基于語料庫的朝鮮語命名實體結構特征研究
2025-01-26 00:00:00黃政豪金光洙
外語學刊 2025年1期
關鍵詞:特征提取

提 要:本文統計Klue-ner和Kochet-ner兩個命名實體語料庫中的新聞、評論和文化遺產文本數據包含的不同類別朝鮮語命名實體。根據統計結果分析朝鮮語命名實體的音節長度特征分布和格詞尾結合率。分析結果表明,音節長度和格詞尾的使用在命名實體分類中具有一定的規律可循。本文的研究成果可用于命名實體分類工作,同時也可以為朝鮮語命名實體語料庫構建提供分布結構建議。
關鍵詞:朝鮮語;格詞尾;命名實體識別;特征提取;名詞分類
中圖分類號:H08 """"文獻標識碼:A """"文章編號:1000-0100(2025)01-0009-10
DOI編碼:10.16263/j.cnki.23-1071/h.2025.01.002
A Corpus-based Study on the Structural Features of" Named Entities in Korean
Huang Zheng-hao Jin Guang-zhu
(Engineering" College, Yanbian University, Yanji" 133002, China;
School of" Foreign Languages, Yanbian University, Yanji 133002, China)
This paper counts the different categories of" Korean named entities contained in the news, comments, and cultural heritage text data in the Klue-ner and Kochet-ner named entity corpora. According to the statistical results, the syllable length feature distribution and case particle combination rate of Korean named entities are analyzed. The results show that the use of