基于GPU實現(xiàn)漢克爾變換并行計算
2012-01-11 08:14:52戴云峰周志芳強建科
物探化探計算技術 2012年5期
戴云峰,周志芳,強建科,劉 冰
(1.河海大學 地球科學與工程學院,江蘇 南京 210098;2.中南大學 地球科學與信息物理學院,湖南 長沙 410083)
基于GPU實現(xiàn)漢克爾變換并行計算
戴云峰1,周志芳1,強建科2,劉 冰2
(1.河海大學 地球科學與工程學院,江蘇 南京 210098;2.中南大學 地球科學與信息物理學院,湖南 長沙 410083)
地球物理勘探技術日新月異,地球物理勘探數(shù)據(jù)的處理和解釋對高性能計算機的要求越來越高。相比于地震勘探,重力、磁法、電法勘探中的并行計算研究還都處于起步階段。基于GPU的并行計算能夠提供強大的計算能力和存儲器帶寬,同時具有良好的可編程性、較低的成本和較短的開發(fā)周期。這里實現(xiàn)了瞬變電磁法一維正演計算中漢克爾變換基于GPU的并行計算,比較了漢克爾變換串行算法和并行算法的計算耗時,基于GPU技術的并行計算相比串行計算,獲得了很高的加速比。
圖形處理器;漢克爾變換;并行計算
0 前言
計算機科學技術的高速發(fā)展和大型工程計算的需求,使得并行計算(Parallel Computing)技術已經(jīng)成為目前乃至今后工程計算領域中一項重要技術。并行計算是相對于串行技術而言的,并行計算可以分為時間和空間上的計算,時間上的并行就是指流水線技術,空間上的并行則是指用多個處理器并發(fā)地執(zhí)行計算。
隨著地球物理勘探工作的深度和廣度不斷提高,數(shù)據(jù)處理結果的精度要求也越來越高。高性能計算技術對于地球物理勘察數(shù)據(jù)處理有著重要的推動作用,這是因為[1]:①地球物理勘察的數(shù)據(jù)量巨大;②地球物理勘察數(shù)據(jù)中蘊涵著大量可并行計算成份。
計算機圖形處理器(Graphics Processing U-nit,GPU,俗稱顯卡)的技術定義是“具有集成轉換、照明、三角形設置/剪切、渲染引擎并且每秒至少可處理一千萬個多邊形的單芯片處理器”。GPU通用計算技術雖然在石油勘探領域中略有使用,但是還不能滿足石油工業(yè)的發(fā)展需要。地震勘探為了獲得更加精確的成像效果,由二維勘探向三維勘探發(fā)展,以及由疊后處理向疊前處理發(fā)展,隨之增加的數(shù)據(jù)處理量向高性能計算技術提出了更高的要求。GPU計算技術已經(jīng)用于加速三維有限元地震波數(shù)值模擬以及地震屬性的提取,鐘勇[2]應用GPU加速計算提取三維地震圖像的結構張量,由結構張量導向進行地震圖像擴散濾波增強預處理;劉紅偉等[3]針對疊前逆時偏移計算量大的問題,使用GPU實現(xiàn)算法加速,比傳統(tǒng)的CPU計算速度提高了一個數(shù)量級。GPU計算技術在電法勘探中的使用較少,電磁法數(shù)據(jù)處理中包含了很多大規(guī)模矩陣的計算,涉及到矩陣乘法和線性方程求解,計算量較大。大地電磁正反演研究的熱點開始向三維問題轉移,交錯網(wǎng)格法等已成為大地電磁三維正演計算的主要方法。直流電法和大地電磁法的三維正演,都存在需要求解大型稀疏對稱系數(shù)矩陣線性方程組的問題,張帆[4]使用基于GPU并行計算和基于MPI的并行計算相結合的計算模式,對這兩種電磁法已有的三維正演串行算法進行并行化處理,提高了運算效率。
