兩種數據校正模型性能的統計特征分析與比較
2011-10-18 10:31:50延樹港周溪召高林陳晶
統計與決策 2011年5期
關鍵詞:模型
延樹港,周溪召,高林,陳晶
(1.上海海事大學a.物流工程學院;b.商船學院,上海201306;2.華東理工大學信息學院,上海200237)
兩種數據校正模型性能的統計特征分析與比較
延樹港1a,周溪召1a,高林2,陳晶1b
(1.上海海事大學a.物流工程學院;b.商船學院,上海201306;2.華東理工大學信息學院,上海200237)
針對傳統化工數據校正模型,文章提出了一種改進型校正模型,并對兩種模型在單一平衡約束的校正效果的統計特性進行了定量分析與比較,得出了兩種模型在不同工藝要求下各自的適應情況,可為數據校正工作的最佳決策提供理論依據。
數據校正;平衡約束;誤差;方差
0 引言
自Kuehn和Davidson提出數據校正方法[1]以來,一直采用在滿足物料、能量等平衡關系的條件下,以與對應測量值偏差的平方和最小的解作為校正值,這種校正模型一直沿用至今。目前數據校正領域的研究重點多放在如何根據傳統模型選擇高效的全局解搜索方法,以節省計算時間和提高搜索全局最優解得成功率,而對傳統模型的校正性能很少做定量分析。本文擬在綜合考慮各種影響因素的情況下,提出將平衡關系加入到校正模型中的一種改進模型,并從數理統計的角度對兩種模型進行定量分析與比較,以說明兩種模型各自所適用的場合。
1 傳統數據校正模型簡介
上世紀60年代,Kuehn和Davidson用拉格朗日乘子法求解帶線性約束的最小二乘問題,從而揭開了工業過程數據校正的序幕。校正的準則為:在滿足物料平衡、熱量平衡、化學反應計量關系或其它物化關系的條件下,要求已測數據的校正值與其對應的測量值的偏差的平方和最小。在傳統模型中,測量數據的校正值嚴格滿足平衡約束,在采樣數據中不存在大誤差的情況下可以實現良好的校正結果。但是當參與校正的數據中局部測點隨機誤差分布的方差相對于其它測點顯著較大時,而求解過程由于必須滿足剛性的約束關系,導致該測點誤差被硬性平攤到其它各個測點。