The results indicate that Ko-LLaMA’s ability in classifying Korean text far surpasses that of CINO and its combinations, as well as LLaMA and GPT-3.5, which have not undergone vocabulary expansion and continued pre-training on Korean language corpora.
Key words:Korean;Large language model;Vocabulary extension;Continued pretraining;Command fine-tuning
1 引言
隨著大型語言模型(LLMs)的出現,自然語言處理領域經歷了實質性的范式轉變。這些模型以其龐大的規模和全面的訓練數據而受到關注,它們在理解和生成類似人類的文本方面表現出了非凡的能力。與專注于文本理解的預訓練語言模型(如BERT)不同,GPT系列(Brown et al." 2020)強調文本生成,使它們相比其他模型更適合發揮創造性。值得注意的是,GPT家族的最新成員,即ChatGPT和GPT-4,受到極大的關注,他們在這個迅速發展的領域中確立了自己的領先地位。然而,盡管LLMs具有很大影響力,但LLMs的實施具有很大的限制,這些限制阻礙了透明和開放的研究。最主要的問題是他們的專有性質,限制了對模型的訪問,從而阻礙了更廣泛的研究社區基于他們的成功進行建設。此外,訓練和部署這些模型所需大量計算資源,對資源有限的大多數研究者來說是個挑戰,進一步加劇了可研究性的問題。為了應對這些限制,NLP研究傾向于使用開源替代品,以增加更大的透明度和協作。LLaMA(Touvron et al. 2023a)、LLaMA-2(Touvron et al, 2023b)和Alpaca(San-Martin et al. 1968)就是這些倡議的顯著例子。這些開源的LLMs旨在促進學術研究,加快NLP領域的進步。開源這些模型的目的是創造一個有利于模型開發、微調和評估的環境,最終創建適用于各種用途強大、有能力的LLMs,所以為了彌補少數民族語言朝鮮語在大語言模型上的空缺,我們研究一款可以用于少數民族語言朝鮮語的大語言模型,便于以后朝鮮語大語言模型的研究與發展。
目前,中英文領域的大語言模型研究已經取得很好的發展,而對于少數民族語言如朝鮮語來說,大語言模型仍處于萌芽階段,沒有發揮出應有的效果。中英文領域的大語言模型的詞匯表幾乎沒有朝鮮語Token,無法編碼和解碼朝鮮語文本。通過對原版LLaMA模型進行詞表擴充、繼續預訓練、指令微調等工作,極大的提高了LLaMA對朝鮮語的理解和生成的能力,充分挖掘了大語言模型在朝鮮語的能力。本文的主要貢獻在于,第一,通過收集大量的朝鮮語訓練語料,使用SentencePiece工具采用BPE的分詞方式對語料進行分詞,并與原版LLaMA詞表進行合并,擴充了20,000個朝鮮語Token. 并且采用低秩適配(LoRA)方法,對詞表擴充后的模型進行了繼續預訓練,在使用較少計算資源的情況下顯著提高了模型在朝鮮語的理解和生成能力。第二,通過公開的YNAT朝鮮語文本分類數據集構造了包括45,678條訓練集、9104條驗證集,9104條測試集的朝鮮語文本分類的指令微調數據集,并對模型進行指令微調,分析了不同數據量對模型指令微調效果的影響,顯著提高了模型朝鮮語文本分類的能力。通過在YNAT朝鮮語文本分類數據集上的對比實驗,表明Ko-LLaMA的效果超過CINO及CINO相關組合模型。
2 相關工作
下文將現梳理大語言模型近幾年的研究進展,再介紹詞表擴充、繼續預訓練、指令微調一系列訓練范式的發展狀況。
