大語言模型對批評隱喻分析中隱喻識別的應用性研究
2025-01-26 00:00:00于艷春
外語學刊 2025年1期


提 要:批評隱喻分析(critical metaphor analysis, CMA)作為一種語篇的隱喻分析方法,意在揭示語言使用者的潛在意圖,不但可深化我們對語言隱喻的理解,還能揭示隱喻在人類思維和交流中的重要作用。隱喻識別作為CMA分析框架中的一個關鍵步驟,為隱喻闡釋和隱喻說明等后續研究工作提供了堅實基礎,是CMA中極其重要且不可或缺的一部分。本研究首先對CMA中隱喻識別的融合性和樞紐性進行深入討論,探究CMA中隱喻識別的發展特性,熟悉CMA的整個分析框架。同時,針對CMA在隱喻識別中存在的客觀性不足問題,提出嘗試結合大語言模型(ChatGPT)進行隱喻識別的方法,并基于真實研究案例了解該方法的具體實踐操作。通過案例,本研究也對使用大語言模型(ChatGPT)進行隱喻識別過程中遇到的問題進行分析和總結,希望通過合理、恰當地應用技術手段,探索人機協作的最佳方式,以提升隱喻識別的客觀性,完善CMA的分析框架,更深入地進行語篇的隱喻研究。
關鍵詞:大語言模型;ChatGPT;批評隱喻分析;隱喻識別;隱喻闡釋;隱喻說明
中圖分類號:H08 """"文獻標識碼:A """"文章編號:1000-0100(2025)01-0047-10
DOI編碼:10.16263/j.cnki.23-1071/h.2025.01.006
A Study on the Applicability of" Large Language Model(ChatGPT)to
Metaphor Identification in Critical Metaphor Analysis
Yu Yan-chun
(School of" Foreign Languages and Literature, Heilongjiang University," Harbin 150080, China;
School of Foreign Languages, Harbin University, Harbin 150080, China)
Critical Metaphor Analysis (CMA), an approach to metaphor analysis in discourse, aims to reveal the hidden intention of language users, which not only deepens our understanding of linguistic metaphors, but also reveals the important role of metaphor in human thinking and communication. As a key stage in CMA, metaphor identification provides a solid foundation for the subsequent research work such as metaphor interpretation and metaphor explanation, and is an extremely important and indispensable part of CMA. This paper first delves into integration and pivotability of metaphor identification in CMA, to explore the developmental characteristics of metaphor identification in CMA, and to become acquainted with the entire analytical framework of CMA. Then, the lack of objectivity of metaphor identification in CMA is discussed, and a method that attempts to apply Large Language Model (ChatGPT) to metaphor identification in CMA is proposed to address this issue. In the meantime, the specific practical operation of the method is demonstrated based on a real case study. It is found that, in addition to enhancing the objectivity of metaphor identification, ChatGPT mainly plays an enlightening role in the analytical process. At all once, three issues have emerged in the process of metaphor identification applying ChatGPT: First, the results of metaphor identification are not entirely consistent with expectations; Second, the frequency statistics of metaphor keywords are