外部知識管理系統設計與實現
2015-03-16 05:45:34北京航天長征科技信息研究所莊恒東李悅張慶民李焱
航天工業管理 2015年5期
◎北京航天長征科技信息研究所 莊恒東 李悅 張慶民 李焱
外部知識管理系統設計與實現
◎北京航天長征科技信息研究所 莊恒東 李悅 張慶民 李焱

中國運載火箭技術研究院經過2年多的外部知識管理工作實踐,發現傳統的外部知識采集、發布和服務模式既無法實現外部知識管理規劃的目標,又不能全面滿足研究院科研生產對外部知識的強烈需求。基于此,研究院在充分調研、論證的基礎上提出了建設外部知識管理系統,以便為科研生產提供更好的知識服務和情報支撐。
外部知識管理與服務對企業有重要的知識支撐作用,是外部知識管理工作開展的技術基礎。研究院的數字圖書館系統擁有各種專利文獻資料、情報與知識產權專題研究報告、航天特色文獻等資源,然而,外部知識管理與服務的技術手段已從傳統的數字圖書館向知識管理系統延伸,建設符合企業自身專業技術發展特色的外部知識管理系統,已成為滿足技術人員需求,更好地支撐科研生產和技術創新的必由之路。
一、外部知識管理系統現狀分析
1.存在的問題
目前,研究院外部知識管理與服務的方式存在以下問題:各個資源系統之間不具備跨庫檢索功能,應用時需要在系統間切換;專利文獻資源不完整,無法實現深度加工;網絡特色資源無法與自建特色資源有機結合;無法實現情報、知識產權專題研究報告和航天特色文獻資源的發布;由于各個數據源系統相互獨立,在進行知識采集時需要登陸多個系統檢索,并需手工下載目錄和全文,采集手段落后;需通過人工采集和導入建立專題庫,尚無完善的檢索索引功能,檢索效率和準確性比較差;服務方式落后且尚未深入到知識層面。針對外部知識資源的各種服務還停留在資源整合階段,尚未進入外部知識挖掘和服務階段,無法提供深入有效的外部知識支撐。因此,建設研究院外部知識管理系統既有其現實的業務需求,同時在形勢上也是非常緊迫的。
2.系統定位
研究院外部知識管理系統的定位是在對現有數字圖書館實現跨庫檢索的基礎上,按照梳理出的專業技術樹進行元數據(題錄信息)自動采集,形成專業專題庫,立足于提供經過專家甄選和判讀的全面、優質、準確的專業外部知識,為設計師和管理人員提供一鍵式外部知識獲取服務,并在專題庫的基礎上向全院技術人員提供外部知識的深度挖掘和個性化服務。
3.建設目標