OpenAI在2018年首次提出GPT(Generative Pretrained Transformer)(Radford "et al. 2018)。這種模型使用Transformer的解碼器架構,并使用一個單向的語言模型目標進行預訓練。在預訓練后,GPT可以通過在特定任務的數據上進行微調來適應各種NLP任務,其工作原理與Bert類似,當作預訓練模型使用。在2019年,OpenAI發布GPT的第二版,即GPT-2(Radford et al. 2019)。與GPT相比,GPT-2有更多的參數(從1.1億增加到3.4億)。GPT-2在許多NLP基準測試中取得領先的表現。2020年,OpenAI發布GPT-3(Mann et al. 2020),是當時最大的語言模型,擁有1750億個參數。GPT-3在文本生成任務上的表現超越許多先前的模型。在GPT-3的基礎上,OpenAI進一步進行微調,于2021年發布InstructGPT(Ouyang et al. 2022)。這個模型經過大量的模型訓練和數據清洗,旨在理解和執行用戶的指令。InstructGPT的訓練過程包括兩個階段。第一階段是預訓練,這是在大量的互聯網文本上進行的。第二階段是微調,這是在一個更小、特定的、由人類審核員生成的數據集上進行的。InstructGPT在許多實際應用中都表現出色,如進行技術支持、提供教育資源、幫助用戶學習新技能等。由于InstructGPT的成功,OpenAI受到啟發并于2022年11月底發布ChatGPT. InstructGPT和ChatGPT都是從GPT-3微調而來,但他們的區別是,InstructGPT是為了理解和執行用戶的指令,而ChatGPT則是為了進行自由形式的對話。基于上述區別,我們確定朝鮮語大語言模型要先經過InstructGPT的訓練階段,但是由于GPT沒有開源,而上述工作要在開源的模型上展開,所以LLaMA(Touvron et al. 2023a)作為Meta開源的模型則是一個比較好的選擇,而且LLaMA在各項NLP任務上取得顯著的成果。
LLaMA作為一款開源的大語言模型在相關研究上做出突出的貢獻,由于LLaMA只在英文的效果上表現卓越,在其他語種上展現出來的能力并沒有很突出,所以LLaMA在其他語言上的加固和拓展也基本采用詞表擴充+繼續預訓練+指令微調的訓練范式。Chinese-LLaMA(Cui et al.2024)是在LLaMA的基礎上增強了中文能力,這也提供了一種思路。雖然加固其中文能力比開發出LLaMA的朝鮮語理解和生成的能力要簡單一些,但是驗證了這一思路的可行性。
3 Ko-LLaMA訓練流程
3.1 原版LLaMA-7B詞表擴充
LLaMA-7B的訓練集大約包含1.4T的Token,其中大部分是英文,小部分是拉丁語和其他歐洲語言(Xia et al. 2023)。因此,LLaMA幾種語言上的能力表明它具有多語種和跨語種理解能力。初步研究表明,LLaMA幾乎沒有朝鮮語理解和生成的能力,在朝鮮語的各類NLP任務表現上都有待提高。為了賦予LLaMA更強的朝鮮語理解和生成能力,我們使用朝鮮語語料庫對LLaMA模型進行繼續預訓練。然而,直接使用朝鮮語語料庫進行繼續預訓練面臨一些挑戰。首先,原始的LLaMA詞匯表包含的朝鮮語Token非常少,這不足以編碼一般的朝鮮語文本。雖然LLaMA Tokenizer可以通過回退到字節碼來支持所有的朝鮮語字符,但這種回退策略會顯著增加序列長度,因為每個朝鮮語字符都被拆分為3-4個字節Token,降低了朝鮮語文本的編碼和解碼效率。其次,字節Tokens不僅用于表示朝鮮語字符,還用于表示其它UTF-8 Tokens,所以使用字節Tokens的方法很難讓LLaMA有效地學習捕獲朝鮮語Token語義的表示。為了解決這些問題并提高編碼效率,我們使用額外的朝鮮語Token擴展LLaMA詞表,并調整模型以適應擴展后的詞表(Gao et al. 2023)。擴展過程如下:
第一,為了增強分詞器對朝鮮語文本的支持,首先使用SentencePiece(Kudo and Richardson 2018),采用BPE的方式在朝鮮語語料庫上訓練一個朝鮮語分詞器,詞匯量為20,000。第二,通過合并他們的詞匯表,將朝鮮語分詞器合并到原版LLaMA分詞器中。這樣就可以得到一個合并過的分詞器,即包含了朝鮮語的LLaMA分詞器,它的詞匯量為49,924。第三,為了使LLaMA模型適應朝鮮語LLaMA分詞器,我們將詞嵌入層和語言模型頭從V×H形狀調整為V’×H,其中V=32000表示原始詞匯表的大小,H表示詞嵌入的維度,V’= 49924是朝鮮語LLaMA分詞器的新詞匯表大小。新添加的行被添加到原始嵌入矩陣的末尾,確保原始詞匯表中標記的嵌入不受影響。