此時若采用傳統模型,相當于用大部分測點數據的劣化來換取少數測點數據的優化,從許多工程實際角度來看是一種得不償失的校正過程。許多學者針對傳統模型未考慮過失誤差的問題,提出了一些解決辦法。這些方法都是在數據校正之前進行顯著誤差偵測和處理[2][3][4][5],但均無法確保顯著誤差被準確無誤的偵測,導致依概率出現的大誤差難以有效剔除,這些大誤差對后續的校正模型的抗擾性提出了很高的要求,傳統校正模型由于剛性的平衡約束關系難以適應此類情況。
2 改進模型的提出與兩種模型的數學表述
為了方便統計分析與比較,設定如下前提:
(1)不同測點的測量誤差相互獨立;
(2)誤差分布均呈高斯分布,分布參數因工況各異,分布的對稱軸為理論真值。
同時為了分析時的規范,對分析過程中用到的符號形式做如下約定:
(1)測點的理論真值Xo:xo1,xo2,xo3,…,xon,n表示測點個數(注:該值在假定傳感器絕對精準情況下測得,現實工藝過程中無法獲得。);
(2)測點的采樣值X:x1,x2,x3,…,xn;
(5)測點的采樣誤差△X=X-Xo:△x1,△x2,△x3,…,△xn;
(6)平衡方程殘差R:r1,r2,r3,…,rn;
(7)約束方程中各測點的正負號表示:bji,表示第j個方程的第i個測點;
2.1 傳統數據校正模型的數學表述
對于傳統數據校正模型有:
(1)理論平衡式:
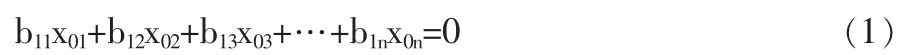
(2)實際平衡式:

(注:由于式中各測點存在隨機誤差,所以存在滿足隨機分布的殘差r)
式(2)-(1)即得到由各測點誤差引起的平衡約束關系殘差式:
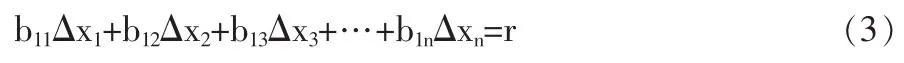
式(3)表明,各測點隨機誤差的代數和造成了平衡關系式的殘差,數據校正的目的就在于剔除殘差R。而數據校正方案優劣的本質在于在剔除殘差R的過程中,各個測點的采樣誤差是否也隨著校正過程依一定概率縮減。
(3)校正后的平衡式:
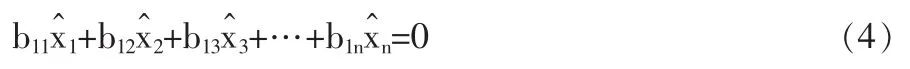
式(4)表明,經過校正處理后得到的值應滿足理論平衡約束方程。
式(4)-(2)即得到校正偏移量與殘差相抵的關系式:
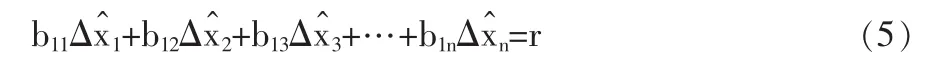
式(5)表明,校正過程本質是抵消殘差,各測點數據做相應改變使滿足理論平衡關系式。在最優方案中,各測點校正方向均與減小殘差的方向相一致。若校正方案中出現某兩個測點的校正增量相抵消,則此方案不是最佳方案。
綜上所述,傳統校正模型可用如下形式表述:
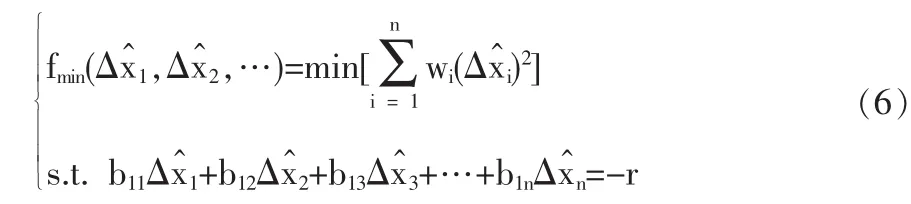
其中約束條件也可寫作式(4),兩者等效。
2.2 改進模型的提出及數學表述
改進模型的主要思想是:將約束方程中的所有等式約束轉化成一定條件下的不等式約束,即容許等式約束在一定范圍內存在殘差,將殘差連同所有的約束關系放入到校正目標函數當中[6]。具體數學表述如下:
理論平衡式與實際平衡式:同(1)和(2)式。
平衡關系殘差式:
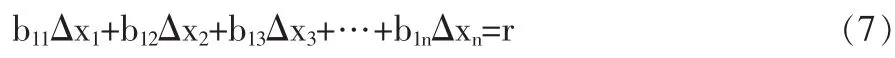
校正后的平衡式:
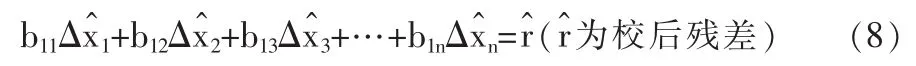
式(8)—(10)即得到校正偏移量與殘差相抵的關系式:
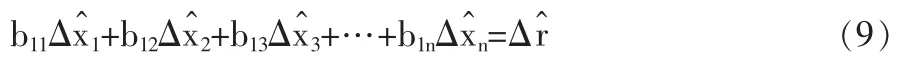
改進模型中△r贊為殘差偏移量。與傳統模型區別在于△r贊并非完全抵消掉r。這是由于傳統校正模型為等式約束,要求校正解嚴格滿足理論平衡約束方程,而新校正模型則為不等式約束,允許校正處理之后依然存留部分偏差。
由此,新校正模型可用如下形式表述:
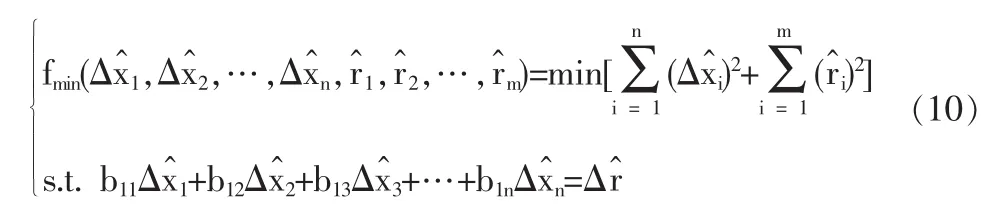
由于改進模型的約束關系實際為不等式約束,為了方便分析,需要從形式上將式(3)~(9)改變成傳統模型的形式,具體操作如下。
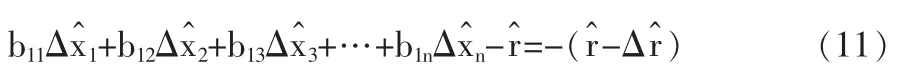