syllable length and case particles has certain regularity in named entity classification, which can be used for named entity classification work and can also provide distribution structure suggestions for the construction of Korean named entity corpora.
Key words:Korean; case particle; named entity recognition; feature extraction; noun classification
1 引言
隨著信息化技術的加速發展,以數字化為媒介的語言數據成為各國之間交流的主要方式。因此,在這些海量語言數據中以自動化的形式抽取關鍵信息成為目前研究的熱點。其中,命名實體識別(Named Entity Recognition,簡稱NER)技術作為信息抽取工作的重要方法,廣泛應用于文本理解、信息檢索、自動摘要、問答系統、機器翻譯等自然語言處理的各項子任務中(Li et al. 2020:50)。
命名實體(Named Entity,簡稱NE)一般是指文本內容中指代性較強且具有特定意義的名詞和數詞。它們通常包括人名、地名、機構名、日期、時間等多種不同的分類(劉瀏等 2018:329)。因此,命名實體自動識別任務可以理解為針對文章中所包含的名詞和數詞的細分類任務。命名實體識別是自然語言處理領域中的一個重要研究方向。它可以幫助我們更好地從文本內容中提取出核心實體,幫助讀者短時間內在海量信息流中快速地定位高價值信息。例如,在新聞、金融、醫療等不同領域數據中我們可以通過命名實體識別技術快速地提取出這些數據中包含的人物、地點、事件、日期、時間等關鍵信息。
由于延邊朝鮮族自治州的特殊地理位置,朝鮮語在這里成為與朝鮮、韓國進行學術文化交流的主要語言(崔仙 2022:33)。作為黏著語的朝鮮語具有語言的普遍特征,也有其獨有的語言學特點。從語言類型的角度來看,漢語和英語屬于主謂賓(SVO)型語言,而朝鮮語屬于主賓謂(SOV)型語言。