大數據驅動的特色資源服務平臺架構研究*
2014-12-24 08:22:58朱維喬
圖書館研究 2014年4期
朱維喬
(廣州航海學院圖書館,廣東 廣州 510725)
1 大數據對圖書館界的影響及應用概述
隨著云計算、傳感網絡等信息技術的蓬勃發展和多種移動終端、社交網絡的廣泛使用,數據量呈爆炸式增長之勢,“大數據”概念應運而生,一些研究機構將其定義為數量超出傳統關系數據庫系統收集、存儲和分析能力的數據集[1],其所產生的影響已滲入社會生活的諸多領域。美國政府宣布的“大數據研究與發展倡議”將大數據定位為未來信息技術發展的核心,預示著其將對全球知識創新與知識服務形式產生深遠的影響。時至今日,大數據技術的廣泛應用使海量多結構數據的即時獲取、深度挖掘和精確分析成為現實,也將為正在興起的知識服務注入更多服務增長點。國內外圖書館界均對其展開了如火如荼的研究與應用。
國內圖書館界的大數據應用以清華大學圖書館為代表,其應用大數據技術為讀者提供知識服務,在檢索平臺上綜合運用多來源數據,將書、刊、文章等元數據匯聚在一起用于檢索,用戶可通過開放鏈接技術定位及獲取資源[2]。國外圖書館界的大數據應用由美國哈佛大學圖書館率先發起,其將圖書大數據公開并在國家公共數字圖書館中提供下載,內容包括書目數據、音頻、視頻、圖像、手稿等多種類型的非結構化數據,共計一千多萬種資料[3],該項大數據服務旨在促進全球圖書目錄的開放共享與大數據技術的研發,滿足急劇擴張的知識服務需求;此外,新加坡國家圖書館管理局采用大數據技術對持續增長的大量非結構化數據進行分析,并在其門戶網站上將讀者最感興趣的信息實行自動推送,目前已完成對“新加坡記憶”特色資源網站的上百萬篇文章的文本分析,并為解決存儲與計算設備擴展性的問題建立了一整套分布式系統基礎架構集群,由在主機上虛擬的數十臺服務器組成,這使其擁有了可擴展的分布式計算平臺,解決了應用大數據技術挖掘和實現用戶知識服務需求的難題[4]。
2 大數據驅動的特色資源服務平臺架構
圖書館特色資源服務平臺架構以用戶的個性化和專業化需求為出發點,提供面向用戶的經過數據分析加工且能滿足實際需求的特色知識信息。本文將針對特色資源平臺架構的主要環節,將大數據作為一種技術方法與提供知識服務的新工具,如圖1所示,分析其在每一環節的具體應用。
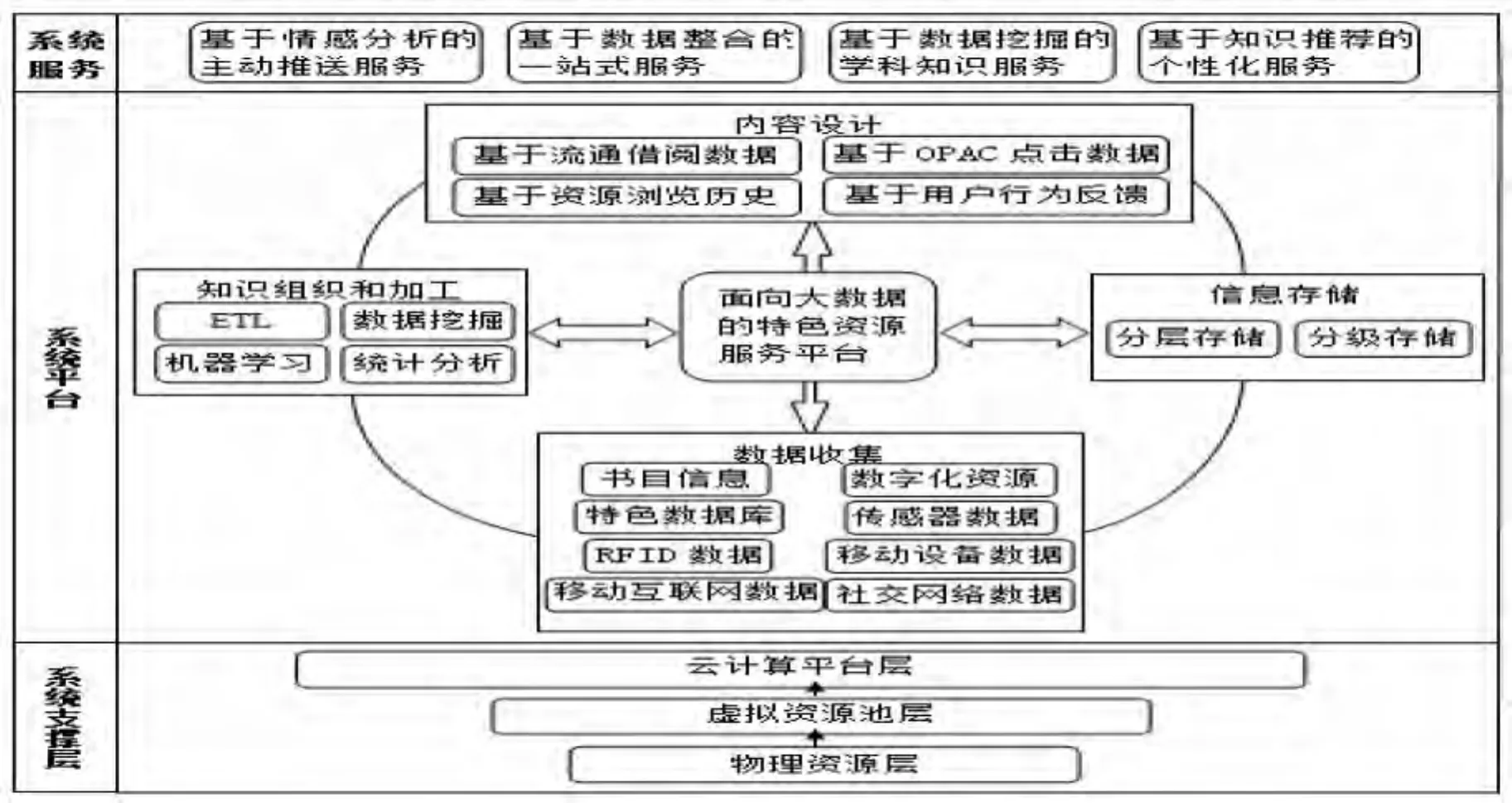
圖1 面向大數據的特色資源平臺體系架構
2.1 內容設計環節
評價特色資源平臺架構的重要因素之一是其內容與功能的設計科學性,內容設計應明確建設的重點方向與目標,基于用戶的使用特點與需求分析而進行。OCLC(聯機計算機圖書館中心)發布報告稱,圖書館正在經受著技術障礙、人才瓶頸等問題的困擾,用戶流失較為嚴重[5]。因此,如何在內容設計環節應用大數據技術進行用戶分析,對特色資源平臺的內容與功能進行合理定位,構建新型特色資源服務從而吸引更多的用戶,將成為特色資源建設工作的挑戰。圖書館應通過分析大數據的主要信息源——即隱含在用戶檢索、咨詢等行為中的非結構化數據,如流通日志中的特色文獻借閱數據、OPAC日志中的點擊流數據、特色數字資源的瀏覽歷史、用戶信息反饋行為等可展示其偏好、習慣模式等特點的數據,進而識別、挖掘和推斷用戶的知識服務需求,按其需求進行特色資源的內容設計,使相同主題、專業與相關學科的各類文獻重組、整合成完整的特色資源體系;與此同時,還應根據動態反饋用戶需求的大數據進行知識更新,使特色資源平臺的開發者、提供者和使用者實現在各個方面提高效率的目標[6],從而提高圖書館自身的核心競爭力。
