基于Copula理論和非參數極值估計在上下游水位的相關性分析應用
2015-04-24 05:17:26趙凱鴿袁永生吳清嬌
服裝學報 2015年2期
關鍵詞:模型
趙凱鴿,袁永生,吳清嬌
(河海大學理學院,江蘇南京210098)
自從Sklar教授于1959年提出Copula函數的概念以來,經過諸多學者的深入研究,形成了Copula函數的基本理論,并且在各個領域得到了廣泛應用,取得了豐富的研究成果。Copula不僅將經典統計學中的線性相關系數及其他相關系數與Copula函數聯系起來,推導出Copula函數與相關系數的關系式,并且能有效地解決一些非線性、非對稱的復雜相關性問題。Copula函數理論的核心是Sklar定理,其重要意義在于將聯合分布函數與其邊緣分布函數聯系起來,并提供了一種由一元邊緣分布構造多元聯合分布函數的途徑和方法,其推論給出了利用連續分布函數的偽逆函數和聯合分布函數求出其相應Copula函數的方法。Copula理論是一種定性與定量分析相結合的統計分析方法。
由Copula導出的相關性度量不僅可以描述變量間的非線性、非對稱相關關系,而且還可以刻畫尾部的相關性。把Copula與時變相結合,構建了t-Copula模型,這一模型將Copula中的參數看成時間的某個確定函數來進行建模,這樣將會減小模型假定錯誤所帶來的偏差。由于相關結構具有相當的不確定性和復雜性,Copula參數的時變結構根本就是未知的,很多文獻采用半參數模型和非參數模型,更實用、更有效、更有意義。
事實上,很多模型的邊際分布是無法準確定位的,因而傳統的參數估計存在一定的局限性。由于非參數估計是不需要事先知道模型的邊際分布,基于此,文中運用非參數技術來估計Copula函數中的參數,從而克服了傳統參數估計的不足。
在國外,Fermaniam[1]認為高維數據進行Rosenblatt變換比較困難,直接利用基于樣本數據的多變量核密度估計的密度函數與均勻密度函數相比較;Werker[2]利用秩相關函數τ的演化方程確立的時變Copula模型來研究波動溢出的問題;Genest[3]利用數據的概率積分變換來估計其相應的密度模型,從而確定最優的Copula函數;Gordon和Johan對任意維下的極值Copula進行非參數估計;Gudendorf G,Segers J[4]從理論上研究了任意維數的極值Copula函數的非參數估計。
