SQL Server數(shù)據(jù)庫(kù)的查詢優(yōu)化探析
2013-02-08 05:37:02李紅麗
長(zhǎng)春教育學(xué)院學(xué)報(bào) 2013年7期
李紅麗
SQL Server數(shù)據(jù)庫(kù)的查詢優(yōu)化探析
李紅麗
SQL Server是一個(gè)關(guān)系數(shù)據(jù)庫(kù)系統(tǒng),是一個(gè)全面的數(shù)據(jù)庫(kù)管理平臺(tái),查詢語(yǔ)句是數(shù)據(jù)庫(kù)中最基本、最常用、最復(fù)雜的語(yǔ)句,數(shù)據(jù)庫(kù)中的查詢?cè)诜祷亟Y(jié)果時(shí)有時(shí)需要很長(zhǎng)的時(shí)間,速度非常緩慢導(dǎo)致用戶無(wú)法忍受。為提高查詢效率,數(shù)據(jù)庫(kù)的查詢優(yōu)化便成了一個(gè)備受關(guān)注的話題。從SQL Server數(shù)據(jù)庫(kù)出發(fā),結(jié)合數(shù)據(jù)庫(kù)中的查詢語(yǔ)句,可以討論影響SQL Server數(shù)據(jù)庫(kù)查詢效率的因素,并提出SQLServer數(shù)據(jù)庫(kù)優(yōu)化查詢的方法。
SQLServer;數(shù)據(jù)庫(kù);查詢效率;查詢優(yōu)化
李紅麗/陽(yáng)泉師范高等專科學(xué)校助教(山西陽(yáng)泉045200)。
1 引言
隨著計(jì)算機(jī)科學(xué)技術(shù)日新月異的發(fā)展,數(shù)據(jù)庫(kù)技術(shù)成了其中發(fā)展較快的領(lǐng)域之一,SQL Server已成為最普及、最全能的數(shù)據(jù)庫(kù)管理系統(tǒng),因此各類信息管理系統(tǒng)與數(shù)據(jù)庫(kù)有了更緊密的結(jié)合。隨著數(shù)據(jù)量的不斷增加,數(shù)據(jù)查詢的速度受到了嚴(yán)重影響,數(shù)據(jù)庫(kù)的合理使用便顯得尤為重要。因此,本文對(duì)數(shù)據(jù)庫(kù)系統(tǒng)的查詢優(yōu)化展開(kāi)討論。
2 影響SQL Server數(shù)據(jù)庫(kù)查詢效率的因素
在SQL Server數(shù)據(jù)庫(kù)中,對(duì)于一個(gè)查詢而言,經(jīng)常會(huì)遇到查詢方法不同但查詢結(jié)果相同的情況,但條件表達(dá)式不同會(huì)使數(shù)據(jù)庫(kù)的響應(yīng)速度出現(xiàn)很大差別。以下面兩條常用SQL語(yǔ)句為例:
Select*from table where TID>1000 and name=’LiYang’;
和 Select*from tablewhere name=’LiYang’and TID>1000;
從這兩條語(yǔ)句的書(shū)寫順序來(lái)看它們不太一樣,如果TID是一個(gè)聚合索引,那么第一條語(yǔ)句查詢時(shí),直接從表的1000條之后的記錄中查找滿足name='LiYang'的記錄;而第二條語(yǔ)句查詢時(shí),需先從全表中查找出滿足name='LiYang'的所有記錄,然后再根據(jù)TID>1000這個(gè)限制條件提取出查詢結(jié)果。可見(jiàn),第一條語(yǔ)句的查詢速度要快。
在設(shè)計(jì)數(shù)據(jù)庫(kù)查詢時(shí),查詢效率顯得至關(guān)重要。在設(shè)計(jì)中應(yīng)注意到:(1)是否用到索引。數(shù)據(jù)庫(kù)索引如同書(shū)籍中的目錄,在訪問(wèn)數(shù)據(jù)庫(kù)時(shí),用戶可以減少遍歷數(shù)據(jù)的次數(shù),從而可以快速找到所需數(shù)據(jù)。(2)I/O吞吐量。在硬件環(huán)境特定時(shí),部署方案的優(yōu)化可適當(dāng)提高I/O吞吐量,避免發(fā)生瓶頸問(wèn)題。(3)應(yīng)當(dāng)創(chuàng)建計(jì)算列。如果沒(méi)有相應(yīng)的計(jì)算列,在進(jìn)行數(shù)據(jù)查詢時(shí)對(duì)已有數(shù)據(jù)再次進(jìn)行計(jì)算,從而浪費(fèi)一部分性能。(4)要有足夠的內(nèi)存。在查詢或訪問(wèn)數(shù)據(jù)庫(kù)中的數(shù)據(jù)時(shí),難免會(huì)占用大量的內(nèi)存空間,當(dāng)內(nèi)存不足時(shí),數(shù)據(jù)的訪問(wèn)速度就會(huì)受到明顯的影響。除此以外,網(wǎng)速慢、查詢出的數(shù)據(jù)量過(guò)大、鎖或者死鎖、返回了不必要的行和列、查詢語(yǔ)句不夠優(yōu)化等,也是影響SQL Server數(shù)據(jù)庫(kù)查詢效率的重要因素。
