交叉驗證在離散數據網格化時的應用
2012-01-11 08:14:50高艷芳
物探化探計算技術 2012年5期
關鍵詞:方法
高艷芳,陳 實,馮 斌
(1.中國地質大學,北京 100083;
2.中國地質科學院 物化探研究所,河北 廊坊 065000)
交叉驗證在離散數據網格化時的應用
高艷芳1,2,陳 實2,馮 斌2
(1.中國地質大學,北京 100083;
2.中國地質科學院 物化探研究所,河北 廊坊 065000)
根據數據的特點,選擇不同的算法和參數對離散數據進行網格化,所得網格化數據對原始數據的反映程度不同。因此,在網格化時,可以利用交叉驗證(Cross Validation)對不同的網格化方法進行定量的評估和比較,以選擇最能尊重原始數據的網格化算法和參數。
離散數據;網格化;交叉驗證;地球化學數據
0 前言
利用離散分布的觀測數據制作等值線圖、框線圖、陰影圖和柵格圖等,用來表達客觀現實的空間分布狀況,需要通過內插或外插方式填充空值點,將不規則的數據轉換為規則分布的矩形陣列,這個過程就叫做離散數據網格化。目前,可以用來制作等值線的軟件很多,各軟件也提供了多種不同或相同的網格化方法。比如:國外著名的ArcGIS[1]、Golden Sufer10[2]、國內著名的軟件 Mapgisk9[3],分別提供了六種、十二種、四種以上的網格化的數學算法,其中都包含Kring方法。諸多的數學算法是為了滿足各行業各領域對具有不同特點(空間分布、數據量)的數據網格化的需要。在網格化的過程中不僅要選擇算法,同時還有許多其它的參數需要根據數據本身的特點進行選擇,例如:網格間距、網格化搜索域的形狀(矩形、圓、橢圓)、搜索半徑和向異性等等。諸多的方法、眾多的參數,給用戶帶來了寬泛的選擇,也讓用戶在使用過程中產生迷惑。盡管有些軟件本身的智能可以根據數據的特點設置默認的網格化方法和參數,用戶使用這些默認的設置就能產生滿意的結果。比如,對于一般的數據,Sufer會將Kring作為首選的算法向用戶推薦,將X、Y中的較大方向的網格數設定為100。Sufer軟件的用戶說明里也說到:當你創建一個網格文件時,通常可以使用其默認的方法和設置,基本上能產生可以接受的圖形[2]。但是實際應用中并非這么簡單。數據量也許過大或過小,數據分布也許過于集中或散亂,應用Kring方法并不是最佳選擇,默認的搜索方式并不能使用戶獲得最佳的結果。這些原因迫使用戶要在眾多方法和參數之間進行選擇來獲得滿意的,能對原始數據進行良好反映的網格化數據。在這樣的前提下,Sufer自版本8開始,引用了一種統計學上的方法,來對離散數據網格化方法及參數的選擇結果進行定量評估,這個方法就是交叉驗證。
1 交叉驗證
交叉驗證(Cross Validation),又稱為循環估計[4](Rotation Estimation),是通過將觀測數據分成不同的子集,來評估和比較算法優劣的一種統計學上的實用方法。交叉驗證的科學基礎是為了滿足對算法的評估需求,一是評估一種算法的普遍性,二是比較兩個或多種算法的特征,以找出最優的算法。交叉驗證目前應用于算法特征評估、模型選擇和調整模型參數三個方面。