這意味著朝鮮語的根節點位置出現的詞類是相對固定的,而位于句子的末尾的多數是朝鮮語中的謂詞(華英楠" 畢玉德 2022:55)。朝鮮語在構詞方法上,實詞通常與虛詞進行拼接,形成一個語節;這些語節再次通過隔寫(空格)形式按照規則順序連接在一起,形成一個具有完整語義的句子(盧星華 金靜 2022:79)。實詞是指能夠獨立表達意義的詞,如名詞、動詞、形容詞等,通常在句子中充當主語、謂語和賓語成分。虛詞則是指不能獨立表達意義,需要依附于實詞的詞,如助詞、介詞、連詞等(宋官懷" 2022:27)。特別是在朝鮮語中,實詞和虛詞之間的拼接關系非常重要,它決定句子的句法結構和語義。
本文通過朝鮮語的這些語言學特點,結合命名實體語料庫內容進行研究,有助于抽取朝鮮語命名實體在文章中的結構特點,能夠更加明確命名實體和其他句子成分之間的上下文依賴關系,從而保證在命名實體自動抽取任務中的識別性能,讓識別結果更接近人工標注的結果。這一成果能加強作為資源稀缺語言的朝鮮語語料的規模和質量,也能夠推進朝鮮語信息化在國內的研究進程。
2 相關研究
命名實體識別任務最早提出于1995年舉辦的第六屆MUC-6會議(Sundheim 1995:319)。目前,命名實體識別技術已經取得一定的發展。研究人員采用各種不同的方法來解決命名實體識別問題,包括基于規則的方法、基于統計學習的方法和基于深度學習的方法等。其中基于深度學習的方法是目前研究的熱點方法。
深度學習是一種人工智能技術,它能夠通過大量數據訓練來自動學習數據中隱藏的規律和關系。在命名實體識別領域中,深度學習能夠有效地提取文本中的特征,并通過多層神經網絡來進行分類。但深度學習建模過程中對所需要的語料庫質量和規模都具有較高的要求。因此,作為低資源語言的朝鮮語,如果直接使用現有的命名實體識別常用方法,則無法達到預期效果。針對這種語料資源不足的問題,通常使用的方法是利用已標注的較大規模的相關領域語料庫,通過遷移方式來解決語料資源不足的問題(吳炳潮等 2022:3776)。同時,為了提高命名實體識別效果在一般使用的詞向量特征外,通常結合字符級別的特征、形態學特征、位置特征和詞典等語言學特征作為識別系統輸入的額外信息來提高識別效果(鄧依依等 2021:30)。特別是在低資源語言類研究中從語言學角度研究能夠用于學習的結構特征來增強語料庫,以解決訓練語料不足的問題。