基于組合分類挖掘模型的調查問卷數據預處理
2011-10-18 10:31:48李春林李冬連萬平
統計與決策 2011年5期
李春林,李冬連,萬平
(河北經貿大學數學與統計學學院,石家莊050061)
基于組合分類挖掘模型的調查問卷數據預處理
李春林,李冬連,萬平
(河北經貿大學數學與統計學學院,石家莊050061)
文章在Bates和Granger對時間序列的組合預測模型的理論基礎上,靈活運用數據挖掘的思維和Clementine數據挖掘軟件中的相關節點,充分利用問卷中已有信息構造組合分類數據挖掘模型,對《影響中國人際關系和諧因素調查問卷》進行分類了預處理。
調查問卷;數據挖掘;數據預處理;組合分類模型
0 引言
問卷調查所獲的微觀數據,尤其在調查范圍廣、人群雜、問卷數量多的情況下,難免會出現工作失誤、被訪者不配合、抽樣方法選取不當、問卷設計不合理等現象,致使問卷數據中存在各種不一致、缺失、錯誤、冗余以及含有與定量分析方法不符的數據等情況。要保證問卷調查分析的質量,對原始數據進行清理、集成、變換和規約等預處理過程不容小覷。
面對問卷數據中的各種不符合要求,尤其是存在缺失值的情況,目前常用的方法有刪除問卷、刪除缺失值、插補法等。最直接和簡便的方法莫過于刪除問卷和缺失值,但這很可能致使結果偏差嚴重。并且這兩種方法的前提條件是問卷量很大,不符合要求的問卷很少(低于10%)[1]。插補法是利用其他數據代替和估算缺失值。如利用回歸、眾數、判定樹歸納、貝葉斯推斷方法等建立一個預測模型,利用模型的預測值代替缺失值。盡管這些方法相對復雜,但能夠最大程度地利用現存數據所包含的信息。
本文所研究問卷數據來自于“當代中國影響人際關系和諧因素問卷調查”,該項調查共獲得有效問卷2972份,其中有以下幾種形式數據需要做相應預處理:
(1)人口統計學數據的預處理。這部分主要是對數值數據進行離散化處理和對分類數據進行概念分層處理。如:本文將年齡離散化為30歲以下(不包括30歲)、30至50歲(不包括50歲)及50歲以上三個階段;將學歷分為中小學、大中專、本科、研究生四個層次。
(2)缺失值預數理。2972份問卷中的被訪者基本信息部分至少存在一項缺失的問卷量達187份;在關于當前社會道德水平(Q15)和我國民主建設(Q28)滿意度的調查題目中,問卷在答案最后設置了“說不清”選項,且分別有106個(3.57%)和497個(16.72%)被訪者選擇了該選項。但“說不清”選項并不是按Likert量測標準設置,不適合定量建模型分析,因此將其視為問卷設計不合理而作缺失值處理。
因為缺失值問卷數量比重較大,不宜作刪除處理。本文試圖利用分類模型根據已有問卷信息進行有指導地學習,建立一個分類模型,再利用所得模型對缺失值進行分類預測。因為不同的模型有自身不同的優點和缺點:神經網絡等非線性方法的精度往往要高于(線性)判別分析、Logistic回歸、線性規劃等線性評分方法;而Logistic回歸、判別分析、線性規劃等方法的穩健性則比神經網絡方法要好[2]。因此,本文試圖用組合模型對缺失值進行分類預處理。同時考慮到問卷數據不僅有數值型數據,也有分類型數據,而判別分析只適用于數值型數據,因此組合模型由Logistic回歸、CHAID決策樹和神經網絡模型構成。本文將以對Q28中“說不清”的預處理過程為例進行說明。