inaccurate; Third, the operation process is repetitive. These issues have prompted us to further ponder. Firstly, LLM (ChatGPT) has not yet possessed fully developed human intelligence, and consequently it may have not been capable of independently completing the identification of complex me-taphor phenomena involving multiple dimensions such as language, culture, and cognition. It needs to be combined with human identification to play an auxiliary and enlightening role. Secondly, the application of technology to empower language research should be determined based on the research objectives and research questions. For frequency statistics tasks, it is possible to consider utilizing relatively mature tools such as Excel or Corpus to showcase their respective strengths. Thirdly, it is necessary to clarify the role that LLM (ChatGPT) plays in metaphor study, so that its potential capabilities can be better harnessed to serve as a copilot in such studies. Thus, it is hoped that, by employing technological means reasonably and appropriately, we can explore the optimal way for human-computer collaboration to enhance the objectivity of metaphor identification, refine the analytical framework of" CMA, and conduct more in-depth study of metaphor in discourse. Meanwhile, it is also hoped that CMA can conti-nue to conduct research across fields such as linguistics, cognitive science, sociology, and computer science, making CMA more satisfactory and providing a more comprehensive analytical perspective and a more objective analytical method for metaphor study in discourse.
Key words: large language models; ChatGPT; critical metaphor analysis; metaphor identification; metaphor interpretation; metaphor explanation
1 引言
批評隱喻分析(critical metaphor analysis, CMA)是由英國學者Charteris-Black(2004:34)2004年提出,不斷發展的一種隱喻分析方法(Charteris-Black 2005, 2014, 2018)。CMA(Charteris-Black" 2018)認為隱喻的語篇功能是人們建立意識形態和修辭動機的基礎,通常會圍繞諸如:為什么這是隱喻,它是什么類型的隱喻,為什么選擇這種類型的隱喻等一系列問題,深入探討隱喻的識別標準、識別單位、類型特點、使用方式和原因、使用目的以及推理效應等相關話題。旨在識別出語篇中的隱喻,并根據使用者的交際目的及語境因素來解釋隱喻選擇的原因,進而揭示語篇中潛在的意識形態、態度和信念。CMA不僅深化我們對隱喻在語言和思維中作用的理解,也為語篇分析提供了新的視角。隱喻識別作為CMA分析框架中的一個關鍵步驟,為隱喻闡釋和隱喻說明等后續研究工作提供堅實基礎,是CMA中極其重要且不可或缺的一部分。不過,由于隱喻的隱蔽性和多義性、動態性和語境依賴性,隱喻識別易受個人經驗和價值觀的影響,因此,如何科學、客觀、有效地識別出語篇中的隱喻是CMA的一個核心問題,也是當前隱喻研究的重點和難點。
