
基于人工神經網絡的裝配序列規劃方法研究*
2010-07-09 08:06:52崔漢國朱石堅
武漢理工大學學報(交通科學與工程版) 2010年5期
張 晶 崔漢國 朱石堅
(海軍工程大學船舶動力學院 武漢 430033)
目前的裝配序列規劃研究[1-3]主要有兩類:(1)根據約束條件推理生成可行裝配序列,然后再進行優選(約束推理法、拆分法、基于知識和事例的方法等);(2)利用現代優化方法進化生成可行裝配序列,邊生成邊篩選(遺傳算法、模擬退火算法等).本文提出并實現了一種基于人工神經網絡的裝配序列規劃方法,達到對裝配序列進行準確預測的目的.
1 裝配序列規劃問題的描述
1.1 裝配模型[4-5]
本文采用聯系矩陣C描述零件之間的連接情況,C與直角坐標方向無關,是一個n×m的矩陣(其中n為零件的數目,m為零件之間連接的數目).連接可以分為緊固連接和非緊固連接(或稱一般連接).前者如螺紋接合、咬接、焊接和粘接等,后者如兩相鄰零件簡單地相對或接觸等.對于零件pi和pj,矩陣C中元素Cir和Cjr在非緊固連接時設置為1,在緊固連接時設置為2;r列中其他元素設置為0.
為直觀方便起見,在以下分析中,對聯系矩陣輔之以圖的方式來表達,將之稱為聯系圖.聯系圖是有向圖,其結點是裝配體中的零件,有向弧表示零件之間的聯系或配合情況,若零件pi在方向k上和零件pj存在聯系或配合關系,則在k方向的聯系圖中連接零件pi和零件pj的有向弧將由pi指向pj,如圖1所示.
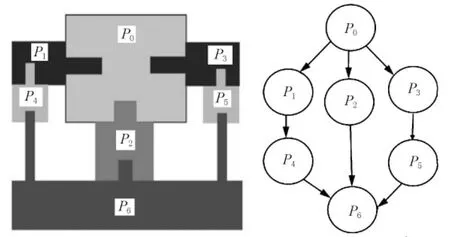
圖1 裝配聯系圖
1.2 基于規則的爆炸圖生成
爆炸圖是組成產品的零件的散列展開圖,定義某直角方向的局部爆炸圖為沿該方向散開的零件的散開序列.在生成爆炸圖時,需要選擇一個零件作為基礎件,然后以基礎件為分界確立各方向的聯系圖,從各方向的聯系圖分別利用相應規則生成各方向相應的爆炸圖.
對與連接矩陣C中每一個零件相關的連接進行數量加總(緊固連接算作2,非緊固連接算作1),加總后最大值所對應的零件即為基礎件.通常,基礎件與其他零件的連接最多,而與連接緊固與否并無絕對關系,因而可以僅依據連接矩陣簡單計數每一個零件的連接,連接數最多的零件即為基礎件.一般在裝配時,基礎件最先裝配;而在拆卸時,基礎件最后拆卸.另外,基礎件一般不包含在任何子裝配體中.
基礎件確定以后,利用基礎件,可以生成方向k的聯系圖,這是通過刪除對應聯系圖中所有在方向k在k方向上零件pi落在零件pj的后面,則在k方向聯系圖中,存在由pi指向pj的有向弧,或者存在由pi指向pj的有向路徑.也可根據聯系矩陣的性質,先通過刪除k方向對應聯系矩陣中所有在方向k上、不落在基礎件后面的零件及其聯系,然后對余下矩陣轉置(將余下的圖中的弧反向)來完成上述操作.
由k方向的聯系圖,基于規則生成k方向爆炸圖的算法如下.
步驟1k方向的聯系圖反向.
步驟2刪除圖中冗余的弧.
步驟3從修改后的聯系圖中,尋找一個無父結點的零件結點P,檢查是否存在一個從P開始的所有零件結點的線性序列.如果有,k方向爆炸圖生成,算法結束;否則,轉步驟3.
