一種面向高校圖書館的個性化圖書推薦系統
2015-01-06 06:31:34王連喜
現代情報 2015年12期
關鍵詞:高校圖書館
王連喜
(廣東外語外貿大學圖書館,廣東廣州510420)
一種面向高校圖書館的個性化圖書推薦系統
王連喜
(廣東外語外貿大學圖書館,廣東廣州510420)
〔摘要〕個性化圖書推薦主要是以用戶特征和借閱行為為挖掘對象,通過獲取用戶的興趣特征及隱含的需求模式,實現用戶與圖書相互關聯的個性化圖書推薦服務。本文通過挖掘用戶的背景信息構建用戶特征模型,然后在設計喜好值計算、用戶相似度計算和內容相似度計算以及標簽信息獲取方法的基礎上,研究多種不同的圖書推薦方法,以挖掘用戶的潛在信息需求。最后利用圖書館的真實數據設計面向高校圖書館的個性化圖書推薦系統,同時以標準網絡數據集通過實驗驗證來評估推薦方法的有效性。
〔關鍵詞〕高校圖書館;推薦系統;個性化需求;圖書推薦
隨著網絡技術與社交媒體的發展和普及,人們逐漸從信息匱乏的狀態陷入了信息過載的困境。在這個信息爆炸的環境中,圖書館的信息消費者與信息生產者都在不同程度上出現了新的挑戰:對于用戶而言,如何從大量的館藏資源中找到適合自己的圖書資源是一件非常困難的事情;而對于圖書館從業人員以及電子資源的信息生產者而言,如何讓其所擁有的資源找到合適的用戶也是一件亟待解決問題。個性化推薦系統就是解決上述兩種問題的重要工具。個性化圖書推薦系統的最重要任務就是將用戶興趣和圖書信息關聯起來,一方面幫助用戶發現對自己有價值的圖書資源;另一方面讓圖書資源最大程度地展現在有需求或有潛在需求的用戶面前,從而使用戶和圖書館達到雙贏的狀態[1]。
目前流行的推薦系統大致是以3種方式實現用戶與圖書的關聯。第一種方式是分析用戶的借閱歷史,為用戶推薦與其借閱記錄中相類似的圖書。第二種方式是挖掘用戶的借閱行為,通過建立興趣模型為用戶推薦具有相似借閱行為用戶的借閱信息;第三種是關聯用戶與圖書的特征信息,通過發現用戶與圖書之間的有趣關聯特征或模式并生成關聯規則,從而為用戶推薦其可能感興趣的圖書。從技術層面來看,學者們針對3種關聯方式提出了一些個性化的推薦技術,包括基于內容的個性化推薦、基于用戶的個性化推薦、基于關聯規則的個性化推薦以及混合推薦等[2-4]。雖然目前已經有多種推薦方法被應用到各個領域,但是不同的推薦技術有著不同的特性和不足:(1)基于內容和用戶的推薦方法主要依靠目標特征的關系親密度(興趣度)來進行衡量目標之間的相似度。兩種方法的推薦效果比較顯著,但是容易受到稀疏問題和冷啟動問題的影響[5];(2)基于關聯規則的個性化推薦方法的核心是發現并建立內容與用戶之間實際或潛在的關聯規則[6]。該方法也會受到稀疏性問題和冷啟動問題的影響,而且還需要消耗大量的建模時間,所以算法的復雜性比較高。
隨著辦學規模的擴大和辦學水平的提高,國家對高校的支持力度越來越大,尤其重視高校學子的人均資源擁有量,所以使得當前高校的館藏資源十分豐富,從而導致圖書館的部分圖書的借閱量偏低,甚至出現零借閱現象。由于高校圖書館的服務對象主要是高校教職工和學生,其基本信息相對簡單、容易獲取且比較準確,所以高校的圖書推薦與電子商務領域的個性化推薦有所不同。個性化圖書推薦是以圖書和用戶的特征及行為為挖掘對象,通過分析用戶對圖書的喜好程度、用戶之間的興趣相似度、圖書內容之間的相似的度以及用戶的喜好標簽等信息,研究并設計適合高校圖書館的個性化圖書推薦系統。
1 個性化圖書推薦方法
根據高校圖書館的圖書及其用戶的特點,從用戶背景信息與知識結構識別、用戶對圖書的偏愛、用戶的相似興趣計算、內容相似度計算以及用戶對喜好標簽標注等入手,研究基于用戶的協同過濾推薦、基于內容的協同過濾推薦、基于標簽的推薦以及基于用戶背景信息的圖書推薦。
1.1基于用戶的協同過濾推薦方法
基于用戶的協同過濾推薦方法的主要思路是,首先計算用戶之間的相似度并找到與目標用戶興趣相似的用戶,然后選擇與其最相似的前M個用戶,最后從M個用戶的借閱圖書集合中依據“喜好值”找到用戶喜歡的且目標用戶并沒有借閱過的圖書,并將其推薦給目標用戶。
為了能夠更好的反映出用戶對借閱圖書的偏好程度,通常用喜好值來度量。假設某用戶u所借閱的圖書序列為BOOK={book1,book2,L,bookn},借閱起始時間為TB={TB1,TB2,L,TBn},每本圖書的借閱時間為T={T1,T2,L,Tn},用戶首次借閱圖書的時間為TF,用戶借閱圖書的最短時間Tmin,用戶借閱圖書的最長時間Tmax,當前時間為TC,則用戶u對圖書booki的喜好值衰減率計算方式如下:
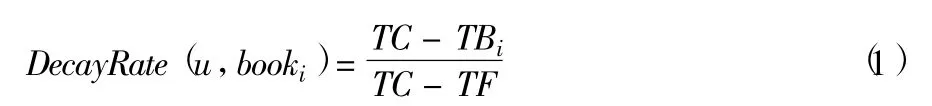
用戶u對圖書booki的喜好值計算方式如下:

基于用戶的協同過濾推薦方法就是在已給定的喜好值計算方法之上,利用修正的余弦相似性公式計算與目標用戶最為相似的Top-N用戶作為與其在借閱興趣上具有較大相似性的最近鄰用戶。任意兩個用戶u1和u2的相似度計算方法如下:

根據用戶的相似性計算可以得出與用戶ui具有近似相同興趣的Top-N用戶,記Top-N用戶集合為SUi。基于用戶的協同過濾推薦方法就是在匯總SUi中每個用戶借閱圖書序列的喜好值的基礎上,根據喜好值總和進行降序排列后得到推薦圖書集合RBi,然后根據用戶ui的圖書借閱集合BBi產生圖書推薦集合FRBi。FRBi的計算如式(4)表示:

1.2基于內容的協同過濾推薦方法
基于內容的協同過濾推薦方法根據用戶對相似圖書的喜好值為用戶進行圖書推薦。該方法首先通過計算圖書之間的相似度,并找到與目標圖書相似的若干最近鄰居,然后綜合圖書相似度和用戶的歷史借閱行為為用戶生成圖書推薦列表。在電子商務領域中,許多基于內容的協同過濾算法都是從內容角度以余弦相似度或皮爾森相關系數等作為相似度計算的依據,本文從圖書館用戶的借閱行為特點及其與圖書的關系特點出發,以用戶對圖書的喜好值作為相似度計算的依據,故而將圖書之間的相似度表示為ri,j:

由式(5)可知,ri,j主要反映是圖書的共現程度。在得到兩本圖書之間的相似度之后,根據用戶的歷史借閱記錄,查找與用戶所借閱過的圖書最相似的Top-N本圖書向用戶進行推薦。
1.3基于標簽的圖書推薦方法
標簽是一種無層次化結構的、用以描述信息的關鍵字。在社交網絡平臺上,用戶可以根據自己的喜好為自己或物品打上合適的標簽(用戶的顯式標簽),系統就會根據用戶的標簽為用戶推薦好友或其他事物。對于圖書網站而言,系統會將用戶對圖書所標注的標簽作為用戶的喜好標簽(用戶的隱式標簽),并根據此標簽為用戶推薦圖書。但是對于圖書館來說,大部分圖書都沒有被用戶標注標簽,所以需要通過外部數據獲取圖書的隱式標簽。基于標簽的推薦方法主要是在獲取用戶的隱式標簽的基礎上,借鑒TFIDF方法計算用戶對圖書的喜好程度(如式(6)所示),選取喜好值高且目標用戶沒有借閱過的Top-N圖書向目標用戶推薦。
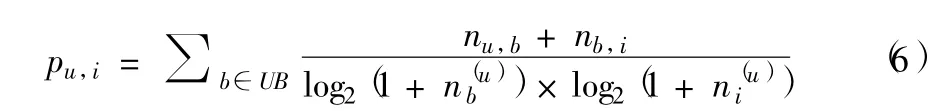
在公式(6)中,UB表示用戶u的隱式標簽集合,nu,b表示用戶u使用標簽b的次數,nb,i表示圖書i被標注為標簽b的次數,nb表示使用標簽b的用戶數量,ni表示圖書i被標注的用戶數量。
1.4基于用戶背景信息的圖書推薦方法
高校用戶由于背景信息的不同,用戶對圖書的借閱偏好也可能會不一樣。一般來說,相同或相近專業的用戶,其借閱的圖書類型會比較類似,而且可能更多地是偏向與專業相關的圖書。基于用戶背景信息的圖書推薦方法的基本思路是先獲取相似背景信息的所有用戶的借閱記錄,然后計算用戶對圖書的喜好值總和,并根據喜好值總和進行排序,選取喜好值總和最大的且沒有被目標用戶借閱過的圖書向目標讀者進行推薦。
2 推薦方法評估
由于當前圖書館的數據基本上沒有被規范處理過,也沒有被評測過,所以不能利用標準的數據集來評估推薦方法的效果。為了方便測試,采用來自互聯網上的MovieLens數據集和CiteULike數據集對推薦方法進行測試與評估。