從主要依靠直覺法辨別語篇中隱喻的傳統隱喻識別研究,到近些年基于神經網絡(Do Dinh, Gurevych" 2016)、自然語言學習(朱嘉瑩等" 2020)等自然語言處理(natural language processing, NLP)的計算隱喻識別研究,語篇中的隱喻識別或者因識別過程的強主觀性而受到質疑,或者因技術的強專業性而難以付諸實踐。而Pragglejaz Group(2007:3)提出的MIP隱喻識別程序因操作相對簡易,一經提出便成為隱喻識別的首選方法,不過在實踐操作中其存在的詞匯單元劃分與計數標準不一等問題也較為明顯。為此,Steen et al.(2010:25-42)提出對MIP進行改良補充的MIPVU. MIPVU除了對隱喻識別的詞匯單元進行詳細劃分說明外,還提出對間接隱喻、直接隱喻和隱性隱喻的識別。這種細化隱喻的識別方法雖然有助于隱喻研究的縱深方向發展,但同時也增加了隱喻識別的難度和復雜度,而且隱喻識別的主觀性問題一直存在,因此,真正運用MIPVU的隱喻研究目前國內還較少見。隨著自動語義分析工具Wmatrix(Rayson 2008:519-549)的開發,部分學者(如孫亞 2012,陳朗" 2022)開始采用Wmatrix與MIP或MIPVU相結合的方法來識別語篇中的隱喻,減少隱喻識別的主觀性。不過,Wmatrix在語境義和基本義的區分上仍需要人工進行判定,而且其預設的始源域范疇可能會導致新奇隱喻的遺漏。CMA作為一種普遍運用的語篇隱喻分析方法,對隱喻識別同樣傾注了大量筆墨,形成具有特色的隱喻識別方法。本研究將基于對CMA中隱喻識別方法的討論,探究CMA中隱喻識別的發展特性以及可能存在的局限性,并針對存在的問題嘗試提出解決方法,同時,基于真實研究案例了解該方法的具體實踐操作,以完善CMA的分析框架,更深入地進行語篇的隱喻研究。
2 CMA中隱喻識別的融合性和樞紐性
在批評話語分析(critical discourse analysis, CDA)影響下應運而生的CMA,基于概念隱喻理論(Conceptual Metaphor Theory, CMT)(Lakoff, Johnson 1980)的隱喻思維主張,認為隱喻源自人類的創造力,對不同現象之間關系的新奇語言編碼、對刺激新的理解方式有啟發作用,是思維和行動的新方式(Charteris-Black" 2004:21)。通過對隱喻的批判性分析,CMA將認知與包含歷史和文化知識的語言資源整合,增加語篇說服力的同時,揭示語言使用者的潛在意圖。可見,融合性是CMA的一個顯著特性,它不僅貫穿于CMA的整個研究過程,更是滲透于CMA的隱喻識別階段。通過運用融合方法識別隱喻,CMA實現在隱喻研究領域的新突破。同時,隱喻識別作為CMA(Charteris-Black" 2018)中連接語境分析與隱喻闡釋和隱喻說明的關鍵環節,將語境提供的必要背景信息整合到隱喻的理解和分析中,彰顯出隱喻識別的樞紐性。
2.1 CMA中隱喻識別的融合性
CMA中隱喻識別的融合性主要體現在理論和技術上的融合。首先,作為理解語言、思維和社會之間復雜關系的重要手段,CMA(Charteris-Black 2004:21, 2005:14)認為隱喻具有潛在的語言、語用和認知特征,隱喻識別需要考慮語義、語境和跨域映射,因此,CMA結合語義學、語用學和認知語言學,提出依據某一個單詞或短語是否由于使用的語義域發生變化而導致語言、語用、認知三個層面的不協調(incongruity)或語義張力(semantic tension)來判斷是否為隱喻的語言、語用、認知三個標準(Charteris-Black" 2004:21-35),體現出CMA中隱喻識別的理論融合。其次,CMA在語料庫的推廣應用及社會科學的影響下,借助語料庫技術,提出運用人工分析語篇樣本識別候選隱喻(candidate metaphors)與機讀大型語料識別隱喻相結合的兩步隱喻識別法(Charteris-Black" 2004:34)。該方法將隱喻識別從傳統的直覺法轉向結合語料庫的社會實證視角,不但打破長久以來僅依靠人工識別隱喻的限制,也補充了隱喻研究的實證證據,是21世紀初隱喻研究的一個創新和突破,體現了CMA中隱喻識別的技術融合。
2.2 CMA中隱喻識別的樞紐性
CMA中隱喻識別的樞紐性凸顯了隱喻識別在CMA中的核心地位和連接作用。一方面,隱喻識別不僅是CMA分析過程中的基點,也是驅動整個分析過程的核心動力,隱喻識別的準確性直接影響隱喻闡釋和隱喻說明的深度和廣度。另一方面,作為CMA(Charteris-Black" 2018)四步分析框架的一個中間環節,隱喻識別能夠確保研究的連貫性,使得從語境分析到隱喻闡釋再到隱喻說明形成一個有邏輯且相互支撐的分析鏈條。
具體來說,作為研究起點,語境分析通過在相關社會語境下對某一特定話題的分析,提出有關隱喻的研究問題。隱喻識別則結合語境信息識別出語篇中的隱喻。一旦識別出隱喻,CMA便運用CMT和概念整合理論(Conceptual Blending Theory, CBT)(Fauconnier, Turner 2002),進一步探討隱喻所傳達的隱喻意義、概念表征和評價意義,以及隱喻搭配或隱喻與其他語言形式互動所形成的積極評價或消極評價(Charteris-Black" 2005:22-23)。之后,CMA在社會語境基礎上,運用目的隱喻(purposeful metaphor)(Charteris-Black" 2012)和社會認知(van Dijk 2008)概念從說話者和受眾兩個互補視角對隱喻選擇進行解釋說明,從而將隱喻的深層含義和意識形態聯系起來。CMA(Charteris-Black" 2018)認為隱喻是出于某些現實目的而進行的語言交際,包括修辭目的(rhetorical)、啟發性目的(heuristic)、謂詞評價目的(predicative)、移情目的(empathetic)、美學目的(aesthetic)、意識形態目的(ideological)和神話目的(mythic)等動態互動的多個目的,它們之間通常由一個主要動機驅動,其他動機輔之。在解釋說明某個特定隱喻的隱喻功能時,會受到更廣泛社會背景的影響,而這恰好是最初研究問題的動機,因此可能會引發新一輪的隱喻識別,也可能通過積極或消極表征開始新的隱喻闡釋循環。由此表明,CMA的語境分析、隱喻識別、隱喻闡釋、隱喻說明四步驟之間雖然是依次描述的,但同時也是遞歸的。