2.2 數據收集環節
數據收集環節的大數據應用,主要是為特色資源平臺建設提供更豐富的資源類型與多維化的數據來源。除圖書館自身的館藏資源,如數據庫中的書目信息、特色文獻數字化后形成的電子圖書圖像、自建特色數據庫等之外,還包括動態的傳感器數據、RFID射頻識別數據、移動設備數據、移動互聯網數據、用戶社交網絡交互數據等;另外,如網絡出版與傳播數據、館際之間的共享數據等圖書館外部的開放知識源都將成為特色資源平臺主要的大數據來源。但由于數據質量參差不齊,圖書館應設置必要的信息采集規則和機制,以確保進入特色資源庫中的知識將得到有效利用[7]。可運用信息過濾技術,針對特色學科、專題進行信息收集分析、處理與存儲,并按照一定的標準格式創建數字信息資源庫,使特色資源平臺建設得以創新并得到更多用戶的肯定,體現出更高的價值。
2.3 信息存儲環節
根據數據生命周期理論與特色資源的被檢索頻率,特色資源庫中的大數據可分為熱數據與冷數據,若二者使用同一存儲空間會影響數字資源的存儲質量。因此,圖書館應根據存儲成本、訪問頻度、數據容量與更新頻率等因素將數據分層存儲。可將存儲空間分為三層:一為快速存儲層,適用于少量熱數據,特點為價格高、容量低、運行速度快;二為次級存儲層,適用于中等價值的數據與知識,運行速度為中等;三為硬盤存儲層,適用于冷數據,特點為價格低、容量大、運行速度慢。在系統中跟蹤并記錄特色資源庫中數據與知識的被檢索頻度,同時設置相應的參數,當其符合某一存儲層的訪問頻度時將自動分配知識元到該存儲層,從而實現知識的效率存儲,以提高大數據環境下特色資源平臺的建設質量。
2.4 知識組織與加工環節
在知識組織與加工環節,大數據為其引入更為專業的數據分析技術,將分散、無序的大數據進行組織、加工與分析,對數據資源的產生、發展及波動規律進行歸納,可依據其對特色資源進行結構調整。特色資源平臺的建設目標是實現資源共享及各種數據庫之間的整合,為用戶提供來源、結構、功能均不相同的多種數據庫的一站式檢索平臺,構建綜合化特色資源服務平臺。這就要求各類數據在加工時嚴格執行統一且高質量的標準,在技術條件實現時才能使數據庫加入到整合檢索系統中。因此,需要對不同格式的數據進行處理和深層次加工,將其轉換成數據庫所要求的文件格式,從而使其符合建設特色數據庫的規范要求。當大量數據存儲于分布廣泛、多種類型的服務器中時,需要借助新型處理手段進行動態數據集的收集、組織與加工和多格式數據的整合規范,將其轉換為規律的有序數據并從中提煉價值,為特色資源平臺建設構建良好的數據支撐體系[8]。
3 面向大數據的特色資源服務體系創新發展
特色資源平臺建設與特色資源服務共同發展、不可分割。基于大數據開展的挖掘數據價值、提取知識的理念為特色資源服務模式的創新發展提供了良好的契機。
3.1 基于情感分析的主動推送服務
傳統的被動服務模式既阻礙了特色資源的有效利用,又背離了特色資源平臺建設的初衷,因此向主動推送服務模式的發展勢在必行,大數據應用使這一轉變成為現實。通過了解關于用戶情感狀態及實際需求的實時大數據,進行用戶行為智能分析與知識需求預測等新型特色資源服務,搜集與加工特色資源,并利用信息推送技術定期將相關特色資源主動推送給用戶,能夠提高特色資源的利用率及拓寬特色資源服務范圍。
3.2 基于數據整合的一站式服務
