基于書目框架(BIBFRAME)的家譜本體設計*
2014-12-31 09:44:26夏翠娟朱雯晶
圖書館論壇 2014年11期
夏翠娟,劉 煒,張 磊,朱雯晶
0 引言
書目框架(BIBFRAME)是美國國會圖書館牽頭開發的下一代書目數據格式標準,也是該開發項目的簡稱。自2011年5月起,美國國會圖書館聯合大英圖書館、德國國家圖書館等6個圖書館,請DC元數據的發明人之一,也是語義萬維網技術的倡導者Eric Miller領銜,正式啟動“書目框架計劃”。該計劃的主要目標是設計一套互聯網時代的書目數據標準,用以取代MARC,并能為圖書館、檔案館、博物館、美術館等“人類文化記憶機構”共同使用[1]。經過3年多的開發,書目框架模型基本成型,各相關規范的文本編寫接近尾聲。目前其官方網站(http://www.loc.gov/bibframe/)發布的成果包括書目框架模型(BIBFRAME Model)、術語詞表(BIBFRAME vocabulary,包含300多個術語,并還在根據需要增加和修訂)、BIBFRAME綱要(BIBFRAME Profile,對于各類“社區”應用書目框架的進一步限定或擴展的規定)、書目框架權威檔(BIBFRAME Authorities)、關系描述(BIBFRAME Relationships)以及MARC數據轉換為BIBFRAME格式的工具、書目框架編輯器(BIBFRAME Editor)的演示平臺等,內容非常豐富;但行百里者半九十,尚有一些關鍵細節還沒有定論,如對書目框架的形式化表達和書目數據的RDF序列化規則等方面還有大量的工作要做,特別是對如何保留或有沒有必要保留那些基于AACR2或RDA的編目規則而得到的大量豐富而微妙的語義,正在進行激烈的論辯。
家譜是一類記載具有血緣關系的家族世系繁衍情況和重要人物及事跡的歷史文獻,是研究人文歷史和地域文化的重要資源。上海圖書館是全世界收藏中文家譜(原件)數量最多的機構。為了更好地保護和庋藏這些資料,上海圖書館在過去10多年一直在進行家譜的整理和數字化工作,初步建立了包含1.8萬余種家譜的影像資源庫,以圖書館人熟悉的MARC格式作為數據檢索和交換格式提供服務。近年隨著“數字人文”研究的興起和各類相關工具平臺的建立,基于文獻的揭示方式難以滿足學者進行深入研究的需要。比如,家譜中包含豐富的人、地、時、事、機構及相互關系等,都不是基于MARC的系統所能描述和揭示的,還必須進一步進行基于內容的深度加工和揭示,并提供靈活的、多維度的展示和操控工具,才能使數字家譜得到更好的利用。
語義萬維網技術尤其是關聯數據技術為上述需求提供了可行的方案。書目框架就是該技術在圖情領域的最新應用,正好能為重組家譜資源、重構家譜服務系統提供新的解決方案。書目框架是基于關聯數據技術框架設計的。關聯數據是語義萬維網的輕量級實現方式,它植根于現有的Web基礎技術:用HTTP URI來標識數據,使URI不僅作為事物的名稱,同時兼作存取地址;以服務器對不同請求的響應來區分信息資源或非信息資源;采用RDF模型作為描述世間萬物及其相互關系的基本結構,在此基礎上可以利用萬維網本體語言(OWL)建立更為復雜的領域知識模型,為更廣泛的基于機器理解的語義互操作奠定了基礎[2-3]。
知識本體給數據賦予了語義,關聯數據技術以標準的格式為數據編碼使得機器能夠理解語義并處理數據間的關系。本文提出采用語義萬維網技術來建設新的家譜知識庫系統,設計一個向下兼容、易于擴展、便于重用和共享、支持家譜數據重組和知識建模的家譜知識本體,這是首要的工作。設計知識本體的一個重要原則是盡量復用已有的本體模型和術語詞表。本文在文獻調研、家譜領域現有案例分析以及技術現狀研究的基礎上,基于書目框架模型,復用書目框架術語詞表中的術語,設計了上海圖書館家譜本體,并采用書目框架應用綱要來規范家譜本體的應用和實施,這是利用語義萬維網技術改造圖書館傳統資源的組織方式,以提升服務效果的一種嘗試,也是對正在發展之中的書目框架應用于中文環境的試驗和檢測。
1 家譜信息系統建設及研究現狀
1.1 現有的家譜應用系統和技術
家譜收藏機構主要是圖書館和教會、宗親會等機構。在國外,家譜收藏機構有美國猶他家譜研究學會、日本國立國會圖書館等;在我國港臺地區,臺灣“故宮博物院”和臺北“國家圖書館”收藏家譜較多,香港大學圖書館也有少量收藏;我國大陸家譜收藏和研究機構主要有中國國家圖書館,上海圖書館等幾個大型的省級公共圖書館,以及少數高校圖書館。目前主要的家譜應用系統有猶他家譜研究學會的家譜檢索中心(FamilySearch.org)、日本國立國會圖書館的東洋文庫、中國國家圖書館的“中華尋根網”、上海圖書館的家譜數據庫、臺灣地區家譜聯合目錄數據庫、《四庫全書》等大型數字化古籍數據庫中的家譜資源庫等。王昭[4]和毛建軍[5]對上述家譜收藏機構和家譜應用系統進行了介紹分析。