3.2 使用LoRA對LLaMA進行繼續預訓練
常規的大語言模型訓練范式,即更新LLMs的全量參數是非常昂貴的,并且在時間和成本上對大多數實驗室或公司來說是不可行的。低秩適配(LoRA)(Hu et al. 2021)是一種參數高效的訓練方法,它保持預訓練模型的權重不變,同時引入可訓練的秩分解矩陣。LoRA凍結預訓練模型的權重,并在每一層注入可訓練的低秩矩陣。這種方法顯著減少總的可訓練參數,使得用更少的計算資源訓練LLMs成為可能。具體來說,對于一個線性層,其權重矩陣W0∈Rdk,其中k是輸入維度,d是輸出維度,LoRA添加了兩個低秩分解的可訓練矩陣B∈Rdr和A∈RrK,其中r是預先設定的秩。帶有輸入x的前向傳遞公式如下:
h=W0x+△Wx=W0x+BAx, B∈Rdr, A∈Rrk(1)
在訓練過程中,W0是凍結的,不接收梯度更新,而B和A是可以更新的。通過選擇秩rmin(d, k),我們減少了內存消耗,因為我們不需要為大的凍結矩陣存儲優化器狀態。我們主要將LoRA適配器集成到注意力模塊和MLP層的權重中,因為在QLoRA(Dettmers et al. 2023)中驗證了將LoRA應用到所有線性Transformer塊的有效性,表明這種選擇是合理的。
我們使用標準的因果語言模型(CLM)任務對LLaMA進行朝鮮語的繼續預訓練,給定輸入序列x=x0,x1,x2,...,模型采用自回歸的方式預測下一個Token ,目標就是最小化負對數似然:
LCLMΘ=-∑ilogpxi|x0,x1,,,,,xi-1;Θ(2)
經過繼續預訓練以后模型能夠完成對已輸入文本進行續寫,即提高了模型對朝鮮語文本的理解和生成能力,接下來只需要對繼續預訓練以后的模型做任務上的指令微調就能讓模型完成具體的下游任務。
3.3 朝鮮語指令微調
由于模型學習的知識是非常廣泛的,所以我們對模型的輸入輸出難以控制,并且經常會生成一些無關的內容,這是因為公式(2)中的語言建模目標
是預測下一個詞而不是follow instructions with hu-man feedback(Ouyang et al. 2022)。為了使語言模型的行為與用戶的意圖相符,可以對模型進行微調,明確地訓練它遵循指示。斯坦福Alpaca(Taori et al. 2023)是一個基于LLaMA的指令模型,它是在由Self-Instruct(Wang et" al. 2023)中的技術生成的52K條指令數據上進行訓練的。我們遵循斯坦福Alpaca的方法,對朝鮮語LLaMA進行有監督的微調訓練,以訓練出一個指令遵循模型。
由于數據有限,沒有對繼續預訓練以后的LLaMA做大規模的指令微調,所以只挑選了一個NLP常見的任務:文本分類,挑選數據進行指令微調,并且與CINO(Ouyang et al. 2022)和CINO的一些組合模型以及原版LLamA和GPT-3.5等大語言模型做效果比對。
在進行指令微調數據之前,需要明確兩個事情,一個是Prompt模版如何確定,另外一個是指令微調的數據從何而來。由于Chinese-LLaMA-Alpaca(Cui" et al. 2023)已經成功進行了指令微調,所以這里的Prompt模版還是采用斯坦福Alpaca模版,不過因為我們要做朝鮮語的指令微調,所以要將其格式轉換成朝鮮語版本。具體Prompt形式如圖2所示:
通過使用上述Prompt模版進行構造數據,并且使用公開數據集YNAT經過數據擴充來構造指令微調的數據,YNAT公開的朝鮮語文本分類數據集,其中訓練集45,678條,驗證集9,104條,測試集9,104條,并且將最終結果與CINO模型及CINO相關組合模型進行結果比較;同時為了驗證與相關大模型在朝鮮語理解能力的差距,設置Ko-LLaMA與原版LLaMA和GPT-3.5在朝鮮語文本分類數據集上的對比實驗。具體結果分析放在實驗與分析環節。
4 實驗與分析
4.1 繼續預訓練實驗
4.1.1 實驗數據集
繼續預訓練的數據集主要是從新華網、人民網朝鮮語版等多家新聞媒體網站上爬取58,642篇新聞文本作為訓練集原始語料以及230篇新聞文本作為測試集原始語料。將部分語料爬取以后經過去除亂碼、特殊符號、圖片等信息過濾得到比較純凈的新聞文本,共計680MB.
