漢語-維吾爾語的一對一詞對齊研究
2012-11-14 07:17:06張亞軍賀琛琛
昌吉學院學報 2012年6期
張亞軍 賀琛琛
(1.昌吉學院計算機工程系 新疆 昌吉 831100;2.昌吉學院人事處 新疆 昌吉 831100)
1 引言
詞語的對齊(簡稱詞對齊,Word Alignment)研究是自然語言處理的一個重要組成部分,詞對齊分為三類:一對一、多對一、多對多。其目的是要找出從源語言的字符串和目標語言的字符串之間的詞對齊。詞對齊對于平行語料庫、語料數據挖掘等方面尤為重要。同時,詞對齊還可以為雙語詞典、語音識別、信息檢索提供源材料。英語和漢語詞對齊研究相對成熟,基本精度在90%以上,取得的召回率約88%。然而漢語-維吾爾語(簡稱漢維)詞對齊的研究,處于前期研究階段。
研究詞對齊方法主要有兩類:
(1)基于語言學的方法:充分使用各種語言學的資源進行詞對齊研究。例如利用統計和詞典相結合的方法進行的詞對齊[1];或者利用語言學比較的方法進行詞對齊等[2]。
(2)基于統計的研究方法:其思路是通過對平行語料庫的統計性訓練,取得雙語對應詞的同現概率作為詞對齊的基礎,主要方法有Brown提出的基于信源信道模型方法實現的詞對齊[3];Dagan等人對Brown的模型進行改進的詞對齊[4];Gale、Piao、Okita都使用互信息和X2檢驗方法進行詞對齊[5][6][7]等。
基于統計方法實現漢維一對一的詞對齊是本文研究的重點內容。
2 詞對齊模型描述
2.1 基于信源信道模型的統計方法
信源信道思想應用于統計機器翻譯,實際上可以理解為一個解碼的過程,此時把翻譯系統視為信源信道,即對于一個目標語言字串S,將尋找一個最大可能的源語言句子T,搜索概率P(T|S)最大值的過程。 由貝葉斯公式:
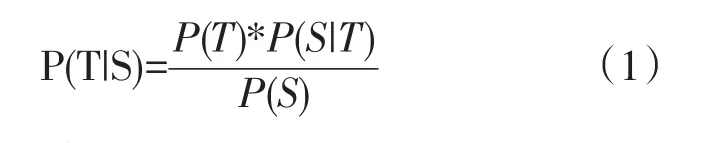
其中P(T)為語言模型,P(S|T)為翻譯模型。
由于式(1)右邊P(S)與T無關,因此,求上式的最大值等同于求等式右邊分子的最大值即:
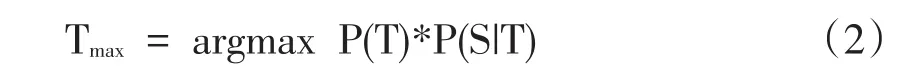
2.2 IBM模型1和模型2
大量的參數訓練是詞對齊的基礎工作,由此可以計算出源語言詞語和目標語言詞對齊的概率,從而搜索出概率最大值。本文采用EM(期望最大化)算法實現的IBM模型1和模型2。
IBM模型1-2的單詞翻譯概率公式相同,計算公式如(3)所示:
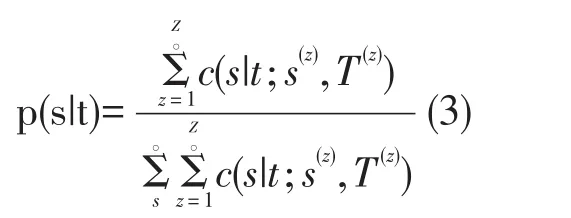
其中c(s|t;S(z),T(z))表示目標語言的單詞t在翻譯句對(S|T)中與源語言的單詞s對齊的期望次數,s表示源語句中的詞語,t表示目標語句中的詞語。Z表示語料庫中句對個數。
IBM模型1-2不同的是目標語言的單詞t在翻譯句對(S|T)中與源語言的單詞s對齊的期望次數。模型一對齊期望次數如(4)式所示:
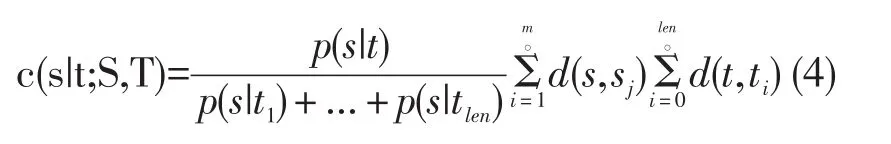