1 組合分類模型的原理
1.1 組合分類模型
對于組合模型的運用,學術界最常用的是Bates和Granger(1969)[3]對時間序列的組合預測模型,如文獻[3]~[6]。而對于組合分類模型的研究尚未見到文獻記載,本文在借鑒Bates和Granger關于時間序列的組合預測模型的基礎上,對組合預測模型進行適當修正,構造出組合分類模型。假設已知一個問題有K個類別,記為c1,c2…,ck;有m個分類模型適用于該問題,分別記為f1,f2,…,fm;pij=p(ci(fj)),表示第j種分類模型判斷某個樣本單元問卷單元屬于第i個類別的概率;wj為第j個模型在組合分類模型中的權重。
因此,組合分類模型可表示為:
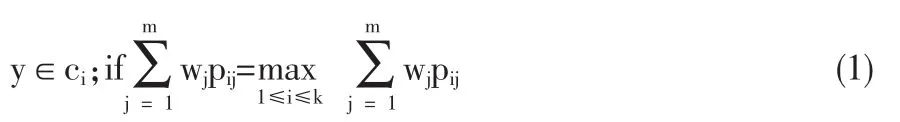
1.2 權重的確定
組合模型中,權重的選擇非常重要。常用的權重選擇方法有算術平均法、標準差法、方差倒數法、均方倒數法、主成分分析法、德爾菲法、最優加權法等。本文使用最優加權法,即對誤差平方和在最小二乘法準則下求解如式(2)所示的線性規劃問題:

如果定義Im=(1,1,…,1)T,且存在協方差矩陣∑,則有:

用Lagrange乘數法求解(3)得:
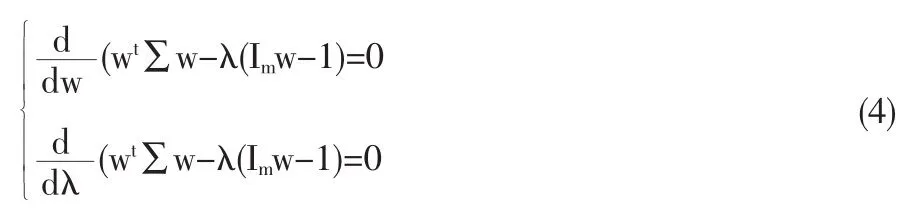
即:
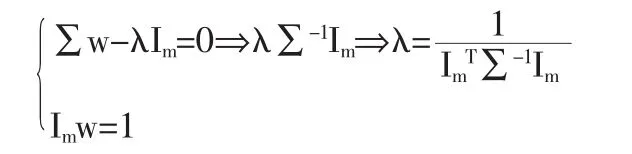
2 單一分類模型及結果
2972份問卷中,有62份因為信息缺失嚴重而無法進行預處理,故將這些問卷刪除。剩下2910份問卷中,有494個被訪者在Q28題中選擇了“說不清”選項,因此將其視為缺失值進行預處理。并以選擇其他選項的2416個有效問卷建立組合分類模型,對選擇“說不清”的494個問卷進行分類預測。
建立模型之前,將2416個有效問卷通過設置隨機種子的方式進行隨機抽樣,隨機選取70%作為訓練問卷用來建立分類預測模型,30%當作測試問卷用來檢驗模型的穩健性。本文單一分類模型的擬合過程分別通過Clementine數據挖掘軟件中的Logistic節點、CHAID決策樹節點和RBF神經網絡節點實現。
2.1 Logistic回歸分類模型
本文因為反應變量為4Likert測量形式,即受訪者對我國民主建設的態度是滿意、比較滿意、不滿意還是很不滿意,因此采用多項logit模型進行分析。將產生三個logit(即對數發生比),并將“很不滿意”定義為參照類,如式(5):

其中p1,p2,p3,p4分別表示被訪者對我國當前民主建設態度是滿意、比較滿意、不滿意和很不滿意的概率,且p1+p2+ p3+p4=1。多項logit模型將產生三套回歸系數系數:滿意對比很不滿意的對數發生比,比較滿意對比很不滿意的對數發生比,不滿意對比很不滿意的對數發生比。
2.2 CHAID決策樹分類模型
