《中國大學生心理健康量表》的因子結構探究
2012-10-17 07:26:46陳志方沐守寬
赤峰學院學報·自然科學版 2012年6期
陳志方,沐守寬
(漳州師范學院 教育科學與技術系,福建 漳州 363000)
《中國大學生心理健康量表》的因子結構探究
陳志方,沐守寬
(漳州師范學院 教育科學與技術系,福建 漳州 363000)
目的:探究《中國大學生心理健康量表》的因子結構.方法:采用《中國大學生心理健康量表》對漳州師范學院2011級新生施測,篩選出說謊量表得分為零且未出現缺失作答的被試2141人,將樣本隨機分成校準(calibration)樣本(n=1140)和驗證(validation)樣本(n=1001),分別進行探索性和驗證性因素分析.結果:探索性因素分析得到《中國大學生心理健康量表》的單因子和二因子結構,驗證性因素分析表明,與單因子結構相比,二因子結構模型擬合較好(RMSEA=0.099,SRMR=0.041,NNFI=0.925,CFI=0.940),本研究二因子結構得到了支持.結論:《中國大學生心理健康量表》存在二因子結構:“神經質”和“精神病性”.
中國大學生心理健康量表;因子結構;因素分析
1 問題提出
隨著社會的發展和進步,人們也越來越體會到心理健康的重要性.而大學生處于心理和思想尚未成熟的半社會化的特殊階段,則更容易產生一系列的思想問題和心理困惑.因此,編制一套科學合理、客觀的評估大學生心理健康的量化工具對于大學生心理問題的預測診斷有著十分重要的現實意義.當前特定針對大學生心理健康而編制的量表主要有鄭日昌等人[1]編制的《中國大學生心理健康量表》(簡稱CCSMHS)、王欣等人[2]編制的《大學生心理健康量表》以及李東方[3]編制的《大學生心理健康量表》.本研究基于CCSMHS.
CCSMHS最終設定了測量大學生心理健康的12個維度[1],此維度最先來自于訪談法、經驗的建構,并借鑒了SCL-90的6個維度.CCSMHS并未對量表的因子結構做進一步的探索與驗證研究,至今仍缺乏對于此結構的探討,其結構的科學性與合理性有待進一步地檢驗.
基于以上認識,本研究采用多種手段,對大學生心理健康量表的12個維度進行探索性和驗證性分析因素分析,并同時對其他相關問題進行了探討.
2 研究方法
2.1 被試
采取整群抽樣方法,被試為漳州師范學院2011級本科生及研究生,有效樣本5333人.本研究從中選取說謊量表得分為0的被試2356人,并剔除掉出現缺失作答的被試215人,余下樣本共2141人,其中男生731人,女生1410人,本科生年齡介于18-20歲之間,研究生年齡介于21-30歲之間.
2.2 施測
問卷施測在新生入學的一個月內完成,由校大學生心理咨詢中心組織實施,心理學專業研究生及專業教師作為主試,所有被試以系為單位在大教室進行測試.所有被試均被告知測驗的目的:(1)建立新生入學心理檔案;(2)鑒別篩選出存在心理障礙的學生并加以干預.測試時間大約20分鐘.測試完成后的一個月內,每個被試都會收到一份心理健康評估報告.
2.3 研究工具
《中國大學生心理健康量表》,由鄭日昌等人于2005年編制,是教育部社政司組織研發的“中國大學生心理健康測評系統”的一個分量表,專門用于評估中國大學生心理健康狀況[1],近年來在全國高校的新生入學中得到了廣泛的使用.該量表由104個項目組成,13個分量表,包括軀體化、焦慮、抑郁、自卑、偏執、強迫、社交退縮、社交攻擊、性心理、依賴、沖動、精神病,說謊量表,包含的項目數分別為 9、6、7、11、12、7、10、10、8、7、8、6、3 個.所有項目均采用 Likert 5 點計分(1沒有~5總是).CCSMHS編制過程嚴格謹慎,量表具有較高的內部一致性信度和重測信度,內容效度、結構效度、效標效度、實證效度被證實均較為理想[1].在本研究中,分量表的內部一致性系數介于0.646至0.846之間.
2.4 數據分析
采用SPSS13.0、LISREL8.70進行描述性統計與探索性因素分析;使用EQS6.1進行驗證性因素分析.
