結合a分層的兼具項目曝光和廣義測驗重疊率控制的選題策略*
2014-01-31 19:56:04王卓然邊玉芳
心理學報 2014年5期
郭 磊 王卓然 王 豐 邊玉芳,2
(1北京師范大學認知神經科學與學習國家重點實驗室;2中國基礎教育質量評價與提升協同創新中心, 北京 100875)
1 引言
計算機化自適應測驗(Computerized Adaptive Testing, CAT)在過去幾十年里備受關注, 已經成為了許多大規模教育測量項目的測驗模式(陳平,2011)。與傳統的紙筆測驗相比, CAT的最大優勢表現在測試更少項目的同時, 能夠快速獲取更加精確的能力估計值(Weiss, 1982), 并且施測更加靈活。由于近來年網絡的快速發展, CAT的測驗功效發揮到了極致, 像GRE、ASVAB、GMAT、美國護士資格考試等大型考試都采用了CAT (唐小娟, 丁樹良,俞宗火, 2012)。
在CAT測驗中, 特別是高風險(high stake)測驗,考試的安全性十分重要(程小揚, 丁樹良, 嚴深海,朱隆尹, 2011)。為了保證測驗及題庫安全性, 主要做法是控制題庫中項目的曝光率, 使其低于預先設定的曝光率最大值。在CAT測驗中, 研究者提出了許多控制項目曝光率的方法, 根據Georgiadou,Triantafillou和Economides (2007)的總結, 當前主要有5類項目曝光控制方法:(1)隨機化方法; (2)條件選擇方法; (3)分層方法; (4)結合前三者的綜合方法; (5)多階段自適應設計。然而, 以上的方法均只關注了項目曝光率的控制。
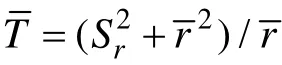
那么, 究竟該如何提高題庫使用的均勻性呢?受Chang和Ying (1999)提出的a分層方法的啟發,我們認為將a分層方法的思想和SHGT法相結合可以提高后者題庫的使用率。a分層的優勢在于, 能夠提高未使用或較少使用項目的曝光率, 使得項目曝光率和題庫使用率更加均衡。但根據Parshall,Harmes和Kromrey (2000)的研究表明, a分層對于某些項目仍然有較大的曝光率。并且在實際題庫中,a與b通常都是正相關的(Lord, 1975), 如果某一層內難度b的范圍不足以覆蓋被試能力水平時, 將會導致某些項目過度選擇。很明顯, SHGT法和a分層法的缺陷可以相互彌補, 前者能夠有效的控制過度曝光項目的出現, 但不能提高題庫使用均勻性, 后者雖能提高題庫使用率, 但未能有效地控制過度曝光的項目。因此, 本研究嘗試將兩種方法相結合,以實現既能控制項目曝光率和廣義測驗重疊率, 又能提高題庫使用率的目的。
查閱國內外文獻, 尚未見到能夠在同時控制項目曝光率和廣義測驗重疊率的基礎上, 提高題庫使用率的研究, 并且沒有研究過測驗考察的內容比例對不同的選題策略有何影響。實際中, 不同測驗所考察的內容比例是根據具體的測驗目的而設置的,而題庫的內容比例是相對穩定不變的。因此, 研究測驗考察的內容比例對不同選題策略的影響很有必要。本研究將a分層、按b分塊的a分層(Chang,Qian, & Ying, 2001)以及按內容分塊的a分層方法(Yi & Chang, 2003)與SHGT法相結合, 分別記作SHGT_a法、SHGT_b法和SHGT_c法, 意在實現上述目標。本文擬采用蒙特卡洛方法進行模擬研究,意在探討:(1)在不同的項目曝光率和廣義測驗重疊率水平下, 不同選題策略之間的表現有何差異; (2)在不同區分度和難度的相關水平下, 不同選題策略之間的表現有何差異; (3)在不同的內容考察比例下,不同選題策略之間的表現有何差異。
2 相關選題策略簡介
2.1 SHGT法
SHGT法是一個比較復雜的選題策略, 它融合了SH法的思想, 同時控制了廣義測驗重疊率, 采用在線更新項目曝光控制參數的方法而成。該方法有幾大優勢:(1)可以同時控制項目曝光率和廣義測驗重疊率; (2)在線更新曝光控制參數, 無需迭代模擬, 大大節省了CAT的時間; (3)能夠適用于題庫中項目和被試群體發生變化的情況; (4)可以和其他選題策略相結合使用。
基于廣義測驗重疊率的概念, Chen (2010)給出了其計算公式:


為了計算和編程的便捷性, 需要對廣義測驗重疊率進行重構, 可以根據遞歸算法進行計算,公式如下:




在定義了兩個指標之后, SHGT法的具體操作分為以下幾個步驟:

δ
/h
, 在給定的選題策略(在SHGT法中, 本文采用最大費歇信息量法; 在新方法中, 采用b-matching法)下, 若選出了題庫中的第i題, 則將第i題的貢獻率η
和臨界值δ
/h
進行比較, 并且從均勻分布U
(0,1)中產生一個隨機數x
。如果滿足條件η
≥δ
/h
且x
≤k
, 那么施測第i題,否則將此題從題庫中刪除, 不再對該被試施測。如此往復;(3)在第一題i施測后, 將前一步的臨界值δ
/h
更新為(δ
?η
)/(h
?1), 作為選擇下一題比較的條件。將施測的第二題記作項目j, 當第二題j施測后,繼續更新臨界值為(δ
?η
?η
)/(h
?2), 即每做完一道項目就更新一次臨界值, 如此往復;(4)基于已施測的t個被試的測驗情況, 計算出每個項目的項目選擇概率(記為P
(S
))和項目曝光概率(記為P
(A
)), 然后對k
值進行更新:如果P
(A
)>r
, 那么k
=0;如果P
(A
)≤r
并且P
(S
)>r
, 那么k
=r
/P
(S
);如果P
(A
)≤r
并且P
(S
)≤r
, 那么k
=1(5)更新完k
值后, 為了保證被試均能順利完成CAT測驗, 需要設置h個k
值等于1, 具體做法是令最接近1的那些k
值等于1, 直到有h個1為止;(6)在得到所有k
值后, 返回到第2步對第t+1個被試施測CAT測驗。重復以上步驟直到所有被試參加完CAT測驗。需要強調的是, 當設定的Ω趨近其下限值時, 會出現無題可選的情況, 此時應在步驟(2)后加上一個補救措施, 詳細過程的描述請參見Chen(2010)。
2.2 a分層法, 按b分塊的a分層法, 按內容分塊的a分層法
2.2.1 a分層法 (STR_a)
Chang和Ying (1999)最早提出了a分層方法來提高題庫安全性。經研究表明, 盡管高a的項目很有價值, 但當高a項目施測于能力真值與項目難度不接近的被試時, 該項目的價值并不能得到充分體現。當對被試能力真值認識有限時, 應盡量避免使用高a的項目, 并且在CAT早期階段使用低a項目,后期使用高a項目的方式是合理的。由此, 他們提出了著名的a分層選題策略, 步驟為:(1)根據區分度a將題庫分成K個水平; (2)相應地, 將測驗也分成K個階段; (3)在測驗的第k個階段, 選擇項目難度與能力估計值最接近的h
個項目施測, 保證h
+h
+…+h
=h
; (4)重復步驟3。2.2.2 按b分塊的a分層法(STR_b)
正如Chang和Ying (1999)的研究表明, a分層有較好表現的一個前提是a和b之間沒有相關。但是在實際題庫中, a與b通常都是正相關的(Lord,1975)。如果某一層內的b范圍不足以覆蓋被試能力水平時, 就會導致某些項目過度選擇。而且在高a層中, 高a低b的項目很少, 將會導致這些項目過度曝光。于是, Chang, Qian和Ying (2001)提出按難度b分塊的a分層法, 步驟為:(1)基于難度b將題庫分成M塊。所有組塊中項目數量相同。將這些組塊按照升序排列; (2)在每個組塊中, 按照a值分成K個水平; (3)將同一水平的不同組塊重新組合,形成K個水平的題庫, 這樣在同一水平內的難度b也覆蓋了整個能力范圍; (4)按照a分層的步驟進行CAT測驗。若a和b的相關為0時, STR_b和STR_a是一樣的。
2.2.3 按內容分塊的a分層法(STR_c)
Van der Linden (2000)認為, CAT只有將統計性能和非統計要求相結合才能被接受, 即要在實際中考慮內容平衡等非統計屬性, 以便CAT測驗有較高的內容效度以及被試的測驗分數可以比較。于是,Yi和Chang (2003)提出了按內容分塊的a分層法,步驟為:(1)根據內容領域將題庫分成若干個組; (2)在每個組里實施STR_b。若內容領域為一個時,STR_c和STR_b是一樣的。
3 研究設計
本研究要比較的選題策略包括:隨機選題法(RN)、SHGT法、SHGT_a法、SHGT_b法以及SHGT_c法。結合方式為, 首先運用STR_a (b或c)法將題庫分層, 在每一層內使用SHGT法。其中,RN作為比較的基線。采用Matlab 2011b自編以上所有選題策略。
3.1 題庫及被試
首先生成360題的題庫(n
=360)。區分度a, 難度b以及猜測度c按如下先驗分布生成:a
~U(0.5,1.5),b
~N(0,1), c~U(0,0.4)。其次, 本研究中固定題庫所考察的內容領域數量g=3, 并且規定內容領域的項目數量比例為1:1:1, 各120題,由此生成模擬題庫, 用于進行所有的實驗。按照先驗分布θ
~N
(0,1)生成3000名被試。3.2 實驗條件及說明

