基于樹編輯距離的聚類算法數據記錄抽取
2013-01-03 02:42:36宮麗娜祝美蓮
赤峰學院學報·自然科學版 2013年12期
關鍵詞:方法
宮麗娜,祝美蓮
(1.棗莊學院,山東 棗莊 277160;2.中國石油大學(華東),山東 青島 266580)
1 引言
網頁信息抽取為許多網絡信息處理應用領域包括網絡數據挖掘、網絡信息檢索等提供了有益的基礎.
前人已經進行了很多網頁信息抽取方法的研究 (如[3][8];文獻[1]給出了一個簡短的總結).RoadRunner[2]:自動生成包裝器的系統,但是它會產生一些錯誤的模式,準確率較低.MDR[3]方法是第一個全自動的抽取信息的算法,這種方法完全不需要用的參與.DEPTA[4]算法是MDR方法的一種改進,它假設網頁中每兩條數據記錄之間的視覺空間都要比數據記錄之間的空間大,但是這種情況并不是總是成立的.所有這些方法都具有一些缺點.
本文中,提出了一種新的自動從網頁中抽取數據記錄的方法.首先,構建DOM模型;第二,我們采用了三種啟發式的規則來發現網頁的主數據區域;最后提出了一種基于樹編輯距離的聚類算法,來分離數據記錄.通過大量真實網頁的實驗驗證,本文方法具有較高的準確率.
2 主數據區域發現
2.1 DOM樹模型
本文方法首先需要將網頁的HTML文檔轉化為DOM樹的形式,由于HTML語言本身也不夠嚴謹,因此要對源文件進行預處理.同時我們還要對標簽進行過濾,去掉一些沒有用的干擾標簽.如<select>標簽,這個標簽下面通常會有很多的節點選擇,會給我們后面的分析造成干擾,預處理的時候將其去掉.
2.2 主數據區域發現
通常,列表頁面都滿足下面幾個特征[8]:DOM樹中的每條數據記錄都是有一系列的連續兄弟子樹組成的.而且,能夠發現每條數據記錄都是由一定數量的完整子樹構成的.
從上述特性得知,定位主數據區域我們所要做的就是找到包含所有記錄項的最小DOM子樹的根節點.本文給出了三種啟發式方法,分別從DOM樹的不同特征考慮當前節點是否包含所有目標記錄項.
2.2.1 最大扇出子樹法,思想是:一個節點包含的子節點越多,它就越有可能是包含所有數據記錄的最小DOM子樹的根節點.
2.2.2 最大內容增大法.計算節點的總的內容量,并減去節點的平均內容量(節點大小除以節點扇出值),作為節點的內容增大量,一個節點的內容增大量越大,它越有可能是包含所有數據記錄的DOM子樹的根節點.
2.2.3 最大標記量法,考慮子樹中包含的HTML標記量,對于沒有祖先關系的兩個節點,節點包含的HTML標記越多,它排位越靠前.
將上述三種方法分別加一個權重,根據權重計算得到一個加權平均的排序節點列表.列表的第一個節點就是我們所要找的節點.
3 數據記錄分割
接下來要研究的是如何將主數據區域中的多條數據記錄進行分離.我們采用樹編輯距離來表示兩棵相鄰子樹的相似度.
3.1 樹編輯距離
計算兩棵樹的樹編輯距離,主要就是要找出兩棵樹之間的一個權值最小的映射,這個映射可以有如下的定義:
假定X是一棵樹,X[i]是樹X中第i個子節點.那么T1和T2之間的映射M是滿足以下條件的有序數對(i,j)的集合對于任何(a1,b1),(a2,b2)
(1)a1=a2 當且僅當 b1=b2
(2)T1[a1]是 T1[a2]的左鄰節點當且僅當 T2[b1]是 T2[b2]的左鄰節點
(3)T1[a1]是T1[a2]的父節點當且僅當T2[b1]是T2[b2]的父節點
本文采用簡單樹匹配算法來求解樹編輯距離.令A=(RA,A1,…,Am)和 B=(RB,B1,…,Bn)是兩棵樹,其中 RA和 RB是 A和B的根節點,Ai和Bj分別是A和B的第i個和第j個第1層子樹.當RA和RB的標記相同時,A和B的最大匹配為MA,B+1,其中MA,B是<A1,A2,…,Am>和<B1,B2,…,Bn>的最大匹配.偽代碼如算法1所示:
算法 1:STM(A,B)
1 開始
2 如果RA和RB不同
3 返回0;
4 否則
5 設m為節點RA的子樹的個數
6 設n為節點RB的子樹的個數
7 M[i,0]←0所有的 i=0,…,m
8 M[0,j]←0所有的 j=0,…,n
9 從i=1到m
10 從j=1到n
11 W[i,j]←STM(Ai,Bj)
12 M[I,j]=max(M[i,j-1],M[i-1,j],M[i-1,j-1]+W[i,j])
13 結束
14 結束
15 返回M[i,j]+1
16 結束
給定兩個HTML文檔,它們對應的DOMTree為T1,T2,T1,和T2中每一個節點標記對應HTML中的一個標簽,其中文本節點用<text>節點代替.記樹T的節點數目為|T|,定義T1與T2的相似度為:
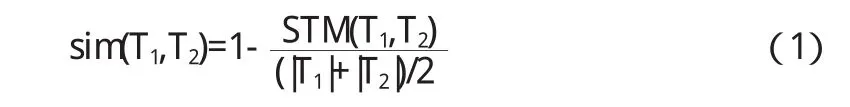
上式中,|T1|,|T2|分別表示兩棵樹的最大匹配節點數.兩棵樹的最大匹配節點數越大,則兩棵樹越相似,即它們所代表的HTML文檔也就越相似.