在探索性因素分析中,本研究采用了四種判斷結構維度的標準:(1)“特征根>1”法,特征值大于1準則是幾乎所有統計軟件的默認選項,因此也相應成為實踐中應用最普遍的確定因子個數的方法,即保留特征值大于等于1的因子,舍棄特征根小于1的因子[4].(2)碎石圖法,按照因子被提取的順序畫出因子特征值隨因子個數變化的散點圖,根據圖的形狀來判斷保留因子的個數,曲線由陡峭變的平緩的前一個點被認為是提取的最大因子數[5].(3)平行分析法,它首先生成一組隨機數據矩陣,接著求出這組隨機數據矩陣的平均特征值,最后通過比較真實數據特征值的碎石圖與隨機矩陣特征值的曲線來確定保留的因子數目.(4)Goldberg的方法[6],涉及到不同水平抽取的因子的相關,繪制出因子分裂的維度圖表,根據圖表來決定可以舍棄的不重要的因子.當提取出了新的一個因子時,可以解釋的總的方差減少或者沒有有意義的因子出現時,因子提取過程也就結束了(Goldberg,2006).
其中最常用來確定因子個數的準則是“特征根>1”法和碎石圖法,但這兩種方法又各有其不足之處,特征值大于1準則只適用于主成分法所求解的因子,運用其它方法進行因素抽取時,我們不能根據特征值的大小來判斷應保留因子的個數.利用碎石圖確定因子個數不可避免具有一定的主觀性,并且有時碎石圖上并沒有明顯的折點,或者有多個折點,難以判斷保留因子的個數[5].平行分析(Parallel Analysis)為探索性因素分析中所保留因子個數的確定提供了另一種新思路.本研究通過四種方法的結合運用,以求更加精確地確定大學生心理健康量表的結構維度.
3 結果與分析
3.1 項目分析
描述統計選取平均數、標準差、正態分布檢驗以及頻數分布圖,正態分布檢驗采用Shapiro-Wilk 正態分布檢驗(Shapiro-Wilk test of normality).如表1結果顯示,平均數分布有略微的傾斜,自卑、偏執、社交退縮平均分最高;其次是社交攻擊、強迫、軀體化、抑郁、依賴、沖動;性心理和焦慮得分較低;得分最低的是精神病維度.正態分布檢驗表明,各分量表的因子得分均呈現正偏態分布.根據各維度得分的人數分別作頻數分布圖,所有圖均呈正偏態分布,這與正態分布檢驗的結果是一致的.因為量表所有項目均采用反向計分,分數越高,越有可能存在心理障礙,反之,分數越低,心理越健康,所以符合理論構想.
關于量表的信度,該量表用4道測謊題來鑒別被試是否認真答題或是否按照自己真實情況作答,并以被試在這4道題上的得分之和等于4分做為剔除廢卷的標準,在一定程度上提高了此量表的信效度.本研究僅選取了測謊維度得分為0的樣本,又進一步提升了信度和效度.將該量表的內部一致性系數作為信度的指標,結果如表1,另外總量表的α系數為0.967.數據表明,該量表的信度較高,具有一定的穩定性.