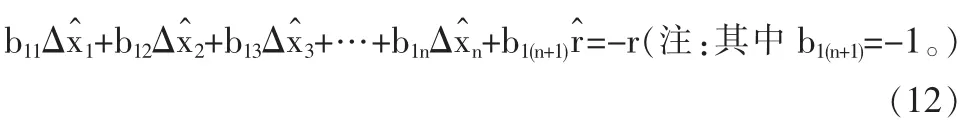
這樣,式(12)從結構形式上與傳統模型相同,只是變量的向量多出一維,意味著解空間多出一個自由度,而全局最優的解很可能在新拓寬的解空間當中。
3 兩種模型性能的定量分析與比較
本文著重論述在單一約束關系情況下兩種模型校正結果的統計特性。在單一約束情況下所有測點在式中的代數地位完全并列。在約束為“總校正效果剛好平衡掉方程殘差”的情況下,要求每個測點為了“平衡掉殘差”這個目的貢獻一份力量,并且模型校正目標函數的實質要求是在總貢獻固定(為相對常數r)的情況下每個測點貢獻的力量要盡可能的小。由此產生一個命題:每個測點數據的貢獻大小相同,并且貢獻的方向均為抵消殘差的方向(注:抵消殘差的方向相同不等同于數據在增減方向上相同)。如果該命題成立,則每個測點的校正偏移量就可以用殘差的線性函數定量的表達,每個測點校正之后的誤差特性也可以定量的表達和討論。以下為該命題的數學表述與論證過程:
當校正偏移量為-r時使fmin最小的解滿足
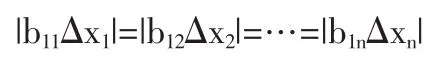
將b1i△xi代入得到:
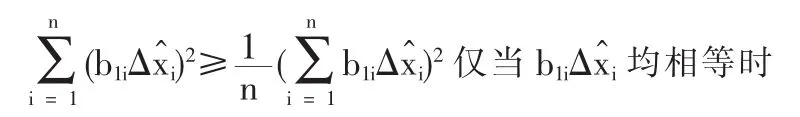

所以傳統模型求得全局最優解時,每個測點的校正偏移量為-r/n(負號表示與殘差抵消的方向,即為抵消殘差做積極貢獻的方向)。由上述結論可知,只要能將殘差r的數值情況定量的表達出來,就可以定量的表達校正偏移量的數字特征。殘差r是平衡關系中各測點誤差的線性組合,各測點誤差是滿足相互獨立的、參數各異的高斯分布:N(μi,σ2i)。的分布參數滿足:
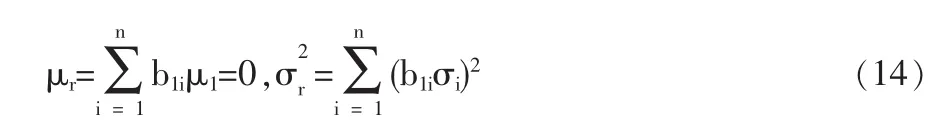
3.1 傳統模型中的數字特征
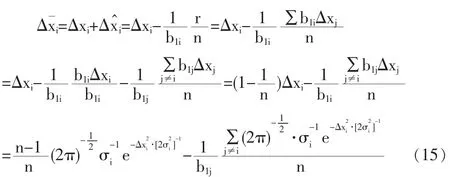
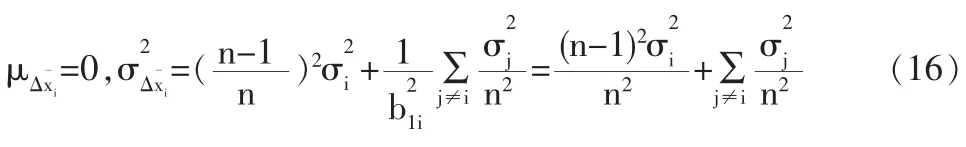