作者在本文中介紹了圖形處理器GPU并行計算的原理,以及CUDA編程模型,實現(xiàn)了漢克爾變換基于GPU的并行計算,比較了漢克爾變換串行計算和并行計算的計算耗時,探討GPU在瞬變電磁法一維正演計算中的應用前景。
1 圖形處理器GPU并行計算的原理
1.1 GPU與CPU結構比較
計算機中的處理器包括CPU(Central Processing Unit,中央處理器)和GPU圖形處理器(Graphic Processing Unit,圖形處理器)。CPU提高單個芯片性能的主要傳統(tǒng)手段是提高處理器的工作頻率,以及增加指令級并行。基于GPU的通用計算技術,它主要應用圖形處理芯片(GPU)的高性能并行處理能力實現(xiàn)科學計算。與CPU相比,GPU的設計中能使更多晶體管用于數(shù)據(jù)處理(ALU,Arithmetic Logic Unit即算術邏輯單元),而非用于數(shù)據(jù)緩存(DRAM)和流控制(Control),見圖1。

圖1 CPU與GPU晶體管使用方式的對比Fig.1 Comparison of transistors used in CPU and GPU
GPU專門用于解決可表示為數(shù)據(jù)并行計算的問題,在許多數(shù)據(jù)元素上并行執(zhí)行的程序,具有極高的計算密度(數(shù)學運算與存儲器運算的比率)。由于所有數(shù)據(jù)元素都執(zhí)行相同的程序,因此對精密流控制的要求不高。由于在許多數(shù)據(jù)元素上運行,且具有較高的計算密度,因而可通過計算隱藏存儲器訪問延遲,而不必使用較大的數(shù)據(jù)緩存。數(shù)據(jù)并行處理會將數(shù)據(jù)元素映射到并行處理線程,許多處理大型數(shù)據(jù)集的應用程序都可使用數(shù)據(jù)并行編程模型來加速計算。
1.2 基于GPU的CUDA編程模型
CUDA(Compute Unified Device Architecture,統(tǒng)一計算設備架構)是一種新型的硬件和軟件架構,用于將GPU作為數(shù)據(jù)并行計算設備并在GPU上進行計算的發(fā)放和管理,而無需將其映射到圖像 API(Application Programming Interface,應用程序編程接口)。隨著以CUDA為代表的GPU通用計算API的普及,GPU的含義有可能從圖形處理器(Graphic Processing Unit)擴展為通用處理器(General Purpose Unit)。GPU擅長的是圖形類的或者是非圖形類的高度并行數(shù)值計算,GPU可以容納成百上千條沒有邏輯關系的數(shù)值計算線程,它的優(yōu)勢是無邏輯關系數(shù)據(jù)的并行計算。GPU數(shù)值計算的優(yōu)勢主要是浮點運算,它執(zhí)行浮點運算快是靠大量并行,但是這種數(shù)值運算的并行性在面對邏輯判斷執(zhí)行時卻發(fā)揮不了作用。
CUDA編程模型將CPU作為主機(Host),GPU作為協(xié)處理器(co-processor)或者設備(Device)。在一個系統(tǒng)中可以存在一個主機和若干個設備。GPU計算的模式就是,在異構協(xié)同處理計算模型中,將CPU與GPU結合起來加以利用,CPU負責進行邏輯性強的事務處理和串行計算,GPU則擅長于執(zhí)行高度并行化的線程任務。CUDA假設CUDA線程可在物理獨立的設備上執(zhí)行,此類設備作為運行C語言程序的主機協(xié)處理器操作,見圖2。例如,當內核在GPU上執(zhí)行,而C語言程序的其它部份在CPU上執(zhí)行。