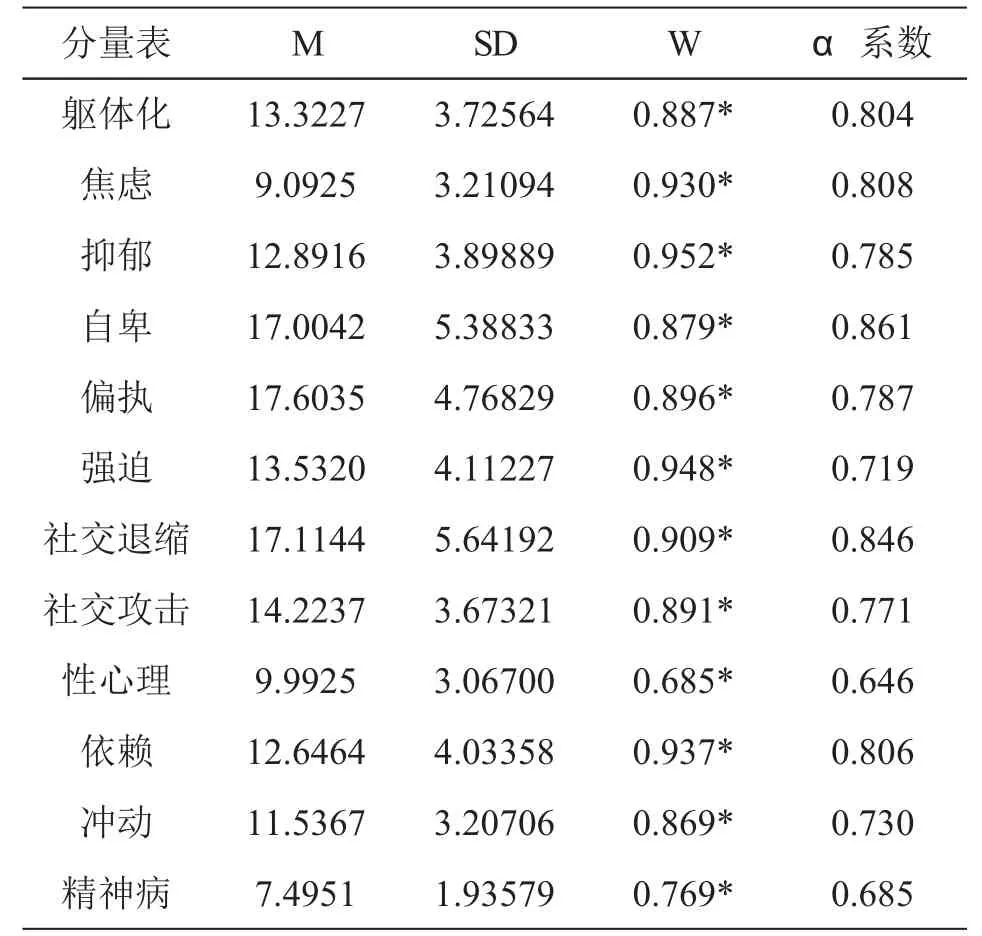
表1 描述性統計
3.2 因素分析
3.2.1 探索性因素分析
將樣本隨機分成校準(calibration)樣本(n=1140)和驗證(validation)樣本(n=1001);用校準樣本進行探索性因素分析.關于探索性因素分析方法的幾點說明:(1)采用了四種判斷結構維度的準則;(2)本研究中因子抽取使用公因子法(principal axis factors),原因在于,主成分法(principal components)的主要功能是簡化數據,即以最少的因子數最大程度地解釋原始數據中的方差.當目的是確定數據結構時,則公因子法更為合適;(3)因子旋轉的方法為正交方差最大化旋轉(varimax).
(1)“k 大于 1”準則
12 個因子的特征值依次為 6.678、0.991、0.840、0.657、0.573、0.515、0.386、0.365、0.287、0.260、0.245、0.203. 可知,僅有一個因素的特征值大于1,為6.678,第二和第三個特征值分別為0.991、0.840.根據特征值大于1準則,應保留1個因子.
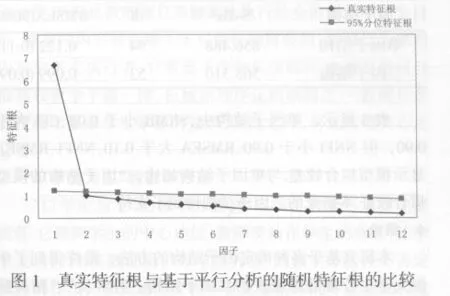
(2)碎石圖與平行分析
如前文所敘,特征值大于1準則有時候是不夠精確的,可運用平行分析方法對真實特征根與95%分位隨機特征根做比對(如圖1).觀察碎石圖可以發現,從第2個點開始曲線由非常陡峭變得趨于平緩,這表明與第1個因子相比,第1個因子后的所有因子均解釋了很少的變異;觀察平行分析曲線,第2點位于碎石圖的第2點之上.以上均表明,應舍棄第2點之后的因子,僅保留1個因子.碎石圖與平行分析的結果與特征值大于1準則所得結果是相一致的.
(3)Goldberg的方法
Goldberg技術揭示出當提取成分時,數據如何分裂成不同的維度,見圖2.