CHAID決策樹模型主要適用于市場調查和社會調查過程分析。CHAID的全稱是Chi-squared Automatic Interaction Detector(卡方自動交互檢測)。1980年,由Kass等人提出,它的理論構想主要來源于決策樹模型,根據反應變量在解釋變量上的分布來進行分類,適用于分類和序次等級數據的分析,是一種以目標最優為依據,具有目標選擇、變量篩選和聚類功能的分析方法[8]。它的基本分析思路是X2自動交叉檢驗[9],首先選定分類的反應變量,然后用解釋變量與反應變量進行交叉分類,產生一系列二維分類表。分別計算二維分類表X2的值或似然估計統計量,以最大統計量的二維表作為最佳初始分類表,并繼續使用分類指標對目標變量進行分類,重復上述過程直到滿足分類條件為止。
2.3 徑向基神經網絡分類模型
徑向基(RBF)神經網絡是由輸入層,隱含層和輸入層構成的3層前向網絡。在RBF網絡中,隱含層節點通過徑向基函數執行一種非線性變化,將輸入空間映射到一個新的空間,輸出層節點則在該新的空間實現線性加權組合[10]。徑向基函數是徑向對稱的標量函數,定義為空間一點x到某一中心xc的歐式距離的單調函數k(‖x-xc‖),x∈RN,最常用徑向基函數為高斯核函數:

其中σ為帶寬,控制函數的徑向作用范圍,xc是核函數中心。
通過Clementine數據挖掘軟件中相關節點的擬合,得到了單一模型對訓練集和測試集的擬合檢驗結果,如表1所示。
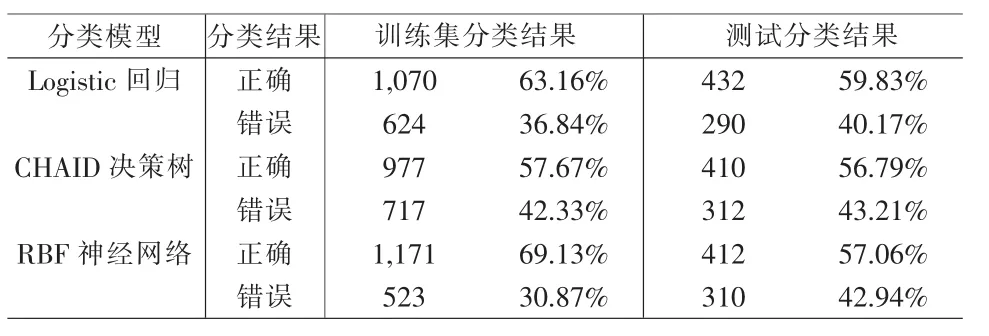
表1 單一模型對訓練集和測試集的分類結果
4 組合分類模型建立過程及結果
從表1可以看出3個單一模型各有優缺點:RBF神經網絡模型對訓練集的擬合精度達69.13%,但對測試集的分類精度卻只有57.06%;而Logistic回歸模型和CHAID決策樹模型盡管對訓練集的擬合精度分別只有63.16%和57.67%,但對測試集的分類精度仍分別達59.83%和56.79%。因此,從這些數據也進一步證明了參考文獻[3]給出的結論。
根據組合模型的理論,設測試集中第r個樣本單元在Q28上實際類別為yi,其中ci=1,2,3,4;r=1,2,…722。分類誤差為eir=yi-cir,即第j種分類模型在第r個樣本單元上的分類誤差。組合誤差為er(第r個樣本單元上的分類預測):
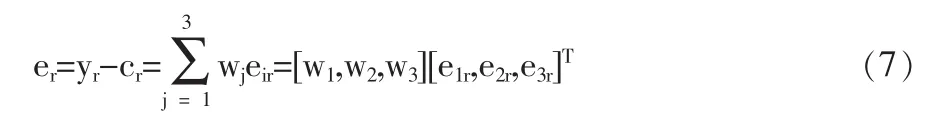
令W=[W1,W2,W3]T;Σ=[e1r,e2r,e3r]T,為第j個分類模型的分類誤差向量,則組合分類模型的誤差矩陣為e=[Σ1,Σ2,Σ3],其協方差矩陣為:
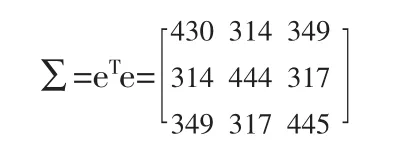
進一步得到其逆矩陣為:

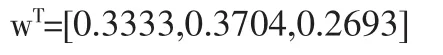
因此,組合分類模型中,Logistic回歸模型的權重為0.3333,CHAID決策樹模型的權重為0.3704,RBF神經網絡模型的權重為0.2963。
因此,本文組合分類模型可表示為如式(8):