日本國立國會圖書館的東洋文庫、中國國家圖書館的“中華尋根網”、上海圖書館的家譜數據庫均采用題名、著者、姓氏、居地、名人等字段進行檢索,是基于字段關鍵詞匹配、面向家譜文獻資源的檢索系統。猶他家譜研究學會的FamilySearch.org不僅可以根據文獻的收藏地、類型、批次號碼和縮微膠卷編號來查詢家譜資料,還可根據姓氏和名字、生平事跡(出生、結婚、居所、死亡等)、配偶或父母關系來查詢。國外還有Ancestry.com 和WeRelate等家譜網站,與FamilySearch一樣,允許用戶自行創建家族樹,上傳家族照片和撰寫人物生平大事,甚至多個不同用戶可共同維護一棵家族樹。
國外家譜領域應用較為廣泛的技術標準是GEDCOM,較有影響的家譜概念模型是GENTECH。GEDCOM 是用于在不同的家譜軟件之間交換數據的家譜數據交換標準,最開始是為耶穌基督后期圣徒教會(The Church of Jesus Christ of Latter-day Saints)的需求設計,也被美國猶他家譜研究學會采用。它不是一個數據模型,可看做是用于家譜數據的文本標記語言。GEDCOM 文件是包含家譜文獻元數據記錄的純文本,其結構適合于20世紀90年代的技術環境。Campanya Artes Joan[6]指出:在目前的環境下,它有以下幾個弊端:專用的格式不利于進一步發展;標準的定義不夠嚴謹,在應用過程中容易產生分歧;數據冗余導致不一致性;沒有足夠的靈活性來適應不同的文化環境,如人名、地名的定義和描述,只能用于家譜領域,無法與其他領域進行數據交換。GENTECH是一個家譜概念模型,源于一個研究者之間的合作項目,只在2000-2004年間延續了很短的時間,但得到美國全國宗譜協會(U.S.National Genealogical Society)的關注。雖然它沒有具體的應用實施方案指南,但常被作為許多相關應用的參考。GENTECH在某種程度上提供了一種處理復雜問題的解決方案[7],比如不同歷史時期同一地理位置具有不同的地理名稱的問題;另一方面,該模型將所有與人有關的信息關聯起來,比如機構、歷史事件、家族活動,還提供將初始數據表達成為具體應用所需的不同形式(文檔、記錄、文件)的靈活性和可擴展性。由于GENTECH沒有成為被廣泛接受的標準規范,沒有得到應用和推廣。GEDCOM 和GENTECH主要是為歐美家譜而設計,在我國少見應用。
21世紀初,W3C推出諸如XML超文本標記語言,GEDCOM 為適應這個趨勢進行升級,GEDCOM6.0版也叫GEDCOM XML。其它基于XML格式的家譜標記語言GedML、EeniML、GenXML,與GEDCOM 一樣,只有少數機構在使用。隨著語義萬維網概念的提出,W3C又推出資源描述框架(RDF)、知識本體語言(OWL)等語義萬維網相關標準規范。RDF/XML作為W3C的推薦標準和語義萬維網技術的基礎,可被大部分機器語言識別和處理,已被廣泛應用于多種不同的領域,有利于跨領域的共享和重用。Jay Askren開發了傳統的GEDCOM 格式轉換為RDF/XML格式的工具,以證明RDF的廣泛適應性[8]。語義技術作為歷史研究的工具得到重視,Albert Mero?o-Pe?uela對基于語義技術的歷史研究方法作了調研,其中涉及家譜研究[9]。關聯數據作為語義萬維網的輕量級實現方式也受到關注,Josh Hansen[10]論述了利用關聯數據技術來實現家譜數據全球共建共享的可行性和方法,其中提到了基于關聯數據技術的一個家譜數據集John Goodwin’s Family Tree[11],該數據集已在最大的關聯數據集注冊中心thedatahub.org注冊。
1.2 現有的家譜元數據方案和家譜本體
在資源組織上,圖書館習慣于將家譜作為一種歷史文獻資源來保存和處理,主要集中在對家譜文獻的整理和元數據著錄上,過去大多利用圖書館編目系統著錄,采用MARC數據格式。近年開始采用DC元數據標準來為家譜資源設計元數據方案,尤其是在我國,如科技部科技基礎性工作專項資金重大項目——我國數字圖書館標準與規范建設的家譜元數據規范子項目的成果:張秋芳等人的《家譜描述元數據規范》[12];國家數字圖書館工程標準規范項目的成果:趙亮等人的《國家圖書館家譜元數據規范與著錄規則》[13],上海圖書館參與了這兩個項目。在這兩個項目的元數據方案中,元數據元素大都包括題名、卷數、修撰者(著者)、版本、譜籍地、堂號、始祖、始遷祖、收藏地、提要等信息。2000年由上海圖書館牽頭,猶他家譜研究學會以及我國臺灣、香港的家譜收藏機構參與整理的《中國家譜總目》[14]是迄今為止收錄我國家譜最多、著錄內容最為豐富的一部專題性聯合目錄,基本采用上述元數據元素。