其中m表示源語言長度即源語言中詞語的個數;len表示目標語言長度即目標語言中詞語的個數;p(s|t)是目標語言單詞與源語言單詞翻譯概率;δ是Kronecker函數,當它的兩個參數相同時,δ=1,否則δ=0。
由于模型1忽略了單詞出現在句子中的位置,模型2在模型1基礎上不再假設每一個源語言詞語與目標語言詞語之間有相同的對齊概率,而是考慮了目標語言句子的不同位置和不同句對長度的影響,可能導致任意兩個對位存在不同的概率,由此引入對位概率p(aj|j,m,l)。模型二對齊次數如(5)式所示:
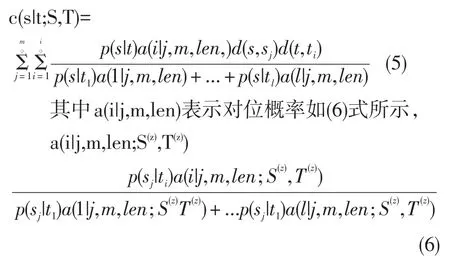
3 漢維一對一詞對齊
3.1 系統處理流程
系統流程如圖1所示,模型1和模型2是研究的重點。
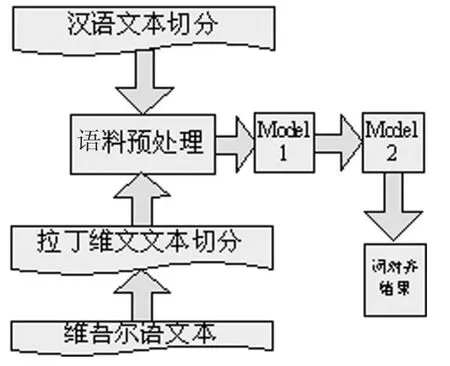
圖1 漢維一對一詞對齊流程
3.2 語料預處理
實驗要求選取平行語料庫中的語料,本文選取漢語語料和維吾爾語語料。具體要求有:將漢語語料和維吾爾語語料分別存放于格式為txt的兩個文本,文本中的每一行都是一個獨立的句子,且漢語文本及維吾爾語文本的相同行為互相對應的一個句對。
例如:
中文文件

維文文件

漢語詞語切分利用中國科學院計算技術研究所提供的中文分詞工具ICTCLAS處理。維吾爾語切分工具由新疆大學多語種信息重點實驗室提供。在詞語對齊訓練過程當中發現對齊結果受到個別拉丁維文字符的影響,采取的方案是將其轉化為無歧義可以識別的字符來處理。例如é轉化為E、ü轉化為U、?轉化為O等。例如:
拉丁維文:

轉換個別字符后的拉丁維文:

3.3 一對一對齊步驟與算法
3.3.1 一對一對齊步驟
(1)語料預處理:將漢文詞語分詞,維文轉化為拉丁維文并將個別字符轉化為無歧義可以識別的字符;
(2)IBM模型1實現漢維詞對齊:以源語言文本和目標語言文本作為輸入文件,初始化單詞概率分布P(S|T),計算目標語言的單詞t在翻譯句對(S|T)中與源語言的單詞s對齊的期望次數,迭代修正單詞翻譯概率。
(3)IBM模型2實現漢維詞對齊:在考慮了目標語言句子的不同位置和不同句對長度因素下,以模型1最終修正的單詞翻譯概率為初始值,計算對位概率a(i|j),不斷迭代修正單詞翻譯概率。
3.3.2 對齊算法
算法主要步驟如下
St1:設輸入預處理后的維吾爾語文本S=S1S2S3…Si… SZ,Si為源文件,漢文文本 T1T2T3…Ti…TZ,Ti為目標文件;
St2:初始化單詞概率分布p(s|t);
St3:對于每一個句對(S(Z),T(Z)),計算期望次數c(s|t;S(Z),T(Z));
St4:對于每一個至少出現在一個目標語言句子中的單詞t計算同時對每一個至少在一個源語言句子出現的單詞s,計算得出新的單詞對位概率值p(s|t);
St5:重復St3和St4,直到迭代完畢,結束模型1算法;
St6:將模型1修正后的單詞對位概率值作為模型2的初始值,并引入對位概率a(i|j,m,l)賦予初始值;
St7:對于每一個句對(S(Z),T(Z)),計算期望次數c(s|t;S(Z),T(Z))和 c(i|j,m,l;S,T);
