于數據挖掘(算法)的二進制目標自動建模研究
2013-02-26 08:39:22丁雪平
大眾科技 2013年10期
丁雪平
(安徽財經大學管理科學與工程學院,安徽 蚌埠 233030)
1 引言
人類正以驚人的速度產生著大量的數據,如何對這些數據進行處理并得到我們需要的信息,對企業進行有效的指導,越來越受到眾多研究者的關注。隨著大數據時代的到來,數據挖掘的工作也變得越來越難,處理數據的時間也要求越來越短。如果企業在面對這些海量的數據時,缺乏有效的分析手段,這些蘊藏著大量的、有價值的、相互關聯的信息的數據就很有可能成為企業的包袱,甚至是垃圾。數據挖掘技術的應用,成為企業的一筆寶貴的財富。
數據挖掘(DM)又稱數據庫中的知識發現(KDD)。所謂數據挖掘是指從大量的、有噪聲、模糊、隨機的數據中揭示出隱含的、先前未知的并且具有潛在價值信息和知識的一個過程。數據挖掘是一種決策支持過程,它是一個交叉學科領域,受多個學科的影響,包括數據庫系統、統計學、機器學習、可視化、信息科學等。高度自動化地分析企業的數據,做出歸納性的推理,從中挖掘出潛在的模式,幫助決策者調整市場策略,減少風險,做出正確的決策。本文講述了某金融機構市場部門希望通過為每一位客戶提供最適合他的報價,進而在未來的商業競爭中為了獲取更為有益的結果。
2 數據挖掘常用算法
數據挖掘的算法有很多,本文選取了幾種比較常見的算法,神經網絡、貝葉斯網絡、決策樹、SVM(支持向量機)、KNN、CHAID、QUEST,就優缺點以及適用范圍進行簡單的比較,如下表1所示。

表1 常用算法比較
由上表可以看出,各種算法都具有許多優缺點,使用范圍也是比較有限的。在我們不知道選用何種建模方法更好、更適合的情況下,可以選用二進制目標自動建模方法,這種建模方法可以同時運用多種模型進行預測估計,綜合多個模型的優點,并且使得對各種方法的嘗試和對結果的比較變得更容易。例如,我們不需要為神經網絡選擇某個快速、動態或修剪的方式,完全可以全部嘗試,或者就直接進行綜合以后整體模型的估計,選擇執行最好的來指導我們進行預測。該模型還可以選擇需要使用的特定建模方法以及每種算法的特定選項,也可以為每個模型指定多個變量。
3 二元分類器
在建模的過程中,我們經常會遇到一些因變量是類別變量,甚至有些是二元變量。如客戶的流失情況,僅有客戶流失與客戶不流失這兩種情況;客戶的響應情況,也只有響應與不響應這兩種結果。例如是否給予客戶可能拖欠貸款。在數據挖掘中我們可以使用二元分類器節點進行解決這類問題。
二元分類器就是將一個線性分類利用超平面劃分高維空間的情況:在超平面一側的所有的點都被分類成“是”,另一側則分成“否”,也就是說透過這個分類器只可以將資料分成兩個類別(是或否)。在數據挖掘中,二元分類器能夠自動創建和對比二元結果,可以在單次傳遞中預測和比較多種不同的建模方法,從而簡化了對各種算法進行嘗試以及對結果的比較,即二元分類器自動建模的關鍵作用就是無需人工選擇建立何種模型,以及如何建模,它完全可以自動建模,并且同時可以比較不同模型的優劣,展示出我們需要的結果。