近年逐漸出現基于知識本體的解決方案,國外有多篇文獻記載家譜本體的設計。2005年荷蘭一家為圖書館、檔案館、博物館提供咨詢服務的公司Ivo Zandhuis[15]論述了家譜本體的設計,定義了一套術語詞表,以RDF/XML格式在Web上發布。美國楊百翰大學(BYU)的Charla Woodbury和David W.Embley在探索中記載了設計的家譜本體和基于本體進行邏輯推理和知識挖掘,處理同一人多名的方法[16]。Josh Hansen闡述了基于關聯數據技術的家譜本體設計思路,發布了一個家譜本體術語詞表(http://purl.org/gen/0.1#)。在我國,上海交通大學的陳艷以上海圖書館的家譜為例論述了中國家譜本體的構建方法、過程和結果[17],武漢大學的董慧等在2008年IEEE大會上介紹了基于本體的家譜知識建模方法[18],遺憾的是沒有公開發布家譜本體術語詞表。
與家譜信息中包含多種實體相關的知識本體有用于人和機構的本體FOAF[19]、關于人與人之間關系的本體Relationship[20]、地理本體GeoNames Ontology[21]、時間本體TimeOntology[22]、事 件 本 體Event[23],Albert Mero?o-Pe?uela對上述本體作了調研[9]。這些本體為解決家譜中的具體問題提供了建模方法上的參考,且其詞表以RDF/XML格式發布,其中的術語可被方便地重用在家譜的本地應用系統。在圖書館中,家譜作為文獻的特征仍然需要得到充分揭示,相關的本體有歐洲數字圖書館數據模型(EDM)[24]、OCLC的Schema.org書目擴展SchemaBibEX[25],以及美國國會圖書館的書目框架,與前二者相比,書目框架明確以替代MARC為目的,不僅僅是一種書目格式,而是一個從模型到詞表、到實現技術的系統性框架。書目框架能兼容RDA、FRBR等已有的標準,也支持與SchemaBibEX甚至檔案界VRA模型的互操作,既能夠深度描述資源的文獻特征,也能描述人、地、時、事等內容特征,雖然尚有諸多細節有待討論,但仍被寄予厚望。
2 上海圖書館家譜本體模型和術語詞表的設計
目前的家譜信息系統大致可以分為兩類:一是以家譜文獻為主要管理對象,二是以家族世襲人物關系及其相關事跡記載為主要對象。當然,這兩類信息系統經常無法截然分開,前者必然會涉及家譜對內容的描述,比如始祖、始遷祖、宗族名人、遷徙地;而后者也離不開家譜文獻,也是通過對家譜記載或修譜時描述而進行記錄。
上海圖書館已有的家譜系統以家譜文獻為管理對象,采用對文獻進行著錄的一整套元數據元素集,以MARC為數據格式,可通過題名、姓氏、居地、堂號、著者、名人、叢書、索取號等與家譜文獻相關的字段進行檢索,在家譜閱覽室可以查看掃描的影像文件。這種僅僅以文獻方式建立的信息系統在很多時候無法滿足用戶的查檢需求,最大的問題是缺乏規范控制,對于姓氏、年代、人名、地名等所有字段都只能采用關鍵詞(自由詞)匹配而不是概念匹配,缺乏必要的準確性,極大地影響了查全率和查準率,而且缺乏聚類功能、關聯關系的發現等。這些缺陷正好都是目前關聯數據技術的強項,也是上海圖書館要以尚未開發完成的書目框架模型來建立家譜信息本體的主因,希望能夠兼顧家譜文獻管理和內容揭示兩方面需求,使圖書館的信息系統由于應用了語義技術,而能夠為更多的人所利用。
2.1 書目框架的核心模型和本體詞表
本文中所說的知識本體(有時簡稱本體),是專指對領域知識進行抽象,建立一定的概念模型,并使計算機能夠“理解”這個模型的一種形式化知識表達工具。知識本體常常表現為一套體系化的術語詞表及其相互之間關系描述,并以一定的機器語言進行編碼而得到的代碼體系。比如,傳統分類編目工作常用的分類法和主題詞表等,如果以SKOS這種專門的、基于RDFS的編碼規范進行編碼之后,所形成的知識體系就可看成是一種本體。知識本體應包括每一個術語的明確定義及其關系(比如敘詞表種的用、代、屬、分、參之類的關系),術語分為類(Class)和屬性(Property)兩種,類是對同一類實體對象的抽象,屬性是對類的各種特征的抽象,用于表示類與類之間的關系。