在國內,學者張堯庭[5]從理論上探討了Copula在金融上應用的可行性;韋艷華、張世英[6]等用Copula-ARCh模型研究了上海證券市場中幾個板塊間的相關性;史道濟,張明恒[7]等也應用Copula函數對金融市場的相關性作過一些探討;趙麗琴、籍艷麗[8]采用對邊際分布不作具體假設的非參數核密度估計Archimedean Copula的參數,并用實際說明其方法的有效性。
文中對現有的非參數估計量進行改進,克服了現有估計量的譜測度H的限制,并引進新的非參數極值估計Z—L方法,以涇流從1975年到1996年上游和下游在不同時間的水位、流量和含沙為例,給出非參數估計的具體實現過程。
1 Copula理論簡介
Copula理論是由Sklar在1959年提出的。Sklar指出,可以將任意一個n維聯合累積分布函數分解為n個邊緣累積分布函數和一個Copula函數,其中邊緣分布函數描述的是變量的分布,Copula函數描述的是變量之間的相關性。也就是說,Copula函數實際上是一類將變量聯合累積分布函數同變量邊緣分布函數連接起來的紐帶函數,因此也有人稱其為“連接函數”。
1.1 Copu la函數的定義及Sk lar定理
定義1 n維Copula函數[9](或稱為n-Copula)是一個函數C,具有如下性質:
1)定義域為 In,即[0,1]n;
2)對于任意 t=(t1,t2,…,tn)∈[0,1]n,若至少有一個tk=0,則C(t)=0;
3)C有零基面(grounded),且是n維遞增的,即對于定義域中的任意真子集
B= [a1,b1]× [a2,b2]× …[an,bn]有
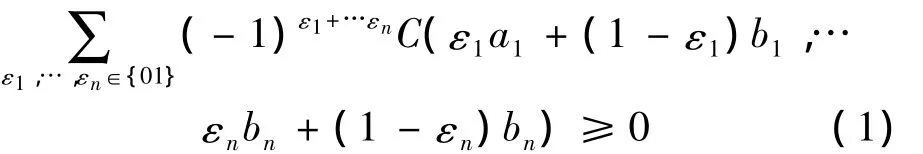
4)對于任意u∈[0,1],C的邊緣函數Ck滿足
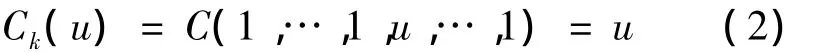
定理2(Sklar定理)Sklar定理[10]是 Copula函數理論的核心,也是基礎,在統計學中的應用最為廣泛,其闡明了多元分布函數與其邊緣分布函數的關系。