大數據環境下的海量數據資源,如文獻資源、科研成果、訪問日志、社交信息等各類網絡資源,來源于不同的機構知識庫與個體用戶,具有數量大、類型多、無序化等特點,因而需要建立數據的統一標準,實現異構系統的有效整合,使整合后的數據更具應用價值,為特色資源服務的開展提供智力支持。在微觀層面的數據整合,通過定位、連接各類數據源,對不同數據賦予統一的元數據格式與資源標識符(URI)來實現,使每個數字資源擁有唯一地址,從而構建元數據項目描述精確的數字資源庫,使分布的各種異構數據資源匯聚、融合為中心知識庫,并通過引擎的方式為用戶提供簡捷、快速的資源發現與獲取服務,構建一站式特色資源服務平臺;在宏觀層面的數據資源庫整合,通過將數據資源按照類型、學科、主題等區別進行分散聚合,形成跨數據庫、跨平臺的無縫鏈接的數字資源集成,力圖在各種數據庫系統之間建立多維度關聯,允許用戶通過集成的資源界面進入圖書館所有的資源、應用與服務入口,方便快捷地一站式完成信息獲取[9]。
3.3 基于數據挖掘的學科知識服務
為了提升特色資源服務質量,圖書館應對所收集的大數據進行加工,基于數據進行知識發現與分析,滿足用戶的學科知識需求。如將不同學科用戶的信息行為數據進行分類,進而分析用戶檢索、瀏覽和下載的文獻特征并加入時間緯度,可歸納出某個學科用戶在特定時期感興趣的主題內容;利用數據挖掘、聚類分析、相關性分析、社會網絡分析等大數據技術預測學科熱點及進行交叉學科的分析研究;基于大數據進行關聯關系分析,構建學者、合作者、會議、期刊、學術成果等元素之間的知識網絡[10];為促進特色學科發展而對數據集合進行的分析,即從元數據倉儲中提取文章關鍵詞等信息,基于時間軸進行學科趨勢分析,可以通過研究關鍵詞在時間軸上分布的方法來分析特色學科領域在一個時間段的發展趨勢并預測未來的發展方向。
3.4 基于知識推薦的個性化服務
隨著知識經濟的發展,用戶的信息需求愈加個性化和專業化,而傳統的大眾化服務模式不但無法為個體用戶提供有針對性的知識服務,也不利于圖書館資源、技術和人才的整合。可見,特色資源服務向個性化模式的發展勢在必行。圖書館應基于對用戶信息使用行為習慣的分析和對資源特定需求的預測,向其主動提供可能需求但難以獲取的資源。通過對讀者顯式行為(如資源評分、贊/踩等)和隱式行為(如瀏覽下載記錄、頁面停留時間、社交網絡數據、借閱記錄等)的分析,建立用戶剖面(user profile)進而精準把握其需求特點、規律和趨向。挖掘其隱性需求,并搭建交互平臺進而提供特色知識服務,從而有針對性地開展特色資源服務的個性化推送,實現特色資源服務效益的最大化。應用知識發現、信息挖掘等大數據技術過濾各類信息源并對用戶進行個性化知識推薦,包括基于內容過濾與協同過濾等推薦方法,通過加工整理、綜合分析形成用戶所需的個性化特色資源,并通過電子郵件發送、系統消息發布或頻道推送等方式傳送給用戶。具體內容包括:個性化定制服務根據用戶定制的目標構建個性化特色資源服務系統,通過挖掘和深加工特定專題的信息資源,查詢并反饋滿足用戶需求的結果,并利用動態網頁自動生成所定制的頁面;個性化傳遞服務以用戶需求為導向,利用信息推送技術定期為用戶傳送相關的特色資源信息。
4 特色資源平臺與服務體系推進大數據應用的制約因素及對策
大數據在特色資源平臺建設與服務應用中存在一些制約因素,圖書館可采取相應對策緩解所受到的限制。
4.1 提升特色資源數據存儲與計算能力