劉嘉錫(2021:8)使用基于自舉的規則方法獲得基本詞典,再結合依存句法進行數據分析獲得能夠輸入至深度學習模型的標注數據,最終完成使用少量人工標注數據的深度學習方法,用于案件要素提取模型。Oh等(2017:317)分析韓國語命名實體語料庫中組成實體的音節特征,構建了基于音節單位的命名實體詞典用于命名實體識別任務。Park等(2021:556)為了解決更新較為頻繁的命名實體未登錄詞問題,使用韓國語詞匯語義網工具UWordMap從詞匯角度分析命名實體的上下文結構特點,為后續的命名實體抽取任務奠定了基礎。
3 研究方法
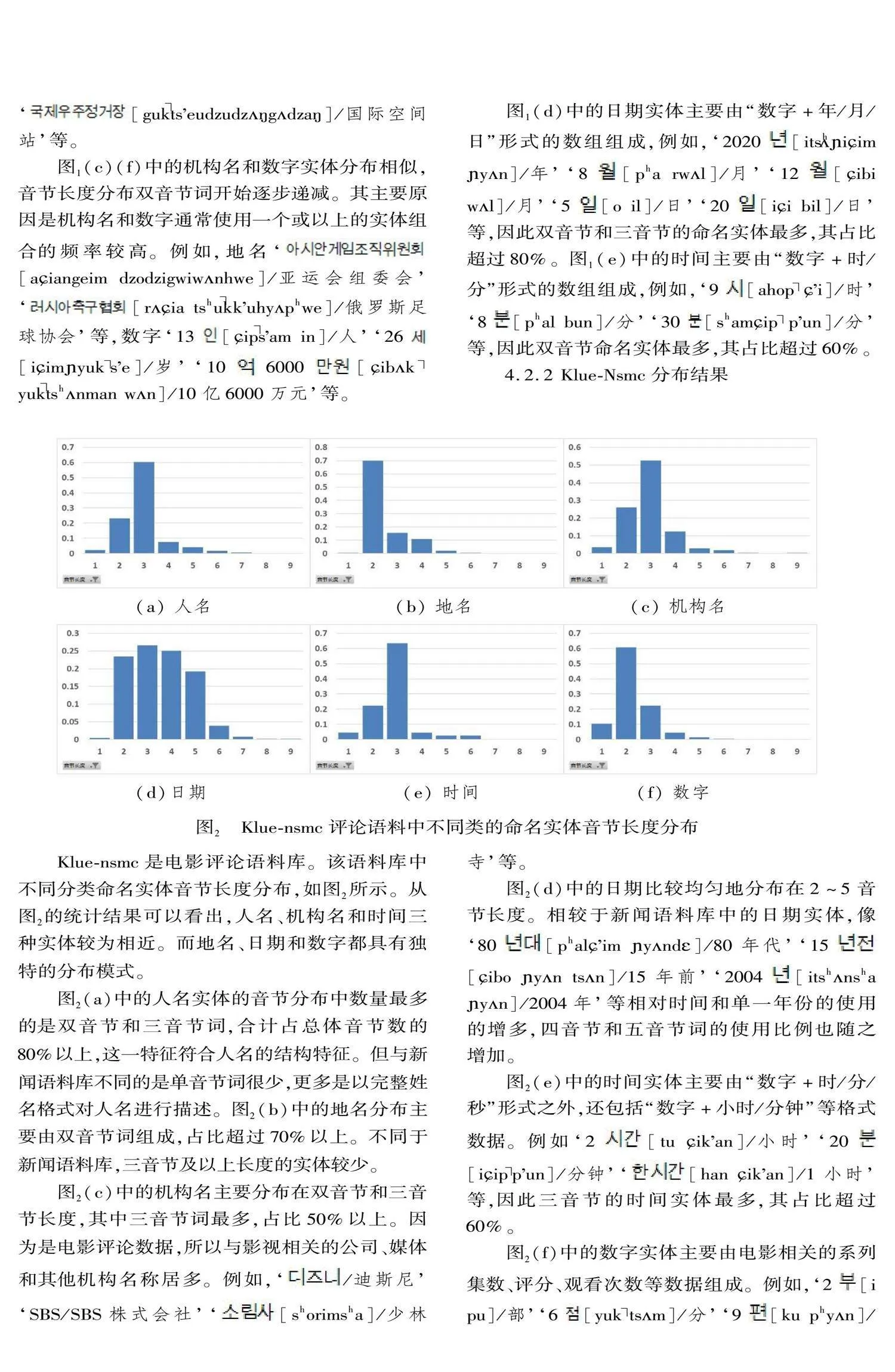
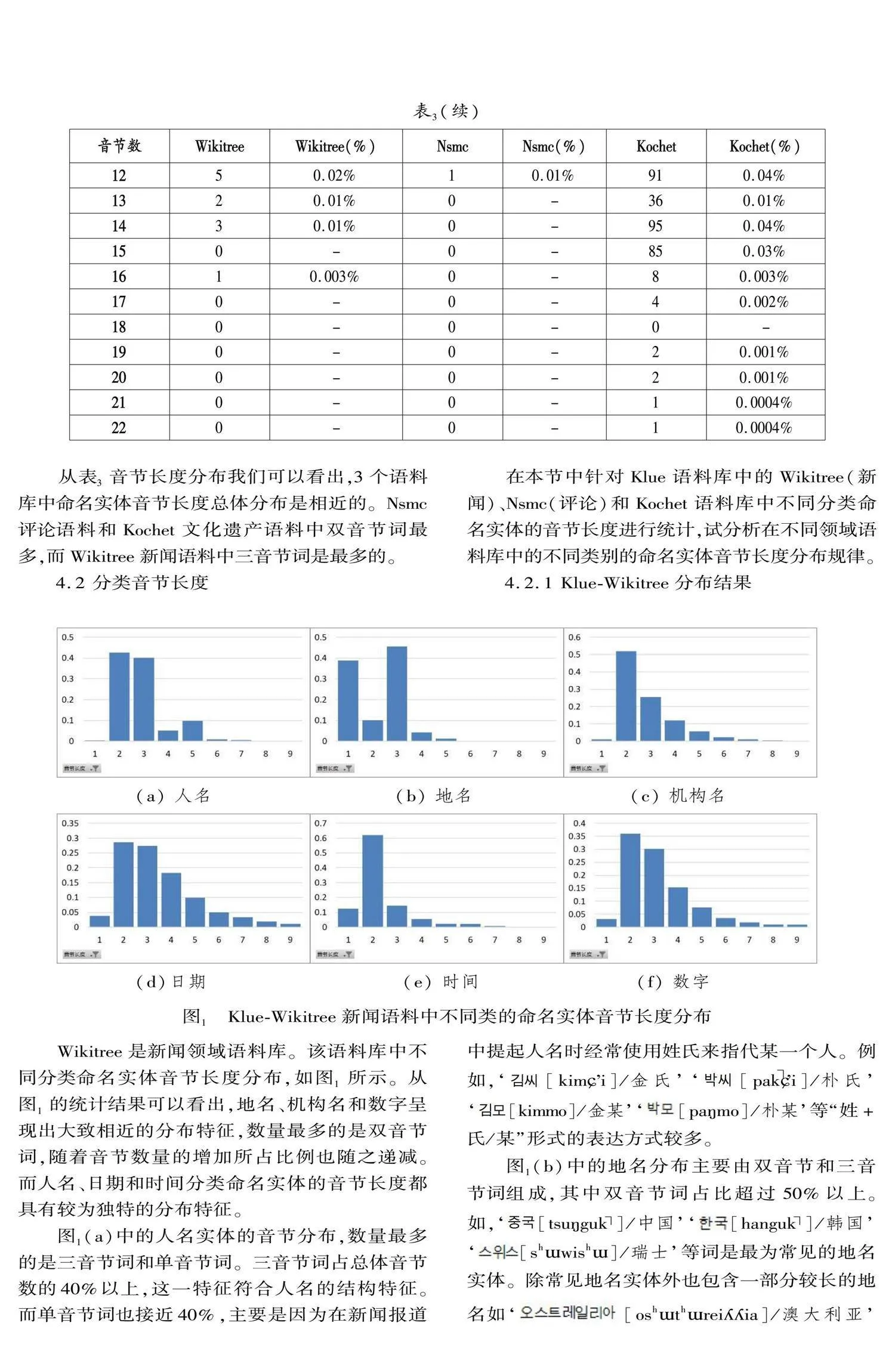
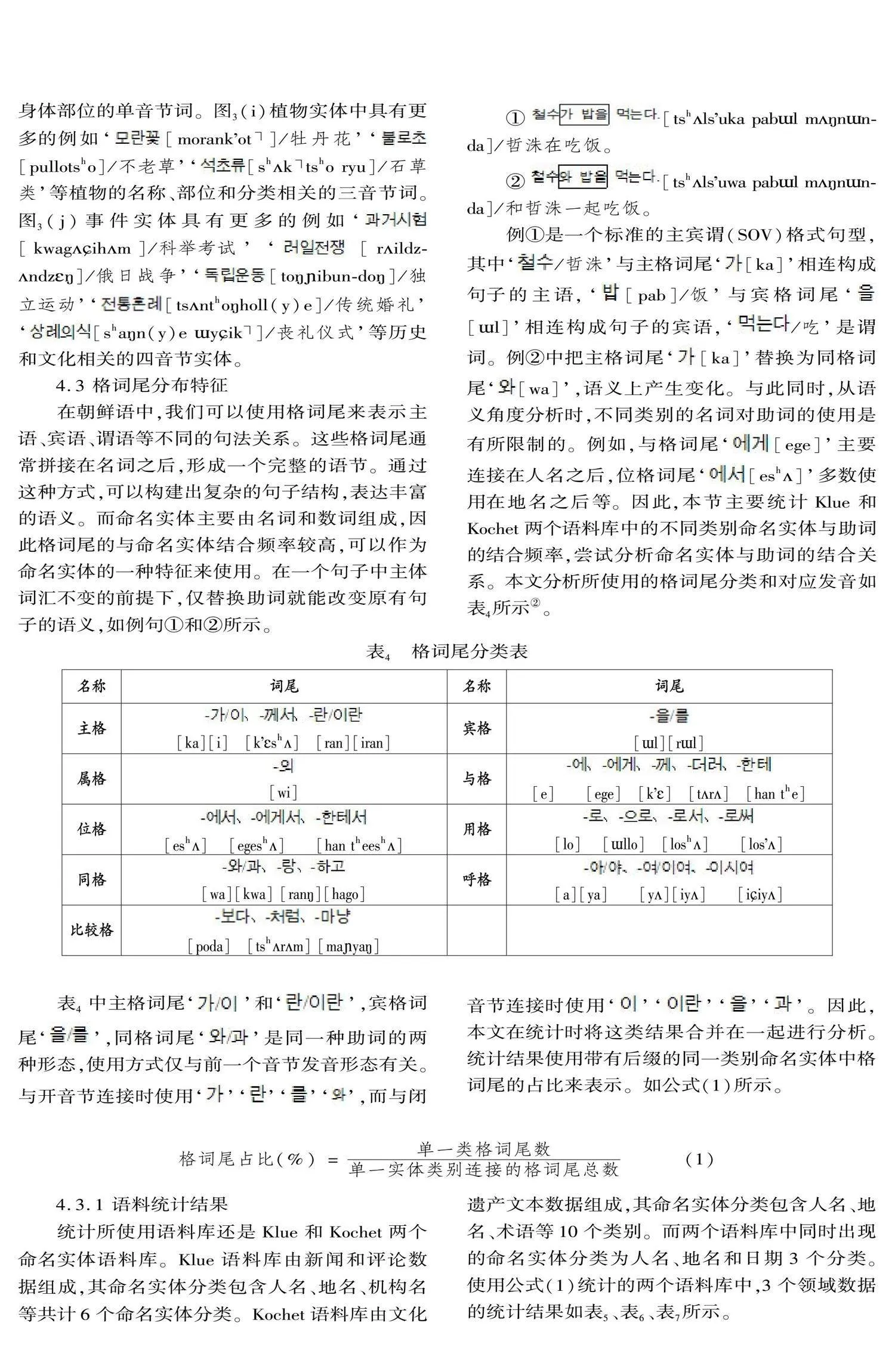
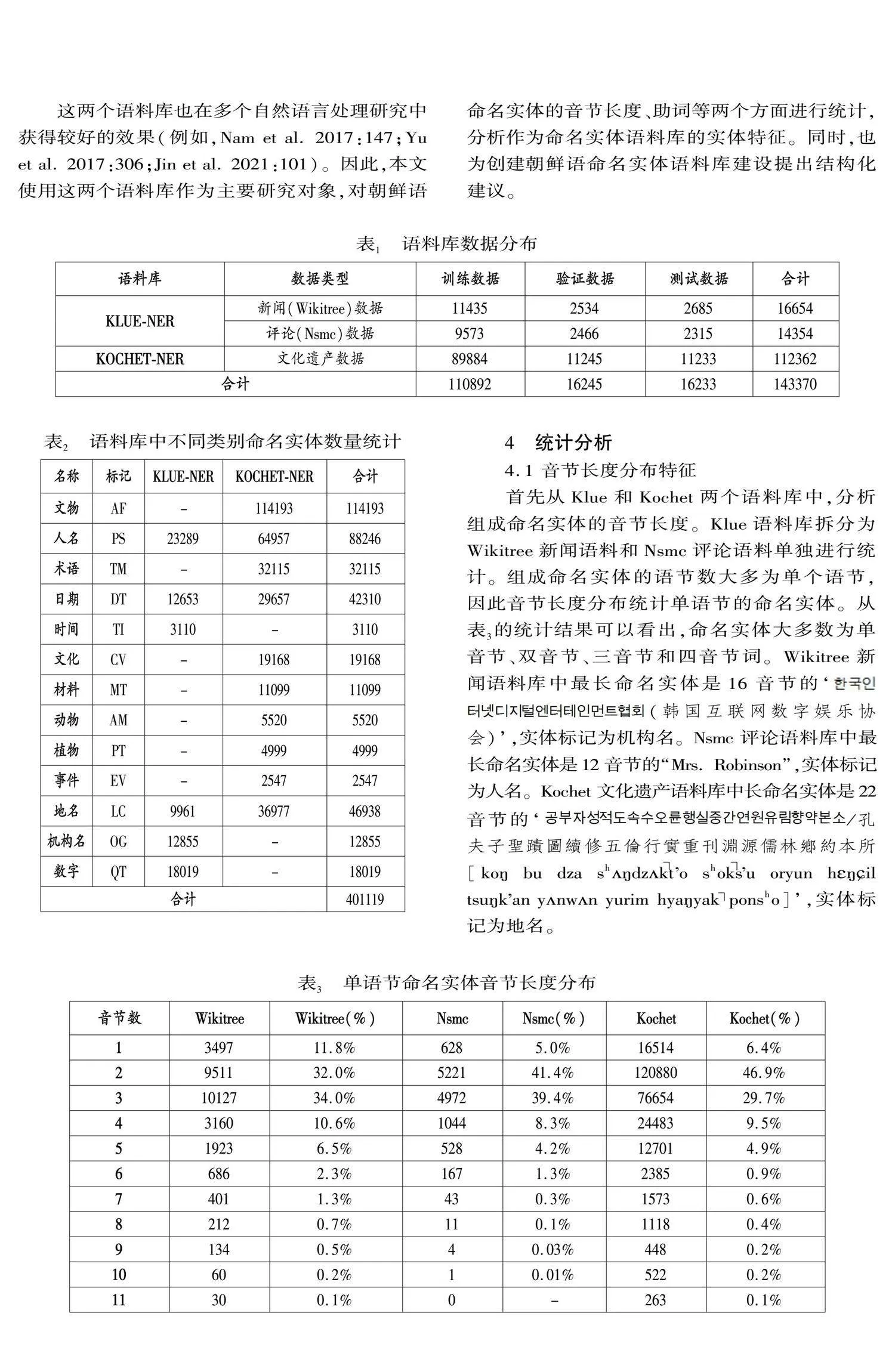
目前在自然語言處理領域所使用的語料庫多為開源語料庫。開源語料庫是一種面向公眾和語言研究人員的可以免費訪問和使用的語料庫,包含大量結構化的可用于研究的不同領域或不同語種語言數據,可用于語言學研究和自然語言處理建模研究。在基于語料庫的語言研究中通常使用字符數、音節長度等數據分析不同語言單位的分布特點。畢玉德等(2019:42),通過統計韓國語新聞語料庫中漢字詞的詞類符數和音節長度等數據考察了漢字詞的總體分布特點。本文使用公開的Klue-ner①和Kochet-ner(Kim et al. 2022:3496)兩個命名實體語料庫,統計組成命名實體的音節長度和助詞數據,從總體分布和不同類別分布兩個角度進行分布特征研究。Klue(Korean Language Understanding Evaluation)組織發布的語料庫包含針對不同任務的8個語料庫,其中Klue-ner是命名實體語料庫,包含人名、地名、機構名、日期、時間、數字等共6個分類的命名實體。Kochet-ner是2022年發布的韓國文化遺產相關文本語料的命名實體標注語料庫,主要有歷史、文物、文化等內容相關的文本數據,包含文物、人名、術語、日期、文化、材料、動物、植物、事件、地名等共10個分類的命名實體。這兩個語料庫都是開源語料庫,是由相關領域專家根據數據構建指南建議進行構建的。其中因命名實體分類數量沒有明確的定義,所以本文使用的兩個語料庫分類也有所不同。