令F是d維聯合分布函數,其邊緣分布F1,…,Fd,一定存在一個 d-Copula函數C,對于任意向量x=(x1,…,xd)∈ Rd,則有
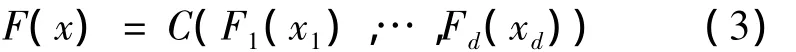
如果F1,…,Fd都是連續的,則C是唯一的;否則C在Ran F1×…×Ran Fd上是唯一的。相反,如果C是一個d-Copula且F1,…,Fd是邊緣分布函數,則由式(3)確定的函數是邊緣分布為F1,…,Fd的d維聯合分布函數。
對于有連續的邊緣分布情況,對于所有的u∈[0,1]d,均有
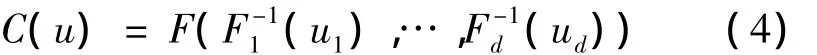
1.2 隨機變量間的相關性度量
任何變量之間如果不是相互獨立的,那么一定會存在一定的相關關系。幾種常用的刻畫多個隨機變量之間的相關性度量,有線性相關系數、Kendall秩相依系數、Spearman秩相依系數、尾部相關系數等,其中Kendall秩相依系數和Spearman秩相依系數是刻畫一致性的,而尾部相關系數是一個極值理論的測度,用來表示當一個觀測變量的實現值為極值時,另一個變量也出現極值的概率。
相關性一直是人們關注的一個焦點問題。Nelsen指出,若對變量作單調增的變換,相應的Copula函數不變,因而由Copula函數導出的一致性和相關性測度的值也不會改變。
1.2.1 線性相關系數(Linear Correlation)(x,
y)T為一個具有非零有限方差的隨機向量,則基于兩個隨機向量(x,y)T的線性相關系數被定義為
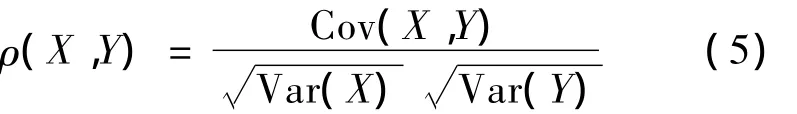
如果兩個隨機變量是獨立的,它們的線性相關系數ρ(x,y)=0;但是反過來卻并不成立。如果 |ρ(x,y)|=1,那么兩個隨機變量完全相關。在嚴格的單調遞增線性變換中,線性相關系數是不變的;但在嚴格的單調遞增的非線性變換中,相關系數卻是改變的。
1.2.2 Kendall秩相依系數
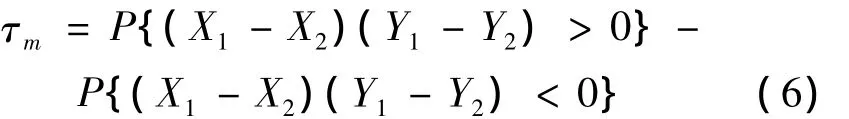
因此,Kendall秩相依系數 τm[3]可以用來反應隨機向量變化一致性的程度。特別地,當τm=1、τm=-1和τm=0時,分布表示X和Y變化完全一致正相關、完全一致負相關和不能確定是否相關。