它還可以選擇需要使用的特定建模算法及每種算法的特定選項。例如,您無需為神經網絡選擇快速、動態或修剪之中的某個方式,完全可以全部嘗試,而且每種可能的設置組合都可以使用,這就是在數據挖掘中的好處了。此外,在數據挖掘SPSS Clementine軟件中該節點可基于指定的選項估計模型集并基于指定的標準對所生成的候選模型進行排序。也就是說一個相對簡單的流,能夠生成和排列一組候選模型,您可以從中選擇那些執行比較好的,然后采用整體節點將它們合并成單一的聚合模型。這種方法綜合了自動化與多個模型相結合的好處,聚合模型往往會產生比從任何一個模型更準確的預測。尤其是對于那些不知道哪種模型最適合評估或預測的情況下,可以嘗試多種方法,然后進行比較,選擇錄用最好的模型。
二元分類器節點可用于創建和對比二元結果(是或否,流失或不流失等)的若干不同模型,使用戶可以選擇給定分析的最佳處理方法。由于支持多種建模算法,因此可以對用戶希望使用的方法、每種方法的特定選項以及對比結果的標準進行選擇。節點根據指定的選項生成一組模型并根據用戶指定的標準排列最佳候選項的順序。
4 基于實例的二進制目標的自動建模
二進制是計算技術中廣泛采用的一種數制。任何一個二進制數據只需要用0和1兩個代碼來表示就夠了。與二元分類器的原理幾乎相同,在用二進制目標進行分類預測的時候,我們通常選擇“1”表示“是”表達肯定或者是通過,歸為第一類;“0”表示“否”表示否定或者沒有通過,歸為第二類。在這整個分類的過程中都是自動化的,無需人工操作,即得到了最后想要的結果,即自動建模。基于此,本文如下舉一個具體的例子進行說明。
本示例基于某一金融公司,金融公司收集了過去四種不同活動的銷售信息(分別標明為 1、2、3、4),希望通過對這些歷史數據進行分析,進而在以后的營銷活動中為每一位客戶匹配合適的報價以創造更好的結果。公司記錄了向21928名顧客進行推銷的詳細信息(campaign,)、該顧客是否接受(response)、以及顧客的一些個人信息和其他服務信息,如年齡(age)、性別(gender)、收入(income)等等,全部記錄在數據文件pm_customer_train1.sav中。由于四種活動舉辦的時間、收集的數據量等都有所不同,其中銷售計劃 2中的記錄數量最多,數據比較全,因此本文將重點對一個時間段的銷售計劃進行建模研究。
(1)數據訓練
第一步:添加SPSS源節點,導入數據。數據已跟蹤到特定的客戶在過去活動中,所提供的活動字段值表示的是歷史數據。
第二步:添加類型節點,并選擇response作為目標字段,方向設置為輸出,其余字段的方向均為輸入方向,并將其類型設置為標志。
第三步:添加選擇節點。數據包含四項不同活動的信息,但我們將重點分析在一個時間段的活動。由于紀錄數量最多屬于銷售計劃于(數據中的編碼為 campaign=2),因此我們可以使用Select節點來選擇僅包含這些記錄中的數據流。