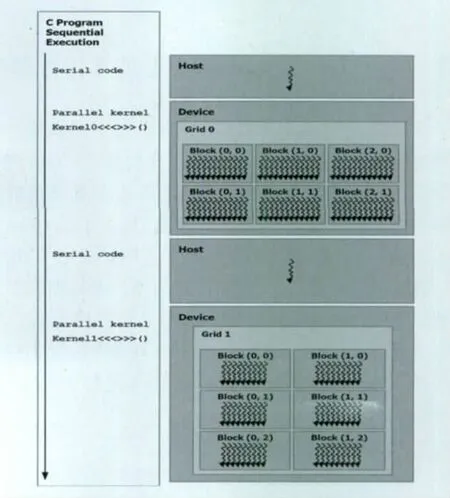
圖2 異構編程(串行代碼在主機上執(zhí)行,并行代碼在設備上執(zhí)行)Fig.2 Heterogeneous programming(serial code running on the host,parallel code executes on the device)
在CUDA編程模型中,將threadIdx設置為一個包含三個元素的向量,因而可使用一維、二維或三維索引標識線程,構成一維、二維或三維線程塊。在NVIDIA Tesla架構中,一個線程塊最多可以擁有512條線程。但一個內核可能由多個大小相同的線程塊執(zhí)行,因而線程總數(shù)應等于每個塊的線程數(shù)乘以塊的數(shù)量。這些塊將組織為一個一維或二維線程塊網(wǎng)格,見圖3。

圖3 線程塊網(wǎng)絡Fig.3 Thread blocks network
2 基于GPU的漢克爾變換并行計算
目前,基于GPU計算的并行算法主要來源于兩個方面:①將串行算法改寫成并行算法;②從數(shù)學模型出發(fā)直接構造并行算法。作者在本文根據(jù)瞬變電磁法一維正演計算的算法,用C語言編制了正演的串行計算程序,并研究使用CUDA的并行算法對串行算法進行改寫,以提高數(shù)據(jù)處理的速度。在windows操作系統(tǒng)下,本文作者所有程序都是在Visual Studio C++2005環(huán)境下運行。實驗使用的是NVIDIA Geforce 8500GT顯卡,它的計算能力為1.1。
2.1 漢克爾變換表達式
水平層狀介質上瞬變電磁一維正演公式可表示為一個雙重積分:內層含有零階和一階貝塞爾函數(shù)的漢克爾型積分,外層為正弦或余弦積分。在積分公式中,由于貝塞爾函數(shù)隨自變量緩慢地震蕩衰減,所以不采用常規(guī)的數(shù)值積分方法計算,采用數(shù)字濾波法具有良好的效果[5]。
漢克爾變換的一般表達式[6]:
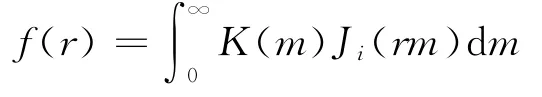
其中 Ji是i階第一類貝塞爾函數(shù);K(m)是積分變換函數(shù);m是被積變量。
數(shù)字濾波器有一組濾波系數(shù),兩個常數(shù):位移a和抽樣間隔s。位移a決定了輸入函數(shù)抽樣起始點,間隔s決定抽樣時的時間間隔。由
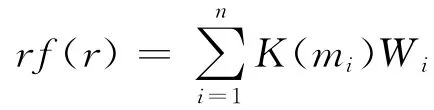
可得出
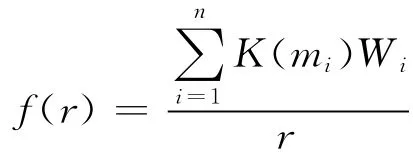
其中 mi= (1/r)*10[a+(i-1)s](i=1、2、…、n);Wi為濾波器系數(shù)。
2.2 漢克爾變換串行算法性能分析及并行算法實現(xiàn)
零階漢克爾變換的串行程序,使用clock_t和clock()函數(shù)來獲得程序各部份的運行時間。計算所耗時間與計算過程中所取時間點個數(shù)的關系見圖4,橫坐標為所取的時間點數(shù),縱坐標為對應的計算耗時(單位:S),分別測得200、300、500、700、900、1 000個時間點的程序計算耗時。在測試運行單元時間時,先清除上一次運行的解決方案,然后再生成新的解決方案。