1.2.3 Spearman 秩相依系數
1.2.4 尾部相關系數
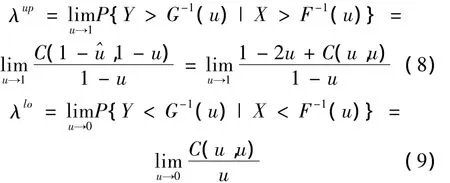
其中
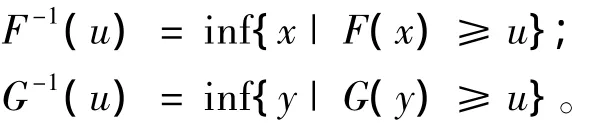
若尾部相關系數[6]λup或 λlo∈ (0,1],則隨機變量X,Y上尾或下尾相關;若λup或λlo=0,則隨機變量X,Y上尾或下尾漸進獨立。
在實際生活中,數據多呈現出尖峰后尾性,對尾部相關關系的分析是掌握波動變化規律以及有效控制風險的一個關鍵問題。而基于Copula函數的尾部相關系數包含了尾部相關的全部信息,就可以更全面、更深入地描述變量之間的相關關系。
1.3 極值Copula及其改進
在實踐生活中,與極值分布函數[11]相對應的是重要的極值Copula函數簇,而對于樣本最大值的廣義極值分布的邊緣
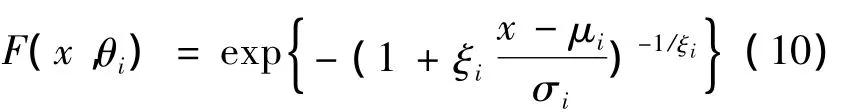
這里
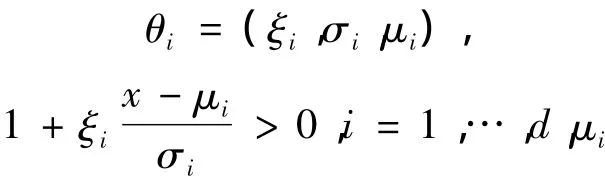
是一個位置參數,σi>0是一個尺度參數,ξi∈R是一個形狀參數,它是極值指標。
假定 Sij= - ln Fj(xij),1≤i≤n,1≤j≤ d,并且是標準的指數自由變量對于 ω ∈ Δd-1,有
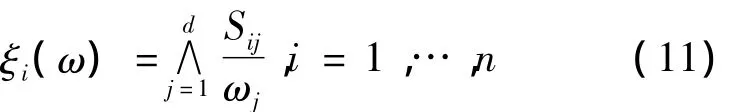
冪型方程:g(x)=xa,a > 0,有
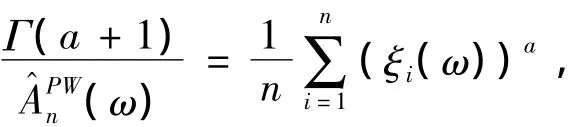
當a=1時剛好是基本的Pickands型估計量。
對數方程:g(x)=ln x,有
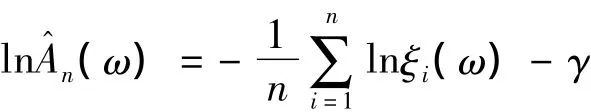
它剛好是CFG估計量。
上面兩個方程滿足頂點約束:A(ei)=1,…,d
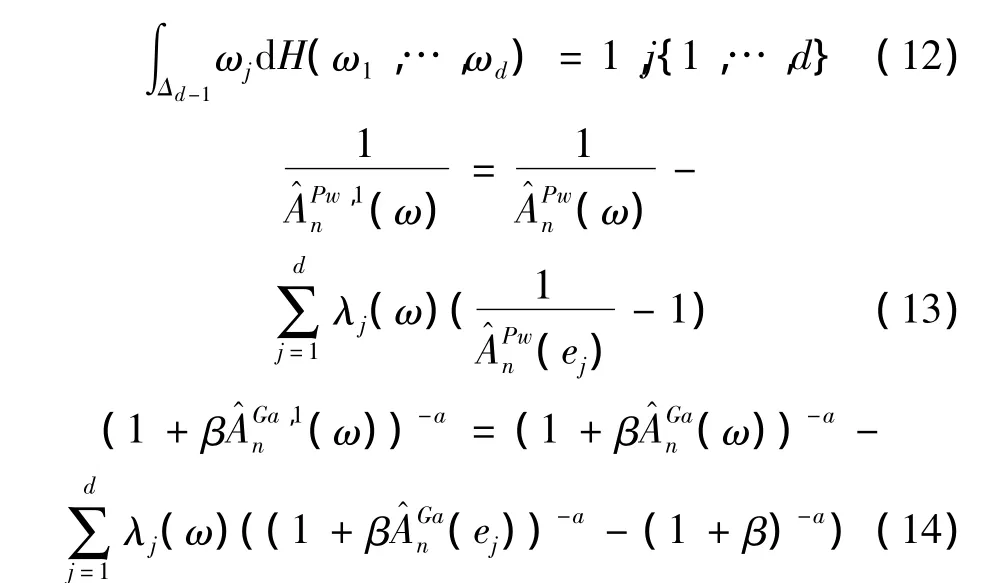
其中λj(ω):Δd-1→R上驗證λj(ek)= δjk,k=1,…,d是連續函數(δjk是克羅內克δ方程)。所以有