第四步:添加二元分類器節點,進行模型估計。在一、 兩分鐘之后,一份報告展示出關于每個在運行期間的模型估計所列出的詳細的信息。(在實際情況下,在一個大的數據中,往往需要估計數百個模型,這可能需要花費幾個小時)。我們可以瀏覽結果并生成建模節點、 模型掘金或為任何您想要使用或進一步探索的模型評價圖。在默認情況下,模型是基于總體準確性排序,因為這是選擇的二進制分類器節點中的量。以這個標準來衡量,我們可以從圖2中看出排名最好的C51模型,但其他幾個模型也近乎準確。我們可以通過單擊列標題,在不同的列中進行排序,或者可以通過工具欄上的下拉列表選擇所需的方法。
第五步:根據這些結果,我們決定選擇模型中生成的三個最準確的模型,并將它們添加到流中,使用整體節點結合他們。通過結合多個模型的預測,我們可以避免限制在各自的單個模型中,進而達到更高的整體準確度。
第六步:添加一個分析節點,輸出結果。形成的樣本流如圖所示:
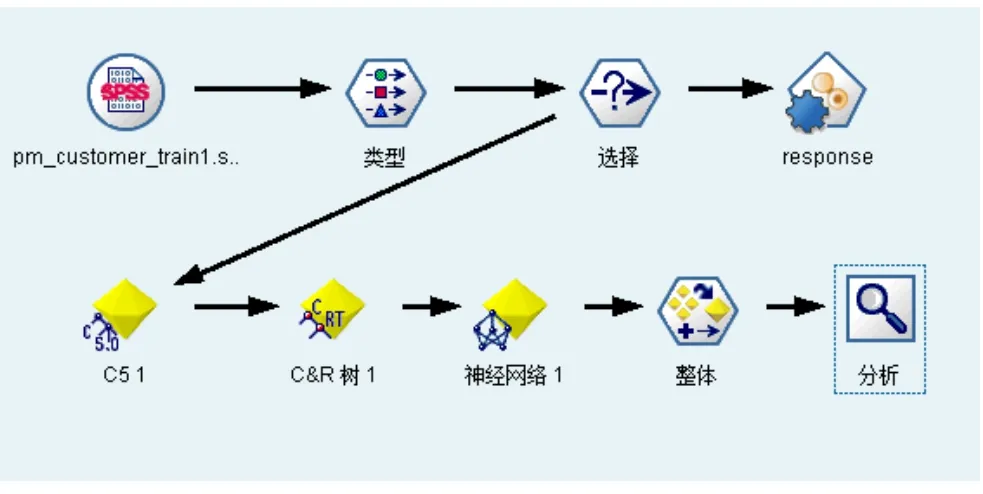
圖1 二元分類樣本流
(2)模型結果分析
本文選擇單個模型中執行最好的C51來分析。從C51模型執行結果可以看出客戶是否會購買這種金融產品的主要影響因素是收入(income) 、交易數量(number_transactions)、營銷分部(branch)有關。并且影響力最大的是收入,占80%以上。
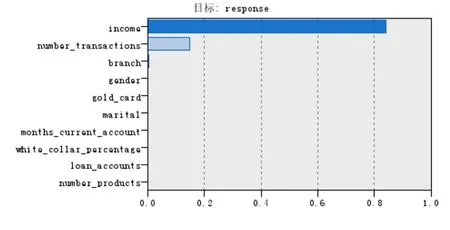
圖2 變量重要性判別
基于變量的重要性,我們選最重要的這一個收入作為分類節點來演示對客戶進行的聚類,如下表所示:
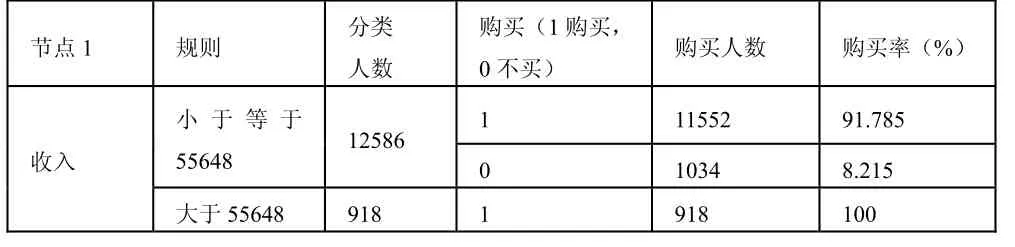
表1 C51聚類
由表可知,收入大于55648的人有918個客戶,他們100%會購買這這項金融產品,我們不需要再進行分類,我們可以直接進行預測,只要收入高于此數目,就極有可能購買這項金融產品,我們無需在這些客戶中花費大量精力去營銷。而收入小于等于55648的客戶有12586人,其中沒有購買的人有1034人,占8.215%,我們不知道這些不購買客戶的具體特點,因此我們繼續進行聚類分析。結下來選擇交易數量作為分類節點進行聚類。可知交易量小于12的那些客戶中,有92.996%的客戶沒有購買此金融產品,因此我們可以對這些客戶群制定策略,進行重點營銷。而對于交易量大于12的那些客戶可選擇branch作為分類節點進行聚類分析,我們能夠分析出哪一個行銷分支機構的營銷工作進行的比較好,進行的不好的那些分支機構如何有針對性的改進工作,提高營銷效率,進而是整個組織獲得更大的利潤。聚合模型的執行結果如圖3所示。
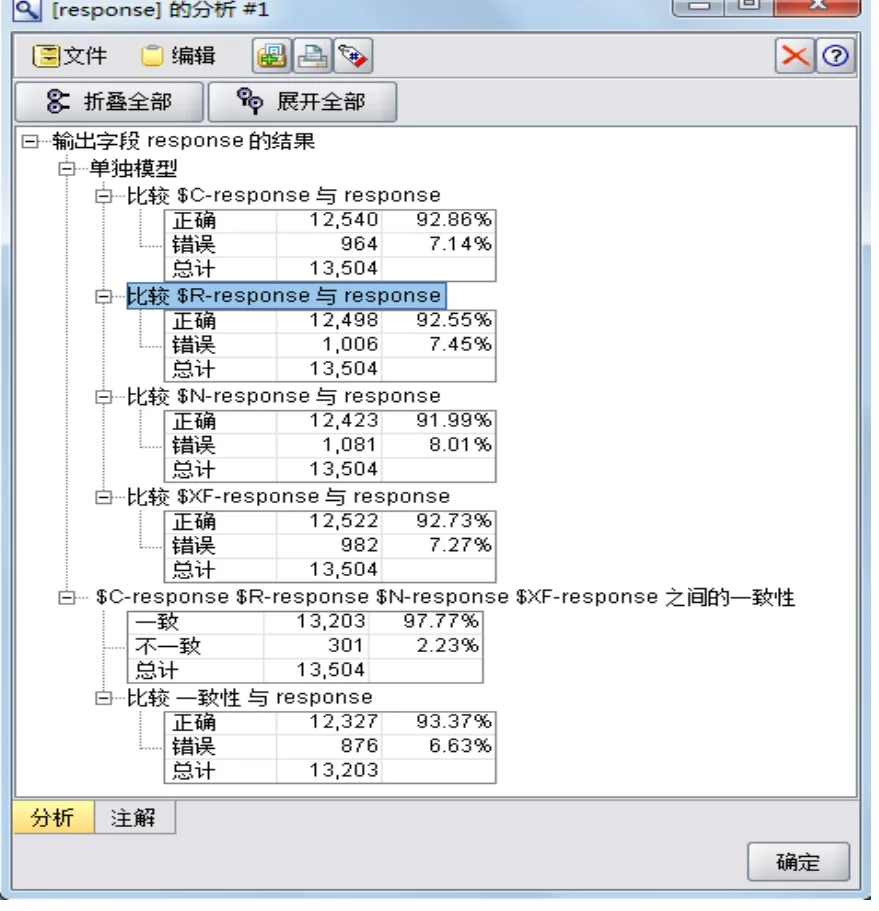
圖3 分析節點處理結果
本文把由單個C51,C&R樹和神經網絡模型生成的預測,分別被命名為$C-response, $R-response,and $N-response(用每個模型類型的前綴與目標字段的名稱相結合來確定這些字段名稱)。整體模型則命名為$XF-response。在訓練數據后進行衡量的測量中,預測值與實際響應相匹配的情況分別為92.86%,92.55%和92.18%。
