
基于輕量級深度神經網絡的核磁共振波譜降噪
2025-02-20 00:00:00詹昊霖房啟元劉佳偉史曉琦陳心語黃玉清陳忠
物理化學學報 2025年2期
關鍵詞:核磁共振波譜;人工智能;深度學習;譜圖去噪;輕量級網絡
1 引言
核磁共振(NMR)波譜被認為是探測分子結構和提供定量信息的強有力的非侵入性檢測技術之一,因此在生命科學、化學、生物學等領域的應用日益廣泛1–7。然而,由于固有的布居數分布,與其他表征方法8,9 (如:質譜、紅外光譜和拉曼光譜)相比,NMR波譜天然表現出較低的靈敏度。特別是,與質子(1H) NMR相比,這一困境對于異核NMR實驗中那些具有低旋磁比和天然豐度的檢測核更為嚴重,因此限制了其更廣泛的應用。
為解決這個問題,幾十年來已經做出了多種努力以抑制噪聲和提高信號強度。一種直接和常見的方法是增加實驗掃描次數和累加采樣信號,但這導致較長的采集時間,尤其是對于二維(2D)或多維(mD)實驗。另一種常規方法是使用配備超高場磁體10,11和低溫檢測系統12的更先進儀器,但這需要昂貴的成本和較高的研究門檻。此外,多種先進的脈沖序列技術,例如,極化轉移增強不靈敏核(INEPT) 13、核Overhauser增強(NOE) 14等,也已經被提出來實現NMR靈敏度增強,特別是在探測不靈敏分子或原子核時。另外,旨在增強NMR信噪比(SNR)的超極化技術15,16,如動態核極化(DNP) 17–20、自旋交換光泵浦(SEOP) 21,22、仲氫誘導超極化(PHIP) 23,24和自發極化轉移(SEBRE) 25等,已經引起了NMR研究人員的廣泛關注。然而,無論是脈沖序列設計還是超極化技術都需要復雜的實驗設置和熟練的實驗操作人員。
數據后處理是減少噪聲和提高信噪比的一種簡單且經濟有效的替代方案。近來,包括壓縮感知26、低秩Hankel 27以及統計學習28等經典算法在液體NMR波譜去噪方面表現出良好的性能。此外,主成分分析(PCA)方法也通過提取主成分和譜圖分離信號與噪聲,應用于固態NMR實驗的噪聲降低29,30。然而,這些傳統算法的性能通常依賴于所使用的處理參數,這些參數通常需要針對不同的譜圖重新優化,限制了進一步的應用。相比之下,基于深度神經網絡的深度學習(DL) 31在NMR領域引起了越來越多的關注,如RF脈沖設計32、代謝分析33、NMR采樣加速34–36、虛擬同核去耦37、Laplace變換38。最近,兩種DL算法39,40已被應用于腦代謝物的磁共振譜圖去噪。需要注意的是,這兩種方法的訓練過程都需要足夠的實際實驗數據,然而,由于NMR樣品和儀器時間的限制,很難獲取大量的真實實驗NMR數據,導致兩者僅關注腦代謝物分析,而無法用于不同化學樣品的各種NMR波譜去噪。此外,DN-Unet 41 (一種改進于原始用于圖像分割的U-Net 42的網絡)使用模擬數據而非真實數據作為訓練數據集來實現液體NMR波譜的信噪比增強。