3.2 聚類算法
由第三節中描述的列表頁面的特點知,數據記錄可以是一棵或者多棵連續子樹的集合,這樣可以產生候選的分割方案,設主數據區域的根節點有n棵子樹,則可以產生2n-1候選分割方法,算法的效率很低.本文采用聚類算法將子樹分類,來減少候選分割方案的數量,來提高算法的效率.
對樣本空間進行聚類,需規定樣本的相異度值,其由相異度矩陣表達,定義如下.
相異度矩陣(dissim ilarity matrix)用來存儲n個樣本兩兩之間的相似性,形式為n×n維矩陣:
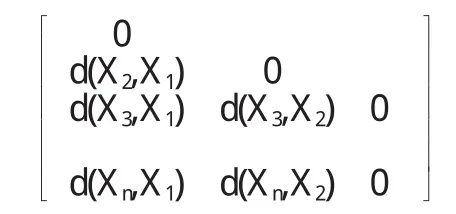
我們用d(X2,X1)來表示樣本Xi和Xj相異性,取值非負數.對象i和j越相似,其值越接近0;否則其值越大.
用上一節介紹的STM算法計算兩棵子樹的距離,首先將每棵子樹都作為一個單獨的簇,定義一個閾值d0,當兩棵子樹之間的距離小于d0時,把兩棵子樹聚類,作為一個大類.閾值d0的大小會影響到簇的數量和規模:如果d0比較大,簇的規模也會比較大大,反之類似.所以選擇一個適當的閾值聚類成功的關鍵,通過多次試驗本文選取的d0值為0.15.
設Ci和Cj分別代表兩個不同的類,Xi和Xj分別表示Ci和Cj的類中心,則類Ci和Cj之間距離我們采用平均距離進行度量:
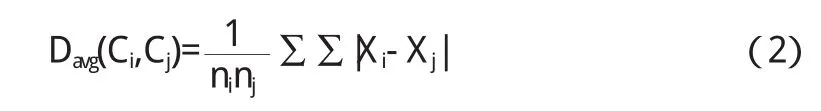
其中,ni和nj表示類Ci和Cj的樣本數目.
算法2:聚類
(1)假設每個子樹Xi都是一個簇{Xi}.
(2)設d0為相似度閾值.
(3)計算相似度矩陣值D=(Dij)m×m,m是簇的個數.
(4)找到最小的矩陣值D,
如果D值小于d0,
將Xi和Xj合并為一個新的簇,并設m=m-1.
否則結束
(5)如果m>2繼續執行(3)
(6)否則結束.
如圖1給出了一個簡單的聚類結果的例子,10棵子樹,聚成了三個類.