書目框架是圖書館領域一個最新的本體模型,它由許多不同的實體類和屬性構成,類和屬性的定義及取值都在書目框架術語詞表(BIBFRAME vocabulary)中規定。書目框架模型[26](見圖1)包含四大類:創造性作品(Work)、實例(Instance)、規范(Authority)、注釋(Annotation),其中與文獻相關的是作品和實例,與內容相關的屬性屬于作品,與格式和載體相關的屬性屬于實例。這與書目記錄的功能需求(FRBR)模型的四大類相比更為簡潔,作品對應FRBR模型中的作品(Work)和內容表達(Expression),實例對應著FRBR模型的載體表現(Manifestation),而FRBR中與館藏復本相關的單件(Item)則作為書目框架的注釋(Annotation)的一個子類。注釋體現了書目框架模型的開放性,在注釋模型中,容納館藏相關的本地信息,可以將各種互聯網資源如書評、評分等信息與書目數據相關聯。FRBR第二組實體人、機構等規范控制相關的數據在書目框架中屬于規范(Authority),規范提供一個輕量級的規范控制層,可利用已有的規范詞表如VIAF、LCSH等,使Web級的規范控制更為有效。基于書目框架模型設計家譜本體,可以將家譜數據中的內容和載體明顯地區分開,并利用書目框架的規范控制方法,實現基于Web的規范控制,利用注釋模型引入更多的開放資源,補充家譜知識庫的不足。
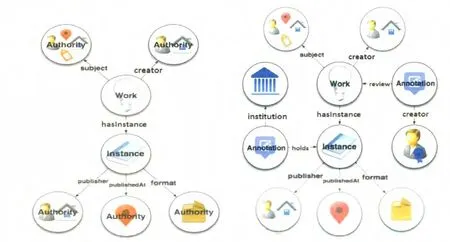
圖1 書目框架的核心模型和注釋模型
到目前為止,書目框架術語詞表共定義了338個術語,除了明確定義核心模型的四大類外,一些與四大類相關的其他資源也被抽象為與這四類同級的資源類,都作為bf:Resource類的子類,比如事件(Event)、關系(Related)、題名項(Title)、標識符(Identifier)、語種項(Language)等,根據關聯數據的原則,這些在MARC記錄中以文本出現的字段值在書目框架中作為資源對象來處理。家譜中的各類數據實體包括文獻相關的類,如題名、責任者、載體項、出版項等,以及可用于家族信息建模的類,如人、家族、機構、地、時、事等均可在書目框架中找到對應的類——bf:Person,Organi zation,bf:Place,bf:Temporal,bf:Family,有豐富的屬性來表達類與類之間的關系。這樣原MARC記錄中作為文本串的數據可以作為資源對象,利用明確定義的屬性來表達對象之間的關聯關系,為數據賦予語義,便于機器處理和跨系統的互操作。該術語詞表已用RDF Schema編碼,提供RDF/XML格式的文件下載。
上海圖書館大量已有家譜數據是MARC格式,而書目框架的目標在于取代MARC,并非拋棄MARC。大量的MARC格式的數據是圖書館的寶貴財產。新的書目格式必須兼容舊格式,使已有數據能夠順暢地轉換為新格式。BIBFRAME的核心數據模型和本體詞表全面考慮了MARC格式的兼容性,且項目組正在開發MARC轉換為BIBFRAME的工具和平臺。基于書目框架來設計家譜本體,在系統實現時可以利用這些工具、平臺,借鑒其方法。
2.2 從家譜元數據到家譜知識本體
上海圖書館現有的家譜數據庫已有一套元數據方案,這決定了數據庫中的元數據記錄的結構。知識本體的設計必須考慮容納現有的數據項,基于現有數據結構來厘清數據之間的關系。知識本體是元數據方案的立體化[27],有哪些元數據元素決定著需要設計哪些類和屬性。元數據方案是平面的,而知識本體則是厘清了元素所描述的類(Class),定義了類與類之間的關系,以屬性(Property)來明確表達這些關系而形成的立體網狀模型[28]。在設計本體時,一個原則是盡可能地復用已有本體的類和屬性,如果已有本體中的類和屬性不足以表達具體應用領域中的數據實體及其關系,就需要自定義新的類和屬性。上海圖書館的家譜本體需建立在上海圖書館的家譜元數據方案之上,表1是上海圖書館家譜元數據元素與書目框架術語詞表中類和屬性的對應。從家譜元數據中可以發現家譜資源與圖書館其他資源相比的共性和特殊性。共性表現在題名項、責任者項、出版項、載體形態項、館藏項等文獻特征,這在書目框架術語詞表中有足夠的類和屬性與之相對應。特殊性表現在和家族相關的屬性如始祖、始遷祖、散居地等,人的屬性如姓、名、字、號、兄弟排行等屬性是家譜甚至是我國家譜所獨有的信息,書目框架的類和屬性不足以描述這些特有屬性,現有的家譜本體以及應用最為廣泛的描述人的本體FOAF也沒有相應的屬性來描述這些特性,因而需要自定義家譜資源專有的類和屬性。在自定義類和屬性時,盡量用繼承的方式繼承書目框架已有的類及其屬性,這樣就能繼承父類中已有的屬性,并保證與書目框架兼容。
家譜中的遷徙信息一般由人(始祖或始遷祖)、地(原居地和遷居地)、時(何時遷往何地)三要素構成,因此被作為事件(bf:Event)來處理。始祖、始遷祖、支祖、房祖、名人等人有所處時代、原居地、遷居地、名、字、號、排行等特性,可以用一個特定的類及其屬性來建模。始祖、始遷祖、支祖、房祖、名人、散居地等屬于某個家族的信息,可用“家族”類來建模。因而自定義了三個類: shlgen:Family(家族);shlgen:Person(人);shlgen:FamilyName(姓氏)。“shlgen”是上海圖書館家譜本體命名空間的前綴,帶有該前綴的類和屬性即為自定義的類和屬性。其中shlgen:Family繼承bf:
Family,shlgen:Person繼承bf:Person,bf是書目框架命名空間的前綴,帶有該前綴的類和屬性即為書目框架所定義。之所以要把姓氏shlgen:FamilyName也定義為一個類,是因為在家譜數據中,姓氏是非常重要的資源,上海圖書館的家譜數據中包括335個姓氏,張、陳、王、李、劉、吳等姓的家譜文獻均在500種以上,而周、朱、徐、黃、楊、胡等姓也達數百種之多,冷僻姓氏有90余種。將姓氏作為資源對象來處理,有利于將關于姓氏的信息,如發源地、地域分布等數據結構化、語義化。
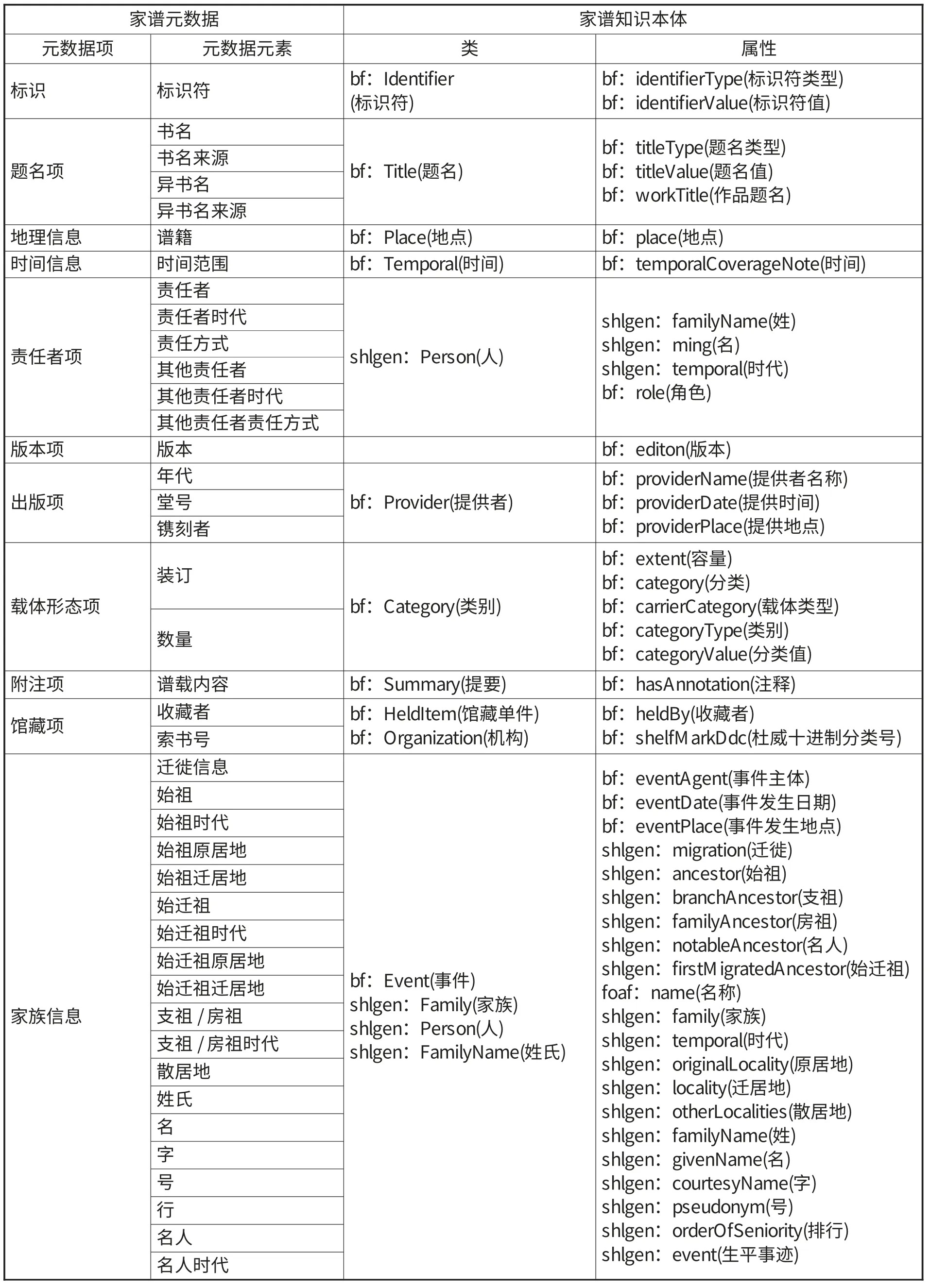
表1 家譜元數據與家譜知識本體的對應關系
書目框架本體對家譜文獻特征描述的類和屬性較為充足,無需作進一步擴展。遵照書目框架的核心數據模型,將家譜分為作品、實例兩個主要部分。家譜元數據中的題名項、責任者項、附注項以及其他與家譜文獻內容有關的人、地、時、事、家族信息等屬性歸于作品,將與文獻載體有關的出版項、載體形態項、版本項歸于實例,而規范與注釋都通過作品和實例各自的屬性所定義的關聯關系與作品和實例相關聯,見圖2。
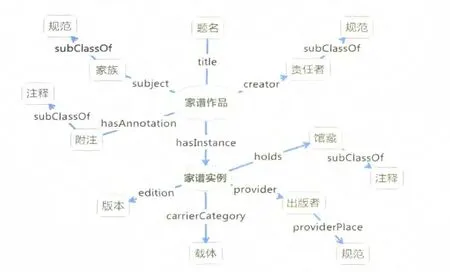
圖2 基于書目框架的家譜本體模型
2.3 家譜實體-關系模型
作品、實例、家族、人之間的實體關系可用實體關系圖來分析。圖3是與作品相關的類和屬性關系圖,圖中圓角矩形表示類,用帶箭頭的有向線條表示屬性,用直角矩形表示文本串(Literal),子類用rdfs:subClassOf表示,類及其屬性的域(Domain)和范圍(Range)可從圖中的有向線條及其起止點看出。比如,代表屬性“bf:creator(責任者)”的有向線條從bf:Work類指向bf:Agent類,那么屬性“bf:creator(責任者)”的域是類“bf:Work(作品)”,表示該屬性是用于描述該類的,其范圍是bf:Agent類,表示該屬性的取值屬于shlgen:Person類,而屬性bf:role(責任方式)的取值是一個文本串(Literal),用直角矩形表示。
自定義的shlgen:Family類和shlgen:Person類是這樣與bf:Work類發生關聯的:作品的主題屬性(bf:subject)的范圍是bf:Authority,而shlgen:Family類繼承了bf:Authority的子類bf:Agent的子類bf:Family(見圖5),所以也繼承了bf:Authority,故可以將shlgen:Family作為作品主題的一種加以揭示。作品的責任者屬性(bf:creator)的范圍是bf:Agent,而shlgen:Person繼 承 了bf:Agent的子類bf:Person(見圖6),因而可以將shlgen:Person作為責任者的一種。
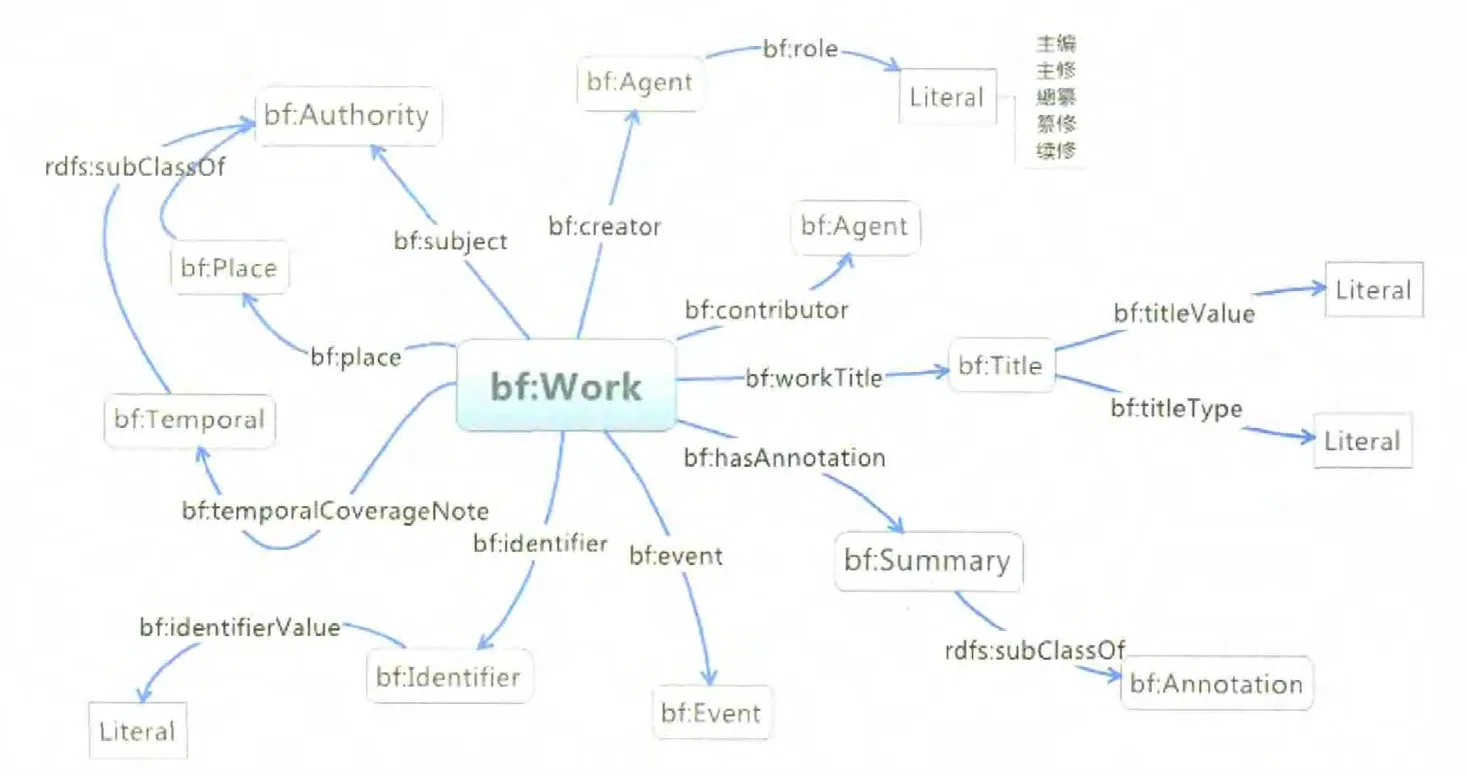
圖3 作品相關的類、屬性及其關系
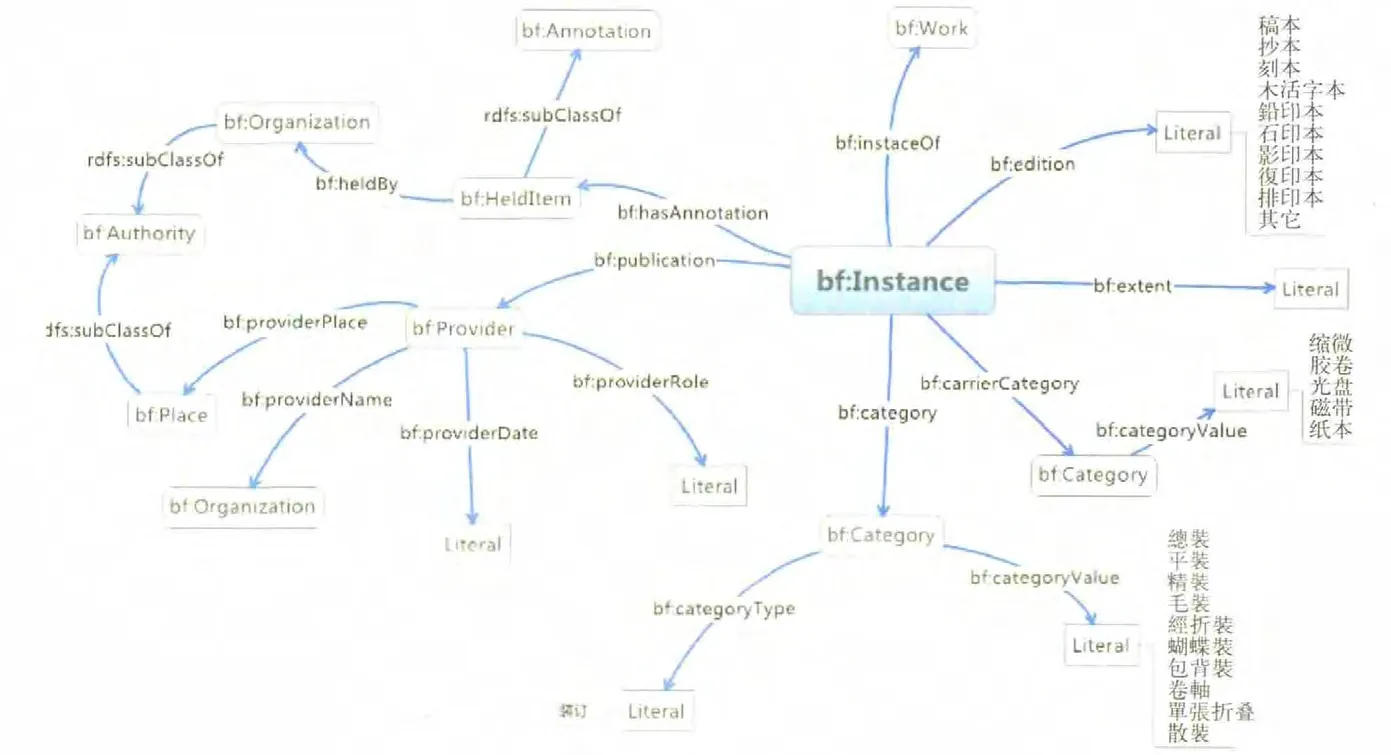
圖4 實例相關的類、屬性及其關系
地點和時間通過屬性bf:place和屬性bf:temporalCoverageNote來與bf:Work發生關聯,這兩個屬性的范圍分別是地點(bf:Place)和時間(bf:Temporal),都是規范(bf:Authority)的子類。圖4中的收藏者屬性(bf:held By)所指向的機構(bf:Organization)和出版地屬性(bf:providerPlace)所指向的地點(bf:Place)也是如此。對注釋(bf:Annotation)來說,作品的附注(bf:Summary)(見圖3)是它的子類,實例的館藏信息(bf:Held Item)(見圖4)是它的子類bf:Held Material的子類。

圖5 上海圖書館家譜本體中家族相關的類、屬性及其關系
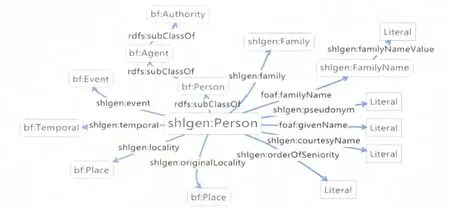
圖6 上海圖書館家譜本體中人相關的類、屬性及其關系
值得注意的是,對責任者和相應的責任者角色的對應處理,在書目框架里有兩種方式:一是bf:creator直接指向責任者實體對象;二是bf:creator的范圍是一個抽象的中間類bf:Related(關系),由“關系”類的屬性bf:related To來指向責任者實體對象,由bf:related Type來表示相應的責任者角色,這里采用第一種方法,最新的BIBFRAME本體詞表中也將bf:creator的范圍定義為bf:Agent類。bf:Agent是bf:Authority的子類,子類可以繼承父類的屬性,因而用從bf:Authority類繼承過來的屬性bf:role來表示責任者的角色,其范圍是一個文本串,取值約束定義為一個列表:主編、主修、總纂、纂修、續修(見圖3)。對取值約束的定義在“實例”的版本(bf:edition)屬性和載體形態屬性(bf:categoryValue)上也有體現(見圖4)。