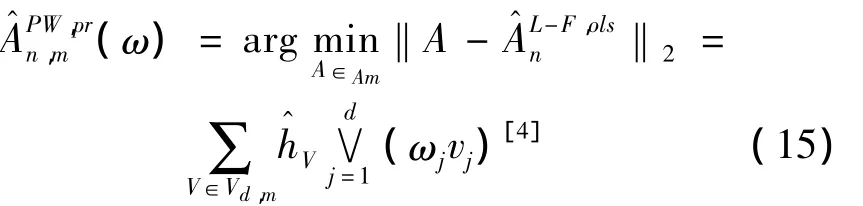
2 非參數核密度估計簡介
由于上下游水位高低分布出現的“尖峰”、“厚尾”現象,很多情況下不滿足正態分布。有文獻采用t-GARCH來描述,還有文獻采用經驗分布來表述。這些方法都有合理的一面,但也有其不合理的一面。比如說,t-GARCH假設本身就是一種局限,而經驗分布一般不連續,光滑性不夠,用來表述上下游水位高低的分布所產生的誤差較大,介于這些不利因素,現應用非參數核密度估計技術來處理上下游水位的邊緣分布。
下面的結論仍然成立。
2.1 非參數核密度估計的定義及基本統計性質
設K(·)為R1上一個給定的概率密度函數,hn>0是一個與有關的常數,滿足當n→∞,hn→0,則
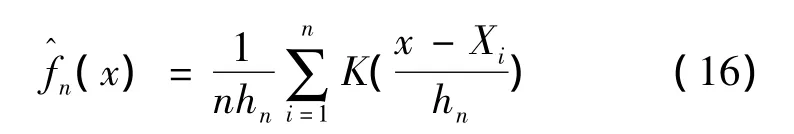
為f(x)的一個核估計,其中K(·)稱為核函數,hn為窗寬或光滑參數。
定理3 若(rA,rB)在點分布函數值的估計分別為
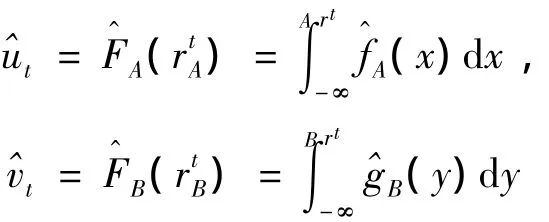
則當核函數選取為正態核,上面兩式可以表示為
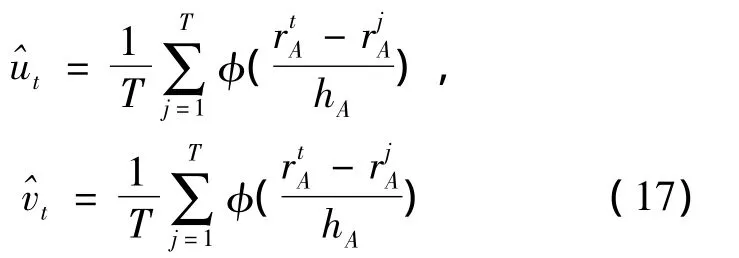
在進行非參數核密度估計時,要解決的問題是如何選擇恰當的核函數及如何確定最優的光滑參數。
2.2 核函數的選擇
核函數的選擇[13]可以有很多種,但是在一般情況下,核函數的選擇往往取決于根據距離分配各個樣本點對密度貢獻的不同。通常選擇什么樣的核函數并不是密度估計中最關鍵的因素,因為選用的任何核函數都能保證密度估計具有穩定相合性。最重要的是光滑參數對估計分布的光滑程度影響很大,所以選擇什么樣的光滑參數是很重要的。
2.3 光滑參數的選取
由式(17)可知,核密度估計的應用需要決定光滑參數hn,而分布密度函數是連續的,所以由的均方誤差(MISE),即MISE的最小來確定hn。由極值定理,解
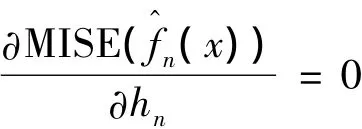
可得到hn的一個最使滿意的解:
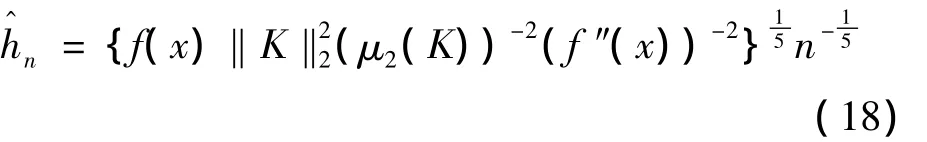
其中
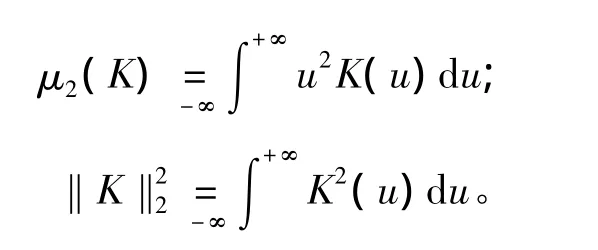