步驟4進行所有零件結點的遍歷.從一個無父結點的零件結點出發,僅僅沿著惟一的弧(指既無多個子結點,又無多個父結點)搜索;當遇到不唯一的弧時,運用規則對相關的零件結點進行k方向上的爆炸或拆卸先后的排序,然后返回步驟3.
1.3 懲罰矩陣
本文使用懲罰指數(penalty index)[6-7]來描述裝配難度級別.表1給出了在某種情況下懲罰指數的定義.

表1 懲罰指數表
懲罰矩陣(penalty matrix)P可以綜合各個獨立因素對部件裝配難度影響.本文采用如下的公式來計算懲罰矩陣
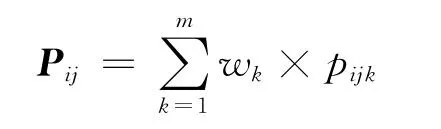
式中:pijk為在因素k下,部件pi和pj之間的懲罰指數;m為需要考慮的獨立因素的個數;wk為在k因素下pijk所占的權重.
在實際應用中,設計者可以設定不同的wk來適應不同的裝配系統.
2 裝配序列規劃的BP優化算法
2.1 BP網絡參數的設定
本文中,利用梯度算法來尋找權值的變化和誤差能量函數的最小值.轉移函數選用tan-sigmoid函數.均方根誤差函數(RMDE)的定義
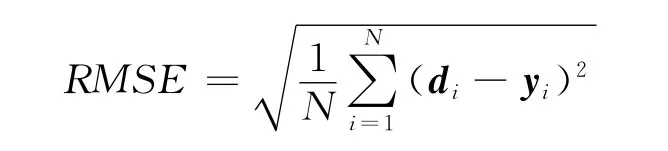
式中:d為目標矢量;y為輸出矢量;N為矢量維數.
終止迭代的臨界條件是:(1)均方根誤差函數值降到預先設定的合理范圍;(2)迭代次數達到預先的設定;(3)訓練樣本和測試數據發生交叉驗證.
2.2 數據的預處理
本文采用如下的公式進行數據的預處理
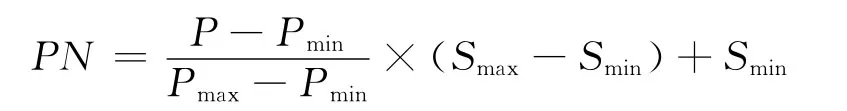
式中:PN為規范后的數據;P為原始數據;Pmin為原始數據的最小值;Pmax為原始數據的最大值;Smax為預期規范后的數據最大值;Smin為預期規范后的數據最小值.
2.3 BP算法的基本步驟
步驟1初始化權值W和閾值b,把所有權值和閾值都設置成較小的隨機數.
步驟2提供訓練樣本集,包括輸入向量P和要求的預期輸出T.
步驟3計算隱含層和輸出層的輸出.
步驟4調整權值和閾值.
步驟5計算均方根誤差函數.
步驟6循環步驟2~步驟5,直至滿足終止迭代的臨界條件.
3 應用實例分析
選取一個由16個部件組成的裝配體作為訓練樣本,同時采用了一個平口鉗(如圖2所示)作為驗證樣本.
3.1 BP網絡輸入、輸出變量的設定
選取待裝配產品的裝配聯系值(assembly incidence,AI)、懲罰值(total penalty value,TPV)、特征數目(feature number,FN)和重量(weight)作為BP網絡的輸入變量,裝配序列號作為輸出變量.