3 CMA中隱喻識別客觀性的不足及大語言模型(ChatGPT)的應用
隨著實踐應用的推廣,CMA中隱喻識別的局限性逐漸顯露,面臨著隱喻識別客觀性不足的挑戰。而隨著人工智能(artificial intelligence, AI)技術的飛速發展,大語言模型(large language models, LLMs)為我們提供新的視角和工具。
3.1 CMA中隱喻識別客觀性的不足
CMA中隱喻識別客觀性的不足主要源于隱喻識別標準不夠細致以及缺乏科學理據。首先,CMA雖然提出從語言、語用和認知三個維度進行隱喻識別,也將單詞尤其是短語作為隱喻識別的語言單位,但卻沒有對此作出詳盡說明,僅憑借“語義不協調或語義張力”來判斷是否為隱喻,而對語義張力的判斷又帶有明顯的主觀性,會被質疑為一種“有依據的直覺”(Deignan 1999:180)。因此,在實際操作中可能會因人工識別標準不一而影響研究結果的可信度。其次,發展的CMA(Charteris-Black" 2018)通過摒棄借助語料庫識別隱喻的兩步法,提出強調識別隱喻類型的五步隱喻識別法,彌補了之前可能由于某些隱喻關鍵詞的遺漏而導致隱喻識別不全面的缺陷,但是,CMA對隱喻類型的劃分標準缺乏科學依據和理據說明,僅依據一個隱喻在100個語料庫詞條樣本中出現的次數來確定其為新奇隱喻(novel me-taphor)(少于5次的)、規約隱喻(conventional me-taphor)(5次至50次的)還是固定隱喻(entrenched metaphor)(超過50次的)。該識別標準的實際效用及科學性值得商榷。另外,CMA雖然在五步隱喻識別法中提出由幾位隱喻學者分別進行隱喻識別來增加研究的可信度,但這種完全依賴人工識別隱喻的過程,難免會存在主觀性問題,影響后續隱喻闡釋及隱喻說明的準確性。因此,如何提升CMA中隱喻識別客觀性的問題再次成為討論的焦點。
3.2 大語言模型(ChatGPT)應用于CMA中的隱喻識別
數智時代,隨著計算語言學、NLP及AI領域研究的重大進展,特別是隨著LLMs對傳統NLP流水線(pipeline)范式的顛覆和取代(袁毓林" 2024a:3)以及LLMs在語言理解、語言生成、語言翻譯以及文本分類等方面取得的巨大進步,語言的多語義識別僅通過輸入適當的提示語(prompt)(程兵" 2023),便可較好地完成任務。因此,可以嘗試突破僅依靠人工的方式,借助LLMs對隱喻進行識別。
3.2.1 ChatGPT應用于CMA中隱喻識別的可行性
LLMs的標志性模型是2022年OpenAI推出的ChatGPT,從初次亮相到幾次迭代更新,ChatGPT被廣大用戶進行過各種測評(焦建利等" 2023:21),例如,通過對包括ChatGPT-3.5在內的16個LLMs進行文本翻譯和標題生成等語言處理任務的評測,ChatGPT-4呈現的語義效果最佳(趙雪等 2023),不但指標穩定性方面能夠保持客觀一致(李春濤等" 2024),而且還能夠識別出語篇中的隱喻、轉喻、夸張等(秦洪武 周霞" 2024,許家金等" 2024)。最重要的是,ChatGPT在語義理解和常識推理方面有著卓越表現(袁毓林" 2024b:62),其語言使用能力在很大程度上和人類接近(袁毓林" 2023:649)。況且,從理論上講,AI語言模型的研究目標與人類語言學的研究目標并不抵觸,可以互相補充,因為前者是為人類自然語言建立可計算的數學模型,后者是用以揭示人類自然語言的結構、功能和發展規律(袁毓林" 2024b:50),因此,可以嘗試將ChatGPT應用于CMA中進行隱喻識別。
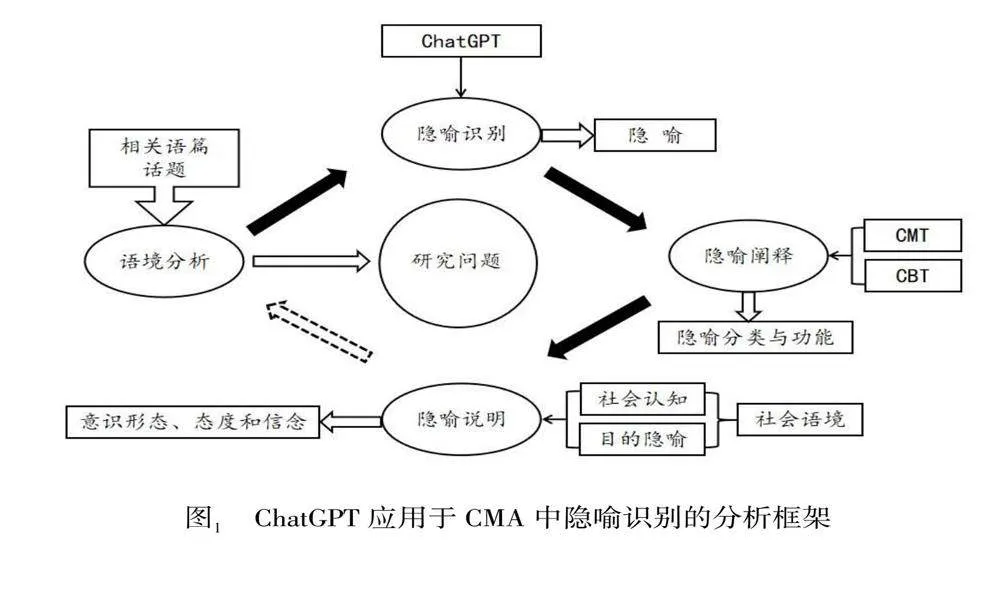
在CMA中結合ChatGPT進行隱喻識別,不但能夠提高隱喻識別的客觀性和工作效率,還能夠促進隱喻研究的創新和發展。首先,ChatGPT是通過大規模文本數據預訓練來學習隱喻遵循的特定語言模式,因此,在執行任務時能夠減少由于個人經驗、情感或偏見帶來的偏差,減少個體差異的影響,從而提高隱喻識別的客觀性;其次,ChatGPT通過其強大的自然語言處理能力,能夠快速處理大量文本數據,自動識別出語境中的隱喻性語言結構,從而極大地節省人力和時間,而且,ChatGPT一旦訓練完成,對于相同的語言結構會產生一致的結果,這不但能夠確保隱喻識別的一致性,為隱喻研究提供更加可靠的數據基礎,同時,也提高了隱喻識別的效率;再次,ChatGPT是在不斷優化和迭代升級中通過持續學習來適應新的語言現象和隱喻表達,這種動態更新能夠確保ChatGPT對隱喻識別的時效性和適應性,從而促進隱喻研究的創新和發展。圖1為ChatGPT應用于CMA中隱喻識別的分析框架。
3.2.2 ChatGPT應用于CMA中隱喻識別的關鍵點
在CMA中結合ChatGPT進行隱喻識別時,提示語的輸入是非常關鍵的一個環節。它是研究者與ChatGPT對話交互的起始點,直接決定隱喻識別結果的范圍和深度。因此,編寫合理準確、符合規范的提示語是提高ChatGPT識別結果質量和品質的關鍵。