這兩個語料庫也在多個自然語言處理研究中獲得較好的效果(例如,Nam et al. 2017:147;Yu et al. 2017:306;Jin et al. 2021:101)。因此,本文使用這兩個語料庫作為主要研究對象,對朝鮮語命名實體的音節長度、助詞等兩個方面進行統計,分析作為命名實體語料庫的實體特征。同時,也為創建朝鮮語命名實體語料庫建設提出結構化建議。
例①是一個標準的主賓謂(SOV)格式句型,其中‘/哲洙’與主格詞尾‘[ka]’相連構成句子的主語,‘[pab]/飯’與賓格詞尾‘[l]’相連構成句子的賓語,‘/吃’是謂詞。例②中把主格詞尾‘[ka]’替換為同格詞尾‘[wa]’,語義上產生變化。與此同時,從語義角度分析時,不同類別的名詞對助詞的使用是有所限制的。例如,與格詞尾‘[ege]’主要連接在人名之后,位格詞尾‘[esh]’多數使用在地名之后等。因此,本節主要統計Klue和Kochet兩個語料庫中的不同類別命名實體與助詞的結合頻率,嘗試分析命名實體與助詞的結合關系。本文分析所使用的格詞尾分類和對應發音如表4所示②。
表4中主格詞尾‘’和‘’,賓格詞尾‘’,同格詞尾‘’是同一種助詞的兩種形態,使用方式僅與前一個音節發音形態有關。與開音節連接時使用‘’‘’‘’‘’,而與閉音節連接時使用‘’‘’‘’‘’。因此,本文在統計時將這類結果合并在一起進行分析。統計結果使用帶有后綴的同一類別命名實體中格詞尾的占比來表示。如公式(1)所示。
格詞尾占比(%)=單一類格詞尾數單一實體類別連接的格詞尾總數 ""(1)
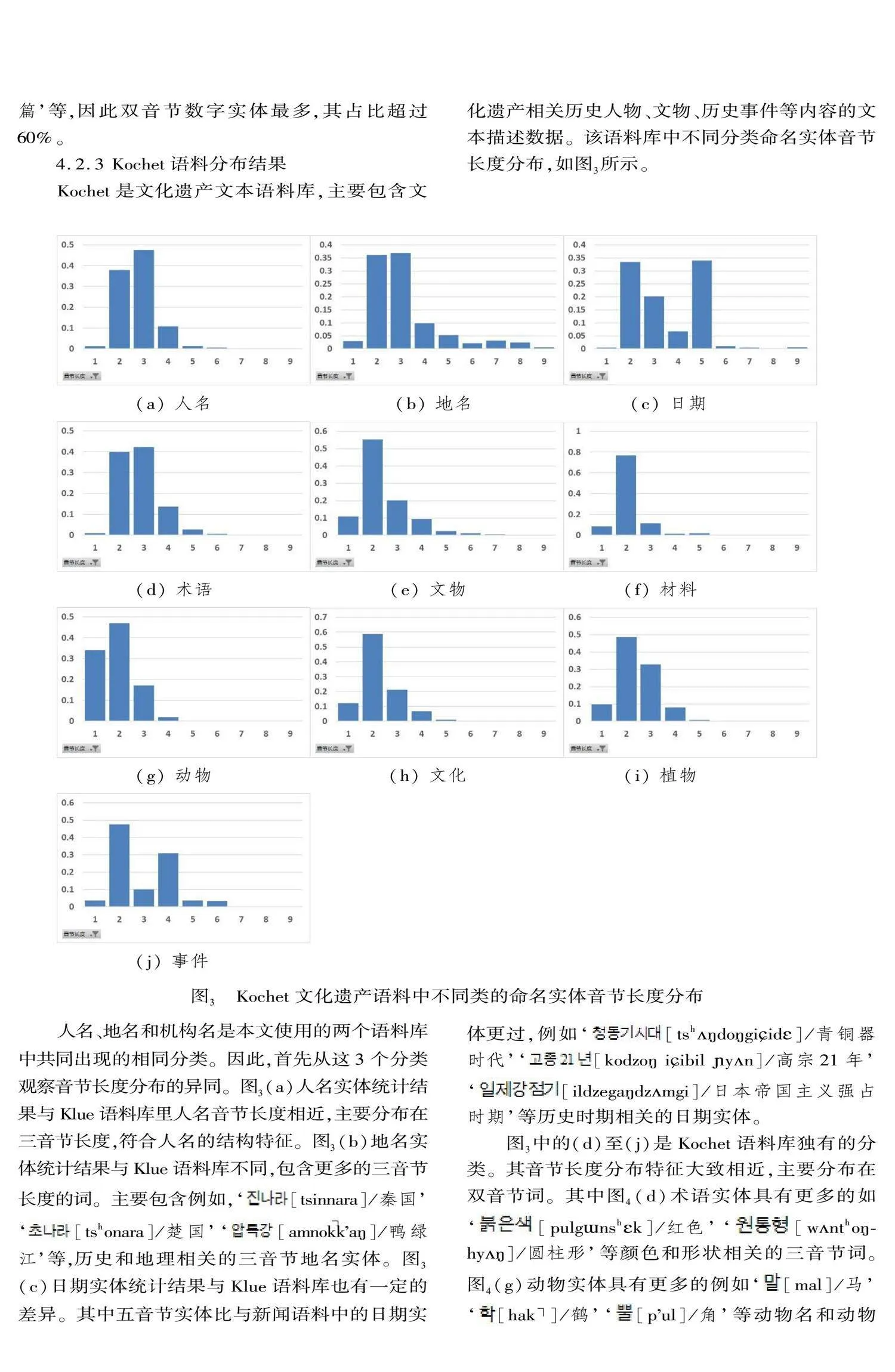
4.3.1 語料統計結果
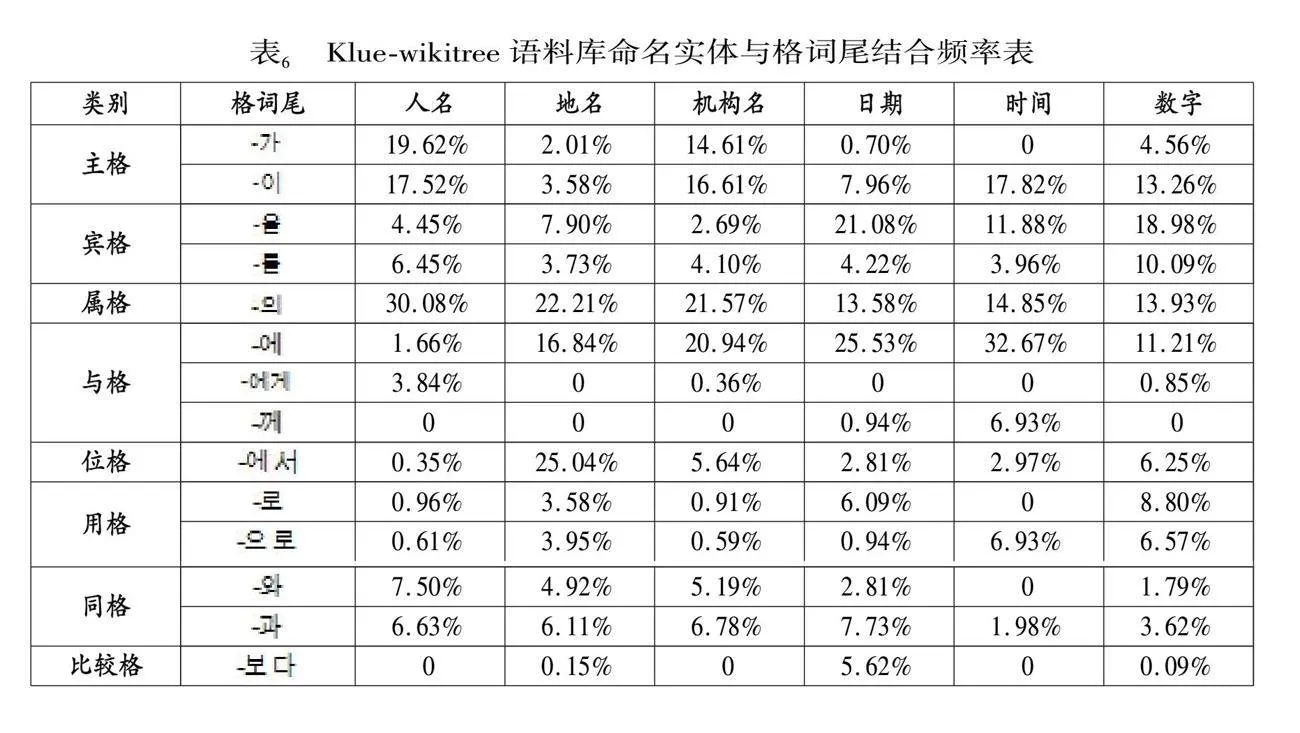
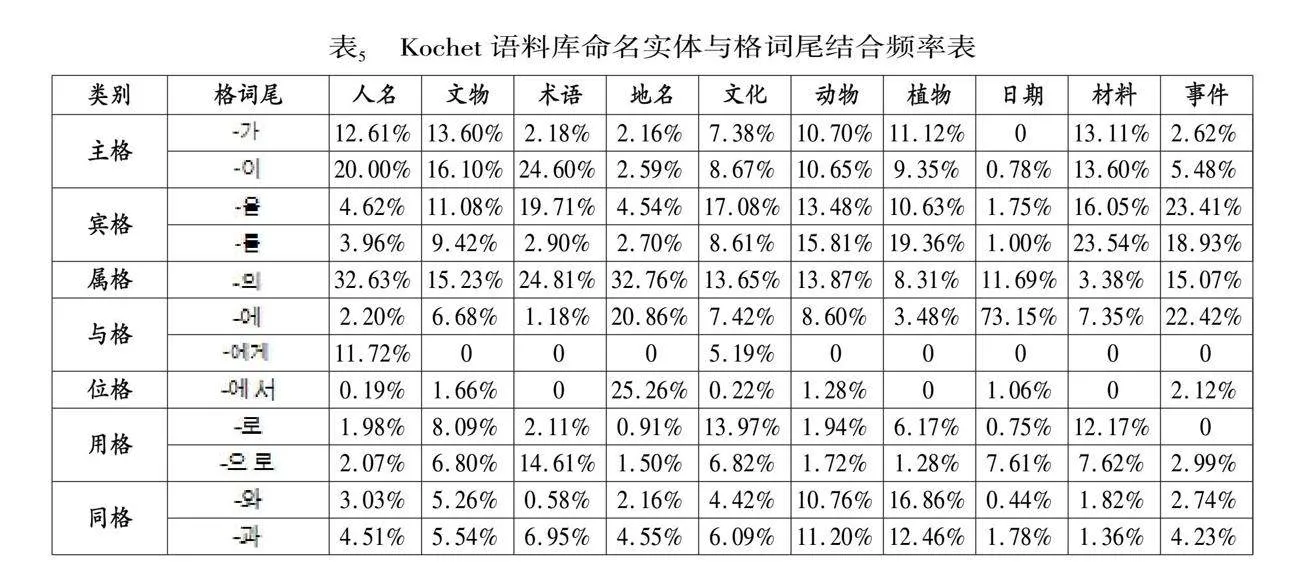
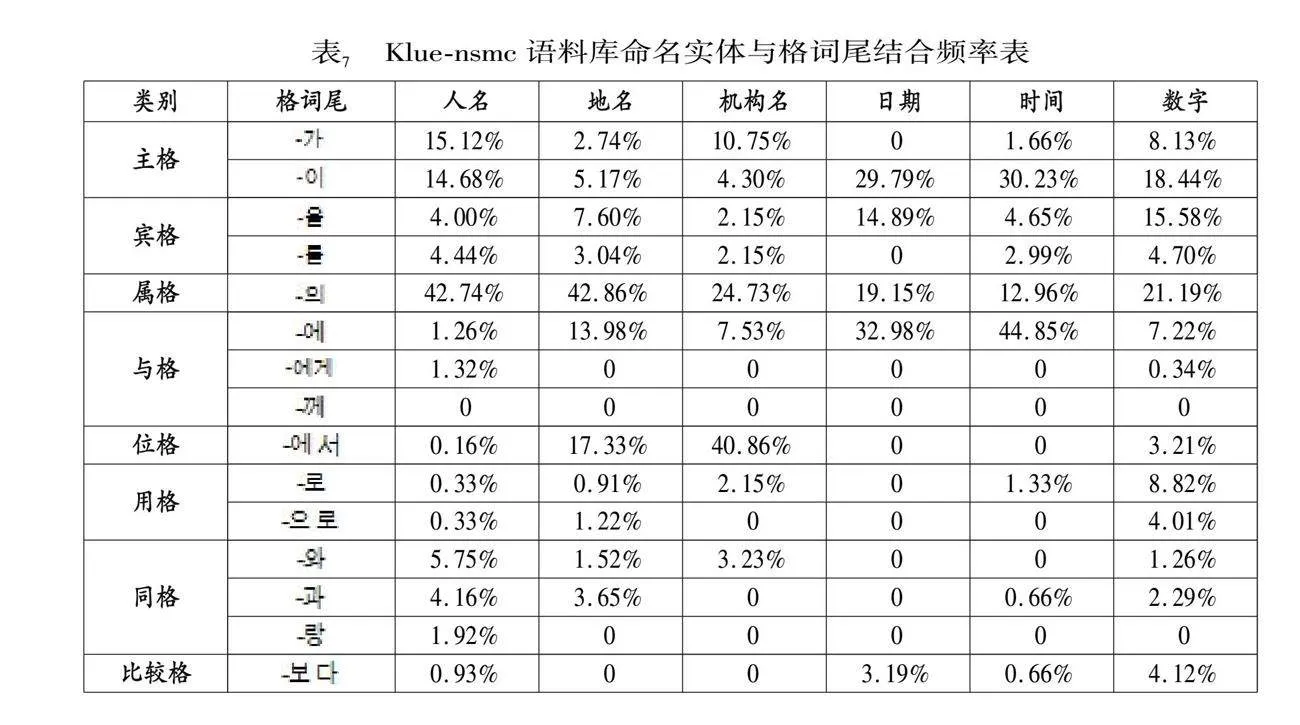
統計所使用語料庫還是Klue和Kochet兩個命名實體語料庫。Klue語料庫由新聞和評論數據組成,其命名實體分類包含人名、地名、機構名等共計6個命名實體分類。Kochet語料庫由文化遺產文本數據組成,其命名實體分類包含人名、地名、術語等10個類別。而兩個語料庫中同時出現的命名實體分類為人名、地名和日期3個分類。使用公式(1)統計的兩個語料庫中,3個領域數據的統計結果如表5、表6、表7所示。