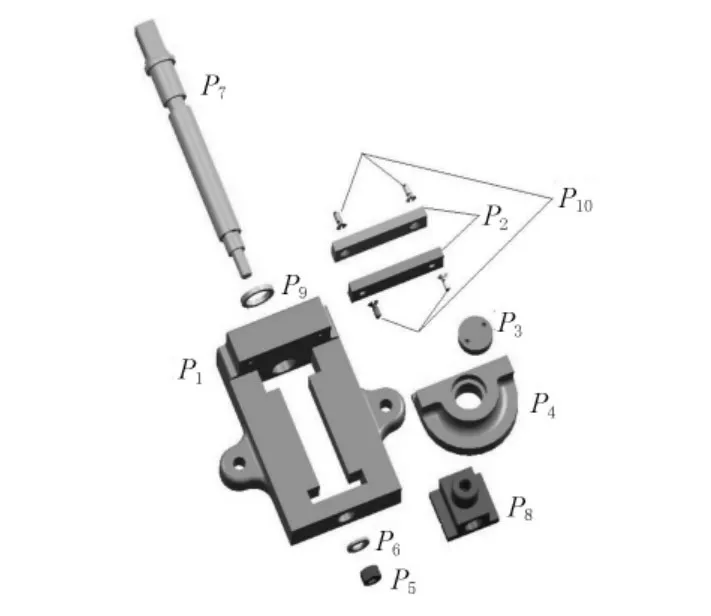
圖2 平口鉗的爆炸圖
AI,TPV的定義分別如下.
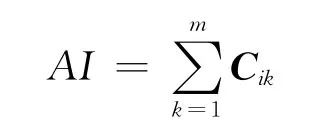
式中:Cik為連接聯系矩陣的元素;m為聯系矩陣Cij的列數.
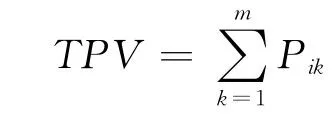
式中:Pik為連接懲罰矩陣的元素;m為懲罰矩陣Pij的列數.
FN為部件的特征數目,一般由CAD建模軟件自動生成,本文由UG生成.重量(weight)可以是實際重量也可采用CAD軟件自動計算得出.本文訓練樣本的重量由實際測試得出,驗證樣本的重量由UG自動生成.表2是訓練樣本的輸入、輸出變量明細,表3是驗證樣本的輸入變量明細.
3.2 BP網絡建模
BPNN由3層組成,即:由4個神經元組成的輸入層(每個神經元對應1個輸入變量,分別為裝配聯系值AI、懲罰值TPV、特征數目FN、重量(weight)、由n個神經元組成的隱含層以及由1個神經元組成的輸出層(對應1個輸出變量,即裝配序列號),拓撲結構為4-n-1.建模按以下步驟進行.
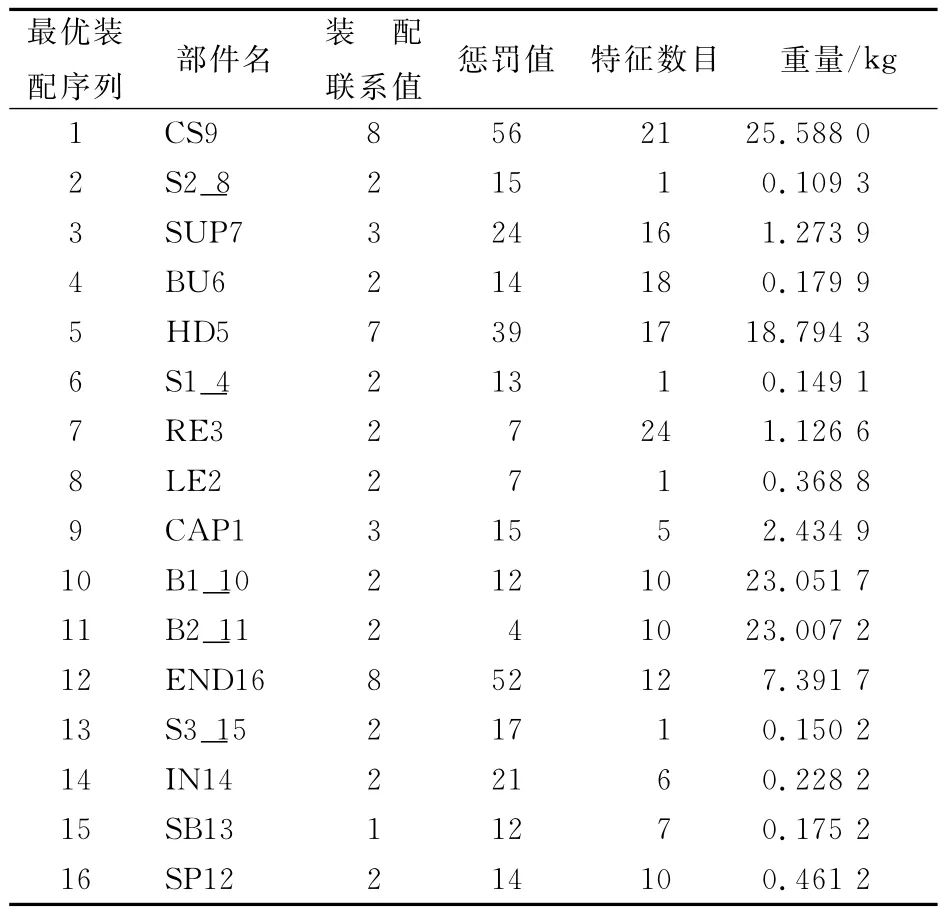
表2 訓練樣本輸入、輸出變量明細表

表3 驗證樣本輸入變量明細表
1)樣本數據的初始化 將樣本數據中的輸入、輸出變量歸一化至[0.1,0.9].