首先,要明確任務目標。清晰明確的提示語能夠幫助ChatGPT理解用戶需求,從而避免因誤解而產生錯誤,減少出錯率,因此,要清晰明確地表達希望ChatGPT執行的任務,例如,“請基于Lakoff和Johnson的隱喻定義幫助識別出下面語篇中的隱喻性表達。Lakoff和Johnson認為,隱喻是人類思維的一種方式,是通過兩個概念域之間不同角色的對應,從一個概念域(始源域)映射到另一個概念域(目標域)的過程,隱喻性表達是實現這種跨域映射的語言形式(詞、短語或句子)。”通過在提示語中運用專業術語,還能夠向ChatGPT明確指示所需分析的領域和目標。其次,要提供足夠的上下文信息。隱喻的理解往往依賴于豐富的上下文,因此,向ChatGPT提供足夠的背景信息,可以幫助它更準確地識別和解讀隱喻。同時,也可以提供具體的文本片段作為示例,幫助ChatGPT更好地理解隱喻識別的具體要求。再次,要適當地調整交互。作為人機交互方式上的“革命性變化”(焦建利等" 2023:21),ChatGPT與研究者之間的多輪次對話交互成為一種常見模式,因此,根據ChatGPT的輸出結果,對于需要更深入的解釋或對某一解釋有疑問時,要調整提示語,或通過提出更多問題以及提供更多信息繼續與ChatGPT進行交互式討論,使其輸出的回應盡量達到滿意結果。總之,提示語在ChatGPT執行任務時至關重要,提示語的質量直接影響最終的分析結果,恰當合理的提示語是輸出較好隱喻識別結果的關鍵點。
4 研究案例
為全面解析ChatGPT應用于CMA中隱喻識別的操作過程,本文以樊登2024全民閱讀大會的演講(以下簡稱F演講)為例進行說明。
4.1 語境分析
全民閱讀自2014年開始,連續10次被寫入政府工作報告。《中華人民共和國國民經濟和社會發展第十四個五年規劃和2035年遠景目標綱要》明確指出,要“深入推進全民閱讀,建設‘書香中國’”。全民閱讀大會由此產生,旨在推動全民多讀書,讀好書,正如帆書一直倡導的“人生如海,好書如帆”。帆書,原名為樊登讀書,源于樊登在2013年發起的樊登讀書會,于2023年更名為帆書,通過精選好書與深入淺出的解讀方式,引領閱讀新模式,響應國家全民閱讀號召。樊登也于2019年開始,每年都會進行相關主題的演講。根據百度百科,截至2022年9月,帆書APP總注冊用戶數突破6000萬。今年,樊登繼續在全民閱讀大會上作了題為《答案在書里》的演講,一以慣之地倡導多讀書、讀好書。對此話題,在本次演講中樊登使用了哪些隱喻?這些隱喻有何功能?為何使用這些隱喻?本文擬圍繞這3個問題展開討論。
4.2 隱喻識別
CMA對隱喻的識別標準是基于語言、語用和認知三個層次的標準,因此,在ChatGPT-4o的對話框內可以輸入提示語“Can you annotate the metaphor cases in the following text according to the criterion of metaphor? And please classify source domain and target domain respectively in the following text. A metaphor is a linguistic representation that results from the shift in the use of a word or phrase from the context or domain in which it is expected to occur to another context or domain where it is not expected to occur, thereby causing semantic tension. It may have any or all of the linguistic, pragmatic and cognitive characteristics. Here is the text:”及F演講語篇,并對上述問題進行多輪對話交互,得到如圖2例示的隱喻識別結果。通過與人工識別結果比對修正后,得到隱喻句共112個,隱喻關鍵詞共73個,隱喻關鍵詞包括隱喻載體和適用于隱喻載體的表達,由此確定隱喻載體。
繼續輸入提示語“Please classify the following expressions according to:自然、人及人體、健康與疾病、動物、植物、食物、建筑、工具、機器、旅行、運動與游戲、演出、沖突、繪畫、教學、熱和冷、光和暗、力、顏色、宇宙、經貿及其他”及確定的隱喻載體后,得到隱喻始源域的歸類結果如圖3例示。隱喻始源域的分類標準是參考K?vecses(2010:18)列出的13類常見隱喻始源域來源,并結合《現代漢語分類詞典》確定。
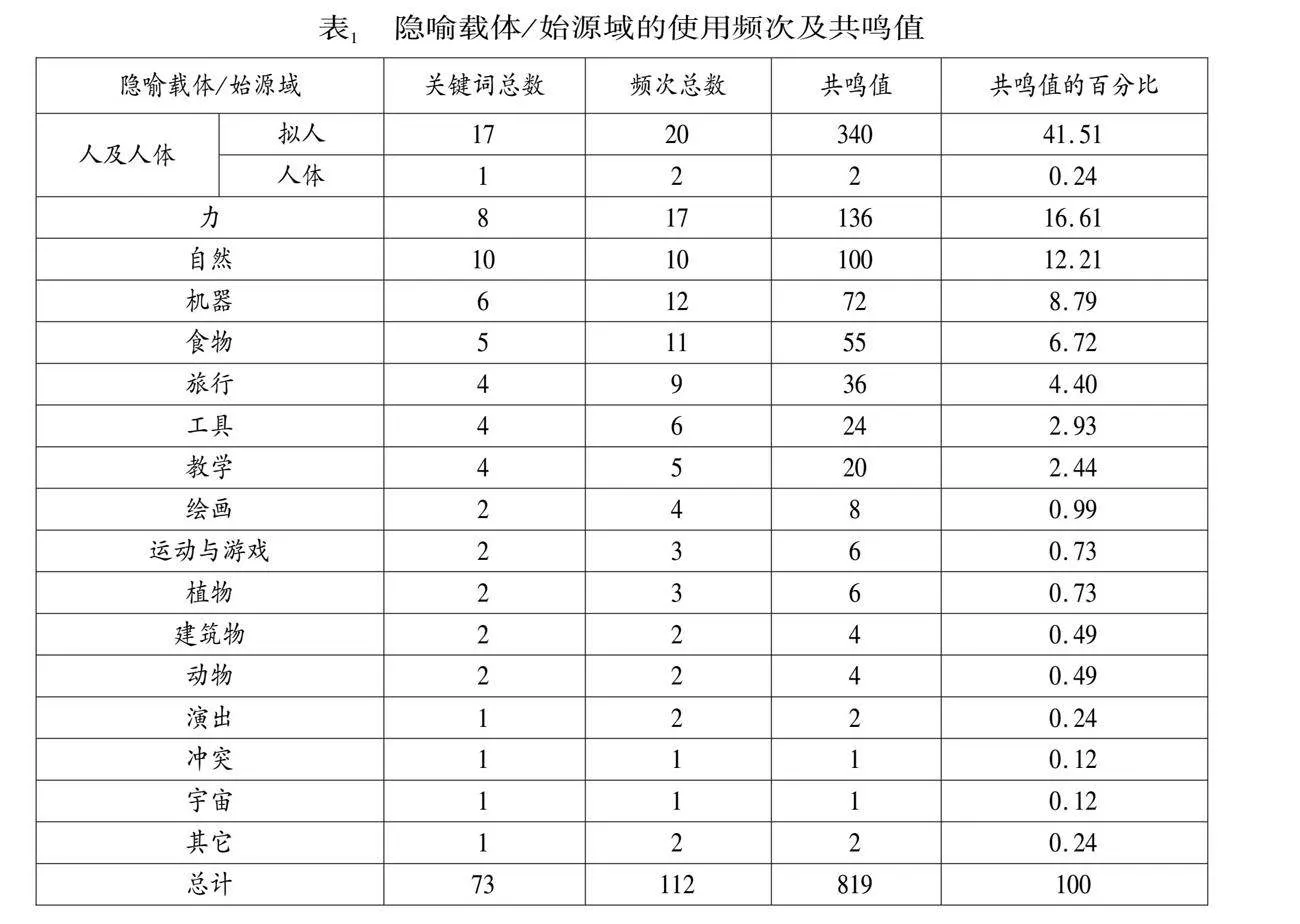
通過查閱詞典,最后識別出的隱喻類別共16類(見表1),像Charteris-Black(2004, 2005)在分析政治演講時所識別出的諸如沖突隱喻、演出隱喻、動物隱喻、建筑物隱喻等,在F演講中也都被識別出,只是比重稍低。而共鳴值位居前5位的分別是擬人隱喻、力隱喻、自然隱喻、機器隱喻及食物隱喻。隱喻始源域的共鳴值(resonance of source domains)(Charteris-Black" 2004:89)是用于衡量始源域生產力的一個參數,由隱喻關鍵詞的類型之和乘以隱喻關鍵詞的頻次之和得出。
4.3 隱喻闡釋
作為一名倡導多讀好書的閱讀運動發起者,樊登的演講均是圍繞與閱讀相關的主題展開,本次演講的主題主要包括:閱讀與冪次法則、冪次法則與健康、冪次法則與大腦等。根據表1,F演講圍繞各主題運用豐富的隱喻,來揭示演講者的思想、觀點和信念。
4.3.1 閱讀與冪次法則