MovieLens是GroupLens項目組開發的一個基于Web的研究型推薦系統,用于接收用戶對電影的評分并提供相應的電影推薦列表。該數據集中包含了943個用戶對1 682部電影的100 000條評分數據,其中每個用戶至少對20部電影進行了評分。
CiteULike數據集包含了網站從2004年11月-2010年3月所有的用戶操作數據,每條數據都包括文章號、用戶名(MD5值)、收藏時間、收藏時用的標簽等4個字段(如表1所示)。若用戶在標注一篇文章時使用了多個標簽,則這些標簽分別存入多條數據中,如表1中的前3行。
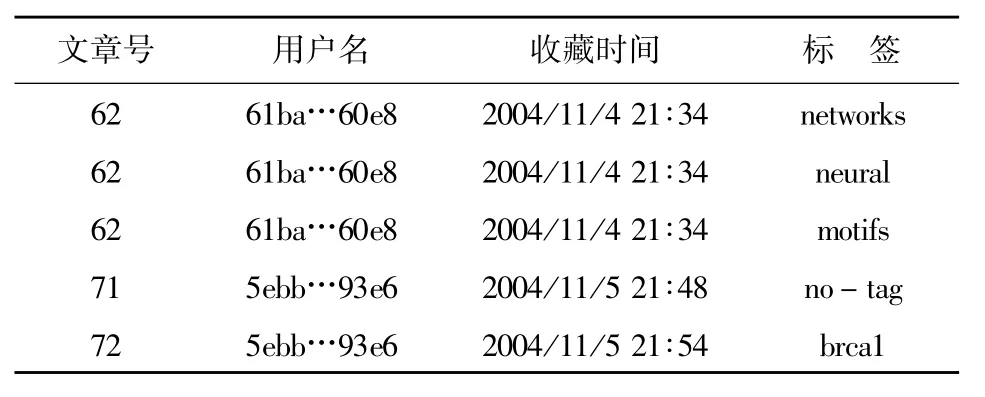
表1 CiteULike 數據(部分)
由兩個數據集的具體描述可知,MovieLens數據集可用于測試基于用戶的協同過濾推薦方法和基于內容的協同過濾推薦方法,CiteULike數據集可用于測試基于標簽的推薦方法。在實驗測試過程中,采用五折交叉驗證方式對3種推薦算法進行測試,評估指標包括準確度、召回率、覆蓋率及平均熱門程度。
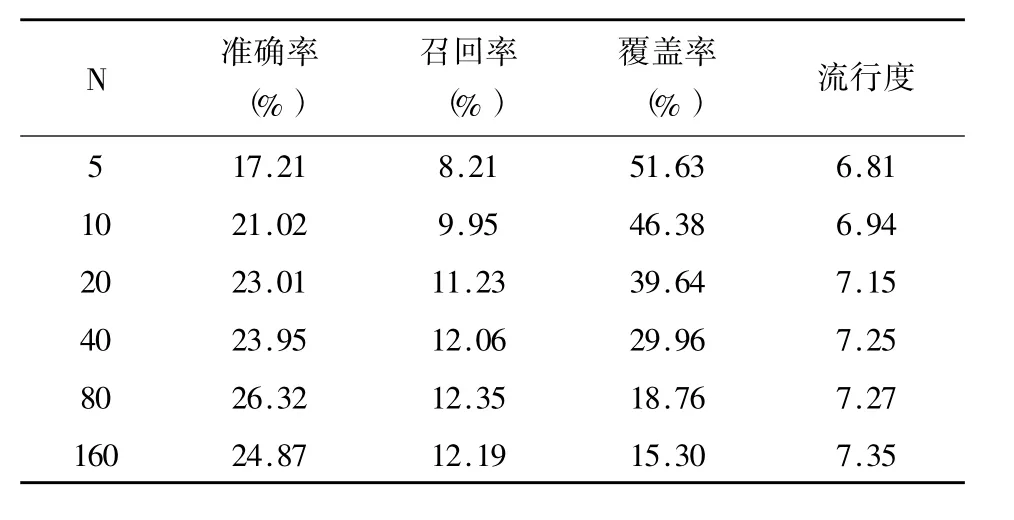
表2 基于用戶的協同過濾推薦方法測試結果
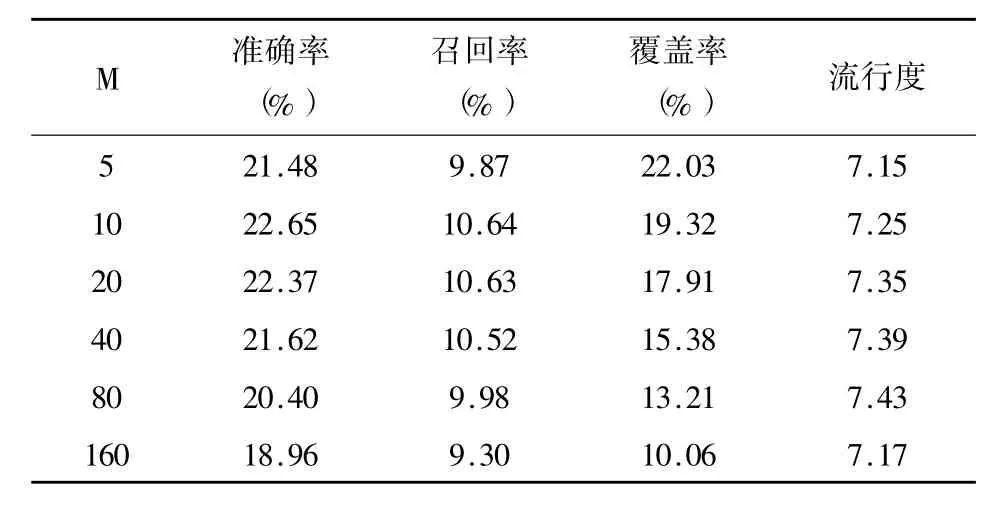
表3 基于內容的協同過濾推薦方法測試結果
表2和表3分別給出了基于用戶的協同過濾推薦方法和基于物品的協同過濾推薦方法測試結果。在兩個表中,N和M分別為每個用戶選出相似用戶的數量和為每本圖書推薦的圖書數量。從表2可以看出,N值只與流行度指標成正相關。當N取80時,基于用戶的協同過濾推薦方法達到較為理想的效果。從表3的結果可以看出,M值與準確度、召回率、流行度既不成正相關,也不成負相關,但是與覆蓋率成負相關。當M取10時,基于內容的協同推薦方法的各項指標達到最佳。
從表4給出的基于標簽的推薦方法測試結果可以看出,該方法也可以得到較好的效果。

