基于時間序列方法適配建模分析的衛生支出預測實證研究*
2015-03-09 11:13:14李望晨王春平張利平
中國衛生統計 2015年2期
關鍵詞:模型
李望晨王春平張利平△
基于時間序列方法適配建模分析的衛生支出預測實證研究*
李望晨1,2,3王春平1,2,3張利平1,2,3△
目的探討幾種代表時間序列預測建模原理和適配性能,根據算例分別建立程序和綜合比較。方法衛生支出預測算例以ARIMA、GM、SVM和曲線擬合法制定方案,借助MATLAB、SAS等軟件實現,討論性能差異和應用價值。結果ARIMA法通用性好、GM法擬合失效、SVM技術設計待完善、曲線擬合法有限制而應作預分析,數據資料特點影響方法適配性能。結論ARIMA法擬合長較多期隨機時序資料有代表意義;GM法適于貧信息小樣本資料建模;SVM泛化性能強但滑動窗多試取、結果對參數敏感;曲線擬合法受數據特點、離群數據和建模數據段等條件限制;各法應對特定問題擇優取舍。
時間序列 適配比較 程序設計 衛生預測 實證研究
時間序列法以擬合歷史資料而慣性延續外推未來,原理性能和信息提取效果受數據量和資料特點限制,而且適于短期預測。當前衛生領域預測問題較代表性統計方法[1-2]包括ARIMA(autoregressive integrated moving average)、GM(grey method)、SVM(support vector machine)和曲線擬合(curve fit)法。但文獻檢索發現多以方法實現為主,有必要進行綜合適配比較研究。
基本原理
1.GM(1,1):根據原始數據序列進行一次累加生成序列該法包括序列累加、建模、識別、檢驗、外推和累減過程。對隨機不規則序列累加生成為規律性序列,建模提取信息擬合和外推,計算殘差序列并作可行性檢驗、殘差檢驗和后驗差檢驗,然后預測應用。
2.SVM:屬于基于結構風險最小化原則的數據挖掘技術,解決樣本容量依賴、維數災難、局部極小點問題,根據樣本集訓練逼近非線性關系,泛化性能優良。根據SVM智能算法原理建立關系模型,進行數據段組成的樣本集訓練后,映射關系f以“黑箱”存儲,可根據新數據段的輸入信息仿真外推和預測應用。
3.曲線擬合法:假定序列隨時間變化類似某種曲線特點,可建立與時序t的回歸曲線y=f(t),應用時還應對曲線類型進行優選。序列預處理后計算增長特征并與曲線理論性質比較:一階差分ut大致線性時取直線;二階差分u(2)t大致線性時選拋物線;lgut特征大致線性時取曲線yt=k+abt;lg(lgyt-lgyt-1)特征大致線性時選曲線yt=kgbt,lg(ut/ytyt-1)特征大致線性時取曲線yt=k/(1+ae-bt)。以特征線性顯著擇優適配相應曲線,常以與時序t相關系數r優選。優選并識別模型參數后,可將時序t代入表達式擬合或外推計算yt。
4.ARIMA:
基本步驟包括定階、識別、檢驗和應用。序列趨勢性時應差分實現平穩化。自相關系數q階截尾則擬合MA(q)模型,偏自相關系數p階截尾則擬合AR(p)模型,兩種相關系數均拖尾則擬合ARIMA(p,q)模型,可根據AIC、SBC信息量選擇最佳模型,經條件最小二乘法識別參數。該法以序列低階差分后的平穩序列建模,提取長期序列變化信息,已成為隨機時間序列經典方法,算法復雜成熟。
實證分析
本文擬借助衛生支出算例進行實證比較和適配論證。以1990-2011年醫療衛生服務支出數據為例,資料來自《中國衛生統計年鑒》,數據平滑變化、規律性強、資料連貫豐富、有趨勢性,早期長時線性增長而近期起伏顯著,見圖1:
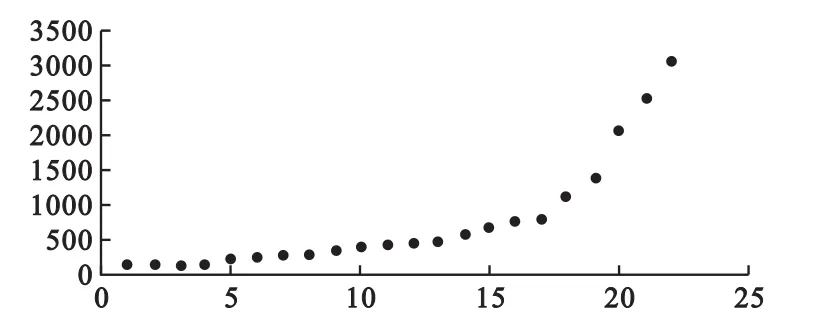
圖1 醫療衛生服務支出時序演化
1.GM(1,1)預測。借助excel或MATLAB軟件計算實現。將1990-2011年數據組成序列{x(0)},累加計算序列{x(1)}和均值序列{z(1)},最后計算參數a=-0.193056,b=-42.2857。得到序列{x(1)}擬合模型依次回代數值k,并累減還原為擬合或預測值擬合與原始序列x(0)不相符,擬合失效。重新以1990年-2000年早期較平緩數據建立擬合模型-956.9024,經比較與原序列擬合尚可以。最后繼續建立模型對少量近期強增長趨勢數據擬合仍不太好。