本研究中CAT測驗的終止規則選取定長CAT,這也是大多數CAT研究采取的方法。固定測驗長度h=30, 這是因為Stocking (1994)建議題庫大小至少應該是測驗長度的12倍。若使用SHGT_a法, 令層數K=4。施測順序為先施測低a層, 最后施測高a層。每層內項目數量固定為7題, 7題, 8題和8題; 若使用SHGT_b法, 令塊數M=3, 再令層數K=4, 其他同SHGT_a法; 若使用SHGT_c法, 先按照內容領域將題庫分成若干個組, 隨后在每個組里實施SHGT_b法; 利用EAP法對被試能力進行更新。



3.3 評價指標
(1)廣義測驗重疊率

(2)誤差均方根

θ
和?θ
分別為能力真值和估計值。RMSE反映了參數真值與估計值之間的平均偏差大小, 其值越小越好。除此之外, 程序還記錄了最大項目曝光率和使用過的項目數量, 以此考察各選題策略的性能。
4 研究結果
總體來看, 根據表1至表4的結果, 不論共享人數為多少, SHGT及3種新方法均能很好地控制項目曝光率和廣義測驗重疊率。例如, 根據表1結


表1 rab=0.2, 測驗內容比例為1:1:1時, 5種選題策略的結果

表2 rab=0.8, 測驗內容比例為1:1:1時, 5種選題策略的結果

表3 rab=0.2, 測驗內容比例為1:2:3時, 5種選題策略的結果

表4 rab=0.8, 測驗內容比例為1:2:3時, 5種選題策略的結果


5 小結與討論

本研究借鑒a分層方法的思想, 成功地將SHGT法與不同形式的a分層法相結合, 在保留各自優勢的前提下, 相互彌補了缺陷。SHGT法在控制廣義測驗重疊率的同時, 解決了項目過度曝光問題, a分層法可以有效提高題庫使用率, 保證了測驗安全性。