4.1.2 模型評估標準
PPL(困惑度)是一種衡量語言模型質量的評價指標。它衡量模型預測下一個單詞的難度。PPL 越低,模型越好。具體來說,PPL 是給定數據集上模型預測的單詞序列的對數似然函數的負值。對于一個包含 N 個單詞的數據集,PPL 計算如下:
PPL=exp-1N∑Ni=1logPwi|w1,...,wi-1(3)
因為LLaMA在經過詞表擴充和繼續預訓練以后,已經可以完成基本的文本續寫,并且其訓練語料大多是新聞文本,在朝鮮語新聞文本續寫效果最為明顯,所以對繼續預訓練以后的模型在230篇新聞文本上采用困惑度作為評估指標進行評估,這里需要注意一點,針對同一個測試集,采用不同tokenizer的模型會導致公式(3)中N的大小不同,即序列長度不同,所以tokenizer不同的模型進行PPL值的對比是沒有意義的,因此本文采用詞表擴充未經過繼續預訓練的模型和詞表擴充并經過繼續預訓練的模型在230篇新聞文本續寫任務的PPL值進行對比,這樣保證tokenizer的一致性,也就是N相同,進而可以描述出模型經過繼續預訓練以后對朝鮮語的理解和生成能力的提升。
4.1.3 實驗設置
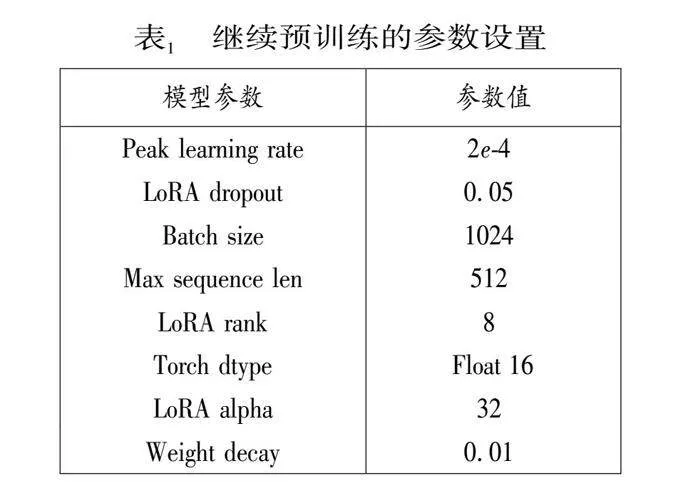
在繼續預訓練部分,由于數據集中沒有其他大模型訓練時用的那么多語料,并且原版LLaMA模型基本沒有朝鮮語的編碼和解碼能力,所以我們設置的學習率等參數相對大一些便于模型快速學習朝鮮語語料的知識,下面表1為繼續預訓練的詳細參數設置。
在繼續預訓練階段我們對模型進行了全面的預訓練,包括Embedding層,這樣不僅可以使模型適應新添加的朝鮮語Token,同時可以最小化對原始模型的干擾,并且我們向模型添加了LoRA權重(adapter),使用PEFT庫去做帶有LoRA的參數高效訓練,同時使用DeepSpeed(Aminabadi et al. 2022)來優化訓練過程中的內存效率,采用AdamW優化器(Loshchilov and" Hutter. 2019),峰值學習率為2e-4,warm-up cosine scheduler為5%。此外,我們還使用值為1.0的梯度裁剪,以緩解潛在的梯度爆炸。最終在兩張A100 GPU(80GB VRAM)進行一次5小時的迭代訓練。
4.1.4 實驗結果分析
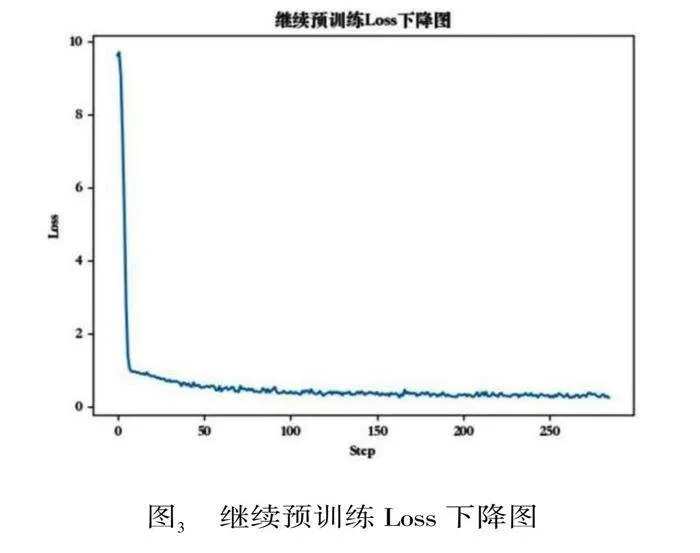
本節使用LLaMA-7B模型經過朝鮮語詞表擴充以后做繼續預訓練,分別在爬取的訓練數據上進行預訓練,其中58, 642篇新聞文本按照9:1的比例劃分訓練集和驗證集,測試集230篇新聞文本,驗證集Loss下降圖如圖3所示。繼續預訓練階段的Loss是前期急劇下降,然后變得平緩并趨于穩定,對此做出的分析是,在預訓練階段模型并不具備朝鮮語的編解碼能力,模型參數還沒有得到很好的調整,誤差相對較大,因此每次參數更新都在較大程度上減小誤差,所以損失下降得快;隨著訓練的進行,模型參數逐漸接近最優解,每次參數更新帶來誤差減小,因此Loss下降速度變慢。
圖3 繼續預訓練Loss下降圖