2.SVM預測。借助Matlab軟件Libsvm工具箱實現。SVM法是通過樣本自組織訓練反映時序延續規律及非線性聯系。通過設置滑動窗將等間隔數據進行組對,順次截取組成訓練樣本和映射關系f:{x(i),x(i+1),x(i+2)}→{x(i+3)},其中輸出為x(i+3),輸入為x(i),x(i+1),x(i+2)。將訓練樣本對分別演示如下:{122.86 132.38 144.77}→{164.81};{132.38 144.77 164.81}→{212.85};…;{1397.23 2081.09 2565.6}→{3111.36}。
訓練完畢經對原始輸入依次測試后得到仿真結果,經驗證比較仿真誤差幾乎為零,說明SVM對訓練集有極強“內插”能力再由輸入{2081.09 2565.6 3111.36}外推預測值773,與實際差距太遠。如果改變滑動窗設置映射f:{x(i),x(i+1)}→{x(i+2)}。重新訓練SVM,經驗證預測值與實際相差仍很大,滑動窗設置改變對結果影響不大。如調試參數重新訓練SVM,結果變化敏感但預測值無法超過3000,與實際不符。原因是原序列訓練后融入早期線性信息,對近期新趨勢的外推不好但符合該方法原理特點。
3.擬合曲線預測。借助excel和SPSS軟件實現。對原序列yt平滑處理后差分計算增長特征發現均與時序t有大致線性變化關系。又計算增長特征與時序t相關系數分別為r1=0.9501,r2=0.749,r3=-0.534。|r1|最大說明修正指數曲線為最優模型。然后用三和法識別參數,去除1990年數據后可將序列(共21個數據)等分為三段,計算參數得預測模型yt=132.5122+36.2046× 1.2417t。令t=21,帶入計算2012年預測值3546.73。重取2003-2011年數據建立模型yt=513.7442+115.2188×1.4994t。令t=9計算2012年預測值4927.22,因近期少量數據突增起伏趨勢,預測值大于實際值,小樣本建模時外推結果受個別數據影響而敏感、不穩定。建模數據段須經調試以保證曲線適配所給該時段特點,該法解釋性好但精度欠佳。
4.ARIMA預測。全步驟借助SAS軟件編程實現。序列經二階差分平穩化預處理消除趨勢,并經過平穩性檢驗和純隨機性檢驗。設置自回歸和移動平均最高階數為5,分別建模后根據AIC、SBC或BIC信息量擇優配置階數,最優定階q=4時信息量最小,AIC=241.34,SBC=245.32。LB,Q或DW統計量用于檢驗擬合效果。經殘差自相關檢驗,延遲6階、12階和18階,P值0.4509,0.9864,0.9998>0.05,經確認原序列信息已提取充分,ARIMA(0,1,4)表達式:(1-B)2xt=1-0.3016B+0.7922B2-0.6868B3+0.11B4。經分析模型擬合效果佳,對2012年外推預測值3556.7,與實際情況相符。
討 論
1.衛生支出時序數據有早期長時平緩、后期起伏遞增趨勢,GM模型累加后無法擬合指數函數,截取近期強趨勢數據后仍不好,對該類特點數據擬合性能不高,有選擇性,尤為適配于數據少、貧信息、欠規則、隨機時序數據特點問題[3]。
2.衛生支出時序數據SVM法建模時,順次截取等數據段后,段前數據為輸入,段后數據為輸出,經反復訓練計算,經外推仿真得預測值。數據有強趨勢性,雖經參數調試優化,外推預測欠佳,該法未有效適配強趨勢數據,預測應用代表意義不應夸大。
3.衛生支出時序數據有平緩光滑曲線增長趨勢,類型多而須借助特征計算優選。鑒于對數據量要求低,不應全納入,否則歷史數據干擾近期信息描述力度,外推效果差。該法對趨勢反映會過度敏感,引起曲線外推值過大,該法適于短期外推。
4.衛生支出時序數據有明顯趨勢,且觀測期較長(數據豐富),可差分提取趨勢信息后平穩序列以ARIMA法建模,算法復雜易實現。簡言之,ARIMA法通用性強且長時數據優先應用,短時數據可選GM法,趨勢數據可選曲線法,時序數據圖預分析和方法性能特點綜合論證后預測建模設計有科學性,探索應用對策有必要。
1.徐國祥.統計預測與決策.上海:上海財經大學出版社,2012.
2.王燕.應用時間序列分析.北京:中國人民大學出版社,2012,12:120-177.
3.周林.GM(1,1)模型預測腸道傳染病發病趨勢的應用.中國衛生統計,2013,30(5):715,718.
(責任編輯:郭海強)
*健康山東重大社會風險預測與治理協同創新中心項目(XT1401001-1401003);山東統計局項目(2014-184);濰坊市科技局項目(201301079)
1.濰坊醫學院公共衛生學院(261053)
2.健康領域社會風險預測治理協同創新中心
3.健康山東重大社會風險與治理協同創新中心
△通信作者:張利平
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