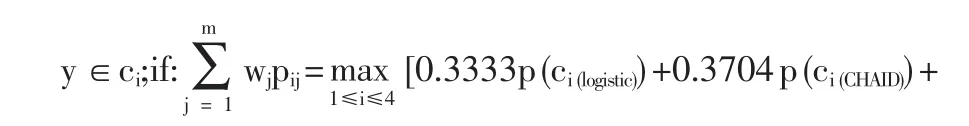

由Clementine分析結果可知,組合模型對測試集的分類準確度為62.88%。因此,最優組合分類模型從總體上起到了提高分類準確度的作用,用該模型對Q28中494個選擇了“說不清”選項的問卷進行分類預處理更為有效和可信,其結果如表2所示。
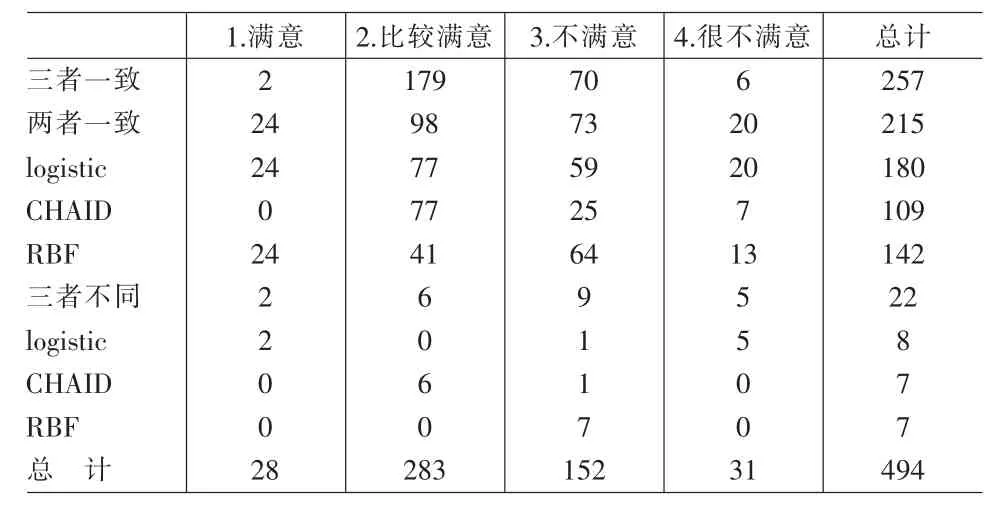
表2 組合分類模型預處理結果
4 結論
本文從問卷的特點出發,借助Clementine數據挖掘軟件構建了適合于分類數據分析的組合分類模型。并有效地對“影響當代中國人際關系和諧因素的問卷調查”所獲問卷數據的缺失值進行預處理。盡管數據預處理過程非常煩瑣和耗時,但能有效地提高數據預處理結果的準確度和可信度,并且能大大提高數據挖掘模式的質量。
[1]朱勝,馮能亮.市場調查方法與應用[M].北京:中國統計出版社, 2004.
[2]石慶炎.一個基于神經網絡——Logistic回歸的混合兩階段個人信用評分模型研究[J].統計研究,2005.
[3]Bates T M,Granger C M J.The Combination of Forecasts[J].J.Operational Research Society,1969,(20).
[4]權軼,張勇傳.組合預測方法中的權重算法及應用[J].科技創業月刊,2006.
[5]趙韓,許輝等.最優組合預測方法在家用汽車需求預測中的應用[J].工業工程,2008.
[6]劉志杰,季令等.基于徑向基神經網絡的集裝箱吞吐量組合預測[J].同濟大學學報(自然科學版),2007.
[7]王濟川,郭志剛.logistic回歸模型方法與應用[M].北京:高等教育出版社,2001.
[8]何凡,沈毅,葉眾.CHAID方法在居民衛生服務需求研究中的應用[J].數理統計與管理,2006.
[9]Chaturvedi A,Green P E,et al.SPSS for Windows,CHAID6.0 [J].Journal of Marketing Research,1995,(21).
[10]馬超群,蘭秋軍,陳為民.金融數據挖掘[M].北京:科學出版社, 2008.
(責任編輯/亦民)
O212
A
1002-6487(2011)05-0011-03
國家社會科學基金重點資助項目(2007AZX004)
李春林(1963-),男,河北任縣人,教授,研究方向:市場調研和數據挖掘。
萬平(1984-),男,湖南湘鄉人,碩士研究生,研究方向:市場調研和數據挖掘。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
電力與能源(2017年6期)2017-05-14 06:19:37
Coco薇(2016年2期)2016-03-22 02:42:52
信息通信技術(2015年6期)2015-12-26 01:16:46
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
