基于概念的視頻檢索中概念語義匹配算法研究
2011-01-29 09:38:58張皓翔尚麟宇
泰山學院學報 2011年6期
張皓翔,尚麟宇
(北京交通大學軌道交通控制與安全國家重點實驗室,北京 100044)
為了實現基于概念視頻檢索中從底層內容到查詢的語義貫通,應用基于WordNet詞典的語義相似度算法,通過對三種不同原理的算法對比應用,得出基于信息量算法在本應用中更有優勢,語義匹配可以提高檢索精度,最優映射數目為2至3個,以及在目前發展水平下,映射到合適的概念比檢測器精度更合適四個重要結論.
語義視頻檢索;相似度算法;查詢預處理;概念檢測器過濾;映射數目
1 引言
統計顯示,著名的視頻共享網站YouTube每天新增6.5萬部視頻,網絡視頻量在以驚人的速度增加.基于概念的視頻檢索技術不用人工標注,直接根據視頻內容建立中間語義概念進行索引,滿足了應用需求[1-3].但是基于概念的視頻在底層特征到上層用戶查詢之間存在著語義鴻溝,如何跨越語義鴻溝,實現語義上的貫通,成為人們的研究熱點[1-2].
在目前的發展水平上看,基于語義概念的視頻檢索包括概念檢測、查詢到概念的匹配和結果融合三個核心內容[3],其中概念檢測模塊實現了從視頻內容到語義概念的語義鴻溝跨越,但查詢到概念的匹配通常采用布爾方法,即使是相似度計算也沒有涉及語義.這樣就導致了從查詢到底層特征的語義中斷.為了實現從查詢到底層內容的語義貫通,引入基于WordNet詞典的語義相似度算法[4],結合理論分析,對語義匹配進行研究,得到了語義貫通會提高檢索精度,基于信息量的算法有優勢,最優匹配數目以及現有條件下,匹配概念數目比較重要的結論.
2 相關工作
在查詢到概念的映射模塊,根據使用的特征不同可以分為:基于文本特征的映射;基于視覺內容的映射[5]等.在本文的實驗中沒有用到樣例查詢,只是對查詢主題的文本描述,所以本文研究是基于文本特征的映射.基于文本的映射主要包括兩步:
第一步是查詢和概念的預先處理,如詞根化,去除停用詞,高頻詞,并進行相應的格式變換.第二步是映射.可以通過判斷查詢中是否包含概念描述中的詞,來確定查詢是否匹配到該概念,完成布爾匹配.或者通過一些相似度計算方法實現軟匹配[6],如基于向量空間模型的相似度計算[3]語言模型[4]等.但是這些研究都沒有涉及語義的層面,如“person”和“car”從詞形或者詞義上看都沒有關系,語義上卻有相關性,因為日常生活中,人經常是需要車作為代步工具的,這用布爾匹配或者向量空間模型是無法表示的.
WordNet語義詞典是由Princeton大學研制出的聯機英語詞匯檢索系統,根據詞義而不是詞形來組織單詞.基于這種詞典結構有很多種算法,文獻[5,7,8]計算兩個單詞之間的相似度,[9]根據上下文建立向量計算形似度,[11]根據詞典的路徑長度計算相似度,[6]根據信息量計算相似度.另外在查詢到概念映射模塊,[9]只選擇最優的一個概念,[10-11]的概念檢測器集合比較小,都沒有涉及檢測器精度過濾這樣的問題.
在本論文中,第3部分介紹用到的語義相似度算法,以及概念檢測器過濾方法.第4部分介紹對概念視頻檢索實現語義貫通的實驗,包括要解決最優映射數目和概念檢測器過濾問題,最后是結論和進一步的工作.
3 語義匹配方法
WordNet核心組織原則是由同義詞集合組成上下位關系,將單詞由詞形組織轉化為語義組織.基于WordNet的語義相似度算法有三種原理.