從上述3個表的統計結果可以看出,不同領域中的不同類別命名實體與格詞尾的結合規則也有著一定的規律。主格詞尾中‘’在3個領域語料庫中與人名的結合頻率是最高的,分別是32.6%、37.1%和29.81%。‘’在Kochet語料庫中僅在人名和文物實體之后少量出現,在Klue語料庫中也是僅與人名一起出現。而‘’在3個語料庫中均未出現。賓格詞尾‘’在Kochet語料庫中事件實體中的占比和材料實體中的占比最高,分別為42.3%和39.6%。在Klue語料庫中,日期實體和數字實體與賓格詞尾結合的頻率較好,分別是25.3%和29%,而在Kochet語料庫中,日期實體與賓格詞尾結合頻率較少,只占2.7%。屬格詞尾‘’主要用于表示上下文對象的所屬關系。根據統計結果可以看出,屬格詞尾在所觀察的語料庫中與人名、術語、地名、機構名都有較高的結合頻率,均超過20%,其中Klue-nsmc評論語料庫中與人名和地名結合頻率超過40%。與格詞尾‘’在Kochet語料庫中的日期實體結合的概率達到73.15%,說明與日期的關聯度較高,與地名和事件實體也有20%以上的結合率。在Klue語料庫中也與日期、時間、地名實體有著較高的結合率。因此在區分這類命名實體時具有一定的作用。與‘’結合的命名實體主要集中在人名和文化實體,其他實體大多數都沒有出現。其中‘’較為特殊,在新聞語料庫中有少量與日期和時間實體結合的案例。‘’‘’只有在Klue-nsmc評論語料庫的人名和機構名中少量出現。位格詞尾在3個領域語料庫中的結合相對比較集中。其中‘’在Kochet語料和Klue-wikitree新聞語料中主要與地名實體具有較高的結合率。除此之外,Klue-nsmc評論語料庫中與機構名結合率達到40.9%。而在統計結果中‘’則只與少量人名有結合情況。用格詞尾‘’和同格詞尾‘’在全部實體分類中都有結合,但占比都較低。用格詞尾‘’和同格詞尾‘’的統計數據也較低,只有在人名、文物、術語實體之后有少量結合情況。比較格詞尾統計結果也較少,與Klue語料庫中的日期實體有一定的結合率。
5 結束語