圖2 基于Goldberg技術的、3種抽取水平下的因子相關圖
根據旋轉后的成分載荷及其所包含的內容,試驗性地得出圖2中的成分命名.從圖2可獲知,2—3層均包括神經質(Neuroticism)和精神病性(Psychoticism)這兩種成分.第3層提取出了僅包含兩個維度的成分:性心理、強迫成分,此成分不滿足鑒別度(identification)要求.僅僅包含一兩個方面的成分是不能作為因子的,因為一個因子應該包含較廣泛的內容.而神經質和精神病性這兩個成分在各個層次上均達到了飽和.
考慮到旋轉策略時,鑒于斜交旋轉方法有時候是優于正交旋轉的,所以此處采用了這兩種方法,加以對比,以使結果更加精確.采用斜交旋轉得到了相差甚微的數據,各個層次提取出的成分也與正交旋轉相一致.
基于以上考慮,利用Goldberg技術,抽取出了兩個因子,分別命名為“神經質”、“精神病性”.
如果嚴格按照(1)和(2)的標準,本研究僅抽取一個因子.但是第二個因子的特征值為0.991,非常接近于1;并且(2)中平行分析曲線的第2點與碎石圖的第2點幾乎重合,所以抽取兩個因子也是可取的.綜合(1)(2)(3)所述,本研究探索性地抽取一個或兩個因子.根據因子包含成分及其負荷大小(見表2),當抽取單因子時,將其命名為神經質(Neuroticism),所包含的項目依次為偏執、焦慮、自卑、抑郁、社交退縮、社交攻擊、精神病、軀體化、沖動、強迫、依賴、性心理;當抽取兩個因子時,將因子1命名為神經質,所包含項目依次為自卑、社交退縮、焦慮、抑郁、依賴、強迫、性心理,將因子2命名為精神病性,所包含項目依次為沖動、社交攻擊、軀體化、偏執、精神病.
3.2.2 驗證性因素分析
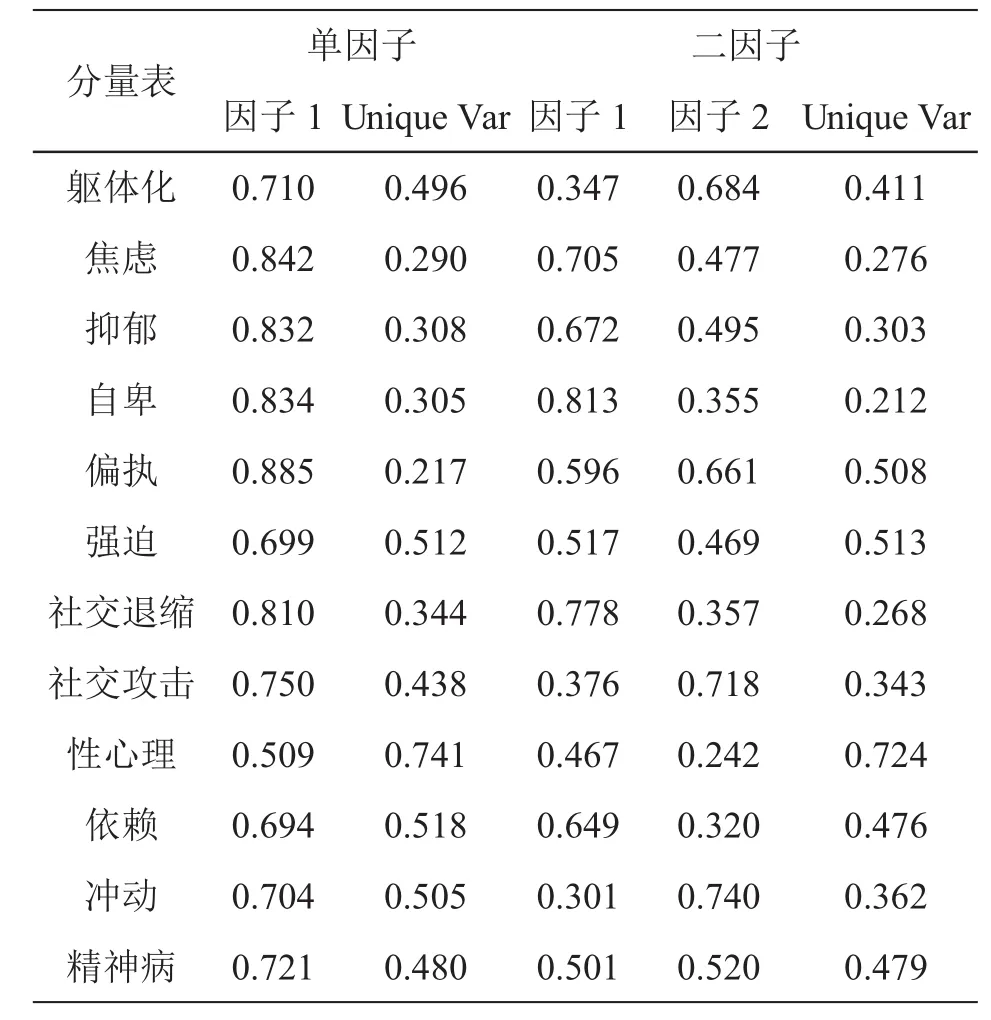
表2 單因子和二因子結構的因子載荷
在探索性因素分析基礎上,用EQS6.1對驗證(validation)樣本(n=1001)進行驗證性因素分析,檢驗CCSMHS 12個分量表的因子結構效度.模型擬合指數選取S-B(Satorra-Bentler scaled chi-square)、RMSEA (the root-mean-square error of approximation)及其90%置信區間、SRMR(the standardized root mean square residual)、NNFI(the non-normed?t index)、CFI(comparative fit index)等.各項擬合指標見表3.

表3 單因子、二因子結構的驗證性因素分析
表3顯示,單因子結構中,SRMR小于0.08、CFI大于0.90,但 NNFI小于 0.90、RMSEA 大于 0.10,NNFI、RMSEA顯示模型擬合較差.與單因子結構相比,二因子結構的模型擬合較好.本研究的二因子結構得到了支持.
4 結論
本研究基于多種確定因子結構的方法,最終得到了中國大學生心理健康量表的二因子結構:“神經質”、“精神病性”,驗證性因素分析較好擬合了二因子結構.這為量表的進一步研究與應用提供了參照.