在此,本研究使用一種輕量級深度神經網絡(稱為LD-Net,輕量級去噪網絡)實現高質量、可靠且非常快速的NMR波譜去噪。這種DL方案基于物理驅動的合成NMR數據學習和端到端特征學習,直接在頻域實現噪聲和期望信號的分離。因此,它能夠準確識別和快速恢復幾乎淹沒在嚴重噪聲中的實際微弱信號,并能有效抑制噪聲和虛假峰,以及提供顯著的信噪比改善。此外,訓練好的網絡模型適用于1D和高維NMR光譜,可用于各種樣品的波譜去噪。其性能已在仿真和實驗NMR譜圖上得到充分評估。
2 方法和實驗
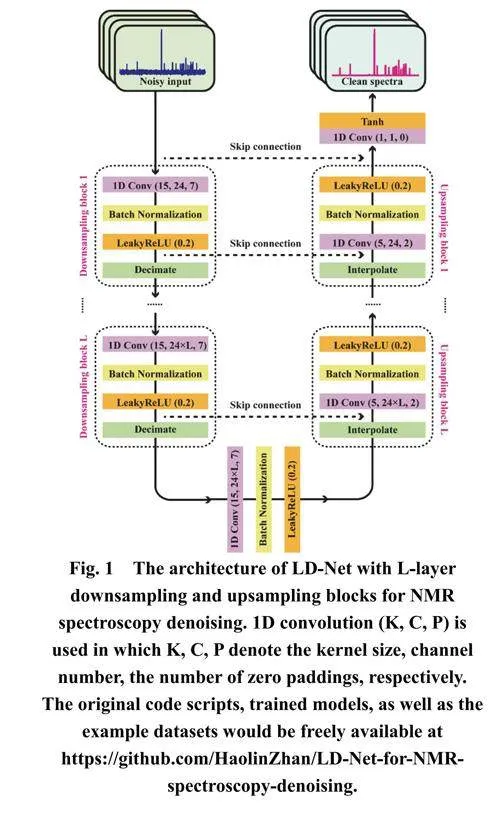
輕量級深度神經網絡LD-Net的主要架構如圖1所示。LD-Net經過訓練,學習從含噪NMR譜圖到目標無噪聲對應譜圖的特征映射,并直接在頻域分離噪聲和期望的干凈信號。受之前關于音頻源分離43和語音增強44文獻的啟發,該深度神經網絡基于U-Net架構的1D卷積改編而開發,由下采樣和上采樣模塊組成,構成編碼-解碼結構,以利用不同層次的特征。更有意義的是,這里用線性抽取和插值替代了之前基于U-Net工作中用于特征下采樣和上采樣的跨步轉置卷積,以提供更好的偽影抑制性能。此外,大卷積核尺寸被選擇來處理這項任務,因為對于稀疏的NMR譜圖,小的卷積核尺寸可能導致大多數輸入到卷積層的信息幾乎不包含有用信息。在下采樣和上采樣模塊中使用非對稱而不是對稱的卷積核,且下采樣模塊使用比上采樣模塊更大的卷積核尺寸,以抑制輸出窗口邊界處可能出現的偽影。此外,在下采樣和上下采樣模塊中逐層通道數增加24。LD-Net的詳細信息在補充信息中給出,訓練和驗證損失曲線如圖S1所示。
本研究展示了僅使用由指數函數疊加生成的合成仿真數據成功訓練深度神經網絡(數據合成的詳細參數總結在補充材料的表S1中),從而繞過了對大量實際實驗數據的需求,領先于大多數傳統DL方法。大量的包含含噪波譜X和相應的目標無噪聲標簽L的合成數據對,例如第k個數據對(Xk,Lk) (其中k是從1到訓練數據集數量K的整數變量),被輸入神經網絡以學習最優網絡參數組θ,通過最小化模型輸出Yk (即Yk = F(Xk, θ))與相應無噪聲標簽Lk之間的歸一化均方誤差(NMSE)。由無噪聲指數函數疊加生成的無噪聲標簽L通過監督學習作為理想參考。標簽質量對網絡性能有重要影響,在實際應用中,通常需要根據神經網絡的目的設計標簽L。此外,引入了M-to-S策略,采用具有不同噪聲水平的多個含噪NMR譜圖對應同一個無噪聲標簽,即(Xk1, Xk2, ..., X km, Yk),其中上標m是對應相同標簽的含噪輸入數量,以增強網絡性能。