表4 基于標簽的推薦方法測試結果
3 實驗與系統設計
3.1數據來源
以廣東某高校圖書館所提供的2010年4月至5月的39 544條借閱記錄(讀者ID,ISBN、借閱時間、實際歸還時間等)以及437 623本圖書的信息(書名、作者、出版社、出版年、ISBN、單價、索書號等)作為實驗數據。經初步統計發現,實驗數據中有借閱行為的用戶有1 978人,詳細的用戶借閱情況及圖書被借閱情況分別如圖1和圖2所示。

圖1 讀者借閱書籍情況
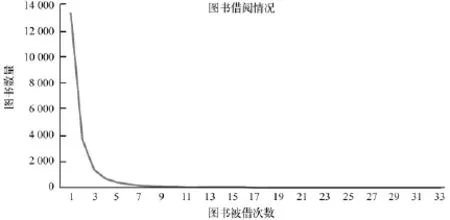
圖2 圖書被借閱情況
由圖1和圖2所示,該圖書館中借閱頻次較高的圖書數量呈遞減趨勢,而且有大部分圖書沒有被借閱過。
3.2數據預處理
由于原始數據中有許多臟數據,不方便用戶理解和建模。為了增強數據的可理解性和降低系統的時間開銷,有必要對實驗數據進行清理和預處理使其能夠滿足推薦方法的數據要求,并提高其效率和性能。由于基于用戶和內容的協同過濾推薦方法以及基于用戶背景信息的推薦方法都是重點分析用戶和圖書的基本特征與行為特征,而基于標注的推薦算法則重點挖掘圖書的內容信息、書評信息、購買信息以及標簽記錄等。為此,我們手動編寫爬蟲算法從豆瓣讀書網上全自動抓取了實驗數據中20 574本圖書的內容信息、20 055條書評信息、57 643條圖書購買信息及89 632條圖書標簽記錄。
與此同時,由于該實驗數據所提供的特征信息比較復雜,所以在實現推薦算法之前需對數據進行預處理,包括提取用戶借閱信息和獲取用戶的隱式標簽(如表5和表6所示)。在獲取用戶的隱式標簽時主要基于以下假設:用戶只對其感興趣的圖書打標簽,所以其預處理過程即獲取用戶使用過的標簽及使用的次數。
3.3系統邏輯結構設計
本系統使用PHP與MYSQL實現。在PHP的應用方面采用MVC設計模式,其目的是更好地實現系統的功能。MVC設計模式將系統分為3層:Model層實現系統中的業務邏輯;View層用于與用戶的交互;Controller層是Model與View之間溝通的橋梁,它可以響應用戶的請求并選擇恰當的視圖以用于顯示,同時它也可以理解用戶的輸入并將它們映射為模型層可執行的操作。

表5 用戶借閱信息表

表6 用戶標簽表
在功能設計方面,本系統主要包括圖書模塊、用戶模塊、搜索模塊和推薦模塊4個部分。圖書模塊主要負責完成與圖書相關的業務邏輯,需要從各個與圖書相關的表中通過模型的操作來提取信息,并將信息提交給控制器,然后在由控制器補充必要的信息之后再傳遞數據給視圖,最后再將信息展示給用戶。
用戶模塊主要負責完成與用戶相關的業務邏輯,包括用戶的登陸、關注、查看粉絲、查看書評、查看其它用戶的信息以及個人信息管理等功能。用戶模塊是一個非常核心的模塊。
搜索模塊主要負責完成與搜索相關的業務邏輯,主要包括圖書搜索、用戶搜索及其結果排序和搜索關鍵詞的優化。
推薦模塊負責從數據庫的推薦表中提取推薦的信息進行組織和排序,并按照不同的要求將數據傳遞給控制器。
3.4系統實現關鍵技術
本系統主要實現基于用戶的協同過濾推薦算法(User -Based Collaborative Filter Algorithm)、基于內容的協同過濾推薦算法(Item-Based Collaborative Filter Algorithm)、基于標簽的推薦算法(Tag-Based Recommend Algorithm)、基于用戶背景信息的推薦算法(Major Feature-Based Recommend Algorithm)。根據前面描述的推薦算法過程可知,本系統主要在實現用戶對圖書的喜好值計算、用戶相似度計算和圖書相似度計算的基礎上產生推薦結果列表。表7~表9分別是基于內容的協同過濾推薦、基于用戶的協同過濾推薦和基于標簽的推薦算法的主要數據庫表設計。

表7 基于內容的協同過濾推薦表

表8 基于用戶的協同過濾推薦表

表9 基于標簽的推薦表
3.5系統效果展示
本系統自用戶登陸開始,從目標搜索到圖書查看的過程中都會產生推薦結果。具體來說,在用戶通過身份識別登陸后,系統根據用戶的專業、年級、學習身份等背景信息以及用戶的隱式標簽和相似用戶等信息通過基于用戶的協同過濾推薦方法、基于用戶背景信息的推薦方法和基于標簽的推薦方法產生推薦結果(如圖3和圖4所示)。
圖3 登陸后推薦頁面(上)