〔1〕鄭日昌,鄧麗芳,張忠良,郭召良.中國大學生心理健康量表的編制[J].心理與行為研究,2005,3(2):102-108.
〔2〕王欣,張月娟,翟紅娟,左曉東.“大學生心理健康量表”的編制和信效度研究[J].中國臨床心理學雜志,2005,13(1):29-30.
〔3〕李東方.大學生心理健康量表的編制[D].華中科技大學,2008.
〔4〕Thompson,B.,&Daniel,L.G.Factor analytic evidence for the construct validity of scores:A historical overview and some guide2lines[J].Educational and Psychological Measurement,1996,56(2):197–208.
〔5〕孔明,卞冉,張厚粲.平行分析在探索性因素分析中的應用[J].心理科學,2007,30(4):924–925.
〔6〕Goldberg,L.R. (2006).Doing it all bass-ackwards:The development of hierarchical structures from the top down.Journal of Research in Personality,40,347–358.
〔7〕師曉寧,劉曉紅,徐燕等.心理測驗在我國大學生心理健康評價中的應用現狀及存在問題 [J].健康心理學雜志,2003,11(4):281~283.
〔8〕盧國華,梁寶勇.堅韌人格量表的編制[J].心理與行為研究,2008,6(2):103~106.
〔9〕Shryack J.etc.The structure of virtue:An empirical investigation of the dimensionality of the virtues in action inventory of strengths[J].Personality and Individual Differences ,2010(48).
〔10〕劉華山.心理健康概念與標準的再認識[J].心理科學,2001,24(4):481~482.
G441
A
1673-260X(2012)03-0200-03
猜你喜歡
品牌研究(2022年9期)2022-04-06 02:41:56
品牌研究(2022年8期)2022-03-23 06:49:06
品牌研究(2022年6期)2022-03-23 05:25:50
品牌研究(2022年1期)2022-03-18 02:01:10
哲學評論(2021年2期)2021-08-22 01:53:34
中華詩詞(2019年7期)2019-11-25 01:43:04
下一代英才(酷炫少年)(2019年3期)2019-03-25 02:34:18
黃河之聲(2017年14期)2017-10-11 09:03:59
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
現代企業(2015年9期)2015-02-28 18:56:50
