數字圖書館跨媒體檢索技術研究
2014-12-31 09:13:26劉忠寶賈君枝趙文娟
圖書館論壇 2014年12期
劉忠寶,賈君枝,趙文娟
多媒體檢索技術是數字圖書館的關鍵技術之一。隨著多媒體數據量不斷增長,如何從中發現有用知識成為熱點。多媒體檢索技術在實際應用中顯示出優勢,但“語義鴻溝”問題并未得到有效解決。跨媒體檢索的出現促進了信息檢索技術的發展,充分利用網頁、圖像、音頻、視頻等數據,通過建立多媒體數據之間的交叉關聯關系,實現真正意義上的語義檢索。跨媒體技術的進一步發展及其在數字圖書館建設中的推廣應用,將從根本上提升數字圖書館的信息檢索能力以及用戶的滿意度。
1 數字圖書館多媒體資源及其交叉關聯關系
數字圖書館的多媒體資源規模龐大且形式多樣,其中文本、圖像、音頻、視頻、3D 模型和動畫等多媒體資源出現新特點:(1)多種媒體數據共同存在;(2)媒體數據的組織結構多樣;(3)不同媒體數據語義表達的一致性;(4)多種媒體數據之間緊密聯系。數據媒體之間存在四種交叉關聯關系:(1)文本內或文本間所包含對象的交叉關聯;(2)各類型多媒體數據所包含對象的交叉關聯;(3)用戶在檢索過程中提供的標注、評價、日志等交換信息之間的交叉關聯;(4)各類型多媒體數據與用戶之間的交叉關聯。上述交叉關聯關系見圖1。各類型多媒體數據之間存在的語義關聯關系對于整合網上資源、實現個性化檢索具有重要意義。
2 數字圖書館與跨媒體檢索
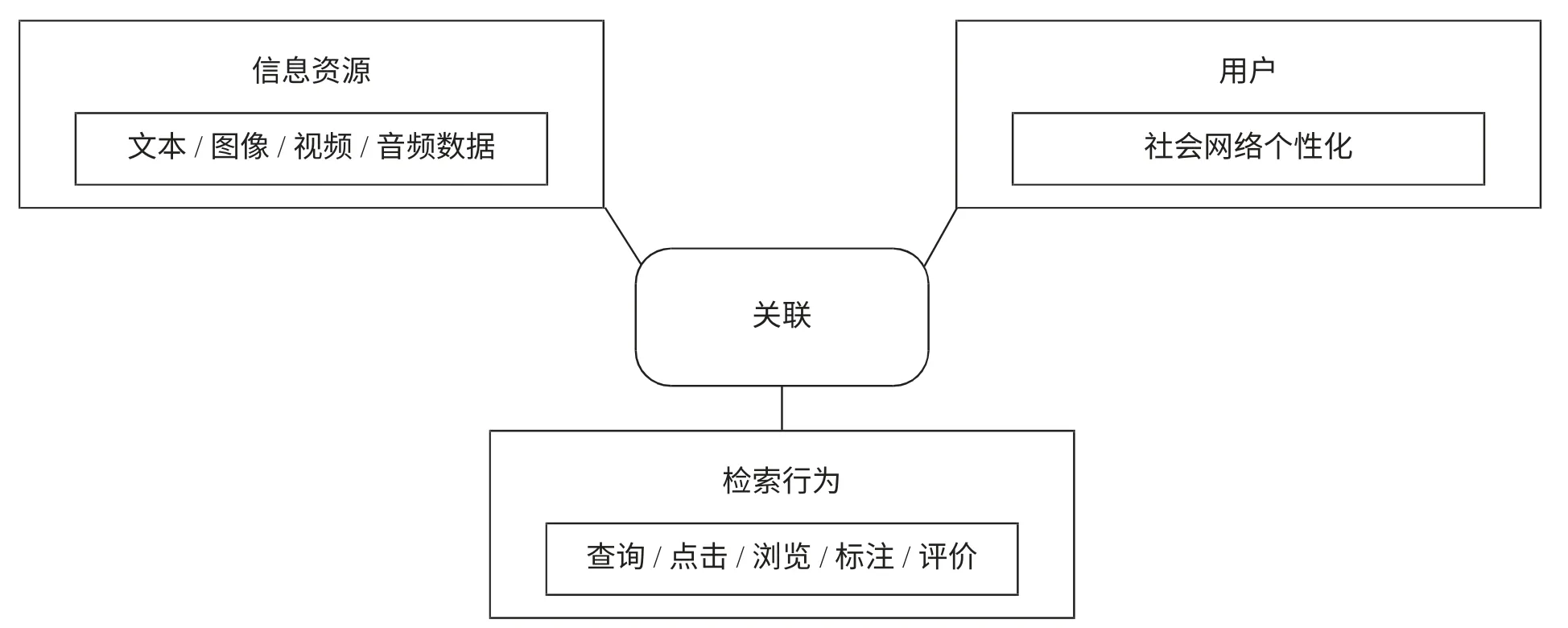
圖1 網絡資源、用戶和檢索行為之間的關聯示意圖
數字圖書館是傳統圖書館在信息時代進一步發展的產物,不僅具有藏書和提供電子資源的功能,而且還具有向公眾提供綜合信息服務的功能。隨著數字圖書館應用的不斷深入,其面臨的知識表達和檢索方式問題日益凸顯:當前數字圖書館主要面向用戶提供閱讀服務,其檢索機制多以關鍵詞檢索為主,缺乏語義理解能力,存在“語義鴻溝”問題,從而限制了信息服務水平的提升。為了解決上述問題,研究人員提出跨媒體檢索。跨媒體檢索是指信息檢索系統在多媒體檢索基礎上通過對各種媒體特征的分析,綜合利用其內在語義聯系,對具有相同或相近語義的信息進行不同媒體表示形式的處理,從而實現數字圖書館多媒體資源的有效存儲和精確檢索。跨媒體檢索的工作機理與人類認識世界的方式相似,即人類利用多種感覺器官認識世界并通過融合多種感知信息來加深對世界的認識。在進行跨媒體檢索時,用戶只需將某一媒體信息作為檢索項,數字圖書館信息檢索系統便會返回語義相同或相近各類型多媒體信息。隨著跨媒體檢索研究的不斷深入,數字圖書館檢索系統面臨的“語義鴻溝”問題終將得到解決。
3 數字圖書館跨媒體檢索技術
3.1 從多媒體檢索到跨媒體檢索
為解決早期基于文本的多媒體檢索費時費力、主觀差異性大的問題,20 世紀90 年代出現了基于內容的多媒體檢索方法,其基本思路是通過視覺、聽覺或者幾何特征來計算被檢索對象和用戶查詢之間的相似度[2-3]。基于內容的多媒體檢索的“內容”在提出時指的是“底層特征(如視覺或聽覺等特征)”或“檢索樣例”,而非語義內容。
為解決信息檢索中存在的“語義鴻溝”問題,研究人員在信息的特征空間和語義空間之間建立某種映射關系和反饋機制。目前主流的反饋技術主要有基于反饋定制、概率模型、機器學習、用戶驅動等幾類。反饋技術的使用有效地提高了檢索效率。但基于內容的多媒體檢索無法實現真正意義上的語義檢索,“語義鴻溝”問題并未從根本上予以解決。
多媒體數據往往伴隨文本信息以及用戶標注信息,從中提取能反映多媒體數據語義信息成為近年來的研究熱點。主流研究的基本思路是通過對標注訓練數據集的學習得到標注對象與文本數據之間的對應關系,然后計算語義關鍵詞在未標注數據中出現的概率。目前,基于圖像的信息檢索重點研究圖像的語義標注,這面臨大規模圖像標注、標注擴展以及標注不一致等問題。標注信息主要利用關鍵詞檢索和圖像檢索的結果對其對應的文本信息進行主題聚類獲得。隨著圖像檢索技術的發展,對圖像的標注不僅局限于對整幅圖像,對圖像包含的實體進行標注成為當下研究的重要方向,典型代表是美國卡內基梅隆大學的人臉標注系統“Name It”[4]。
