多邊形填充硬件算法的研究與實現(xiàn)
2010-01-05 08:15:58李慶誠白振軒
天津師范大學(xué)學(xué)報(自然科學(xué)版) 2010年1期
劉 洋,李慶誠,白振軒
(1.天津師范大學(xué)計算機(jī)與信息工程學(xué)院,天津 300387;2.南開大學(xué)信息技術(shù)科學(xué)學(xué)院,天津 300071)
多邊形填充硬件算法的研究與實現(xiàn)
劉 洋1,2,李慶誠2,白振軒2
(1.天津師范大學(xué)計算機(jī)與信息工程學(xué)院,天津 300387;2.南開大學(xué)信息技術(shù)科學(xué)學(xué)院,天津 300071)
提出一種多邊形填充的硬件算法,并通過在Xilinx公司生產(chǎn)的Vertex2 Pro實驗板上進(jìn)行驗證,證明該算法的可行性及其良好高效性.
多邊形填充算法;硬件加速算法;協(xié)處理IP核;Verilog語言;嵌入式開發(fā)套件(EDK)
多邊形的填充是計算機(jī)圖形學(xué)中最基本的問題之一,填充的任務(wù)是要找出所有位于多邊形內(nèi)部的像素,并賦以適當(dāng)?shù)南袼刂?以往,實現(xiàn)此類算法均需利用高級語言完成,硬件采用通用處理器,利用軟件方法來實現(xiàn).但在嵌入式設(shè)備中,由于考慮到功耗等問題,一般不可能使用高性能的通用處理器.如在嵌入式手持閱讀器中,處理器的主頻只有200 M Hz,但在版面顯示之前,含有大量面向密集的計算[1],如在一般圖形解析與矢量字體解析中的多邊形填充問題,當(dāng)通過軟件完成這些任務(wù)時,速度會很慢,從而對用戶快速瀏覽版面造成影響.因此,設(shè)計特別的硬件來彌補(bǔ)通用處理器的不足是一個非常自然且有效的辦法[2].本研究在探討各種多邊形填充算法的基礎(chǔ)上,提出一種基于硬件實現(xiàn)的多邊形填充算法,即利用硬件加速的方法提高多邊性的填充效率,并在Xilinx公司的Vertex2 Pro實驗板上進(jìn)行測試.
1 多邊形填充算法
多邊形填充算法主要有兩種[3]:一種是通過橫越區(qū)域的掃描線的覆蓋間隔來填充;另一種是從給定的位置開始涂描,直至指定的邊界條件為止.掃描線方法在一般圖形軟件包中,主要用來填充多邊形、圓、橢圓和其他簡單曲線.從內(nèi)部點開始的填充方法用于邊界形狀復(fù)雜的多邊形和交互式繪圖系統(tǒng).在矢量圖形的填充問題上,掃描線填充算法是一種比較可行的算法,因此,許多研究在該算法上做了大量改進(jìn),以提高填充效率.例如,張玉芳等人提出一種混合填充算法,該算法采用鏈表和數(shù)組結(jié)合的數(shù)據(jù)結(jié)構(gòu),形成連續(xù)的填充軌跡,有效地提高了時間效率[4].2000年,甘泉提出通用掃描線多邊形填充算法,該算法可以有效解決任意間距、任意傾角的掃描線對多邊形的填充問題[5].2002年,陽波等人進(jìn)一步結(jié)合代數(shù)曲線積分思想與活性邊表技術(shù),提出一種新的任意多邊形代數(shù)積分算法[6].以上改進(jìn)算法均從不同的角度改進(jìn)了傳統(tǒng)的掃描線算法,但大多是在軟件平臺上完成的.考慮到嵌入式產(chǎn)品自身的功耗問題,單純依靠提高處理器主頻的軟件實現(xiàn)加速并非切實可行,而目前,國外的廠商,如 HP,CALCOMP,VERSTATEC等公司均在矢量圖形光柵化上取得了良好效果,但這些技術(shù)都嚴(yán)格保密.西安電子科技大學(xué)李春霞碩士將圖形學(xué)中一些基本算法進(jìn)行硬件實現(xiàn),并對其進(jìn)行了性能分析[7].本研究在此基礎(chǔ)上,針對多邊形填充問題,提出并實現(xiàn)了其硬件算法.
2 核心算法的描述
本研究的多邊形填充算法主要分2步:
第1步:初始化工作,包括3小步:
(1)求多邊形坐標(biāo)的最小值和最大值,分別記作minx,maxx;
(2)記錄每條邊的信息,存在數(shù)組line_ info中,其中每一個元素的結(jié)構(gòu)如表1所示;

表1 邊的數(shù)據(jù)結(jié)構(gòu)Table1 Datastructureofedge
(3)記錄頂點(較小x值)的信息,存在數(shù)組point info中,其中每一個元素的結(jié)構(gòu)如表2所示.