(1)本研究只采取了在a分層的每一層內選取近似相等的項目數量, 沒有考察升序的實驗條件。根據已有研究表明, 采用升序的a分層效果更佳(Chang & Ying, 1999; Chang & Ying, 1996, 2008; Hau& Chang, 2001), 這在以后研究中可以進行探討;
(2)本研究發現, 在測驗考察內容比例不均衡條件下, 新方法均有較穩定的表現, 尤以SHGT_c法表現最好。但這是在題庫及內容數量相對較小,測驗長度固定為30題時的結果。今后可以研究在不同題庫容量、不同內容領域數量及比例條件下,新方法的表現;
(3) CAT的優勢在于可以對每個被試的能力估計精度進行控制, 這時就需要采用變長的CAT。具體做法可以根據每層內達到的信息量值作為變長CAT的標準(Wen, Chang, & Hau, 2000; 戴海琦, 陳德枝, 丁樹良, 鄧太萍, 2006);
(4)程小揚等人(2011)提出了引入曝光因子的CAT選題策略, 該方法使題庫中項目的調用更加均勻, 曝光率指標明顯降低, 能力估計精度也較高。將該選題策略與本文提出的方法進行比較也是值得研究的方向。
Chang, H. H., Qian, J. H., & Ying, Z. L. (2001). A–Stratified multistage computerized adaptive testing with b blocking.Applied Psychological Measurement, 25
(4), 333–341.Chang, H. H., & Ying, Z. L. (1996). A global information approach to computerized adaptive testing.Applied Psychological Measurement, 20
(3), 213–229.Chang, H. H., & Ying, Z. L. (1999). A–stratified multistage computerized adaptive testing.Applied Psychological Measurement, 23
(3), 211–222.Chang, H. H., & Ying, Z. L. (2008). To weight or not to weight?Balancing influence of initial items in adaptive testing.Psychometrika, 73
(3), 441–450.Chang, H. H., & Zhang, J. M. (2002). Hypergeometric family and item overlap rates in computerized adaptive testing.Psychometrika, 67
(3), 387–398.Chen, P. (2011).Item replenishing cognitive diagnostic computerized adaptive testing—— based on DINA model.
Unpublished doctoral thesis, Beijing Normal University.[陳平. (2011).認知診斷計算機化自適應測驗的項目增補—— 以DINA模型為例
. 博士學位論文, 北京師范大學.]Chen, S. Y. (2010). A procedure for controlling general test overlap in computerized adaptive testing.Applied Psychological Measurement, 34
(6), 393–409.Chen, S. Y., & Ankenman, R. D. (2004). Effects of practical constraints on item selection rules at the early stages of computerized adaptive testing.Journal of Educational Measurement, 41
(2), 149–174.Chen, S. Y., Ankenmann, R. D., & Spray, J. A. (2003). The relationship between item exposure and test overlap in computerized adaptive testing.Journal of Educational Measurement, 40
(2), 129–145.Chen, S. Y., & Lei, P. W. (2005). Controlling item exposure and test overlap in computerized adaptive testing.Applied Psychological Measurement, 29
(3), 204–217.Chen, S. Y., & Lei, P. W. (2010). Investigating the relationship between item exposure and test overlap: Item sharing and item pooling.British Journal of Mathematical and Statistical Psychology, 63
(1), 205–226.Chen, S. Y., Lei, P. W., & Liao, W. H. (2008). Controlling item exposure and test overlap on the fly in computerized adaptive testing.British Journal of Mathematical and Statistical Psychology, 61
(2), 471–492.Cheng, X. Y., Ding, S. L., Yan, S. H., & Zhu, L. Y. (2011).New item selection criteria of computerized adaptive testing with exposure–control factor.Acta Psychologica Sinica, 43
(2), 203–212.[程小揚, 丁樹良, 嚴深海, 朱隆尹. (2011). 引入曝光因子的計算機化自適應測驗選題策略.心理學報, 43
(2),203–212.]Dai, H. Q., Chen, D. Z., Ding, S. L., & Deng, T. P. (2006). The comparison among item selection strategies of CAT with multiple–choice items.Acta Psychologica Sinica, 38
(5),778–783.[戴海琦, 陳德枝, 丁樹良, 鄧太萍. (2006). 多級評分題計算機自適應測驗選題策略比較.心理學報, 38