數字圖書館傳統的單一類型搜索引擎利用文本信息和鏈接屬性實現信息檢索,通過多媒體視聽覺底層特征和樣例,以及相關反饋技術實現基于內容的多媒體檢索。這些方法忽略了媒體之間存在的關聯特性,難以實現不同類型媒體數據的統一檢索。為了滿足人們對這些多媒體數據檢索的需求,需要研究一種新的檢索方法,可以檢索到相似主題、不同類型的多媒體對象。這種新的檢索方式能夠處理和查詢不同類型的多媒體數據,極大地擴展人們獲取多媒體信息的途徑和范圍。這類“跨媒體檢索”方式需要達到如下要求[5]:
首先,跨媒體檢索要支持檢索過程中在數據類型上的跨越。所謂異構多媒體數據指的是不同類型的多媒體數據,如圖像與音頻數據就互為異構多媒體數據。如給定一幅圖像、一篇文本和一段音頻數據,雖然它們對信息的表現形式各異,底層特征也不同。但是,異構多媒體數據卻可以在語義層面統一起來:如老虎的圖像、老虎習性的描述性文字和老虎吼叫的音頻數據雖然表達形式各異,卻在語義層面共同表達了老虎這一概念。傳統的單一媒體相關技術忽略了異構多媒體數據在語義上的共性,因而不能有效處理異構多媒體數據共存的復雜多媒體數據,也無法有效跨越“語義鴻溝”。作為單一媒體技術在理論和功能上的延伸,跨媒體技術將異構多媒體數據統一理解分析;圖像、文本、音頻、視頻等異構多媒體數據在語義層面的共性得以利用,這不但更符合人類的思維方式,而且也便于對異構多媒體數據的統一管理,以方便用戶對其使用以及信息的傳遞。
其次,跨媒體檢索要支持同構多媒體數據在語義上的跨越。所謂同構多媒體數據指的是相同類型的多媒體數據,如兩幅圖像互為同構多媒體數據。由于不同概念之間有著復雜的關聯,雖然同構多媒體數據表達方式一致,但是它們所蘊含的語義聯系卻錯綜復雜。如何挖掘同構多媒體數據之間的語義關聯信息是跨媒體研究的又一重要內容。以不同的文本數據為例,它們雖然表達形式一致,但是所蘊含的語義關聯卻有可能是相反、相近、相同的。跨媒體研究就是要根據同構多媒體數據在特征空間內錯綜復雜的分布找到它們之間的潛在的語義關聯,從而完成語義的跨越。比如僅僅在文本的特征空間,“稻谷”和“午飯”這兩個文本對象所描述的內容屬于不同概念,而在語義層面二者有明顯的關聯。跨媒體研究則要根據全體文本對象在特征空間的分布,挖掘出同構多媒體數據之間這種固有的語義關聯,從而方便對這些多媒體數據的檢索和利用。
最后,跨媒體檢索也要支持異構多媒體數據在語義上的跨越。對異構多媒體數據在語義上的跨越,目的是找到異構多媒體數據之間錯綜復雜的語義關聯,這是對前面所述兩項研究的綜合。比如老虎的叫聲和灰狼的圖像,它們既不是同一類多媒體數據(二者類型分別屬于音頻和圖像),表達的語義也不相同(二者語義分別屬于老虎和灰狼),但是考慮到老虎和灰狼同屬食肉動物,這兩類多媒體數據之間又有一定的語義關聯。這種異構多媒體數據的語義關聯挖掘,傳統的單一媒體研究并沒有涉及。因此,這一研究內容是跨媒體研究對傳統單一媒體研究的進一步延伸和拓展。從圖像、音頻等媒體數據中提取出來的視覺和聽覺等特征量綱不同,存在異構性。要實現跨媒體檢索,需要解決如何度量異構特征相似性問題。
最近一些研究通過典型相關性分析(Canonical Correlation Analysis,CCA)挖掘異構數據在特征上潛在的統計關系,從而生成包含不同類型數據的同構子空間實現異構數據相似性度量,并在特征降維后能最大程度地保持原始異構數據的相關性。由于典型相關性分析是建立在兩個不同變量場所對應矩陣的基礎上,因此,同樣也適用于對圖像與音頻、音頻與文本等跨媒體特征的相關性分析。
3.2 從多媒體表達到跨媒體表達