在書目框架中,很多在元數據記錄中取值范圍為字符串的屬性被作為實體對象來處理,如標識符、題名、版本項、載體項、出版者項。以題名為例,作品的題名屬性bf:w orkTitle的范圍不再是一個文本串,而是bf:Title類,該類的兩個屬性bf:titleType和bf:Value分別定義題名的類型(縮寫、封面、書脊……)和值。對于上海圖書館家譜數據來說,當一個作品有多個書名時,用這種面向對象的方式更易于處理書名類型和值的對應關系。用RDF三元組表示如下:
作品0010012——bf:workTitle——題名1
題名1——bf:titleType——“卷端”
題名1——bf:titleValue——“維揚安阜洲丁氏重修族譜六卷”
作品0010012——bf:workTitle——題名2
題名2——bf:titleType——“版心”
題名2——bf:titleValue——“丁氏族譜”
家族shlgen:Family、人shlgen:Person、姓氏shlgen:FamilyName這三個類及其屬性見圖5和圖6所示。
3 上海圖書館家譜本體的實施、擴展與重用
3.1 基于書目框架應用綱要的家譜本體實施
書目框架是一個試圖兼容MARC、RDA、VRA以及未來可能出現的標準規范的框架,被設計成具有一定的靈活性和可擴展性,因而不能對具體領域的具體應用作出具體的規定。書目框架應用綱要是根據具體需求為領域本體的實施和應用在語法、用法甚至數據格式上作出明確定義的規范文檔,它獨立于書目框架模型和術語詞表,由特定的應用領域自行維護,以適應具體的應用需求。書目框架應用綱要具體表現為一個或多個文件,以一定的格式編寫而成,可被機器處理,是抽象的本體到具體的應用系統之間的橋梁。書目框架應用綱要(BibFrame Profile)規范[29]是如何將BIBFRAME核心模型和本體詞表應用于具體領域的指南性規范,定義了如何為領域應用構造一個應用綱要的規則和語法。應用綱要由“綱要定義(Profile Definition)”和多個“資源模板(Resources Templates)”組成,“綱要定義”聲明了該應用綱要用于哪種,比如“專著”、“信函”等,“資源模板”規定具體應用綱要包含哪些類(如作品、實例、規范、注釋)。一個“資源模板”包含多個“屬性模板(Properties Template)”。屬性模板定義一個類有哪些屬性,各個屬性的域和范圍,以及屬性的數據類型約束和取值約束。“綱要定義”“資源模板”和“屬性模板”都有各自的元素來明確定義,比如“綱要定義”需由identifier(應用綱要的標識符,機讀)、Title(應用綱要的標題,人讀)、Description(應用綱要的描述)、Resource Templates(應用綱要所包含的資源模板)等元素來描述。
基于書目框架設計的家譜本體即是一個領域本體,如何在系統中得到應用和實施可以用書目框架應用綱要來定義。應用綱要由標準的編碼語言編寫,可被機器處理。系統讀取應用綱要定義的規則自動生成基于家譜本體的對象數據。家譜的書目框架應用綱要以JSON格式來定義,限于篇幅,這里只截取“綱要定義”、一個“資源模板”和兩個“屬性模板”的定義代碼。“資源模板”以shlgen:Person為例,“屬性模板”以shlgen:family和shlgen:given-Name為例。第一個屬性的范圍是shgen:Family類,第二個屬性的范圍是Literal,其中“"type":"resource",”這 行 代 碼 表 示 屬 性shlgen:family的范圍是另一個資源對象,“"valueTemplateRefs":["bfp:Family",]”指明是哪種資源對象,"bfp:Family"指的是另一個資源模板的ID,這個資源模板所定義的類(shlgen:Family)是屬性shlgen:family的范圍。代碼如下:


3.2 家譜本體的擴展