當神經網絡模型訓練良好后,對于給定的含噪譜圖X,可以通過Y = F(X, θ)實現目標去噪模型輸出Y,然后用于隨機化學樣品的NMR波譜去噪。它也適用于通過逐行重建的高維NMR,表明了良好的泛化性。此外,由于在頻域直接進行譜圖去噪,訓練好的1D模型幾乎不需要訓練和測試數據集之間的采樣點數和譜寬匹配。
3 結果與討論
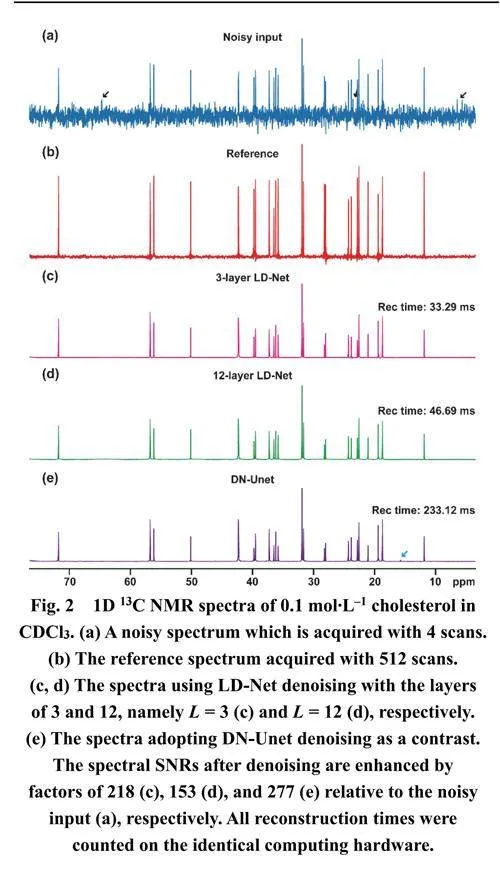
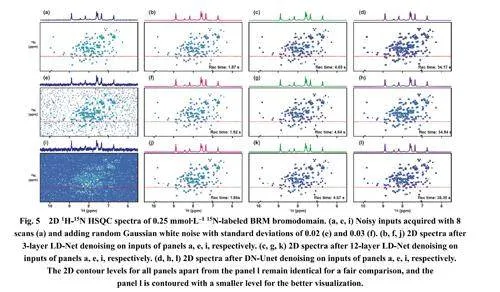
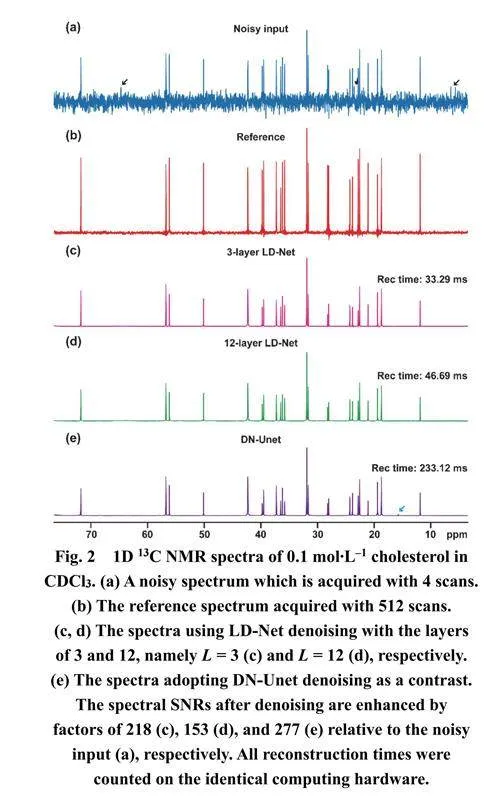
為了說明輕量級神經網絡在NMR波譜去噪方面的潛力,我們在模擬和實驗NMR譜圖上驗證了其性能。如圖S2所示,在具有不同信噪比水平的模擬測試集上的去噪結果表明了LD-Net的良好性能。在一個具有挑戰性的案例中,即使微弱峰(在圖S2c中用黑色箭頭標記)完全淹沒在嚴重噪聲中,LD-Net仍能準確識別并快速恢復它(見圖S2c中的第3行),并實現有效的噪聲減少和信噪比增強。圖2展示了實驗獲得的膽固醇1D異核NMR上的噪聲降低結果,其譜圖參數如表S2所示。由于13C的低天然豐度(約1.1%)和低旋磁比(與1H相比為1/4),通過少量掃描采集和累加的1D 13C譜圖(圖2a)表現出低信噪比性能,其中期望的峰和令人困擾的噪聲相互干擾,且出現假陽性峰(用黑色箭頭標記)。在這種情況下,與參考譜圖(圖2b)相比,LDNet方法(圖2c,d)能夠提取所有有用信號,并識別和消除所有假陽性峰,從而促進波譜分析和信息提取。伴隨著有效的噪聲抑制,超過兩個數量級的信噪比增強被實現,盡管單純的信噪比增強數值的意義并不大。相比之下,在DN-Unet去噪譜圖中仍然存在虛假峰(在圖2e中用藍色箭頭標記)。
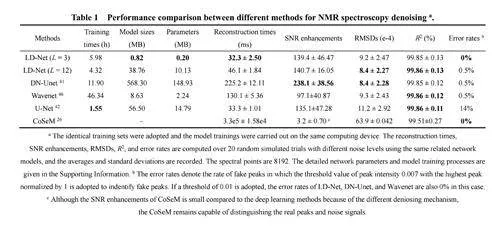
此外,與DN-Unet相比,LD-Net所需的計算時間加快了5–7倍。對于另一個臨床藥物阿奇霉素的樣品(圖S3),這種加速達到了10倍以上。這種優勢在2D甚至mD NMR波譜去噪的情況下將進一步擴大和凸顯。更有意義的是,如表1所總結的,LDNet具有更短的模型訓練時間、更小的模型大小、更少的參數,優于DN-Unet。特別是,具有較少下采樣和上采樣層(即L = 3)的LD-Net的模型大小約比DN-Unet小700倍,突出了其輕量級優勢并促進了在便攜設備上的潛在應用。類似地,LD-Net在不含和含有額外噪聲的阿奇霉素1D 13C NMR上表現出令人滿意的去噪效果(圖S3和S4)。此外,通過計算相對于參考光譜的均方根偏差(RMSDs)來評估定量能力,RMSDs的范圍約為0.01–0.02,表明了良好的定量性能,詳細數值總結在表S3中。因此,輕量級神經網絡LD-Net是NMR波譜去噪的一種有用工具。