3.1 基于路徑長度的算法
針對WordNet的詞典結構,很直觀的計算相似度的方法是計算兩個單詞之間的路徑長度.比如說要計算nickel和credit card的相似度,從結構樹的分支nickel往上尋找到第一個同時包含這兩個單詞的概念,Medium of Exchange,從這個單詞向下找到另外一個分支Credit Card,共有七步,可以據此得到兩個單詞的相似度.WUP和LCH是基于路徑長度的算法.
3.2 基于信息量的算法
基于信息量的算法RES,JCN是根據單詞在訓練語料中的出現頻率計算熵值得到相似度.
RES算法公式如下:

JCN算法公式如下:
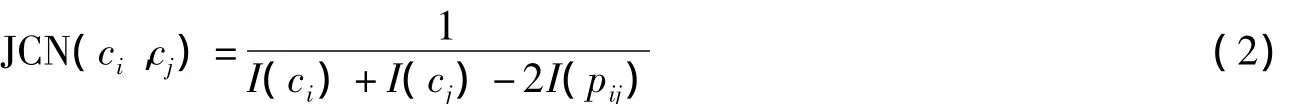
公式中的I表示熵值,即信息量.詞典中單詞的出現頻率是從Brown Corpus of American English(100萬個單詞,涵蓋新聞、自然科學領域等)語料庫訓練得到的.
3.3 基于二次共現信息的算法
基于二次共現信息的算法VECTORE和LESK是根據Harris的分布假設理論提出,分布假設理論指語義相似的詞在同一語言文本中共同出現的概率相比于沒有語義關系的詞更大.因此根據詞典中單詞的注釋信息建立二次共現上下文向量,計算兩個單詞向量空間的夾角余弦得到相似度.
這三種原理的方法都是基于WordNet語義詞典,因此計算得到的是語義相似度.將其應用到基于內容的視頻檢索中,可以實現查詢到中間概念的語義匹配.
3.4 概念檢測器過濾方法
對每個概念檢測器計算其可信度,公式如下,SHLF_i表示鏡頭S在第i個概念檢測器中的產生概率,系統中我們設η=0.1,那么概念檢測器K的可信度計算公式如下:
為了最大化這些概念檢測器的精度,從TRECVID2007HLF任務中選擇最優的6個結果進行融合.取列表中的前500個鏡頭,根據每個鏡頭在提交列表中的位置信息按如下公式計算:
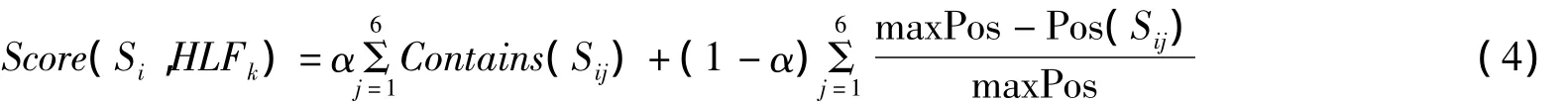
其中Contains(Sij)表示列表j中是否包含鏡頭Si.maxPos表示列表里最大的排序數,這里為500. Pos(Sij)表示鏡頭Si在列表j中的排序.公式的前半部分表示有多少個列表中包含鏡頭Si,后半部分進一步描述鏡頭Si在這些列表中的重要程度.
4 實驗
基于語義概念的視頻檢索包括概念檢測、查詢到概念的匹配和結果融合三個核心內容,如下圖1所示.