在F演講開篇,讀書便被映射為物理學中的冪次法則(例①),冪次法則的累積效應同時也映射至讀書日積月累帶來的影響。對于冪次法則的作用,F演講運用隱喻關鍵詞“主宰”和程度副詞“幾乎”(例②)使冪次法則被映射為具有超能力的支配地位,與閱讀、健康、大腦都緊密相關,表達了演講者對冪次法則的積極評價。同時,冪次法則還被描述為一條“曲線”,曲線具有的弧度及連續性映射著冪次法則的高低點及遞進性,使聽眾頭腦中呈現出曲線的輪廓,形成對冪次法則的基本認識。
① 讀書……是物理學當中一個非常重要的現象,叫做冪次法則。
② 冪次法則構成的:y等于n的x次方,這條曲線主宰著幾乎整個自然界……
4.3.2 冪次法則與健康
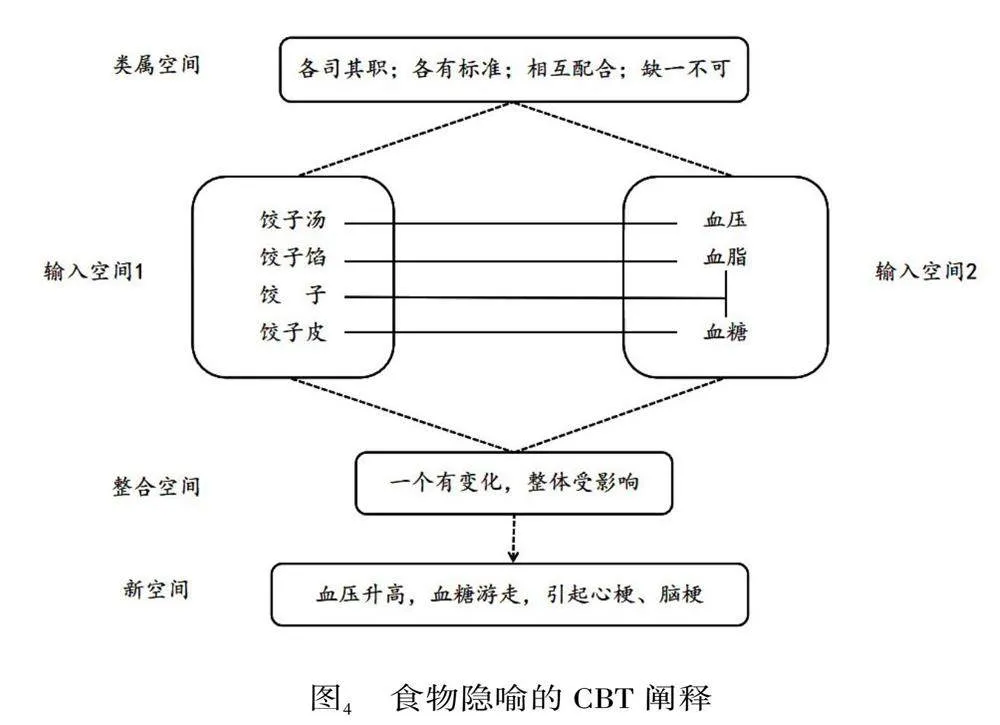
健康對于我們來說是最重要的,在描述冪次法則與健康的關系時,F演講首先運用隱喻搭配:自然隱喻[煙霧是水]①和[煙霧是泥沙]+工具隱喻[血管是橡皮管子]+旅行隱喻[血管是路]為聽眾搭建一個花園澆花的場景。水的運動性和靈活性、泥沙的黏著性和不規則性同時映射在煙霧上,橡皮管子的運送功能和可能存在的堵塞隱患、道路的平坦與否和出行的通暢與否同時映射在血管上。如果煙霧進入血管中,其黏著性會使其沉積在血管壁上,長此以往,會導致血管壁不光滑,影響血液流動。煙霧對血管的傷害通過隱喻搭配清晰地展現出來,也表達了演講者對吸煙行為的消極評價。基于血管的運送功能,受到傷害的血管會導致血糖、血脂、血壓發生異常。F演講運用一系列的食物隱喻將復雜的醫學專業問題生活化。如圖4所示,醫學域與餃子域的各元素之間存在著映射關系,同餃子皮、餃子餡、餃子湯一樣,血糖、血脂、血壓也都有自己的作用,有各自的健康指標,它們共同維護人體的健康,如果一個發生變化,整體都會受到影響。正如,餃子煮漏會導致餃子湯渾濁、餃子餡漂浮,如果血壓升高,血糖血脂便會分離,堵塞在血管的某處,引起心梗、腦梗等疾病。F演講運用我們熟悉的飲食域映射抽象的醫學概念,使其更易理解的同時,指出讀書獲取的醫學知識對于我們健康生活的重要性,表達演講者對讀書的積極評價。
而心梗、腦梗之類疾病的發生同樣與冪次法則有關,特別是讓人聞風色變的癌癥,它們表面上是“斷崖式”的突然發生,其實,都源于累積效應。F演講運用大量的擬人隱喻[細胞是人]描述癌癥的累積源由,將人類的主觀能動性、人類的思維能力及具體人物特征映射至細胞上。細胞便具有人類“大公無私”(例③)、“寬容體諒”(例④)的特征,它們會規律性地生長、死亡,同時也具有人的情感,會“難受”、會“痛苦”(例⑤),如果長期遭受外來傷害,它們也會思考(例⑥)、會“叛變”(例⑦),最終以一種新的形象存在:癌細胞。例⑥中指稱代詞“我”的搭配使用,更強化了細胞的思維能力,使醫學知識具象化的同時,更加深入人心。
③ 我們人類的細胞……最大的特點是“大公無私”,……
④ 比如說你的手被刀子劃破了,把很多細胞直接殺死了,沒關系,它會長好,它會原諒你。
⑤ 假如你……讓這些細胞很難受、很痛苦,它就會突然改變性狀。
⑥ 這群細胞突然之間不想跟你們合作了,我不想做多細胞生物了,我打算做單細胞生物。
⑦ 當我們的細胞在遭受著長期的非致命性傷害的時候,他就決定叛變了。
4.3.3 冪次法則與大腦
F演講從孩子的教育入手談論冪次法則與大腦的關系。同樣地,不當教育行為的累積效應也會導致孩子突然出現心理問題、學習問題,造成教育的失敗。F演講首先運用隱喻鏈,即教育要盯住→盯住就上來→不盯就下去(例⑧),表明嚴格管理的必要性,同時,力隱喻[嚴格監督就是眼睛盯住]與連詞“一……就……”“不……就……”的互動也暗示部分父母雖然重視孩子教育,但卻選擇了錯誤的教育方式,無形中給孩子施加了更大的壓力,而過大的壓力則意味著對大腦的不良影響。容器隱喻[感官系統是容器](例⑨)表明大腦面對過大壓力時,能夠像容器一樣被封閉起來,選擇隔斷與外界的聯系。機器隱喻[感官系統是機器](例⑩)表明感官系統各部分會如同機器般統一選擇開或關。動物隱喻[孩子是野獸](例B11)和擬人隱喻[身體是人](例B12)暗指當孩子在全部感官系統關閉后出現的暴力行徑或自殘行為,這就是不良累積效應。多種隱喻的搭配使用形象描述了孩子在錯誤教育方式下可能產生的不良后果,表明了演講者對部分家長教育方式的消極評價,并以此暗示家長讀書獲取的教育知識對于提升健康教育意識和采取積極教育行為對孩子健康成長的重要性。
⑧ 甚至有很多家長認為,真正有效的教育就是“盯住”,因為一盯住成績就上來,不盯就下去。
⑨ 當一個人覺得很痛苦時,為了自我保護,他會封閉掉所有的感官系統。
⑩ 他身上針對所有快樂的感受器也都被關掉了。
B11 很多校園霸凌的新聞……會有那么多的人像野獸一樣的去打自己的同類。
B12 自殘……會讓他覺得有意義……,他的身體還在愛著他……
為避免教育悲劇的發生,F演講繼續運用旅行隱喻[孩子的成長是旅行]→[孩子頭腦的變化是方向或路徑的轉變](例B13)告誡家長,要提前預知可能發生的事,并及時采取有效措施,以免孩子心理突然發生變化。同時,運用自然隱喻[人腦是微縮的自然界](例B14)提醒家長,孩子的成長是有規律性的,強行干擾會造成意想不到的后果。還運用機器隱喻[人是復雜體系](例B15)再次提醒家長,孩子不是“汽車”,不要試圖“掌控”孩子,要適當的“放手”,給孩子一定的成長空間,只有這樣,孩子的人生之路才能“走好”。最后,F演講運用動物隱喻[信息封閉是信息繭房](例B16)希望聽眾們不做繭房里的繭,突破自己,讀“破圈”之書,做“破圈”之人,表達了演講者對讀書的積極評價和強烈推薦。
B13" 想要讓所有的家長,能提前到冪次曲線拐彎的地方看一眼。
B14 人腦就是一個微縮的自然界。
B15 人的一生屬于復雜體系。
B16 只讀自己喜歡的書,會陷入在一個封閉的信息繭房里邊。
4.4 隱喻說明