命名實體通常在文章中充當主語、謂語、賓語或狀語,是文章中主要語義表達單位。在自然語言處理過程中命名實體自動識別和自動分類工作是自然語言理解的基礎工作。這一工作流程中需要構建大規模高質量的命名實體語料庫。因此,本文以Klue-ner和Kochet-ner兩個命名實體語料庫作為研究對象,統計和分析了兩個語料庫中的新聞、評論和文化遺產等3個領域文本數據的不同類別朝鮮語命名實體的音節長度特征和格詞尾結合率特征。
文章首先從音節長度分析了Klue-ner和Kochet-ner兩個命名實體語料庫。統計結果表明,總體音節長度在兩個語料庫中的分布相近,主要分布在1~6音節區間,其中分布最多的是雙音節詞。而對于每個命名實體類別都有著較為獨特的音節分布特點。人名主要分布在三音節詞這一特征可以作為朝鮮語命名實體語料庫構建時的實體分布結構參考。
其次從命名實體與格詞尾結合率的角度分析兩個命名實體語料庫。統計結果顯示,不同類別的命名實體和格詞尾都具有不同的結合頻率。在主格詞尾、賓格詞尾、與格詞尾等區分度較高,而且在與格詞尾、位格詞尾、用格詞尾、同格詞尾和比較格詞尾等類型詞尾中的一部分只在特定的命名實體類別之后出現,具有一定的區分度。這些實體和格詞尾的結合方式可以作為命名實體分類時的一種依據。
總之,命名實體識別是自然語言處理領域中的一個重要研究方向。它可以幫助我們更好地理解文本內容,提取出有用的信息。因此,建設更準確的語料庫和提取更多的特征是提高命名實體識別精度的最佳途徑。這些特征可以加快自動化標記命名實體的準確率和效率,從而解決朝鮮語命名實體語料庫規模的不足問題。
注釋
①Park. S.等人發表在arXiv上的開源語料庫KLUE:Korean Language Understanding Evaluation(https://Klue-benchmark.com)
②格詞尾分類和命名參考了金永壽的《中國朝鮮語規范原則與規范細則研究》(166頁)。
參考文獻
畢玉德 趙 巖 安帥飛. 基于新聞語料庫的韓國語漢字詞分布特點研究[J]. 民族語文, 2019(4).‖Bi, Y.-D.," Zhao, Y.," An, S.-F." Distributional Characteristics of" Sino-Korean Words in Korean: A News Corpus-based Study[J]. Minority Language of China, 2019(4).