通常使用經驗法則決定光滑參數,假設f(x)為正態概率密度N(0,σ2),若核函數選取為正態核,則有

3 時變Copula模型的非參數極值估Z-L計算法
設有時間序列{(Xi,Yi),t=1,2,…,T},單變量隨機時間序列{Xi}和{Yi}都是平穩的,現對{Xi}和{Yi}之間的聯合分布或相關結構進行建模,根據時變Copula模型的非參數估計思路,得出算法:
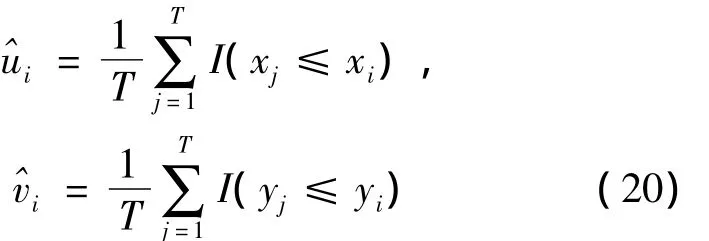
其中I(·)是示性函數。
其次,確定最佳光滑參數[14],也就是給定光滑參數的可能取值集合,比如{h1,h2,…,hm};然后對光滑參數的每一個可能取值 hi,i=1,2,…,m,在偽樣本觀測條件下根據下式:
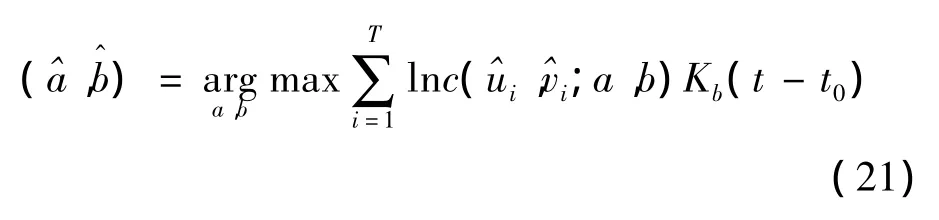
其中核函數選取
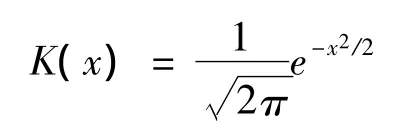
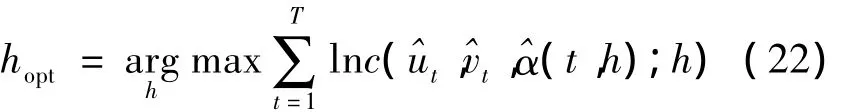
最后,時變Copula模型的非參數極值Z-L估計:
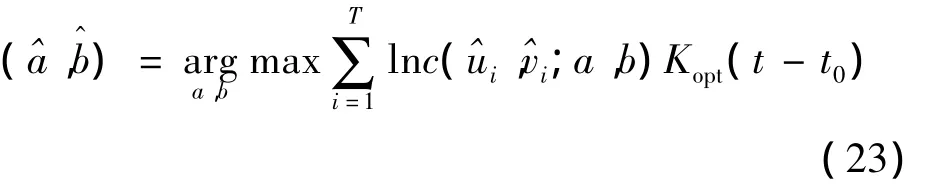
由式(23)就可以得到時變Copula模型的時間點t0的參數估計量(t0)=,再將此過程對每一個時間點進行循環,就得到時變Copula模型參數估計量的時變軌跡。
4 徑流上下游水位的相關性
文中數據包括1975年至1996年夾河灘水位和高村水位,共計497個調查數據。首先用核方法來估計密度函數,核估計主要是由核密度函數和窗寬構成。水位的變化率定義為:Xt=10(ln Pt- lnt-1),再選取高斯核函數
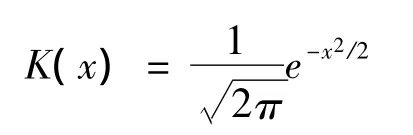
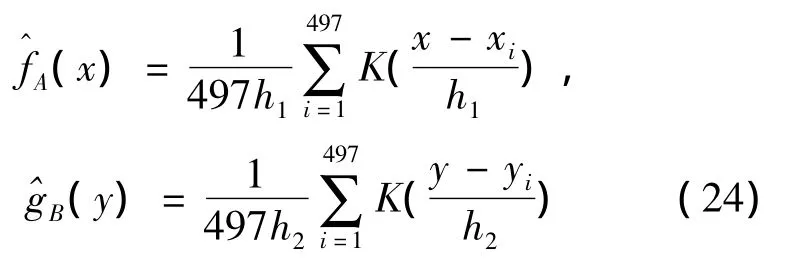
從圖1a,b可以看出,整個分布略顯左偏,表現出一定的間峰程度。夾河灘和高村的水位變化具有很強的厚尾性,且兩者間的變化存在一定的相關性,這和實際生活中的情況是一致的。下面觀察水位變化率序列的統計特征,其結果如表1所示。