2)網絡結構的初始化 神經元激活函數選取tan-sigmoid型函數,取隱含層神經元個數初始值n=20,在訓練過程中進行隱含層節點的動態刪減.采用 Nguyen-Widrow方法[8]和權值空間逐步搜索算法[9]進行權值的初始化.
3)網絡的自適應訓練 將歸一化后的樣本數據提交給網絡,應用帶動量的自適應學習速率梯度下降算法進行反復批量訓練,直到網絡結構最精簡,同時學習誤差滿足要求為止.這時,BPNN拓撲結構為4-15-1,模型建立完成.圖3是該BP網絡模型訓練的均方根誤差函數RMSE的變化情況.
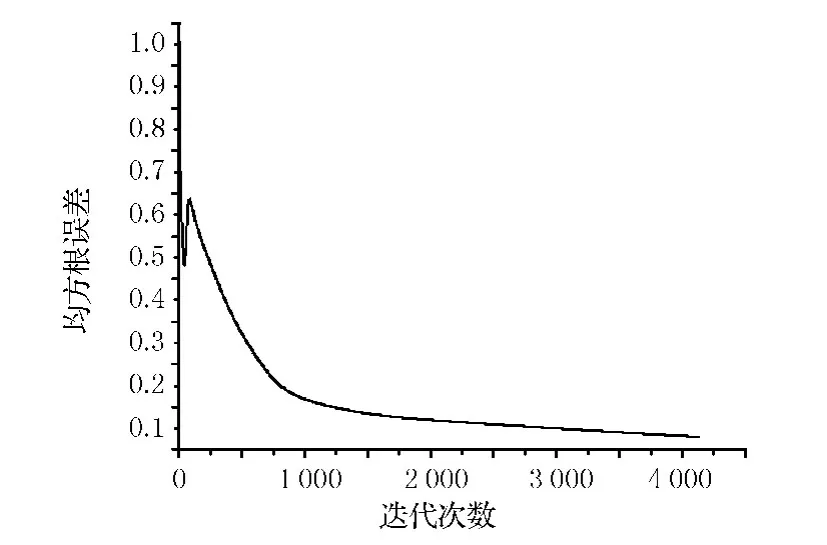
圖3 BP網絡模型訓練的均方誤差變化
3.3 仿真結果
用訓練好的BP網絡對測試樣本(平口鉗)的裝配序列進行預測,預測結果如圖4所示.網絡的輸出值為歸一到[0.1,0.9]的裝配序列號.從圖上可以得出平口鉗的裝配序列為P1→P9→P8→P7→P4→P3→P6→P5→P2→P10.這與實際的最優裝配序列完全吻合.因此基于人工神經網絡的裝配序列規劃算法可以正確地預測出裝配體的裝配序列.
