D—S算法在多傳感器網絡機動目標識別中的應用
2014-04-29 00:44:03高文付
電腦迷 2014年23期
高文付

摘 要 采用矩陣分析方法建立了用于目標識別的多傳感器數據融合的數學模型。該模型綜合了來自多種不同傳感器的的基本概率分配值,通過定義相關系數矩陣來獲取基本概率分配值矩陣。提出了一種多傳感器信息融合的新算法,該算法依靠可信度的積累,通過多級遞推融合可獲得目標狀態基于全局信息的融合估計值。實例分析表明:基于融合后的識別結果較各傳感器單獨決策的結果性能優化,具有較強的容錯性和有效性。
關鍵詞 數據融合 D-S規則 目標識別 矩陣分析
中圖分類號:TP212.9 文獻標識碼:A
0引言
當各傳感器對它們各自的判決并不能百分之百確信時,可以采用一種基于統計方法的數據融合分類算法,即Dempster-Shafer算法。該算法能捕捉、融合來自多傳感器的信息,這些信息在模式分類中具有能確定某些因素的能力。使用D-S規則來融合各傳感器事件(也稱之為命題)的知識,最后找到各命題的交集及與之對應的概率分配值。
1算法概述
每個傳感器都能接收一類觀察量,這些可觀察量都體現了目標及它們所在環境的某些信息。各傳感器對這些可觀察量再利用各分類算法(傳感器級融合)進行分類。這里對每個傳感器k(k=1,…,n)賦予一個0-1之間的概率分配值m,這個概率分配值反映了對該判決的確信程度。概率分配值越接近1,說明該判決越有明確的證據支持,從而對物體類型的不確定程度就越低。然后各傳感器的各概率分配值通過D-S規則融合,從而再選出某種假設,使該假設能被在各傳感器上已經得到的絕大多數證據所支持。
假設n個互斥且窮盡的原始子命題存在,比如目標的類型是a1或a2…或an。這個命題集組成了整個假設事件的空間,我們稱之為識別框架 。對該命題集里的每個子命題都可以賦予一個概率分配值m(ai)。如果碰到不是所有的概率分配值都能直接賦給各子命題或他們的并時,可以把剩下的概率分配值全部分配給u(它代表了由不知道所引起的不確定,以后該概率分配值可以進一步的細化)
如果遇到交命題是空集的情況,那么該交命題所對應的概率分配值應設為0,其他非空的交命題所對應的概率分配值應同乘以一個因子K,使得所有概率分配值的和為1,即如果交命題c的概率分配值是這種形式時:
這里定義為空集,如果K為1,則說明mA和 mB是完全矛盾的,此時用D-S規則來融合兩個得到完全矛盾信息的傳感器是不可能的。
當有三個或更多的傳感器信息需要融合時,可以再一次使用D-S規則,方法是把前兩個傳感器融合后的交命題及對應的概率分配值作為一組新的概率分配值,然后用前面討論的類似方法將第三個傳感器的命題及對應的概率分配值與其相融合。
2基于矩陣分析的D-S規則數據融合
將n個待識別目標以及框架u的m組后驗可信度分配構成矩陣:
式(3)表示各傳感器被支持的綜合程度,被支持的綜合程度越高,則在數據融合中的重要程度也越高。根據各傳感器數據的重要程度對數據進行融合,得到式(7),從而得到最后的融合結果。
3識別實例與分析
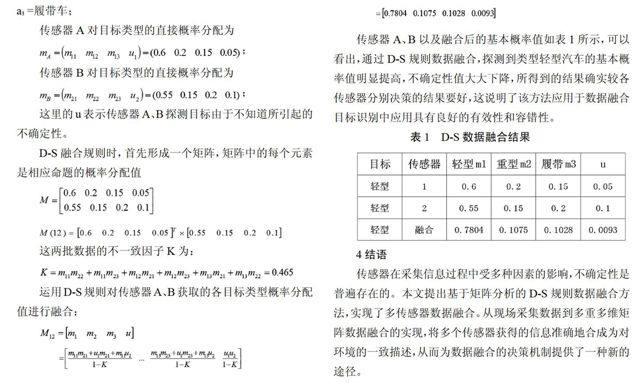
下面用一個三目標雙傳感器的例子來說明如何運用該法則進行融合。假設存在三個目標 :a1=輕型汽車,a2 =重型汽車,a3 =履帶車;
這里的u表示傳感器A、B探測目標由于不知道所引起的不確定性。
D-S融合規則時,首先形成一個矩陣,矩陣中的每個元素是相應命題的概率分配值
這兩批數據的不一致因子K為:
運用D-S規則對傳感器A、B獲取的各目標類型概率分配值進行融合:
傳感器A、B以及融合后的基本概率值如表1所示,可以看出,通過D-S規則數據融合,探測到類型輕型汽車的基本概率值明顯提高,不確定性值大大下降,所得到的結果確實較各傳感器分別決策的結果要好,這說明了該方法應用于數據融合目標識別中應用具有良好的有效性和容錯性。
4結語
傳感器在采集信息過程中受多種因素的影響,不確定性是普遍存在的。本文提出基于矩陣分析的D-S規則數據融合方法,實現了多傳感器數據融合。從現場采集數據到多重多維矩陣數據融合的實現,將多個傳感器獲得的信息準確地合成為對環境的一致描述,從而為數據融合的決策機制提供了一種新的途徑。