2 網格化時交叉驗證的基本思想
自Golden Sufer.8開始,引入了交叉驗證來進行網格化算法的評估。實現的基本思想:已知有N個點的觀測數據,交叉驗證通過計算和分析網格化后每個觀測點上數據的殘差,來對數據網格化的質量進行相對的評估。
數據的殘差=網格化后的評估值-觀測值[5]。
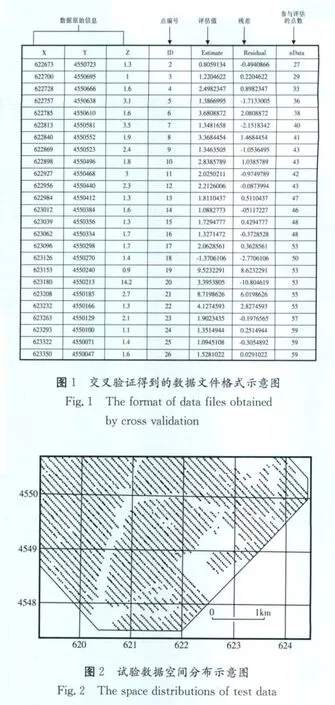
計算每個觀測點殘差的過程是:先把該點的觀察值從數據集中拿出,利用剩下的數據和確定的網格化方法,來計算該點插值后的評估值,利用這個值和觀測值就能得到該點上的殘差[2]。通過對N個觀測點逐個的計算,將得到含有M個(M為用戶用來進行交叉驗證的數據點數)殘差值的數據文件(見圖1),然后利用多種統計處理手段對殘差數據進行分析,來定量評價網格化方法,指導網格化數學算法和參數的選擇。
在Sufer8中,交叉驗證得到的數據文件是一個ASCII的數據文件,共有M行。M是進行交叉驗證的點數,可以是全部的觀測點N,是部份隨機的觀測點。每一行共有七列,前三列是數據點的原始信息:X、Y方向的坐標及Z值,后面的依次是點號、該點的評估值、該點的殘差和參與該點插值評估的數據點的個數。
3 交叉驗證的應用
將野外采樣獲得的樣本數據進行網格化來制作地球化學圖,是地球化學數據處理的主要手段之一。地球化學普查或詳查、區域化探,涉及的工作范圍為數十平方公里、數百平方公里,數據量數千甚至上萬個。因此地球化學數據的特點是分布范圍較廣,數據量大。
作者在本實例中,采用的數據是地球化學詳查工作的成果。點線距為:40*100,樣點數為2 706個,呈不規則多邊形分布在5.2km2*3.2km2的礦區范圍上,如圖2所示。
Sufer8中提供了十二種的網格化方法,對于地球化學數據來說,并不是全部適用:
(1)自然臨近點、三角網線性插值因為網格化方法不能向外擴邊,而滿足不了地球化學方法技術的要求。
(2)多項式回歸因為不是真正進行網格化插值,只是定義一種趨勢或模式。
(3)最近點也不是進行真正的插值,只適用于數據分布均勻而空值點少的數據。
所以在制作地球化學圖時,也只有距離倒數、克里格、徑向基本函數、改進謝別德、最小曲率、移動平均這些方法可以選擇。
采用距離倒數、克里格、徑向基本函數、改進謝別德、最小曲率、移動平均分別對本數據進行網格化處理,網格間距設定為40*40,圓域搜索,搜索半徑為300。在網格化時使用交叉驗證獲得的結果見下頁表1。
分析以上的結果,從數據的范圍、獲得殘差的平均值和標準離差等統計數據可以看出,克里格和距離倒數,以及徑向基本函數、改進謝別德,是化探數據進行網格化可選的數學算法。克里格和徑向基本函數產生的結果特別相似,網格化后的Z值會超出原始數據的范圍;而距離倒數和改進謝別德方法相似,皆以距離倒數為權重。由于克里格和距離倒數這兩種方法在插值點與取樣點重合時,插值點的值就是樣本點的值,所以克里格和距離倒數這兩種方法成為地球化學數據常用的方法,加之由于使用克里格方法產生的網格數據在制作等值線時,可以避免出現更多的牛眼點[8],因此克里格成為了地球化學數據網格化時首選的方法。大量的實際經驗表明,地球化學數據進行網格化處理可以利用的方法有距離倒數、克里格、徑向基本函數[7],交叉驗證的結果給予了證明。