上述家譜本體中類和屬性主要基于目前上海圖書館家譜數據的現狀來設計,能夠容納現有家譜數據中的數據項。隨著標引方法和技術的進步,如基于圖像的標引技術,家譜數據中更多的數據項將在未來的標引工作中提取出來,比如家譜的世系圖錄包含家族中詳細的成員名單和他們之間的親屬關系。目前上海圖書館的家譜世系圖錄只是掃描后作為圖片存儲,沒有對圖中的文字進行OCR識別,這部分內容是家譜資源中寶貴的財富,如果將來做更細粒度的標引,那么目前的本體就不夠用,需要進一步擴展。一般來說,本體的擴展有復用已有本體和自定義本體兩種做法,本文設計的家譜本體在模型和框架層面能夠支持這兩種做法。以世系圖錄為例,可以采用復用已有本體的辦法。比如要復用genOnt來描述人與人之間的關系,可以為shlgen:Person類增加屬于genOnt本體 的 屬 性, 例 如 用 genont: hasFather、genont:hasMather來表示父母子女的關系。如果還不夠用,還可以關系本體(Relationship)的屬性rel:friend Of表示朋友關系,域和范圍均為shlgen:Person。以人的墓志銘為例,目前已有的家譜數據中沒有墓志銘的數據,但將來如果對《中國家譜資料選編》做標引,就需要對墓志銘作出定義。可以采用自定義新的屬性來擴展目前的家譜本體,為shlgen:Person增加一個屬性shlgen:epitaph,其域為shlgen:Person,范圍為文本串(Literal)。至于在本體擴展時究竟采用哪種方法,原則是盡量復用已有的較為成熟和被業界公認的本體,如果沒有可復用的本體才考慮自定義。家譜本體擴展的目的是為數據實體增加相關的描述,使數據間的關系更豐富。由于數據的編碼采用RDF數據模型,因而只需要增加一個或多個三元組,不影響后臺數據的存儲結構。
3.3 家譜本體的重用
知識本體是領域共享的知識,得到更多應用系統的重用才能體現更大的價值。本體的重用需要做好兩方面的準備:一方面要準備供人讀的翔實的說明文檔,對類和屬性的定義要明確,盡量避免在被重用的過程中產生歧義;另一方面要在Web上發布機器可讀的基于標準編碼語言的文檔,一般用RDFs或OWL語言,在文檔中聲明前綴和命名空間,用規范的元素描述類和屬性的定義。書目框架采用了RDFs的9個元素來對其本體詞表編碼,見表2。
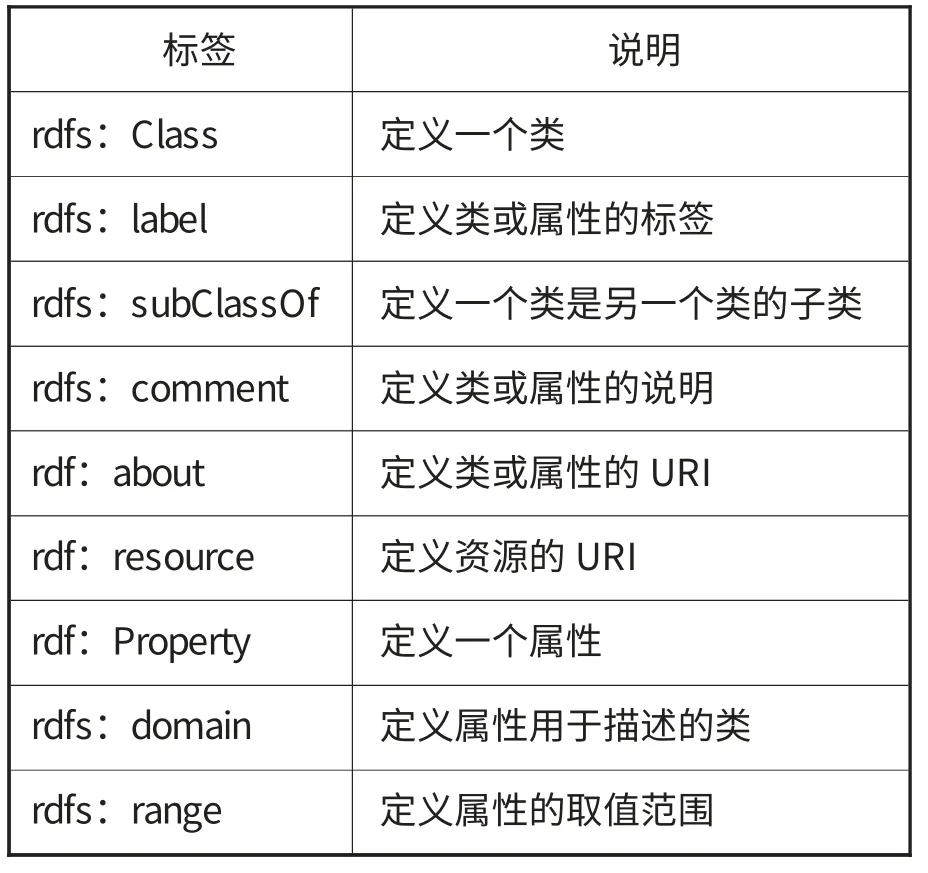
表2 上海圖書館家譜本體的RDFs編碼規則
上海圖書館家譜本體也采用RDFs來定義。以下示例是對bf:Work類和自定義類shlgen:Family的定義,以RDF/XML格式編碼:


4 總結與展望
書目框架作為基于關聯數據技術的本體模型,既能揭示家譜資源的文獻特征,又能揭示其內容特征,并在家譜各種數據實體之間建立能被機器處理和理解的關聯關系。這些措施能有效提高家譜系統的查全率和查準率,提升家譜資源服務的效果。
然而目前書目框架項目尚未結束,其模型仍在發展變化之中,一些細節尚未決定或仍在討論和征求意見的階段,這導致基于書目框架來設計家譜本體存在一定的風險性。因此,在家譜本體的設計過程中,主要以書目框架的核心模型和總體框架為基礎模型框架,盡量避免復用存在爭議或概念尚不明晰的類和屬性,同時考慮架構的靈活性和可擴展性(好在基于關聯數據的模型本身就具有這方面的優勢),以便今后進一步修訂。
家譜本體設計的難點在于對人、地、時、事之間復雜關系的處理,尤其是家譜數據中對時間和地點的描述:不同時間同一地點的名稱不一致、不同地點重名、同一地點在不同的時間范圍內屬于不同的行政區域劃分、同一時間使用不同的紀年方式、時間范圍的起止定位等問題為數據的清洗和實體對象的提取帶來了困難。處理這些問題,需要引入已有的外部本體和規范詞表,比如事件本體(Event Ontology)、時間本體(Time Ontology)、關系本體(Relationship Ontology),以及即將以關聯數據發布的Getty的地理名詞敘詞表[30]等,來處理人、地、時、事之間的復雜關系,以補充現有家譜本體的不足。
下一步的工作是將以RDFs編碼的家譜本體發布成關聯數據,使之在Web上可訪問可獲取,可被其他本體復用,并提供數據消費接口(如SPARQL端點)等,以達到方便地共享和重用的目的。同時,基于書目框架應用綱要開發應用系統,生成包含豐富關聯的家譜對象數據,在這個過程中進一步檢測家譜本體的健壯性和可靠性。
在我國,關聯數據的介紹和試驗已經有四五年,然而到目前為止,較大規模的實際應用還付之闕如。國外圖書館界最常見的關聯數據應用是將國家書目庫發布成關聯數據,通常只有國家圖書館的數據才具有足夠的規范性和權威性。選擇家譜資源進行嘗試,并采用書目框架作為本體模型,主要是基于上海圖書館家譜文獻在質和量等方面于業界具有舉足輕重的地位;同時,家譜資源無論多么特殊,都是上海圖書館館藏文獻的一部分,它需要遵從圖書館信息系統功能需求的一般性原則。
以關聯數據為代表的語義技術對圖書情報領域有著極為特殊的意義。上海圖書館正努力把該項目做成關聯數據應用的一個示范性項目,希望能以此帶動數字圖書館的資源揭示從基于文獻向基于內容進行升級,為打造數字人文服務和研究平臺進行具有突破意義的探索和嘗試。
[1] 劉煒,夏翠娟. 書目數據新格式BIBFRAME 及其應用[J]. 大學圖書館學報,2014 (5):5-13.