3.2 改進模型中的數字特征
由前述公式可知:當且僅當等式左邊各項均相等且均等于-r/(n+1)時,fmin有最小值,即當贊=r/(n+1)時,fmin有最小值。關于其中的符號,也可從工程的角度來做解釋:由于殘差r在校正過程中呈縮小趨勢,校正后的殘差贊為[0,r]區間中較為接近0點的基值,所以與r同向,而校正偏移量△贊由于是抵消r的作用,所以贊與r反向。由于
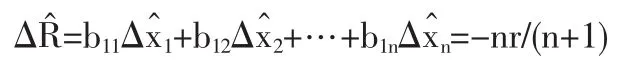
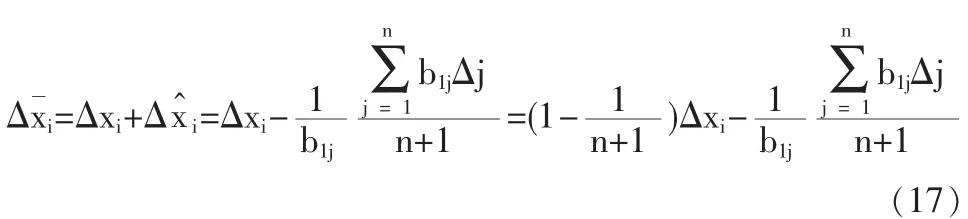
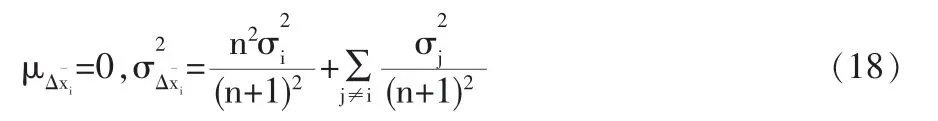
3.3 兩種模型數字特征的定量比較
3.3.1 所有測點方差相等或近似的情況(無局部測點方差較大的情況)
當所有測點方差均相等,即σ1=σ2=…=σn=σ,則:
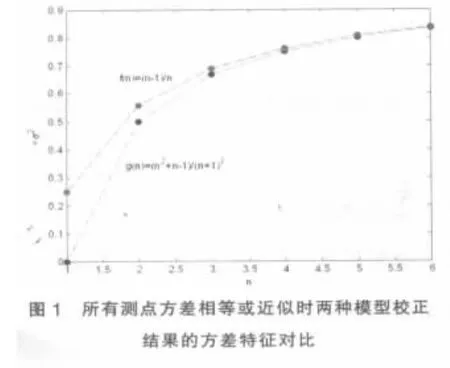
由圖1可知,隨測點數增加,兩種模型計算結果均向σ趨近,在達到0.8σ后增幅極小,并且兩種方法從n=3開始差別極小,即在測點采樣值標準差相等或相近的情況下,兩種模型處理結果的數字特征基本基本相同。
3.3.2 局部測點方差較大的情況
當局部測點誤差的方差顯著大于其他測點,即
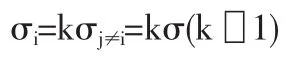
(1)對于方差較大測點的分析
傳統模型校正結果的方差特征:
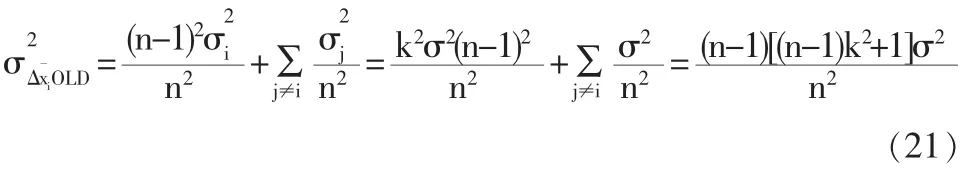
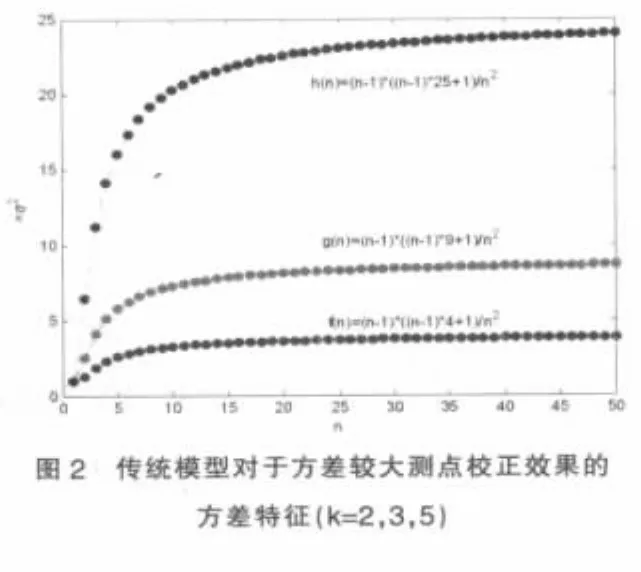
由圖2可見,當標準差倍數k分別等于2、3、5時(此時該測點初始方差分別為其他測點的4、9、25倍,具有廣泛的代表性),隨著測點數的增加,在達到0.8σ之后增幅趨緩,即對于方差顯著較大的測點,傳統模型約以0.7~0.8的比例將該點隨機誤差減小。
改進模型校正結果的方差特征:
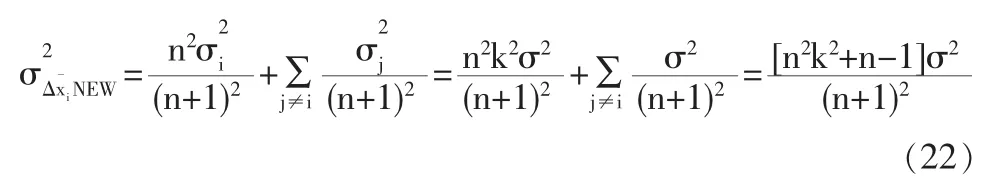
根據式(21)與(22),兩種模型的方差差異如下:
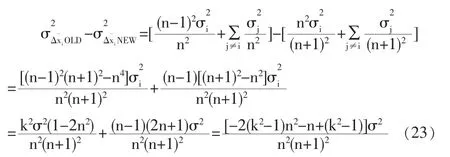
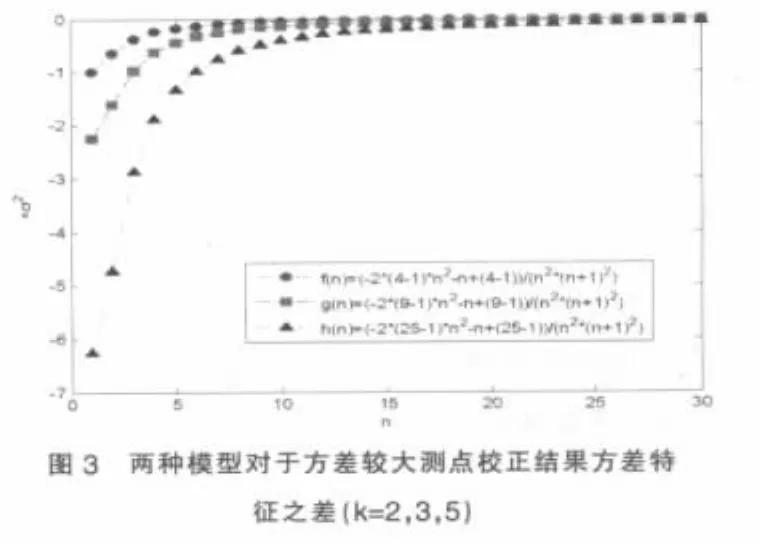
由圖3可見,就該測點而言,傳統模型校正后的誤差小于改進模型。這是由于傳統模型為了保證嚴格的平衡約束關系,將該測點的誤差硬性分攤到其他測點上,而改進模型則相對較好的防止了大誤差測點的誤差擴散。
(2)對于其它測點的分析
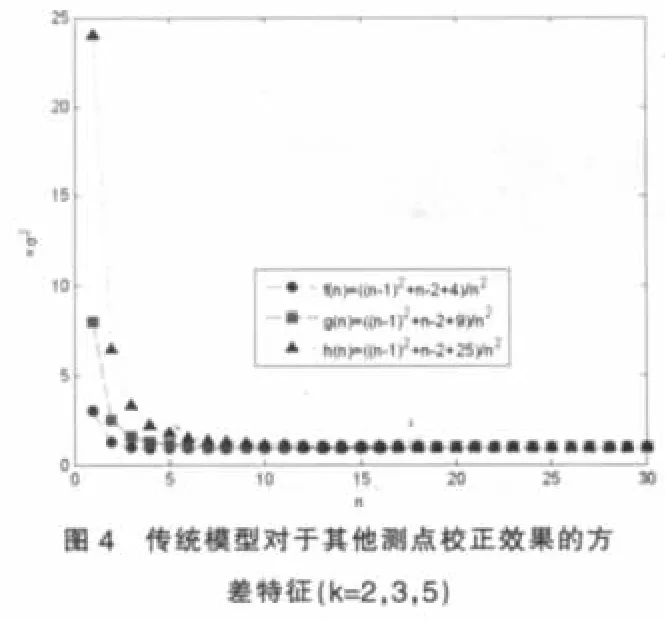
傳統模型校正結果的方差特征:
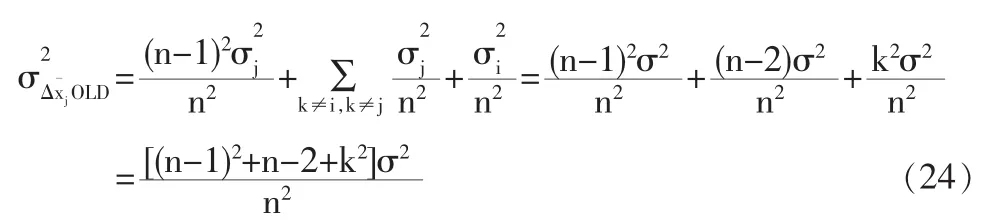
改進模型校正結果的方差特征:
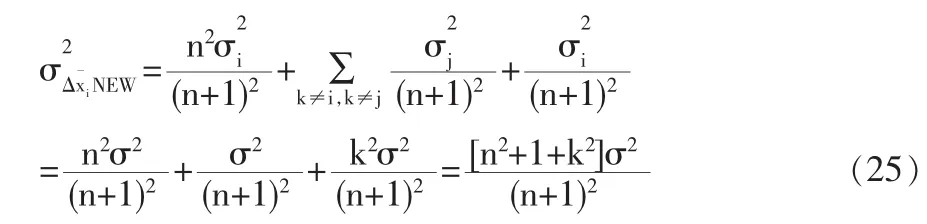
根據式(24)與(25),兩種模型的方差差異如下:
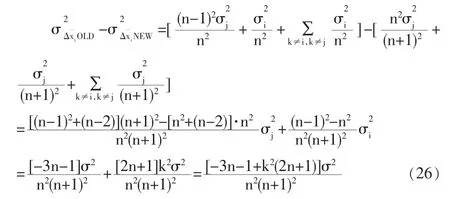
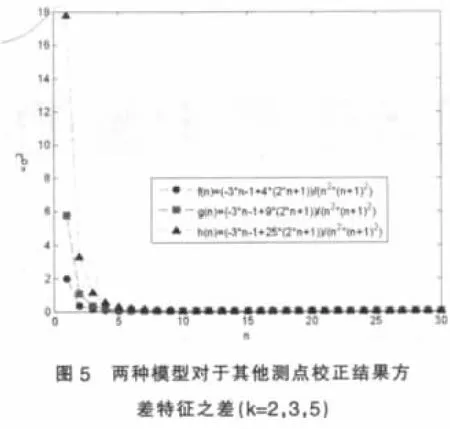
由圖5可見,對于其他測點,傳統模型校正后誤差的方差均大于改進模型,證實了傳統模型將大誤差測點的誤差分攤到其他測點上,使整個系統的測點均受到明顯污染,而改進模型則相對穩健一些。
4 結論
本文應用概率論及數理統計的方法較為詳細地定量分析并推理了兩種校正模型在單一約束關系下采樣數據隨機誤差分布情況不同時的校正效果,根據概率統計理論得出的定量結論可以看出,改進模型以一定理論和操作上的優勢:
(1)方便運用啟發式算法進行可行解的搜索。傳統模型求解過程要求校正解嚴格滿足平衡約束關系。當平衡關系中部分解向量確定后,剩余向量由于與這些向量之間存在由平衡約束關系決定的相關關系而被確定下來,被隨之確定的向量可能嚴重偏離原始采樣值,卻無法自行糾正。這使得求解過程捉襟見肘,實際操作中很難顧全所有變量。而改進模型把等式約束轉化成為不等式約束,并將不等式的“傾斜程度”作為優化目標中的一個參考量,不但與傳統模型等效,而且在生成解向量的過程中,維與維之間互不約束,拓展了求解空間,使求解過程更容易運用各種優化算法,只在評判解的適應度環節中將劣質解篩除。