St8:對于每一個至少出現在一個目標語言句子中的單詞t計算同時對每一個至少在一個源語言句子出現的單詞s,計算得出新的單詞對位概率值p(s|t)和新的對位概率值a(i|j,m,l);
St9:重復St7和St8,直到迭代完畢,結束模型2算法。
4 對齊結果與分析
本文平行語料庫由新疆大學信息學院多語種信息技術重點實驗室提供。語料庫中整理了漢維相對應的10000句對。從中抽出本實驗所需的漢維相對應331個句對,其中這331個句對中的詞都是一對一的對齊方式。
4.1 模型實現
(1)通過上述一對一漢維詞對齊步驟,本文實現了一個可以在windows下運行的漢維詞語對齊模型系統。本系統的核心代碼是采用visual studio 2010平臺下的C#編寫,主要采用數據庫訪問的方式存取數據,運行界面如圖所示。
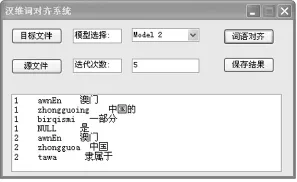
圖2 運行界面
(2)為對比該系統的評測指標,在相同語料下,利用Giza++[7]進行了的漢維詞語對齊,其中從模型1到模型2。如圖3所示:

圖3 Giza++詞對齊結果
4.2 系統評價指標
將漢維331句對進行詞對齊的人工校對,同時從Giza++結果中找出一對一的漢維詞對齊作為標準測試語料。按照規定,引入了三種評測指標:
正確率=正確的對齊總數/對齊總數*100%
召回率=正確的對齊總數/實有對齊總數*100%

可以得到以下幾個結論:
(1)兩個模型運行測試結果
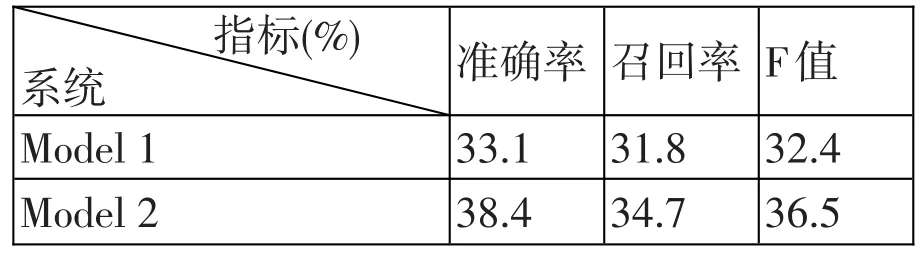
表1:Model 1和Model 2的對齊結果
(2)本系統同Giza++的詞對齊相比,各項評測指標如表2所示。
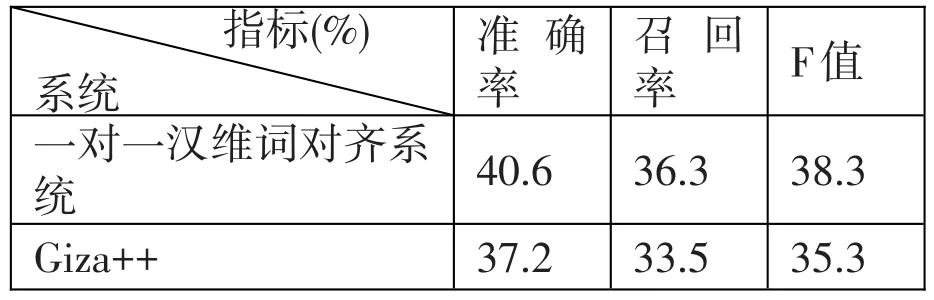
表2:與Giza++對齊結果比較
4.3 實驗結果分析
從上述兩個表中可以發現,正確率和召回率不高,經過總結分析,影響因素如下:
1.漢語和維吾爾語在切分過程中容易出現切分錯誤,在詞對齊時會導致錯誤放大。
2.漢語和維吾爾語的句法結構不同。漢語屬于SVO語言,而維吾爾語是SOV語言。
3.漢語無形態語言,而維吾爾語為形態豐富的語言。維吾爾語中有明顯形態標志的格,大部分出現在句子的末尾,最多可能出現四種形態標記。
4.本實驗中選取的語料規模較小,部分詞語可能未能夠覆蓋。
5.模型2的效果比模型1好。但是同Giza++相比較,若使用基于信源信道模型的統計方法來解決一對一詞對齊,后者的效果較好。
5 總結
論文的主要研究工作是基于統計機器翻譯的一對一漢維詞對齊方面。通過測試,本方法基本達到實驗效果,同時也為后續其他詞語級對齊打下基礎。
目前,本系統設計主要考慮了IBM模型1-2實現了一對一詞對齊。但是當我們觀察一些實際翻譯例子時發現,很多情況下句對中的詞語為一對多、多對一、多對多。因此,在今后的工作中,首要研究如何實現漢語和維吾爾語一對多、多對一和多對多的對位關系;其次要考慮兩種句法結構相差大的語言上的句子結構。
[1]鄧丹,劉群,俞鴻魁.基于雙語詞典的漢英詞對齊算法研究[J].計算機工程,2005,(8):31-16.