圖4 登陸后推薦頁面(下)
如果登陸用戶在搜索框內通過目標關鍵詞進行檢索后(如圖5所示),并在得到的返回結果中查看任何一本圖書的信息(如圖6所示),系統將會通過基于內容的協同過濾推薦方法在頁面下方產生相應的推薦結果(如圖7所示)。
圖5 搜索結果返回頁面(部分)
圖6 圖書詳細信息頁面(基本信息及購買信息)

圖7 圖書的詳細信息頁面(基于內容的協同過濾推薦)
4 結論
本文首先介紹當前圖書推薦系統的基本情況及其各自的特性的不足,然后對喜好值計算、相似度計算以及四種推薦方法的思路及原理進行詳細闡述,最后構建系統實現面向高校圖書館的個性化圖書推薦系統。
當然,本系統還有很大的完善空間,例如:可以改進基于標簽的推薦算法以提高推薦的效率;實現基于圖的推薦算法、如Random Walk等,使本系統的推薦方式實現多樣化。
參考文獻
[1]Hwang S Y,Lim E P.A data mining approach to new library book recommendations[J].Digital Libraries:People,Knowledge,and Technology,2002:229-240.
[2]丁雪.基于數據挖掘的圖書智能推薦系統研究[J].情報理論與實踐,2010,(5):107-110.
[3]安德智,劉光明,章恒.基于協同過濾的圖書推薦模型[J].圖書情報工作,2011,55(1):35-38.
[4]邵志峰,李榮陸,胡運發.基于中圖分類法的用戶興趣模型研究[J].計算機應用與軟件,2007,(8):85-87.
[5]羅喜軍,王韜丞,杜小勇,等.基于類別的推薦——一種解決協同推薦中冷啟動問題的方法[J].計算機研究與發展,2007,(3).
[6]蘇玉召,趙妍.個性化關鍵技術研究綜述[J].圖書與情報,2011,137(1):59-65.
(本文責任編輯:孫國雷)
Personalized Books Recommender System for University Library
Wang Lianxi
(Library,Guangdong University of Foreign Studies,Guangzhou 510420,China)
〔Abstract〕Personalized books recommend methods are worked by getting the user's interest features and implicit demand patterns,so as to mining users'borrowing behaviors and achieving the personalized book recommendation service by associating the user and the books.This paper built a profile of the user model with the background information,and then designed the methods of user preference,user similarity and content similarity,as well as the acquisition of label information,to tap the latent user information demand.Finally,a personalized book recommendation system for Univerity library was developed,and the experimental results with the standard network data sets showed that the proposed recommend methods are effective.
〔Key words〕university library;recommend system;personalized demand;books recommender
作者簡介:王連喜(1985-),男,館員,碩士,研究方向:數據挖掘與自然語言處理,發表論文20余篇。
基金項目:教育部人文社會科學研究青年項目“微博熱點事件發現及其內容自動摘要研究”(項目編號:14YJC870021)、廣東省科技計劃項目“廣東省企業競爭情報信息提取及態勢推理機制研究——以汽車行業為例”(項目編號:2015A030401093)、廣東外語外貿大學校級教學研究項目“英語學習平臺的個性化資源推薦研究”(項目編號:GWJYQN14010)的研究成果。
收稿日期:2015-10-15
〔中圖分類號〕G252.62
〔文獻標識碼〕B
〔文章編號〕1008-0821(2015)12-0041-06
DOI:10.3969/j.issn.1008-0821.2015.12.007
猜你喜歡
現代經濟信息(2016年19期)2016-10-20 16:13:56
出版廣角(2016年15期)2016-10-18 00:19:57
科技視界(2016年21期)2016-10-17 19:32:37
科技視界(2016年21期)2016-10-17 19:25:20
商(2016年27期)2016-10-17 06:39:10
商(2016年27期)2016-10-17 06:38:27
商(2016年27期)2016-10-17 06:30:59
科學與財富(2016年28期)2016-10-14 23:43:29
科學與財富(2016年28期)2016-10-14 00:28:44
科技視界(2016年20期)2016-09-29 13:17:57