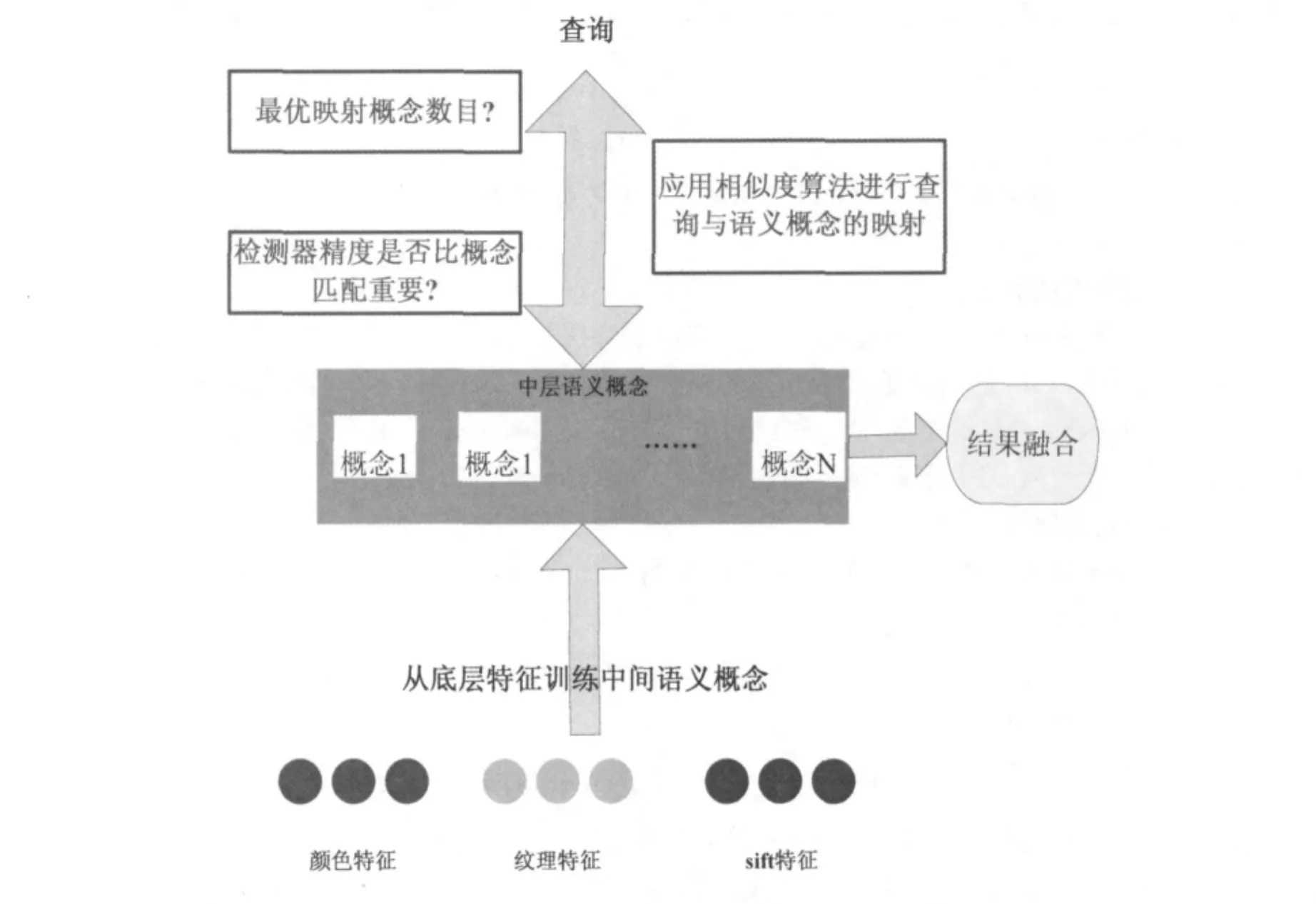
圖1 基于概念的視頻檢索框架圖
在底層內容到中間語義概念模塊,采用香港城市大學訓練的374個LSCOM基于局部描述子的概念檢測器,用SVM支持向量機方法訓練得到.在結果融合模塊,工作是把多個排序結果融合為一個,即最終的視頻檢索結果.可以采用1∶1的系數進行融合[5],在本實驗中,采用有權重的融合方法.
實現語義的貫通,需要跨越查詢和中間概念的語義鴻溝.在這個模塊,采用國際檢索會議TRECVID2007年的24個查詢主題,應用語義相似度算法后,應該得到如表1所示的結果.
其中“0197”到“0220”是TRECVID2007年的24個查詢主題編號,“Actor”到“Yasser_Arafat”是香港城市大學訓練的374個概念.
將三種原理的六種語義相似度算法分別進行計算得到如表所示的結果,來驗證信息量算法在基于內容視頻檢索上的優勢.