[2][Huang,2000]Jin-Xia Huang,and Key-Sun Choi.C-hinese-Korean word alignment based on linguistic c-omparison[C].In:Annual Meeting of the Association for Computational Linguistics,2000.392-399.
[3]Brown P F,Della Pietra S A,Della Pietra V J,et al.The Mathematics of Statistical Machine Translation:Parameter Estimation[J].Computational Linguistics,1993,19(2):263
[4][Dagan,1993]Dagan L,Chunch K,et al.Robust bilingual word alignment for machine aided translation[A].Proceedings of the W orkshop on Very Large corpora:Academic and Industrial Perspectives[C],C olumbus,1993.1-8.
[5][Gale,1991]Gale,W.and Church,K.Identifying W ord Correspondences in Parallel Texts[A].Proceedings of the 4th DARPA Speech and Natural LanguageWorkshop[C],Pacific Grove,CA,1991.152-157.
[6]Piao,Scott.Word alignment in English-Chinese parallel corpora.Literary and Linguistic Computing,2002,17(2).pp.207-230.
[7]Okita,Tsuyoshi.Word alignment and smoothing methods in statistical machine translation:Noise,prior knowledge and overfitting.Dublin City University School of Computing,2012.
猜你喜歡
閱讀(快樂英語中年級)(2024年9期)2024-10-23 00:00:00
時代英語·高三(2024年3期)2024-09-03 00:00:00
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
意林(繪英語)(2017年5期)2017-05-15 02:17:23
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