特色資源平臺建設與服務中的傳統數據處理方法在數據量不高于TB級時尚可承受,但其處理海量實時數據的時間與成本均至少增長幾個數量級,這成為制約大數據應用的技術瓶頸。在數據量的增長與數據復雜性的變化遠超過存儲、計算能力增強的情況下,設計最合理的分級、分層數據存儲架構成為特色資源服務體系中資源管理的重要環節。這對海量數據的存儲與計算能力提出了更高標準,要求其具有高度的靈活性與可擴展性,能夠支持PB級甚至更高規模的數據存儲、組織及分析。可見,對特色資源服務技術架構的革新和存儲、計算能力的提升成為大勢所趨。
4.2 完善成本可控的基礎設施構建
大數據分析需要強大的硬件設備作為后臺技術支撐,設備存儲和計算規模隨著數據量的持續增加而增大,相應成本也隨之提高,但作為公益性質的信息服務機構,圖書館在基礎設施的資金投入上與大型IT企業相比差距甚大,從而使得大數據應用受制于軟硬件成本而較難實現。為了解決成本問題,圖書館可將高端服務器設備轉換為由中低端軟硬件組成的大規模計算機集群[11],利用云計算技術為大數據創造彈性可擴展的基礎設施保障,這就要求存儲、分析非結構化數據的基礎設施是根據大規模分布式數據的密集型應用而設計,具備將存儲和計算需求分布到其中并可獲取、存儲及分析海量數據的性能。
4.3 培養特色資源服務的數據分析人才
調查顯示,相關領域人才的稀缺是制約大數據技術發展的關鍵因素[12]。大數據作為一項前沿技術,其研究人才需要具有跨學科的學習經歷,如需要集成信息技術、人工智能、數學算法等多個學科領域的技術成果。在大數據時代,圖書館要提升以知識應用為特征的特色資源服務效能,就需要館員既具有特色資源服務工作必備的基本素養,更應當掌握大數據環境下的數據組織與數據挖掘等技術,對特色資源做出有價值的預測性分析,以制定切實可行的知識服務方案。國外專業教育已開始朝培養熟練駕馭大數據的“數據圖書館員”方向發展,我國圖書館界應密切關注國外同行進展,積極培養大數據技術人才,推薦優秀館員加入科研團隊中并承擔大數據研究的任務,通過實踐積累數據分析的技能。
4.4 強化對數據安全及用戶隱私的保護
在大數據應用的推動下,特色資源服務向以數據為中心的創新型服務轉化,數據安全問題也隨之顯現。海量數據的產生、存儲與分析意味著有更多數據可能被暴露,被黑客攻擊的可能性隨著特色資源數據價值的提高而增加。此外,為了將更優質的個性化知識服務提供給讀者,圖書館從多種渠道獲取用戶個人信息、地理位置和搜索歷史等數據進而分析其信息查詢行為,這使其個人隱私在一定程度上受到威脅,成為制約大數據應用的障礙。因此,數據安全、隱私保護等均成為特色資源平臺建設與服務中亟待解決的難題,應盡快采取應對方案。在知曉用戶信息的同時需要保護其隱私權,這就要求館員自覺規范其行為、提高專業素養和職業道德,并通過為用戶設置權限,使其對個人檢索歷史等數據的保存時間和用途具有知情權,從而消除用戶的顧慮。
5 結束語
綜上所述,大數據這一新技術可為特色資源服務平臺構建良好的數據支撐體系,可為特色資源服務模式轉變等業務需求提供全新的解決方案,對加速特色資源的整合利用、提升圖書館數字化知識服務能力將起到積極的推動作用。作為未來圖書館領域無可置疑的技術發展形態,大數據應用尚處于初期的探索與實踐階段,其在特色資源服務平臺架構方向的研究還有待進一步發展完善。
[1]張文彥,武瑞原,于潔.大數據時代的圖書館初探[J].圖書與情報,2012(6):15-21.
[2]大數據環境下清華大學圖書館的實踐 [EB/OL].[2013-11-19].http://news.tsinghua.edu.cn/publish/news/mobile/4207/2013/20130829152841109507827/20130829152841109507827_.html.