表1 相似度比較結果示意圖
根據不同的語義相似度算法得到24個主題的檢索結果,用Trecvid評測工具對結果進行評測.
4.1 最優映射數目實驗
同布爾映射不同的是,語義匹配的結果經過歸一化和排序之后,需要選擇一定數目的概念,數目不同對結果的影響也不同.如果選擇的概念數目少,會丟失查詢主題信息的可能;如果選擇的概念數目多,會造成混入噪聲的可能.
對每個算法的每個主題選擇2~5個概念進行實驗,如對WUP算法計算出來的查詢和概念的相似度,選擇前2個概念融合結果,計算24個查詢主題的平均MAP值,再選擇三個概念和四個概念,分別計算平均MAP值,將三個值進行比較,得到的最好結果對應的映射概念數目視為最優.

圖2 最優映射概念數目實驗結果
圖2中的橫軸代表六種算法,每種算法的直方圖從左到右依次代表映射2到5個概念,縱軸代表映射精度,即平均MAP值.從實驗結果來看,除了JCN算法的最優映射數目為3個,其它的算法映射兩個概念得到最好的結果,隨著映射概念數目的增多,融合效果會變差,所以最優的映射個數是2~3個.
4.2 算法應用結果比較
將語義相似度算法應用到基于概念的視頻檢索中,根據實驗數據,對不同原理的語義匹配效果進行分析.
表2是各個算法的MAP值:(映射概念數目2個到3個的結果算術平均)

表2 語義匹配效果
在視頻檢索中采用布爾匹配的映射方法,得到的檢索結果平均MAP值為0.0156,所以可以從表3中看出,上述六種語義算法的應用相比于布爾匹配都可以提高檢索精度.
從圖2中可以看到,基于路徑長度的算法LCH要優于WUP,基于二次共現信息向量的算法VECTOR要優于LESK,基于信息量的算法RES和JCN結果相當.將查詢主題映射到2個概念時,RES的應用效果最好,將查詢主題映射到3個概念時,JCN的應用效果最好.這兩種算法都是基于信息量的語義算法,所以基于信息量的算法在視頻檢索的語義匹配占有優勢.
而基于二次共現信息向量方法,由于對詞性沒有限制,應該體現應用優勢,在這里可能是數據中的名詞居多,因此這兩種算法特有的優勢沒有發揮出來.
相比于前兩種原理的算法,基于信息量的相似度算法減少了詞典結構不合理性對結果的影響,融入了人類語言中不同單詞出現的頻率對語義的作用,所以會更有優勢.
4.3 語義概念過濾
從查詢到中間概念的匹配采用語義匹配方法之后可以提高檢索的精度,并且用基于信息量的相似度算法為最好.但就目前的研究情況,關于語義匹配的一個問題是概念訓練數目不夠多并且精度不夠高.
美國CMU Alex G.Hauptmann領導的研究組得出人工語義概念研究的理論基礎:(1)關于語義概念集的大小:用幾千個(<5000)概念就能達到很高的檢索精度,并且每個概念的檢測精度不用太高(也不能低于MAP=10%),可以達到和文本檢索相當的效果(MAP=65%).
從這個理論出發,目前比較成熟的概念檢測器如香港城市大學的374個LSCOM基于局部描述子的概念檢測器,相對于5000個概念,數目顯然很少,并且訓練的概念精度也都不是很高,需要過濾.因此在語義匹配問題上出現了選擇題:(1)映射到合適的概念,但有些概念檢測器的精度比較低;(2)映射到較少的概念,但是概念檢測器的精度較高.這兩種情況下的語義匹配結果是不同的.下面的實驗驗證了在目前的條件下,第一種情況的語義匹配結果更好.
結果按照精度從高到低的順序排序,選擇域值為1,得到187個概念進行語義匹配實驗,依次是六種算法映射到2~4個概念,得到最后的視頻檢索精度(平均MAP值)如表3所示:

表3 概念檢測器過濾實驗結果
從表中可以看到,匹配概念數目為2的時候,只有三種方法的平均檢測精度上升,WUP、LCH和RES算法的檢測精度值甚至下降.主題映射到3個概念時,應用效果有了明顯的下降.