由于需要考慮PPL可比性的問題,所以在PPL對比實驗中需要保證對比模型的詞表一致,為了說明繼續預訓練對Ko-LLaMA的朝鮮語理解和生成能力的提升,我們將擴充詞表但未經過繼續預訓練的模型和擴充詞表并經過繼續預訓練的模型在230篇新聞文本上的續寫任務計算得到的PPL值進行對比。在文本續寫中,擴充詞表但是沒有經過繼續預訓練的模型的PPL值為41.287,擴充詞表并經過訓練以后的模型的PPL值為11.683,具體結果如下表2所示。這表明繼續預訓練以后的模型能夠有效地學習新聞文本中的語言模式并預測單詞序列。下圖4為擴充詞表并經過繼續預訓練模型的續寫效果展示。
最終得出結論:經過預訓練后的模型在文本建模任務上的良好性能表明,它可以用于各種自然語言處理應用,例如文本摘要、機器翻譯和問答以及分類。進一步的研究可以探索該模型在各種數據集和任務上的性能,并對其進行微調以提高特定任務的性能。
4.2 指令微調實驗
4.2.1 實驗數據集
指令微調的訓練數據是直接通過公開的YNAT數據,按照斯坦福的Alpaca格式的Prompt模版進行拼接得到,其中訓練集45,678條,驗證集9,104條,測試集9,104條,包含朝鮮語文本及其所處的類別共7個主題科技、經濟、文化、美容/健康、社會、生活、世界。數據樣例見圖5。
4.2.2 模型評估標準
本節在Ko-LLaMA與CINO及相關模型進行分類效果評定的時候,標準采用準確率(A)、精確率(P)、召回率(R)以及F1值作為實驗的評價標準。計算公式為:
A=TTP+TTNTTP+TTN+TFP+TFN(4)
P=TTPTTP+TFP(5)
R=TTPTTP+TFN(6)
F1=2PRP+R(7)
式中:TTP為樣本屬于類Ci,并被分類器正確分類到類Ci的樣本數;TFP為樣本不屬于類Ci,但被分類器分到類Ci的樣本數;TFN為樣本屬于類Ci,但被分類器分到其他類的樣本數。本文所研究的朝鮮語文本分類屬于多分類任務,因此采用宏平均來衡量整體的分類效果,即單獨計算每個類別的P和R,再進行算術平均得到測試集總體的P和R,最后通過(7)式得到F1。
4.2.3 實驗設置
指令微調部分參數設置與繼續預訓練部分參數設置是不同的,因為在指令微調的時候,模型已經學習過朝鮮語知識,并且我們主要的任務是對齊問答格式,所以我們可以設置的相對小一些。下面的表3是指令微調時設置的參數詳情。
本節實驗分為兩個階段:
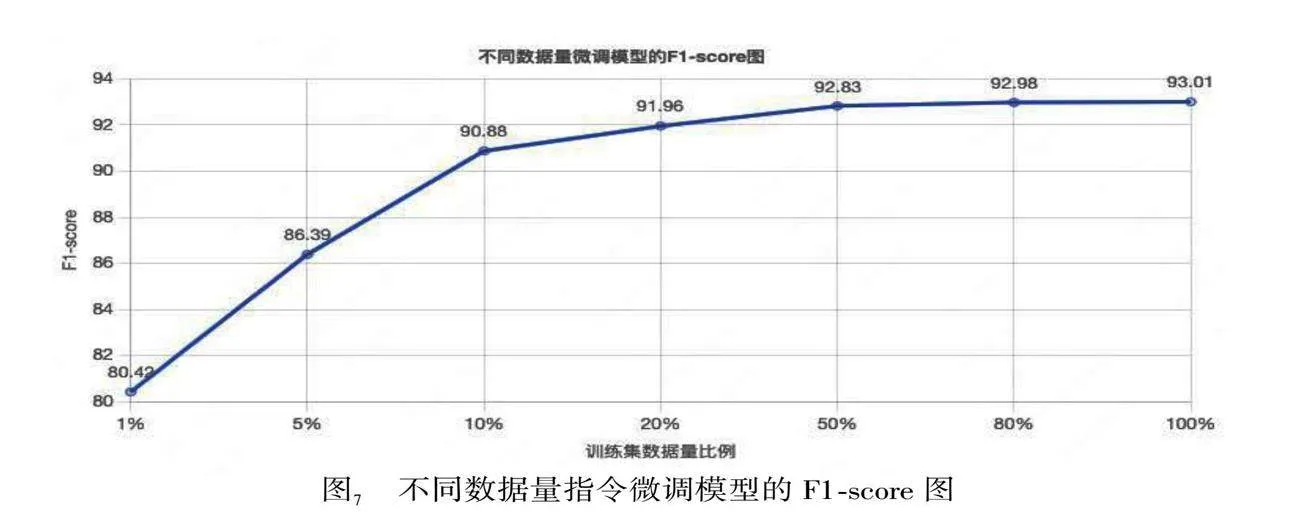
階段1,驗證不同數據量對經過預訓練以后模型能力的影響,分別隨機抽取訓練集數據的1%、5%、20%、50%、80%、100%的數據對繼續預訓練以后的模型進行指令微調并驗證效果。
階段2,分別采用CINO及CINO+TextCNN、CINO+BiLSTM、CINO+TextCNN+BiLSTM(模型串聯,下面稱為Model series)、CINO+TextCNN/BiLSTM(TextCNN和BiLSTM并聯在CINO后面,下面稱為Model parallel)以及Ko-LLaMA在YNAT數據集上進行評測實驗。
4.2.4 實驗結果分析