當時間點的個數(shù)小于500點時,即使測試的是整個程序運行的時間,由于運行速度很快,加上計時函數(shù)的精度限制,所得的計算耗時幾乎為“0”值,見圖4。在這種情況下,使用并行的算法來實現(xiàn)漢克爾變換反而得不償失。根據(jù)CUDA實現(xiàn)效果原則,計算量太小使用CUDA不劃算。作者在對漢克爾變換的串行算法與并行算法進行計算性能對比時,所取時間點個數(shù)為512(單個線程塊最多擁有的線程數(shù))。
作者在本文中進行了漢克爾變換的并行計算,計算出N點的零階漢克爾變換(一階變換原理相同,不再重復)。使用取對數(shù)間隔函數(shù),獲得的對數(shù)間隔時間點,即計算式中r的值,以數(shù)組的形式作為漢克爾變換計算的輸入。對于單個的時間點計算涉及累加的操作,但各個時間點之間是沒有影響的,故具有較好的并行性。因為只是進行漢克爾變換并行計算,數(shù)據(jù)量不大,所以只使用了一個線程塊,每個線程塊中定義與時間點相同個數(shù)的線程(每個線程塊Block最多可以定義512條線程Thread),每個線程負責進行一個時間點的漢克爾變換。漢克爾變換的系數(shù)為單精度,計算結果和串行計算漢克爾變換的結果相同。數(shù)值計算的精度取決于積分區(qū)間的長度n,抽樣點的位置λi和加權系數(shù)Wi。
所取時間點數(shù)為512的漢克爾變換串行計算與并行計算性能的對比,時間單位:ms,見圖5。串行計算用時為15ms,而并行內核函數(shù)計算的用時為0.027 937ms,即使包含計算結果從顯存輸出到內存中計算耗時(圖中并行計算1代表)也僅僅只有0.525 206ms。
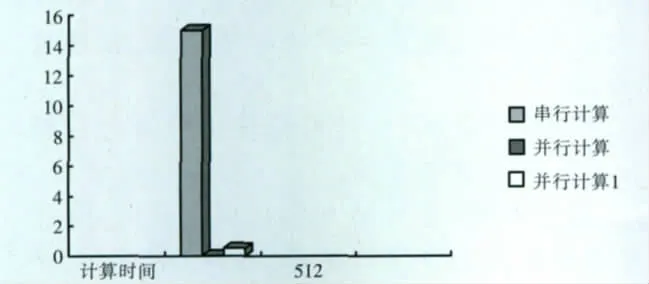
圖5 漢克爾變換串行與并行運行耗時對比(單位:ms)Fig.5 Time-consuming comparison of Hankel transform serial and parallel operation(unit:ms)
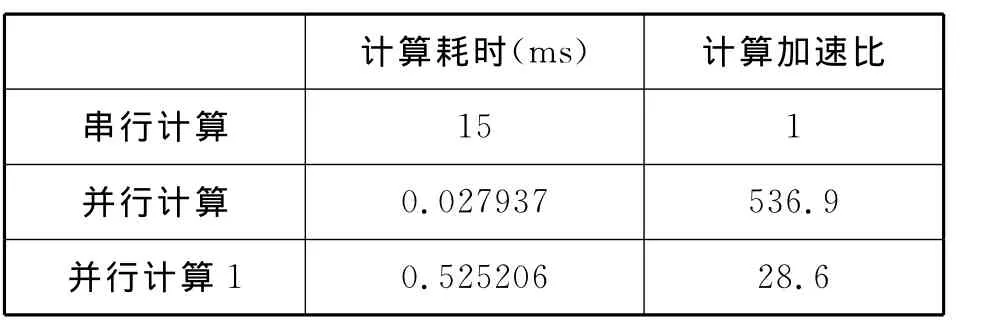
表1 漢克爾變換并行計算相對串行計算加速比Tab.1 Hankel transform parallel computing speedup relative serial
由此可見,對于數(shù)據(jù)量比較大的漢克爾變換,使用并行計算可以獲得很大的性能提高,見表1。但是并行計算的過程相對于串行算法的計算過程略顯繁瑣,而且CUDA的編程模型很大程度上依賴于硬件的模型,特別是CUDA存儲器使用的限制,這就給編程帶來了一些麻煩。鑒于設備內寄存器和共享存儲器的容量有限,在進行大型科學計算的過程中一定要考慮內存的溢出。GPU單精度性能遠遠超過雙精度,作者在本文中使用過的雙精度需要截斷成單精度,在程序運行時出現(xiàn)了一些警告,但這并不影響程序的運行,可能計算精度會稍微差一點。使用共享存儲器使得漢克爾變換計算過程中線程間的通信延遲最小,性能大幅度提高。
3 結論
(1)在水平層狀介質上瞬變電磁測深一維正演計算中,對于漢克爾變換的計算,基于GPU技術的并行計算相比串行計算獲得很高的加速比。并行計算的過程相對于串行算法的計算過程略顯繁瑣,而且CUDA的編程模型很大程度上依賴于硬件的模型,但是GPU在并行計算方面的優(yōu)勢以及超強的浮點運算性能可以大大縮短計算時間。作者在本文中僅僅實現(xiàn)了漢克爾變換不同時間點的并行計算,僅僅是整個正演程序的一部份,對于整個串行正演程序更深入的并行算法有待進一步研究。