研究院外部知識管理系統的總體建設目標是建設面向全院的外部知識管理系統,逐步實現資源的自動化加工、統一檢索、分析與挖掘、深度應用與智能化應用。系統建設分為基礎資源整合和基礎應用構建、資源加工深化、持續應用3個階段。
第一階段建設重點主要包含:自動采集互聯網和涉密內網圖書館電子資源,整合成外部知識資源庫;按照專業技術樹進行數據自動采集和篩選,形成專業知識庫;進行航天領域知識體系和專業敘詞表建設,構建知識檢索、導航及相應的管理應用,滿足全院對外部知識和數字資源的個性化應用需求。
二、總體設計
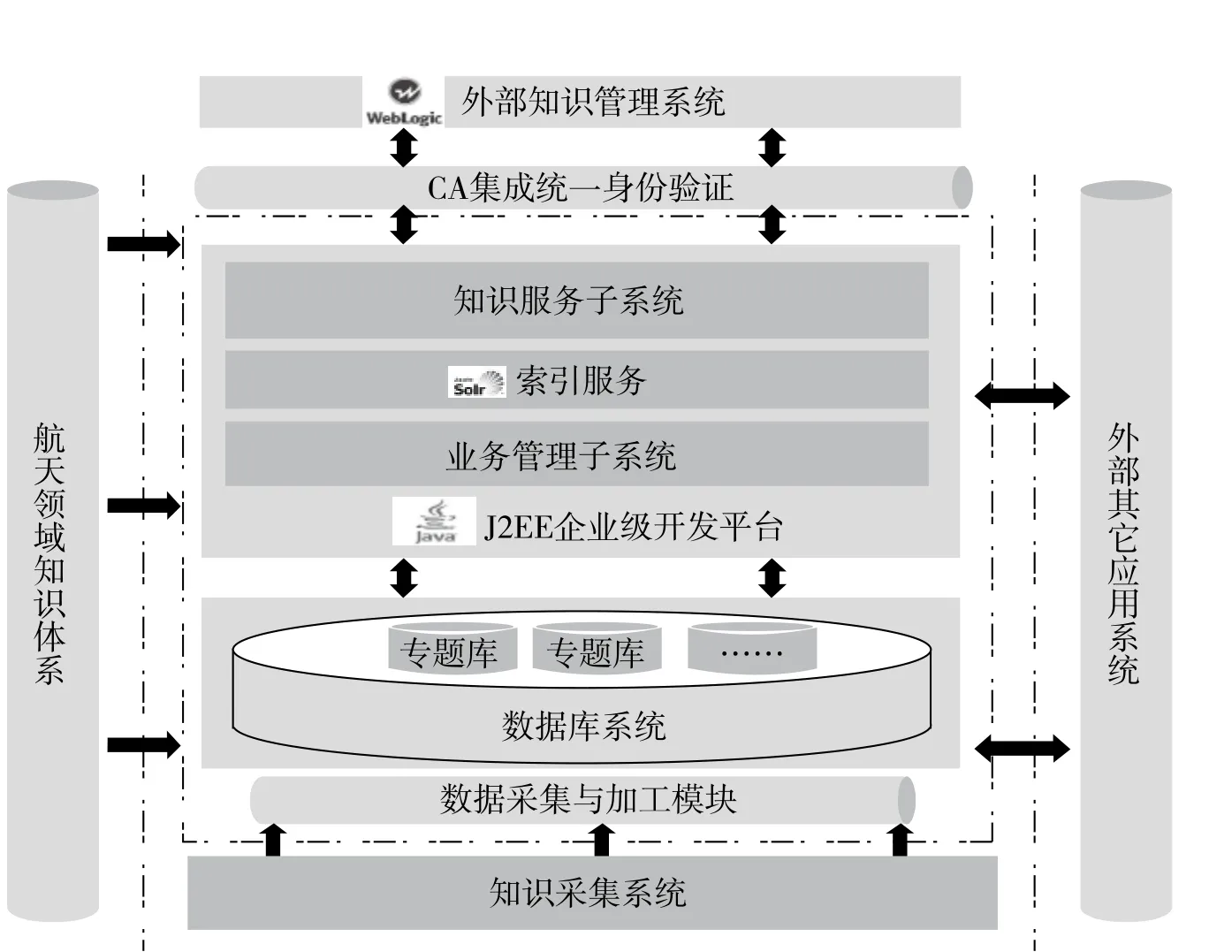
圖1 外部知識管理系統構架
1.總體架構(見圖1)
知識采集子系統實現底層數據資源采集,數據資源包括清華同方等數據庫系統和互聯網數據,通過數據采集加工模塊實現數據的自動采集與加工,并借助航天領域的專業敘詞對采集的數據進行標注和加工,形成專題知識庫。
業務管理子系統實現對整個系統的管理控制,包括用戶和權限、知識體系、專題知識庫的采集配置以及對專業敘詞的管理。同時可針對系統的使用情況進行統計和匯總,并對系統參數、專題數據庫進行批量數據導入導出,滿足數據遷移和不同系統間交換的需要。
知識服務子系統借助于底層結構良好的專題知識庫以及自動索引和知識服務組件,實現知識檢索、導航及個性化的服務。同時系統在開放和交互層面預留充分的接口,支持集成研究院的門戶系統并能實現用戶的統一身份認證,也支持其它業務系統的數據交互。
2.技術路線
系統整體以B/S架構為主、部分功能采用C/S架構輔助的方式,模塊與功能基于SOA的服務架構進行設計與構建。
◆互聯網數據和專題知識庫的采集基于微軟.NET技術開發的Windows應用程序實現,C/S架構,主要考慮到.NET Frameworks強大的網絡通訊類庫支持和桌面程序開發的便捷性較為適合進行數據采集、調試和跟蹤。開發工具使用微軟Visual Studio 2010和 .NET Frameworks 4.0運行環境平臺。
◆業務管理和知識服務功能基于JAVA的J2EE開發框架構建,B/S架構,適合進行企業級的門戶網站開發與定制,有成熟、穩定和安全的開源框架支撐及跨平臺的系統部署支持,充分保障了系統的技術優勢。開發工具采用MyEclipse 10.0 和JDK1.6運行平臺。
◆海量數據的索引基于開源軟件Solr搭建,并進行自主二次開發和定制,滿足不同專題知識庫索引構建的需要以及與敘詞管理模塊、知識體系的掛接整合,為系統提供高性能的檢索服務。