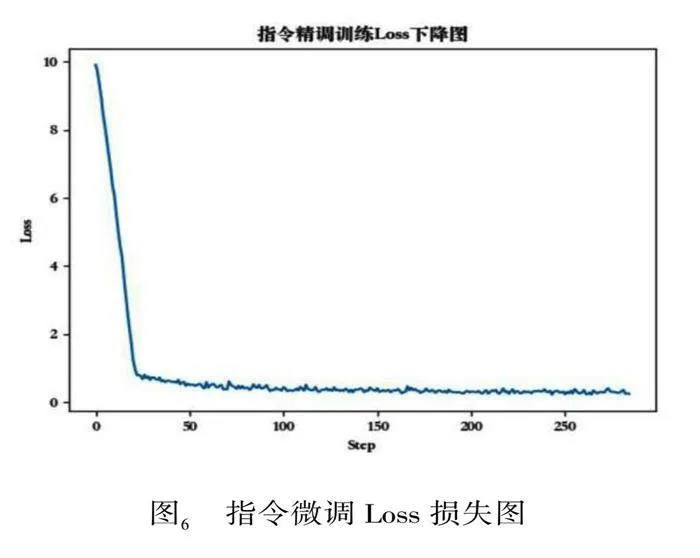
指令微調階段的驗證集Loss如下圖6所示。和預訓練階段Loss下降非常相似,都是前期急劇下降,然后變得平緩并趨于穩定。對此做出的分析:
雖然模型已經在大量數據上預訓練過,但是當模型開始在特定任務的數據上進行微調時,它仍然需要進行一些參數的調整以適應這個新任務。在微調的初始階段,模型由于對新任務的數據分布不熟悉,因此可能會有較大的誤差,這就導致了在微調初期下降得較快。而隨著微調的進行,模型對新任務的數據分布逐漸熟悉,每次更新帶來的誤差減小,因此Loss下降的速度會變慢。
第一階段的實驗:驗證不同數據量對預訓練以后模型能力的影響,所以我們分別隨機抽取了訓練數據的1%、5%、20%、50%、80%、100%進行微調,其F1-score的變化如下圖7所示。
從圖7中可以看出不同數據量對應的F1-score值的變化情況符合Loss下降的規律,當僅用1%的數據時,模型并沒有很好的被充分訓練,所以F1-score低,Loss高;當繼續增加訓練數據時,Loss急劇下降,F1-score迅速升高;再繼續增加數據至50%時,F1-score就已經趨于平穩,再繼續增加數據的收益將會很低。
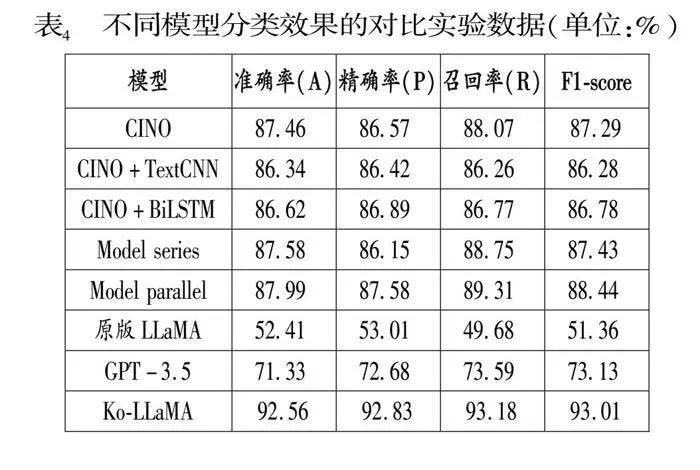
第二階段實驗:使用全部指令微調數據在經過繼續預訓練以后的模型上做文本分類任務的指令微調,Ko-LLaMA在朝鮮語文本分類上的能力得到巨大的提升。具體實驗結果由表4給出,根據實驗結果得出以下結論:經過繼續預訓練和指令微調的Ko-LLaMA的效果要顯著優于CINO的多種組合模型的效果,因為Ko-LLaMA模型參數更多并且已經在大規模的語料庫上進行了預訓練,當其經過詞表擴充以及繼續預訓練,模型可以很快的學習到朝鮮語的相關知識并進行理解;同時Ko-LLaMA的效果也優于未經過詞表擴充和繼續預訓練的大語言模型(原版LLaMA和GPT-3.5)的效果,對此的分析為原版LLaMA和GPT-3.5詞表中缺少朝鮮語Token導致對朝鮮語的編碼能力很弱,并且未經過朝鮮語語料的預訓練更將導致對朝鮮語的理解能力不理想。最后在指令微調的數據集上,通過特定的格式的Prompt引導模型如何完成一個分類任務,這樣模型可以更好的學習到如何去完成一個分類任務。最終Ko-LLaMA在YNAT朝鮮語文本分類數據集上的效果為:準確率(A)92.57%、精確率(P)92.83%、召回率(R)93.19%、F1-score 93.01%。
5 結束語
本文提出一種基于LLaMA并且能夠理解少數民族語言朝鮮語的大語言模型Ko-LLaMA.因為原版LLaMA無法理解和生成朝鮮語,所以我們增加額外的2萬個朝鮮語Token,并且與原版LLaMA進行詞表合并,最終詞表大小為49,924;然后通過爬取的58,642篇朝鮮語文檔進行繼續預訓練,在訓練過程中使用PEFT庫去做帶有LoRA的參數高效訓練,同時使用DeepSpeed來優化訓練過程中的內存效率,通過繼續預訓練,使Ko-LLaMA能夠理解和生成朝鮮語,由于數據量的限制,朝鮮語的的理解和生成能力并不是特別強,只能進行一些基本的續寫;然后我們通過公開數據集YNAT,按照斯坦福Alpaca的Prompt格式進行構造數據,并且對繼續預訓練以后的模型進行指令微調訓練,通過隨機抽取不同比例的指令微調數據進行指令微調訓練,分析不同數據量對指令微調效果的影響,經過全部數據指令微調訓練以后的Ko-LLaMA在朝鮮語文本分類任務上的能力已經得到顯著提高。