通過對F演講中隱喻概念表征及評價意義的分析闡釋,我們可以揭示出演講文本中的隱喻所構建的思想、觀點和信念。
首先,從當前形勢上看,隨著信息技術的快速發展,網絡短視頻、碎片化信息已成為人們日常生活中不可或缺的一部分。面對大量撲面而來、應接不睱的信息,學會甄別尤為重要。而甄別信息所需要的獨立思考能力,除通過經驗、閱歷積累外,讀書培養是最為重要的途徑。F演講運用長期讀書所產生的冪次效應激勵聽眾要多讀好書,讀破圈之書。在幫助聽眾理解兩者之間的關系時,F演講運用擬人隱喻、隱喻搭配以及隱喻鏈,將抽象知識具體化、復雜知識直觀化、專業知識生活化,激活聽眾對閱讀的新認知,調整或擴展聽眾的認知結構,從而深化聽眾對閱讀價值的理解,形成更廣泛的閱讀認同和重視閱讀的社會氛圍,更好地傳達“讀書讓我們更具深度、理性和智慧”的思想。
其次,從隱喻的現實交際目的上看,在F演講中,演講者以隱喻方式激勵聽眾要多讀好書,講述與讀書密切相關的冪次法則故事。在講述花園澆花、包餃子和煮餃子的生活故事時,隱喻將聽眾拉進生活,增添親切感的同時,引起聽眾注意,建立信任感,實現隱喻修辭目的的同時,讓聽眾感受到讀書在獲取知識、內化知識、培養思考能力過程中起到的重要作用,實現其意識形態目的。在講述孩子教育問題時,隱喻將累積效應發生后的悲慘故事展示在聽眾面前,激起聽眾悲傷情緒的同時,也啟發聽眾、激勵聽眾采取積極措施,實現隱喻的移情目的和啟發性目的。在講述細胞故事時,隱喻使用描寫人類動作、情感的動詞和形容詞,例如,“不想”“決定”“難受”等,拉近與聽眾距離的同時也提醒聽眾要避免長期傷害,實現隱喻的謂詞評價目的。而所有故事的講述都是在演講者意識形態目的下進行的神話敘事,即多讀書、讀好書。
通過運用結合ChatGPT的CMA分析F演講,本文將LLM(ChatGPT)運用到CMA的隱喻識別中。我們發現ChatGPT除了提高隱喻識別的客觀性之外,最大助力是對分析過程起到的啟示作用。同時,也遇到3個問題:一是隱喻識別的結果與預期不完全一致;二是對隱喻關鍵詞的頻次統計結果不準確;三是操作過程的反復性。這在某種程度上表明,第一,LLM(ChatGPT)還不具備完善的人類智能(馮志偉" 2024:89),對于涉及語言、文化、認知等多個層面復雜隱喻現象的識別,目前機器尚無法獨立完成,還需要與人工識別相結合,發揮其輔助和啟示作用;第二,運用何種技術賦能語言研究要根據研究目的和研究問題來確定,對于頻次統計類任務,可以運用技術較為成熟的Excel或語料庫等工具來完成,展示其各有所長;第三,要明確LLM(ChatGPT)在隱喻研究中所扮演的角色。LLM(ChatGPT)雖然功能強大,但現階段仍然受控于使用者的指令來完成任務,因此,我們要利用LLM(ChatGPT)的超強能力,同時也要保持自己的特色(Mollick" 2024),使LLM(ChatGPT)在隱喻研究中發揮副駕駛(copilot)作用(袁毓林" 2024c:576),即,研究人員與LLM(ChatGPT)形成伙伴關系,二者全程參與任務,LLM(ChatGPT)可以完成一些重復性的工作,研究人員則專注于更高級別的思考和創新,并運用專業知識和判斷,確保隱喻分析的深度和準確性,同時也通過LLM(ChatGPT)的提示,獲得新觀點,補充或修正自己的結論,實現人機協作的最佳方式。
5 結束語
CMA作為一種普遍運用的語篇隱喻分析方法,不但深化我們對語言隱喻的理解,還揭示隱喻在人類思維和交流中的重要作用。隱喻識別作為CMA分析框架中的一個關鍵環節,發揮著至關重要的作用。本研究首先就CMA中隱喻識別的融合性和樞紐性進行深入討論,了解CMA中隱喻識別的發展特性,熟悉CMA的整個分析框架。同時,針對CMA中隱喻識別客觀性不足的問題,本研究提出在CMA中運用LLM(ChatGPT)進行隱喻識別的解決方法,并基于真實研究案例了解該方法的具體實踐操作。通過案例,本研究也對運用LLM(ChatGPT)進行隱喻識別過程中遇到的問題加以分析和總結,希望通過合理、恰當地運用技術手段,探索人機協作的最優路徑,從而提升隱喻識別的客觀性,完善CMA的分析框架,更深入地進行語篇的隱喻研究。同時,也希望CMA能繼續跨語言學、認知科學、社會學和計算機科學等領域的研究,使CMA更加完善,為語篇的隱喻研究提供更全面的分析視角、更客觀的隱喻識別方法。
注釋
①符號[]為概念隱喻標識。
參考文獻
陳 朗. 從MIP到MIPVU: 隱喻識別的方法、應用與問題[J]. 外語學刊, 2022(5).‖Chen, L. From MIP to MIPVU: Approach, Practice and Issues in Metaphor Identification Procedure[J]. Foreign Language Research, 2022(5).
程 兵." 以ChatGPT為代表的大語言模型打開了經濟學和其他社會科學研究范式的巨大新空間[J]. 計量經濟學報, 2023(3).‖Cheng, B. Artificial Intelligence Generative Content (AIGC) Including ChatGPT Opens a New Big Paradigm Space of Economics and Social Science Research[J]. China Journal of Econometrics, 2023(3).
馮志偉. 從ChatGPT到Sora發展中的術語問題[J]. 中國科技術語, 2024(2).‖Feng, Z.-W. Term Problem in the Development from ChatGPT to Sora[J]. China Terminology, 2024(2).