在數字圖書館知識表達方面,早期人工智能領域有一些研究人員主張用統一的邏輯框架來表示各種事物。隨著數據挖掘技術的發展,通過統計學習的方法獲得多媒體數據表達的研究逐漸成為機器學習領域的熱點。從多媒體數據中提取出文本和視覺、聽覺等底層特征,拼合成特征向量后,需要解決如何學習得到特征向量相似度度量函數,使其與數據在原始空間幾何分布一致的問題。該方面較有代表性的工作可分為子空間學習和流形學習兩類。
研究表明數字圖書館中許多類型數據的分布并不是線性的,而是非線性的流形結構。基于上述理論,國內外研究人員提出多種流形學習方法[6]。同時多媒體數據中局部特征提取也成為業界關注的熱點。“詞袋”在自然語言理解中表示文檔,受其啟發,“視覺單詞”和“數據文法”可以用來表示圖像和視頻數據。該方法利用SIFT(Scale- Invariant Feature Transform)算法提取圖像和視頻數據的局部特征并將聚類后的結果作為視覺單詞。計算機視覺中有關圖像分割技術的發展使得通過對圖像中對象識別,構建視覺單詞和視覺文法實現圖像解釋成為可能。由于從圖像、視頻、網頁和動畫等多媒體數據中提取的特征仍然較多,傳統向量空間模型表示多媒體數據存在兩大問題:其一是造成“維數災難”問題;其二是由于特征向量維度過高以及訓練樣本不足,將不同屬性特征進行拼合引起“過壓縮”問題,導致大量信息丟失。另外,不同類型特征通過簡單向量拼接也在一定程度上減弱或忽略了視頻中這些多種屬性特征之間關聯性。為了反映跨媒體數據中存在的交叉關聯等復雜關系,矩陣、張量和圖等形式下數據結構被使用[8],由于其能描述復雜對象各組成部分之間的拓撲結構,并能闡明關于表示的假設,因而計算效率得到有效提高。如何實現矩陣、張量和圖等復雜結構處理是實現跨媒體理解要解決的關鍵問題。
4 未來研究熱點
信息檢索技術是數字圖書館建設的重要內容之一,其經歷了人工標注階段、內容檢索階段以及跨媒體檢索階段。隨著互聯網上數據量的不斷增長,信息資源檢索至今仍作為一個熱門研究方向備受關注。在未來幾年,信息資源檢索在以下方面值得關注:
(1)底層特征很難與高層語義建立準確的對應關系,“語義鴻溝”問題仍是跨媒體檢索面臨的一大難題。
(2)Web2.0 時代下,用戶在媒體內容生成和編輯過程中的參與度急劇增強。如何從用戶交互中獲取用戶行為,生成偏好信息,發現用戶社區,實現更理想的個性化檢索將是下一代數字圖書館提供更優質服務的關鍵所在。
(3)近年涌現出不少利用機器學習算法在互聯網級語料庫或圖像庫實現知識發現和語義理解的研究成果。該研究的進一步深入是將跨媒體檢索推向實用的必經之路[10-11]。
(4)壓縮感知和變量選擇理論與方法相結合,用來對圖像形成更加有效的“稀疏表達”(Sparse Representation),已成為計算機視覺和機器學習等領域的研究熱點。如可針對圖像中不同視覺特征在表示特定高層語義時所起重要程度不同,定義結構性組稀疏(Structural Group ing Sparsity)機制實現高維異構特征的差別性選擇[12]。
[1] 吳飛,莊越挺.互聯網跨媒體分析與檢索:理論與算法[J].計算機輔助設計與圖像圖形學報,2010,22(1):1- 9.
[2] Datta R.,Joshi D.,Li J.,et al. Image retrieval:ideas,influences,and trends of the new age[J]. ACM Computing Surveys,2008,40(2),5- 60.
[3] Smoliar S.,Zhang H J.. Content based video indexing and retrieval [J]. IEEE Multimedia,1994,1(2):62- 72.