表2 頂點的數(shù)據(jù)結(jié)構(gòu)Table2 Datastructureofvertex
第2步:掃描所有列,得到交點.
?x∈[minx,maxx),求x與各個邊的交點y,將當(dāng)前列(x列)的交點信息存在數(shù)組cur_ et中將上一列(x-1列)的交點信息存在數(shù)組prev _et中其中cur_ et與prev_ et中的元素結(jié)構(gòu)相同,如表3所示.

表3 交點的數(shù)據(jù)結(jié)構(gòu)Table3 Datastructureofintersection
求交點y的具體步驟分為以下7小步:
(1)x=minx,進(jìn)入(2);
(2)如果x<maxx,執(zhí)行(3),否則結(jié)束;
(3)如果x>minx,執(zhí)行(4),否則執(zhí)行(5);
(4)對于數(shù)組prev_ et中的所有交點,如果其值不大于它本身所在直線的最大x值減1,則利用Bresenham算法求出當(dāng)前的交點值,并將結(jié)果按交點的大小順序插入數(shù)組cur_ et中;否則考察數(shù)組中下一個交點;
(5)掃描頂點交點信息(即數(shù)組point_ info),查找是否存在坐標(biāo)x值與當(dāng)前列相同的點,并將其按y值大小順序插入到數(shù)組cur_ et中;
(6)輸出當(dāng)前x列值,以及數(shù)組cur_ et所有信息(即當(dāng)前列與所有邊的交點坐標(biāo));
(7)將數(shù)組cur_ et中的信息寫回prev_ et中,以備下次使用,置x=x+1,返回(2).
下面,以多邊形 A(2,1),B(7,1),C(9,5),D(6,8),E(5,4),F(2,9)為例:
第1步:初始化工作,分為3小步:
(1)minx=2,maxx=9;
(2)記錄每條邊的信息,存在數(shù)組line info中,如表4所示;

表4 本例中邊表情況Table4 Onecaseabouttheedgetable
(3)記錄頂點(較小x值)的信息,存在數(shù)組point_ info中,如表5所示;

表5 本例中頂點表情況Table5 Onecaseaboutthevertextable
第2步:掃描所有列,得到交點.
(1)x=2,掃描數(shù)組point_ info,將A點和 F點按大小順序插入數(shù)組cur_ et,輸出交點(2,1)和(2,9),并將數(shù)組cur_ et的內(nèi)容放入prev_ et中;
(2)x=3,讀取數(shù)組prev_ et,利用Bresenham算法求出當(dāng)前的交點值,按大小順序插入數(shù)組cur_ et中,然后,掃描數(shù)組point_ info,但沒有相應(yīng)點,無需插入,輸出交點(3,1)和(3,8),將數(shù)組cur_ et的內(nèi)容放入prev_ et中;
(3)x=4,5,6,7和8的情況與(2)相同,不再贅述;
(4)x=9,程序結(jié)束.
3 算法的實現(xiàn)
多邊形填充算法的實現(xiàn):在Xilinx公司的Vertex2 Pro實驗板[8]上完成.Vertex2 Pro系列 FPGA是Xilinx公司推出的高端 FPGA產(chǎn)品,該開發(fā)板引入M icroBlaze內(nèi)核并提供相應(yīng)的集成開發(fā)環(huán)境EDK.其中,M icroBlaze是基于Xilinx公司FPGA的微處理器軟 IP核,該 IP核采用 RISC架構(gòu)和哈佛結(jié)構(gòu)的32位指令和數(shù)據(jù)總線,內(nèi)部有32個32位寬度的通用寄存器;在150 M Hz的時鐘頻率下,最高可以達(dá)到125 DM IPS的處理性能,其邏輯結(jié)構(gòu)如圖1所示(圖中省略了指令側(cè)的同類接口).
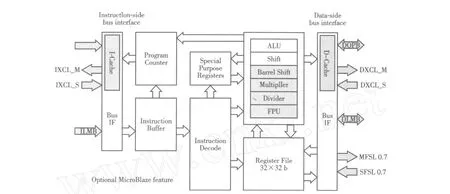
圖1 M icroBlaze IP核邏輯結(jié)構(gòu)Fig.1 M icroBlaze IP core structure
使用Xilinx公司提供的EDK,可以在參數(shù)化的圖形界面下方便地完成嵌入式軟處理器系統(tǒng)的設(shè)計.該套件具備2個突出的優(yōu)點:一是設(shè)計靈活;二是可以整合用戶自定義IP核,使算法在硬件中并行執(zhí)行,而不是在軟件中串行執(zhí)行,從而極大地加速了任務(wù)的執(zhí)行速度,即所謂的硬件加速.本研究首先利用Xilinx公司的 EDK,很方便地構(gòu)架出實驗結(jié)構(gòu),如圖2所示.