我們通過與CINO、CINO+TextCNN、CINO+BiLSTM、CINO+TextCNN+BiLSTM、CINO+TextCNN/BiLSTM以及原版LLaMA和GPT-3.5等以及原版LLaMA和GPT-3.5等一系列模型進行比較,Ko-LLaMA的朝鮮語文本分類效果比CINO等一系列模型顯著提高。
*閆曉東為本文的通訊作者。
參考文獻
Aminabadi, R.Y., Rajbhandari, S., et al. Deep Speed Infe-rence: Enabling Efficient Inference of Transformer Mo-dels at Unprecedented Scale[OL]. arXiv Preprint ar-Xiv: 2207.00032, 2022.
Brown, T.B., Mann, B., et al. Language Models Are Few-shot Learners[OL]. arXiv Preprint arXiv: 2005.14165, 2020.
Cui, Y., Yang, Z., et al. Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca[OL]. arXiv Preprint arXiv: 2304.08177, 2024.
Dettmers, T., Pagnoni, A., et al. QLoRA: Efficient Finetu-ning of Quantized LLMs[OL]. arXiv Preprint arXiv: 2305.14314, 2023.
Gao, P., Han, J., et al. Llama-Adapter V2: Parameter-efficient Visual Instruction Model[OL]. arXiv Preprint arXiv: 2304.15010, 2023.
Hu, E.J., Shen, Y., et al.LoRA: Low-rank Adaptation of Large Language Models[OL]. arXiv Preprint arXiv: 2106.09685, 2021.
Kudo, T., Richardson, J. Sentence Piece: A Simple and Language Independent Subword Tokenizer and Detokenizer for Neural Text Processing[OL]. arXiv Preprint ar-Xiv: 1808.06226, 2018.