[4] Satoh S.,NakamuraY.,Kanade T..Name- It:naming and detecting faces in news videos [J]. IEEE Multimedia,1999,6(1):22- 35.
[5] Zhuang Y T,Yang Y,Wu F. Mining semantic correlation of heterogeneous multimedia data for cross- media retrieval[J]. IEEE Transactions on Multimedia,2008,10(2):221- 229.
[6] Saul L.K.,Weinberger K.Q.,Ham J.H,et al.Spectral methods for dimensionality reduction [M].Cambridge,MIT Press,2006.
[7] Korn,F.,Pagel,B.,Faloutsos,C.. On the “Dimensionality Curse” and the “Self- Similarity Blessing”[J]. IEEE Transactions on Knowledge and Data Engineering,2001,13(1):96- 111.
[8] Tao D.,Li X.,Wu X.,et al. Supervised tensor learning [J]. Knowledge and Information Systems,2007,13(1):1- 42.
[9] Wright J.,Yang A.,Ganesh A.,et al. Robust face recognition via sparse representation [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,31(2):1- 18.
[10] Mahoney M.,Lim L.,Carlsson G.. Algorithmic and statistical challengesin modern large scale data analysis[J].SIGKDD Explorations,2008,10(2):57- 60.
[11] Talwalkar A.,Kumar S.,Rowley H.. Large scale manifold learning[C]. Proceedings of Computer Vision and Pattern Recognition,Anchorage,2008:1- 8.
[12] Wu F,Han Y H,Tian Q,et al. Multilabel boosting for image annotation by structural grouping sparsity [J].ACM Multimedia,2010:15- 24.
猜你喜歡
當代陜西(2021年17期)2021-11-06 03:21:36
名師在線·上旬刊(2021年3期)2021-09-10 04:20:48
開放教育研究(2020年2期)2020-03-31 01:54:14
消費導刊(2018年10期)2018-08-20 02:56:28
學苑創造·A版(2018年11期)2018-02-01 06:29:20
讀者(2017年5期)2017-02-15 18:04:18
現代語文(2016年21期)2016-05-25 13:13:44
河南電力(2016年5期)2016-02-06 02:11:40
語文知識(2015年9期)2015-02-28 22:01:42
大連民族大學學報(2015年2期)2015-02-27 08:28:11