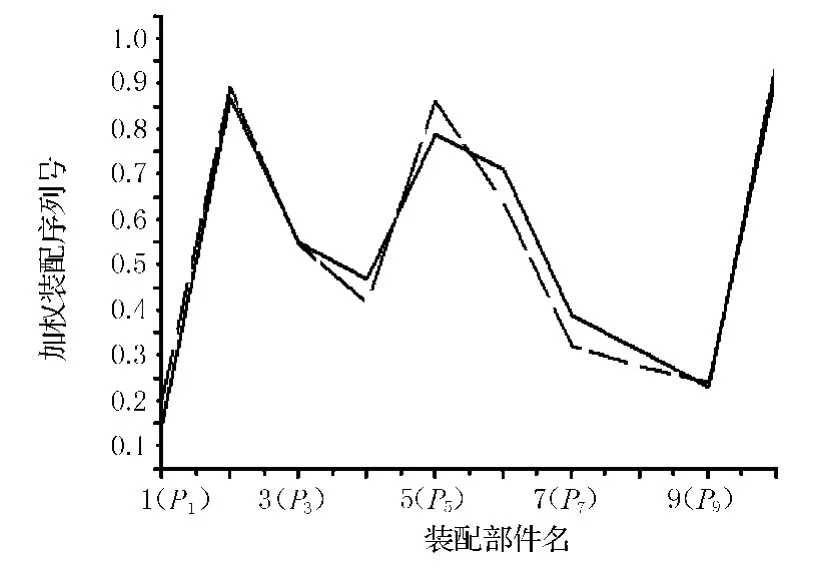
圖4 測試樣本的預測、實際序列輸出圖
4 結 束 語
本文用裝配聯系矩陣、裝配聯系圖、懲罰矩陣來表示裝配體,能夠表達零件之間優先關系、裝配代價.該模型允許新增優先約束、裝配可行性信息,具有較強的可擴充性和實用性.基于上述信息,建立了基于人工神經網絡的裝配序列規劃算法,對裝配序列進行了預測.實踐證明,該方法是一個行之有效的復雜產品裝配序列規劃方法,能夠高效快速地搜索到具有工程實際意義的最優或近優裝配序列,且已應用到實際的工程項目中.
[1]張伯鵬.數字化制造是先進制造技術的核心技術[J].制造業自動化,2000(2):1-5.
[2]嚴曉光,高艷麗,耿 標.計算機輔助裝配順序規劃技術概述[J].CAD/CAM 與制造業信息化,2004(11):11-13.
[3]潘洋宇,王拴虎,龔光榮.計算機輔助裝配工藝設計關鍵技術研究[J].機械,2003,30(2):52-55.
[4]付宜利,田立中,謝 龍.基于有向割集分解的裝配序列生成方法[J].機械工程學報,2003,39(6):58-62.
[5]韓水華,盧正鼎,陳傳波.基于幾何推理的裝配序列自動規劃研究[J].計算機輔助設計與圖形學學報,2000,12(7):528-532.
[6]Luong M R,Abhary K.Assembly sequence planning and optimization using genetic algorithms[J].Applied Soft Computing,2003,2(3):223-253.
[7]Lai H,Huang Y.a systematic approach for automatic assembly sequence plan generation [J].International Journal of Advanced Manufacturing Technology,2004,24:752-763.
[8]Nguyen D,Widrow B.Improving the learning speed of 2-layer neural networks by choosing initial values of the adaptive weights[J].Proceedings of the IJCNN,1991,3:21-26.
[9]Liu G,Li X.The improvement of BP algorithm and self-adjustment of structural parameters[J],OR Transactions,2001,5(1):81-88.
猜你喜歡
計算機應用(2022年2期)2022-03-01 12:33:42
計算機應用(2022年1期)2022-02-26 06:57:42
計算機應用(2021年4期)2021-04-20 14:06:36
計算機應用(2021年3期)2021-03-18 13:44:48
計算機應用(2021年1期)2021-01-21 03:22:38
小讀者(2020年2期)2020-03-12 10:34:06
趣味(語文)(2018年1期)2018-05-25 03:09:58
學苑創造·A版(2015年6期)2015-07-01 09:00:12
小天使·一年級語數英綜合(2015年2期)2015-01-14 06:35:05
英語學習(2007年8期)2007-12-31 00:00:00