Loshchilov, I., Hutter, F. Decoupled Weight Decay Regula-rization[OL]. arXiv Preprint arXiv: 1711.05101, 2019.
Mann, B., Ryder, N. et al. Language Models Are Few-shot Learners[OL]. arXiv Preprint arXiv: 2005.14165, 2020.
Ouyang, L., Wu, J., et al. Training Language Models to Follow Instructions with Human Feedback[EB/OL]. arXiv Preprint arXiv: 2203.02155, 2022.
Radford, A., Wu, J., et al. Language Models Are Unsupervised Multitask Learners[J]. OpenAI" Blog, 2019(1).
San-Martin, M., Copaira, M., et al. Aspects of" Reproduction in the Alpaca[J]. Reproduction, 1968(3).
Taori, R., Gulrajani, I., et al. Alpaca: A Strong, Replicable Instruction-following Model[OL]. https://crfm.stanford.edu/2023/03/13/alpaca.html, 2023.
Touvron, H., Lavril, T., et al. LLaMA: Open and Efficient Foundation Language Models[OL]. arXiv Preprint ar-Xiv: 2302.13971, 2023.
Touvron, H., Martin, L., et al. Llama 2: Open Foundation and Fine-tuned Chat Models [OL]. arXiv Preprint ar-Xiv: 2307.09288, 2023.
Wang, Y., Kordi, Y., et al. Self-Instruct: Aligning Language Models with Self-Generated Instructions[OL]. arXiv Preprint arXiv: 2212.10560, 2023.
Xia, M., Gao, T., et al. Sheared Llama: Accelerating Language Model Pre-training via Structured Pruning[OL]. arXiv Preprint, arXiv: 2310.06694, 2023.
定稿日期:2024-12-10【責任編輯 孫 穎】