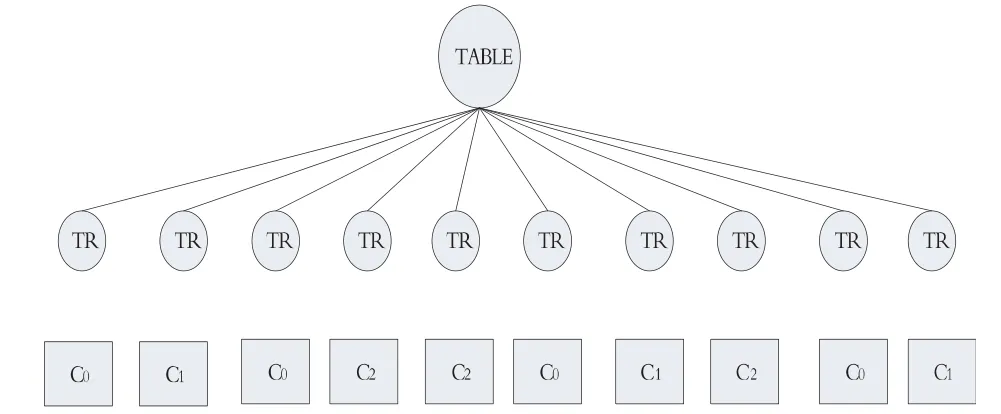
圖1 聚類結果示例
前面的預處理步驟完成后,我們下面生成候選數據記錄分割方案.我們利用文獻[8]中的方法產生候選分割方案:

圖2 候選分割方案
3.4 最佳分割方案
為了獲得正確的數據記錄分割方案,我們依賴列表頁面所具有的特征,即每條記錄的樹結構相似.這樣我就可以選擇具有最高相似度的候選分割方案作為最終結果,我們為每一條記錄添加一個根節點,構造成樹結構.然后根據STM算法來計算每條記錄之間的相似性.計算公式如下面的公式(3):

根據公式3對圖2獲得的候選分割方案分別計算其相似性,可以看出,以C0開始的分割方案的相似性最高,這樣就選擇列表當中的第一種方案作為最佳分割方案.
4 實驗分析
4.1 評價標準
本文采用標準指標查全率(Recall)和準確率(Precision)來評價我們的系統的好壞.
4.2 實驗
為了檢驗本為提出的方法的效果,選用了不同類型的200個網頁作為實驗對象,挖掘網頁中的相似記錄項.同時將我們的實驗結果與MDR算法進行比較,實驗的數據如表1所示.
從表1可以看出,對于淘寶和亞馬遜等站點,基于本文方法抽取相似記錄項,都取得了100%的召回率和100%準確率.經查看網頁結構發現網頁結構化程度非常高.易趣和CNKI等站點的召回率和準確率相對較低,經查看網頁結構,發現這些站點的結構化程度相對較低.從總體上看,實驗取得了98.82%的召回率和99.52%的準確率,說明本文方法,對于各種類型的列表網頁的信息抽取,取得了很好的效果.本文方法同MDR方法結果進行比較,在準確率和召回率方面都有提高,證明本文方法的有效性.

表1 實驗結果
5 總結
本文提出了將最大扇出子樹法、最大內容增大法和最大標記量法三種啟發式方法結合的思路查找網頁的主數據區域.在數據記錄分割階段,采用基于樹編輯距離的聚類算法來減少候選分割方案,最后通過給出的公式挑選出最佳分割方案,完成數據記錄的抽取.實驗證明對各種類型列表頁面進行數據記錄抽取的效果都很不錯.但是本文方法只適用于一個主數據區域的頁面,以后將進一步研究多信息塊的數據記錄抽取.
〔1〕A.H.F.Laender,B.A.Ribeiro-Neto,A.Soares da Silva,J.S.Teixeira,A brief survey of web data extraction tools,ACM SIGMOD Record 31(2)(2002)84–93.
〔2〕V.Crescenzi,G.Mecca,P.Merialdo,ROADRUNNER:towards automatic data extraction from large web sites,in:Proceedings of the 2001 International VLDB Conference,(2001):109–118.
〔3〕B.Liu,Grossman,R.and Y.Zhai,Mining data records in Web pages.KDD,(2003):601-606.
〔4〕Y.Zhai,B.Liu,Structured data extraction from the web based on partial tree alignment,IEEE Transactions on Knowledge and Data Engineering 18 (12)(2006)1614–1628.
〔5〕A.Arasu,H.Garcia-Molina,Extracting structured data from web pages,in:Proceedings of the ACM SIGMOD International Conference on Management of Data,(2003).
〔6〕C.Chang,S.Lui,IEPAD:information extraction based on pattern discovery,in:Proceedings of 2001 InternationalWorldWide Web Conference,(2001):681–688.
〔7〕B.Liu,Y.Zhai,NET:System for extracting Web data from flat and nested data records.In Proceedings of the Conference on Web Information Systems Engineering,(2005):487-495.
〔8〕Manuel A′lvarez,Alberto Pan,Juan Raposo,Fernando Bellas,Fidel Cacheda,Extracting lists of data records from semi-structured web pages,Data&Knowledge Engineering(64),(2008):491-509.
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