崔 仙. 多元通和:延邊地區法治文化建設研究[D]. 延邊大學博士學位論文, 2022.‖Cui, X. Harmonious Pluralism: Research on Yanbian District Legislative Culture Development[D]. Yanbian University, 2022.
鄧依依 鄔昌興 魏永豐等. 基于深度學習的命名實體識別綜述[J]. 中文信息學報, 2021(9).‖Deng, Y.-Y. Wu, C.-X.," Wei, Y.-F.," et al. A Survey on Named Entity Recognition Based on Deep Learning[J]. Journal of Chinese Information Processing, 2021(9).
華英楠 畢玉德. 基于依存樹庫的朝鮮語依存距離研究[J]. 外語學刊, 2022(6).‖Hua, Y.-N.," Bi, Y.-D." Research on Dependency Distance of Korean Based on Dependency Tree Bank[J]. Foreign Language Research, 2022(06).
劉 瀏 王東波. 命名實體識別研究綜述[J]. 情報學報, 2018(3).‖Liu, L., Wang, D.-B. A Review on Named Entity Recognition[J]. Journal of the China Society for Scientific and Technical Information, 2018(3).
劉嘉錫. 基于小規模標注的案件要素提取模型[D]. 哈爾濱工業大學碩士學位論文, 2021.‖Liu, J.-X. Case Element Extraction Model Based on Small-scale Annotation[D]. Harbin Institute of Technology, 2021.
盧星華 金 靜." 朝鮮語口語與書面語實詞間相關關系的一元線性回歸分析[J]. 民族語文, 2022(5).‖Lu," X.-H.," Jin, "J. Correlation Between Content Words in Spoken and Written Korean: A Univariate Linear Regression Analysis[J]. Minority Languages of China, 2022(5).
宋官懷. 基于“三一語法”教學體系的對外漢語綜合課詞匯教學行動研究[D]. 浙江科技大學碩士學位論文, 2022.‖Song, G.-H. A Study on Vocabulary Teaching in Integrated Chinese as a Foreign Language Based on “Trinity Grammar” Teaching System[D]. Zhejiang University of" Science amp; Technology, 2022.
吳炳潮 鄧成龍 關貝等. 動態遷移實體塊信息的跨領域中文實體識別模型[J]. 軟件學報, 2022(10).‖Wu, B.-C.," Deng, C.-L.," Guan, B.," et al. Dynamically Transfer Entity Span Information for Cross-domain Chinese Named Entity Recognition[J]. Journal of" Software, 2022(10).
Jin, G.," Yu, Z. A Korean Named Entity Recognition Method Using Bi-LSTM-CRF and Masked Self-attention[J]. Computer Speech amp; Language, 2021(65).
Kim, G., Kim, J., Son, J., et al. KOCHET: A Korean Cultural Heritage Corpus for Entity-related Tasks[A]. Proceedings of the 29th International Conference on Computational Linguistics[C]. Gyeongju: International Committee on Computational Linguistics, 2022.
Li, J., Sun, A., Han, J.," et al. A Survey on Deep Learning for Named Entity" Recognition[J].IEEE Transactions on Knowledge and Data Engineering, 2020(1).
Nam, S., Hahm, Y., Choi, K.S. Application of" Word Vector with Korean Specific Feature to Bi-LSTM Model for Named Entity Recognition[A]. Proceedings of the 29th Annual Conference on Human and Language Technology[C]. Daegu: Human and Language Technology, 2017.
Oh, S.," Lim, C.," Ahn, K.," et al. Syllables-based Named Entity Extraction and Automatic Corpus Construction using Bidirectional Dynamic LSTM[J]. Korean Language Information Science Society, 2017.
Park, S.," Ock, C. CRF Based Named Entity Recognition Using a Korean Lexical Semantic Network[J]. Journal of KIISE, 2021(5).
Park, S.," Moon J.," Kim, S.," et al. Klue: Korean Language Understanding Evaluation[J]. arXiv Preprint arXiv: 2105.09680, 2021.
Sundheim, B. Named Entity Task Definition[A]. MUC-6: Proceedings of" 6th Message Understanding Conference[C]. New York: Message Understanding Conference, 1995.
Yu, H., Ko, Y." Expansion of" Word Representation for Named Entity Recognition Based on Bidire Ctional lstm Crfs[J]. Journal of" KIISE, 2017(3).
定稿日期:2024-12-10【責任編輯 孫 穎】
猜你喜歡
艦船科學技術(2022年15期)2022-09-14 09:21:50
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年19期)2018-11-14 02:37:08
自動化學報(2017年7期)2017-04-18 13:41:09
自動化學報(2017年11期)2017-04-04 02:52:58
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
計算機工程(2015年4期)2015-07-05 08:28:02
機電信息(2015年3期)2015-02-27 15:54:46
機械工程師(2015年10期)2015-02-02 01:13:49