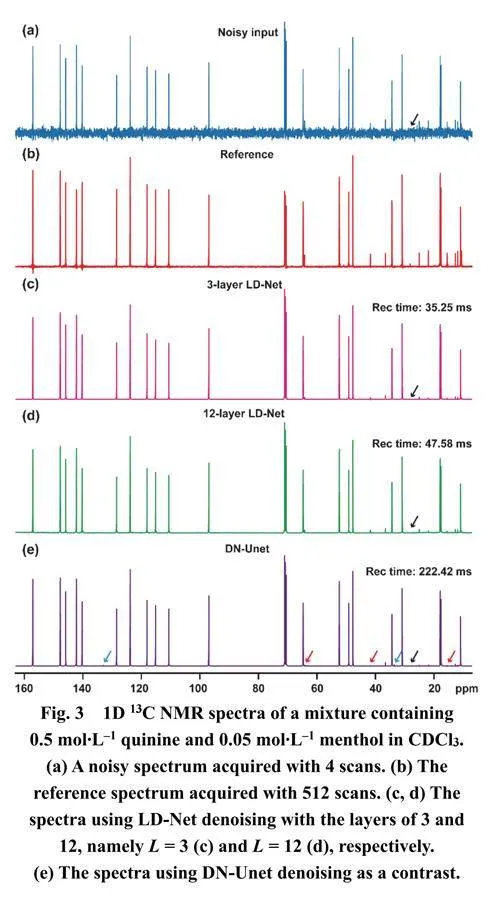
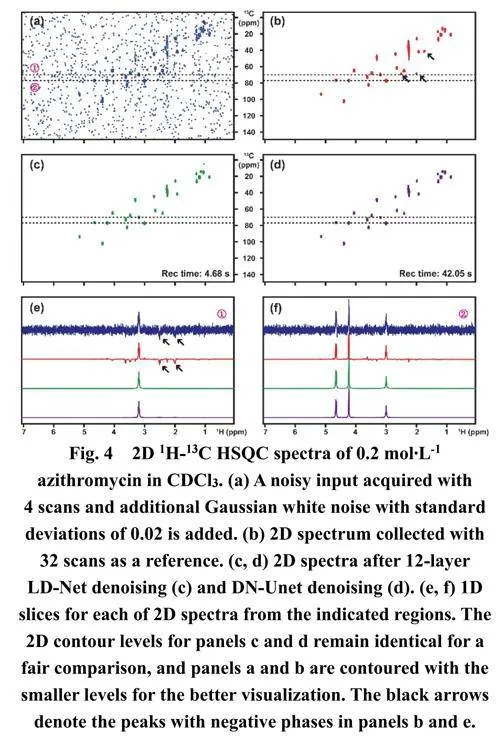
另一個展示其適用性和強大性的例子是在一個具有挑戰性的含有奎寧和薄荷醇兩種成分的混合物上進行的,這兩種成分的濃度存在很大差異。盡管在原始譜圖中低濃度組分的強度接近噪聲水平(圖3a),LD-Net (圖3c,d)提供了一個優秀的去噪譜圖,幾乎恢復了所有有用的NMR信號,且沒有引入虛假峰。相比之下,DN-Unet (圖3e)中幾個用紅色箭頭標記的信號幾乎被忽略,并且在得到的譜圖中遺憾地出現了用藍色箭頭標記的偽影。需要注意的是,用黑色箭頭標記的峰既沒有被LDNet也沒有被DN-Unet恢復,因為這個峰的強度可能低于儀器的檢測限并且完全淹沒在嚴重的噪聲中。此外,應該注意到在這種情況下,包括LD-Net和DN-Unet在內的深度學習方法對恢復不同強度的信號表現出不同的效果,因此導致弱峰強度的重建不夠理想。這種現象可能源于在網絡訓練過程中,較弱強度的譜峰對最小化網絡輸出Y和相應標簽L之間的差異的貢獻較小,后續研究通過調整不同強度譜峰對網絡損失的貢獻可能解決這個問題。如圖4和圖5所示,LD-Net在2D乃至mD NMR波譜去噪方面展示了高潛力。如圖4c和圖S5所示,通過使用與1D NMR去噪相同的提出的1D模型進行逐行去噪,LD-Net仍能保留所有峰值并在2DNMR上實現令人滿意的譜圖去噪。此外,在圖4b,e中,隨著噪聲的抑制,用黑色箭頭標記的負峰也被消除。與DN-Unet (圖4d)相比,3層(圖S5)和12層(圖4c) LD-Net在2D NMR去噪方面分別實現了21倍和9倍的時間節省。圖5進一步討論了在具有更復雜譜圖和不同噪聲水平的樣品上進行2D NMR去噪的性能,以之前文獻45中報道的0.25 mmol?L–1蛋白質樣品為例。在存在不同水平噪聲的情況下,LDNet(圖5)在區分噪聲和期望信號、消除假陽性和假陰性峰以及提供干凈譜圖方面保持魯棒。更有意義的是,可以看到即使在存在大量噪聲的情況下,LD-Net (圖5i)成功恢復了在2D譜圖和1D軌跡中幾乎淹沒在嚴重噪聲中的微弱峰。