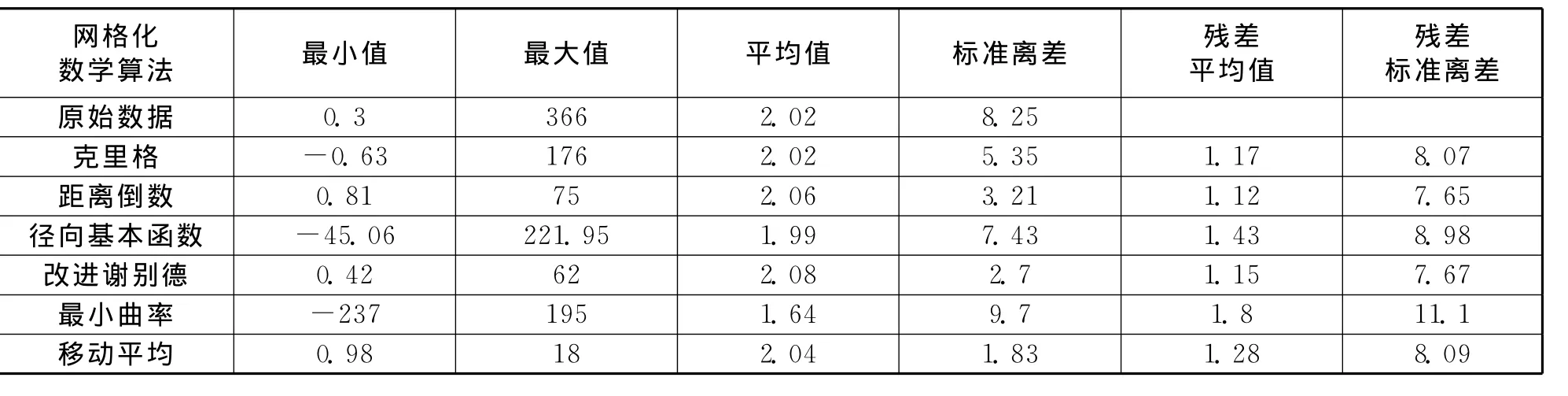
表1 交叉驗證結果對比表Tab.1 The comparison of the results from cross validation
4 結論
不規則分布的原始數據經過網格化后獲得網格數據,由網格數據來產生等值線圖,用來分析某種客觀現象連續的分布態勢,是科學研究中通常采用的方法。但是網格化后的數據不一定完全尊重原始數據,而等值線形態和趨勢僅是由網格化后的數據點所決定,這使得原始數據點和等值線圖會產生一定的偏離。因此尋找最優的網格化的方法和參數,對原始數據進行最接近的表達,是網格化時最需要考慮的地方。這個選擇可以利用已獲得的經驗值,比如對地球化學數據進行網格化一般選用克里格方法,網格間距通常為采樣間距的一半,搜索半徑為2倍~5倍,同樣可以利用交叉驗證來給予理論上的支持。同時,交叉驗證使得網格化過程變得透明,從交叉驗證的結果可以得到參與某一點網格化的數據點數,可以對原數據點網格化前、后的數據值進行比較,這使得網格化不再僅僅是一個快速完成的過程,而是讓用戶真正參與其中,去通過定量分析選擇自己需要的算法和參數。
[1] 秦濤,付宗堂.ArcGIS中幾種空間內插方法的比較[J].物探化探計算技術2007,29(1):72.
[2] GOLDEN SOFTWARE,INC.User’s Guide of Surfer 8[M].Golden Software,Inc.2002.
[3] 中地數碼.MAPGIS K9空間分析使用手冊[M].北京:中地數碼,2009.
[4] PAYAM REFAEILZADEH,LEI TANG,HUAN LIU .Cross-Validation http://www.public.asu.edu/~ltang9/papers/ency-cross-validation.pdf.
[5] 徐新強,張志剛.高程異常模型的已知點框架約束[J].海洋測繪,2006,26(6):59.
[6] 郭思,郭科,謝箭.基于ArcGIS儲量估算系統的開發與實踐[J].物探化探計算技術,2010,32(5):560.
[7] 高艷芳.離散數據網格化參數的確定和數學模型的選擇[J].地質與勘探,2002,38(增刊):139.
[8] 徐愛萍,胡力,舒紅.空間克里金插值的時空擴展與實現[J].計算機應用,2011,31(1):273.
O 241.5
A
10.3969/j.issn.1001-1749.2012.05.21
1001—1749(2012)05—0619—03
2012-05-10 改回日期:2012-06-07
高艷芳(1965-),女,碩士,高級工程師,在中國地質科學院物化探研究所信息中心從事GIS技術的應用開發工作。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