(2)相比于地震勘探,重力、磁法、電法勘探中的并行計算研究還都處于起步階段,我們需要基于GPU計算平臺開發(fā)更多應用于地球物理方面的并行計算軟件。研究并行算法和編程模型,在地球物理勘探數(shù)據(jù)處理中具有廣闊的前景。
[1] 劉羽,王家映.地球物理數(shù)據(jù)處理與并行計算[J].桂林工學院學報,2004,24(4):412.
[2] 鐘勇,陳磊.基于GPU計算的三維地震斷層解釋[J].石油物探,2011,50(2):160.
[3] 劉紅偉,李博,劉洪,等.地震疊前逆時偏移高階有限差分算法及 GPU實現(xiàn)[J].地球物理學報,2010,53(7):1725.
[4] 張帆.基于MPI和GPU直流電法和大地電磁法三維正演的并行算法研究[D].北京:中國地質大學,2011.
[5] 唐寶山.瞬變電磁法中心回線裝置一維正反演研究[D].北京:中國地質大學,2008.
[6] 劉桂芬.回線源層狀大地航空瞬變電磁場的理論計算[D].吉林:吉林大學,2008.
[7] 趙改善.地球物理高性能計算的新選擇:GPU計算技術[J].勘探地球物理進展,2007,30(5):399.
[8] 趙改善.可重構計算技術及其在地球物理中的應用前景[J].勘探地球物理進展,2007,30(4):309.
[9] HE CHUAN,SUN CHUANWEN,LU MI,et al.Prestack Kirchhoff time migration on hight performance reconfigurable computing platform[J].Expanded Abstract of 75th Annual international SEG Meeting ,2005:902.
[10]HE CHUAN,QIN GUAN,ZHAO WEI.Highorder finite difference modeling on reconfigurable computing platform[J].Expanded Abstract of 75th Annual international SEG Meeting 2005:755.
[11]張舒.模式識別并行算法與GPU高速實現(xiàn)研究[D].成都:電子科技大學,2009.
[12]趙國澤,陳小斌,湯吉.中國地球電磁法新進展和發(fā)展趨勢[J].地球物理學進展,2007,22(4):1171.
[13]NVIDIA CUDA計算統(tǒng)一設備架構編程指南2.0[S].
[14]羅延鐘,張勝業(yè),王衛(wèi)平.時間域航空電磁法一維正演研究[J].地球物理學報,2003,46(5):719.
[15]KNIGHT JH,RAICH AP.Transient electro-magnetic calculations using the Gaver-Stehfest inverse Laplace transform method[J].Geophysics,1982,47(1):47.
TP 317.4
A
10.3969/j.issn.1001-1749.2012.05.20
1001—1749(2012)05—0614—05
水利部公益性行業(yè)科研專項經(jīng)費項目資助(201001020)
2011-11-24 改回日期:2012-04-02
戴云峰(1988-),男,碩士,從事水文地質方面研究。