◆設計系統時充分考慮每個模塊的可擴充接口,保證系統能隨時加掛各種應用模塊,支持應用的橫向擴展,當服務器資源無法滿足應用需求時可簡單地部署在多臺服務器上。

圖2 外部知識管理系統部署規劃
◆系統采用開放性框架體系,使用標準XML格式數據作為系統間數據調用和傳輸的載體,以便于多個系統之間共享、交換數據。
3.系統部署
研究院外部知識管理系統以大集中的方式進行部署,應用與數據全部集中模式。在院級部署一套系統,院屬單位所有用戶均登錄到此系統進行訪問,如圖2所示。
采集服務器主要完成互聯網大規模數據采集與存儲,需進行分布式采集,由一臺采集中控服務器進行采集總體控制,并通過其分發任務進行采集,運行狀態向中控反饋。
數據庫服務器的可靠性和可用性是首要的需求,其次是數據處理能力和安全性,然后是可擴展性和可管理性。
索引服務器必須依靠高性能的索引服務在數據庫之外構建索引服務。
資源加工服務器在完成自動數據處理的同時為資源加工人員提供相應的服務,如詞表資源的人工構建、數據標引的人工糾錯等服務,滿足數據處理的各種需要。
應用服務器應具有較高的會話處理能力,以及較高的磁盤輸入/輸出。

三、關鍵技術
1.自動采集整合
實現互聯網信息資源的自動采集、加工和存儲,能夠建成各個領域多個面向主題的數據庫,最終形成本地數據庫。對數量龐大的信息源能夠方便、快捷地獲取和分析,從而提升情報研究、知識發現、科學預測、技術預見、科研評價及決策咨詢服務的能力。
按照研究院專業技術樹的結構建立各專業的外部知識專題庫,并實現圖書館多種電子數據庫資源的自動采集,可對更新周期、采集對象、知識類型、專業采集檢索式、專業技術樹進行管理。
自動采集的對象主要包括:以互聯網各門戶網站、軍事網站、科技網站等為采集對象,搜集、整理與研究院專業技術、型號任務、業務發展相關的專業技術、新聞消息等各類外部知識。從互聯網中采集的外部知識資源需識別標題、作者、機構、發布時間等相關記錄項。以研究院涉密內網部署的圖書館資源數據庫為采集對象,識別標題、作者、關鍵詞、作者機構、發布時間等相關記錄項。
為了保證所采集外部知識的質量,采集模塊需實現以下功能:
圖2為Bi2O3薄膜樣品的SEM圖.可以明顯看出,樣品B-air的顆粒為短棒狀,局部區域有一定程度的團聚(見圖2(a)).樣品B-N2的顆粒呈規則的橢圓球體,顆粒之間邊界分明,并沒有團聚現象(見圖2(b)).而樣品B-O2的顆粒則發生嚴重團聚,形成大小不一的團簇,顆粒之間沒有明顯的邊界(見圖2(c)).