由上圖可以看出,整體模型的整體精確性為92.78%,這4個模型之間的一致性也高達97.77%。在這種情況下雖然不是跟那最好的三個單個模型一樣精確,但是區別很小,都在92%以上,因此是有意義的。總體而言,當集成模型應用到數據集以外的訓練數據時,通常將有可能表現的更好。
綜上所述,本文使用二元分類器節點比較了多種不同的模型,選擇生成結果中那些執行較精確的模型,并將它們添加到流,與整體節點結合使用,進行分析預測。基于集成模型、C51、C&R樹和神經網絡模型上進行最好的鍛煉數據,集成模型分析的結果幾乎和最好的單個模型一樣,并且如果把集成模型應用到其他數據庫時,可能會有更好的表現。如果目標是使盡可能多的過程自動化,無需深入挖掘任何一種模式的具體細節時,這個方法就可以讓我們獲得一個可靠的模型。
5 結語
針對數據挖掘的幾種主要算法,分析了各自的優缺點及其所適用的領域。目前數據挖掘逐漸從高端的研究轉向常用的數據分析。在國外像金融業、零售業等這樣一些對數據分析需求比較大的領域已經成功地采用了數據挖掘技術來輔助決策。盡管如此,數據挖掘技術仍然面臨著許多問題和挑戰。如超大規模數據集中的數據挖掘效率有待提高,開發適應于多數據類型、有噪音的挖掘方法,網絡與分布式環境下的數據挖掘,動態數據和知識的數據挖掘等。總之,數據挖掘只是一個強大的工具,它不會在缺乏指導的情況下自動地發現模型,而且得到的模型必須在現實生活中驗證。數據分析者們必須知道他所選用的挖掘算法的原理是什么以及是如何工作的,并且要深刻了解期望解決問題的領域,理解數據,了解其過程,只有這樣才能解釋最終所得到的結果,從而促使挖掘模型的不斷完善和提高,使得數據挖掘真正地滿足信息時代人們的要求,服務于社會。
[1] 邵峰晶.數據挖掘原理與算法[M].北京:科學出版社,2009.
[2] 陸安生.決策樹C5算法的分析與應用[J].電腦知識與技術,2005.
[3] Jiawei Han,Micheline Kamber,Data Mining: Concepts and Techniques, Second Edition[M] Beijing: China Machine Press. 2007.
[4] 陳良維.數據挖掘中聚類算法研究[J].微計算機信息,2006.
[5] 王立偉.數據挖掘研究現狀綜述[J].圖書與情報,2008(5).
[6] 夏艷軍,周建軍,向昌盛.現代數據挖掘技術研究進展[J].江西農業學報,2009.
[7] 陶翠霞.淺談數據挖掘及其發展狀況[J].科技信息,2008(4).
[8] 談恒貴.王文杰.李游華.數據挖掘分類算法綜述[J].微型機與應用,2005(2).
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
光學精密工程(2016年6期)2016-11-07 09:07:19
信息通信技術(2015年6期)2015-12-26 01:16:46
核科學與工程(2015年4期)2015-09-26 11:59:03
河南科技(2014年23期)2014-02-27 14:18:43