3 SQLServer數(shù)據(jù)庫(kù)優(yōu)化查詢的方法
3.1 合理使用索引
索引查詢是數(shù)據(jù)庫(kù)中重要的記錄查詢方法,它的根本目的就是為了加快查詢速度。以下是實(shí)際應(yīng)用中應(yīng)該注意的幾點(diǎn)。
3.1.1 連接操作需要經(jīng)常進(jìn)行,但是沒(méi)有指定為外鍵的列上建立索引,而連接操作不經(jīng)常進(jìn)行的字段優(yōu)化器會(huì)自動(dòng)生成索引;特別注意不要在選擇的欄位上使用索引,這樣是無(wú)意義的,最好在條件選擇的語(yǔ)句上合理的使用索引。如where,order by。
舉例:Select id,title,content,cat_id from article where cat_id=11;
這個(gè)語(yǔ)句在id,title,content上使用索引是毫無(wú)意義的,對(duì)這個(gè)語(yǔ)句沒(méi)有任何優(yōu)化作用。但如果在外鍵cat_id上使用索引,可以起到優(yōu)化作用。
3.1.2 在SQL語(yǔ)句中GROUP BY、ORDER BY的字段上經(jīng)常建立索引。
3.1.3 在條件表達(dá)式中用到的不同值較多的列上最好建立檢索,在不同值較少的列上不需要建立索引,如性別字段上就不必建立索引。
3.1.4 經(jīng)常存取的列應(yīng)避免建立索引。
3.1.5 如果某些列需要建立連接應(yīng)該建立索引。
3.1.6 如果有多個(gè)待排序的列,可在這些列上建立復(fù)合索引(compound index),但注意建立復(fù)合索引的順序要按照使用的頻度來(lái)確定。
3.1.7 在缺省情況下要建立非簇集索引,但有時(shí)也要考慮簇集索引,如:含有有限數(shù)目(不是很少)唯一的列,進(jìn)行大范圍的查詢。
索引的充分利用可減少I/0的掃描次數(shù),有效避免對(duì)整個(gè)表的搜索。當(dāng)然索引的合理性要建立在對(duì)各種查詢的分析和預(yù)測(cè)中,也取決于DBA所設(shè)計(jì)的數(shù)據(jù)庫(kù)結(jié)構(gòu)。
3.2 避免或簡(jiǎn)化排序
在數(shù)據(jù)庫(kù)查詢時(shí)應(yīng)避免或簡(jiǎn)化對(duì)大型表的重復(fù)排序。在可以利用索引自動(dòng)以適當(dāng)?shù)拇涡蜻M(jìn)行輸出時(shí),優(yōu)化器可自動(dòng)避免排序的步驟。為避免多余的排序,要適當(dāng)?shù)脑鰷p索引,適當(dāng)?shù)睾喜?shù)據(jù)庫(kù)表。如果實(shí)在避免不了排序,要考慮適當(dāng)簡(jiǎn)化。
3.3 避免對(duì)大型表進(jìn)行全表順序掃描
在使用嵌套查詢時(shí),對(duì)表的順序掃描會(huì)使查詢效率明顯下降。為避免這種情況,可以對(duì)連接的列進(jìn)行索引。如有三個(gè)表:學(xué)生表Studen(t學(xué)號(hào)Sno、姓名Sname、性別Sex、年齡Sage、系別Sdept),課程表Course(課程號(hào)Cno,課程名Cname,先行課Cpno,學(xué)分Ccredit)和選課表SC(學(xué)號(hào)Sno、課程號(hào)Cno、成績(jī)Score)。如果其中兩個(gè)表要做連接,就要在“學(xué)號(hào)”這個(gè)連接字段上建立索引。
此外,也可使用并集來(lái)避免順序存取。雖然在所有的列上都有索引,但某些形式的where子句迫使優(yōu)化器使用順序存取。以下例子是強(qiáng)迫對(duì)orders表執(zhí)行順序操作:

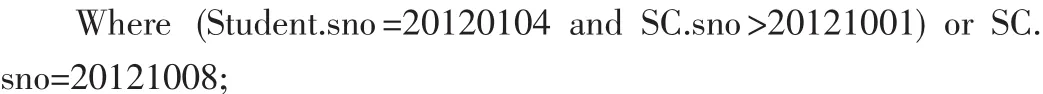
在Student.sno和SC.sno上雖建立了索引,但在這個(gè)語(yǔ)句中優(yōu)化器還會(huì)使用順序存取路徑掃描整張表。因?yàn)檫@個(gè)語(yǔ)句檢索的是分離的行的集合,所以應(yīng)改為如下語(yǔ)句:

此時(shí)就可以利用索引路徑處理查詢,提高查詢效率。
3.4 避免相關(guān)子查詢
如果一個(gè)列的標(biāo)簽在主查詢和where子句中的查詢中同時(shí)出現(xiàn),那么當(dāng)主查詢中的列值改變后,很可能子查詢必須重新查詢一次。查詢嵌套的層次越多,效率就會(huì)越低,因此要盡量避免子查詢。若子查詢不可避免,就要在子查詢中將多余的行全部過(guò)濾掉。
3.5 避免使用通配符匹配
在數(shù)據(jù)庫(kù)查詢中使用通配符匹配時(shí)特別耗費(fèi)時(shí)間。如以Student表為例看like關(guān)鍵字:

在執(zhí)行查詢時(shí)就會(huì)利用索引來(lái)查詢,顯然會(huì)大大提高速度。
3.6 避免在where子句使用數(shù)據(jù)轉(zhuǎn)換和串操作等函數(shù)操作

除以上優(yōu)化方法之外,還應(yīng)注意:(1)要避免在經(jīng)常被更新的列上建立索引。因?yàn)槊看胃虏僮鳎械乃饕家鱿鄳?yīng)的調(diào)整。另外,所有的分頁(yè)操作都被記錄在日志中,這樣也會(huì)增加I/O操作。(2)要避免在經(jīng)常更新的列上建立聚集索引,以免引起整行的移動(dòng)。(3)要盡量在where子句中少用OR和IN。可以考慮將其使用Union分成幾個(gè)子查詢。(4)應(yīng)避免在where子句中使用NOT、<>、或!=運(yùn)算符,減少全表掃描。
4 結(jié)束語(yǔ)
SQLServer是微軟公司出品的關(guān)系型數(shù)據(jù)庫(kù)管理(RDBMS)軟件,雖應(yīng)用很廣,效率很高,但在實(shí)際應(yīng)用過(guò)程中,隨著數(shù)據(jù)庫(kù)規(guī)模越來(lái)越大,數(shù)據(jù)量呈指數(shù)級(jí)上升,應(yīng)進(jìn)一步完善提升,從而繼續(xù)改善數(shù)據(jù)庫(kù)(尤其是大型數(shù)據(jù)庫(kù))的性能。
[1]石樹(shù)剛.關(guān)系數(shù)據(jù)庫(kù)[M].北京:清華大學(xué)出版社,1998
[2王珊,薩師煊.數(shù)據(jù)庫(kù)系統(tǒng)概論[M].北京:高等教育出版社,2006
[3]付立平,青巴圖,郎彥.數(shù)據(jù)庫(kù)原理與應(yīng)用[M].北京:高等教育出版社,2004
[4]陳佳.基于SQL server數(shù)據(jù)庫(kù)優(yōu)化查詢的分析 [J].企業(yè)導(dǎo)報(bào),2010,8:179-181
[5]谷震離.SQL Server數(shù)據(jù)庫(kù)應(yīng)用程序性能優(yōu)化方法[J].計(jì)算機(jī)工程與設(shè)計(jì),2006,27(15)
G202
A
1671-6531(2013)07-0054-01
郭一鶴
猜你喜歡
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2022年11期)2022-02-14 07:14:12
甘肅教育(2020年14期)2020-09-11 07:57:42
科普童話·學(xué)霸日記(2020年1期)2020-05-08 16:45:11
小天使·一年級(jí)語(yǔ)數(shù)英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
財(cái)經(jīng)(2017年2期)2017-03-10 14:35:35
財(cái)經(jīng)(2016年15期)2016-06-03 07:38:02
財(cái)經(jīng)(2016年3期)2016-03-07 07:44:46
財(cái)經(jīng)(2016年6期)2016-02-24 07:41:51
時(shí)代英語(yǔ)·高二(2015年1期)2015-03-16 00:08:11