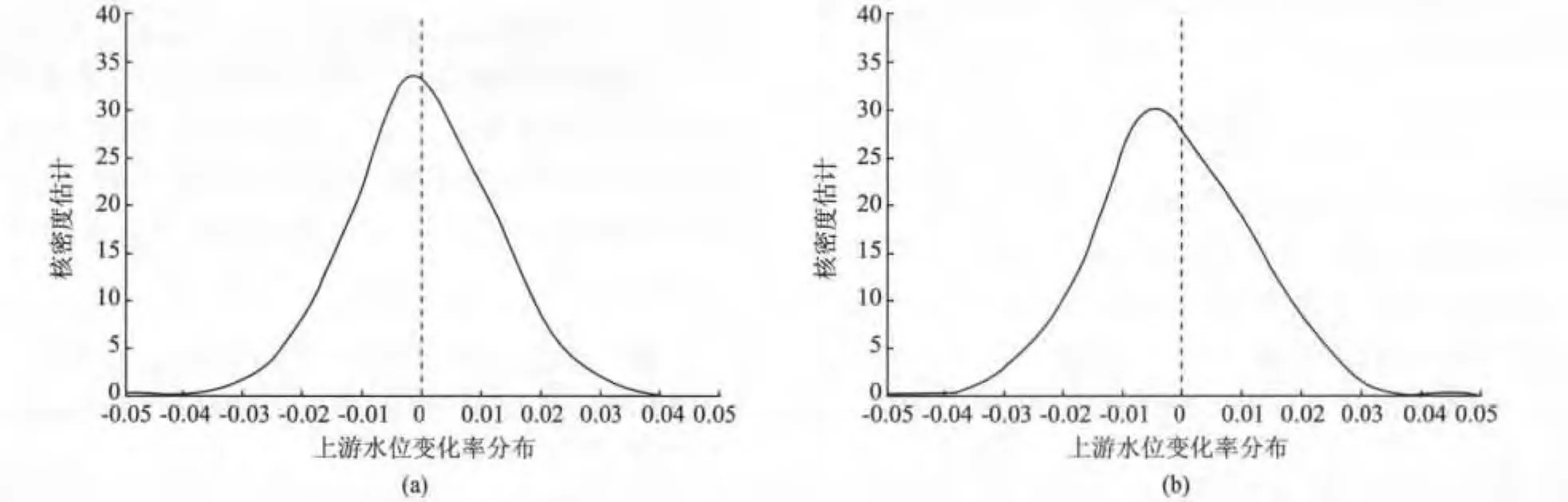
圖1 夾河灘和高村水位的邊際密度的核估計Fig.1 Nuclear estimate of the C lip quay’s and the High village’smarginal density

表1 上游、下游水位序列的基本統計Tab.1 Basic statistics of upstream and downstream’s water level sequences
由表1數據可以知道,上游和下游水位的均值和標準差都大于0,高村的峰度比較大,這即是經常說的尖峰厚尾特征。負的偏度表明在整個調查期間,水位下降的天數少于上升的天數,每天上升的平均幅度高于每天下降的幅度。高的峰度表明水位以更大的概率出現在各自的均值附近。
圖2a,b分別給出上游夾河灘和下游高村的水位變化率的時間序列。可以看出,它們之間的波動有一定的相似性,這說明上游、下游水位的變化有一定的聯系。
還求得相應的相關系數如下:Linear Correlation 0.735 36;Kendallτm0.914 83;Spearman ρk0.907 35;尾部相關系數0.886 21。數據說明上游夾河灘和下游高村的水位存在著較強的相關性,且ρk和τm比經典的相關系數大,可見運用非參數核密度估計得到的Copula函數參數值是非常準確的。
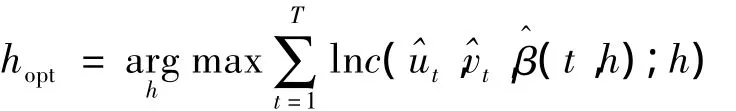
通過公式計算得到夾河灘、高村水位樣本的Kendalls秩相關系數,其值非常接近1,說明夾河灘和高村的水位具有極高的正相關性,與實際情況相符。同時也說明文中所估計的Copula是合理的,非參數極值估計Z-L算法在Copula函數的估計問題上是可行的。

表2 參數估計Tab.2 Parameter estimation
因此,非參數估計Copula密度函數在其度量模型相關方面是有意義的,并且在研究實際問題時,利用非參數估計相依模型間的聯系是很有效的,它也能夠避免由于失當的模型或參數的選擇所產生的誤差。
致謝:東南大學數學系林金官教授所作關于《鏈接函數的非參數極值估計》的報告,對本文幫助很大,僅此致謝!