所以在目前的研究水平上,映射到合適數目的概念比過濾檢測器精度效果更好.
5 結論和進一步工作
通過以上的實驗,我們得到如下的結論:
(1)在查詢到概念的匹配模塊,采用語義匹配方法會實現語義貫通,提高檢索精度,使得結果從平均MAP0.0156提高到0.02235(RES),0.02145(JCN);
(2)基于WordNet的相似度算法中,基于信息量的算法減少了詞典結構不合理性對結果的影響,融入了單詞頻率對語義的作用,因此更有優勢;
(3)語義匹配最優映射概念數目為2~3個.從實驗分析,映射到一個概念的時候,會丟失查詢主題信息,映射到4個以上概念的時候,會引入誤匹配噪聲,對結果產生消極影響;
(4)在概念檢測器目前的發展水平上,將查詢主題匹配到合適數目的概念比映射精度較高的概念效果要好.結合4.3節理論分析,如果有5000個概念,即使精度比較低,也能得到滿意的結果,但是實驗中用到的374個概念相對于5000概念,顯然比較少,所以單純提高檢測器精度并不能改善結果,大規模的訓練語義概念應該是今后發展的重點.
本論文在基于概念的視頻檢索中實現了語義匹配,從查詢到底層內容的語義實現了貫通,提高了檢索精度.下一步的工作是針對查詢和概念的零概率問題,提出統計和規則相結合的查詢擴展方法,用擴展后的查詢進行概念匹配,以期提高檢索精度.
[1]Han J,Ngan K N,LiMingjing,etal.Amemory learning framework for effective image retrieval[J].IEEE Transactionson Image Processing,2005,14(4):511-524.
[2]魏維,游靜,劉鳳玉,許滿武.語義視頻檢索綜述[J].計算機科學,2006,2(10).
[3]Pedersen T.,Patwardhan S.,Michelizzi J.Wordnet::similarity-measuring the relatedness of concepts[J].In AAAI,2004,(9).
[4]D.Wang,X.Li,J.Li,B.Zhang.The importance ofquery-concept-mapping for automatic video retrieval[J].In ACM Multimedia,2007,(11).
[5]劉群,李素建.基于《知網》的詞匯語義相似度計算[J].中文計算語言學,2002,(7):59-76.
[6]X.Li,D.Wang,J.Li,B.Zhang.Video search in concept subspace:A text-like paradigm[J].In Proc.of CIVR,2007,(8).
[7]Z.Wu,M.Palmer.Verb semantic and lexical selection[J].In Annual Meeting of the ACL,1994,(12).
[8]Resnik P.Using information content to evaluate semantic similarity in a taxonomy[J].In IJCAL,1995,(6).
[9]C.G.Snoek,B.Huurnink,L.Hollink,M.de Rijke,G.Schreiber,M.Working.Adding semantics to detectors for video retrieval[J].IEEE transactions on Multimedia,2007,(11).
[10]A.Haubold,A.P.Natsev,M.R.Naphade.Semantic multimedia retrieval using lexical query expansion and model-based reranking[J].In Proc.of ICME,2006,(5).
[11]M.G.Christel,A.G.Hauptmann.The use and utility of highlevel semantic feature extraction[J].In Proc.of CIVR,2005,(7).
猜你喜歡
現代裝飾(2022年1期)2022-04-19 13:47:32
開放教育研究(2020年2期)2020-03-31 01:54:14
現代裝飾(2020年2期)2020-03-03 13:37:44
中學生數理化·高一版(2018年9期)2018-10-09 06:46:48
中學生數理化·高一版(2017年9期)2017-12-19 12:15:14
湘江法律評論(2016年0期)2016-06-15 20:29:32
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
衡陽師范學院學報(2015年2期)2015-02-26 03:24:39
當代修辭學(2011年6期)2011-01-29 02:49:50