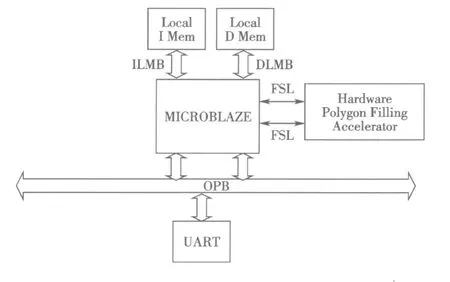
圖2 多邊形填充異構(gòu)單M icroBlaze核處理器設(shè)計模塊圖Fig.2 Polygon f illing design block diagram based on hybrid M icroBlaze processor
圖中,M icroBlaze核作為主處理器,主要負(fù)責(zé)數(shù)據(jù)的輸入輸出,而實現(xiàn)算法的主要部分放在自行設(shè)計的IP核中,作為主處理器的協(xié)處理核,實現(xiàn)多邊形填充的硬件加速功能.其設(shè)計遵循如下基本需求:
(1)指令集適用于多邊形填充問題,能夠通過使用此指令集的軟件編程控制硬件,適應(yīng)具體的應(yīng)用場景;
(2)能夠針對具體密集計算真正起到硬件加速作用;
(3)能夠快速地存取大量數(shù)據(jù),主核與協(xié)核之間的通信不會成為整個系統(tǒng)的瓶頸.
IP核的設(shè)計與實現(xiàn)是在 Xilinx公司提供的ISE開發(fā)工具上完成的,所使用的算法如本研究第2部分所述,語言是Verilog語言,對于該模塊的接口定義如下:

編寫程序后,在modelsim下進(jìn)行邏輯仿真與后仿真成功,其仿真結(jié)果如圖3.
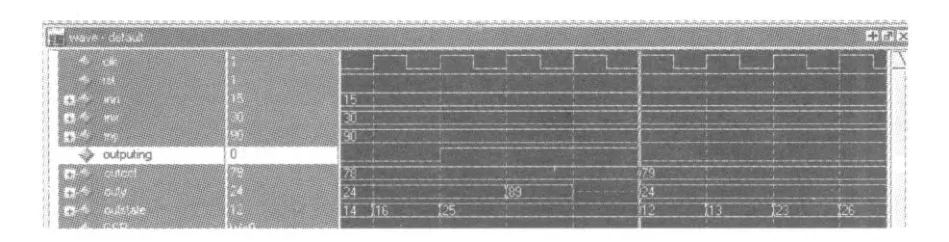
圖3 在modelsim下后仿真圖Fig.3 The ModelSim Simulation Result
協(xié)核由于功能單一,一般不具備完整的人機(jī)交互等功能,主要靠主核控制,而主核與協(xié)核之間需要設(shè)計特別的通信或數(shù)據(jù)共享機(jī)制,該機(jī)制應(yīng)保證數(shù)據(jù)的正確性、可控制性和傳輸效率等.
在EDK中,主核M icroBlaze與用戶自定義的IP核的連接是通過快速單向鏈路總線(Fast Simp lex Link,簡稱 FSL)完成的.FSL總線是M icroBlaze所特有的總線,可以實現(xiàn)用戶IP核與軟核處理器的高速連接,為設(shè)計者提供了一條解決這類問題的途徑.最后,實驗結(jié)果通過實驗板上的串口輸出到計算機(jī)屏幕上,以驗證結(jié)果的正確性.
4 實驗結(jié)果
為了測試本算法的性能,將該算法與軟件實現(xiàn)的多邊形填充算法在時間上作了多組比較,其平均時間如圖4所示.
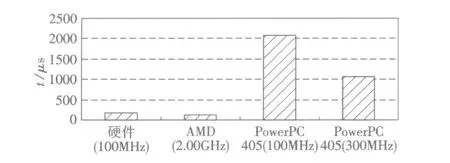
圖4 實驗結(jié)果對照圖Fig.4 The comparison of experimental result
圖中,本研究提出的硬件算法所用的時鐘頻率為100 M Hz,平均所需填充時間為 163μs.而用軟件實現(xiàn)算法時,使用傳統(tǒng)的掃描線方法,測試環(huán)境分別有三種:第一種是在 PC環(huán)境下,處理器是AMD Athlontm64 X2 Dual Core Processor 3 600+2.00 GHz,內(nèi)存大小為1 GB;第二種是在Xilinx公司的Vertex2 Pro實驗板上搭建的PowerPC 405處理器系統(tǒng)平臺,其主頻為100 M Hz,內(nèi)存為256 MB的DDR SDRAM(最大實際工作頻率為133 M HZ);第三種也是在PowerPC 405處理器系統(tǒng)上,其主頻為300 M Hz,其他與第二種相同.