[1]Jean-David Fermanian J.Goodness-of-fit tests for Copulas[J].Journal of Multivariate Analysis,2005,95(1):119-152.
[2]Rob W J,van den Goorbergh,Christian Genest,et al.Bivariate option pricing using dynamic copula models[J].Insurance:Mathematicsand Economics,2005,37:101-114.
[3]Genest C J,Quessy F,Remillard B.Goodness-of-fit procedures for copulamodels based on the probability integral transform[J].Scandinavian Journal of Statistics,2006,33(2):337-366.
[4]Gudendorf G,Segers J.Nonparametric estimation of an extreme-value copula in arbitrary dimensions[J].Journal of Multivariate Analysis,2011,102(1):37-47.
[5]張堯庭.連接函數(Copula)技術與金融風險分析[J].統計研究,2002(4):48-51.ZHANG Tingyao.Copula technique and risk analysis[J].Journal of Northwest Statistical Research,2002(4):48-51.(in Chinese)
[6]韋艷華,張世英,孟利峰.Copula理論在金融上的應用[J].西北農林科技大學學報:社會科學版,2003,3(5):97-101.WEIYanhua,ZHANG Shiying,MENG Lifeng.The application of Copula in the financial[J].Journal of Northwest Sci-Tech University of Agriculture and Forestry:Social Science Edition,2003,3(5):97-101.(in Chinese)
[7]張明恒.多金融資產風險價值的Copula計量方法研究[J].數量經濟技術經濟研究,2004(4):29-32.ZHANG Lingheng.Many financial assets value at risk of copulasmeasurementmethod research[J].Quantitative and Technica Economics,2004(4):29-32.(in Chinese)
[8]趙麗琴,籍艷麗.Copula函數的非參數核密度估計[J].統計與決策,2009(9):29-32.ZHAO Liqin,JI Yanli.Copula and nonparametric kernel density estimation[J].Statistics and Decision,2009(9):29-32.(in Chinese)
[9]Nelsen R B.An Introduction to Copulas[M].2nd ed.New York:Springer Science Business Media,2006:7-19,157-215.
[10]Capéraà P,Fougères A L,Genest C.A nonparametric estimation procedure for bivariate extreme value copulas[J].Biometrika,1997,84(3):567-577.
[11]Bücher A,Dette H,Volgushev S.New estimators of the Pickands dependence function and a test for extreme-value dependence[J].The Annals of Statistics,2011,39(4):1963-2006.
[12]Prakasa Rao B L S.Nonparametric Function Estimation[M].London:Academic Press Inc,1983.
[13] ZHANG D,Wells M T,PENG L.Nonparametric estimation of the dependence function for a multivariate extreme evalue distributions[J].Journal of Multivariate Analysis,2008,99(4):577-588.
[14]龔金國,史代敏.時變Copula模型非參數估計的大樣本性質[J].浙江大學學報:理學版,2012,39(6):630-642.GONG Jinguo,SHIDaimin.Large sample properties of nonparametric estimation in time-varying Copula model[J].Journal of Zhejiang University:Science Edition,2012,39(6):630-642.(in Chinese)
[15]龔金國.Copula與非參數核密度估計[D].成都:四川大學,2005.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