傳統數據后處理和深度學習方案構成了波譜去噪的兩個主流方式。表1總結了幾種典型DL方法和一種常規算法之間的性能定量比較。與最近提出用于NMR和MRI去噪的非DL去噪算法CoSeM 26(具有無需網絡預訓練和良好泛化性的優勢)相比,DL方案幾乎不需要耗時且主觀的參數優化,并且受益于非迭代低復雜度神經網絡映射而能實現快速去噪重建。雖然DN-Unet 41通常提供更大的信噪比增強,但受限于更長的模型訓練時間、更大的模型大小和更多的模型參數。此外,經典U-Net 42在模型所需訓練時間方面具有一定優勢,但遺憾的是有較高的引入偽影的可能性。此外,與最近兩種專注于腦代謝物MRS去噪的DL方法39,40相比,LDNet擺脫了對大量實際實驗數據的需求,并在各種化學樣品上保持穩健,從而促進了DL在NMR領域的應用,例如在1D和mD純化學位移NMR 47–49上的潛在去噪。此外,所提出的LD-Net模型在不同采樣點數和被測譜圖的譜寬上提供了良好的兼容性,無需網絡重新訓練,表明了良好的泛化性。總之,LD-Net在NMR波譜去噪方面表現出一定的優勢。
如前述示例所示,LD-Net方案使用端到端映射,在譜圖去噪和信噪比改善方面表現出良好性能,同時能夠有效恢復淹沒在噪聲中的期望弱峰并很好地抑制虛假峰。當前LD-Net的局限性仍需要強調:首先,與所有基于DL的方案一樣,模型訓練是不可避免的,且訓練數據集在一定程度上影響著最終模型的性能(圖S6)。然而,由于具有良好的泛化性,LD-Net模型可以預先使用充分考慮多種可能性的訓練數據集進行訓練,然后適用于一般化學樣品和NMR實驗。其次,極低的信噪比仍然限制其性能。當原始NMR信號低于儀器檢測限時,DL方案可能無法處理。第三,大多數DL算法普遍缺乏足夠的可解釋性,不可避免地降低了其魯棒性。因此,我們也在積極探索可解釋的DL算法。
4 結論
總之,我們展示了使用輕量級深度神經網絡進行NMR波譜降噪的概念驗證示范。LD-Net基于物理驅動的合成NMR波譜學習,實現了直接且良好的去噪,且適用于各種化學樣品和NMR實驗。實驗結果表明,LD-Net能夠有效抑制噪聲和虛假信號,恢復期望的弱峰,并提供顯著的信噪比改善。此外,由于具有更短的模型訓練時間、更小的模型大小、更少的網絡參數以及更快的計算效率等優勢,LD-Net優于現有的基于DNN的去噪方法。因此,本研究為NMR去噪提供了一種有效的DL方法,并作為人工智能賦能化學研究的一個有前景的范例,從而促進了深度學習方案在化學領域的廣泛應用。
猜你喜歡
西安航空學院學報(2022年2期)2022-07-04 07:45:42
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
小康(2017年16期)2017-06-07 09:00:59
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
軟件工程(2016年8期)2016-10-25 15:47:34