一是內容過濾。能夠自動過濾掉不需要采集的網頁、媒體文件、廣告、欄目,有效避免垃圾信息的下載以及對帶寬的浪費,同時保存網頁中與正文相關的表格和圖片。
二是自動排重。對采集到的數據進行自動排重,可以從標題、URL、內容3個層次上對數據進行排重,減少系統中的重復數據。
三是元數據(包括作者、摘要、期刊、單位、卷期、關鍵詞、分類號等基本信息)抽取。可以靈活配置內容提取模板,自動從網頁html代碼中提取標題、作者、來源、時間等元數據,同時識別正文區域。
四是知識采集人員可對入庫的文獻數據實現批量或單篇的手動標引,內容包括所屬專業分類、關鍵技術點等。
2.全文檢索
經過采集以及資源整合后的文獻數據存儲到全文檢索數據庫中,該數據庫將承擔標引、自動分類、自動聚類、全文檢索等功能,其中音視頻資料也可進行自動分類標引并創建索引。
全文檢索是對電子文檔、網頁、語音、圖像等非結構化數據進行綜合管理,核心功能是實行非結構化信息的統一存儲管理與全文檢索,提供對包含元數據信息的半結構化數據及關系型數據庫的良好支持。全文檢索技術將搜索技術無縫整合到了外部知識管理系統,實現高效的知識檢索應用服務。遵循傳統的文獻檢索和知識檢索結合的思路,提供普通檢索、高級檢索、專業檢索、二次檢索、專利知識特色檢索,以滿足用戶的使用需求。
3.知識導航
知識地圖功能是采用Flex技術開發,具有Flash程序的交互性和動畫性,能夠直觀展現知識節點之間的關系并引導用戶進行逐級的知識漫游,通過動態變化增加用戶的應用樂趣。
在初始狀態下,知識地圖僅載入一個中心節點及其相鄰節點。當點擊任意一個頂點時,該頂點會變為中心頂點,同時會載入數量有限的更多與之相關的頂點。所有的頂點都可以自動避開其余頂點找到合適的空間位置,避免了頂點的重疊,便于用戶操作點擊。同時,知識地圖可以計算每個頂點與中心頂點的最小距離,使用適當的放縮系數使靠近中心頂點的頂點面積較大,而遠離的面積較小,整個知識體系主次分明。
4.跨庫檢索
跨庫檢索主要用于滿足用戶的資源整合、實時快速檢索的需求,對數據資源采用虛擬資源整合技術。用戶可以通過一個統一的資源搜索入口,以統一的檢索方式搜索和訪問所有整合的虛擬數據庫資源,以統一的格式獲取所需信息資源。
資源整合庫主要負責從開放資源接口的廠商數據庫中采集資源信息并重新加工整合為本地數據庫。該庫主要定義了各資源庫的相關配置和轉換方式,通過該資源庫提取出鏡像數據庫中的資源信息,配置索引信息,經過分類排重等操作建立新的表結構信息,整合加工后存儲至資源整合數據庫中,方便數據的統一管理。
對于未開放資源接口的資源庫信息,采用代理檢索技術,模擬用戶登錄本地鏡像資源庫發送檢索請求,利用網絡爬蟲技術抓取特定網頁。從抓取到的網頁中抽取所包含的相關信息(元數據、原文鏈接),將數據進行相似度排序、重新整理,以統一的方式將查詢結果展示。
5.知識采集管理
采集策略包括檢索詞、檢索式和采集周期。采集人員可以通過該功能對各檢索策略進行添加、刪除和修改操作,并對采集周期進行設定,以實現系統按照設定時間自動進行知識的增量更新。采集檢索式要能夠實現與、或、非以及嵌套等常用邏輯運算。
所有知識均按照專業技術分類和入庫時間進行分類排序,并對文獻實現按照專業技術分類、入庫時間、標題、作者、機構、關鍵詞和摘要的檢索查詢功能。管理員可對外部知識資源按照專業分類、時間、檢索結果等進行批量(單篇)添加、刪除和修改操作。
中國運載火箭技術研究院外部知識管理系統第一階段實現了知識采集與整合、服務、挖掘分析專利文獻服務和系統管理等功能模塊,與研究院門戶系統實現單點登陸集成,與CA系統集成實現數字簽名認證。外部知識管理系統的建設實現了高效整合知識資源,拓寬了技術人員知識獲取的途徑,滿足了個性化知識需求并促進了知識共享與交流,有效支撐了研究院的專業發展和技術創新。

猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
商周刊(2017年9期)2017-08-22 02:57:56
資源再生(2017年3期)2017-06-01 12:20:59
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