焦建利 陳 麗 吳偉偉. 由ChatGPT引發的教育之問:可能影響與應對之策[J]. 中國教育信息化, 2023(3).‖Jiao, J.-L.," Chen, L., Wu, W.-W." Educational Issues Triggered by ChatGPT: Possible Impacts and Counter Measures[J]. Chinese Journal of ICT in Education, 2023(3).
李春濤 閆續文 張學人." GPT在文本分析中的應用:一個基于Stata的集成命令用法介紹[J]. 數量經濟技術經濟研究, 2024(5).‖Li, C.-T.," Yan, X.-W.," Zhang, X.-R." Application of GPT in Textual Analysis: An Introduction to A Community Developed Command within Stata[J]. Journal of Quantitative amp; Technological Economics, 2024(5).
秦洪武 周 霞." 大語言模型與語言對比研究[J]. 外語教學與研究, 2024(2).‖Qin, H.-W.," Zhou, X." Large Language Models for Contrastive Linguistics[J]. Foreign Language Teaching and Research, 2024(2).
孫 亞. 基于語料庫方法的隱喻使用研究:以中美媒體甲流新聞為例[J]. 外語學刊, 2012(1).‖Sun, Y. A Corpus-based Approach to Metaphor Use: A Case Study of H1N1 Flu Discourse in Chinese and American Media[J]. Foreign Language Research, 2012(1).
許家金 趙 沖 孫銘辰." 大語言模型的外語教學與研究應用[M]. 北京:外語教學與研究出版社, 2024.‖Xu, J.-J.," Zhao, C.," Sun, M.-C. Applications of Large Language Models in Foreign Language Teaching and Research[M]. Beijing: Foreign Language Teaching and Research Press, 2024.
袁毓林. 超越聊天機器人,走向通用人工智能——ChatGPT的成功之道及其對語言學的啟示[J]. 當代語言學, 2023(5).‖Yuan, Y.-L. Beyond Chatbots and Towards Artificial General Intelligence (AGI): The Success of ChatGPT and Its Implications for Linguistics[J]. Contemporary Linguistics, 2023(5).
袁毓林. ChatGPT等大型語言模型對語言學理論的挑戰與警示[J]. 當代修辭學, 2024a(1).‖Yuan, Y.-L. Challenges and Warnings from Large Language Models like ChatGPT on Linguistics Theories[J]. Contemporary Rhetoric, 2024a(1).
袁毓林. 如何測試ChatGPT的語義理解與常識推理水平?——兼談大語言模型時代語言學的挑戰與機會[J]. 語言戰略研究, 2024b(1).‖Yuan, Y.-L. How to Test ChatGPT’s Performance in Semantic Understan-ding and Common-Sense Reasoning: Challenges and Opportunities of Linguistics in the Era of Large Language Models[J]. Chinese Journal of Language Policy and Planning, 2024b(1).
袁毓林. ChatGPT語境下語言學的挑戰和出路[J]. 現代外語, 2024c(4).‖Yuan, Y.-L. Challenges and Prospects for Linguistics in the Context of ChatGPT[J]. Modern Foreign Languages, 2024c(4).
趙 雪 趙志梟 孫鳳蘭 王東波. 面向語言文學領域的大語言模型性能評測研究[J]. 外語電化教學, 2023(6).‖Zhao, X.," Zhao, Z.-X.," Sun, F.-L.," Wang, D.-B. Performance Evaluation Study of" Large Language Models for the Field of Language and Literature[J]. Technology Enhanced Foreign Language Education, 2023(6).
朱嘉瑩 王榮波 黃孝喜 諶志群." 基于Bi-LSTM的多層隱喻識別方法[J]. 大連理工大學學報, 2020(2).‖Zhu, J.-Y.," Wang, R.-B.," Huang, X.-X.,""" Chen, Z.-Q." Multi-level Metaphor Detection Method Based on Bi-LSTM[J]. Journal of Dalian University of Technology, 2020(2).
Charteris-Black, J. Corpus Approaches to Critical Metaphor Analysis[M]. Hampshire: Palgrave Macmillan, 2004.
Charteris-Black," J. Politicians and Rhetoric: The Persuasive Power of Metaphor[M]. Hampshire: Palgrave Macmillan, 2005.
Charteris-Black, J. Forensic Deliberations on “Purposeful Metaphor”[J]. Metaphor and the Social World, 2012(2).
Charteris-Black, J. Analyzing Political Speeches: Rhetoric, Discourse and Metaphor[M]. Basingstoke amp; New York: Palgrave MacMillan, 2014.
Charteris-Black," J. Analysing Political Speeches: Rhetoric, Discourse and Metaphor(2nd Edition)[M]. Hampshire: Palgrave Macmillan, 2018.
Deignan, A. Corpus-based Research into Metaphor[A]. In: Cameron, L., Low, G.(Eds.), Researching and Appl-ying Metaphor[C]. Cambridge: Cambridge Press, 1999.
Do, Dinh, E.L., Gurevych, I. Token-Level Metaphor Detection Using Neural Networks[A]. In: Klebanov, B., Shutova, E., Lichtenste, P.(Eds.), Proceedings of the Fourth Workshop on Metaphor in NLP[C]. San Diego: Association for Computational Linguistics, 2016.
Fauconnier, G., Turner, M." The Way We Think — Concep-tual Blending and the Mind’s Hidden Complexities[M]. New York: Basic Books, 2002.
K?vecses, Z. Metaphor: A Practical Introduction(2nd Edition)[M]. New York: Oxford University Press, 2010.
Lakoff, G., Johnson," M. Metaphors We Live By[M]. Chicago and London: The University of Chicago Press, 1980.
Mollick, E. Co-Intelligence: Living and Working with AI[M]. WH Allen, 2024.
Pragglejaz Group. MIP: AMethod for Identifying Metaphorically Used Words in Discourse[J]. Metaphor and Symbol, 2007(1).
Rayson, P. From Key Words to Key Semantic Domains[J]. International Journal of Corpus Linguistics, 2008(4).
Steen, G.J., Dorst, A.G., Herrmann, J.B.," Kaal, A.A.," Krennmayr, T.," Pasma, T." A Method for Linguistic Me-taphor Identification: From MIP to MIPVU[M]. Amsterdam: John Benjamins, 2010.
van Dijk, T. Discourse and Context: A Sociocognitive Approach[M]. Cambridge: Cambridge University Press, 2008.
定稿日期:2024-12-10【責任編輯 孫 穎】