[2] Tim Berners-Lee. Linked Data [EB/OL]. [2011-05-15]. http://www.w3.org/DesignIssues /LinkedData.html.
[3] 劉煒. 關聯數據:概念、技術及應用展望[J]. 大學圖書館學報,2011 (2):5-12.
[4] 王昭. 家譜文獻資源整理現狀與思考[J]. 中國科技信息,2013 (5):62-66.
[5] 毛建軍. 中國家譜數字化資源的開發與建設[J]. 檔案與建設,2007 (1):22-24.
[6] Campanya Artes Joan. The Family History Department of The Church of Jesus Christ of Latter-day Saints(LDS Church) . The GEDCOM Standard Release 5.5 Introduction[EB/OL]. [2014-05-11]. http://homepages.rootsweb.ancestry.com/~pmcbride/gedcom/55gcint.htm#S1.
[7] GENTECH Genealogical Data Model: A Comprehensive Data Modelfor Genealogical Research and Analysis (version 1.1) [EB/OL].(2000-05-29)[2014-07-03]. https://www.ngsgenealogy.org/ngsgentech/projects/Gdm/Gdm.htm.
[8] Jay Askren. The Semantic Web for Family History[EB/OL]. [2014-05-16]. http://jay.askren.net/Projects/SemWeb/
[9] Albert Mero?o-Pe?uela. Semantic Technologies for Historical Research: A Survey[EB/OL] .[2014-07-15].http://www.semantic-web-journal.net/system/files/swj588.pdf.
[10] Josh Hansen. The Coming Web of Genealogical Data[EB/OL]. [2014-05-12]. http: //fht.byu.edu/prev_workshops/workshop12/papers/3.1%20Josh%20Hansen% 20-% 20FHT% 202012% 20Workshop% 20Paper%20-%20The%20Coming%20Web%20of%20Genealogical%20Data.pdf.
[11] John Goodwin .John Goodwin’s Family Tree[EB/OL].[2014-07-08]. http://datahub.io/dataset/john-goodwinsfamily-tree.
[12] 周秋芳,顧燕,陳建華,等. 我國數字圖書館標準規范建設:家譜描述元數據規范[EB/OL].[2014-05-08].http://www.docin.com/p-9321300.html.
[13] 趙亮,蘇品紅.國家數字圖書館工程標準規范成果:國家圖書館家譜元數據規范與著錄規則[M].北京:國家圖書館出版社,2014:10-40.
[14] 上海圖書館. 中國家譜總目[M]. 上海:上海古籍出版社,2008:10-12.
[15] Ivo Zandhuis. Towards a Genealogical Ontology for the Semantic Web [EB/OL]. [2014-06-09]. http://www.zandhuis.nl/sw/genealogy/.
[16] Charla Woodbury,David W. Embley. Family History Research on the Semantic Web:Building a Semantic Prototype for Danish Research[EB/OL].[2014-07-28].http://fht.byu.edu/prev_workshops/workshop05/FHTCD/session1/s1-CharlaWoodbury_SemanticWeb.pdf.
[17] 陳艷.中國家譜的知識本體構建[D]. 上海:上海交通大學,2007.
[18] Ying Jiang, Hui Dong. Ontology Based Knowledge Modeling of Chinese Genealogical Record[C]//Semantic Computing and Systems, 2008. WSCS '08. IEEE International Workshop:33-34.
[19] Dan Brickley,Libby MillerFOAF Vocabulary Specification 0.99 [EB/OL]. [2014-07-04]. http: //xmlns.com/foaf/spec/.
[20] Ian Davis, Eric Vitiello Jr. RELATIONSHIP: A vocabulary for describing relationships between people[EB/OL]. [2014-07-05]. http://vocab.org/relationship/.html.
[21] GeoNames Team. GeoNames Ontology [EB/OL].[2014-07-05]. http://www.geonames.org/ontology/documentation.html.
[22] Jerry R. Hobbs, Feng Pan. Time Ontology in OWL[EB/OL]. (2006-09-27)[2014-07-05]. http://www.w3.org/TR/owl-time/.
[23] Yves Raimond, Samer Abdallah The Event Ontology[EB/OL].[2014-07-09]. http://motools.sourceforge.net/event/event.html.
[24] PeroniSilvio,TomasiFrancesca,VitaliFabio. Reflecting on the Europeana Data Model[M]. Digital Libraries& Archives,2013:228-240.
[25] Ted Fons, Jeff Penka, Richard Wallis. OCLC’s Linked Data Initiative:Using Schema.org to Make Library Data Relevant On The Web[EB/OL].[2014-06-12]. http://www.niso.org/apps/group_public/download.php/9408/IP_Fons-etal_OCLC_isqv24no2-3.pdf.
[26] Library of Congress. Bibliographic Framework as a Web of Data:Linked Data Model and Supporting Services[EB/OL]. (2012-11-21)[2013-09-12]. http://www.loc.gov/bibframe/pdf/marcld-report-11-21-2012.pdf.
[27] 劉煒,李大玲,夏翠娟. 元數據與知識本體[J]. 圖書館雜志,2004 (6):50:54.
[28] 葉鷹,金更達.基于元數據的信息組織與基于本體論的知識組織[J].中國圖書館學報,2004(4):43-47.
[29] Library of Congress. BIBFRAME Profiles: Introduction and Specification [EB/OL]. [2014-06-18].http://www.loc.gov/bibframe/docs/bibframe-profiles.html.
[30] The J. Paul Getty Trust. Getty Thesaurus of Geographic Names Online[EB/OL]. [2014-07-18]. http:// www.getty.edu/research/tools/vocabularies/tgn/index.html.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
海峽姐妹(2020年9期)2021-01-04 01:35:44
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
山東青年(2016年1期)2016-02-28 14:25:25
核科學與工程(2015年4期)2015-09-26 11:59:03
當代修辭學(2014年3期)2014-01-21 02:30:44
公務員文萃(2013年5期)2013-03-11 16:08:37