[3]WATTERS A.Strata Week:Harvard library releases big data for its books[EB/OL].[2013-08-26].http://strata.oreilly.com/2012/04/harvard-book-data-cloudera-hadoop-splunk-ipo.html.
[4]Future Gov.Singapore library uses analytics and big data technology to ease users’search[EB/OL].[2013-11-6].http://www.futuregov.asia/articles/2013/sep/11/singapore-library-uses-analytics-and-big-data-tech/.
[5]MICHALKO J,MALPAS C,ARCOLIO A.Research libraries,risk and systemic change[R/OL].[2013-08-22].http://www.oclc.org/content/dam/research/publications/library/2010/2010-03.pdf?urlm=162937.
[6]王捷.大數據時代下圖書館開展信息服務的對策[J].現代情報,2013(3):81-83.
[7]孫卓.基于大數據構建圖書館知識服務引擎研究[J].圖書館學研究,2013(18):48-51.
[8]周杰,蘇靜,曾建勛.下一代數字圖書館的發展思考[J].圖書情報工作,2013(8):35-39.
[9]張麒麟,陳雅.圖書館數字資源的服務模式比較研究[J].圖書館論壇,2013(4):28-31.
[10]朱靜薇,李紅艷.大數據時代下圖書館的挑戰及其應對策略[J].現代情報,2013(5):9-13.
[11]張興旺,李晨暉,秦曉珠.構建于廉價計算機集群上的云存儲的研究與初步實現[J].情報雜志,2011(11):166-171,182.
[12]潘永花,相斌斌,周震剛,等.中國大數據技術與服務市場2012-2016年預測與分析[R/OL].[2013-09-19].http://www.idc.com.cn/prodserv/detail.jsp?id=NTAx.
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
今日農業(2021年17期)2021-11-26 23:38:44
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
英語學習(上半月)(2019年9期)2019-10-10 02:17:36
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
小太陽畫報(2018年1期)2018-05-14 17:19:25
知識經濟·中國直銷(2017年10期)2017-11-07 02:39:51
資源再生(2017年3期)2017-06-01 12:20:59
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
陜西教育·綜合版(2015年5期)2015-06-28 06:17:52