(2)避免個別測點依概率產生的大誤差過分污染其他測點。傳統校正方法會有預處理環節,校正之前對顯著誤差進行甄別,但無法確保能將所有顯著誤差甄別出來。當甄別后的數據中依然存有顯著誤差時,如果采用傳統模型,由于必須滿足剛性的約束關系,誤差無法避免地平攤到其他測點中。改進模型的優勢便在于,平衡約束將發揮積極的“吸能”效用,將誤差的一部分吸入不等式約束關系中,以避免其他測點數據受到直接的沖擊。
綜上所述,通過對兩種模型性能的統計特征定量分析,可知改進模型更易于進行編程求解,在各測定誤差統計特征相近時與傳統模型等效,并在局部測點誤差較大時,校正效果明顯優于傳統模型,可為化工生產決策提供更加科學的決策支持。
[1]Kuehn,D.R,Davidson H.Computer Control:Mathematics of Control [J].Chem Eng Prog,1961,7(6).
[2]Madron F,Veverka V[J].AIChEJ.,1992,38(2).
[3]袁永根.化工過程測量數據校正的序貫模塊算法[R].第四屆化工過程的數學模擬分析年會,1993.
[4]王希若,榮岡.高置信度的顯著誤差綜合檢測法[J].儀器儀表學報, 2000,21(2).
[5]葉蕾,侍洪波.動態過程的數據校正和過失誤差的偵破[J].世界儀表與自動化,2005,(9).
[6]陳晶.電廠數據在線校正系統建模及誤差特征的研究[D].華東理工大學碩士學位論文,2009.
(責任編輯/亦民)
TP274
A
1002-6487(2011)05-0004-04
延樹港(1970-),男,山東東營人,博士研究生,研究方向:交通信息數據處理。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