(5),778–783.]Georgiadou, E. G., Triantafillou, E., & Economides, A. A. (2007).A review of item exposure control strategies for computerized adaptive testing developed from 1983 to 2005.The Journal of Technology, Learning and Assessment, 5
(8), 4–37.Hau, K. T., & Chang, H. H. (2001). Item selection in computerized adaptive testing: Should more discriminating items be used first?Journal of Educational Measurement,38
(3), 249–266.Lord, F. M. (1975). The ‘ability’ scale in item characteristic curve theory.Psychometrika, 40
(2), 205–217.Parshall, C., Harmes, J. C., & Kromrey, J. D. (2000). Item exposure control in computer–adaptive testing: The use of freezing to augment stratification.Florida Journal of Educational Research, 40
(1), 28–52.Revuelta, J., & Ponsoda, V. (1998). A comparison of item exposure control methods in computerized adaptive testing.Journal of Educational Measurement, 35
(4), 311–327.Stocking, M. L. (1994).Three practical issues for modern adaptive testing item pools
(ETS Research Rep. No. 94–5).Princeton, NJ: Educational Testing Service.Stocking, M. L., & Swanson, L. (1993). A method for severely constrained item selection in adaptive testing.Applied Psychological Measurement, 17
(3), 277–292.Sympson, J. B., & Hetter, R. D. (1985).Controlling item–exposure rates in computerized adaptive testing.
Paper presented at the Proceedings of the 27th annual meeting of the Military Testing Association. San Diego.Tang, X. J., Ding, S. L., & Yu, Z. H. (2012). Application of computerized adaptive testing in cognitive diagnosis.Advances in Psychological Science, 20
(4), 616–626.[唐小娟, 丁樹良, 俞宗火. (2012). 計算機化自適應測驗在認知診斷中的應用.心理科學進展, 20
(4), 616–626.]van der Linden, W. J. (2000). Constrained adaptive testing with shadow tests. In W. J. van der Linden & C. A. W. Glas(Eds.).Computerized adaptive testing: Theory and practice
(pp. 27–52).
Norwell MA: Kluwer.van der Linden, W. J. (2003). Some alternatives to Sympson–Hetter item–exposure control in computerized adaptive testing.Journal of Educational and Behavioral Statistics, 28
(3), 249–265.Way, W. D. (1998). Protecting the integrity of computerized testing item pools.Educational Measurement: Issues and Practice, 17
(4), 17–27.Weiss, D. J. (1982). Improving measurement quality and efficiency with adaptive testing.Applied Psychological Measurement, 6
(4), 473–492.Weiss, D. J. (1985). Adaptive testing by computer.Journal of Consulting and Clinical Psychology, 53
(6), 774–789.Wen, J. B., Chang, H. H., & Hau, K. T. (2000).Adaptation of a–stratified method in variable length computerized adaptive testing.
Paper presented at the American Educational Research Association Annual Meeting. Seattle.Yi, Q., & Chang, H. H. (2003). a–Stratified CAT design with content blocking.British Journal of Mathematical and Statistical Psychology, 56
(2), 359–378.猜你喜歡
科學大眾(2022年11期)2022-06-21 09:20:52
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大世界(2018年1期)2018-04-12 05:39:14
臺聲(2016年2期)2016-09-16 01:06:53
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
時代英語·高三(2014年5期)2014-08-26 02:49:51