由圖4可以看出,第一種軟件實現(xiàn)是在高主頻CPU下完成的,其平均所需填充時間為 128μs,在PC環(huán)境下,多邊形填充算法程序與其他程序共享CPU與內(nèi)存資源,故真實的程序運(yùn)行時間應(yīng)好于此值;第二、三種軟件實現(xiàn)是在嵌入式系統(tǒng)通常使用的低主頻處理器上實現(xiàn)的,其平均時間分別為2079μs和1 066μs,PowerPC主頻為300 M Hz的情況下,與100 M Hz運(yùn)算速度相比沒有提高3倍,主要是因為連接 PowerPC與內(nèi)存之間的總線頻率僅為100 M Hz,成為整個系統(tǒng)的瓶頸.通過圖4所反映的數(shù)據(jù)可以看到,本研究的硬件算法在主頻為100 M Hz的情況下,填充速度已基本達(dá)到目前主流通用處理器對該問題的處理速度,并遠(yuǎn)遠(yuǎn)超過了一般嵌入式處理器的處理速度,從而驗證了該硬件算法的高效性.
5 結(jié)論
上述實驗表明,本研究設(shè)計的算法能夠?qū)σ话愣噙呅芜M(jìn)行有效填充,并具有以下特點:(1)由于使用Bresenham算法求出當(dāng)前的交點值,故無需乘除運(yùn)算,便于硬件實現(xiàn);(2)算法中有大量可同時進(jìn)行的步驟,稍加改動,即可實現(xiàn)并行化.同時,該算法也有片上資源使用率較高等需要改進(jìn)的環(huán)節(jié).總之,本研究的主要目標(biāo)在于滿足嵌入式手持閱讀器的版面加速需求,但目前還處于實驗階段,將其真正應(yīng)用于實踐是本研究下一階段需要完成的任務(wù).
[1] Johnston W E.High-speed,wide area,data intensive computing:a ten year retrospective[C].//IEEE Computer Society.Proceedings of theSeventh International Symposium on High Perfo rmance Distributed Computing.Chicago IL:University of Chicago Press,1998:280-291.
[2] 戴鴻君.基于異構(gòu)多核體系與組件化軟件的嵌入式系統(tǒng)研究[D].杭州:浙江大學(xué),2007.
[3] Donald H,Baker M P.計算機(jī)圖形學(xué)[M].北京:電子工業(yè)出版社,1998.
[4] 張玉芳,劉君,彭燕.一種改進(jìn)的掃描線多邊形填充算法[J].計算機(jī)科學(xué),2005.
[5] 甘泉.通用掃描線多邊形填充算法[J].計算機(jī)工程與應(yīng)用,2000.
[6] 陽波,王衛(wèi)星,魏許青.基于曲線積分的任意多邊形填充算法[J].計算機(jī)工程與應(yīng)用,2002.
[7] 李春霞.矢量光柵變換(VCR)的研究與硬件實現(xiàn)[D].西安電子科技大學(xué),2005.
[8] Xilinx Inc..Xilinx XUP Virtex-II Pro Development System[EB/OL].(2009-11-3)[2009-11-3].http://www.xilinx.com/univ/xupv2p.
Research and im plementation of polygon filling algorithm based on hardware
L IU Yang1,2,L IQingcheng2,BA I Zhenxuan2
(1.College of Computer and Information Engineering,Tianjin Normal University,Tianjin 300387,China;2.College of Information Technical Science,Nankai University,Tianjin 300071,China)
A kind of polygon filling algo rithm based on hardware is p resented,and its feasibility and good perfo rmance are confirmed by the imp lementation on Vertex2 Pro board of Xilinx Co rpo ration.
polygon filling algo rithm;hardware advanced algorithm;co-p rocessor IP co re;Verilog Language;embedded design kit(EDK)
TP368.2
A
1671-1114(2010)01-0019-04
2009-09-04
天津市科技支撐計劃重點項目(08ZCKFGX01400)
劉 洋(1977—),男,講師,博士研究生,主要從事片上多核系統(tǒng),軟硬件協(xié)同設(shè)計方面的研究.E-mail:snake8young@yahoo.com.cn
(責(zé)任編校 紀(jì)翠榮)
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
體育科技文獻(xiàn)通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
民用飛機(jī)設(shè)計與研究(2019年4期)2019-05-21 07:21:24
鐵道通信信號(2018年2期)2018-04-18 12:18:23
電鍍與環(huán)保(2016年3期)2017-01-20 08:15:32
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
